【NLP】什么是语义搜索以及如何实现 [Python、BERT、Elasticsearch]
语义搜索是一种先进的信息检索技术,旨在通过理解搜索查询和搜索内容的上下文和含义来提高搜索结果的准确性和相关性。与依赖于匹配特定单词或短语的传统基于关键字的搜索不同,语义搜索会考虑查询的意图、上下文和语义。
语义搜索在搜索结果的精度和相关性至关重要的应用中非常宝贵,例如从大型数据库中检索信息、电子商务产品搜索、企业搜索以及改善搜索引擎和虚拟助手中的用户体验。
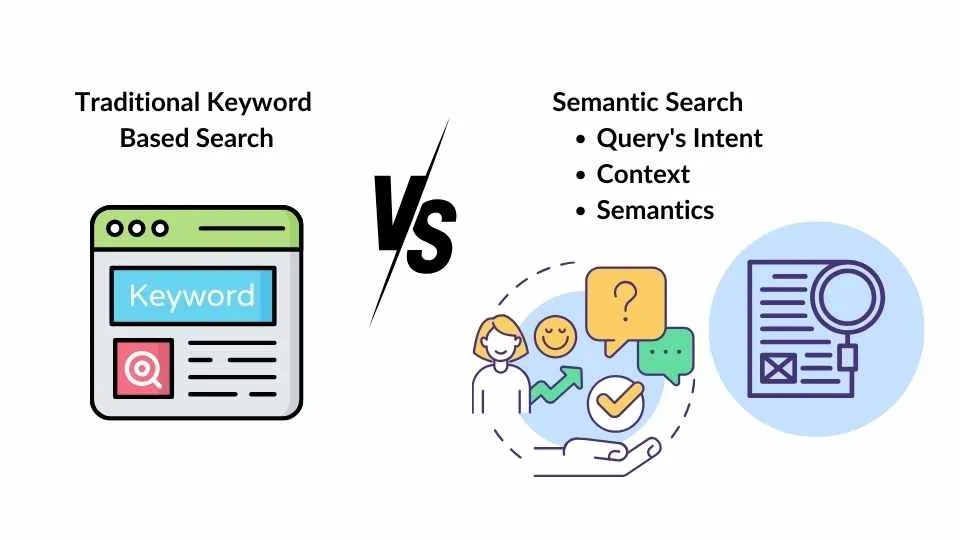
传统的基于关键字的搜索依赖于匹配特定的单词或短语,而语义搜索则考虑查询的意图、上下文和语义。
NLP 中的语义搜索如何工作?
自然语言处理(NLP)上下文中的语义搜索是指应用NLP技术通过理解搜索查询和正在搜索的内容的含义和上下文来增强搜索结果的准确性和相关性。以下是语义搜索与 NLP 的关系:
- 自然语言理解: NLP 分析和理解搜索查询中使用的自然语言以及搜索数据库中的内容。NLP 技术,例如词性标注、命名实体识别和句法分析,有助于从文本中提取含义。
- 查询扩展: NLP 中的语义搜索通常涉及查询扩展,系统识别同义词、相关概念和上下文相关术语,以扩大搜索查询的范围。这确保了搜索结果不限于精确的关键字匹配,而是包括概念上相关的内容。
- 实体识别:基于 NLP 的语义搜索系统可以识别文本中的实体(例如人、地点、组织),并使用此信息来提高搜索准确性。例如,认识到“苹果”指的是科技公司,而不是水果。
- 概念匹配: NLP 支持的语义搜索超越了精确的关键字匹配,还考虑了单词和短语之间的基本概念和关系。它可以识别概念上与查询相关的内容,即使术语不存在。
- 情感分析:在某些情况下,使用 NLP 技术的情感分析可以合并到语义搜索中,以确定内容的情感或情绪基调,这对于特定的搜索应用程序非常重要。
- 上下文理解: NLP 有助于理解单词和短语的使用上下文,从而使搜索系统能够提供上下文相关的结果。
- 多语言搜索: NLP通过理解语言的细微差别和特定于语言的上下文,使语义搜索能够在多种语言中工作。
- 机器学习:机器学习模型可用于基于 NLP 的语义搜索系统,根据用户交互和反馈不断提高搜索结果的相关性。
总体而言,NLP 语义搜索提供了更复杂和上下文感知的搜索功能,使其在各种应用中都很有价值,包括网络搜索引擎、企业搜索、电子商务、聊天机器人和虚拟助理,在这些应用中,理解和满足用户的意图至关重要。
语义搜索的例子是什么?
以下是语义搜索的示例,用于说明其工作原理:
场景:假设您正在使用语义搜索引擎为您的研究项目查找有关“替代能源”的信息。在传统的基于关键字的搜索中,您可以简单地输入查询“替代能源”,然后根据这些关键字的精确匹配获得结果列表。然而,通过语义搜索,结果更加上下文相关并且概念驱动。
语义搜索查询: 您输入查询“住宅用最环保的替代能源是什么?”
语义搜索过程:
- 自然语言理解:语义搜索系统使用 NLP 来分析您的查询。它了解您正在寻找适合住宅使用的环保替代能源。
- 查询扩展:系统通过考虑同义词和相关术语来扩展您的查询。它可能包括“绿色能源”、“可再生能源”和“家庭能源解决方案”等概念。
- 上下文理解:系统识别您查询的上下文,即住宅用途和环境友好性。它知道您对工业规模的能源解决方案不感兴趣,而是对适合家庭的能源解决方案感兴趣。
- 概念匹配:语义搜索系统匹配概念和相关术语,而不是精确的关键字匹配。它搜索讨论环保且适用于住宅应用的可再生能源的内容。
什么是语义引擎?
语义引擎是一种软件系统或组件,旨在理解、分析和处理人类语言的含义和上下文。它通常用于自然语言理解(NLU)、自然语言处理(NLP)和语义搜索。语义引擎使用各种技巧和技术来提取和处理文本和语音的语义,使它们能够执行广泛的任务,包括:
- 自然语言理解 (NLU):语义引擎可以理解文本或语音的含义,使它们能够提取实体、识别意图并理解上下文。它们通常用于聊天机器人、虚拟助理和客户支持系统中,以与人类类似的方式与用户进行交互。
- 语义搜索:语义引擎可以执行简单关键字匹配之外的高级搜索操作。他们了解搜索查询背后的上下文和意图,使搜索结果更加相关和准确。
- 信息检索:语义引擎用于从大型数据库或文档集合中检索信息的系统。他们可以识别相关文档并提取有意义的内容。
- 情绪分析:这些引擎可以确定文本的情绪或情绪基调,例如识别客户评论是正面还是负面。
- 文档摘要:语义引擎可以通过识别基本信息和重要细节来简洁地总结冗长的文档。
- 机器翻译:机器翻译系统使用语义分析来理解一种语言的句子含义,并生成另一种语言的语义准确的翻译。
- 命名实体识别 (NER):它们可以对文本中的人名、地名、组织等实体进行识别和分类。
- 主题建模:语义引擎可以根据语义内容将文档或文本分组为主题或集群,有助于内容分类和组织。
- 问答:它们用于问答系统,可以理解自然语言的问题,并通过从文档或知识库中提取信息来提供准确的答复。
- 推荐系统:语义分析可以帮助根据用户的偏好和过去的行为向他们推荐产品、内容或服务。
为了构建语义引擎,开发人员通常使用自然语言处理 (NLP) 和机器学习技术,其中可能涉及大型数据集和预训练语言模型(如 BERT、GPT-3 或特定领域模型)的训练模型。这些引擎可以进行定制和微调,以增强特定应用程序、领域或语言的性能。
语义引擎对于改善人机交互、搜索和信息处理至关重要,使其成为许多现代应用程序和服务不可或缺的一部分。
如何用Python实现语义搜索
您可以结合使用自然语言处理 (NLP) 库和技术在 Python 中实现语义搜索。
旁注:在现实场景中,您通常会使用更广泛的数据集和可能的预训练模型以获得更好的结果。这个例子作为一个基本的介绍。
1.安装所需的库:
您将需要spaCy和 scikit-learn等 Python 库来执行语义搜索。您可以使用 pip 安装它们:
pip install spacy
pip install scikit-learn2. 预处理您的数据:
对于语义搜索,您应该拥有要搜索的文档或文本的集合。在此示例中,我们假设您有一个文档列表。
documents = [
"太阳能电池板是一种可再生能源,对环境有益。",
"风力涡轮机利用风能发电。",
"地热供暖利用来自地球的热量为建筑物供暖。",
"水电是一种可持续能源,依靠水流发电。",
# 根据需要添加更多文档
]3. 标记化和向量化:
您需要对文本进行标记并将其转换为数值向量。在此示例中,我们将使用 spaCy 进行标记化,并使用 scikit-learn 的 TF-IDF 向量化。
import spacy
from sklearn.feature_extraction.text import TfidfVectorizernlp = spacy.load("zh_core_web_sm")# Tokenize and vectorize the documents
tfidf_vectorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vectorizer.fit_transform(documents)4、用户查询处理:
现在,使用 spaCy 处理用户的查询,对其进行标记化和矢量化。
user_query = "风能对环境有什么好处?"query_vector = tfidf_vectorizer.transform([user_query])5. 语义搜索:
使用余弦相似度等相似度度量来计算用户查询和文档之间的相似度。余弦相似度越高,文档与用户的查询越相似。
from sklearn.metrics.pairwise import cosine_similarity# 计算用户查询与所有文档之间的余弦相似度
cosine_similarities = cosine_similarity(query_vector, tfidf_matrix)# 获取最相似文档的索引
most_similar_document_index = cosine_similarities.argmax()6. 检索结果:
一旦获得最相似的文档索引,您就可以从集合中检索相关文档。
most_similar_document = documents[most_similar_document_index]
print("最相似的文档:", most_similar_document)这是使用 spaCy 和 scikit-learn 在 Python 中实现语义搜索的基本示例。我们的下一个示例将使用更先进的预训练模型 BERT 来提高语义理解和搜索准确性。
如何用BERT实现语义搜索
使用 BERT(来自 Transformers 的双向编码器表示)实现语义搜索涉及使用预训练的 BERT 模型为文档和用户查询生成嵌入,然后计算它们的相似度。以下是有关如何在 Python 中使用 BERT 执行语义搜索的分步指南:
1.安装所需的库:
您将需要 Hugging Face 的 Transformers 库才能使用 BERT 模型。您可以使用 pip 安装它:
pip install transformers 2. 预处理您的数据:
您应该像以前一样拥有一系列文档。确保您已下载并可以使用您选择的 Hugging Face BERT 模型。您可以从各种预训练的 BERT 模型中进行选择,例如“bert-base-uncased”或“bert-large-uncased”。
3. 对文档进行标记和编码:
使用 BERT 分词器和模型对文档进行分词和编码。
from transformers import BertTokenizer, BertModel
import torchtokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
model = BertModel.from_pretrained("bert-base-chinese")# Tokenize and encode the documents
document_embeddings = []
for document in documents:inputs = tokenizer(document, return_tensors="pt", padding=True, truncation=True)outputs = model(**inputs)document_embedding = outputs.last_hidden_state.mean(dim=1) # Average over tokensdocument_embeddings.append(document_embedding)
document_embeddings = torch.cat(document_embeddings)4. 对用户查询进行标记和编码:
以与文档相同的方式对用户查询进行标记和编码。
user_query = "风能对环境有什么好处?"
user_query_inputs = tokenizer(user_query, return_tensors="pt", padding=True, truncation=True)
user_query_outputs = model(**user_query_inputs)
user_query_embedding = user_query_outputs.last_hidden_state.mean(dim=1)5. 语义搜索:
计算用户查询和文档嵌入之间的相似度。一种常见的相似性度量是余弦相似性。
from sklearn.metrics.pairwise import cosine_similarity# 计算用户查询与所有文档之间的余弦相似度
similarities = cosine_similarity(user_query_embedding, document_embeddings)# 查找最相似文档的索引
most_similar_document_index = similarities.argmax()6. 检索结果:
从您的集合中检索最相似的文档。
most_similar_document = documents[most_similar_document_index]
print("最相似的文档:", most_similar_document)此示例演示如何使用 BERT 模型执行语义搜索来生成文档和用户查询的嵌入,然后计算相似度以查找最相关的文档。与传统方法相比,BERT 的上下文理解可以显着提高搜索结果的质量。
如何使用 Elasticsearch 实现语义搜索
Elasticsearch 是一种流行的开源搜索和分析引擎,可利用其文本分析功能和各种功能来实现语义搜索。Elasticsearch 为构建复杂的搜索应用程序提供了基础,这些应用程序可以理解并提供上下文相关的搜索结果。以下是如何使用 Elasticsearch 实现它的高级概述:
1.安装并设置Elasticsearch:
首先,您需要安装 Elasticsearch 并设置 Elasticsearch 集群。您可以从官方网站下载 Elasticsearch,并按照特定操作系统的安装和配置说明进行操作。
2. 为您的数据建立索引:
Elasticsearch 通过索引和搜索文档来工作。您需要对要执行语义搜索的文档建立索引。为此,您将定义 Elasticsearch 索引并使用 Elasticsearch 的 REST API 或客户端库将文档添加到索引中。
例如,如果您有一系列文章,则每篇文章都可以是 Elasticsearch 索引中的一个文档。您需要指定在索引过程中如何分析和标记文档的内容。要启用语义搜索,您可能需要使用自定义分析器或考虑同义词和其他特定于语言的细微差别的特定于语言的分析器。
3.使用全文搜索:
Elasticsearch 提供了强大的全文搜索功能,允许您对索引数据执行基于关键字的搜索。您可以使用 match 查询或 multi_match 查询来搜索文档中的特定关键字。
{"query": {"match": {"content": "renewable energy sources"}}
}4. 实现语义搜索:
要实现语义搜索,您可以通过合并语义搜索组件(例如词嵌入、同义词或本体)来扩展 Elasticsearch 的功能。以下是使用 Elasticsearch 实现此目的的几种方法:
- 同义词:您可以创建同义词列表并使用 Elasticsearch 的同义词标记过滤器来扩展查询术语以包含同义词。这使得 Elasticsearch 能够查找包含相似但不相同术语的文档。
- 词嵌入:您可以使用预先训练的词嵌入模型(例如,Word2Vec 或 FastText)来表示向量空间中的词。这些嵌入可用于查找具有相似语义内容的文档。Elasticsearch 不提供对嵌入的本机支持,但您可以使用自定义脚本或外部库基于嵌入执行相似性搜索。
- 自定义分析器:您可以在 Elasticsearch 中创建考虑语义信息(例如同义词和词干)的自定义分析器。这可以通过了解查询的上下文来帮助改善搜索结果。
- 图数据库集成:您可以将 Elasticsearch 与 Neo4j 等图数据库集成,以实现更复杂的语义搜索应用程序。图数据库可以存储概念和实体之间的关系,而Elasticsearch可以处理文本搜索和检索。
- 查询扩展:您可以通过识别相关术语或概念并相应地修改 Elasticsearch 查询来扩展用户的查询,以检索更多上下文相关的结果。
- 评估和调整:持续评估结果的质量并微调 Elasticsearch 配置、分析器和搜索查询,以提高结果的相关性。
使用 Elasticsearch 实现语义搜索可能是一个复杂且持续的过程。尽管如此,它仍然提供了强大的功能,可以通过理解查询和文档的含义和上下文来提高搜索结果的相关性。
结论
语义搜索和语义引擎代表了理解和处理自然语言的先进方法,使得从文本和语音中提取含义和上下文成为可能。这些技术有着广泛的应用。它们有助于提高搜索结果的质量和相关性,并实现人与机器之间更自然、更智能的交互。
语义搜索超越了传统的基于关键字的搜索,它考虑了查询背后的意图、上下文和含义。它利用自然语言处理 (NLP) 和查询扩展、同义词识别和概念匹配等技术来提供更准确和上下文相关的搜索结果。
由 NLP 和机器学习提供支持的语义引擎是语义搜索的核心,支持各种应用,包括自然语言理解、情感分析、信息检索和推荐系统。这些引擎可以针对特定领域、语言和用例进行定制,使其成为增强用户体验和自动化信息处理任务的多功能工具。
随着技术的进步,语义搜索和语义引擎可能会在各个行业中发挥越来越重要的作用,从电子商务和客户支持到医疗保健和内容推荐。它们理解人类语言和上下文细微差别的能力使得人与机器之间的交互更加直观和高效。
相关文章:
【NLP】什么是语义搜索以及如何实现 [Python、BERT、Elasticsearch]
语义搜索是一种先进的信息检索技术,旨在通过理解搜索查询和搜索内容的上下文和含义来提高搜索结果的准确性和相关性。与依赖于匹配特定单词或短语的传统基于关键字的搜索不同,语义搜索会考虑查询的意图、上下文和语义。 语义搜索在搜索结果的精度和相关…...

【JavaScript】JS基础语法
1 JavaScript 的书写形式 1.1 行内式 直接嵌入到 html 元素内部 <input type"button" value"按钮" onclick"alert(hello JavaScript)" >1.2 内嵌式 写在script标签内 <script>alert("haha")</script>1.3 外部式…...

06-云计算概览及问题关注
容器生态系统 容器生态系统包含核心技术、平台技术和支持技术。 1-1 容器核心技术 其中容器核心技术指的是能让容器在主机服务器上运行的技术,包含容器规范、容器 runtime、容器管理工具、容器生态工具、registries、容器 OS。 容器规范: 容器除了常…...
怎么监控钉钉聊天记录内容(监控钉钉聊天记录的3种形式)
企业沟通工具的普及,越来越多的企业开始使用钉钉作为内部沟通工具。然而,对于企业管理者来说,如何监控钉钉聊天记录内容成为了一个重要的问题。本文将介绍几种方法,帮助企业管理者实现监控钉钉聊天记录内容的目的。 一、钉钉自带功…...

深入理解强化学习——强化学习的历史:时序差分学习
分类目录:《深入理解强化学习》总目录 相关文章: 强化学习的历史:最优控制 强化学习的历史:试错学习 强化学习的历史:试错学习的发展 强化学习的历史:K臂赌博机、统计学习理论和自适应系统 强化学习的…...

OpenCloudOS9操作系统搭建Confluence8.0.4企业WIKI
OpenCloudOS9操作系统搭建Confluence8.0.4企业WIKI 1. 概要2. 系统基础环境配置3. 安装并配置MySQL3.1. 安装MySQL3.2. MySQL基本配置3.3. 创建Confluence数据库4. 安装并配置Confluence5. 破解Confluence6. 优化配置Confluence7. confluence对接Windows AD域环境1. 概要 Atlas…...

03-Vue中的常用指令的使用,事件及其修饰符
常用指令 指令语法和插值语法 Vue框架中的所有指令的名字都以v-开始,完整语法格式<HTML标签 v-指令名:参数"javascript表达式(表达式的结果是一个值)"></HTML标签>: 指令的职责是当表达式的值改变时,将其产生的连带影响,响应式地作用于DOM元素不是所有…...

ScrapeKit库中Swift爬虫程序写一段代码
以下是一个使用ScrapeKit库的Swift爬虫程序,用于爬取网页视频的代码: import ScrapeKit// 创建一个配置对象,用于指定爬虫ip服务器信息 let config Configuration(proxyHost: "duoip", proxyPort: 8000)// 创建一个爬虫对象 let s…...
总感觉戴助听器耳朵又闷又堵怎么办?
随着助听器技术的进步发展,这些问题都有了一定程度的改善。例如,现在的助听器变得越来越小巧,外形更加美观和隐蔽;各种降噪技术和验配技巧也提升了助听器的音质和清晰度。 但是,还有一个问题困扰着很多助听器用户&…...
编程助手DevChat:让开发更轻松
#AI编程助手哪家好?DevChat“真”好用 # 目录 前言一、安装Vscode1、下载链接2、安装 二、注册DevChat1、打开注册页2、验证成功完成邮箱绑定3、绑定微信可获得8元 三、安装插件四、配置Access Key1、获取Access Key2、设置Access Key①、点击左下角管理(…...

稳定扩散的高分辨率图像合成
推荐稳定扩散AI自动纹理工具:DreamTexture.js自动纹理化开发包 1、稳定扩散介绍 通过将图像形成过程分解为去噪自动编码器的顺序应用,扩散模型 (DM) 在图像数据及其他数据上实现了最先进的合成结果。此外,它们的配方…...
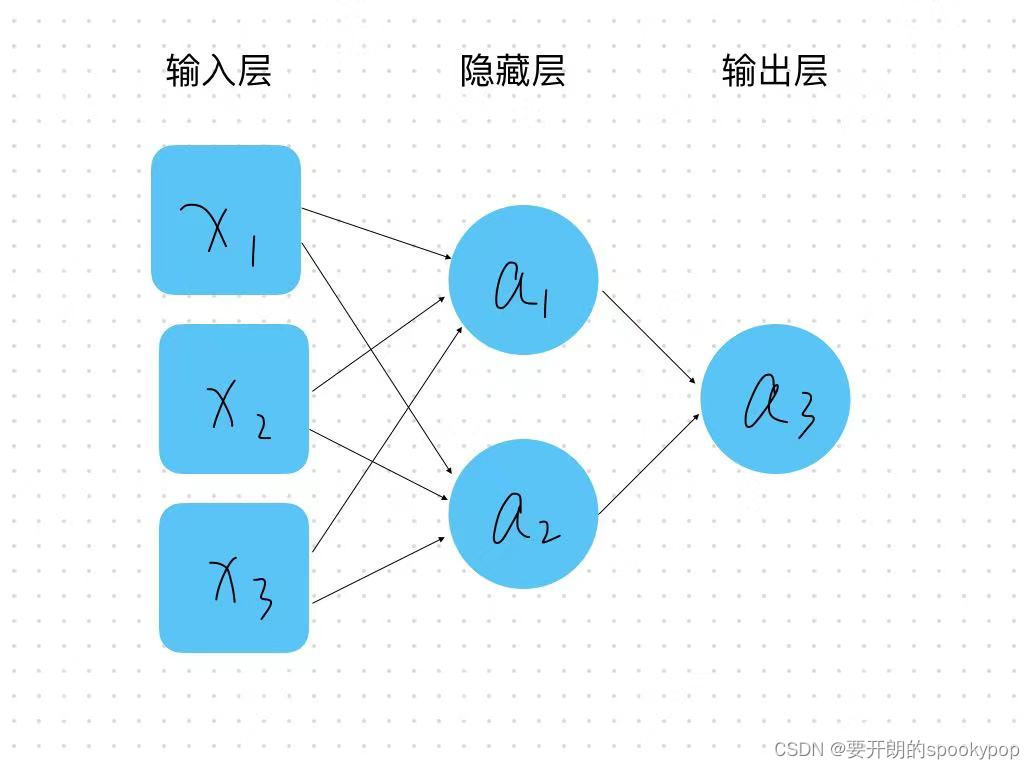
3 Tensorflow构建模型详解
上一篇:2 用TensorFlow构建一个简单的神经网络-CSDN博客 本篇目标是介绍如何构建一个简单的线性回归模型,要点如下: 了解神经网络原理构建模型的一般步骤模型重要参数介绍 1、神经网络概念 接上一篇,用tensorflow写了一个猜测西…...
智慧农场牧场小程序源码 智慧农业认养系统源码
智慧农场牧场小程序源码 智慧农业认养系统源码 要了解源码的,看文末。 随着科技的进步和人们对绿色食品的需求增加,智慧农场正成为未来农业发展的方向。智慧农场是指运用先进的技术手段,如物联网、云计算、智能控制技术、大数据分析等&…...

3D数据过滤为2D数据集并渲染
开发环境: Windows 11 家庭中文版Microsoft Visual Studio Community 2019VTK-9.3.0.rc0vtk-example参考代码 代码逻辑:初始化数据集points -> 添加数据集到polydata -> 通过vtkVertexGlyphFilter过滤(带顶点、单元数据)po…...
)
第十一章 ObjectScript 系统宏(二)
文章目录 第十一章 ObjectScript 系统宏(二) 宏引用FormatText(text, arg1, arg2, ...)FormatTextHTML(text, arg1, arg2, ...)FormatTextJS(text, arg1, arg2, ...)GETERRORCODE(sc)GETERRORMESSAGE(sc,num)ISERR(sc)ISOK(sc)Text(text, domain, langua…...

跨境电商大作战:2023黑色星期五准备指南
黑色星期五,作为全球购物狂欢的象征,已经成为了电商业务的一年一度的重要节点。尤其对于跨境电商来说,这一天意味着巨大的商机和挑战。为了在这个竞争激烈的时刻脱颖而出,跨境电商必须做好充分的准备。Nox聚星在这里给大家分享几个…...
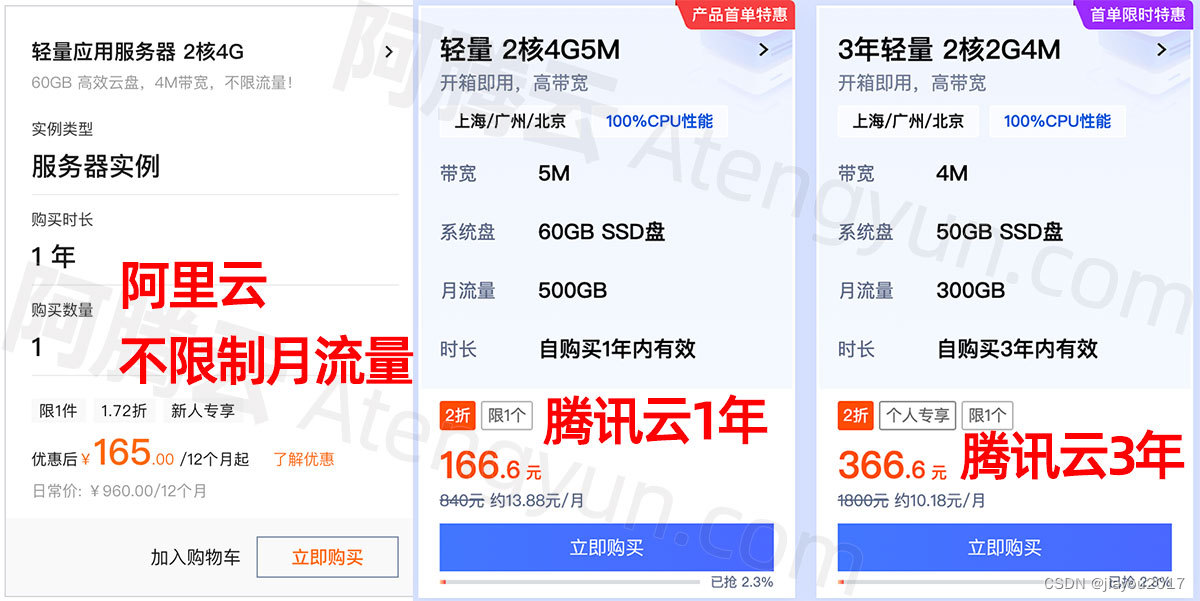
我的天!阿里云服务器居然比腾讯云优惠1元!
2023阿里云服务器优惠活动来了,以前一直是腾讯云比阿里云优惠,阿里云绝地反击,放开老用户购买资格,99元服务器老用户可以买,并且享受99元续费,阿腾云亲测可行,大家抓紧吧,数量不多&a…...

鸡尾酒学习——未命名(芒果口味)
1、材料:冰块、伏特加、芒果汁、元气森林卡曼橘味; 2、口感:芒果味道,酸甜为主,苦为辅。 3、视觉效果:黄色液体; 4、步骤: (1)向杯子中加入适量冰块ÿ…...

modbusTCP【C#】
为了编写一个完整的Modbus TCP库,您需要遵循以下步骤: 1. 安装NModbus4库:NModbus4是一个用于C#的Modbus库,它支持串口和TCP通信。您可以通过NuGet包管理器安装它。 2. 创建Modbus主机:使用ModbusIpMaster.CreateIp方…...

解决Linux Debian12系统中安装VirtualBox虚拟机无法使用USB设备的问题
Debian12系统中安装VirtualBox,再VirtualBox虚拟机中无法使用 USB设备。如下图所示: 解决方法如下: 1.安装 Virtualbox增强功能。如下图所示: 2.添加相关用户、用户组( Virtualbox 装完成后会有 vboxusers 和 vboxs…...
)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)在当今微服务架构盛行的时代,Go语言因其高性能和并发优势成为后端开发的热门选择。而Goframe作为一款企业级的Go应用开发框架,提供了从数据库操作到API…...

用数字逻辑门复刻柏林钟:从二进制编码到硬件实现
1. 项目概述:用数字电路复刻“柏林钟”作为一个在柏林长大的孩子,我从小就对库达姆大街上的那座“柏林钟”着迷。它不像传统时钟那样用指针或数字告诉你时间,而是通过几排不同颜色的发光方块,以一种近乎艺术的方式呈现时间。这种独…...

Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题
Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题当你第一次用Godot4完成一个2D场景搭建时,那种成就感往往会被几个突如其来的bug瞬间击碎——角色神秘消失、背景纹丝不动、屏幕边缘出现诡异黑边。这些问题看似简单,…...

HarmonyOS 6学习:解决图片放大后无法移动至边缘的matrix4矩阵变换技巧
从"卡在中间"到"自由拖拽":一次完整的图片缩放平移边界问题攻关在HarmonyOS 6应用开发中,我最近遇到了一个看似简单却让人头疼的图片查看器问题:用户双指放大图片后,想要拖动查看边缘细节,却发现图…...

艾尔登法环存档迁移终极指南:3分钟解决角色转移难题
艾尔登法环存档迁移终极指南:3分钟解决角色转移难题 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档版本不兼容而烦恼吗?EldenRingSaveCopier 是你的终极解决…...

用图神经网络做缺陷定位,准确率比传统方法高出30%
在现代软件工程的复杂迷宫中,缺陷定位始终是测试团队面临的核心挑战。想象这样一个场景:一个电商系统在特定压力条件下偶发订单丢失,日志中只留下泛泛的超时错误,问题可能深藏在上百个微服务的调用链、分布式事务的竞态条件或某个…...

告别多头对接!DMXAPI 为企业打造国产大模型 “统一入口”
一、企业 AI 落地的普遍痛点:被接口和平台消耗的成本在企业数字化转型的浪潮中,AI 大模型已经成为标配,但很多企业在落地时,都会陷入一个共同的困境:为了满足不同业务场景的需求,需要同时对接 DeepSeek、阿…...

2026数据治理平台选型:五款产品如何赋能数据中台建设?
一、引言:数据中台的成败,关键在治理在数字化浪潮的席卷下,“数据中台”已成为当代企业信息化架构中的核心战略组件。然而,一个悖论正困扰着大量企业:数据中台的基础设施搭建日趋完善,但真正将数据转化为业…...

基于晶体管逻辑的水箱自动控制器设计与实现
1. 项目概述:一个基于晶体管逻辑的自动水箱/湿度灌溉控制器 如果你也像我一样,曾经为家里的花园、阳台植物或者农村老家的储水塔手动开关水泵而烦恼,那么这个项目就是为你准备的。我设计并制作了一个完全自动化的水箱水位控制器,它…...

3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验
3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hive…...