hiveSQL语法及练习题整理(mysql)
目录
hiveSQL练习题整理:
第一题
第二题
第三题
第四题
第五题
第六题
第七题
第八题
第九题
第十题
第十一题
第十二题
hivesql常用函数:
hiveSQL常用操作语句(mysql)
hiveSQL练习题整理:
第一题
我们有如下的用户访问数据userId visitDate visitCountu01 2017/1/21 5u02 2017/1/23 6u03 2017/1/22 8u04 2017/1/20 3u01 2017/1/23 6u01 2017/2/21 8U02 2017/1/23 6U01 2017/2/22 4要求使用SQL统计出每个用户的累积访问次数,如下表所示:用户id 月份 小计 累积u01 2017-01 11 11u01 2017-02 12 23u02 2017-01 12 12u03 2017-01 8 8u04 2017-01 3 3--建表drop table if exists test_one;create table test_one(userId string comment '用户id',visitDate string comment '访问日期',visitCount bigint comment '访问次数') comment '第一题'row format delimited fields terminated by '\t';--插入数据insert into table test_one values('u01','2017/1/21',5);insert into table test_one values('u02','2017/1/23',6);insert into table test_one values('u03','2017/1/22',8);insert into table test_one values('u04','2017/1/20',3);insert into table test_one values('u01','2017/1/23',6);insert into table test_one values('u01','2017/2/21',8);insert into table test_one values('u02','2017/1/23',6);insert into table test_one values('u01','2017/2/22',4);--查询selectuserId `用户id`,visitDate `月份`,sum_mn `小计`,sum(sum_mn) over(partition by userId rows between UNBOUNDED PRECEDING and current row) `累计`from(selectt1.userId,t1.visitDate,sum(t1.visitCount) sum_mnfrom(selectuserId,--date_format(to_date(from_unixtime(UNIX_TIMESTAMP(visitDate,'yyyy/MM/dd'))),'yyyy-MM') visitDate,date_format(regexp_replace(visitdate,"/","-"),'yyyy-MM') visitDate,visitCountfrom test_one) t1group by userId,visitDate) t2;第二题
有50W个京东店铺,每个顾客访客访问任何一个店铺的任何一个商品时都会产生一条访问日志,访问日志存储的表名为Visit,访客的用户id为user_id,被访问的店铺名称为shop,请统计:1)每个店铺的UV(访客数)2)每个店铺访问次数top3的访客信息。输出店铺名称、访客id、访问次数--建表drop table if exists test_two;create table test_two(shoop_name string COMMENT '店铺名称',user_id string COMMENT '用户id',visit_time string COMMENT '访问时间')row format delimited fields terminated by '\t';--插入数据insert into table test_two values ('huawei','1001','2017-02-10');insert into table test_two values ('icbc','1001','2017-02-10');insert into table test_two values ('huawei','1001','2017-02-10');insert into table test_two values ('apple','1001','2017-02-10');insert into table test_two values ('huawei','1001','2017-02-10');insert into table test_two values ('huawei','1002','2017-02-10');insert into table test_two values ('huawei','1002','2017-02-10');insert into table test_two values ('huawei','1001','2017-02-10');insert into table test_two values ('huawei','1003','2017-02-10');insert into table test_two values ('huawei','1004','2017-02-10');insert into table test_two values ('huawei','1005','2017-02-10');insert into table test_two values ('icbc','1002','2017-02-10');insert into table test_two values ('jingdong','1006','2017-02-10');insert into table test_two values ('jingdong','1003','2017-02-10');insert into table test_two values ('jingdong','1002','2017-02-10');insert into table test_two values ('jingdong','1004','2017-02-10');insert into table test_two values ('apple','1001','2017-02-10');insert into table test_two values ('apple','1001','2017-02-10');insert into table test_two values ('apple','1001','2017-02-10');insert into table test_two values ('apple','1002','2017-02-10');insert into table test_two values ('apple','1002','2017-02-10');insert into table test_two values ('apple','1005','2017-02-10');insert into table test_two values ('apple','1005','2017-02-10');insert into table test_two values ('apple','1006','2017-02-10');--1)每个店铺的UV(访客数)selectshoop_name,count(*) shoop_uvfrom test_twogroup by shoop_nameorder by shoop_uv desc;--2)每个店铺访问次数top3的访客信息。输出店铺名称、访客id、访问次数selectshoop_name `商店名称`,user_id `用户id`,visit_time `访问次数`,rank_vis `忠诚排名`from(selectshoop_name,user_id,visit_time,row_number() over(partition by shoop_name order by visit_time desc) rank_visfrom(selectshoop_name,user_id,count(*) visit_timefrom test_twogroup by shoop_name,user_id) t1) t2where rank_vis<=3;第三题
-- 已知一个表STG.ORDER,有如下字段:Date,Order_id,User_id,amount。-- 请给出sql进行统计:数据样例:2017-01-01,10029028,1000003251,33.57。-- 1)给出 2017年每个月的订单数、用户数、总成交金额。-- 2)给出2017年11月的新客数(指在11月才有第一笔订单)drop table if exists test_three_ORDER;create table test_three_ORDER(`Date` String COMMENT '下单时间',`Order_id` String COMMENT '订单ID',`User_id` String COMMENT '用户ID',`amount` decimal(10,2) COMMENT '金额')row format delimited fields terminated by '\t';--插入数据insert into table test_three_ORDER values ('2017-10-01','10029011','1000003251',19.50);insert into table test_three_ORDER values ('2017-10-03','10029012','1000003251',29.50);insert into table test_three_ORDER values ('2017-10-04','10029013','1000003252',39.50);insert into table test_three_ORDER values ('2017-10-05','10029014','1000003253',49.50);insert into table test_three_ORDER values ('2017-11-01','10029021','1000003251',130.50);insert into table test_three_ORDER values ('2017-11-03','10029022','1000003251',230.50);insert into table test_three_ORDER values ('2017-11-04','10029023','1000003252',330.50);insert into table test_three_ORDER values ('2017-11-05','10029024','1000003253',430.50);insert into table test_three_ORDER values ('2017-11-07','10029025','1000003254',530.50);insert into table test_three_ORDER values ('2017-11-15','10029026','1000003255',630.50);insert into table test_three_ORDER values ('2017-12-01','10029027','1000003252',112.50);insert into table test_three_ORDER values ('2017-12-03','10029028','1000003251',212.50);insert into table test_three_ORDER values ('2017-12-04','10029029','1000003253',312.50);insert into table test_three_ORDER values ('2017-12-05','10029030','1000003252',412.50);insert into table test_three_ORDER values ('2017-12-07','10029031','1000003258',512.50);insert into table test_three_ORDER values ('2017-12-15','10029032','1000003255',612.50);-- 1)给出 2017年每个月的订单数、用户数、总成交金额。selectdate_format(`date`,'yyyy-MM') `date`,count(*) `订单数`,count(distinct(user_id)) `用户数`,sum(amount) `总成交金额`from test_three_ORDERgroup by date_format(`date`,'yyyy-MM');-- 2)给出2017年11月的新客数(指在11月才有第一笔订单)selectcount(DISTINCT (t1.user_id))from(selectuser_idfrom test_three_ORDERwhere date_format(`date`,'yyyy-MM') = '2017-11'group by user_id) t1left join(selectuser_idfrom test_three_ORDERwhere date_format(`date`,'yyyy-MM') < '2017-11'group by user_id) t2on t1.user_id = t2.user_idwhere t2.user_id is null;-- 第二种写法selectcount(User_id) `11月新客数`from(SELECTUser_id,Order_id,`Date`,LAG (`DATE`,1,0) over(partition by User_id order by `Date`) preOrderFROMtest_three_ORDER) t1where date_format(`date`,'yyyy-MM')='2017-11' and preOrder=0;第四题
-- 有一个5000万的用户文件(user_id,name,age),一个2亿记录的用户看电影的记录文件(user_id,url),-- 根据年龄段观看电影的次数进行排序?--建表--用户表drop table if exists test_four_log;create table test_four_user(user_id string COMMENT '用户ID',name string COMMENT '用户姓名',age int COMMENT '用户年龄')row format delimited fields terminated by '\t';--日志表drop table if exists test_four_log;create table test_four_log(user_id string COMMENT '用户ID',url string COMMENT '链接')row format delimited fields terminated by '\t';--插入数据insert into table test_four_user values ('1','1',8);insert into table test_four_user values ('2','2',45);insert into table test_four_user values ('3','3',14);insert into table test_four_user values ('4','4',18);insert into table test_four_user values ('5','5',17);insert into table test_four_user values ('6','6',19);insert into table test_four_user values ('7','7',26);insert into table test_four_user values ('8','8',22);insert into table test_four_log values('1','111');insert into table test_four_log values('2','111');insert into table test_four_log values('3','111');insert into table test_four_log values('4','111');insert into table test_four_log values('5','111');insert into table test_four_log values('6','111');insert into table test_four_log values('7','111');insert into table test_four_log values('8','111');insert into table test_four_log values('1','111');insert into table test_four_log values('2','111');insert into table test_four_log values('3','111');insert into table test_four_log values('4','111');insert into table test_four_log values('5','111');insert into table test_four_log values('6','111');insert into table test_four_log values('7','111');insert into table test_four_log values('8','111');insert into table test_four_log values('1','111');insert into table test_four_log values('2','111');insert into table test_four_log values('3','111');insert into table test_four_log values('4','111');insert into table test_four_log values('5','111');insert into table test_four_log values('6','111');insert into table test_four_log values('7','111');insert into table test_four_log values('8','111');-- 根据年龄段观看电影的次数进行排序?selectage_size `年龄段`,count(*) `观影次数`from(selectu.*,l.url,casewhen u.age >=0 and u.age <= 10 then '1-10'when u.age >=11 and u.age <= 20 then '11-20'when u.age >=21 and u.age <= 30 then '21-30'when u.age >=31 and u.age <= 40 then '31-40'when u.age >=41 and u.age <= 50 then '41-50'else '51-100'end age_sizefromtest_four_user u join test_four_log l on u.user_id = l.user_id) t1group by age_sizeorder by `观影次数` desc;第五题
-- 有日志如下,请写出代码求得所有用户和活跃用户的总数及平均年龄。(活跃用户指连续两天都有访问记录的用户)-- 日期 用户 年龄-- 11,test_1,23-- 11,test_2,19-- 11,test_3,39-- 11,test_1,23-- 11,test_3,39-- 11,test_1,23-- 12,test_2,19-- 13,test_1,23create table test_five_active(active_time string COMMENT '活跃日期',user_id string COMMENT '用户id',age int COMMENT '用户年龄')row format delimited fields terminated by '\t';insert into table test_five_active values ('11','test_1',11);insert into table test_five_active values ('11','test_2',22);insert into table test_five_active values ('11','test_3',33);insert into table test_five_active values ('11','test_4',44);insert into table test_five_active values ('12','test_3',33);insert into table test_five_active values ('12','test_5',55);insert into table test_five_active values ('12','test_6',66);insert into table test_five_active values ('13','test_4',44);insert into table test_five_active values ('13','test_5',55);insert into table test_five_active values ('13','test_7',77);-- 所有用户的总数及平均年龄selectcount(*) sum_user,avg(age) avg_agefrom(selectuser_id,avg(age) agefrom test_five_activegroup by user_id) t1;-- 活跃人数的总数及平均年龄select -- 最外一层算出活跃用户的个数以及平均年龄count(*),avg(d.age)from(select -- 最后还需要以user_id分组,去重(防止某个用户在11,12号连续活跃,然后在14,15号又连续活跃,导致diff求出不一致,所以此用户会出现两次)c.user_id,c.agefrom(select -- 以用户和差值diff分组,看分组下的数据的个数是否大于等于2(连续两天登录),取出活跃用户的数据b.user_id,b.age,b.diff,count(*) flagfrom(select -- 用活跃日期减去排名,求出差值,看差值是否相等,相等差值的数据肯定是连续活跃的数据a.active_time,a.user_id,a.age,a.rank_time,a.active_time-a.rank_time difffrom(select -- 以用户和活跃日期分组(去重,防止某个用户在同一天活跃多次),求出每个用户的活跃日期排名active_time,user_id,age,rank() over(partition by user_id order by active_time) rank_timefrom test_five_activegroup by active_time,user_id,age ) a) bgroup by b.user_id,b.age,b.diffhaving count(*) >=2) cgroup by c.user_id,c.age) d;第六题
请用sql写出所有用户中在今年10月份第一次购买商品的金额,表ordertable字段(购买用户:userid,金额:money,购买时间:paymenttime(格式:2017-10-01),订单id:orderid)create table test_six_ordertable(`userid` string COMMENT '购买用户',`money` decimal(10,2) COMMENT '金额',`paymenttime` string COMMENT '购买时间',`orderid` string COMMENT '订单id')row format delimited fields terminated by '\t';--插入数据insert into table test_six_ordertable values('1',1,'2017-09-01','1');insert into table test_six_ordertable values('2',2,'2017-09-02','2');insert into table test_six_ordertable values('3',3,'2017-09-03','3');insert into table test_six_ordertable values('4',4,'2017-09-04','4');insert into table test_six_ordertable values('3',5,'2017-10-05','5');insert into table test_six_ordertable values('6',6,'2017-10-06','6');insert into table test_six_ordertable values('1',7,'2017-10-07','7');insert into table test_six_ordertable values('8',8,'2017-10-09','8');insert into table test_six_ordertable values('6',6,'2017-10-16','60');insert into table test_six_ordertable values('1',7,'2017-10-17','70');-- 写出所有用户中在今年10月份第一次购买商品的金额selectuserid,`money`,paymenttime,orderidfrom(selectuserid,`money`,paymenttime,orderid,rank() over(partition by userid order by paymenttime) rank_timefrom test_six_ordertablewhere date_format(paymenttime,'yyyy-MM') = '2017-10') awhere rank_time=1;
第七题
--现有图书管理数据库的三个数据模型如下:--图书(数据表名:BOOK)--序号 字段名称 字段描述 字段类型--1 BOOK_ID 总编号 文本--2 SORT 分类号 文本--3 BOOK_NAME 书名 文本--4 WRITER 作者 文本--5 OUTPUT 出版单位 文本--6 PRICE 单价 数值(保留小数点后2位)--读者(数据表名:READER)--序号 字段名称 字段描述 字段类型--1 READER_ID 借书证号 文本--2 COMPANY 单位 文本--3 NAME 姓名 文本--4 SEX 性别 文本--5 GRADE 职称 文本--6 ADDR 地址 文本----借阅记录(数据表名:BORROW LOG)--序号 字段名称 字段描述 字段类型--1 READER_ID 借书证号 文本--2 BOOK_D 总编号 文本--3 BORROW_ATE 借书日期 日期--(1)创建图书管理库的图书、读者和借阅三个基本表的表结构。请写出建表语句。--图书create table test_seven_BOOK(BOOK_ID String COMMENT '总编号',SORT String COMMENT '分类号',BOOK_NAME String COMMENT '书名',WRITER String COMMENT '作者',OUTPUT String COMMENT '出版单位',PRICE decimal(10,2) COMMENT '单价')row format delimited fields terminated by '\t';--读者create table test_seven_READER( READER_ID String COMMENT '借书证号',COMPANY String COMMENT '单位',NAME String COMMENT '姓名',SEX String COMMENT '性别',GRADE String COMMENT '职称',ADDR String COMMENT '地址')row format delimited fields terminated by '\t';--借阅记录create table test_seven_BORROW_LOG( READER_ID String COMMENT '借书证号',BOOK_D String COMMENT '总编号',BORROW_ATE date COMMENT '借书日期')row format delimited fields terminated by '\t';-- 插入数据insert into table test_seven_book values ('1001','A1','Java','James Gosling','sun','11');insert into table test_seven_book values ('1002','A2','linux','Linus Benedict Torvalds','sun','22');insert into table test_seven_book values ('1003','A3','Java3','James Gosling3','sun3','33');insert into table test_seven_book values ('1004','A4','Java4','James Gosling4','sun4','44');insert into table test_seven_book values ('1005','B1','Java5','James Gosling5','sun','55');insert into table test_seven_book values ('1006','C1','Java6','James Gosling6','sun5','66');insert into table test_seven_book values ('1007','D1','Java7','James Gosling7','sun6','77');insert into table test_seven_book values ('1008','E1','Java8','James Gosling4','sun3','88');insert into table test_seven_reader values ('7','buu',decode(binary('李大帅'),'utf-8'),'man','lay1','beijing4');insert into table test_seven_reader values ('2','buu2','苏大强','man','lay2','beijing2');insert into table test_seven_reader values ('3','buu2','李二胖','woman','lay3','beijing3');insert into table test_seven_reader values ('4','buu3','王三涛','man','lay4','beijing4');insert into table test_seven_reader values ('5','buu4','刘四虎','woman','lay5','beijing1');insert into table test_seven_reader values ('6','buu','宋冬野','woman','lay6','beijing5');insert into table test_seven_borrow_log values ('1','1002','2019-06-01');insert into table test_seven_borrow_log values ('1','1003','2019-06-02');insert into table test_seven_borrow_log values ('1','1006','2019-06-03');insert into table test_seven_borrow_log values ('2','1001','2019-06-04');insert into table test_seven_borrow_log values ('3','1002','2019-06-05');insert into table test_seven_borrow_log values ('4','1005','2019-06-06');insert into table test_seven_borrow_log values ('5','1003','2019-06-06');insert into table test_seven_borrow_log values ('3','1006','2019-06-07');insert into table test_seven_borrow_log values ('2','1003','2019-06-03');insert into table test_seven_borrow_log values ('3','1008','2019-06-03');insert into table test_seven_borrow_log values ('1','1002','2019-06-04');--(2)找出姓李的读者姓名(NAME)和所在单位(COMPANY)。select name,company from test_seven_reader where name like '李%';--(3)查找“高等教育出版社”的所有图书名称(BOOK_NAME)及单价(PRICE),结果按单价降序排序。select BOOK_NAME,PRICE from test_seven_book order by PRICE desc;--(4)查找价格介于10元和20元之间的图书种类(SORT)出版单位(OUTPUT)和单价(PRICE),结果按出版单位(OUTPUT)和单价(PRICE)升序排序。select SORT,OUTPUT,PRICE from test_seven_book where PRICE between 10 and 20 order by OUTPUT,PRICE asc;--(5)查找所有借了书的读者的姓名(NAME)及所在单位(COMPANY)。selectrd.name,rd.COMPANYfrom(selectREADER_IDfrom test_seven_borrow_loggroup by READER_ID) t1jointest_seven_reader rdon t1.READER_ID = rd.READER_ID;--(6)求”科学出版社”图书的最高单价、最低单价、平均单价。selectmax(PRICE) max,min(PRICE) min,avg(PRICE) avgfromtest_seven_book;--(7)找出当前至少借阅了2本图书(大于等于2本)的读者姓名及其所在单位。selectrd.READER_ID,rd.name,rd.COMPANYfrom(selectREADER_ID,count(*) numfrom test_seven_BORROW_LOGgroup by READER_IDhaving count(*) >= 2) t1jointest_seven_reader rdon t1.READER_ID = rd.READER_ID;--(8)考虑到数据安全的需要,需定时将“借阅记录”中数据进行备份,-- 请使用一条SQL语句,在备份用户bak下创建与“借阅记录”表结构完全一致的数据表BORROW_LOG_BAK.--井且将“借阅记录”中现有数据全部复制到BORROW_l0G_BAK中。create table BORROW_LOG_BAK(READER_ID String COMMENT '借书证号',BOOK_D String COMMENT '总编号',BORROW_ATE date COMMENT '借书日期')as select * from test_seven_BORROW_LOG;--(9)现在需要将原Oracle数据库中数据迁移至Hive仓库,--请写出“图书”在Hive中的建表语句(Hive实现,提示:列分隔符|;数据表数据需要外部导入:分区分别以month_part、day_part 命名)create table test_seven_book_oracle (book_id string COMMENT '总编号',sort string COMMENT '分类号',book_name string COMMENT '书名',writer string COMMENT '作者',output string COMMENT '出版单位',price decimal(10,2) COMMENT '单价')PARTITIONED BY (month string,day string)row format delimited fields terminated by '|';--(10)Hive中有表A,现在需要将表A的月分区 201505 中 user_id为20000的user_dinner字段更新为bonc8920,-- 其他用户user_dinner字段数据不变,请列出更新的方法步骤。--(Hive实现,提示:Hlive中无update语法,请通过其他办法进行数据更新)create table tmp_A as select * from A where user_id<>20000 and month_part=201505;insert into table tmp_A partition(month_part=’201505’) values(20000,其他字段,bonc8920);insert overwrite table A partition(month_part=’201505’) select * from tmp_A where month_part=201505;第八题
-- 有一个线上服务器访问日志格式如下(用sql答题)-- 时间 接口 ip地址-- 2016-11-09 11:22:05 /api/user/login 110.23.5.33-- 2016-11-09 11:23:10 /api/user/detail 57.3.2.16-- .....-- 2016-11-09 23:59:40 /api/user/login 200.6.5.166-- 求11月9号下午14点(14-15点),访问api/user/login接口的top10的ip地址create table test_eight_serverlog(server_time string COMMENT '时间',server_api string comment '接口',server_ip string COMMENT 'ip地址')row format delimited fields terminated by '\t';insert into table test_eight_serverlog values ('2016-11-09 11:22:05','/api/user/login','110.23.5.33');insert into table test_eight_serverlog values ('2016-11-09 11:23:10','/api/user/detail','57.3.2.16');insert into table test_eight_serverlog values ('2016-11-09 14:59:40','/api/user/login','200.6.5.161');insert into table test_eight_serverlog values ('2016-11-09 14:22:05','/api/user/login','110.23.5.32');insert into table test_eight_serverlog values ('2016-11-09 14:23:10','/api/user/detail','57.3.2.13');insert into table test_eight_serverlog values ('2016-11-09 14:59:40','/api/user/login','200.6.5.164');insert into table test_eight_serverlog values ('2016-11-09 14:59:40','/api/user/login','200.6.5.165');insert into table test_eight_serverlog values ('2016-11-09 14:22:05','/api/user/login','110.23.5.36');insert into table test_eight_serverlog values ('2016-11-09 14:23:10','/api/user/detail','57.3.2.17');insert into table test_eight_serverlog values ('2016-11-09 14:59:40','/api/user/login','200.6.5.168');insert into table test_eight_serverlog values ('2016-11-09 14:59:40','/api/user/login','200.6.5.168');insert into table test_eight_serverlog values ('2016-11-09 14:22:05','/api/user/login','110.23.5.32');insert into table test_eight_serverlog values ('2016-11-09 14:23:10','/api/user/detail','57.3.2.13');insert into table test_eight_serverlog values ('2016-11-09 14:59:40','/api/user/login','200.6.5.164');insert into table test_eight_serverlog values ('2016-11-09 15:22:05','/api/user/login','110.23.5.33');insert into table test_eight_serverlog values ('2016-11-09 15:23:10','/api/user/detail','57.3.2.16');insert into table test_eight_serverlog values ('2016-11-09 15:59:40','/api/user/login','200.6.5.166');selectserver_ip,count(*) visit_timefrom test_eight_serverlogwhere date_format(server_time,'yyyy-MM-dd HH')='2016-11-09 14'and server_api = '/api/user/login'group by server_iporder by visit_time desc;第九题
-- 有一个充值日志表如下:-- CREATE TABLE `credit log`-- (-- `dist_id` int(11)DEFAULT NULL COMMENT '区组id',-- `account` varchar(100)DEFAULT NULL COMMENT '账号',-- `money` int(11) DEFAULT NULL COMMENT '充值金额',-- `create_time` datetime DEFAULT NULL COMMENT '订单时间'-- )ENGINE=InnoDB DEFAUILT CHARSET-utf8-- 请写出SQL语句,查询充值日志表2015年7月9号每个区组下充值额最大的账号,要求结果:-- 区组id,账号,金额,充值时间--建表create table test_nine_credit_log(dist_id string COMMENT '区组id',account string COMMENT '账号',`money` decimal(10,2) COMMENT '充值金额',create_time string COMMENT '订单时间')row format delimited fields terminated by '\t';--插入数据insert into table test_nine_credit_log values ('1','11',100006,'2019-01-02 13:00:01');insert into table test_nine_credit_log values ('1','12',110000,'2019-01-02 13:00:02');insert into table test_nine_credit_log values ('1','13',102000,'2019-01-02 13:00:03');insert into table test_nine_credit_log values ('1','14',100300,'2019-01-02 13:00:04');insert into table test_nine_credit_log values ('1','15',100040,'2019-01-02 13:00:05');insert into table test_nine_credit_log values ('1','18',110000,'2019-01-02 13:00:02');insert into table test_nine_credit_log values ('1','16',100005,'2019-01-03 13:00:06');insert into table test_nine_credit_log values ('1','17',180000,'2019-01-03 13:00:07');insert into table test_nine_credit_log values ('2','21',100800,'2019-01-02 13:00:11');insert into table test_nine_credit_log values ('2','22',100030,'2019-01-02 13:00:12');insert into table test_nine_credit_log values ('2','23',100000,'2019-01-02 13:00:13');insert into table test_nine_credit_log values ('2','24',100010,'2019-01-03 13:00:14');insert into table test_nine_credit_log values ('2','25',100070,'2019-01-03 13:00:15');insert into table test_nine_credit_log values ('2','26',100800,'2019-01-02 15:00:11');insert into table test_nine_credit_log values ('3','31',106000,'2019-01-02 13:00:08');insert into table test_nine_credit_log values ('3','32',100400,'2019-01-02 13:00:09');insert into table test_nine_credit_log values ('3','33',100030,'2019-01-02 13:00:10');insert into table test_nine_credit_log values ('3','34',100003,'2019-01-02 13:00:20');insert into table test_nine_credit_log values ('3','35',100020,'2019-01-02 13:00:30');insert into table test_nine_credit_log values ('3','36',100500,'2019-01-02 13:00:40');insert into table test_nine_credit_log values ('3','37',106000,'2019-01-03 13:00:50');insert into table test_nine_credit_log values ('3','38',100800,'2019-01-03 13:00:59');--查询充值日志表2019年1月2号每个区组下充值额最大的账号,要求结果:区组id,账号,金额,充值时间selectaaa.dist_id,aaa.account,aaa.`money`,aaa.create_time,aaa.money_rankfrom(selectdist_id,account,`money`,create_time,dense_rank() over(partition by dist_id order by `money` desc) money_rank -- dense_rank最完美,因为不仅可以求第一多,而且还可以求第二多,第三多...from test_nine_credit_logwhere date_format(create_time,'yyyy-MM-dd') = '2019-01-02') aaawhere money_rank = 1;-- 第二种写法,不用开窗函数withtmp_max_money as(selectdist_id,max(`money`) maxfrom test_nine_credit_logwhere date_format(create_time,'yyyy-MM-dd')='2019-01-02'group by dist_id)selectcl.dist_id dist_id,cl.account acount,cl.money money,cl.create_time create_timefrom test_nine_credit_log clleft join tmp_max_money mmon cl.dist_id=mm.dist_idwhere cl.money=mm.max and date_format(create_time,'yyyy-MM-dd')='2019-01-02';第十题
-- 有一个账号表如下,请写出SQL语句,查询各自区组的money排名前十的账号(分组取前10)-- CREATE TABIE `account`-- (-- `dist_id` int(11)-- DEFAULT NULL COMMENT '区组id',-- `account` varchar(100)DEFAULT NULL COMMENT '账号' ,-- `gold` int(11)DEFAULT NULL COMMENT '金币'-- PRIMARY KEY (`dist_id`,`account_id`),-- )ENGINE=InnoDB DEFAULT CHARSET-utf8-- 替换成hive表drop table if exists `test_ten_account`;create table `test_ten_account`(`dist_id` string COMMENT '区组id',`account` string COMMENT '账号',`gold` bigint COMMENT '金币')row format delimited fields terminated by '\t';insert into table test_ten_account values ('1','11',100006);insert into table test_ten_account values ('1','12',110000);insert into table test_ten_account values ('1','13',102000);insert into table test_ten_account values ('1','14',100300);insert into table test_ten_account values ('1','15',100040);insert into table test_ten_account values ('1','18',110000);insert into table test_ten_account values ('1','16',100005);insert into table test_ten_account values ('1','17',180000);insert into table test_ten_account values ('2','21',100800);insert into table test_ten_account values ('2','22',100030);insert into table test_ten_account values ('2','23',100000);insert into table test_ten_account values ('2','24',100010);insert into table test_ten_account values ('2','25',100070);insert into table test_ten_account values ('2','26',100800);insert into table test_ten_account values ('3','31',106000);insert into table test_ten_account values ('3','32',100400);insert into table test_ten_account values ('3','33',100030);insert into table test_ten_account values ('3','34',100003);insert into table test_ten_account values ('3','35',100020);insert into table test_ten_account values ('3','36',100500);insert into table test_ten_account values ('3','37',106000);insert into table test_ten_account values ('3','38',100800);selectdist_id,account,gold,gold_rankfrom(select`dist_id`,`account`,`gold`,dense_rank() over(partition by dist_id order by gold desc) gold_rankfrom test_ten_account) tmpwhere gold_rank <= 3;第十一题
-- 1)有三张表分别为会员表(member)销售表(sale)退货表(regoods)-- (1)会员表有字段memberid(会员id,主键)credits(积分);-- (2)销售表有字段memberid(会员id,外键)购买金额(MNAccount);-- (3)退货表中有字段memberid(会员id,外键)退货金额(RMNAccount);-- 2)业务说明:-- (1)销售表中的销售记录可以是会员购买,也可是非会员购买。(即销售表中的memberid可以为空)-- (2)销售表中的一个会员可以有多条购买记录-- (3)退货表中的退货记录可以是会员,也可是非会员4、一个会员可以有一条或多条退货记录-- 查询需求:分组查出销售表中所有会员购买金额,同时分组查出退货表中所有会员的退货金额,-- 把会员id相同的购买金额-退款金额得到的结果更新到表会员表中对应会员的积分字段(credits)-- 建表--会员表drop table if exists test_eleven_member;create table test_eleven_member(memberid string COMMENT '会员id',credits bigint COMMENT '积分')row format delimited fields terminated by '\t';--销售表drop table if exists test_eleven_sale;create table test_eleven_sale(memberid string COMMENT '会员id',MNAccount decimal(10,2) COMMENT '购买金额')row format delimited fields terminated by '\t';--退货表drop table if exists test_eleven_regoods;create table test_eleven_regoods(memberid string COMMENT '会员id',RMNAccount decimal(10,2) COMMENT '退货金额')row format delimited fields terminated by '\t';insert into table test_eleven_member values('1001',0);insert into table test_eleven_member values('1002',0);insert into table test_eleven_member values('1003',0);insert into table test_eleven_member values('1004',0);insert into table test_eleven_member values('1005',0);insert into table test_eleven_member values('1006',0);insert into table test_eleven_member values('1007',0);insert into table test_eleven_sale values('1001',5000);insert into table test_eleven_sale values('1002',4000);insert into table test_eleven_sale values('1003',5000);insert into table test_eleven_sale values('1004',6000);insert into table test_eleven_sale values('1005',7000);insert into table test_eleven_sale values('1004',3000);insert into table test_eleven_sale values('1002',6000);insert into table test_eleven_sale values('1001',2000);insert into table test_eleven_sale values('1004',3000);insert into table test_eleven_sale values('1006',3000);insert into table test_eleven_sale values(NULL,1000);insert into table test_eleven_sale values(NULL,1000);insert into table test_eleven_sale values(NULL,1000);insert into table test_eleven_sale values(NULL,1000);insert into table test_eleven_regoods values('1001',1000);insert into table test_eleven_regoods values('1002',1000);insert into table test_eleven_regoods values('1003',1000);insert into table test_eleven_regoods values('1004',1000);insert into table test_eleven_regoods values('1005',1000);insert into table test_eleven_regoods values('1002',1000);insert into table test_eleven_regoods values('1001',1000);insert into table test_eleven_regoods values('1003',1000);insert into table test_eleven_regoods values('1002',1000);insert into table test_eleven_regoods values('1005',1000);insert into table test_eleven_regoods values(NULL,1000);insert into table test_eleven_regoods values(NULL,1000);insert into table test_eleven_regoods values(NULL,1000);insert into table test_eleven_regoods values(NULL,1000);-- 分组查出销售表中所有会员购买金额,同时分组查出退货表中所有会员的退货金额,-- 把会员id相同的购买金额-退款金额得到的结果更新到表会员表中对应会员的积分字段(credits)withtmp_member as( select memberid,sum(credits) creditsfrom test_eleven_membergroup by memberid),tmp_sale as(select memberid,sum(MNAccount) MNAccountfrom test_eleven_salegroup by memberid),tmp_regoods as(select memberid,sum(RMNAccount) RMNAccountfrom test_eleven_regoodsgroup by memberid)insert overwrite table test_eleven_memberselectt1.memberid,sum(t1.creadits)+sum(t1.MNAccount)-sum(t1.RMNAccount) creditsfrom(selectmemberid,credits,0 MNAccount,0 RMNAccountfrom tmp_memberunion allselectmemberid,0 credits,MNAccount,0 RMNAccountfrom tmp_saleunion allselectmemberid,0 credits,0 MNAccount,RMNAccountfrom tmp_regoods) t1where t1.memberid is not NULLgroup by t1.memberid---------------------第2种写法-用left join--------------------------insert overwrite table test_eleven_memberselectt3.memberid,sum(t3.credits) creditsfrom(selectt1.memberid,t1.MNAccount - NVL(t2.RMNAccount,0) creditsfrom(selectmemberid,sum(MNAccount) MNAccountfrom test_eleven_salegroup by memberid) t1left join(selectmemberid,sum(RMNAccount) RMNAccountfrom test_eleven_regoodsgroup by memberid)t2on t1.memberid = t2.memberidwhere t1.memberid is not NULLunion allselectmemberid,creditsfrom test_eleven_member) t3group by t3.memberid;第十二题
--现在有三个表student(学生表)、course(课程表)、score(成绩单),结构如下:--建表create table test_twelve_student(id bigint comment '学号',name string comment '姓名',age bigint comment '年龄')row format delimited fields terminated by '\t';create table test_twelve_course(cid string comment '课程号,001/002格式',cname string comment '课程名')row format delimited fields terminated by '\t';Create table test_twelve_score(id bigint comment '学号',cid string comment '课程号',score bigint comment '成绩')row format delimited fields terminated by '\t';--插入数据insert into table test_twelve_student values (1001,'wsl1',21);insert into table test_twelve_student values (1002,'wsl2',22);insert into table test_twelve_student values (1003,'wsl3',23);insert into table test_twelve_student values (1004,'wsl4',24);insert into table test_twelve_student values (1005,'wsl5',25);insert into table test_twelve_course values ('001','math');insert into table test_twelve_course values ('002','English');insert into table test_twelve_course values ('003','Chinese');insert into table test_twelve_course values ('004','music');insert into table test_twelve_score values (1001,'004',10);insert into table test_twelve_score values (1002,'003',21);insert into table test_twelve_score values (1003,'002',32);insert into table test_twelve_score values (1004,'001',43);insert into table test_twelve_score values (1005,'003',54);insert into table test_twelve_score values (1001,'002',65);insert into table test_twelve_score values (1002,'004',76);insert into table test_twelve_score values (1003,'002',77);insert into table test_twelve_score values (1001,'004',48);insert into table test_twelve_score values (1002,'003',39);--其中score中的id、cid,分别是student、course中对应的列请根据上面的表结构,回答下面的问题--1)请将本地文件(/home/users/test/20190301.csv)文件,加载到分区表score的20190301分区中,并覆盖之前的数据load data local inpath '/home/users/test/20190301.csv' overwrite into table test_twelve_score partition(event_day='20190301');--2)查出平均成绩大于60分的学生的姓名、年龄、平均成绩selectstu.name,stu.age,t1.avg_scorefromtest_twelve_student stujoin(selectid,avg(score) avg_scorefrom test_twelve_scoregroup by id) t1on t1.id = stu.idwhere avg_score > 60;--3)查出没有'001'课程成绩的学生的姓名、年龄selectstu.name,stu.agefromtest_twelve_student stujoin(selectidfrom test_twelve_scorewhere cid != 001group by id) t1on stu.id = t1.id;--4)查出有'001'\'002'这两门课程下,成绩排名前3的学生的姓名、年龄selectstu.name,stu.agefrom(selectid,cid,score,rank() over(partition by cid order by score desc) ranfromtest_twelve_scorewhere cid = 001 or cid = 002) t1join test_twelve_student stuon t1.id = stu.idwhere ran <= 3;--5)创建新的表score_20190317,并存入score表中20190317分区的数据create table score_20190317as select * from test_twelve_score where dt = '20190317';--6)如果上面的score_20190317score表中,uid存在数据倾斜,请进行优化,查出在20190101-20190317中,学生的姓名、年龄、课程、课程的平均成绩selectstu.name,stu.age,cou.cname,t1.avg_scorefrom(selectid,cid,avg(score) avg_scorefrom test_twelve_scoregroup by id,cidwhere dt >= '20190101' and dt <= '20190317') t1left join test_twelve_student stu on t1.id = stu.idleft join test_twelve_course cou on t1.cid = cou.cid--7)描述一下union和union all的区别,以及在mysql和HQL中用法的不同之处?union会对数据进行排序去重,union all不会排序去重。HQL中要求union或union all操作时必须保证select 集合的结果相同个数的列,并且每个列的类型是一样的。--8)简单描述一下lateral view语法在HQL中的应用场景,并写一个HQL实例-- 比如一个学生表为:-- 学号 姓名 年龄 成绩(语文|数学|英语)-- 001 张三 16 90,80,95-- 需要实现效果:-- 学号 成绩-- 001 90-- 001 80-- 001 95create table student(`id` string,`name` string,`age` int,`scores` array<string>)row format delimited fields terminated by '\t'collection items terminated by ',';selectid,scorefromstudent lateral view explode(scores) tmp_score as score;hivesql常用函数:
-------------------------Hive SQL 常用函数 ------------------------------常用日期函数
--unix_timestamp:返回当前或指定时间的时间戳 select unix_timestamp(); select unix_timestamp('2008-08-08 08:08:08');
--from_unixtime:将时间戳转为日期格式 select from_unixtime(1218182888);
--current_date:当前日期 select current_date();
--current_timestamp:当前的日期加时间 select current_timestamp();
--to_date:抽取日期部分 select to_date('2008-08-08 08:08:08'); select to_date(current_timestamp());
--year:获取年 select year(current_timestamp());
--month:获取月 select month(current_timestamp());
--day:获取日 select DAY(current_timestamp());
--hour:获取时 select HOUR(current_timestamp());
--minute:获取分 select minute(current_timestamp());
--second:获取秒 select SECOND(current_timestamp());
--weekofyear:当前时间是一年中的第几周 select weekofyear(current_timestamp()); select weekofyear('2020-01-08');
--dayofmonth:当前时间是一个月中的第几天 select dayofmonth(current_timestamp()); select dayofmonth('2020-01-08');
--months_between: 两个日期间的月份 select months_between('2020-07-29','2020-06-28');
--add_months:日期加减月 select add_months('2020-06-28',1);
--datediff:两个日期相差的天数 select datediff('2019-03-01','2019-02-01'); select datediff('2020-03-01','2020-02-01');
--date_add:日期加天数 select date_add('2019-02-28',1); select date_add('2020-02-28',1);
--date_sub:日期减天数 select date_sub('2019-03-01',1); select date_sub('2020-03-01',1);
--last_day:日期的当月的最后一天 select last_day('2020-02-28'); select last_day('2019-02-28');
--date_format() :格式化日期 日期格式:'yyyy-MM-dd hh:mm:ss' select date_format('2008-08-08 08:08:08','yyyy-MM-dd hh:mm:ss'); --常用取整函数
--round: 四舍五入 select round(4.5);
--ceil: 向上取整 select ceil(4.5);
--floor: 向下取整 select floor(4.5);
--
--常用字符串操作函数
--upper: 转大写 select upper('abcDEFg');
--lower: 转小写 select lower('abcDEFg');
--length: 长度 select length('abcDEFg');
--trim: 前后去空格 select length(' abcDEFg '); select length(trim(' abcDEFg '));
--lpad: 向左补齐,到指定长度 select lpad('abc',11,'*');
--rpad: 向右补齐,到指定长度 select rpad('abc',11,'*');
--substring: 剪切字符串 select substring('abcdefg',1,3); select rpad(substring('13843838438',1,3),11,'*');
--regexp_replace: SELECT regexp_replace('100-200', '(\\d+)', 'num'); select regexp_replace('abc d e f',' ','');
-- 使用正则表达式匹配目标字符串,匹配成功后替换!
--
--集合操作
--size: 集合中元素的个数
--map_keys: 返回map中的key
--map_values: 返回map中的value select size(friends),map_keys(children),map_values(children) from person;
--array_contains: 判断array中是否包含某个元素 select array_contains(friends,'lili') from person;
--sort_array: 将array中的元素排序 select sort_array(split('1,3,4,5,2,6,9',','));
-- select sort_array(split('a,d,g,b,c,f,e',','));--------------------常用日期函数
--返回时间戳
select unix_timestamp();--返回当前时间到1970年1月1号的时间戳(经过了多少秒)
select unix_timestamp("1970-01-01 00:00:05");--指定时间的时间戳
--时间戳转日期
select from_unixtime(5);
--当前日期
select current_date();
--当前的日期加时间
select current_timestamp();
--抽取日期部分
select to_date(current_timestamp());
select to_date('2008-08-08 08:08:08');
--获取年月日、时分秒 (注意,必须满足日期和时间的格式才能识别)
select year(current_timestamp()),month (current_timestamp()),day(current_timestamp()),
hour(current_timestamp()),minute (current_timestamp()), second(current_timestamp());
--当前时间或指定时间是一年中的第几周 、 一个月中的第几天
select weekofyear(current_timestamp());
select weekofyear('2008-08-08 08:08:08');
select dayofmonth(CURRENT_date());
select dayofmonth('2008-08-08 08:08:08');
--两个日期间的月份 两个日期见相差的天数
select months_between('2008-08-08','2008-09-08');
select datediff('2008-09-08','2008-08-08');
--日期加减月、 加减天
select add_months('2008-08-08',1);
select date_add('2008-08-08',1);
select date_sub('2008-08-08',1);
--日期的当月的最后一天
select last_day('2008-08-08');
--格式化日期 日期格式:'yyyy-MM-dd hh:mm:ss' 把日期转化为SQL能够识别的格式
select date_format('2008-08-08 08:08:08','yyyy-MM-dd hh:mm:ss');--------------------------------常用取整函数 具体的使用看需求
--四舍五入
select round(4.6);
--向上取整
select ceil(4.01);
--向下取整
select floor(4.99);------------------------------常用字符串操作函数
--转为大写
select upper('sdadsadASSS');
--转为小写
SELECT lower('AAAAASASDDDA');
--求字符串的长度
SELECT length('sdadasdasd');
--把字符串前后的空格去掉 字符串中间的空格去不掉,需要使用替换了
SELECT trim(' woshi haoren ');
--向左、右补齐,到指定长度 l表示左 r表示右 pad 填补
SELECT lpad('abc',8,'*');
SELECT rpad('abc',8,'*');
--剪切字符串 从哪开始剪,剪切的长度是多少
SELECT SUBSTRING('12345678',2,5);
select rpad(substring('13843838438',1,3),11,'*');
--使用正则表达式匹配目标字符串,匹配成功后替换!
SELECT regexp_replace('a b c -12 32',' ','');--去掉所有的空
select replace('d d d',' ','-');------------------------------集合操作
show tables;
desc test;
SELECT * from test limit 10;
--集合中元素的个数 不含有struct ,而且struct也不属于集合
SELECT size(friends),size(children)
FROM test;
--返回map中的key,返回map中的value
SELECT map_keys(children),map_values(children)
from test;
--将array数组中的元素排序
SELECT sort_array(split('1,3,4,2,6,4,3,8',','));
SELECT sort_array(split('b,a,ss,a,z,w,f,z',','));
hiveSQL常用操作语句(mysql)
1.建库语句:CREATE DATABASE [IF NOT EXISTS] database_name[COMMENT database_comment][LOCATION hdfs_path][WITH DBPROPERTIES (property_name=property_value, ...)];例:create DATABASE if NOT EXISTS hive_db2comment "my first database"location "/hive_db2"
2.库的修改:alter database hive_db2 set DBPROPERTIES ("createtime"="2018-12-19");
3.库的删除drop database db_hive cascade if exists; -- 删除存在表的数据库
3.建表语句:CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char][MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)][STORED AS file_format] Textfile[LOCATION hdfs_path][TBLPROPERTIES (property_name=property_value, ...)][AS select_statement]例1:create table student2(id int COMMENT "xuehao", name string COMMENT "mingzi")COMMENT "xueshengbiao"ROW format delimitedfields terminated by '\t'STORED as Textfilelocation '/student2' -- 直接加载该目录下的数据文件到表中TBLPROPERTIES ("createtime"="2018-12-18");例2:create table student(id int, name string)row format delimitedfields terminated by '\t';load data local inpath '/opt/module/datas/student.txt' into table student;例3:create table student4 like student2; -- 仅复制表结构
4.导入数据语句4.1 不加local则导入hdfs上文件,但会剪贴原文件,local本地仅粘贴load data [local] inpath '/opt/module/datas/student.txt' [overwrite] into table student [partition (partcol1=val1,…)];4.2 创建表并导入数据(依据以存在的表)create table student6 as select * from student; -- 仅导入数据,不会导入其他细节属性 --被创建表不能是外部表 -- 被创建表不支持分区及分桶4.3 覆盖插入insert overwrite table student3 select * from student;4.4 插入带分区的表insert into table stu_par partition(month = '08') select id ,name from stu_par where month = '09';4.5 将单表中数据导入多表from studentinsert into table student4 select *insert into table student5 select *;4.6 多分区导入单表from stu_parinsert into table stu_par partition(month = '06')select id ,name where month = '08'insert into table stu_par partition(month = '07')select id,name where month = '10';
5.表的修改操作5.1 修改表的属性alter table stu_ex set TBLPROPERTIES ('EXTERNAL' = 'TRUE');5.2 重命名表名alter table student4 rename to student3;5.3 修改表的serde属性(序列化和反序列化)alter table table_name set serdepropertyes('field.delim'='\t');
6.列的更新操作6.1 修改列语法ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]6.2 增加或替换列语法ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...) 例1:增加列:alter table student2 add COLUMNS (score double);例2:修改列:alter table student2 CHANGE COLUMN score score int AFTER id;例3:替换列(全部替换):alter table student2 replace COLUMNS (id int, name string);
7.带有分区的表7.0 查看分区show partitions table_name;7.1 创建单个分区create table stu_par(id int, name string)partitioned by (month string)ROW format delimitedFIELDS terminated by '\t';-- 错误示例create table stu_par2(id int, name string)partitioned by (id int)ROW format delimitedFIELDS terminated by '\t'; 错!!!!(不能以数据库字段作为分区)-- 加载数据到指定分区(分区不存在则自动创建)load data local inpath '/opt/module/datas/student.txt' into table stu_par partition(month = '12');load data local inpath '/opt/module/datas/student.txt' into table stu_par partition(month = '11');-- 合并分区查询结果select * from stu_par where month = '11'unionselect * from stu_par where month = '12';7.2 增加多个分区alter table stu_par add partition (month = '08') partition(month='07');7.3 删除多个分区alter table stu_par drop partition(month='08'),partition(month='09');7.4 创建多级分区create table stu_par2(id int, name string)partitioned by (month string, day string)row format delimitedFIELDS terminated by '\t';7.5 导入数据到多级分区load data local inpath '/opt/module/datas/student.txt' into table stu_par2 partition (month='12',day='19');7.6 向多级分区增加分区alter table stu_par2 add partition(month = '12', day = '17');7.7 查询多级分区中的数据select * from stu_par2 where day = '18';7.8 修复分区(也可以使用添加分区的语句)msck repair table dept_partition2;
8.创建外部表(删除表不会删除表中数据,仅删除表的元数据)create external table stu_ex2(id int, name string)ROW format delimitedFIELDS terminated by '\t'location '/student';8.1 外部表与内部表的转换alter table stu_ex set TBLPROPERTIES ('EXTERNAL' = 'TRUE');
9.数据的导出9.1 导出同时格式化(不加local则导出到hdfs)insert overwrite local directory '/opt/module/datas/student'row format delimitedfields terminated by '\t'select * from student;9.2 hadoop命令导出到本地dfs -get /user/hive/warehouse/student/month=201709/000000_0 /opt/module/datas/export/student3.txt;9.3 shell命令导出hive -f/-e 执行语句或者脚本 > file -- -f跟文件,-e跟执行语句9.4 export仅可以导出到hdfs,常用于hdfs集群hive表迁徙export table default.student to '/user/hive/warehouse/export/student'; -- 同时会导出表的元数据
10.数据的导入(仅能导入export导出的数据,因为需要获取表的元数据)import table table_name from 'export导出数据的路径';
11.清除表中数据truncate table student; -- 只能删除管理表,不能删除外部表中数据
12.Like、RLike:RLike可以使用java的正则表达式
13.group by及having的使用 -- hive中对于使用group by后查询字段仅限group by的字段及聚合函数select deptno, avg(sal) avg_sal from emp group by deptno having avg_sal > 2000;
14.mapreduce的join 14.1 mapreduce中的reducejoin特点:在mapper阶段进行数据关联标记,在reducer阶段进行数据聚合14.2 mapreduce中的mapjoin特点:将小表加载到内存中,在mapper阶段根据内存中的数据对大表进行数据处理,没有reduce阶段
15.HQL的join15.1 仅支持等值连接不支持非等值连接例:不支持select * from A left join B on A.id != B.id;15.2 不支持在on条件中使用‘or’15.3 每个join都会启动一个mapreduce任务,但hive默认开启mapreduce优化关闭mapreduce优化:set hive.auto.convert.join=false;
16.order by会进行全局排序,则reduce数量被看作1个,效率低下
17.sort by -- 局部排序对于每个mapreduce各分区进行局部排序,分区中的数据随机给定
18.distribute by18.1 即mapreduce中自定义分区操作,hql书写规则:先分区后排序 18.2 distribute by的分区规则是根据分区字段的hash码与reduce的个数进行模除后,余数相同的分到一个区。
19.cluster by当distribute和sort字段相同时可用cluster进行替代,默认正序,单不支持desc倒序
20.分桶 -- 分桶表的数据需要通过子查询的方式导入20.1 开启分桶的设置set hive.enforce.bucketing=true;20.2 分桶表的创建create table stu_buck(id int, name string)clustered by(id) into 4 bucketsrow format delimited fields terminated by '\t';20.3 分桶的规则用分桶字段的hash值与桶的个数求余,来决定数据存放在那个桶,20.4 分桶与分区区别a. 分桶结果在表的目录下存在多个分桶文件b. 分区是将数据存放在表所在目录不同文件路径下c. 分区针对是数据存储路径,分桶针对的是数据文件,分桶可以在分区的基础粒度细化
21.分桶的抽样 21.1 抽样语法 -- 必须 x<=yselect * from table_name tablesample(bucket x out of y on bucketKey); -- on bucketKey可不写21.2 抽样规则a. y用来决定抽样比例,必须为bucket数的倍数或者因子,例:bucket数为4时,当y=2时,4/2=2,则抽取两个桶的数据,具体抽取哪个桶由x决定b. x用来决定抽取哪个桶中的数据例1:当bucket=4, y=4, x=2时,则需要抽取的数据量为bucket/y=1个桶,抽取第x桶的数据例2:当bucket=4, y=2, x=2时,则需要抽取的数据量为bucket/y=2个桶,抽取第x桶和第x+y桶的数据例3:当bucket=12, y=3, x=2时,抽bucket/y=4个桶,抽取第x桶和第x+2y桶的数据
22.NVL函数NVL(column_name, default_cvalue),如果该行字段值为null,则返回default_value的值
23.CONCAT_WS()函数使用规则:concat_ws(separator, [string | array(string)]+)例:select concat_ws('_', 'www', array('achong','com')) 拼接结果:www_achong_com
24.COLLECT_SET(col)函数使用规则:仅接受基本数据类型,将字段去重汇总,并返回array类型例(行转列):表结构name xingzuo blood孙悟空 白羊座 A大海 射手座 A宋宋 白羊座 B猪八戒 白羊座 A凤姐 射手座 A需求:把星座和血型一样的人归类到一起射手座,A 大海|凤姐白羊座,A 孙悟空|猪八戒白羊座,B 宋宋查询语句:SELECT CONCAT_WS(',', xingzuo, blood), CONCAT_WS('|', COLLECT_SET(NAME))FROM xingzuoGROUP BY xingzuo, blood
25.EXPLODE(爆炸函数)及LATERAL_VIEW)(侧写函数)25.1 explode:将列中的array或者map结构拆分成多行 -- 一般需结合lateral_view使用25.2 lateral_view: LATERAL VIEW udtf(expression) 表别名 AS 列别名例(行转列)select movie, category_namefrom movie_info lateral view explode(category) table_tmp as category_name;
26.开窗函数 -- 常结合聚合函数使用,解决即需要聚合前的数据又需要聚合后的数据展示26.1 语法:UDAF() over (PARTITION By col1,col2 order by col3 窗口子句(rows between .. and ..)) AS 列别名(partition by .. order by)可替换为(distribute by .. sort by ..)26.2 over(): 指定分析数据窗口大小26.3 窗口子句 -- 先分区在排序然后接rows限定执行窗口26.3.01 n PRECEDING:往前n行数据26.3.02 n FOLLOWING:往后n行数据例:select name, orderdate, cost, sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and 1 FOLLOWING) from business;26.3.03 CURRENT ROW:当前行26.3.04 UNBOUNDED PRECEDING 表示从前面的起点26.3.05 UNBOUNDED FOLLOWING表示到后面的终点例:select name, orderdate, cost, sum(cost) over(partition by name order by orderdate rows between CURRENT ROW and UNBOUNDED FOLLOWING) from business;
27.LAG(col,n,default_val):往前第n行数据
28.LEAD(col,n, default_val):往后第n行数据例:select name, orderdate, cost, lag(orderdate, 1, 'null') over(partition by name order by orderdate)from business; -- 即获取前1行的orderDate数据
29.ntile(n):把有序分区中的行分为n组,每组编号从1开始 -- 分组规则详见:ntile的分组规则.sql例:select name,orderdate,cost, ntile(5) over(order by orderdate) num from business
30.Rank函数rank() 出现相同排序时,总数不变dense_rank() 出现相同排序时,总数减少row_number() 不会出现相同排序sql执行顺序from... where...group by... having.... select ... order by...hql执行顺序 from … where … group by … having … select … order by … 或from … on … join … where … group by … having … select … distinct … order by … limit存在开窗函数时,起码在order by之前执行例题1:-- 集合类型数据导入{"name": "songsong","friends": ["bingbing" , "lili"] , //列表Array, "children": { //键值Map,"xiao song": 18 ,"xiaoxiao song": 19}"address": { //结构Struct,"street": "hui long guan" ,"city": "beijing" }}基于上述数据结构,我们在Hive里创建对应的表,并导入数据。1.1 格式化数据为:songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijingyangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing1.2 建表语句:create table test(name string, friends array<string>,children map<string, int>,address struct<street:string, city:string>)row format delimitedfields terminated by ','collection items terminated by '_'map keys terminated by ':';1.3 数据写入语句load data local inpath '/opt/module/datas/test.txt' into table test;1.4 查询语句select friends[0] friend,children['xiao song'] age,address.city from test where name = 'songsong';相关文章:
)
hiveSQL语法及练习题整理(mysql)
目录 hiveSQL练习题整理: 第一题 第二题 第三题 第四题 第五题 第六题 第七题 第八题 第九题 第十题 第十一题 第十二题 hivesql常用函数: hiveSQL常用操作语句(mysql) hiveSQL练习题整理: 第一题 我…...
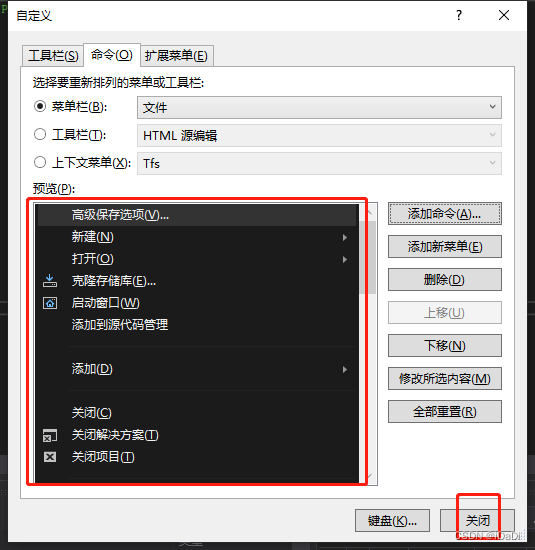
【UE4】UE编辑器乱码问题
环境:UE4.27、vs2019 如何解决 问题原因,UE的编码默认是UTF-8,VS的默认编码是GBK 通过"高级保存选项" 直接修改VS的 .h头文件 的 编码 为 UTF-8 步骤1. 步骤2. 修改编码后,从新编译,然后就可以解决编辑器…...
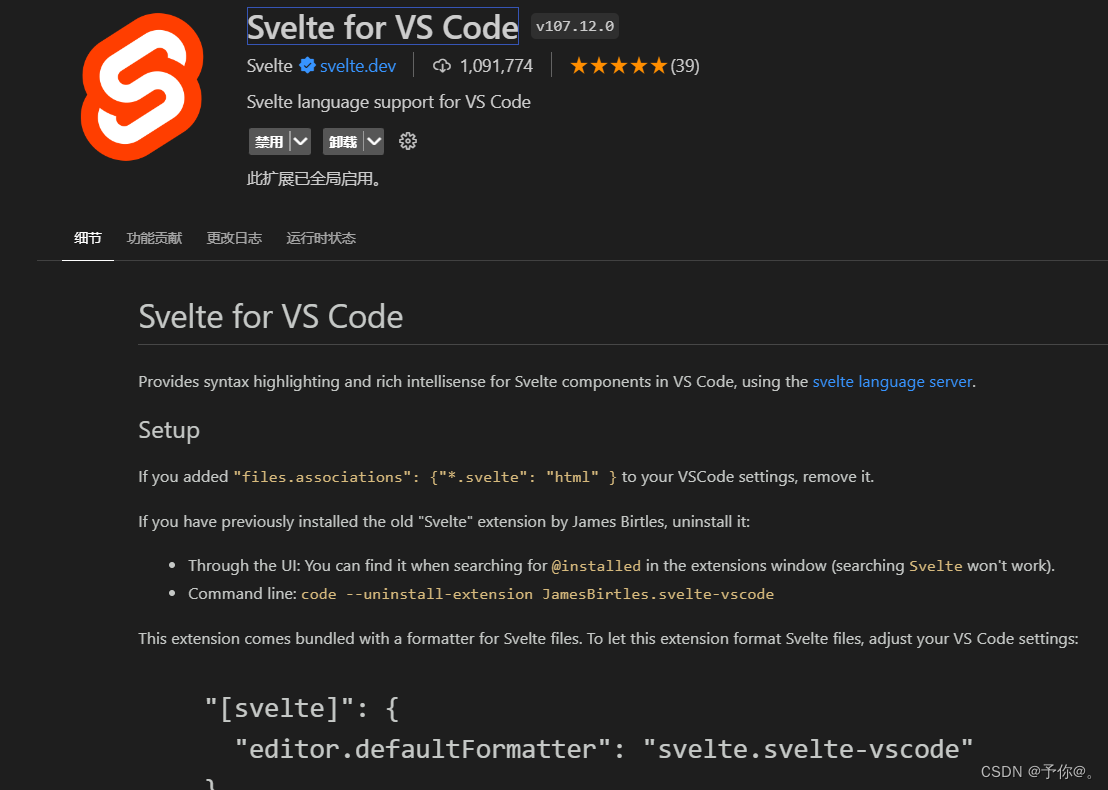
2 创建svelte项目(应用程序)
官网方式搭建: npm create sveltelatest my-app cd my-app npm install npm run dev 官网中介绍: 如果您使用的是 VS Code,安装 Svelte for VS Code 就可以了,以便语法高亮显示。 然后,一旦您的项目设置好了&#…...
手机怎么打包?三个方法随心选!
有的时候,电脑不在身边,只有随身携带的手机,这个时候又急需把文件打包发送给同事或者同学,如何利用手机操作呢?下面介绍了具体的操作步骤。 一、通过手机文件管理自带压缩功能打包 1、如果是iOS系统,就在手…...
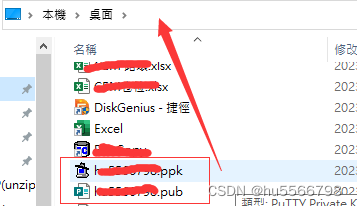
SecureFX如何用Public key 連接sftp
點擊connection 右鍵點開站點的properties 點選SSH2--Authentication---Pulickey 先選擇Putty Key Generator save出來的public key(.pub)文件(Putty Key Generator 保存時可能沒加.pub後綴保存,可自行對public key加上後綴.pub) 同時注意要…...

BUUCTF 隐藏的钥匙 1
BUUCTF:https://buuoj.cn/challenges 题目描述: 路飞一行人千辛万苦来到了伟大航道的终点,找到了传说中的One piece,但是需要钥匙才能打开One Piece大门,钥匙就隐藏在下面的图片中,聪明的你能帮路飞拿到钥匙ÿ…...
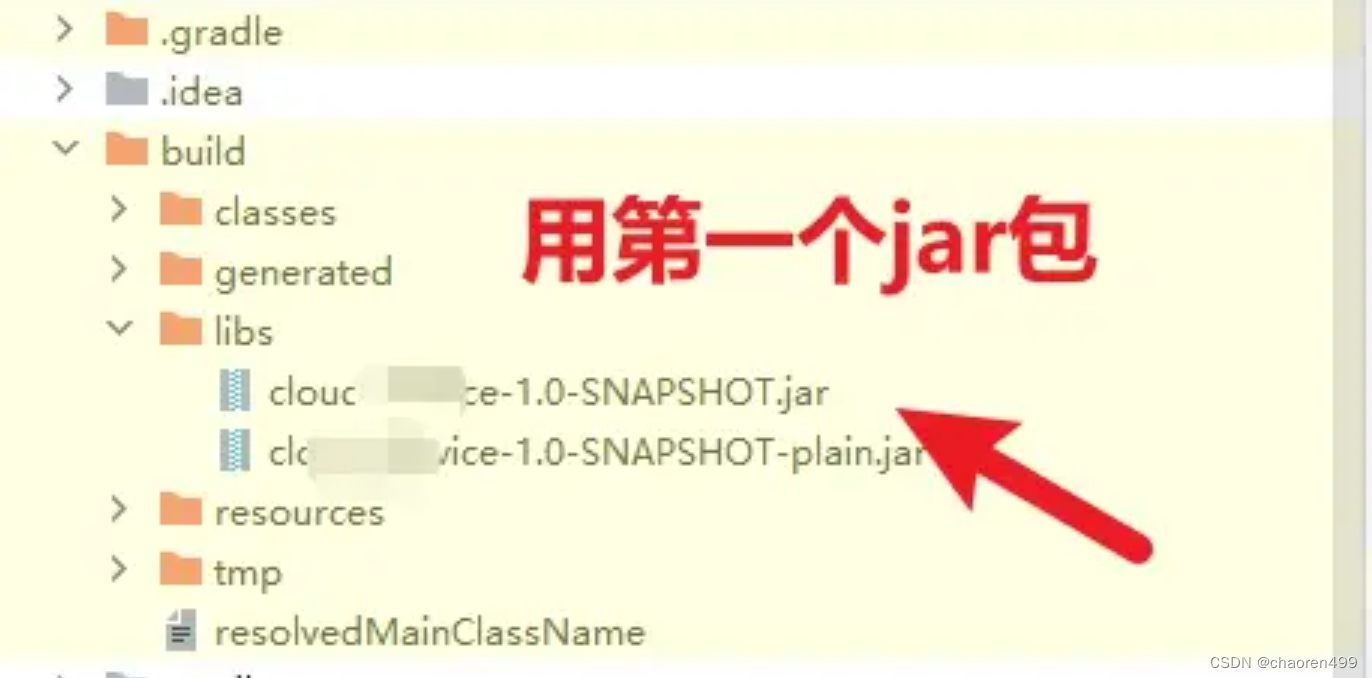
idea使用gradle教程 (idea gradle springboot)2024
这里白眉大叔,写一下我工作时候idea怎么使用gradle的实战步骤吧 ----windows 环境----------- 1-本机安装gradle 环境 (1)下载gradle Gradle需要JDK的支持,安装Gradle之前需要提前安装JDK8及以上版本 https://downloads.gra…...

本地部署 lama-cleaner
本地部署 lama-cleaner 什么是 lama-cleanerGithub 地址部署 lama-cleaner启动 lama-cleaner 什么是 lama-cleaner lama-cleaner 是一款由 SOTA AI 模型提供支持的免费开源修复工具。 从照片中删除任何不需要的物体、缺陷、人物,或擦除并替换(由稳定扩…...

供应链云仓系统:实现采购、销售、收银、路线规划一体化,高效协同,再创商业价值!
供应链云仓系统是一款集合采购、销售、收银、路线规划等多项功能的软件系统,旨在帮助企业实现业务流程的全面自动化和协同化。通过该系统,企业可以轻松管理供应链的各个环节,提高运营效率,降低成本,实现商业价值的最大…...

如何用devtools快速开发一个R语言包?
如何用devtools快速开发一个R语言包? 1. 准备工作2. 如何完整开发一个R包3. 初始化新包4. 启用Git仓库5. 按照目标实现一个函数6. 在.R文件夹下创建文件并保存代码7. 函数测试8. 阶段性总结9. 时不时地检查完整工作状态10. 编辑DESCRIPTION文件11. 配置许可证12. 配…...
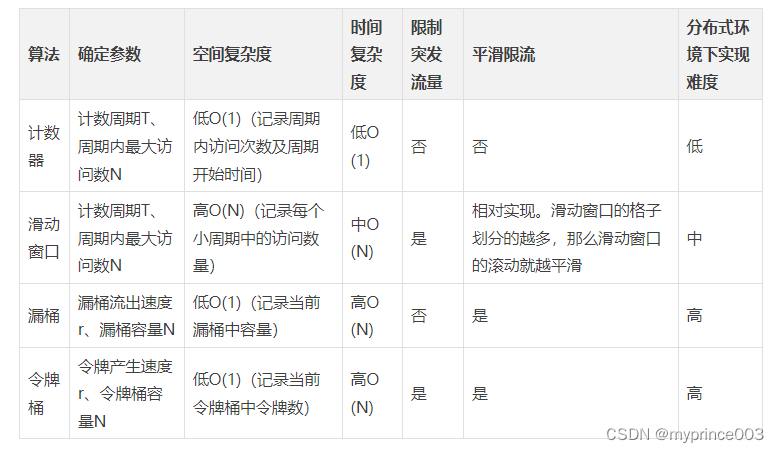
1、Sentinel基本应用限流规则(1)
Sentinel基本应用&限流规则 1.1 概述与作用 随着微服务的流行,服务和服务之间的稳定性变得越来越重要。缓存、降级和限流是保护微服务系统运行稳定性的三大利器。 缓存:提升系统访问速度和增大系统能处理的容量 降级:当服务出问题或者影…...
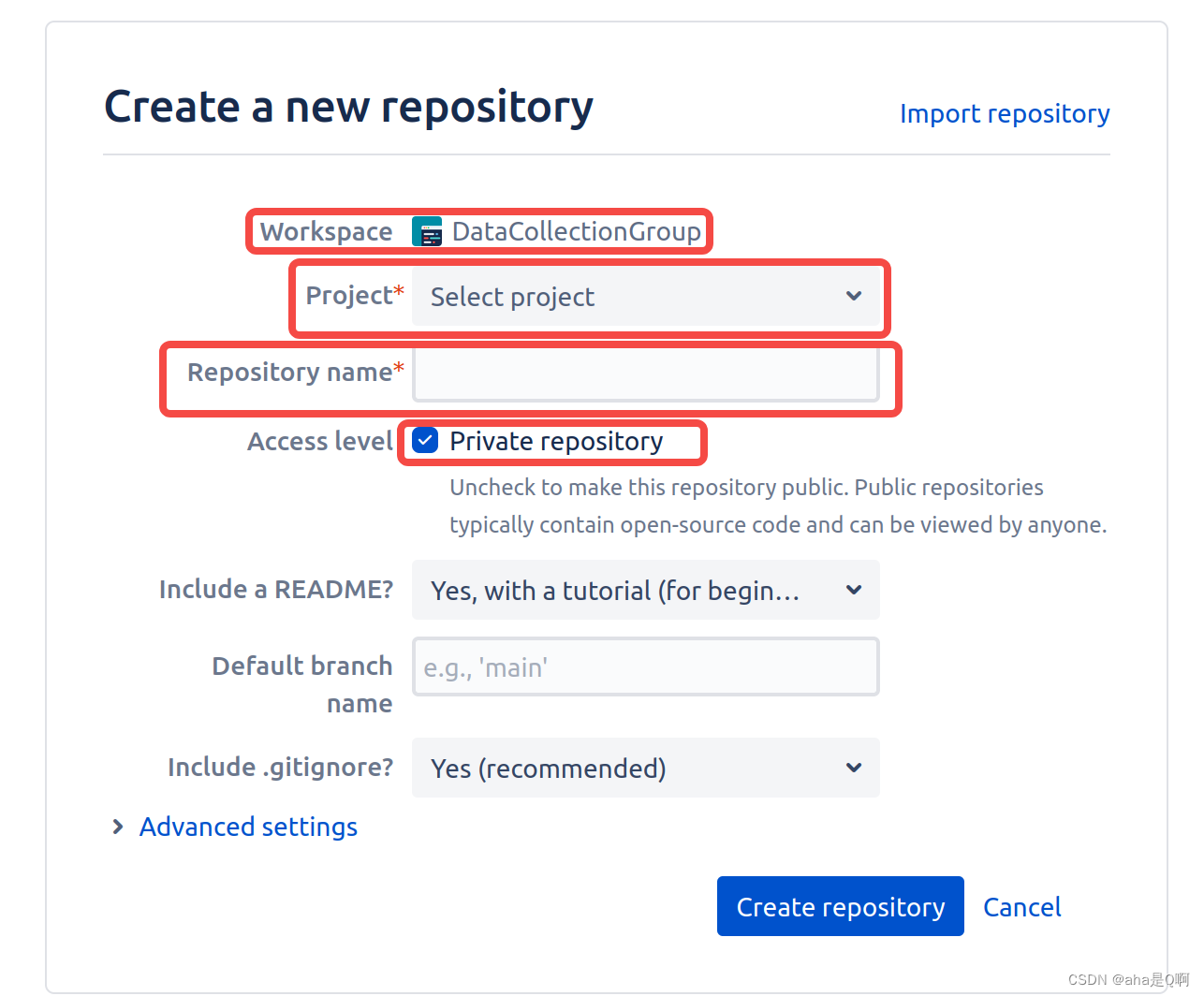
BitBucket 进行代码管理
目的&原因 小团队代码管理,BitBucket 提供免费代码仓库。 创建代码仓库&邀请团队 注册&创建 group(workspace) 可创建私有通过邮箱 invite 团队成员 创建仓库 要选择所属的 workspace 和 project(没有可同时创建&…...

惊艳!拓世法宝AI智能数字人一体机解锁数字文博的全民体验
在数字化的潮流中,我们见证了历史与现代技术的完美融合。在今年的“国际古迹遗址日”,世界首个超时空参与式博物馆“数字藏经洞”正式与公众见面,在这里开启了一场前所未有的文化探索之旅。 时间和空间被艺术化的数字技术巧妙地折叠…...

Redis之与SSM集成Spring注解式缓存
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是君易--鑨,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的博客专栏《Redis实战开发》。🎯🎯 …...
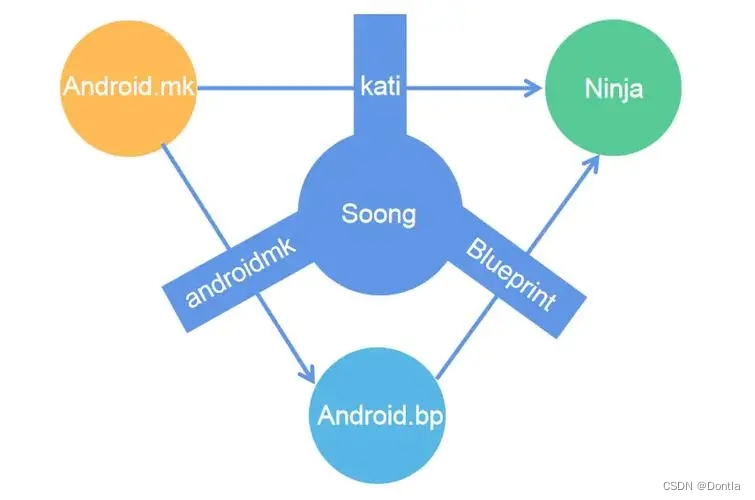
Android 安卓 Soong构建系统——Blueprint Android.bp配置文件解析
文章目录 Android.bp起源Android.bp文件结构如何编写Android.bp文件实例详解实例1实例2 常见问题解答1. 如何确定使用哪种模块类型?2. 如何指定模块的依赖项?其他疑问可参考官方文档 参考文章:Android.bp 语法和使用 Android.bp起源 早期的A…...

【Redis】SSM整合Redis注解式缓存的使用
【Redis】SSM整合Redis&注解式缓存的使用 一、SSM整合Redis1.2.配置文件spring-redis.xml1.3.修改applicationContext.xml1.4.配置redis的key生成策略 二、Redis的注解式开发及应用场景2.1.什么是Redis注解式2.实列测试 三、Redis中的击穿、穿透、雪崩的三种场景 一、SSM整…...
lua中的循环 while、for、repeat until三种循环方式、pairs和ipairs区别
lua中的循环 while、for、repeat until三种循环方式、pairs和ipairs区别 介绍for循环参数ipairs和pairs whilerepeat until总结 介绍 这里我用while、for、repeat until分别输出1-20之间的奇数 ,具体的语法可以看下面的代码 for循环 参数 定义一个初始值为start…...
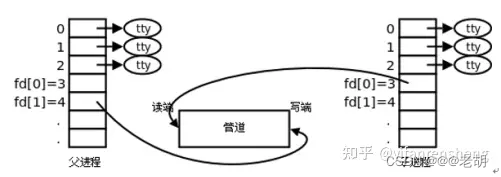
Linux 进程的管道通信
文章目录 无名管道pipe有名管道 进程之间的通信:Linux环境下,进程地址空间相互独立,每个进程各自有不同的用户地址空间。任何一个进程的全局变量在另外一个进程中都看不到,所以进程之间不能相互访问,要交换数据必须通过…...

OpenGL和Vulkan比较
比较 见参考 参考 Reference GuidesCopyright 2022-2023 The Khronos Group Inc. :: Vulkan Documentation ProjectDifference Between OpenGL vs VulkanVulkan与OpenGL对比——Vulkan的全新渲染架构 图形程序接口:OpenGL、OpenCL、Vulkan、OpenGL ES、WebGL…...

OpenCV入门3:像素操作
在OpenCV中,图像的像素值是以一个多维数组的形式表示的。上一篇已经介绍了cv::Mat类。对于图像中的每一个像素,可以通过Mat对象中的at<type>(i,j)函数(type可以是uchar、int等)获得Mat对象的像素值。 访问像素值࿱…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略
告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略当GIS初学者第一次安装ArcGIS 10.6时,往往会被其庞大的安装体积所震惊。许多用户习惯性地点击"下一步",结果发现C盘空间被迅速吞噬,系统运行变得迟缓。本文将深…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...

账务台账数据
银行里说的 “账务台账数据”,本质就是按会计规则把每笔业务逐笔、分户、分科目记下来的完整明细流水 余额 辅助信息,核心是 “可逐笔追溯、可对账、可审计” 的一套明细数据。下面用通俗、具体的方式拆开说:一、银行 “账务台账” 到底是什…...

Keil µVision链接器错误204解决方案
1. 问题现象与背景解析最近在使用Keil Vision进行嵌入式开发时,不少工程师遇到了一个令人头疼的链接器错误。具体表现为编译时出现"FATAL ERROR 204: INVALID KEYWORD"的致命错误,错误位置指向链接器控制文件中的特定行。这个问题在C166和C51两…...

收藏|2026年大模型算法岗崛起!程序员小白入门高薪赛道全攻略
前些年,算法岗位一直稳居技术圈高薪行列,无数程序员争相入局,也成为计算机专业毕业生求职首选方向。 伴随大模型技术飞速迭代落地,行业就业格局迎来重大变革。如今含金量最高、人才缺口最大、长期发展潜力顶尖的岗位,已…...

实战解锁:在Blender中掌握专业级MMD动画制作全流程
实战解锁:在Blender中掌握专业级MMD动画制作全流程 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools MMD …...

DeTikZify:基于AI的TikZ图形程序自动生成技术深度解析
DeTikZify:基于AI的TikZ图形程序自动生成技术深度解析 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ. 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify DeTikZify是一款革命性的多模态…...

如何用OpenHRMS打造企业级人力资源管理系统:30+模块完全指南
如何用OpenHRMS打造企业级人力资源管理系统:30模块完全指南 【免费下载链接】OpenHRMS 项目地址: https://gitcode.com/gh_mirrors/op/OpenHRMS 还在为繁琐的人力资源管理头疼吗?🤔 面对员工考勤、薪酬计算、绩效评估等复杂流程&…...

SafeExamBrowser安全绕过实战:虚拟机检测绕过与日志伪装技术架构深度解析
SafeExamBrowser安全绕过实战:虚拟机检测绕过与日志伪装技术架构深度解析 【免费下载链接】safe-exam-browser-bypass A VM and display detection bypass for SEB. 项目地址: https://gitcode.com/gh_mirrors/sa/safe-exam-browser-bypass SafeExamBrowser&…...