Docker Stack部署应用详解+Tomcat项目部署详细实战
Docker Stack 部署应用
概述
单机模式下,可以使用 Docker Compose 来编排多个服务。Docker Swarm 只能实现对单个服务的简单部署。而Docker Stack 只需对已有的 docker-compose.yml 配置文件稍加改造就可以完成 Docker 集群环境下的多服务编排。
stack是一组共享依赖,可以被编排并具备扩展能力的关联service。
Docker Stack和Docker Compose区别
- Docker stack 会忽略了“构建”指令,无法使用 stack 命令构建新镜像,它是需要镜像是预先已经构建好的。 所以 docker-compose 更适合于开发场景;
- Docker Compose 是一个 Python 项目,在内部,它使用 Docker API 规范来操作容器。所以需要安装 Docker -compose,以便与 Docker 一起在计算机上使用;Docker Stack 功能包含在 Docker 引擎中。你不需要安装额外的包来使用它,docker stacks 只是 swarm mode 的一部分。
- Docker stack 不支持基于第2版写的 docker-compose.yml ,也就是 version 版本至少为3。然而 Docker Compose 对版本为2和 3 的文件仍然可以处理;
- docker stack 把 docker compose 的所有工作都做完了,因此 docker stack 将占主导地位。
- 单机模式(Docker Compose)是一台主机上运行多个容器,每个容器单独提供服务;集群模式(swarm + stack)是多台机器组成一个集群,多个容器一起提供同一个服务;
compose.yml deploy 配置说明
docker stack deploy 不支持的参数:
(这些参数,就算yaml中包含,在stack的时候也会被忽略,当然也可以为了 docker-compose up 留着这些配置)
build
cgroup_parent
container_name
devices
tmpfs
external_links
links
network_mode
restart
security_opt
userns_mode
deploy:指定与服务的部署和运行有关的配置。注:只在 swarm 模式和 stack 部署下才会有用。且仅支持 V3.4 及更高版本。
可以选参数:
-
endpoint_mode:访问集群服务的方式。3.2版本开始引入的配置。用于指定服务发现,以方便外部的客户端连接到swarm
-
vip:默认的方案。即通过 Docker 集群服务一个对外的虚拟 ip对外暴露服务,所有的请求都会通过这个虚拟 ip 到达集群服务内部的机器,客户端无法察觉有多少个节点提供服务,也不知道实际提供服务的IP和端口。
-
dnsrr:DNS的轮询调度。所有的请求会自动轮询获取到集群 ip 列表中的一个 ip 地址。客户端访问的时候,Docker集群会通过DNS列表返回对应的服务一系列IP地址,客户连接其中的一个。这种方式通常用于使用自己的负载均衡器,或者window和linux的混合应用。
-
labels:在服务上设置标签,并非附加在service中的容器上。如果在容器上设置标签,则在deploy之外定义labels。可以用容器上的 labels(跟 deploy 同级的配置) 覆盖 deploy 下的 labels。
-
mode:用于指定是以副本模式(默认)启动还是全局模式
-
replicated:副本模式,复制指定服务到集群的机器上。默认。
-
global:全局模式,服务将部署至集群的每个节点。类似于k8s中的DaemonSet,会在每个节点上启动且只启动一个服务。
-
replicas:用于指定副本数,只有mode为副本模式的时候生效。
-
placement:主要用于指定约束和偏好。这个参数在运维的时候尤为关键
-
constraints(约束):表示服务可以部署在符合约束条件的节点上,包含了:
-
node attribute matches example
Home | NODE.ID 节点id Home | NODE.ID == 2ivku8v2gvtg4
-
node.hostname 节点主机名 node.hostname != node-2
-
node.role 节点角色 (manager/worker node.role == manager
-
node.platform.os 节点操作系统 node.platform.os == windows
-
node.platform.arch 节点架构 node.platform.arch == x86_64
-
node.labels 用户定义的labels node.labels.security == high
-
engine.labels Docker 引擎的 labels engine.labels.operatingsystem == ubuntu-14.04
-
preferences(偏好):表示服务可以均匀分布在指定的标签下。
preferences 只有一个参数,就是spread,其参数值为节点的属性,即约束表中的内容
-例如:node.labels.zone这个标签在集群中有三个值,分别为west、east、north,那么服务中的副本将会等分为三份,分布到带有三个标签的节点上。
- max_replicas_per_node:3.8版本中开始引入的配置。控制每个节点上最多的副本数。
注意:当 最大副本数*集群中可部署服务的节点数<副本数,会报错
- resources:用于限制服务的资源,这个参数在运维的时候尤为关键。
示例:配置 redis 集群运行需要的 cpu 的百分比 和 内存的占用。避免占用资源过高出现异常。
- limit:用于限制最大的资源使用数量
cpus:cpu占比,值的格式为百分比的小数格式
memory:内存的大小。示例:512M
- reservation:为最低的资源占用量。
cpus
memory
- restart_policy:容器的重启策略
condition:重启的条件。可选 none,on-failure 或者 any。默认值:any
delay:尝试重启的时间间隔(默认值:5s)。
max_attempts:最大尝试重启容器的次数,超出次数,则不再尝试(默认值:一直重试)。
window:判断重启是否成功之前的等待时间(一个总的时间,如果超过这个时间还没有成功,则不再重启)。
- rollback_config:更新失败时的回滚服务的策略。3.7版本加入。和升级策略相关参数基本一致。
- update_config:配置应如何更新服务,对于配置滚动更新很有用。
parallelism:同时升级[回滚]的容器数
delay:升级[回滚]一组容器的时间间隔
failure_action:若更新[回滚]失败之后的策略:continue、 pause、rollback(仅在update_config中有) 。默认 pause
monitor:容器升级[回滚]之后,检测失败的时间检测 (支持的单位:ns|us|ms|s|m|h)。默认为 5s
max_failure_ratio:最大失败率
order:升级[回滚]期间的操作顺序。可选:stop-first(串行回滚,先停止旧的)、start-first(并行回滚,先启动新的)。默认 stop-first 。注意:只支持v3.4及更高版本
tomcat+mysql项目实现docker stack的编排方式
实验环境:
主机 ip 系统 角色 工作容器
server153 192.168.121.153 centos7 manager tomcat
server154 192.168.121.153 centos7 worker tomcat
server155 192.168.121.153 centos7 worker mysql
首先准备好三台docker主机,也是要创建以和swarm集群,这里我就不再赘述了,我的上一篇博文介绍的很清楚,忘记了可以去看一看,docker的安装也包括在内了
每台机器都拉取同样的tomcat镜像
docker pull oxnme/tomcat
docker pull mysql:5.7
然后创建一个空目录开始编写compose.yml文件,跟docker compose差不多的,都是yaml文件
我们想要定制的内容都是在里面写好就行了
[root@server153 ~]# mkdir test
[root@server153 ~]# cd test/
[root@server153 test]# vim compose.yml
[root@server153 test]# cat compose.yml
version: "3.8"
services:mysql: image: mysql:5.7volumes:- type: volumesource: mysql-datatarget: /var/lib/mysql#指定网络networks:- net-test#在启动容器时初始化密码,还有创建一个Zrlog数据environment:- MYSQL_ROOT_PASSWORD=MySQL@666- MYSQL_DATABASE=Zrlogdeploy:#复制策略mode: replicated#创建docker容器数量replicas: 1# 容器内部的服务端口映射到VIPendpoint_mode: vipplacement:#约束条件,只有主机名为server155时才生效constraints:- "node.Hostname == server155"#容器重启策略restart_policy:condition: anytomcat:image: oxnme/tomcat:latest#将8080端口映射到主机的80端口上ports:- 80:8080volumes:- type: volumesource: tomcat-datatarget: /usr/local/tomcat/webapps#指定网络networks:- net-test#同上deploy:mode: replicatedreplicas: 1endpoint_mode: vipplacement:constraints:- "node.Hostname != server155"restart_policy:condition: any#依赖条件,只有在mysql容器存在的时候才生效depends_on:- mysql
volumes:#由docker自己创建一个空的数据卷mysql-data:#我们自己创建数据卷,不用docker帮创建tomcat-data:external: true
#由docker创建一个新的网络
networks:net-test:driver: overlay
写完compose.yaml文件以后就可以开始配置我们需要自己实现的内容了
先创建tomcat-data数据卷,你要在哪个节点布置tomcat容器就在哪个节点都要创建,我这里是打算155节点只放mysql容器,所以就不创建155的了
创建以后将项目代码放进去就好了,也可以通过远程挂载的方式挂载同一个目录数据
如果没有创建docker就会帮我们创建一个空的数据卷,那显然不是我们要的
因为我们要事先准好数据卷和项目,docker只能帮我们创建的空的数据卷
下面这两步是在153和154节点都要做的
[root@server153 test]# docker volume create tomcat-data
tomcat-data
[root@server153 test]# ls /var/lib/docker/volumes/
backingFsBlockDev metadata.db tomcat-data
将tomcat项目代码的war包改名为ROOT.war放到刚创建的数据卷目录下
[root@server153 test]# cp ~/zrlog-2.2.1-efbe9f9-release.war /var/lib/docker/
volumes/tomcat-data/_data/ROOT.war
[root@server153 test]# ls /var/lib/docker/volumes/tomcat-data/_data/
ROOT.war
然后就可以docker stack 启动我们的容器了
[root@server153 test]# docker stack deploy --compose-file compose.yml zrlog
Creating network zrlog_net-test
Creating service zrlog_mysql
Creating service zrlog_tomcat
创建好以后查看容器启动情况,要看tomcat容器启动在哪个节点
[root@server153 test]# docker stack ps zrlog
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
h2a1y9djbaz2 zrlog_mysql.1 mysql:5.7 server155 Running Running 48 seconds ago
hw3s50anymvy zrlog_tomcat.1 oxnme/tomcat:latest server153 Running Running 52 seconds ago
然后去浏览器访问192.168.121.153

第一次访问需要连接数据库创建信息,所以会自动跳到安装页面
这时候就填写mysql容器创建好的数据库和密码了
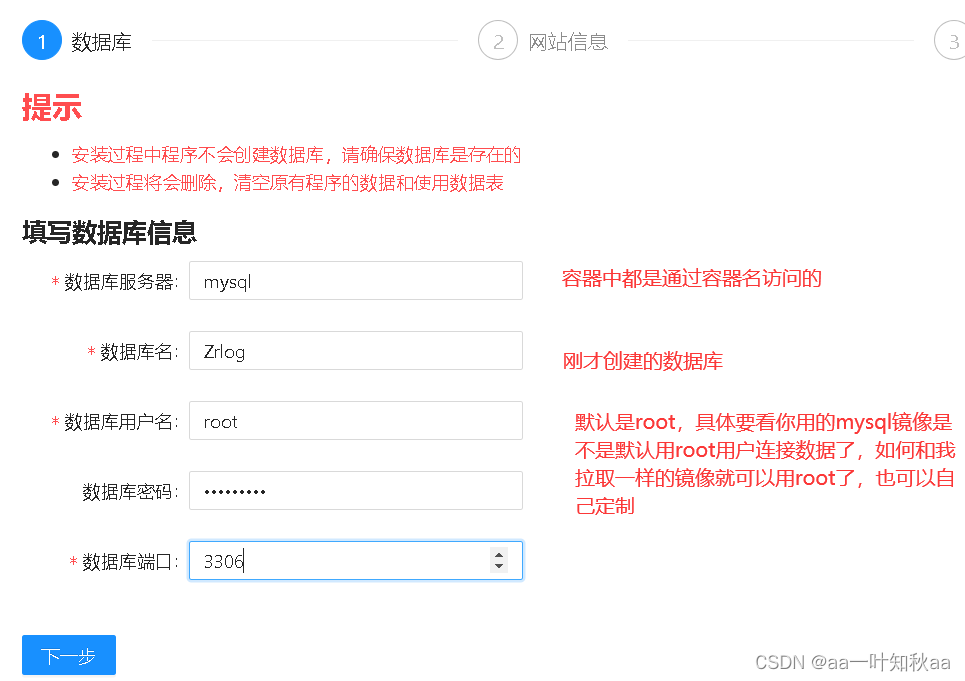
进入下一步随便填
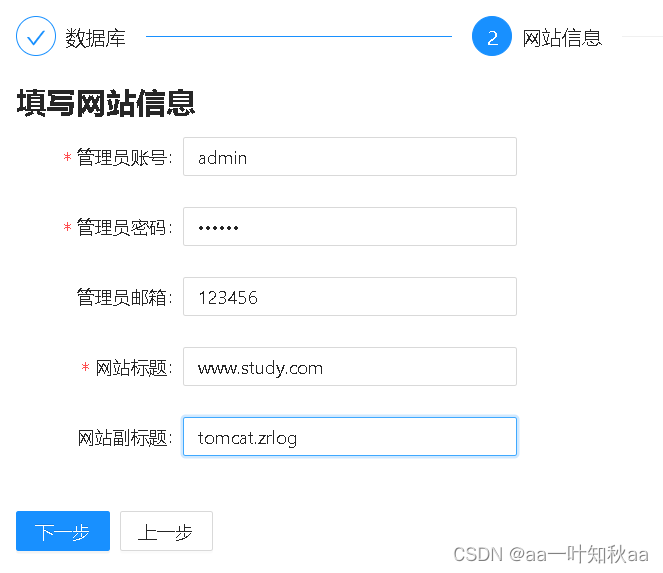
下一步安装好以后就可以直接访问了
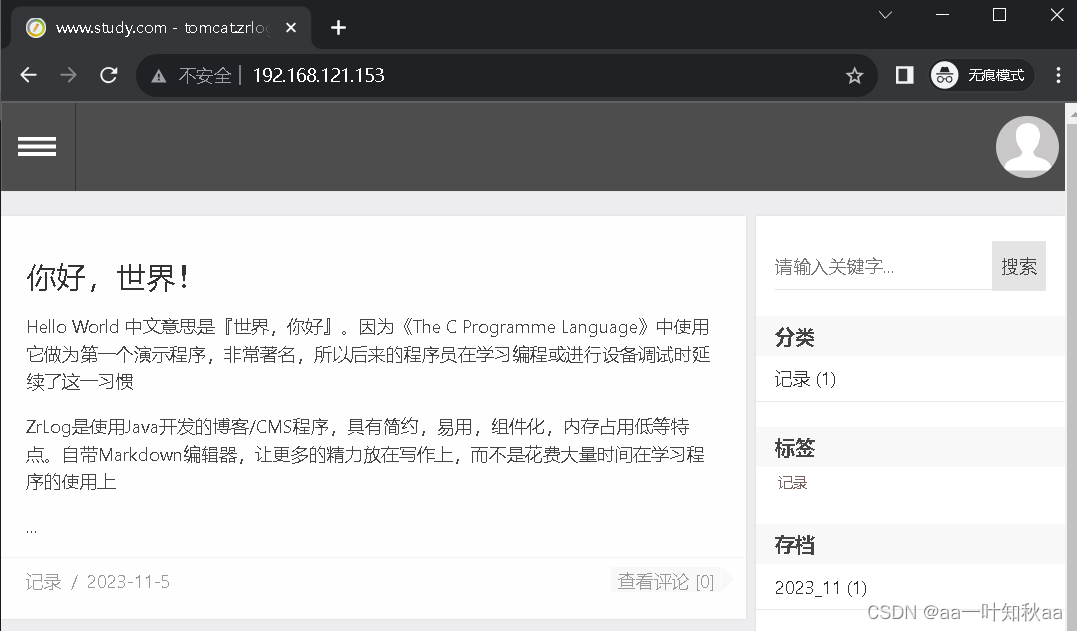
然后用docker stack实现tomcat项目的部署到这里就完成了
然后也试一下容器的动态拉伸
[root@server153 test]# docker service scale zrlog_tomcat=3
zrlog_tomcat scaled to 3
overall progress: 3 out of 3 tasks
1/3: running
2/3: running
3/3: running
verify: Service converged
[root@server153 test]# docker stack ps zrlog
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
h2a1y9djbaz2 zrlog_mysql.1 mysql:5.7 server155 Running Running 15 minutes ago
hw3s50anymvy zrlog_tomcat.1 oxnme/tomcat:latest server153 Running Running 15 minutes ago
rlhd2lfc70dp zrlog_tomcat.2 oxnme/tomcat:latest server154 Running Running 2 minutes ago
30md1m5jcha5 zrlog_tomcat.3 oxnme/tomcat:latest server154 Running Running 2 minutes ago
可以看到也是可以的,因为原理都是一样的,如果有数据一致性的问题,可以用rsync解决
只要清楚了docker的原理解决起来就容易了
主要的还是理解,这样应对不同的项目就可以完美解决了
文章的部分内容是在网上找的,如有侵权请告知删除
相关文章:
Docker Stack部署应用详解+Tomcat项目部署详细实战
Docker Stack 部署应用 概述 单机模式下,可以使用 Docker Compose 来编排多个服务。Docker Swarm 只能实现对单个服务的简单部署。而Docker Stack 只需对已有的 docker-compose.yml 配置文件稍加改造就可以完成 Docker 集群环境下的多服务编排。 stack是一组共享…...

Compose-Multiplatform在Android和iOS上的实践
本文字数:4680字 预计阅读时间:30分钟 01 简介 之前我们探讨过KMM,即Kotlin Multiplatform Mobile,是Kotlin发布的移动端跨平台框架。当时的结论是KMM提倡将共有的逻辑部分抽出,由KMM封装成Android(Kotlin/JVM)的aar和…...

XXL-JOB 默认 accessToken 身份绕过导致 RCE
文章目录 0x01 漏洞介绍0x02 影响版本0x03 环境搭建0x04 漏洞复现第一步 访问页面返回报错信息第二步 执行POC,进行反弹shell第三步 获取shell0x05 修复建议摘抄免责声明0x01 漏洞介绍 XXL-JOB 是一款开源的分布式任务调度平台,用于实现大规模任务的调度和执行。 XXL-JOB 默…...
所有函数的介绍及使用)
7 库函数之复位和时钟设置(RCC)所有函数的介绍及使用
7 库函数之复位和时钟设置(RCC)所有函数的介绍及使用的介绍及使用 1. 图片有格式二、RCC库函数固件库函数预览2.1 函数RCC_DeInit2.2 函数RCC_HSEConfig2.3 函数RCC_WaitForHSEStartUp2.4 函数RCC_AdjustHSICalibrationValue2.5 函数RCC_HSICmd2.6 函数RCC_PLLConfig2.7 函数…...

第十七节——指令
一、概念 在Vue.js中,指令(Directives)是一种特殊的语法,用于为HTML元素添加特定的行为和功能。指令以v-作为前缀,通过在HTML标签中使用这些指令来操作DOM,修改元素的属性、样式或行为。 Vue.js提供了一组…...

优雅的 Dockerfile 是怎样炼成的?
Docker 简介 目前,Docker 主要有两个形态:Docker Desktop 和 Docker Engine。 Docker Desktop 是专门针对个人使用而设计的,支持 Mac(已支持arm架构的M系芯片) 和 Windows 快速安装,具有直观的图形界面&a…...

2023-2024 中国科学引文数据库来源期刊列表(CSCD)
文章目录 CSCD来源期刊遴选报告2023-2024 中国科学引文数据库来源期刊列表(CSCD) CSCD来源期刊遴选报告 2023-2024 中国科学引文数据库来源期刊列表(CSCD)...

【3D图像分割】基于Pytorch的VNet 3D图像分割5(改写数据流篇)
在这篇文章:【3D 图像分割】基于 Pytorch 的 VNet 3D 图像分割2(基础数据流篇) 的最后,我们提到了: 在采用vent模型进行3d数据的分割训练任务中,输入大小是16*96*96,这个的裁剪是放到Dataset类…...
WebSocket Day02 : 握手连接
前言 握手连接是WebSocket建立通信的第一步,通过客户端和服务器之间的一系列握手操作,确保了双方都支持WebSocket协议,并达成一致的通信参数。握手连接的过程包括客户端发起握手请求、服务器响应握手请求以及双方完成握手连接。完成握手连接后…...

c#的反编译工具ISPY和net reflector 使用比较
我有一份Asp.net程序需要修改,但没有源码,只有dll,需要使用反编译工具回复源码,尝试使用了市面上的两种主流的工具ISPY和net reflector ,最终用ISPY恢复了源码。 比较 ISPY 恢复的代码和实际有差距,但还能…...
基于LDA主题+协同过滤+矩阵分解算法的智能电影推荐系统——机器学习算法应用(含python、JavaScript工程源码)+MovieLens数据集(四)
目录 前言总体设计系统整体结构图系统流程图 运行环境模块实现1. 数据爬取及处理2. 模型训练及保存3. 接口实现4. 收集数据5. 界面设计 系统测试相关其它博客工程源代码下载其它资料下载 前言 前段时间,博主分享过关于一篇使用协同过滤算法进行智能电影推荐系统的博…...

方阵行列式与转置矩阵
1.转置矩阵:格式规定:如果矩阵A为n阶方阵,那么A的T次方为矩阵A的转置矩阵,即将矩阵A的行与列互换。 2.转置矩阵的运算性质: 1.任何方阵的转置矩阵的转置矩阵为方阵自身。 2.多个矩阵的和的转置矩阵等于多个转置矩阵的…...

【Java 进阶篇】Java Cookie共享:让数据穿越不同应用的时空隧道
在Web开发中,Cookie是一种常见的会话管理技术,用于存储和传递用户相关的信息。通常,每个Web应用都会在用户的浏览器中设置自己的Cookie,以便在用户与应用之间保持状态。然而,有时我们需要在不同的应用之间共享Cookie数…...
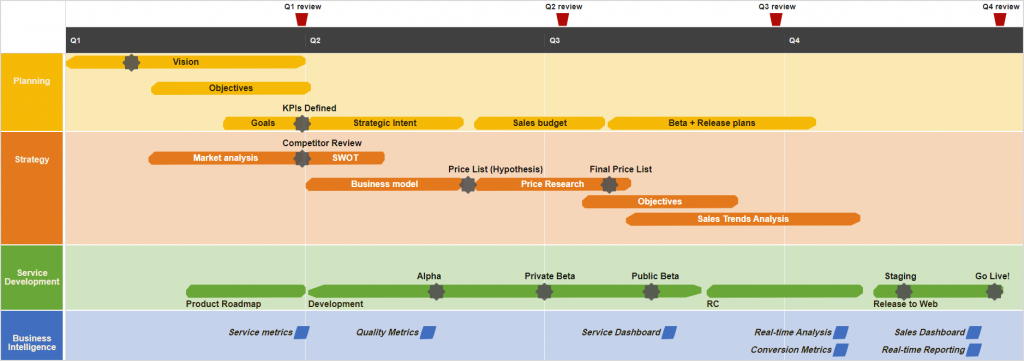
甘特图组件DHTMLX Gantt用例 - 如何拆分任务和里程碑项目路线图
创建一致且引人注意的视觉样式是任何项目管理应用程序的重要要求,这就是为什么我们会在这个系列中继续探索DHTMLX Gantt图库的自定义。在本文中我们将考虑一个新的甘特图定制场景,DHTMLX Gantt组件如何创建一个项目路线图。 DHTMLX Gantt正式版下载 用…...

克里金插值matlab代码
% 克里金插值示例 clc; clear; % 生成模拟数据 x linspace(0, 10, 11); y linspace(0, 10, 11); [X, Y] meshgrid(x, y); Z sin(sqrt(X.^2 Y.^2)) 0.1 * randn(size(X)); % 设置克里金参数 nugget 0.1; % 块金值 range 1; % 范围 sill 1; % 基台值 azimuth …...
【LeetCode】23. 合并 K 个升序链表
题目链接:23. 合并 K 个升序链表 题目描述: 数据范围: **思考:**这题实际上就是合并两个有序列表的进阶版,只不过这里变成了合并K个,那么这里我们显然就知道,核心的合并两个有序列表的思路不…...

2023年【熔化焊接与热切割】免费试题及熔化焊接与热切割考试总结
题库来源:安全生产模拟考试一点通公众号小程序 熔化焊接与热切割免费试题参考答案及熔化焊接与热切割考试试题解析是安全生产模拟考试一点通题库老师及熔化焊接与热切割操作证已考过的学员汇总,相对有效帮助熔化焊接与热切割考试总结学员顺利通过考试。…...
为什么要学中文编程?它能有哪些益处?免费版编程工具怎么下载?系统化的编程教程课程怎么学习
一、为什么要学习这个编程工具?能给自己带来什么益处? 1、不论在哪里上班,都不是铁饭碗:现在全球经济低迷,使得很多企业倒闭, 大到知名国企小到私营企业,大量裁员。任何人都无法保证自己现在的…...
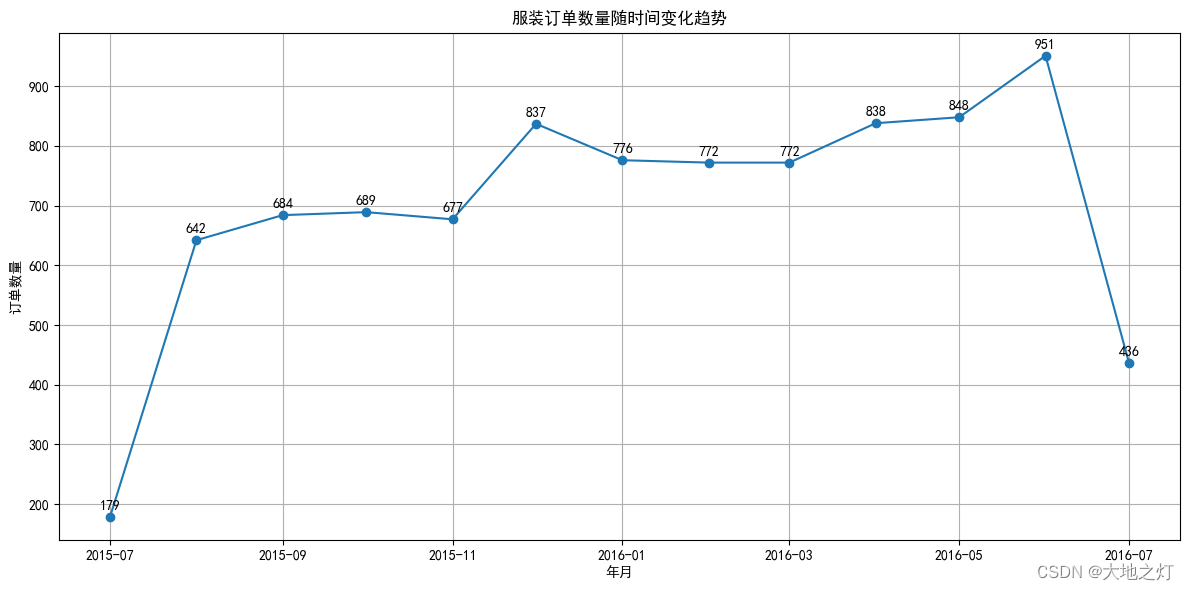
数据分析实战 - 2 订单销售数据分析(pandas 进阶)
题目来源:和鲸社区的题目推荐: 刷题源链接(用于直接fork运行 https://www.heywhale.com/mw/project/6527b5560259478972ea87ed 刷题准备 请依次运行这部分的代码(下方4个代码块),完成刷题前的数据准备 …...
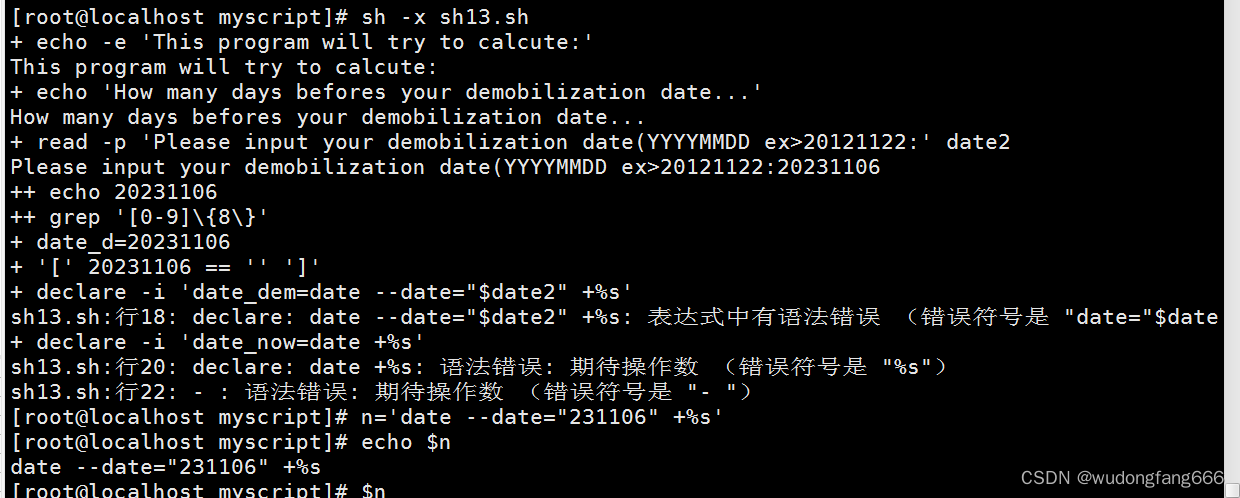
测试服务器端口是否开通,计算退休时间
本案例知识点 netstat -tuln | grep 80 nestat 目前主机打开的网络服务端口,-tuln目前主机启动的服务,如图 报错说参数太多,仔细检查发现if后的中括号内,变量少双引号导致,改完之后运行显示22,25端口开放࿰…...
真实输出)
SenseVoice-small-ONNX效果展示:情感倾向标注(兴奋/平静/急促)真实输出
SenseVoice-small-ONNX效果展示:情感倾向标注(兴奋/平静/急促)真实输出 1. 核心能力概览 SenseVoice-small-ONNX是一个基于ONNX量化的多语言语音识别模型,它不仅能够准确识别语音内容,还能智能分析说话人的情感倾向。…...

Zotero文献去重终极解决方案:从混乱到有序的智能管理指南
Zotero文献去重终极解决方案:从混乱到有序的智能管理指南 【免费下载链接】ZoteroDuplicatesMerger A zotero plugin to automatically merge duplicate items 项目地址: https://gitcode.com/gh_mirrors/zo/ZoteroDuplicatesMerger 如何解决文献库重复危机&…...

Qwen-Image-Edit-F2P结合YOLOv8实现智能人像编辑:目标检测应用案例
Qwen-Image-Edit-F2P结合YOLOv8实现智能人像编辑:目标检测应用案例 你有没有想过,给照片里的人换个发型、加副眼镜,或者换个背景,能有多简单?过去这可能需要专业的设计师,花上不少时间在Photoshop里一点点…...

一键部署GLM-4.6V-Flash-WEB:GitCode镜像真香,省去半天环境搭建时间
一键部署GLM-4.6V-Flash-WEB:GitCode镜像真香,省去半天环境搭建时间 1. 为什么选择GLM-4.6V-Flash-WEB 在多模态大模型快速发展的今天,开发者最头疼的不是模型性能,而是如何快速部署和运行。GLM-4.6V-Flash-WEB作为智谱AI最新开…...

Go 语言实现 RAG 系统:从原理、架构到生产级工程落地
Go 语言实现 RAG 系统:从原理、架构到生产级工程落地 一、为什么要用 Go 做 RAG 工程 RAG(Retrieval-Augmented Generation,检索增强生成)已经成为企业落地大模型最常见、也最务实的一条路线。原因很直接:纯大模型回答虽然能力强,但在企业场景里通常会遇到三类核心问题…...

从命令到思想:Shell脚本编程的“一课一得”
引言在Linux系统学习的旅程中,Shell脚本编程是一个绕不开的重要关卡。在此之前,我们只是在命令行中逐条输入指令,像一个机械的执行者;在此之后,我们开始将自己的思路封装成可复用的逻辑,成为一个真正的设计…...

革命性无代码网站构建器Silex:10分钟创建专业静态网站的完整指南
革命性无代码网站构建器Silex:10分钟创建专业静态网站的完整指南 【免费下载链接】Silex Silex is an online tool for visually creating static sites with dynamic data. With the free/libre spirit of internet, together. 项目地址: https://gitcode.com/gh…...

基于STM32的简易示波器设计与实现
1. 项目概述 这个基于STM32的开源简易示波器项目,是我最近用正点原子精英板完成的一个实用工具开发。作为一个嵌入式开发者,我经常需要观察各种信号波形,但专业示波器价格昂贵且不便携。于是决定自己动手做一个成本低廉、功能实用的简易示波器…...
 一次性安装中文手册的完整命令)
linux (CentOS 7) 一次性安装中文手册的完整命令
一,一次性第一步:安装 CentOS 7 专属的中文语言包 man 手册包yum install -y kde-l10n-Chinese man-pages-zh-CN第二步:刷新语言环境,让配置生效export LANGzh_CN.UTF-8第三步:验证,直接执行中文 man lsma…...

基于OpenCV的航天器自主对接算法原型
南加州大学SURE项目学生开发算法原型,助力航天器对接自动化 作为在新泽西州长大、并在加拿大就读寄宿学校的学生,Derek Chibuzor年少时经常乘坐飞机。这段旅行经历激发了他对飞行的持久兴趣。进入南加州大学后,Chibuzor选择主修航空航天工程。…...