python网络数据获取
文章目录
- 1网络爬虫
- 2网络爬虫的类型
- 2.1通用网络爬虫
- 2.1.1
- 2.1.2
- 2.2聚焦网络爬虫
- 2.2.1 基于内容评价的爬行策略
- 2.2.2 基于链接结构的爬行策略
- 2.2.3基于增强学习的爬行策略
- 2.2.4基于语境图的爬行策略
- 2.3增量式网络爬虫
- 深层网页爬虫
- 3网络爬虫基本架构
- 3.1URL管理模块
- 3.2网页下载模块
- 3.3网页解析模块
- 3.4数据存储器
- 4网页下载模块
- 4.1 requests简介
- 4.2 requests库的使用
- 5网页解析模块
- 5.1 beautiful soup4简介
- 5.2 创建beautiful soup4 对象
- 5.3 查询结点
- 5.4获取结点信息
- 5.4.1利用Tag对象获取结点信息
- 5.4.2利用BeautifulSoup对象获取其他结点信息
- 6 案例
1网络爬虫
网络爬虫(web spider)又称网络机器人、网络蜘蛛,是一种根据既定规则,自动提取网页信息的程序或脚本。将互联网上的目标网页数据保存到本地,以便进行本地数据文件操作和后续处理
传统爬虫以一个或若干初始网页的统一资源定位符(Uniform Resource Location ,URL)为起点,下载每一个URL指定的网页,分析并获取页面内容,并不断从当前页面抽取新的URL放入队列,记录每一个已经爬取过的页面,直到URL队列为空或满足设定的停止条件为止。
2网络爬虫的类型
2.1通用网络爬虫
通用网络爬虫又称全网爬虫,爬行对象从一些种子URL扩充到整个Web ,主要为门户站点搜索引擎和大型Web服务提供商采集数据。这类网络爬虫的爬行范围和数量巨大,对爬行速度和存储空间要求较高,而对爬行页面的顺序要求相对较低,通常采用并行工作方式应对大量待刷新的页面,适合为搜索引擎获取广泛的主题。
通用网络爬虫大致由页面爬行模块、页面分析模块、链接过滤模块、页面数据库、URL队列和初始URL集合等几部分构成。为了提高工作效率,通用网络爬虫可以采用深度优先和广度优先等爬行策略。
2.1.1
采用深度优先爬行策略的爬虫按照深度由低到高的顺序,依次访问下一级网页链接,直到不能再深入为止。爬虫在完成一个爬行分支后返回上一个链接节点进一步搜索其它链接。当所有链接遍历完毕,爬行任务结束。这种爬行策略比较适合垂直搜索或站内搜索,但爬行页面内容层次较深的站点时会造成资源的巨大浪费。
2.1.2
采用广度优先爬行策略的爬虫按照网页内容目录层次深浅来爬行页面,优先爬取目录层次较浅的页面。当同一层次的页面爬行完毕,再深入下一层次继续爬取。这种爬行策略能够有效控制页面的爬取深度,避免遇到一个无穷深层分支时无法结束爬行的问题。该策略无需存储大量的中间节点,不足之处是需要较长时间才能爬行到目录层次较深的页面。
2.2聚焦网络爬虫
聚焦网络爬虫又称主题网络爬虫,它会选择性地爬取与预定主题相关的页面。与通用网络爬虫相比,聚焦网络爬虫只需爬取与主题相关的页面,极大地节省了硬件和网络资源,保存页面数量少且更新快,可以更好地满足特定人群对特定领域信息的爬取需求。页面内容和链接重要性不同导致链接的访问顺序也不一样,聚焦爬虫爬行策略因此分为以下四种。
2.2.1 基于内容评价的爬行策略
基于内容评价的爬行策略将文本相似度计算方法引入网络爬虫中。该策略以用户输入的查询词为主题,将包含查询词的页面视为主题相关页面,其局限性在于无法评价页面与主题相关度的高低,可以尝试利用空间向量模型计算页面与主题的相关度大小。
2.2.2 基于链接结构的爬行策略
网页页面中的链接指示了页面之间的相互关系,基于链接结构的搜索策略模式利用这些结构特征评价页面和链接的重要性,以此决定搜索顺序。其中,PageRank算法是这类搜索策略的代表,具体做法是每次选择PageRank值较大的页面链接进行访问。
2.2.3基于增强学习的爬行策略
基于增强学习的爬行策略将增强学习引入聚焦爬虫,利用贝叶斯分类器,根据整个网页文本和链接文本对超链接进行分类,为每个链接计算出重要性,从而决定链接的访问顺序。
2.2.4基于语境图的爬行策略
基于语境图的爬行策略通过建立语境图来学习网页之间的相关度。该策略训练一个机器学习系统,通过该系统计算当前页面到相关Web页面的距离,距离近的页面中的链接优先访问。
2.3增量式网络爬虫
增量式网络爬虫**对已下载的网页采取增量式更新策略,只爬行新产生或已经发生变化的网页,在一定程度上保证爬行尽可能新的页面。**与周期性爬行和刷新页面的爬虫相比,增量式爬行按需爬取新产生或发生更新的页面内容,有效减少了数据下载量并及时更新爬行过的网页,减小时间和空间上的耗费,但是增加了爬行算法的复杂度和实现难度。
为了保持本地存储的页面为最新页面,增量式爬虫通过监测网页数据的更新情况,持续更新本地的页面内容,常用方法有:
统一更新法︰爬虫以相同的频率访问所有网页,不考虑网页的改变频率。
个体更新法︰爬虫根据个体网页的改变频率重新访问各页面。
基于分类的更新法︰爬虫根据网页改变频率分为更新较快网页子集和更新较慢网页子集两类,然后以不同的频率访问这两类网页。
为了保证本地集中的页面质量,增量式爬虫需要对网页的重要性进行排序,常用广度优先策略和PageRank优先策略;也可以采用自适应方法,根据历史爬取结果和网页实际变化速度对页面更新频率进行调整;或者将网页分为变化网页和新网页两类,分别采用不同的爬行策略。
深层网页爬虫
Web页面按照存在方式可以分为表层网页和深层网页两类。表层网页是指传统搜索引擎可以索引到的页面,以超链接可以到达的静态网页为主。深层网页是指隐藏在搜索表单后,大部分内容不能通过静态链接获取,只有用户提交关键词才能获得的Web页面。深层网页是目前互联网上最大、发展最快的新型信息资源。深层网页爬虫爬行过程中最重要的部分就是表单填写,表单填写方法可以分为两类。
基于领域知识的表单填写∶此方法一般会维持一个本体库,通过语义分析来选取合适的关键词填写表单。一种方法是将数据表单按照语义分配到各个组中,每组从多方面注解,结合各种注解结果预测最终的注解标签;也可以利用一个预定义的领域本体知识库来识别深层网页内容,同时利用Web站点导航模式识别自动填写表单时所需的路径导航。
基于网页结构分析的表单填写:此方法一般无需领域知识或仅利用有限领域知识,将网页表单表示为文档对象模型(Document Object Model ,DOM),从中提取表单各字段值。一种方法是将HTML网页表示为DOM树形式,将表单区分为单属性表单和多属性表单,分别进行处理;也可以将Web文档构造成DOM树,将文字属性映射到表单字段。
3网络爬虫基本架构
3.1URL管理模块
URL管理模块负责管理URL链接,维护已经爬行的URL集合和计划爬行的URL集合,防止重复爬取或循环爬取。其主要功能包括︰添加新的URL链接、管理已爬行的URL和未爬行的URL以及获取待爬行的URL。
URL管理模块的实现方式有两种:一种是利用python中集合数据类型不包含重复元素的特点达到去重效果,防止重复爬取或循环爬取;另一种实现方式是在数据库表中创建记录时,为每一个URL增加一个标志字段,例如︰已爬行的网页链接标记为“1”,未爬行的网页链接标记为“O”。当有新链接产生时,先在已爬行的链接集中查询,如果发现该链接已被标记为“1”,那么不再爬行该URL的链接页面。
3.2网页下载模块
这是网络爬虫的核心组件之一,用于从URL管理模块中将指定URL对应的页面下载到本地或者以字符串形式读入内存,方便后续使用字符串相关操作解析网页内容。
Python第三方库requests是一个处理HTTP请求的模块,其最大优点是程序编写过程更接近正常的URL访问过程。
3.3网页解析模块
网页解析模块是网络爬虫的另一个核心组件,用于从网页下载模块获取已下载的网页,并解析出有效数据交给数据存储器。网页解析的实现方式多种多样。由于下载到本地的网页内容以字符串形式保存,可以使用字符串相关操作从中解析出有价值的结构数据,例如:可以使用正则表达式指定规则,然后根据规则找出感兴趣的字符串;也可以使用python自带的HTML解析工具html.parser从网页内容的字符串中解析出相关信息;还可以使用python第三方库beautifulsoup4实现网页解析。作为一种功能强大的结构化网页解析工具,beautifulsoup4模块能够根据HTML和XML语法建立解析树,进而高效解析和处理页面内容。
3.4数据存储器
数据存储器负责将网页解析模块解析出的数据存储起来,用于后续的数据分析和信息利用。
4网页下载模块
4.1 requests简介
requests是python中一个处理HTTP请求的第三方库,需要预先安装。requests模块在python内置模块的基础上进行了高度封装,使得python进行网络请求时更加简洁和人性化。
requests库支持非常丰富的链接访问功能,包括HTTP长连接和连接缓存、国际域名和URL获取、HTTP会话和Cookie保持、浏览器使用风格的SSL验证、自动内容解码、基本摘要身份验证、有效键值对的Cookie记录、自动解压缩、Unicode响应主体、HTTP ( S )代理支持、文件分块上传、流式下载、连接超时和分块请求等。
4.2 requests库的使用
通过URL访问网络链接并返回网页内容是requests模块的基本功能,其中与网页请求相关的函数有6个,具体使用方法如表所示。

# requests.get()方法向目标网址发送请求,接收响应,该方法返回一个response对象。这里的参数url必须采用HTTP或HTTPS方式访问In[ ] : import requestsurl= 'https: / / www.baidu.com/'r_obj =requests.get(ur1)type(r_obj)
out[ ] :requests.models. Response
与浏览器的交互过程类似,调用requests.get()方法后,返回的网页内容保存为一个response对象,便于后续操作。response对象的常用属性如表所示。

import requests
def getHTMLText(url):try:r_obj=requests.get(url,timeout=30)r_obj.raise_for_status()r_obj.encoding='utf-8'return r_obj.textexcept:return ""
url="http://www.baidu.com"
print(getHTMLText(url))
5网页解析模块
5.1 beautiful soup4简介
Python第三方库beautifulsoup4(也称BeautifulSoup或bs4库)用于解析和处理HTML、XML文件并提取数据。
beautifulsoup4支持多种解析器,其优势是能够根据HTML和XML语法建立解析树,进而高效解析其中的内容,为用户提供需要的数据。
HTML建立的web页面一般比较复杂,除了有用内容之外,还包含大量用于页面格式的元素。一个网页文件通常可以表示为一个文档对象模型(DOM)。DOM是一种处理HTML和XML文件的标准编程接口,它提供了对整个文档的访问模型,将网页文档表示为一个树形结构,树的每个节点表示一个HTML标签( Tag )或标签内的文本项。
5.2 创建beautiful soup4 对象
# 实例化的Beautifulsoup对象相当于一个页面,表示一个文档的全部内容
In[ ] : import requestsFrom bs4 import BeautifulSoupurl = 'http://www.baidu.com'r_obj = requests.get(url)bs = BeautifulSoup(r_obj.content, from_encoding='utf-8')type(bs)
out[ ] : bs4.BeautifulSoup
BeautifulSoup对象是一个树状结构,它包含了HTML页面的每一个标签(Tag )元素,如、等。也就是说,HTML的主要结构都成为BeautifulSoup对象的属性。表中列出了BeautifulSoup对象的常用属性。

5.3 查询结点
- find() 方法
- find()方法实现指定范围内的单次条件定位,目的是找到满足条件的第一个节点,返回第一个匹配到的对象。格式如下:
find(name, attrs, recursive, string)- 参数name:标签名,可以是字符串类型,定位到指定标签名的结点;也可以是列表类型,用于匹配多个标签名;还可以是正则表达式,用于传递自定义的标签名规则;找到后返回一个BeautifulSoup标签对象。
- 参数attrs:标签的属性,以字典类型指定标签的属性名及属性值,查找其第一次出现的位置,找到后返回一个BeautifulSoup标签对象;
- 参数recursive: 设置查找层次,参数为布尔类型数据,默认为True,表示当前标签下的所有子孙标签;如果设置为False,表示只查找当前标签下的直接子标签;
- 参数text:查找标签的文本内容,而不使用标签的属性去匹配。参数可以是字符串类型,字符串列表等,搜索指定范围的字符串内容,返回匹配字符串的列表。
- findall() 方法
- find_all()方法实现指定范围内多个符合要求的定位,目的是找到所有满足条件的节点,返回多个匹配结果构成的列表。find_all)方法语法格式如下∶
find_all(name, attrs, recursive, text, limit,**kwargs)- 其中范围限制参数limit只用于find_all()方法,用于设置网页中获取结果的范围。find()方法等价于参数limit等于1的情形。参数**kwargs用于选择具有指定属性的标签,属于冗余技术。其它参数的含义与find)方法类似。
# 查找title标签
bs.find('title')# 查找第一个链接标签
bs.find('a')# 查找所有的链接标签
bs.find_all('a')# 查找class为mnav的所有链接标签
bs.find_all('a', class_='mnav')
5.4获取结点信息
5.4.1利用Tag对象获取结点信息
不难发现,BeautifulSoup对象的属性名与HTML的标签名称相同。实际上,HTML页面中的每一个Tag元素在beautifulsoup4库中也是一个对象,称为Tag对象,如、

import requests
import lxml
from bs4 import BeautifulSoupurl = 'http://www.baidu.com'
r_obj = requests.get(url)bs = BeautifulSoup(r_obj.content, 'lxml',from_encoding='utf-8')
# 查找第一个链接标签
link_tag = bs.find('a')
# 节点标签名称
link_tag.name
# 节点的属性
link_tag.attrs
link_tag['href']
link_tag.text
5.4.2利用BeautifulSoup对象获取其他结点信息
一个网页文件通常表示为一个DOM树结构,它精确地描述了HTML文档中标签结点间的层次关系。在解析网页文档的过程中,可以利用beautifulsoup4模块中BeautifulSoup对象的上行遍历属性和下行遍历属性获取不同层次结点的信息。

url = 'http://www.pythonscraping.com/pages/page3.html'
r_obj = requests.get(url)
bs_obj = BeautifulSoup(r_obj.content, 'lxml')# 获取表格标签
table_tag = bs_obj.find('table')# 获取表格的每行内容,即“孩子”结点
for row in table_tag.children:print(row)# 获取子孙结点
for descendant in table_tag.descendants:print(descendant)# 返回下一个“同辈”结点
first_row = table_tag.find('tr')for sibling in first_row.next_siblings:print(sibling)# 返回“父亲”结点
first_row.parent
6 案例
import requests
from bs4 import BeautifulSoup# 爬取红楼梦全集并存盘
if __name__ == '__main__':# 目录页url = 'http://hongloumeng.5000yan.com/'req = requests.get(url)# 解析目录页soup = BeautifulSoup(req.content, from_encoding='utf-8')# find_next找到第二个divsoup_text = soup.find('div', class_='sidamingzhu-list-mulu')# 遍历ul的子结点,获得标题和对应的链接地址f = open('hongloumeng.txt', 'w', encoding='utf-8')for link in soup_text.ul.children:if link != '\n':download_url = link.a.get('href')download_req = requests.get(download_url)download_soup = BeautifulSoup(download_req.content, from_encoding='utf-8')download_text = download_soup.find('div', class_='grap')f.write(f'\n{link}\n')f.write(download_text.text)
f.close()相关文章:
python网络数据获取
文章目录1网络爬虫2网络爬虫的类型2.1通用网络爬虫2.1.12.1.22.2聚焦网络爬虫2.2.1 基于内容评价的爬行策略2.2.2 基于链接结构的爬行策略2.2.3基于增强学习的爬行策略2.2.4基于语境图的爬行策略2.3增量式网络爬虫深层网页爬虫3网络爬虫基本架构3.1URL管理模块3.2网页下载模块3…...
[Datawhale][CS224W]图机器学习(六)
目录一、简介二、概述三、算法四、PageRank的缺点五、Python实现迭代法参考文献一、简介 PageRank,又称网页排名、谷歌左侧排名、PR,是Google公司所使用的对其搜索引擎搜索结果中的网页进行排名的一种算法。 佩奇排名本质上是一种以网页之间的超链接个…...

aws ecr 使用golang实现的简单镜像转换工具
https://pkg.go.dev/github.com/docker/docker/client#section-readme 通过golang实现一个简单的镜像下载工具 总体步骤 启动一台海外区域的ec2实例安装docker和awscli配置凭证访问国内ecr仓库编写web服务实现镜像转换和自动推送 安装docker和awscli sudo yum remove awsc…...

【20230225】【剑指1】分治算法(中等)
1.重建二叉树class Solution { public:TreeNode* traversal(vector<int>& preorder,vector<int>& inorder){if(preorder.size()0) return NULL;int rootValuepreorder.front();TreeNode* rootnew TreeNode(rootValue);//int rootValuepreorder[0];if(preo…...
「JVM 高效并发」Java 线程
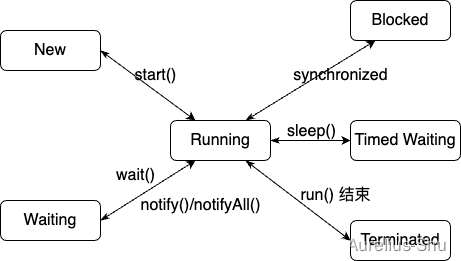
进程是资源分配(内存地址、文件 I/O 等)的基本单位,线程是执行调度(处理器资源调度)的基本单位; Loom 项目若成功为 Java 引入纤程(Fiber),则线程的执行调度单位可能变为…...

ADAS-可见光相机之Cmos Image Sensor
引言 “ 可见光相机在日常生活、工业生产、智能制造等应用有着重要的作用。在ADAS中更是扮演着重要的角色,如tesla model系列全车身10多个相机,不断感知周围世界。本文着重讲解下可见光相机中的CIS(CMOS Image Sensor)。” 定义 光是一种电磁波&…...

【ESP 保姆级教程】玩转emqx MQTT篇③ ——封装 EmqxIoTSDK,快速在项目集成
忘记过去,超越自己 ❤️ 博客主页 单片机菜鸟哥,一个野生非专业硬件IOT爱好者 ❤️❤️ 本篇创建记录 2023-02-26 ❤️❤️ 本篇更新记录 2023-02-26 ❤️🎉 欢迎关注 🔎点赞 👍收藏 ⭐️留言📝🙏 此博客均由博主单独编写,不存在任何商业团队运营,如发现错误,请…...

Python自动化测试面试题-编程篇
前言 随着行业的发展,编程能力逐渐成为软件测试从业人员的一项基本能力。因此在笔试和面试中常常会有一定量的编码题,主要考察以下几点。 基本编码能力及思维逻辑基本数据结构(顺序表、链表、队列、栈、二叉树)基本算法…...

CIT 594 Module 7 Programming AssignmentCSV Slicer
CIT 594 Module 7 Programming Assignment CSV Slicer In this assignment you will read files in a format known as “comma separated values” (CSV), interpret the formatting and output the content in the structure represented by the file. Q1703105484 Learning …...
链路追踪——【Brave】第一遍小结
前言 微服务链路追踪系列博客,后续可能会涉及到Brave、Zipkin、Sleuth内容的梳理。 Brave 何为Brave? github地址:https://github.com/openzipkin/brave Brave是一个分布式追踪埋点库。 #mermaid-svg-riwF9nbu1AldDJ7P {font-family:"…...
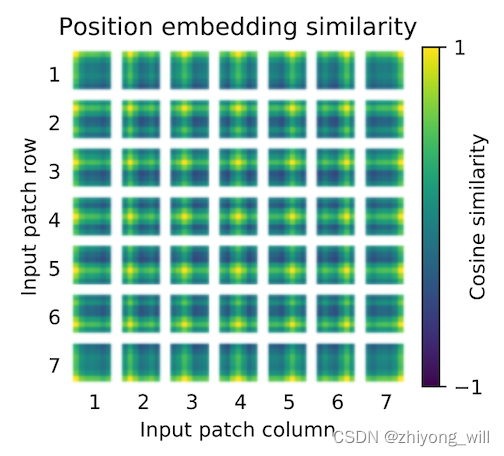
Vision Transformer(ViT)
1. 概述 Transformer[1]是Google在2017年提出的一种Seq2Seq结构的语言模型,在Transformer中首次使用Self-Atttention机制完全代替了基于RNN的模型结构,使得模型可以并行化训练,同时解决了在基于RNN模型中出现了长距离依赖问题,因…...

104-JVM优化
JVM优化为什么要学习JVM优化: 1:深入地理解 Java 这门语言 我们常用的布尔型 Boolean,我们都知道它有两个值,true 和 false,但你们知道其实在运行时,Java 虚拟机是 没有布尔型 Boolean 这种类型的&#x…...

QML 颜色表示法
作者: 一去、二三里 个人微信号: iwaleon 微信公众号: 高效程序员 如果你经常需要美化样式(最常见的有:文本色、背景色、边框色、阴影色等),那一定离不开颜色。而在 QML 中,颜色的表示方法有多种:颜色名、十六进制颜色值、颜色相关的函数,一起来学习一下吧。 老规矩…...
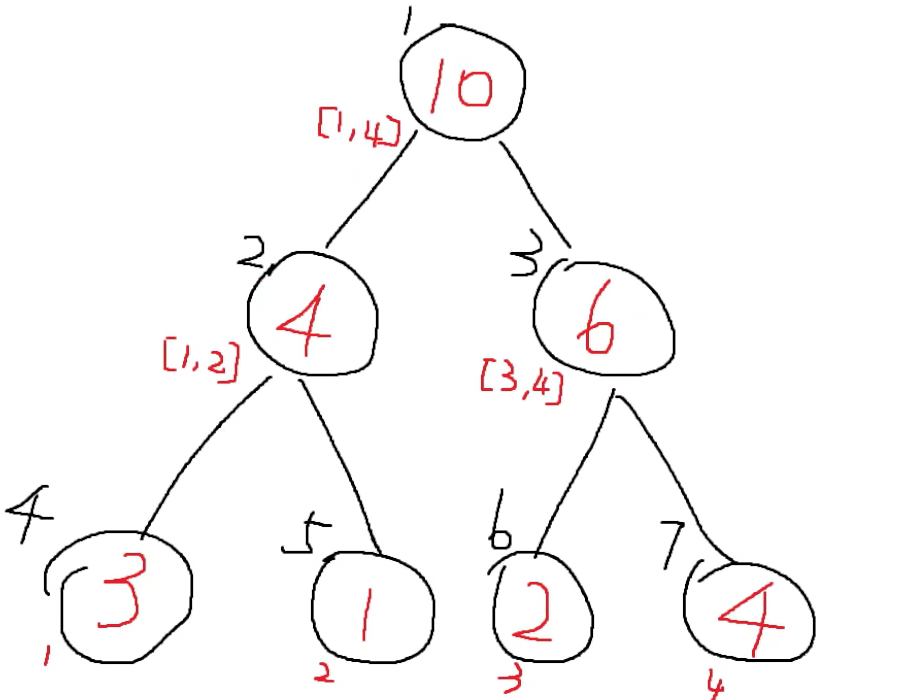
基础数据结构--线段树(Python版本)
文章目录前言特点操作数据存储updateLazy下移查询实现前言 月末了,划个水,赶一下指标(更新一些活跃值,狗头) 本文主要是关于线段树的内容。这个线段树的话,主要是适合求解我们一个数组的一些区间的问题&am…...

【micropython】SPI触摸屏开发
背景:最近买了几块ESP32模块,看了下mircopython支持还不错,所以买了个SPI触摸屏试试水,记录一下使用过程。硬件相关:SPI触摸屏使用2.4寸屏幕,常见淘宝均可买到,驱动为ILI9341,具体参…...
【云原生】k8s中Pod进阶资源限制与探针
一、Pod 进阶 1、资源限制 当定义 Pod 时可以选择性地为每个容器设定所需要的资源数量。 最常见的可设定资源是 CPU 和内存大小,以及其他类型的资源。 当为 Pod 中的容器指定了 request 资源时,调度器就使用该信息来决定将 Pod 调度到哪个节点上。当还…...
AI - stable-diffusion(AI绘画)的搭建与使用
最近 AI 火的一塌糊涂,除了 ChatGPT 以外,AI 绘画领域也有很大的进步,以下几张图片都是 AI 绘制的,你能看出来么? 一、环境搭建 上面的效果图其实是使用了开源的 AI 绘画项目 stable-diffusion 绘制的,这是…...
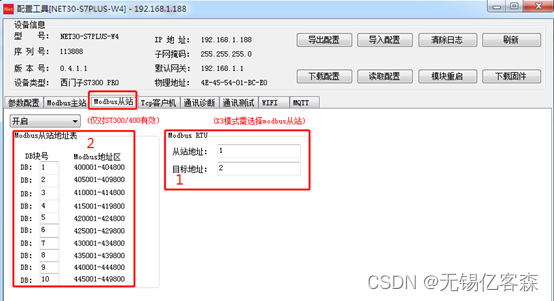
应用场景五: 西门子PLC通过Modbus协议连接DCS系统
应用描述: 西门子PLC(S7200/300/400/200SMART)通过桥接器可以支持ModbusRTU串口和ModbusTCP以太网(有线和无线WIFI同时支持)两种通讯方式连接DCS系统,不需要编程PLC通讯程序,直接在模块中进行地…...

我继续问了ChatGPT关于SAP顾问职业发展前景的问题,大家感受一下
目录 SAP 顾问 跟其他IT工作收入情况相比是怎么样的? 如何成为SAP FICO 优秀的顾问 要想成为SAP FICO 优秀的顾问 ,需要ABA开发技能吗 SAP 顾问中哪个类型收入最多? 中国的ERP软件能够取代SAP吗? 今天我继续撩 ChatGPT。随便问…...
)
Python小白入门---00开篇介绍(简单了解一下)
Python 小白入门 系列教程 第一部分:Python 基础 介绍 Python 编程语言安装 Python 环境变量和数据类型运算符和表达式控制流程语句函数和模块异常处理 第二部分:Python 标准库和常用模块 Python 标准库简介文本处理和正则表达式文件操作和目录操作时…...
)
面试题:文本表示方法详解——One-hot、Word2Vec、上下文表示、BERT词向量全解析(NLP基础高频考点)
1. 为什么面试官总爱问“文本表示方法”?1.1 这个问题的本质是什么任何 NLP 系统,不管是情感分析、文本分类、搜索推荐、智能客服,还是今天的大模型应用,本质上都绕不开一个前提:机器并不真正认识“文字”,…...

3分钟搞定抖音无水印下载:从新手到高手的完整指南
3分钟搞定抖音无水印下载:从新手到高手的完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. …...

如何高效为离线音乐库批量下载同步歌词:LRCGET工具全解析
如何高效为离线音乐库批量下载同步歌词:LRCGET工具全解析 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否拥有大量本地音乐文件却苦于…...

Cursor Pro破解工具:5步实现永久免费使用的完整指南
Cursor Pro破解工具:5步实现永久免费使用的完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial…...

Avogadro 2:开源分子可视化库的终极技术解析
Avogadro 2:开源分子可视化库的终极技术解析 【免费下载链接】avogadrolibs Avogadro libraries provide 3D rendering, visualization, analysis and data processing useful in computational chemistry, molecular modeling, bioinformatics, materials science,…...

[STM32U3] 【每周分享】【STM32U385RG 测评】+调试串口通讯,字符串打印
接着上一回,这会进行串口打印实验 一、查询原理图,找到我们需要配置的串口 如上图:PA9、PA10、USART1 二、按流程打开IDE软件,建立新的工程文件。 配置如下:debug、RCC、USART1 配置完成后就可以生成代码了 三、代…...

Windows上快速安装APK的终极指南:APK Installer完整使用教程
Windows上快速安装APK的终极指南:APK Installer完整使用教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经需要在Windows电脑上运行Android应用…...

拒绝无效熬夜!Paperxie 本科论文智能写作,把毕业季还给你
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/ai/dissertationhttps://www.paperxie.cn/ai/dissertation 凌晨三点的图书馆,光标在空白文档里闪了又闪,Word 字数统计停在 478;导师的修…...
)
手把手教你用wget和md5sum搞定nuScenes数据集下载与校验(Linux/Windows教程)
跨平台高效获取nuScenes数据集:从命令行下载到完整性验证全指南 在自动驾驶和计算机视觉领域,nuScenes数据集因其丰富的传感器数据和精细的标注而成为研究热点。但面对数百GB的数据量,传统下载方式往往力不从心——浏览器下载容易中断&#…...

收藏!普通人零基础转行AI,3-5个月实现高薪就业的进阶指南
本文指出AI行业对非计算机专业人才的需求激增,半路转行者因具备行业经验而更具竞争力。文章澄清了转行AI的常见误区,强调“技术懂业务”是关键,并提供了普通人转行AI的3步走策略:选择AI算法、自然语言或应用工程师等低门槛岗位&am…...