06_es分布式搜索引擎2
一、DSL查询文档
1.DSL查询分类
①查询所有:match_all
②全文检索:利用分词器对用户输入的内容分词,倒排索引去匹配
match_query
multi_match_query
③精确查询:根据精确词条查找数据,查找的是keyword,数值,日期,boolean类型字段
ids,range,term
④地理geo查询:根据经纬度查询
geo_distance
geo_bounding_box
⑤复合查询:将各种条件组合起来,合并查询条件
bool
function_score

总结:查询DSL的基本语法是什么?
GET /索引库名/_search
{ "query": { "查询类型": { "FIELD": "TEXT"}}}
2.全文检索
全文检索查询,会对用户输入内容进行分词。用于搜索框搜索

①match查询:对用户输入的内容分词,然后倒排索引库查询。一个字段

查询三钻的酒店
GET /hotel/_search
{"query": {"match": {"starName": "三钻"}}
}
②multi_match:多个字段查询。参与的字段越多,查询性能越差。

查询品牌,酒店名,商业圈有“外滩如家”
GET /hotel/_search
{"query": {"multi_match": {"query": "外滩如家","fields": ["brand","name","business"]}}
}
3.精确查询
查询的keyword,不进行分词的字段
①term:根据词条准确值查询
②range:范围查询(价格)

①term:

查询品牌是“7天酒店”
GET /hotel/_search
{"query": {"term": {"brand": {"value": "7天酒店"}}}
}
②range:
查询200-250酒店

GET /hotel/_search
{"query": {"range": {"price": {"gte": 200,"lte": 250}}}
}
总结:精确查询常见的有哪些?
- term查询:根据词条精确匹配,一般搜索keyword类型、数值类型、布尔类型、日期类型字段
- range查询:根据数值范围查询,可以是数值、日期的范围
4.地理查询
场景:
查询附近的酒店,附近的人,打车附近的出租车

①矩形范围内:geo_bounding_box
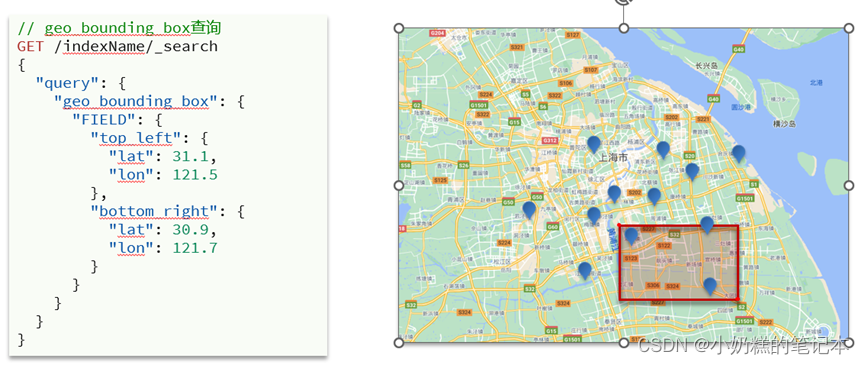
②以指定中心点为半径:

查询这个点15公里范围内的酒店
GET /hotel/_search
{"query": {"geo_distance":{"distance":"15km","location":"31.282444,121.479385"}}
}
5.相关性算分:竞价排名
①fuction score:算分函数查询,可以控制文档相关性算分,控制文档排名


②词条频率越高,得分越高,排名越靠前

③elasticsearch中的相关性打分算法是什么?
- TF-IDF:在elasticsearch5.0之前,会随着词频增加而越来越大
- BM25:在elasticsearch5.0之后,会随着词频增加而增大,但增长曲线会趋于水平

6.修改相关性算分:竞价排名
使用 function score query,可以修改文档的相关性算分(query score),根据新得到的算分排序。

①原始条件查询,搜索文档并根据相关性打分(query score)
②过滤条件:符合条件的文档才重新算分
③算分函数:
算分函数,算分函数的结果称为function score ,将来会与query score运算,得到新算分,常见的算分函数有:
- weight:给一个常量值,作为函数结果(function score)
- field_value_factor:用文档中的某个字段值作为函数结果
- random_score:随机生成一个值,作为函数结果
- script_score:自定义计算公式,公式结果作为函数结果
④加权模式,定义function score与query score的运算方式,包括:
- multiply:两者相乘。默认就是这个
- replace:用function score 替换 query score
- 其它:sum、avg、max、min
案例:搜索外滩的酒店,“如家”品牌给公司充钱了,让他的排名靠前一些。
分析:
①文档为品牌是“如家”的
②算分函数是weight
③加权模式是求和sum
GET /hotel/_search
{"query": {"function_score": {"query": {"match": {"all": "外滩"}},"functions": [{"filter": {"term": {"brand": "如家"}},"weight": 2}],"boost_mode": "sum"}}
}
7.复合查询Boolean Query
布尔查询是一个或多个查询子句的组合。子句组合方式:
must:”与”,必须匹配每个子查询
should:“或”选择性匹配子查询
must_not:必须不匹配,不参与算分,类似“非”
filter:必须匹配,不算分。
案例1:查询上海的酒店,品牌是皇冠假日或华美达。价格不低于500,评分是大于45分的


案例2:搜索名字包含“如家”,价格不高于400,在坐标31.21,121.5周围10km范围内的酒店。
GET /hotel/_search
{"query": {"bool": {"must": [{"match": {"name": "如家"}}],"must_not": [{"range": {"price": {"gte": 400}}}],"filter": [{"geo_distance": {"distance": "10km","location": {"lat": 31.21,"lon": 121.5}}}]}}
}
二、搜索结果处理
1.排序
es支持对搜索结果排序,默认是根据相关度算分(_score)排序。可以排序的字段:keyword类型,数值类型,地理坐标类型,日期类型。
排序语法

地理坐标排序语法

案例1:对酒店数据按照用户评价降序排序,评价相同的按照价格升序排序
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"score":"desc"},{"price": "asc"}]
}
案例2:实现对酒店数据按照到你的位置坐标的距离升序排序
获取经纬度的方式:https://lbs.amap.com/demo/jsapi-v2/example/map/click-to-get-lnglat/
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"_geo_distance": {"location": {"lat": 31.220393,"lon": 121.544427},"order": "asc","unit": "km"}}]
}
2.分页
es的搜索结果默认是top10条。
es通过修改from,size参数控制返回的分页结果

深度分页问题
ES是分布式的,所以会面临深度分页问题。例如按price排序后,获取from = 990,size =10的数据:

①首先在每个数据分片上都排序并查询前1000条文档。
②然后将所有节点的结果聚合,在内存中重新排序选出前1000条文档
③最后从这1000条中,选取从990开始的10条文档
如果搜索页数过深,或者结果集(from + size)越大,对内存和CPU的消耗也越高。因此ES设定结果集查询的上限是10000
总结
from + size:
- 优点:支持随机翻页
- 缺点:深度分页问题,默认查询上限(from + size)是10000
- 场景:百度、京东、谷歌、淘宝这样的随机翻页搜索
after search:
- 优点:没有查询上限(单次查询的size不超过10000)
- 缺点:只能向后逐页查询,不支持随机翻页
- 场景:没有随机翻页需求的搜索,例如手机向下滚动翻页
3.高亮
搜索关键字突出显示。

原理:
①搜索关键字标记出来
②页面加css样式

案例:如家酒店高亮

三、RestClient查询文档
1.快速入门
①请求DSL的组织

RestAPI中其中构建DSL是通过HighLevelRestClient中的resource()来实现的,其中包含了查询、排序、分页、高亮等所有功能

RestAPI中其中构建查询条件的核心部分是由一个名为QueryBuilders的工具类提供的,其中包含了各种查询方法

②解析结果response

③查询全部酒店的完整代码
@Test
void testMatchAll() throws IOException {// 1.准备查询请求,参数是索引库名SearchRequest request = new SearchRequest("hotel");// 2.组织DSL参数request.source().query(QueryBuilders.matchAllQuery());// 3.发送请求,得到响应SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析结果SearchHits searchHits = response.getHits();// 4.1 获取查询的条数long total = searchHits.getTotalHits().value;// 4.2 获取查询的集合SearchHit[] hits = searchHits.getHits();// 4.3 遍历List<HotelDoc>hotelDocList = new ArrayList<>();for (SearchHit hit : hits) {// 转换为JsonString json = hit.getSourceAsString();// 转换为java对象HotelDoc hotelDoc = JSONObject.parseObject(json, HotelDoc.class);// 保存在集合中hotelDocList.add(hotelDoc);}System.out.println(hotelDocList);
}
查询的基本步骤是:
- 创建SearchRequest对象
- 准备Request.source(),也就是DSL。
- QueryBuilders来构建查询条件
- 传入Request.source() 的 query() 方法
- 发送请求,得到结果
- 解析结果(参考JSON结果,从外到内,逐层解析)
2.构建查询条件,只要记住一个类:QueryBuilders
①全文检索查询(分词,模糊查询)
单字段:QueryBuilders.matchQuery(字段名,值)
多字段:QueryBuilders.multiMatchQuery(值, 字段1,字段2);
演示:酒店名字带有“如家“的有哪些?

request.source().query(QueryBuilders.termQuery("name","如家"));②精确查询,不分词
精确查询常见的有term查询和range查询

③复合查询boolean query
查询品牌为如家,价格在200元内的酒店
// 创建bool查询
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 添加must条件
boolQuery.must(QueryBuilders.termQuery("brand","如家"));
// 添加filter条件
boolQuery.filter(QueryBuilders.rangeQuery("price").lte(200));
request.source().query(boolQuery);
3.分页和排序
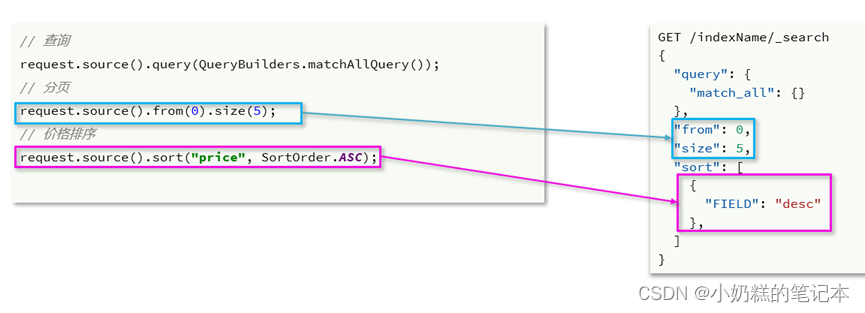
演示:查询名为“如家“的酒店,查询结果进行价格降序,每页显示3条
// 页码
int page = 1,size=3;
// 2.组织DSL
// 2.1 查询
request.source().query(QueryBuilders.termQuery("name","如家"));
// 2.2 分页 从from序号数size个
request.source().from((page-1)*size).size(size);
// 2.3 价格排序
request.source().sort("price", SortOrder.DESC);
4.高亮
根据name搜索高亮

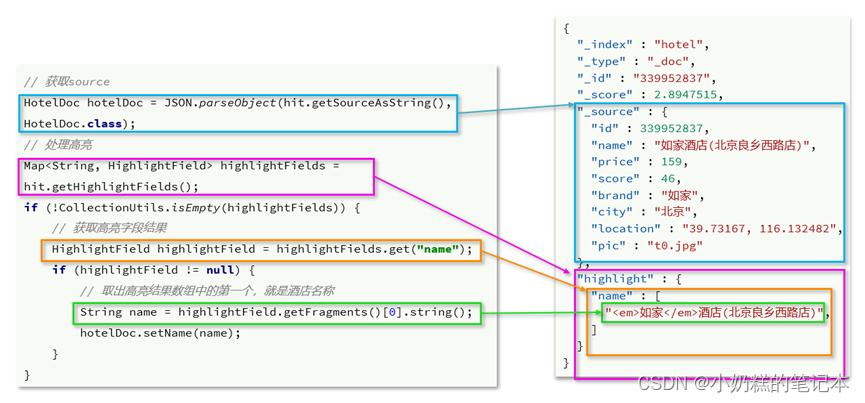
代码
@Test
void testHight() throws IOException{// 1.请求requestSearchRequest request = new SearchRequest("hotel");// 2. 组织DSLrequest.source().query(QueryBuilders.matchQuery("all","如家"));request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));// 3.发送请求,得到响应SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.分析结果SearchHits searchHits = response.getHits();// 5.解析SearchHit[] hitss = searchHits.getHits();// 6.遍历for (SearchHit hit : hitss) {// 转换为jsonString json = hit.getSourceAsString();// 得到对象HotelDoc hotelDoc = JSONObject.parseObject(json, HotelDoc.class);// 获取高亮结果Map<String, HighlightField> highlightFields = hit.getHighlightFields();// 根据字段获取HighlightField highlightField = highlightFields.get("name");// 获取高亮值String name = highlightField.getFragments()[0].string();// 覆盖结果hotelDoc.setName(name);System.out.println(name);}}
四、黑马旅游案例
@Overridepublic PageResult search(RequestParams params) throws IOException {// 1.得到请求参数String key = params.getKey();Integer page = params.getPage();Integer size = params.getSize();String sortBy = params.getSortBy();String brand = params.getBrand();String starName = params.getStarName();String city = params.getCity();Integer minPrice = params.getMinPrice();Integer maxPrice = params.getMaxPrice();String location = params.getLocation();// 2.创建搜索请求SearchRequest request = new SearchRequest(HotelConstants.HOTEL_INDEX);// 3.编写DSL 组合查询boolQueryBoolQueryBuilder boolQuery = QueryBuilders.boolQuery();// 3.1.1 输入框关键字mustif (key != null && !"".equals(key)) { //输入框不为空,模糊查询boolQuery.must(QueryBuilders.matchQuery("all", key));} else {//输入框为空,查询全部boolQuery.must(QueryBuilders.matchAllQuery());}// 3.1.2 城市--filterif (city != null && !"".equals(city)) {boolQuery.filter(QueryBuilders.termQuery("city", city));}// 3.1.3 品牌--filterif (brand != null && !"".equals(brand)) {boolQuery.filter(QueryBuilders.termQuery("brand", brand));}// 3.1.4 星级--filterif (starName != null && !"".equals(starName)) {boolQuery.filter(QueryBuilders.termQuery("starName", starName));}// 3.1.5 价格--filterif (minPrice != null && maxPrice != null) {boolQuery.filter(QueryBuilders.rangeQuery("price").gte(minPrice).lte(maxPrice));}// 3.1.6 查询条件// 3.1.7 =====广告推荐算分查询(查询条件,算分条件)FunctionScoreQueryBuilder functionScoreQuery = QueryBuilders.functionScoreQuery(boolQuery,new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{new FunctionScoreQueryBuilder.FilterFunctionBuilder(QueryBuilders.termQuery("isAD",true),// 算分条件ScoreFunctionBuilders.weightFactorFunction(10) // 算分比例)});request.source().query(functionScoreQuery);// 3.2 页码request.source().from((page - 1) * size).size(size);// 3.3 排序if (location != null && !"".equals(location)) {request.source().sort(SortBuilders.geoDistanceSort("location", new GeoPoint(location)).order(SortOrder.ASC).unit(DistanceUnit.KILOMETERS));}if (!SortConstants.DEFAULT.equals(sortBy)) {request.source().sort(sortBy, SortOrder.DESC);}//4. 发送请求得到响应SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 5.解析响应PageResult pageResult = handleResponse(response);return pageResult;}相关文章:
06_es分布式搜索引擎2
一、DSL查询文档 1.DSL查询分类 ①查询所有:match_all ②全文检索:利用分词器对用户输入的内容分词,倒排索引去匹配 match_query multi_match_query ③精确查询:根据精确词条查找数据,查找的是keyword,数值,日期,b…...

【3D图像分割】基于 Pytorch 的 VNet 3D 图像分割3(3D UNet 模型篇)
在本文中,主要是对3D UNet 进行一个学习和梳理。对于3D UNet 网上的资料和GitHub直接获取的代码很多,不需要自己从0开始。那么本文的目的是啥呢? 本文就是想拆解下其中的结构,看看对于一个3D的UNet,和2D的UNet&#x…...
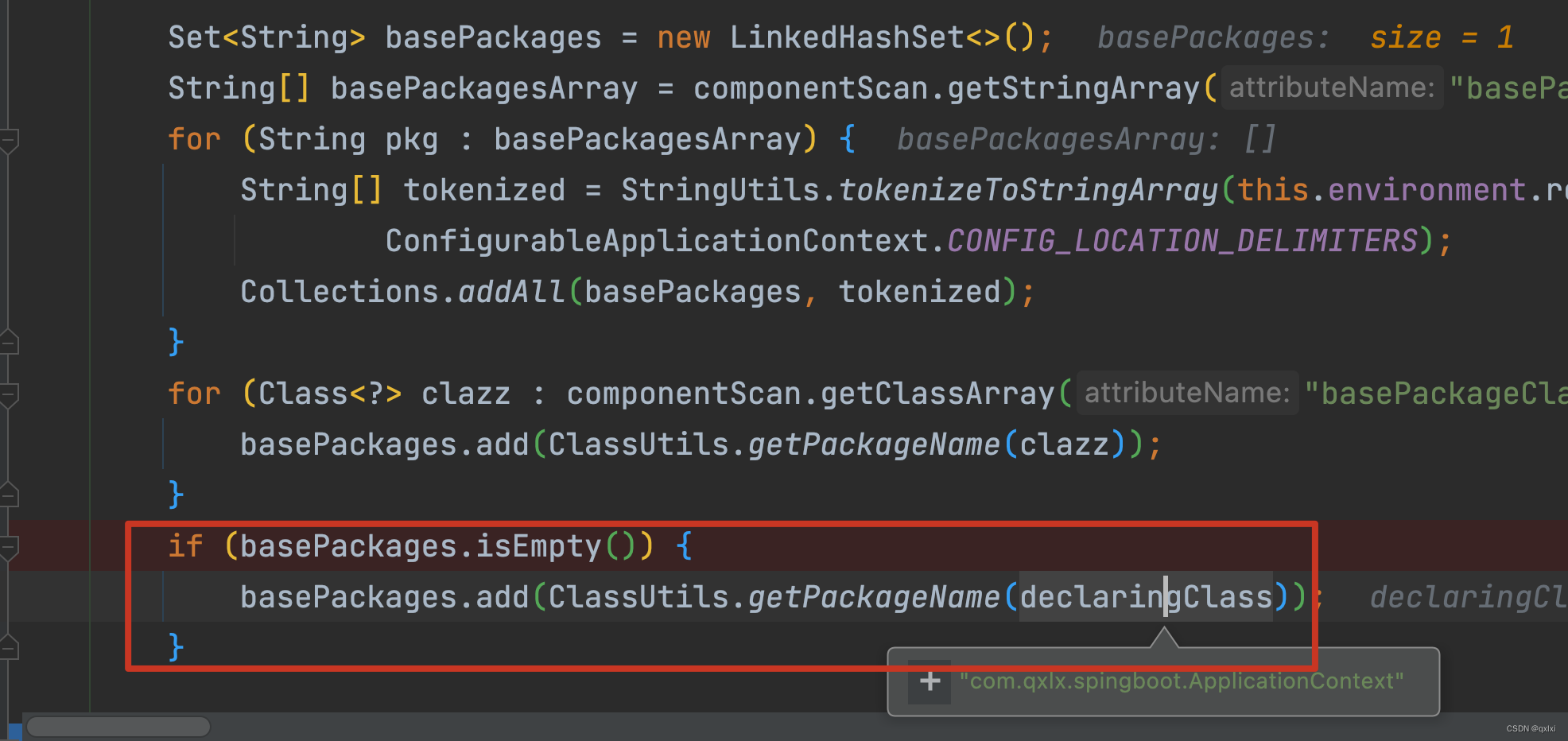
【源码解析】Spring Bean定义常见错误
案例1 隐式扫描不到Bean的定义 RestController public class HelloWorldController {RequestMapping(path "/hiii",method RequestMethod.GET)public String hi() {return "hi hellowrd";}}SpringBootApplication RestController public class Applicati…...

由于找不到vcruntime140.dll无法继续执行代码
在计算机使用过程中,我们可能会遇到一些错误提示,其中之一就是“vcruntime140.dll丢失”。这个错误通常发生在运行某些程序或游戏时,它会导致程序无法正常运行。那么,如何解决vcruntime140.dll丢失的问题呢?本文将介绍…...
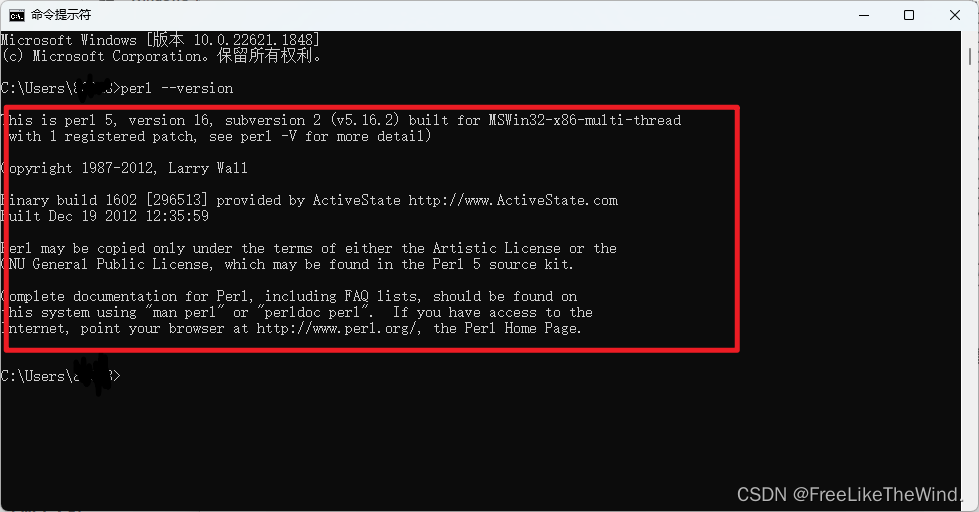
Perl安装教程
1. perl简介 Perl 是 Practical Extraction and Report Language 的缩写,可翻译为 “实用报表提取语言”。Perl 是高级、通用、直译式、动态的程序语言。Perl 最初的设计者为拉里沃尔(Larry Wall),于1987年12月18日发表。Perl 借…...

Docker数据卷使用过程中想到的几个问题
1.已经创建的容器如何挂载数据卷? 答:已经创建的容器我的理解是不能改变改变数据卷挂载的。 但有一种方法可以将数据卷挂载记录到文件里,通过修改文件而改变数据卷挂载,就是通过使用docker compose,这样每次只要修改在…...

Angular 中的路由
1 使用 routerLink 指令 路由跳转 命令创建项目: ng new ng-demo创建需要的组件: ng g component components/home ng g component components/news ng g component components/produect找到 app-routing.module.ts 配置路由: 引入组件: import { Ho…...
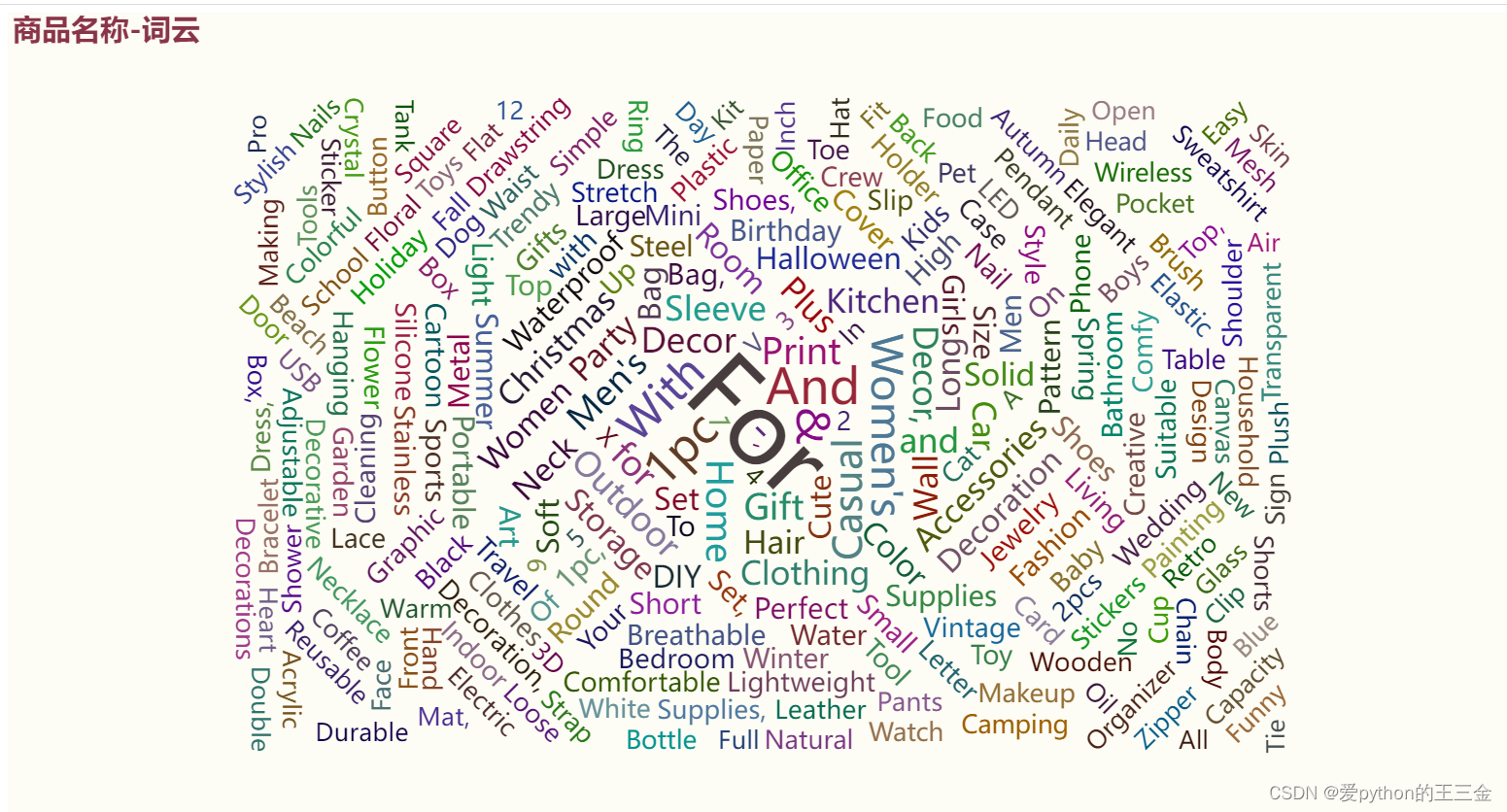
【市场分析】Temu数据采集销售额商品量占比分析数据分析接口Api
引言 temu电商平台是一个充满活力的电商平台,拥有多种商品类别和数万家店铺。在这个项目中我的任务是采集平台上的大量公开数据信息。通过数据采集,我旨在深入了解temu电商平台的产品分布、销售趋势和文本描述,以揭示有趣的见解。 数据采集…...
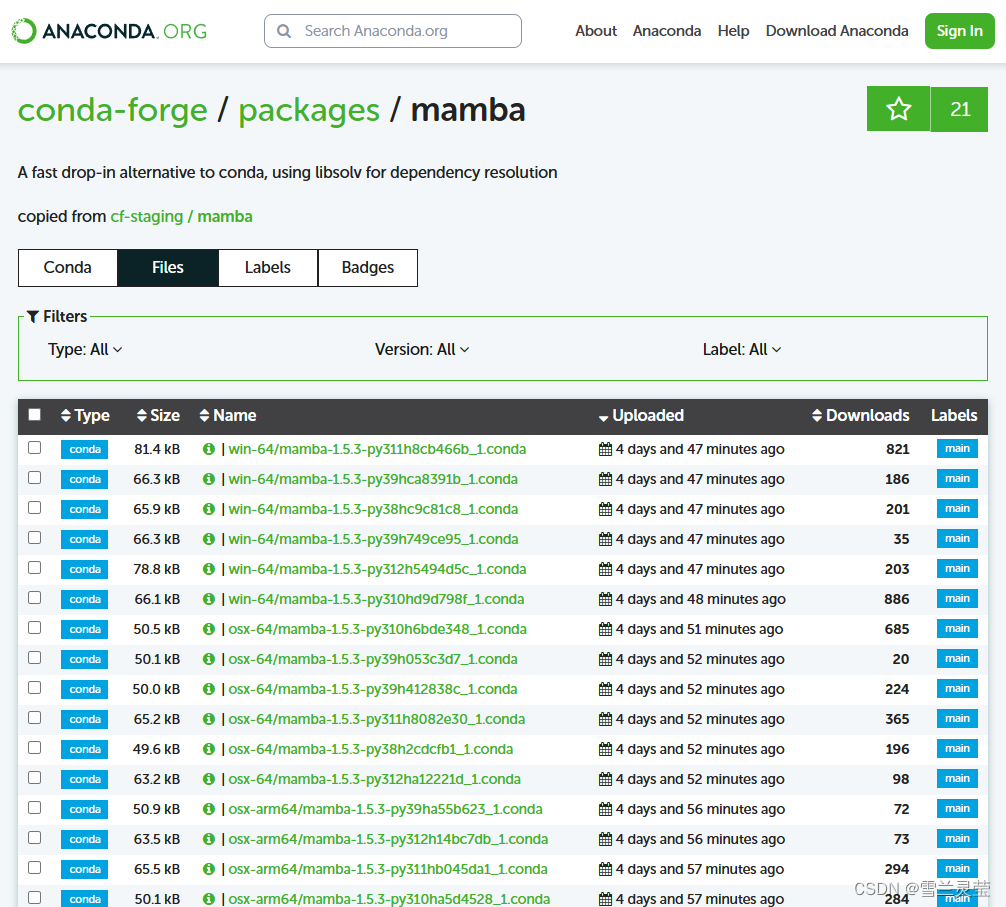
Python笔记——linux/ubuntu下安装mamba,安装bob.learn库
Python笔记——linux/ubuntu下安装mamba,安装bob.learn库 一、安装/卸载anaconda二、安装mamba1. 命令行安装(大坑,不推荐)2. 命令行下载guihub上的安装包并安装(推荐)3. 网站下载安装包并安装(…...

Redis之Java操作Redis的使用
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是君易--鑨,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的博客专栏《Redis实战开发》。🎯🎯 …...
《网络协议》01. 基本概念
title: 《网络协议》01. 基本概念 date: 2022-08-30 09:50:52 updated: 2023-11-05 15:28:52 categories: 学习记录:网络协议 excerpt: 互联网、网络互连模型(OSI,TCP/IP)、计算机通信基础、MAC 地址、ARP & ICMP、IP & 子…...

设置Ubuntu网络代理
设置Ubuntu网络代理 1 编写set_proxy.sh 在/home/xxx新建文件set_proxy.sh,添加如下代码: #!/bin/sh hostip$(cat /etc/resolv.conf | grep nameserver | awk { print $2 }) wslip$(hostname -I | awk {print $1}) port10809PROXY_HTTP"http://$…...

LeetCode----23. 合并 K 个升序链表
题目 给你一个链表数组,每个链表都已经按升序排列。 请你将所有链表合并到一个升序链表中,返回合并后的链表。 示例 1: 输入:lists = [[1,4,5],[1,3,4],[2,6]] 输出:[1,1,2,3,4,4,5,6] 解释:链表数组如下: [ 1->4->5, 1->3->4, 2->6 ] 将它们合并到…...
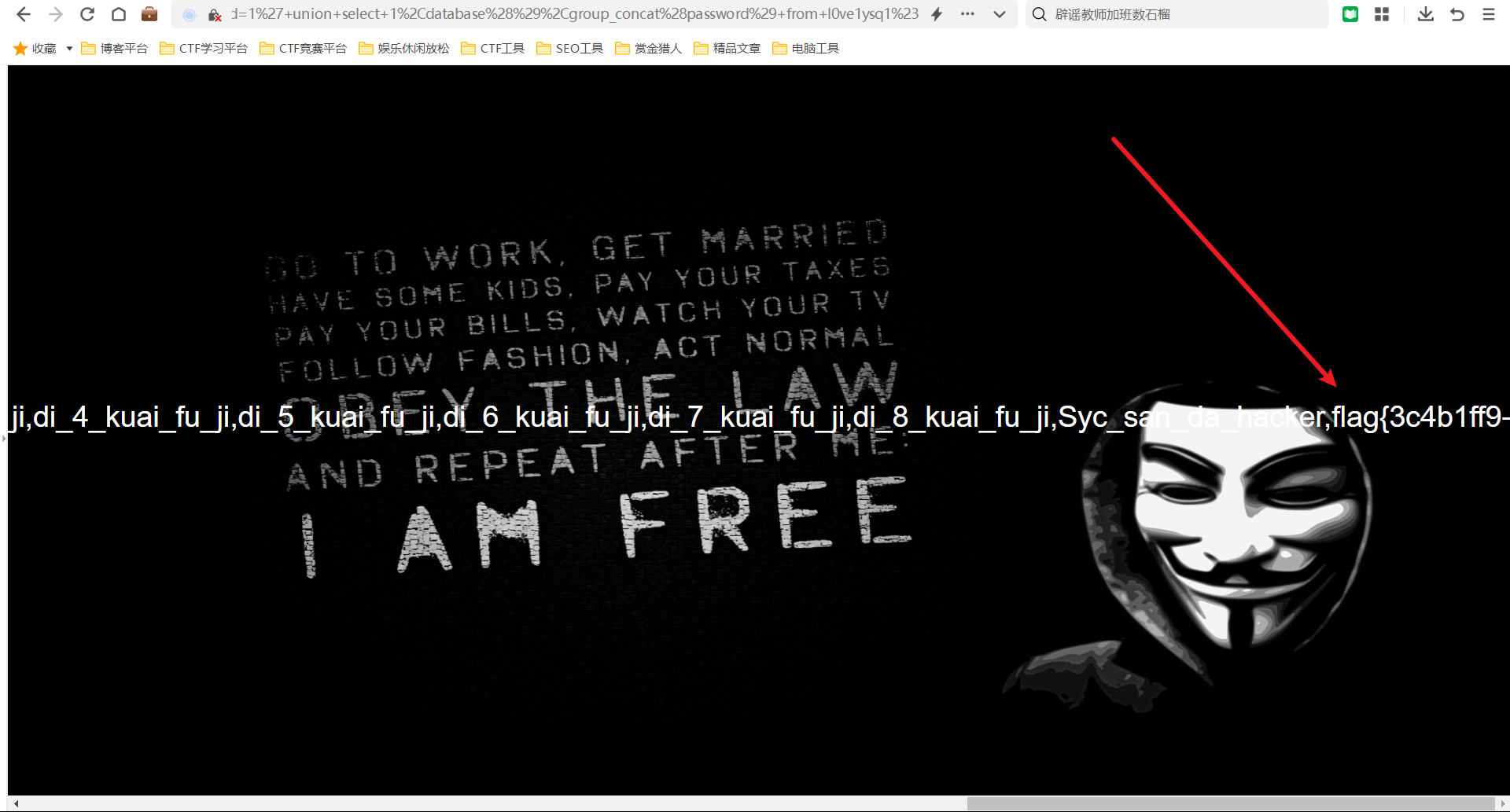
[极客大挑战 2019]LoveSQL 1
题目环境:判断注入类型是否为数字型注入 admin 1 回显结果 否 是否为字符型注入 admin 1 回显结果 是 判断注入手法类型 使用堆叠注入 采用密码参数进行注入 爆数据库1; show database();#回显结果 这里猜测注入语句某字段被过滤,或者是’;被过滤导致不能…...
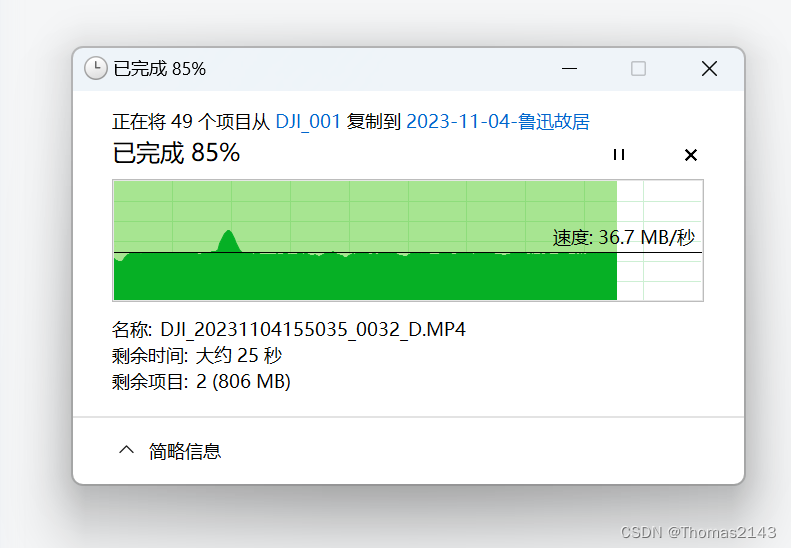
dji mini4pro 图片拷贝到电脑速度
环境 win电脑 amd3600 m.2固态硬盘 dp快充数据线 直接主机使用dp线连接无人机 9成是raw格式图片 一小部分是视频和全景图 TF卡信息: 闪迪 128GB 129元 闪迪 128GB TF(MicroSD) 存储卡U3 C10 V30 A2 4K 至尊超极速移动版 "TF卡至尊超极速" 理论读取200MB/s …...

基于深度学习的目标检测算法 计算机竞赛
文章目录 1 简介2 目标检测概念3 目标分类、定位、检测示例4 传统目标检测5 两类目标检测算法5.1 相关研究5.1.1 选择性搜索5.1.2 OverFeat 5.2 基于区域提名的方法5.2.1 R-CNN5.2.2 SPP-net5.2.3 Fast R-CNN 5.3 端到端的方法YOLOSSD 6 人体检测结果7 最后 1 简介 ǵ…...
前端面试题之CSS篇
1、css选择器及其优先级 标签选择器: 1类选择器、属性选择器、伪类选择器:10id选择器:100内联选择器(style“”):1000!important:10000 2、display的属性值及其作用 属性值作用none元素不显示,…...

【SQL相关实操记录】
一. 两张表的联合查询 task表中含 id(任务的序列号), action(任务内容), owner(任务分配的对象), target_date(目标完成日期), status(任务的完成状态),mmid(对应meeting的序列号--表示在该meeting中所对应布置的任务). meeting表中含id(meeting的序列号), status(meeting记…...
Python爬虫实战-批量爬取下载网易云音乐
大家好,我是python222小锋老师。前段时间卷了一套 Python3零基础7天入门实战https://blog.csdn.net/caoli201314/article/details/1328828131小时掌握Python操作Mysql数据库之pymysql模块技术https://blog.csdn.net/caoli201314/article/details/133199207一天掌握p…...

LeetCode 面试题 16.14. 最佳直线
文章目录 一、题目二、C# 题解 一、题目 给定一个二维平面及平面上的 N 个点列表 Points,其中第 i 个点的坐标为 Points[i][Xi,Yi]。请找出一条直线,其通过的点的数目最多。 设穿过最多点的直线所穿过的全部点编号从小到大排序的列表为 S,你仅…...

2026行李箱推荐别乱买!唯尊、海澜之家、森马、外交官、珉璐保罗五款横评
对于技术从业者而言,行李箱不仅是装载衣物的容器,更是保护精密电子设备、应对高频差旅与跨城迁移的可靠装备。无论是前往异地调试系统、参加技术峰会,还是举家搬迁,一个设计合理、性能可靠的行李箱能显著提升出行效率与体验。本文…...

Win11Debloat系统优化工具使用指南
Win11Debloat系统优化工具使用指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and customize your Windows experien…...

【新手必看】鼎利测试软件Pilot Pioneer-② 工具栏与菜单栏功能详解
1. Pilot Pioneer工具栏全解析 刚接触鼎利测试软件Pilot Pioneer时,最让我头疼的就是密密麻麻的工具栏图标。但用久了才发现,这些看似复杂的按钮其实是提升效率的"快捷键"。先说说最上方的自定义快速访问工具栏,这个区域就像手机桌…...

AI的恶意使用
AI 生成的内容与犯罪活动:人工智能系统正被滥用于生成诈骗、欺诈、敲诈勒索及未经同意的私密影像。尽管此类伤害的发生已有充分记录,但关于其发生率和严重程度的系统性数据仍然有限。 影响和操纵:在实验环境中,AI 生成的内容在改变…...

企业内部培训,适合用教学云桌面吗?
企业内部培训常面临环境部署繁琐、运维压力大、设备资源固化、数据安全难控等问题,教学云桌面凭借集中化管理与弹性资源配置,成为不少企业的选型方向。结合实际应用与技术特性来看,教学云桌面适配企业培训场景,且能系统性解决传统…...

FXGL:JavaFX游戏开发的现代化架构实践
FXGL:JavaFX游戏开发的现代化架构实践 【免费下载链接】FXGL Java / JavaFX / Kotlin Game Library (Engine) 项目地址: https://gitcode.com/gh_mirrors/fx/FXGL FXGL是一个基于JavaFX构建的现代化游戏开发框架,为Java开发者提供了完整的游戏开发…...

使用 Dify 快速搭建 Ostrakon-VL 智能应用:无需编码的视觉工作流
使用 Dify 快速搭建 Ostrakon-VL 智能应用:无需编码的视觉工作流 1. 引言:当视觉理解遇上无代码开发 想象一下,你是一家电商公司的运营人员,每天需要处理上千张商品图片——识别商品类别、提取关键属性、整理成表格。传统方式要…...

利用codex与快马平台,十分钟快速生成待办事项应用原型
最近在尝试快速验证一个待办事项应用的想法,发现用InsCode(快马)平台配合AI模型真的能十分钟就搞出可运行的原型。整个过程特别适合像我这样想快速验证产品概念的人,记录下具体操作和思考过程。 明确核心功能需求 首先梳理出最简功能清单:输入…...

窗口像素重构技术:重新定义显示分辨率控制范式
窗口像素重构技术:重新定义显示分辨率控制范式 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 问题溯源:窗口分辨率控制的行业痛点解析 在数字内容创作与专业显示领域,窗口分…...

Omni-Vision Sanctuary 算法优化:LSTM时序网络在视频分析中的应用
Omni-Vision Sanctuary 算法优化:LSTM时序网络在视频分析中的应用 1. 引言:视频分析中的时序挑战 视频数据与静态图像最大的区别在于时间维度。传统计算机视觉方法在处理连续帧时,往往将每一帧视为独立图像进行分析,忽略了帧与帧…...