【机器学习可解释性】5.SHAP值的高级使用
机器学习可解释性
- 1.模型洞察的价值
- 2.特征重要性排列
- 3.部分依赖图
- 4.SHAP 值
- 5.SHAP值的高级使用
正文
汇总SHAP值以获得更详细的模型解释
总体回顾
我们从学习排列重要性和部分依赖图开始,以显示学习后的模型的内容。
然后我们学习了SHAP值来分解单个预测的组成部分。
现在我们将对SHAP值展开讨论,看看聚合许多SHAP值如何为排列重要性图和部分依赖图提供更详细的替代方案。
SHAP值 回顾
Shap 值显示了给定特征对我们预测的改变程度(与我们在该特征的某个基线值上进行预测相比)。
例如,考虑一个超简单的模型:
y = 4 ∗ x 1 + 2 ∗ x 2 y = 4* x1 + 2∗x2 y=4∗x1+2∗x2
如果 x 1 x1 x1 取值2,而不是基线值0,这样 x 1 x1 x1的SHAP值
应该是8(4乘以2)
我们在实践中使用的复杂模型很难计算这些。但通过一些聪明的算法,shap值允许我们将任何预测分解为每个特征值的效果总和,生成如下图:

除了每个预测的细分之外,Shap库还提供了Shap值组的可视化功能。我们将重点关注其中的两种可视化。这些可视化在概念上与排列重要性图和部分依赖图相似。因此,前面练习中的多个线索将在这里结合在一起。
总结图
排列重要性非常重要,因为它创建了简单的数字度量来查看哪些特征对模型重要。这有助于我们轻松地比较特性,并且您可以向非技术人员展示结果图。
但它并没有告诉你每个特性的重要性。如果一个特征具有中等排列重要性,那可能意味着它具有中等排列重要性
- 对一些预测有很大影响,但总体上没有影响,或者
- 所有预测的中等效应
SHAP总结图可以让我们鸟瞰特征的重要性和驱动因素。我们将浏览一个足球数据的示例图:

这张图由许多点组成。每个点有三个特点:
- 垂直位置显示它所描绘的特征
- 颜色显示该特征在数据集的那一行中是高还是低
- 水平位置显示该值的影响是否导致较高或较低的预测
例如,左上角的点代表进球很少的球队,将预测值降低0.25。
有些东西你应该能够很容易地挑选出来:
- 该模型忽略了
Red和Yellow & Red特征。 - 通常
Yellow Card(黄牌)不会影响预测,但有一种极端情况,高数值会导致低得多的预测。 Goal Scored越高,预测越高,得分越低,预测越低
如果你观察的时间够长,你会发现这张图里有很多信息。在练习中,你会遇到一些问题来测试你的理解能力。
总结图代码
您已经看到了加载足球数据的代码:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifierdata = pd.read_csv('../input/fifa-2018-match-statistics/FIFA 2018 Statistics.csv')
y = (data['Man of the Match'] == "Yes") # Convert from string "Yes"/"No" to binary
feature_names = [i for i in data.columns if data[i].dtype in [np.int64, np.int64]]
X = data[feature_names]
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state=1)
my_model = RandomForestClassifier(random_state=0).fit(train_X, train_y)我们使用以下代码获取所有验证数据的SHAP值。它足够短,我们在评论中解释它。
import shap # package used to calculate Shap values# 创建计算 shap values 对象
explainer = shap.TreeExplainer(my_model)# 计算 shap values 为画图作准备
# 计算所有val_X的shap values 而不是一行,这样有更多的数据用于作图shap_values = explainer.shap_values(val_X)# 以索引1 的值来作图
shap.summary_plot(shap_values[1], val_X)
这里的代码并不太复杂。但也有一些需要注意的地方。
- 绘制时,我们调用shap_values[1]。对于分类问题,每个可能的结果都有一个单独的SHAP值数组。在本例中,我们索引以获得预测
True的SHAP值。 - 计算SHAP值可能很慢。这在这里不是问题,因为这个数据集很小。但是,在使用合理大小的数据集进行绘图时,您需要小心。例外是在使用xgboost模型时,SHAP对其进行了一些优化,因此速度要快得多。
这提供了对模型的一个很好的概述,但我们可能想要深入研究单个特性。这就是SHAP依赖性贡献图发挥作用的地方。
SHAP依赖性贡献图
我们以前使用部分依赖图来显示单个特征如何影响预测。这些都是深刻的,并且与许多真实的用例相关。另外,只要稍加努力,它们就可以向非技术人员解释清楚。
但还有很多东西他们没有展示出来。例如,效果的分布是怎样的?某一特定值的影响是相当恒定的,还是取决于其他特征的值而变化很大?SHAP依赖性贡献图提供了与PDP相似的解释,但它们添加了更多细节。

先从形状开始,我们一会儿再回来讲颜色。每个点代表一行数据。水平位置是数据集的实际值,垂直位置显示该值对预测的影响。这个曲线向上倾斜的事实表明,你控球越多,模型对赢得本场最佳球员的预测就越高。
这一差异表明,其他特征必须与控球率相互作用。例如,这里我们突出了两个具有相似控球值的点。这个值导致一个预测增加,另一个预测减少。

相比之下,简单的线性回归会产生完美的曲线,然而这个没有。
这表明我们要深入研究相互作用,图中包含了颜色编码来帮助我们做到这一点。虽然主要趋势是向上的,但您可以直观地检查是否因网点颜色而变化。
考虑下面这个非常狭窄的具体例子。

这两点在空间上与上升趋势相去甚远。它们都是紫色的,表示该队进了一球。你可以这样理解:一般来说,拥有球权会增加球队球员赢得奖项的机会。但如果他们只进了一个球,这种趋势就会逆转,如果他们进的球那么少,裁判可能会因为他们控球太多而惩罚他们。
除了这几个异常值之外,颜色表示的相互作用在这里并不是很引人注目。但有时它会突然出现在你面前。
依赖性贡献图的代码
我们用下面的代码得到依赖性贡献图。与summary_plot唯一不同的行是最后一行。
import shap # package used to calculate Shap values# Create object that can calculate shap values
explainer = shap.TreeExplainer(my_model)# calculate shap values. This is what we will plot.
shap_values = explainer.shap_values(X)# make plot.
shap.dependence_plot('Ball Possession %', shap_values[1], X, interaction_index="Goal Scored")

如果您没有为interaction_index提供一个参数,Shapley会使用一些逻辑来选择一个可能有趣的参数。
这不需要编写大量代码。但这些技术的诀窍在于批判性地思考结果,而不是编写代码本身。
轮到你了
用一些问题来测试自己,用这些技巧来提升你的技能。
练习部分
设置
我们再次提供了代码来进行基本的加载、审查和模型构建。运行下面的单元格以设置所有内容:
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import shap# Environment Set-Up for feedback system.
from learntools.core import binder
binder.bind(globals())
from learntools.ml_explainability.ex5 import *
print("Setup Complete")import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_splitdata = pd.read_csv('../input/hospital-readmissions/train.csv')
y = data.readmitted
base_features = ['number_inpatient', 'num_medications', 'number_diagnoses', 'num_lab_procedures', 'num_procedures', 'time_in_hospital', 'number_outpatient', 'number_emergency', 'gender_Female', 'payer_code_?', 'medical_specialty_?', 'diag_1_428', 'diag_1_414', 'diabetesMed_Yes', 'A1Cresult_None']# Some versions of shap package error when mixing bools and numerics
X = data[base_features].astype(float)train_X, val_X, train_y, val_y = train_test_split(X, y, random_state=1)# For speed, we will calculate shap values on smaller subset of the validation data
small_val_X = val_X.iloc[:150]
my_model = RandomForestClassifier(n_estimators=30, random_state=1).fit(train_X, train_y)
这里用的还是前面用到医院再次入院的数据集
data.describe()
| – | time_in_hospital | num_lab_procedures | num_procedures | num_medications | number_outpatient | number_emergency | number_inpatient | number_diagnoses | readmitted |
|---|---|---|---|---|---|---|---|---|---|
| count | 25000.000000 | 25000.00000 | 25000.000000 | 25000.000000 | 25000.000000 | 25000.000000 | 25000.00000 | 25000.000000 | 25000.000000 |
| mean | 4.395640 | 42.96012 | 1.341080 | 15.988440 | 0.365920 | 0.203280 | 0.64300 | 7.420160 | 0.456400 |
| std | 2.991165 | 19.76881 | 1.705398 | 8.107743 | 1.224419 | 0.982973 | 1.26286 | 1.940932 | 0.498105 |
| min | 1.000000 | 1.00000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.00000 | 1.000000 | 0.000000 |
| 25% | 2.000000 | 31.00000 | 0.000000 | 10.000000 | 0.000000 | 0.000000 | 0.00000 | 6.000000 | 0.000000 |
| 50% | 4.000000 | 44.00000 | 1.000000 | 15.000000 | 0.000000 | 0.000000 | 0.00000 | 8.000000 | 0.000000 |
| 75% | 6.000000 | 57.00000 | 2.000000 | 20.000000 | 0.000000 | 0.000000 | 1.00000 | 9.000000 | 1.000000 |
| max | 14.000000 | 126.00000 | 6.000000 | 81.000000 | 36.000000 | 64.000000 | 21.00000 | 16.000000 | 1.000000 |
前几个问题需要检查每个特征的效果分布,而不仅仅是每个特征的平均效果。运行下面的单元格,以获得shap_values的总结图。运行大约需要20秒。
explainer = shap.TreeExplainer(my_model)
shap_values = explainer.shap_values(small_val_X)shap.summary_plot(shap_values[1], small_val_X)

问题 1
以下哪个特征对预测的影响范围更大(即最积极和最消极的影响之间的差异更大)
- diag_1_428
- payer_code_?
# 在以下填写变量 'diag_1_428' 或 'payer_code_?'
feature_with_bigger_range_of_effects = ____# Check your answer
q_1.check()
答案:
feature_with_bigger_range_of_effects = ‘diag_1_428’
问题 2
你认为效应大小的范围(最小效应和最大效应之间的距离)是一个很好的指标,表明哪个特征具有更高的排列重要性吗?为什么或者为什么不呢?
如果效应大小的范围测量的是与排列重要性不同的东西:对于“在讨论人群中的再入院风险时,模型认为这两个特征中哪一个对我们来说更重要”这个问题,哪个是更好的答案?
在你决定了你的答案之后,运行下面的代码行。
# Check your answer (Run this code cell to receive credit!)
q_2.solution()
结论:
没有。效应范围的宽度不是排列重要性的合理近似值。就此而言,范围的宽度并不能很好地映射到任何直观的“重要性”,因为它可以由几个异常值来确定。然而,如果图表上的所有点彼此之间分布广泛,这是一个合理的迹象,表明排列的重要性很高。由于影响的范围对异常值非常敏感,所以排列重要性是衡量对模型普遍重要的东西的更好方法。
问题 3
diag_1_428和payer_code_?是二进制变量,取值为0或1。
从图表中,你认为哪一个通常会对预测的再入院风险产生更大的影响:
- 将diag_1_428从0修改为1
- 改变payer_code_ ?从0到1
为了节省滚动时间,我们在下面添加了一个单元格来再次绘制图形(这个单元格运行得很快)。
shap.summary_plot(shap_values[1], small_val_X)

# Set following var to "diag_1_428" if changing it to 1 has bigger effect. Else set it to 'payer_code_?'
bigger_effect_when_changed = ____# Check your answer
q_3.check()
答案:
bigger_effect_when_changed = “diag_1_428”
要获得结论和解释,运行下一行。
结论:
虽然diag_1_428的大多数SHAP值很小,但少数粉点(变量的高值,对应于具有该诊断的人)具有较大的SHAP值。换句话说,这个变量的粉色点离0很远,让某人拥有更高的(粉色)值会显著增加他们的再入院风险。在现实世界中,这种诊断很罕见,但对患有这种疾病的人来说风险更大。相比之下,payer_code_?有许多蓝色和粉红色的值,并且两者的SHAP值都与0有意义的不同。但是改变payer_code_?从0(蓝色)到1(粉红色)的影响可能比更改diag_1_428的影响要小。
问题 4
一些特征(如number_inpatient)在蓝色点和粉色点之间有相当清晰的分隔。num_lab_procedures等其他变量将蓝色和粉红色的点混杂在一起,尽管SHAP值(或对预测的影响)并不都是0。
您认为您从num_lab_procedures将蓝色和粉红色的点混在一起的事实中学到了什么? 为了得到答案,运行下面的行来验证您的结论。
结论:
这种混乱表明,有时增加该特征会导致更高的预测,有时会导致更低的预测。换句话说,特征值的高低对预测既有积极的影响,也有消极的影响。对于这种“混乱”的效果,最可能的解释是变量(在本例中为num_lab_procedures)与其他变量具有交互作用。例如,可能有一些诊断需要进行许多实验室检查,而其他诊断则意味着风险增加。我们还不知道还有什么其他特性与num_lab_procedures交互,尽管我们可以用SHAP贡献依赖图来研究它。
问题 5
考虑下面的SHAP贡献依赖性图。
x轴显示feature_of_interest,点根据other_feature上色。

feature_of_interest和other_feature之间是否存在交互?如果是这样,当other_feature值高或other_feature值低时,feature_of_interest是否对预测有更积极的影响?
当您准备好得到答案时,运行以下代码。
# Check your answer (Run this code cell to receive credit!)
q_5.solution()
结论:
首先,回想一下,SHAP值是对给定特征对预测的影响的估计。因此,如果点从左上角到右下角呈趋势,这意味着低的feature_of_interest值导致更高的预测。
回到这个图表:
当other_feature值较高时,Feature_of_interest向下倾斜。要看到这一点,请将目光集中在粉色点上(other_feature值较高的地方),并通过这些粉色点想象一条最适合的线。它向下倾斜,表明预测随着feature_of_interest的增加而下降。
现在把你的眼睛集中在蓝色的点上,想象一下这些点之间的最佳拟合线。它通常是相当平坦的,甚至可能在图的右侧向上弯曲。因此,当other_feature值较高时,增加feature_of_interest会对预测产生更积极的影响。
问题 6
通过运行以下单元格查看重新接收数据的总结图:
shap.summary_plot(shap_values[1], small_val_X)

num_drugs和num_lab_procedures都有粉红色和蓝色的点。
除了num_drugs具有更大的影响(更积极和更消极)之外,很难看出这两个特征在影响再入院风险方面有什么有意义的区别。为每个变量创建SHAP依赖性贡献图,并描述您认为这两个变量对预测影响的不同之处。
提醒一下,这里是您之前看到的用于创建这种类型的图的代码。
shape.dependence_plot(feature_of_interest, shap_values[1], val_X)
回想一下,您的验证数据名为small_val_X。
# Your code here
____
提示:这里需要填写 ‘num_lab_procedures’ 和 ‘num_medications’ 的
依赖性贡献图。
答案:
shap.dependence_plot(‘num_lab_procedures’, shap_values[1],
small_val_X) shap.dependence_plot(‘num_medications’, shap_values[1],
small_val_X)


粗略地说,num_lab_procedures看起来像一个没有什么可识别模式的云。它在任何一点都不会陡然向上或向下倾斜。很难说我们从那个情节中学到了什么。同时,这些值并不都非常接近于0。所以这个模型似乎认为这是一个相关的特征。一个潜在的下一步将是通过给它涂上不同的其他特征来搜索交互来探索更多。
另一方面,num_drugs明显向上倾斜,直到值大约为20,然后又向下倾斜。如果没有更多的医学背景,这似乎是一个令人惊讶的现象……你可以做一些探索看看这些病人是否在其他特征上也有不寻常的价值。但下一步最好是与领域专家(在本例中是医生)讨论这一现象。
祝贺你
就是这样!机器学习模型不应该再像黑盒子一样,因为你有工具来检查它们,并了解它们对世界的了解。
这是调试模型、建立信任和学习解释以做出更好决策的优秀技能。这些技术彻底改变了我做数据科学的方式,我希望它们也能对你产生同样的影响。
真正的数据科学包含探索的元素。我希望你能找到一个有趣的数据集来试用这些技术(Kaggle有很多免费的数据集可供试用)。如果你在这个世界上学到了一些有趣的东西,可以在这个论坛上分享你的作品。我很想看看你如何运用你的新技能。。
相关文章:
【机器学习可解释性】5.SHAP值的高级使用
机器学习可解释性 1.模型洞察的价值2.特征重要性排列3.部分依赖图4.SHAP 值5.SHAP值的高级使用 正文 汇总SHAP值以获得更详细的模型解释 总体回顾 我们从学习排列重要性和部分依赖图开始,以显示学习后的模型的内容。 然后我们学习了SHAP值来分解单个预测的组成部…...

CentOS开机自动运行jar程序实现
前面已经有一篇文章介绍jar包如何在CentOS上运行,《在linux上运行jar程序操作记录》 后来发现系统重启后不能自动运行,导致每次都要手动打开,这篇介绍如何自动开机启动运行jar程序。 一、找到JDK程序执行位置 [rootlocalhost /]# which jav…...
matlab双目标定中基线物理长度获取
在MATLAB进行双目摄像机标定时,通常会获得相机的内参,其中包括像素单位的焦距(focal length)以及物理单位的基线长度(baseline)。对于应用中的深度估计和测量,基线长度的物理单位非常重要,因为它直接影响到深度信息的准确性。有时候,您可能只能获取像素单位的焦距和棋…...

自己动手实现一个深度学习算法——二、神经网络的实现
文章目录 1. 神经网络概述1)表示2)激活函数3)sigmoid函数4)阶跃函数的实现5)sigmoid函数的实现6)sigmoid函数和阶跃函数的比较7)非线性函数8)ReLU函数 2.三层神经网络的实现1)结构2&…...
gRPC源码剖析-Builder模式
一、Builder模式 1、定义 将一个复杂对象的构建与表示分离,使得同样的构建过程可以创建不同的的表示。 2、适用场景 当创建复杂对象的算法应独立于该对象的组成部分以及它们的装配方式时。 当构造过程必须允许被构造的对象有不同的表示时。 说人话:…...

ARM传输数据以及移位操作
3.2.2 数据传送指令 LDR/STR指令用来在寄存器和内存之间输送数据。如果我们想要在寄存器之间传送数据,则可以使用MOV指令。MOV指令的格式如下。 MOV {cond} {s}Rd, oprand2 MOV {cond} {s}Rd, oprand2 其中,{cond}为条件指令可选项,{s}用来表…...
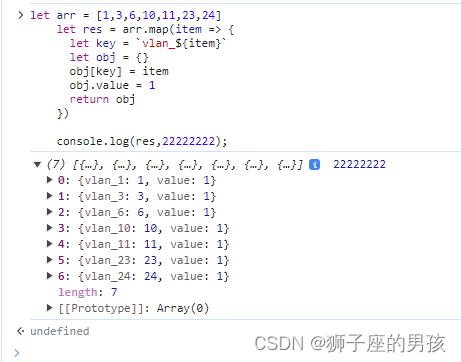
06、如何将对象数组里 obj 的 key 值变成动态的(即:每一个对象对应的 key 值都不同)
1、数据情况: 其一、从后端拿到的数据为: let arr [1,3,6,10,11,23,24] 其二、目标数据为: [{vlan_1: 1, value: 1}, {vlan_3: 3, value: 1}, {vlan_6: 6, value: 1}, {vlan_10: 10, value: 1}, {vlan_11: 11, value: 1}, {vlan_23: 23, v…...
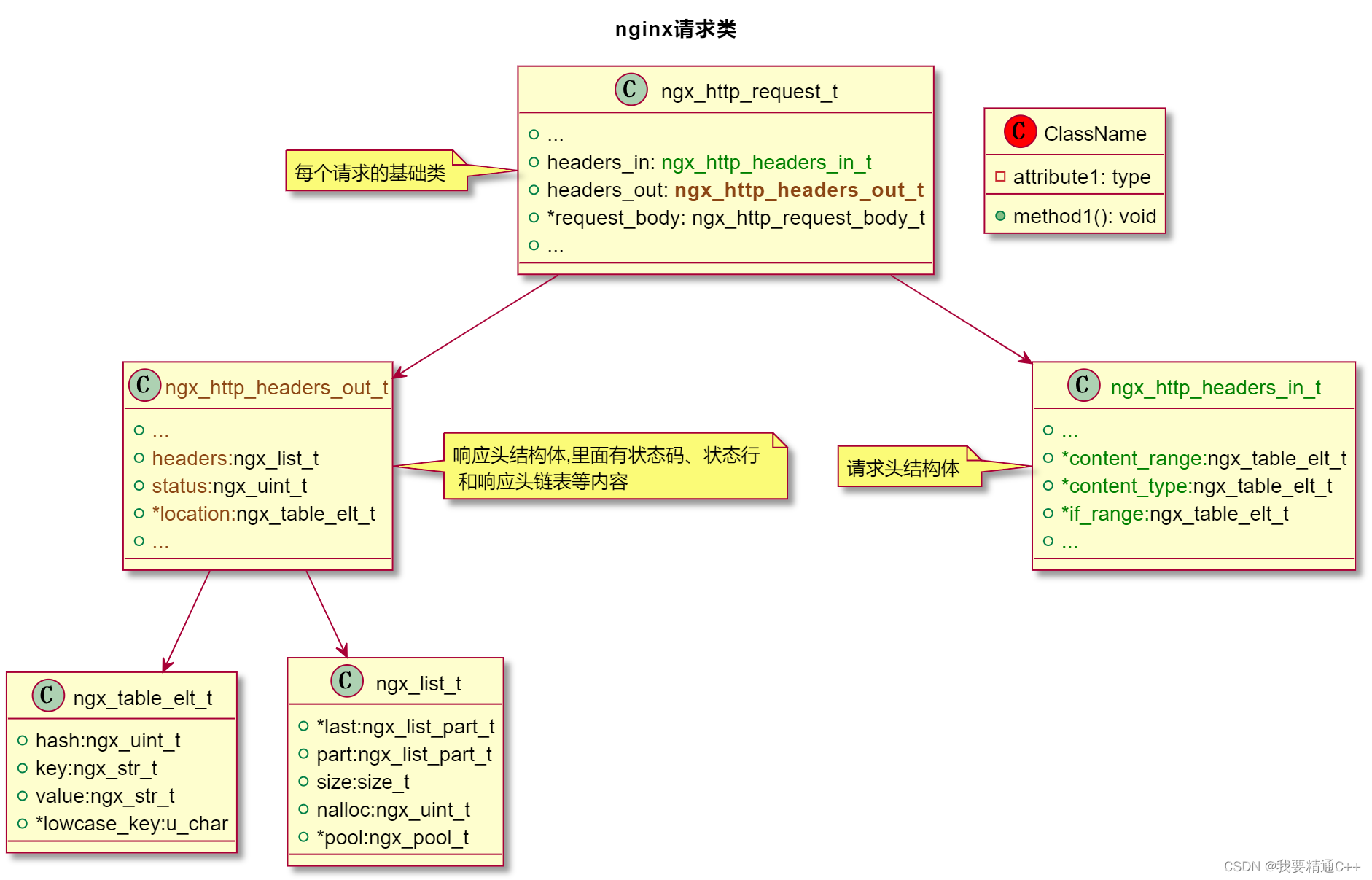
ngx_http_request_s
/* 罗剑锋老师的注释参考: https://github.com/chronolaw/annotated_nginx/blob/master/nginx/src/http/ngx_http_request.h */struct ngx_http_request_s {uint32_t signature; /* "HTTP" */ngx_connection_t …...

Docker 学习路线 2:底层技术
了解驱动Docker的核心技术将让您更深入地了解Docker的工作原理,并有助于您更有效地使用该平台。 Linux容器(LXC) Linux容器(LXC)是Docker的基础。 LXC是一种轻量级的虚拟化解决方案,允许多个隔离的Linux系…...

UEFI实战——显示图片
一、准备工作 1.1 BMP格式图片 参考:BMP格式详解获取“BMP格式详解”文档里的图片,命名为Logo.bmp将Logo.bmp图片放到U盘里,U盘格式FAT32二、实例代码 2.1 代码结构 TextPkg/ ├── Display.c ├── GetFile.c ├── Test.c ├── Test.dsc ├── Test.h └── Tes…...
Ansible中的playbook
目录 一、playbook简介 二、playbook的语法 三、playbook的核心组件 四、playbook的执行命令 五、vim 设定技巧 六、基本示例 一、playbook简介 1、playbook与ad-hoc相比,是一种完全不同的运用。 2、playbook是一种简单的配置管理系统与多机器部署系统的基础…...
怎样去除视频中的杂音,保留人声部分?
怎样去除视频中的杂音,保留人声部分?这个简单嘛!两种办法可以搞定:一是进行音频降噪,把无用的杂音消除掉;二是提取人声,将要保留的人声片段提取出来。 这就将两种实用的办公都分享出来…...
基于Qt QTreeView|QTreeWidget控件使用简单版
头文件解析: 这是一个C++代码文件,定义了一个名为MainWindow的类。以下是对每一句的详细解释: ```cpp #ifndef MAINWINDOW_H #define MAINWINDOW_H ``` 这是一个条件编译指令,用于避免头文件的重复包含。`MAINWINDOW_H`是一个宏定义,用于唯一标识这个头文件。 ```cpp #…...
edge浏览器的隐藏功能
1. edge://version 查看版本信息 2. edge://flags 特性界面 具体到某一特性:edge://flags/#overlay-scrollbars 3. edge://settings设置界面 详情可参考chrome: 4. edge://extensions 扩展程序页面 5. edge://net-internals 网络事件信息 6. edge://component…...
安卓抓包之小黄鸟
下载安装 下载地址: https://download.csdn.net/download/yijianxiangde100/88496463 安装apk 即可。 证书配置:...

Django中的FBV和CBV
一、两者的区别 1、在我们日常学习Django中,都是用的FBV(function base views)方式,就是在视图中用函数处理各种请求。而CBV(class base view)则是通过类来处理请求。 2、Python是一个面向对象的编程语言…...

信息泄露--
大唐电信AC简介 大唐电信科技股份有限公司是电信科学技术研究院(大唐电信科技产业集团)控股的的高科技企业,大唐电信已形成集成电路设计、软件与应用、终端设计、移动互联网四大产业板块。 大唐电信AC集中管理平台存在弱口令及敏感信息泄漏漏…...

C#WPF文本格式化模式实例
本文演示C#WPF文本格式化模式实例 WPF 文本渲染优缺点 WPF中的文本渲染和旧式的基于 GDI的应用程序的文本染有很大区别。很大一部分区 别是由于 WPF 的设备无关显示系统造成的,但 WPF 中的文本染也得到了显著增强,能更清晰地显示文本,在 LCD 监视器上尤其如此。 然而,W…...

嵌入式云平台一些基础概念的理解
1.SDK SDK是Software Development Kit的缩写,译为”软件开发工具包”,通常是为辅助开发某类软件而编写的特定软件包,框架集合等,SDK一般包含相关文档,范例和工具。 我自己的理解就似乎,SDK也就是软件开发工具包,他会为其使用者提供一些封装好的接口&…...
【项目管理】生命周期风险评估
规划阶段目标:识别系统的业务战略,以支撑系统的安全需求及安全战略 规划阶段评估重点:1、本阶段不需要识别资产和脆弱性;2、应根据被评估对象的应用对象、应用环境、业务状况、操作要求等方面识别威胁; 设计阶段目标…...

告别演讲焦虑:PPTTimer如何让时间管理变得简单智能
告别演讲焦虑:PPTTimer如何让时间管理变得简单智能 【免费下载链接】ppttimer 一个简易的 PPT 计时器 项目地址: https://gitcode.com/gh_mirrors/pp/ppttimer 你是否曾在重要演讲时频繁看表,担心时间不够用?是否在PPT演示中因时间控制…...
)
毕业论文神器!高效论文写作全流程AI论文写作工具推荐(2026 最新)
论文写作全流程可拆解为文献调研→选题/开题→大纲/初稿→文献综述→降重/去AI味→润色/格式→查重/投稿七大环节,2026年AI论文写作工具按环节精准匹配,兼顾中文适配、降重能力、去AI痕迹、学术合规四大核心需求,覆盖免费/付费、通用/垂直场景…...

PowerBI主题模板完整指南:35个JSON模板快速打造专业报表
PowerBI主题模板完整指南:35个JSON模板快速打造专业报表 【免费下载链接】PowerBI-ThemeTemplates Snippets for assembling Power BI Themes 项目地址: https://gitcode.com/gh_mirrors/po/PowerBI-ThemeTemplates 还在为PowerBI报表的单调外观而烦恼吗&…...

通过TaotokenCLI工具一键配置多开发环境提升团队协作效率
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置多开发环境提升团队协作效率 在团队协作开发中,一个常见的挑战是确保所有成员都能快速、…...

PX4固件编译避坑指南:自定义机型后如何正确生成airframe_metadata并更新QGC
PX4固件编译避坑指南:自定义机型后如何正确生成airframe_metadata并更新QGC 当你花费数小时精心设计了一个全新的无人机机型,修改完所有参数并准备在QGroundControl(QGC)中测试时,却发现地面站无法识别你的自定义机型—…...
)
保姆级教程:用ENVI+SNAP搞定哨兵1号雷达数据预处理(附水稻监测实战)
从零掌握哨兵1号雷达数据处理:ENVI与SNAP双软件协同实战指南 当第一次接触哨兵1号雷达数据时,许多研究者都会被其独特的成像机制和处理流程所困扰。与光学遥感不同,雷达数据需要经过一系列专业预处理才能用于分析。本文将带你系统掌握ENVI和…...

手把手教你给老旧JLink V8“续命”:AT91-ISP搭配SAM-PROG刷机全记录
手把手教你给老旧JLink V8“续命”:AT91-ISP搭配SAM-PROG刷机全记录 当你的JLink V8突然罢工,电脑反复提示"无法识别的USB设备",先别急着给它判死刑。这款经典调试工具采用的AT91SAM7S64主控芯片,其实有着惊人的"复…...

Gev入门指南:5分钟快速搭建高性能TCP服务器
Gev入门指南:5分钟快速搭建高性能TCP服务器 【免费下载链接】gev 🚀Gev is a lightweight, fast non-blocking TCP network library / websocket server based on Reactor mode. Support custom protocols to quickly and easily build high-performance…...

长期使用Token Plan套餐在Taotoken平台带来的月度成本控制感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Token Plan套餐在Taotoken平台带来的月度成本控制感受 作为一名需要频繁调用大模型API进行项目开发的工程师,成…...

告别数据锁定:用youdaonote-pull实现有道云笔记的本地化自由
告别数据锁定:用youdaonote-pull实现有道云笔记的本地化自由 【免费下载链接】youdaonote-pull 📝 一个一键导出 / 备份「有道云笔记」所有笔记的 Python 脚本。 A Python script to export/backup all the notes of the "Youdao Note". 项目…...