CNN卷积神经网络模型的GPU显存占用分析
一、参考资料
浅谈深度学习:如何计算模型以及中间变量的显存占用大小
如何在Pytorch中精细化利用显存
二、相关介绍
0. 预备知识
为了方便计算,本文按照以下标准进行单位换算:
- 1 G = 1000 MB
- 1 M = 1000 KB
- 1 K = 1000 Byte
- 1 B = 8 bit
1. 模型参数量的计算方法
参考博客:CNN卷积神经网络模型的参数量、计算量计算方法(概念版)
2. 张量的数据类型
| Data type | dtype | CPU tensor | GPU tensor |
|---|---|---|---|
| 32-bit floating point | torch.float32 or torch.float | torch.FloatTensor | torch.cuda.FloatTensor |
| 64-bit floating point | torch.float64 or torch.double | torch.DoubleTensor | torch.cuda.DoubleTensor |
| 16-bit floating point | torch.float16 or torch.half | torch.HalfTensor | torch.cuda.HalfTensor |
| 8-bit integer (unsigned) | torch.uint8 | torch.ByteTensor | torch.cuda.ByteTensor |
| 8-bit integer (signed) | torch.int8 | torch.CharTensor | torch.cuda.CharTensor |
| 16-bit integer (signed) | torch.int16 or torch.short | torch.ShortTensor | torch.cuda.ShartTensor |
| 32-bit integer (signed) | torch.int32 or torch.int | torch.IntTensor | torch.cuda.IntTensor |
| 64-bit integer (signed) | torch.int64 or torch.long | torch.LongTensor | torch.cuda.LongTensor |
通常,模型训练使用以下两种数据类型:
float32单精度浮点型;int32整型。
8bit的整型int所占的空间为 1B,32bit的浮点型float所占空间为 4B。而double双精度浮点型和长整型long在平常的模型训练中一般不会使用。
消费级显卡对单精度计算有优化,服务器级显卡对双精度计算有优化。
3. 关于inplace=False
我们都知道激活函数Relu()有一个默认参数inplace,默认设置为False。当设置为True时,我们在通过relu()计算得到的新值不会占用新的空间,而是直接覆盖原来的值,这也就是为什么当inplace参数设置为True时可以节省一部分内存的缘故。

三、显存占用相关介绍
0. 引言
torch.FatalError: cuda runtime error (2) : out of memory at /opt/conda/conda-bld/pytorch_1524590031827/work/aten/src/THC/generic/THCStorage.cu:58
由于显存不足,导致程序崩溃。学会计算模型以及中间变量所占显存大小,是很有必要的。
1. 图片的显存占用
假设一张RGB三通道真彩色图片,长宽分别为 500x500,数据类型为单精度浮点型,那么这张图片所占显存的大小为:500x500x3x4B=3MB。而一个 (256, 3, 100, 100)-(N, C, H, W) 的FloatTensor所占的空间为:256x3x100x100x4B = 31MB
2. 模型的显存占用
通常,模型占用的显存来自两个部分:
- 模型自身的参数(params),即有参数的网络层。
- 模型在计算时产生的中间参数(memory)。

一般来说,模型自身参数并不会占用很多的显存空间,主要占用显存空间的是计算时产生的中间参数。
2.1 模型自身的参数(params)
有参数的网络层,包括:
- 卷积层:
Conv2d(Cin, Cout, K),参数量为Cin × Cout × K × K - 全连接层:
Linear(M->N),参数量为M×N - BatchNorm层:
BatchNorm(N),参数量为2N - Embedding层:
Embedding(N,W),参数量为N × W
不带参数的网络层,包括:
- 激活层Relu等;
- 池化层;
- Dropout层;
2.2 模型的中间参数(memory)
- 模型在计算时产生的中间参数,也就是输入图像在计算时每一层产生的输入和输出;
- backward反向传播计算时产生的额外的中间参数;
- 优化器在优化时产生的额外的模型参数。
3. 实际显存与理论显存
为什么实际占用的显存空间比理论计算的大?
大概原因是深度学习框架一些额外的开销。不过,通过上面公式计算出来的显存理论值和实际值不会相差太多。
4. 计算显存占用大小
4.1 方法一(推荐)
使用 torchstat 工具,计算模型的显存占用大小。参考博客:CNN卷积神经网络模型的参数量计算方法(经验版)
4.2 方法二
当然,也可以自定义函数计算显存占用大小,代码如下所示:
# 模型显存占用监测函数
# model:输入的模型
# input:实际中需要输入的Tensor变量
# type_size 默认为 4 默认类型为 float32 def modelsize(model, input, type_size=4):para = sum([np.prod(list(p.size())) for p in model.parameters()])print('Model {} : params: {:4f}M'.format(model._get_name(), para * type_size / 1000 / 1000))input_ = input.clone()input_.requires_grad_(requires_grad=False)mods = list(model.modules())out_sizes = []for i in range(1, len(mods)):m = mods[i]if isinstance(m, nn.ReLU):if m.inplace:continueout = m(input_)out_sizes.append(np.array(out.size()))input_ = outtotal_nums = 0for i in range(len(out_sizes)):s = out_sizes[i]nums = np.prod(np.array(s))total_nums += numsprint('Model {} : intermedite variables: {:3f} M (without backward)'.format(model._get_name(), total_nums * type_size / 1000 / 1000))print('Model {} : intermedite variables: {:3f} M (with backward)'.format(model._get_name(), total_nums * type_size*2 / 1000 / 1000))
重要说明:当然,我们计算出来的显存占用理论值仅仅是做参考作用,因为Pytorch在运行的时候需要额外的显存开销,所以实际的显存会比我们计算的稍微大一些。
5. 显存优化方法
在Pytorch中优化显存是我们处理大量数据时必要的做法,因为我们并不可能拥有无限的显存。显存是有限的,而数据是无限的,我们只有优化显存的使用量才能够最大化地利用我们的数据。
优化除了算法层的优化,最基本的显存优化无非也就以下几点:
- 减少输入图像的尺寸;
- 减少batch,减少每次的输入图像数量;
- 多使用下采样,池化层;
- 一些神经网络层可以进行小优化,利用relu层中设置
inplace; - 购买显存更大的显卡;
- 从深度学习框架上面进行优化。
5.1 牺牲计算速度减少显存使用量
在PyTorch中,如果一个模型占用的显存太大了,可以将一个计算过程分成两半,先计算前一半,保存后一半需要的中间结果,然后再计算后一半。
# 首先设置输入的input=>requires_grad=True
# 如果不设置可能会导致得到的gradient为0# 输入
input = torch.rand(1, 10, requires_grad=True)# 假设我们有一个非常深的网络
layers = [nn.Linear(10, 10) for _ in range(1000)]# 定义要计算的层函数,可以看到我们定义了两个
# 一个计算前500个层,另一个计算后500个层def run_first_half(*args):x = args[0]for layer in layers[:500]:x = layer(x)return xdef run_second_half(*args):x = args[0]for layer in layers[500:-1]:x = layer(x)return x# 我们引入新加的checkpoint
from torch.utils.checkpoint import checkpointx = checkpoint(run_first_half, input)
x = checkpoint(run_second_half, x)# 最后一层单独调出来执行
x = layers[-1](x)
x.sum.backward()
对于Sequential-model来说,因为Sequential()中可以包含很多的block,所以官方提供了另一个功能包:
input = torch.rand(1, 10, requires_grad=True)
layers = [nn.Linear(10, 10) for _ in range(1000)]
model = nn.Sequential(*layers)from torch.utils.checkpoint import checkpoint_sequential# 分成两个部分
num_segments = 2
x = checkpoint_sequential(model, num_segments, input)
x.sum().backward()
6. 跟踪显存使用情况
再次浅谈Pytorch中的显存利用问题(附完善显存跟踪代码)
我们借用 Pytorch-Memory-Utils 这个工具来检测我们在训练过程中关于显存的变化情况,分析出我们如何正确释放多余的显存。
通过Pytorch-Memory-Utils工具,我们在使用显存的代码中间插入检测函数,就可以输出类似于下面的信息,At __main__ <module>: line 13 Total Used Memory:696.5 Mb表示在当前行代码时所占用的显存,即在我们的代码中执行到13行的时候所占显存为695.5Mb。At __main__ <module>: line 15 Total Used Memory:1142.0 Mb表示程序执行到15行时所占的显存为1142.0Mb。两条数据之间表示所占显存的tensor变量。
# 12-Sep-18-21:48:45-gpu_mem_track.txtGPU Memory Track | 12-Sep-18-21:48:45 | Total Used Memory:696.5 MbAt __main__ <module>: line 13 Total Used Memory:696.5 Mb+ | 7 * Size:(512, 512, 3, 3) | Memory: 66.060 M | <class 'torch.nn.parameter.Parameter'>
+ | 1 * Size:(512, 256, 3, 3) | Memory: 4.7185 M | <class 'torch.nn.parameter.Parameter'>
+ | 1 * Size:(64, 64, 3, 3) | Memory: 0.1474 M | <class 'torch.nn.parameter.Parameter'>
+ | 1 * Size:(128, 64, 3, 3) | Memory: 0.2949 M | <class 'torch.nn.parameter.Parameter'>
+ | 1 * Size:(128, 128, 3, 3) | Memory: 0.5898 M | <class 'torch.nn.parameter.Parameter'>
+ | 8 * Size:(512,) | Memory: 0.0163 M | <class 'torch.nn.parameter.Parameter'>
+ | 3 * Size:(256, 256, 3, 3) | Memory: 7.0778 M | <class 'torch.nn.parameter.Parameter'>
+ | 1 * Size:(256, 128, 3, 3) | Memory: 1.1796 M | <class 'torch.nn.parameter.Parameter'>
+ | 2 * Size:(64,) | Memory: 0.0005 M | <class 'torch.nn.parameter.Parameter'>
+ | 4 * Size:(256,) | Memory: 0.0040 M | <class 'torch.nn.parameter.Parameter'>
+ | 2 * Size:(128,) | Memory: 0.0010 M | <class 'torch.nn.parameter.Parameter'>
+ | 1 * Size:(64, 3, 3, 3) | Memory: 0.0069 M | <class 'torch.nn.parameter.Parameter'>At __main__ <module>: line 15 Total Used Memory:1142.0 Mb+ | 1 * Size:(60, 3, 512, 512) | Memory: 188.74 M | <class 'torch.Tensor'>
+ | 1 * Size:(30, 3, 512, 512) | Memory: 94.371 M | <class 'torch.Tensor'>
+ | 1 * Size:(40, 3, 512, 512) | Memory: 125.82 M | <class 'torch.Tensor'>At __main__ <module>: line 21 Total Used Memory:1550.9 Mb+ | 1 * Size:(120, 3, 512, 512) | Memory: 377.48 M | <class 'torch.Tensor'>
+ | 1 * Size:(80, 3, 512, 512) | Memory: 251.65 M | <class 'torch.Tensor'>At __main__ <module>: line 26 Total Used Memory:2180.1 Mb- | 1 * Size:(120, 3, 512, 512) | Memory: 377.48 M | <class 'torch.Tensor'>
- | 1 * Size:(40, 3, 512, 512) | Memory: 125.82 M | <class 'torch.Tensor'> At __main__ <module>: line 32 Total Used Memory:1676.8 Mb
当然这个检测工具不仅适用于Pytorch,其他的深度学习框架也同样适用,不过需要注意下静态图和动态图在实际运行过程中的区别。
相关文章:
CNN卷积神经网络模型的GPU显存占用分析
一、参考资料 浅谈深度学习:如何计算模型以及中间变量的显存占用大小 如何在Pytorch中精细化利用显存 二、相关介绍 0. 预备知识 为了方便计算,本文按照以下标准进行单位换算: 1 G 1000 MB1 M 1000 KB1 K 1000 Byte1 B 8 bit 1. 模型参数量的计…...
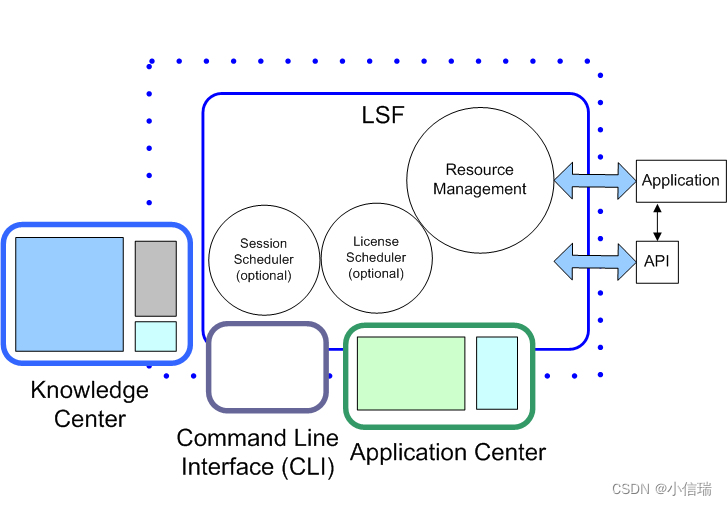
LSF 概览——了解 LSF 是如何满足您的作业要求,并找到最佳资源来运行该作业的
LSF 概览 了解 LSF 是如何满足您的作业要求,并找到最佳资源来运行该作业的。 IBM Spectrum LSF ("LSF", load sharing facility 的简称) 软件是行业领先的企业级软件。LSF 将工作分散在现有的各种 IT 资源中,以创建共享的,可扩展…...
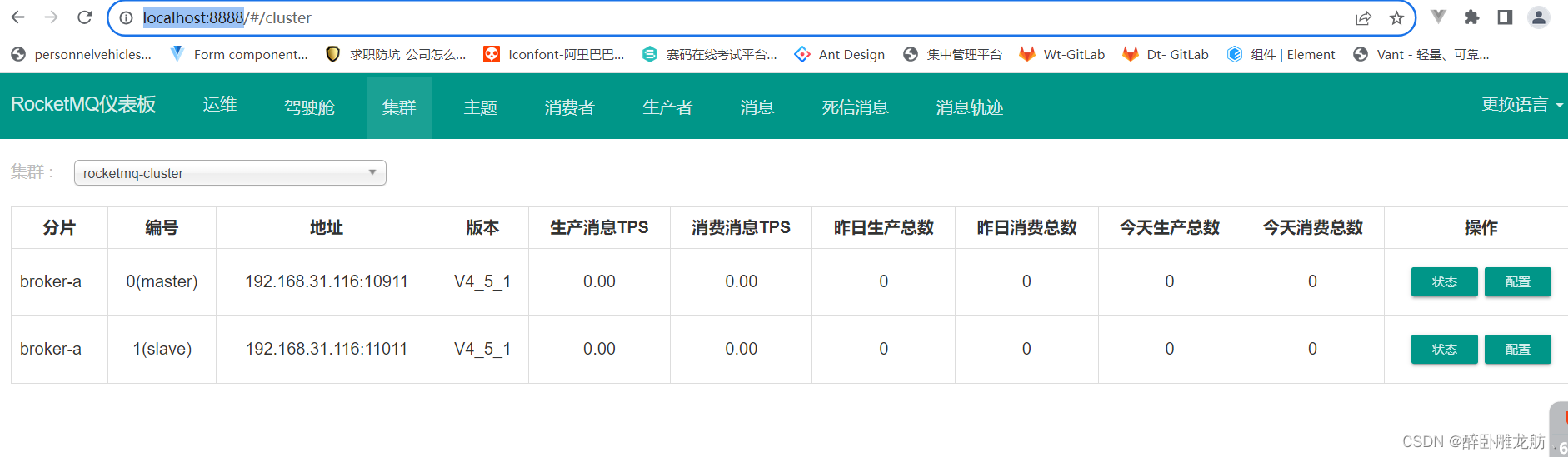
三.RocketMQ单机安装及集群搭建
RocketMQ单机安装及集群搭建 一:安装环境1.软硬件要求2.下载RocketMQ 二.安装单机MQ1.上传并解压2.目录介绍3.修改MQ启动时初始JVM内存4.启动NameServer与Broker5.测试RocketMQ 三.RocketMQ集群搭建1.集群概念特点2.集群模式分类3.集群工作流程4.双主双从集群搭建4.…...
uniapp 模仿 Android的Menu菜单栏
下面这张图就是我们要模拟的菜单功能 一、模拟的逻辑 1. 我们使用uni-popup组件(记得要用hbuilder X导入该组件)uni-app官网 2. 将组件内的菜单自定义样式 二、uniapp代码 写法vue3 <template><view><uni-popup ref"showMenu"…...

wordcloud Python中的词云库
Python中的词云库是一个非常流行的文本可视化工具,可以将文本中的关键词以词云形式呈现。本篇文章将详细讲解Python中的词云库的使用和API以及代码注释。 安装词云库 安装词云库的方式很简单,只需要在命令行中使用pip命令即可。具体命令如下所示&#…...
直播间讨论区需要WebSocket,简单了解下
由于 http 存在一个明显的弊端(消息只能有客户端推送到服务器端,而服务器端不能主动推送到客户端),导致如果服务器如果有连续的变化,这时只能使用轮询,而轮询效率过低,并不适合。于是 WebSocket…...

2024年天津高职升本科考试将于11月开始报名
2024年天津高职升本科考试文化课网上报名及其现场确认将于11月下旬开始 2023年11月1日,天津招考资讯官方网站发布了本月(11月)报名事项安排,将进行下列考试项目网上报名工作,2024年备考天津专升本的考生可以看到2024年…...

linux mysql 创建数据库并配置用户远程管理
要在Linux上创建MySQL数据库并配置用户以实现远程管理,您可以执行以下步骤: 1. 登录到MySQL服务器: 在您的Linux终端中,使用以下命令登录到MySQL服务器。您需要提供MySQL服务器的用户名和密码。 mysql -u root -p 输入密码后&a…...

pppoe拨号案例
R3服务端 interface LoopBack0 ip address 1.1.1.1 255.255.255.255 aaa local-user test password cipher admin local-user test service-type ppp ip pool test network 100.0.0.0 mask 255.255.255.0 interface Virtual-Template0 ppp authentication-mode chap remote …...

基于STM32C8T6的智能蓝牙小车控制设计
**单片机设计介绍,1655基于STM32C8T6的智能蓝牙小车控制设计 文章目录 一 概要二、功能设计设计思路 三、 软件设计五、 程序文档 六、 结论七、 文章目录 一 概要 基于STM32C8T6的智能蓝牙小车控制设计是基于STM32微控制器和蓝牙模块开发的一种小型智能车辆控制系统…...

P3983 赛斯石(赛后强化版),背包
题目背景 白露横江,水光接天,纵一苇之所如,凌万顷之茫然。——苏轼真程海洋近来需要进购大批赛斯石,你或许会问,什么是赛斯石? 首先我们来了解一下赛斯,赛斯是一个重量单位,我们用…...

系统架构设计师历年真题案例知识点汇总
常见的软件质量属性有多种,例如性能(Performance)、可用性(Availability)、可靠性(Reliability)、健壮性(Robustness)、安全性(Security)、可修改性(Modification)、可变性(Changeability)、易用…...
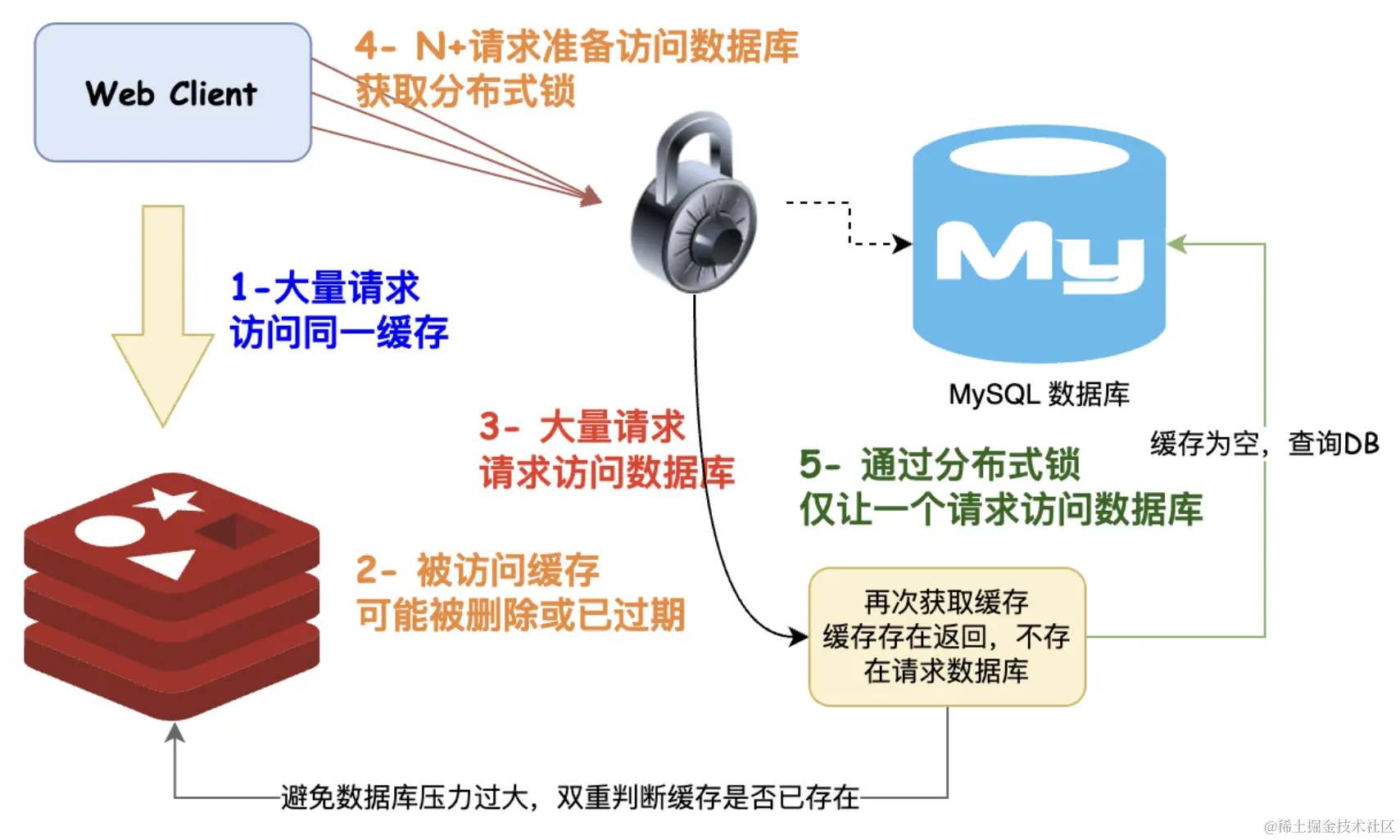
缓存击穿只会逻辑过期 OR 互斥锁?深入思考 == 鹤立鸡群
网上但凡看得见的文章,大部分在说缓存穿透时都是无脑分布式锁 / 逻辑过期,分布式锁一点问题都没有么?逻辑过期一点问题都没有么?还能不能再进一步优化? 在聊聊缓存击穿的双重判定锁之前,我们将按照循循渐进…...

从 Seq2Seq 到 Attention:彻底改变序列建模
探究Attention机制和意力的起源。 简介 在这篇博文[1]中,将讨论注意力机制的起源,然后介绍第一篇将注意力用于神经机器翻译的论文。由于上下文压缩、短期记忆限制和偏差,具有 2 个 RNN 的 Seq2Seq 模型失败了。该模型的 BLEU 分数随着序列长度…...

手机通讯类、ip查询、智能核验、生活常用API接口推荐
手机通讯类 手机号码归属地:提供三大运营商的手机号码归属地查询。 空号检测:通过手机号码查询其在网活跃度,返回包括空号、停机等状态。 手机在网状态:支持传入三大运营商的号码,查询手机号在网状态,返…...

1.6 基本安全设计准则
思维导图: 1.6 基本安全设计准则笔记 目标:理解和遵循一套广泛认可的安全设计准则,以指导保护机制的开发。 主要准则: 机制的经济性:安全机制应设计得简单、短小,便于测试和验证,减少漏洞和降…...

图扑 HT for Web 手机端运维管理系统
随着信息技术的快速发展,网络技术的应用涉及到人们生活的方方面面。其中,手机运维管理系统可提供数字化、智能化的方式,帮助企业和组织管理监控企业的 IT 环境,提高运维效率、降低维护成本、增强安全性、提升服务质量,…...
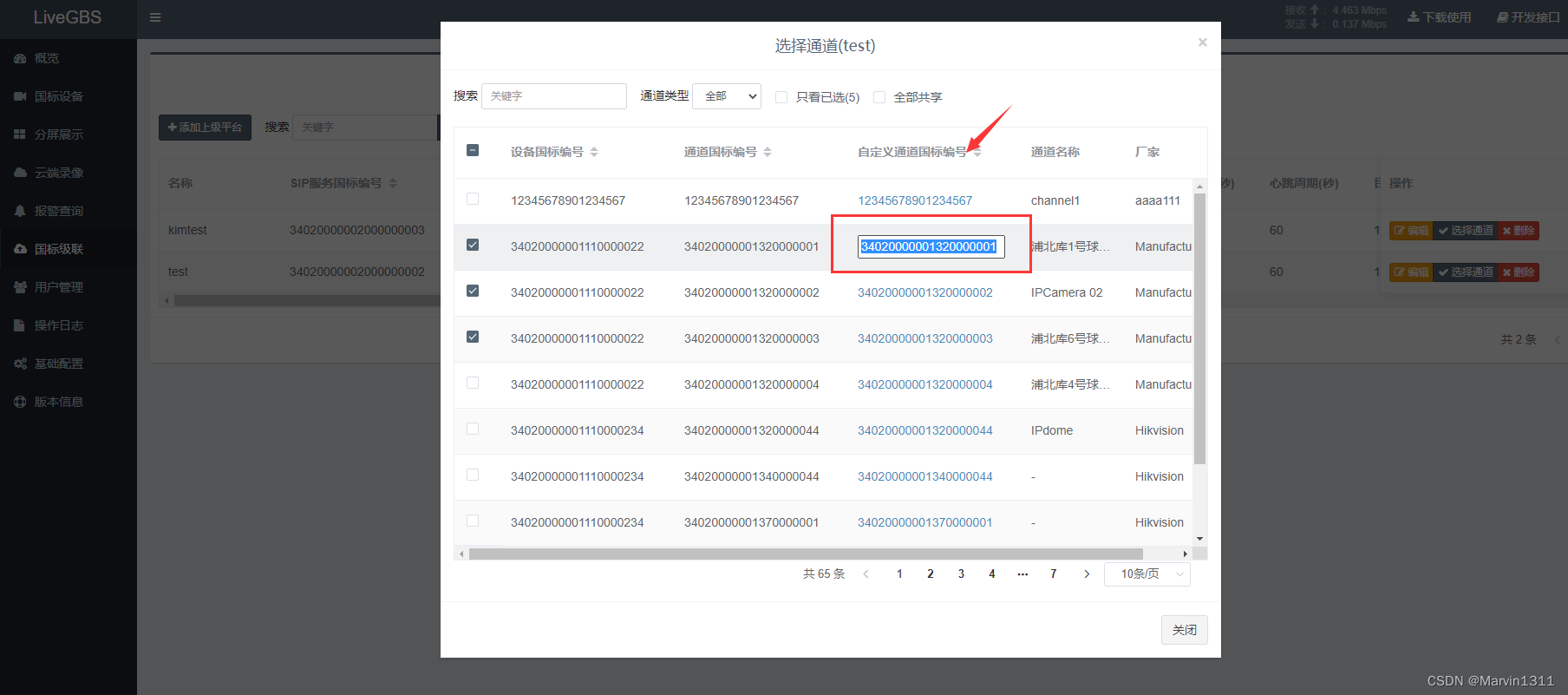
LiveGBS流媒体平台GB/T28181常见问题-国标级联海康国标级联大华国标级联华为等,配置了国标级联, 上级看不到通道该怎么办?
LiveGBS常见问题-国标级联海康国标级联大华国标级联华为等,配置了国标级联, 上级看不到通道该怎么办? 1、如何配置国标级联2、上级看不到通道排查2.1、是否共享通道2.3、通道编号是否满足上级要求 3、如何抓包分析4、搭建GB28181视频直播平台 1、如何配置国标级联 …...
数字频带传输——二进制数字调制及MATLAB仿真
文章目录 前言一、OOK1、表达式2、功率谱密度3、调制框图 二、2PSK1、表达式2、功率谱密度 三、2FSK1、表达式 四、MATLAB 仿真1、MATLAB 源码2、仿真及结果①、输入信号及频谱图②、2ASK 调制③、2PSK 调制④、2FSK 调制⑤、随机相位 2FSK 调制 五、资源自取 前言 数字频带信…...

Bitdu 150万美元投资MSG:Web3合作典范催动极致交易体验
在Web3时代,如何一键把握DEX领域的机遇,是摆在一众中心化交易所面前的难题。 近期,新锐加密资产交易所Bitdu向MsgSender(MSG)投资150万美元,引起了专业的交易者们的关注。大家普遍认为,这一事件…...

【王炸组合】Hermes Agent 官方 UI 发布:本地白嫖 Google Gemma 4,零成本打造最强微信 AI 助手
前言如果说 2025 年是 AI 大模型的爆发年,那么 2026 年 4 月就是“个人 AI 智能体”的普及元年。随着 Gemma 4(Google 4月2日刚刚发布,31B 性能直逼 GPT-4o)的开源,以及 Hermes Agent 终于告别了繁琐的命令行、发布了正…...

Percy HTML宏完全教程:在Rust中编写声明式UI组件
Percy HTML宏完全教程:在Rust中编写声明式UI组件 【免费下载链接】percy Build frontend browser apps with Rust WebAssembly. Supports server side rendering. 项目地址: https://gitcode.com/gh_mirrors/pe/percy Percy是一个基于Rust和WebAssembly的前…...

终极jsqrcode实战教程:构建企业级QR码扫描应用的完整方案
终极jsqrcode实战教程:构建企业级QR码扫描应用的完整方案 【免费下载链接】jsqrcode Javascript QRCode scanner 项目地址: https://gitcode.com/gh_mirrors/js/jsqrcode GitHub 加速计划 / js / jsqrcode 是一款功能强大的Javascript QRCode scanner&#x…...

Autosar Nm-被动唤醒时一帧网管报文是如何发出的?
文章目录 前言 Autosar CanNm状态机 软件实现流程 总结 前言 之前发现在被动唤醒时,ECU也会发送一帧网络管理报文,且不是第一帧发送的报文,但是不知道这帧网络管理报文是如何被发送的,本文基于这一疑问来进行分析,加深对网络管理的理解 Autosar CanNm状态机 ECU被动唤醒时…...

【AGI军事伦理红区预警】:20年国防科技专家首次公开3大不可逾越的AI作战红线
第一章:AGI与军事应用的伦理边界 2026奇点智能技术大会(https://ml-summit.org) 通用人工智能(AGI)在军事系统中的深度集成正以前所未有的速度推进,从自主侦察分析到动态战术推演,其能力已超越传统自动化范畴。然而&…...

python tfsec
## 关于 Python 中的 tfsec:一个安全工程师的视角 如果你在 Python 项目中处理过 Terraform 代码,或者你的团队同时维护着基础设施即代码和应用程序代码,那么你很可能遇到过这样一个问题:如何确保那些定义云资源的 .tf 文件是安全…...
:数组和方法 - 代码的复用)
10年老兵带你学Java(第3课):数组和方法 - 代码的复用
本课目标 数组:一组数据的容器方法:代码的复用面向对象入门:类和方法的关系 上节课学了变量,一个变量存一个数据。 这节课学数组,一个变量存一组数据。还有方法,把代码打包成可复用的块。一、数组ÿ…...

golang如何实现错误预算Error Budget计算_golang错误预算Error Budget计算实现实战
错误预算是SLO允许的失败请求占比上限,需绑定固定时间窗口、用累计值而非rate计算、避免float64实时减法,推荐Prometheus聚合异步校准。什么是错误预算,Go 里为什么不能直接用 float64 算错误预算是 SLO(Service Level Objective&…...
)
别再折腾环境了!手把手教你用TexLive 2024和TeXstudio搞定LaTeX中文排版(附配置避坑点)
零失败LaTeX中文环境配置指南:TexLive 2024与TeXstudio终极方案 第一次打开TeXstudio时,看到满屏的红色报错提示和乱码中文,我的硕士论文开题报告差点因此延期——这可能是许多LaTeX初学者的共同记忆。不同于Word的"安装即用"&…...
)
保姆级教程:用Unity把原神角色变成你的专属桌宠(附完整C#脚本)
Unity实战:打造高互动性原神风格桌宠全流程指南 从零开始构建你的虚拟伙伴 在数字生活日益丰富的今天,个性化桌面伴侣已成为许多用户表达自我风格的方式。想象一下,当你工作疲惫时,桌面上可爱的游戏角色会对你眨眼;当你…...