PyTorch入门学习(十七):完整的模型训练套路
目录
一、构建神经网络
二、数据准备
三、损失函数和优化器
四、训练模型
五、保存模型
一、构建神经网络
首先,需要构建一个神经网络模型。在示例代码中,构建了一个名为Tudui的卷积神经网络(CNN)模型。这个模型包括卷积层、池化层和全连接层,用于处理图像分类任务。
class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init()self.mode1 = nn.Sequential(nn.Conv2d(3, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4, 64),nn.Linear(64, 10))def forward(self, x):x = self.mode1(x)return x
二、数据准备
训练深度学习模型需要数据集。在示例中,使用CIFAR-10数据集作为示例数据。数据集的准备包括下载、预处理和分割成训练集和测试集。
import torch
import torchvision
from torch.utils.data import DataLoader# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="D:\\Python_Project\\pytorch\\dataset2", train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root="D:\\Python_Project\\pytorch\\dataset2", train=False, transform=torchvision.transforms.ToTensor(), download=True)# 创建数据加载器
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)train_data_size = len(train_data)
test_data_size = len(test_data)
三、损失函数和优化器
在训练中,需要定义损失函数和优化器。损失函数用于度量模型的输出与真实标签之间的差距,而优化器用于更新模型的参数以减小损失。
loss_fn = nn.CrossEntropyLoss()
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
四、训练模型
模型训练分为多轮迭代,每轮包括训练和测试步骤。在训练步骤中,通过反向传播算法更新模型参数,以最小化损失函数。在测试步骤中,用测试集验证模型性能。
for epoch in range(10): # 训练的轮数tudui.train()for data in train_dataloader:imgs, targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()tudui.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_dataloader:imgs, targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs, targets)total_test_loss += loss.item()accuracy = (outputs.argmax(1) == targets).sum()total_accuracy += accuracyprint("整体测试集上的Loss:{}".format(total_test_loss))print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))
五、保存模型
最后,可以保存训练好的模型,以备后续使用。示例代码展示了两种保存模型的方式,包括保存整个模型和仅保存模型参数。
# 保存方式一
torch.save(tudui, "tudui_{}.pth".format(epoch))
# 保存方式二(官方推荐)
# torch.save(tudui.state_dict(), 'tudui_{}.pth'.format(epoch))
完整代码如下:
import torch
from torch import nn# 搭建神经网络
class Tudui(nn.Module):def __init__(self):super(Tudui,self).__init__()self.mode1 = nn.Sequential(nn.Conv2d(3,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,64,5,1,2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4,64),nn.Linear(64,10))def forward(self, x):x = self.mode1(x)return xif __name__ == '__main__':tudui = Tudui()input = torch.ones((64,3,32,32))output = tudui(input)print(output.shape)import torch
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from P27_model import *
import time# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="D:\\Python_Project\\pytorch\\dataset2",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="D:\\Python_Project\\pytorch\\dataset2",train=False,transform=torchvision.transforms.ToTensor(),download=True)# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)# 如果train_data_size=10,训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))# 利用DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)# 创建网络模型
tudui = Tudui()# 损失函数
loss_fn = nn.CrossEntropyLoss()# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate)# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0# 训练的轮数
epoch = 10# 添加tensorboard
writer = SummaryWriter("logs_train")
# 添加开始时间
strat_time = time.time()for i in range(epoch):print("----------第{}轮训练开始----------".format(i+1))# 训练步骤开始tudui.train() # 这两个层,只对一部分层起作用,比如 dropout层;如果有这些特殊的层,才需要调用这个语句for data in train_dataloader:imgs, targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs, targets)# 优化器优化模型optimizer.zero_grad() # 优化器,梯度清零loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:end_time = time.time() # 结束时间print(end_time - strat_time)print("训练次数:{}, Loss:{}".format(total_train_step, loss.item())) # 这里用到的 item()方法,有说法的,其实加不加都行,就是输出的形式不一样而已writer.add_scalar("train_loss", loss.item(),total_train_step)# 每训练完一轮,进行测试,在测试集上测试,以测试集的损失或者正确率,来评估有没有训练好,测试时,就不要调优了,就是以当前的模型,进行测试,所以不用再使用梯度(with no_grad 那句)# 测试步骤开始tudui.eval() # 这两个层,只对一部分层起作用,比如 dropout层;如果有这些特殊的层,才需要调用这个语句total_test_loss = 0total_accuracy = 0with torch.no_grad(): # 这样后面就没有梯度了, 测试的过程中,不需要更新参数,所以不需要梯度?for data in test_dataloader: # 在测试集中,选取数据imgs, targets = dataoutputs = tudui(imgs) # 分类的问题,是可以这样的,用一个output进行绘制loss = loss_fn(outputs, targets)total_test_loss = total_test_loss + loss.item() # 为了查看总体数据上的 loss,创建的 total_test_loss,初始值是0accuracy = (outputs.argmax(1) == targets).sum() # 正确率,这是分类问题中,特有的一种,评价指标,语义分割之类的,不一定非要有这个东西,这里是存疑的,再看。total_accuracy = total_accuracy + accuracyprint("整体测试集上的Loss:{}".format(total_test_loss))print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size)) # 即便是输出了上一行的 loss,也不能很好的表现出效果。# 在分类问题上比较特有,通常使用正确率来表示优劣。因为其他问题,可以可视化地显示在tensorboard中。writer.add_scalar("test_loss", total_test_loss, total_test_step)writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)total_test_step = total_test_step + 1# print(total_test_step)# 保存方式一,其实后缀都可以自己取,习惯用 .pth。torch.save(tudui, "tudui_{}.pth".format(i))# 保存方式2(官方推荐)# torch.save(model.state_dict(), pth_dir + '/model_{}.pth'.format(i)print("模型已保存")writer.close()参考资料:
视频教程:PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】
相关文章:
:完整的模型训练套路)
PyTorch入门学习(十七):完整的模型训练套路
目录 一、构建神经网络 二、数据准备 三、损失函数和优化器 四、训练模型 五、保存模型 一、构建神经网络 首先,需要构建一个神经网络模型。在示例代码中,构建了一个名为Tudui的卷积神经网络(CNN)模型。这个模型包括卷积层、…...
《 Hello 算法 》 - 免费开源的数据结构与算法入门教程电子书,包含大量动画、图解,通俗易懂
这本学习算法的电子书应该是我看过这方面最好的书了,代码例子有多种编程语言,JavaScript 也支持。 《 Hello 算法 》,英文名称是 Hello algo,是一本关于编程中数据解构和算法入门的电子书,作者是毕业于上海交通大学的…...

数据库之事务
数据库之事务 事务的特点: ACID 原子性 一致性:数据库的完整性约束,不能被破坏 隔离性 持久性:数据一旦提交,事务的效果将会被永久的保留在数据库中。而且不会被回滚 主从复制 高可用 备份 权限控制 脏读&am…...
NOIP2023模拟12联测33 B. 游戏
NOIP2023模拟12联测33 B. 游戏 文章目录 NOIP2023模拟12联测33 B. 游戏题目大意思路code 题目大意 期望题 思路 二分答案 m i d mid mid ,我们只关注学生是否能够使得被抓的人数 ≤ m i d \le mid ≤mid 那我们就只关心 a > m i d a > mid a>mid 的房…...
代码随想录打卡第六十三天|84.柱状图中最大的矩形
84.柱状图中最大的矩形 题目:给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。求在该柱状图中,能够勾勒出来的矩形的最大面积。 提示: 1 < heights.length <105 0 < h…...

python tempfile 模块使用
在Python中,tempfile 模块用于创建临时文件和目录,它们可以用于存储中间处理数据,不需要长期保存。该模块提供了几种不同的类和函数来创建临时文件和目录。 下面是几个常用的 tempfile 使用方法: 临时文件 使用 NamedTemporary…...

【软件测试】接口测试实战详解
最近找到了几个问题,都还比较有代表性。 作为一个初级测试,想学接口测试,但是一点头绪都没有。求教大神指点,有没有好的书或者工具推荐?如何做接口测试呢?接口测试有哪些工具做接口测试的流程一般是怎么样…...

轻量封装WebGPU渲染系统示例<20>- 美化一下元胞自动机之生命游戏(源码)
当前示例源码github地址: https://github.com/vilyLei/voxwebgpu/blob/feature/rendering/src/voxgpu/sample/GameOfLifePretty.ts 系统特性: 1. 用户态与系统态隔离。 2. 高频调用与低频调用隔离。 3. 面向用户的易用性封装。 4. 渲染数据(内外部相关资源)和渲染机制分离…...
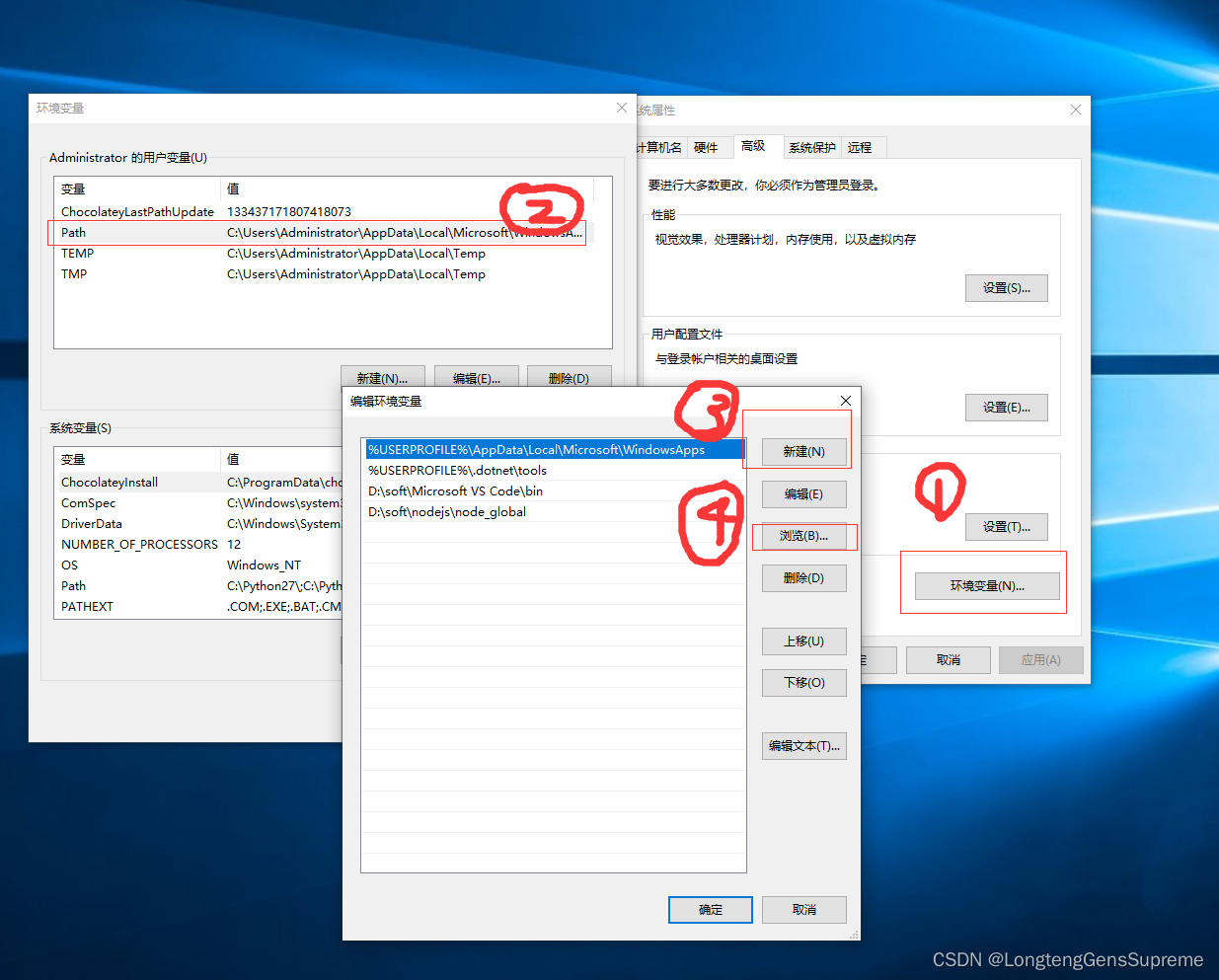
Nodejs的安装以及配置(node-v12.16.1-x64.msi)
Nodejs的安装以及配置 1、安装 node-v12.16.1-x64.msi点击安装,注意以下步骤 本文设置nodejs的安装的路径:D:\soft\nodejs 继续点击next,选中Add to PATH ,旁边的英文告诉我们会把 环境变量 给我们配置好 当然也可以只选择 Nod…...
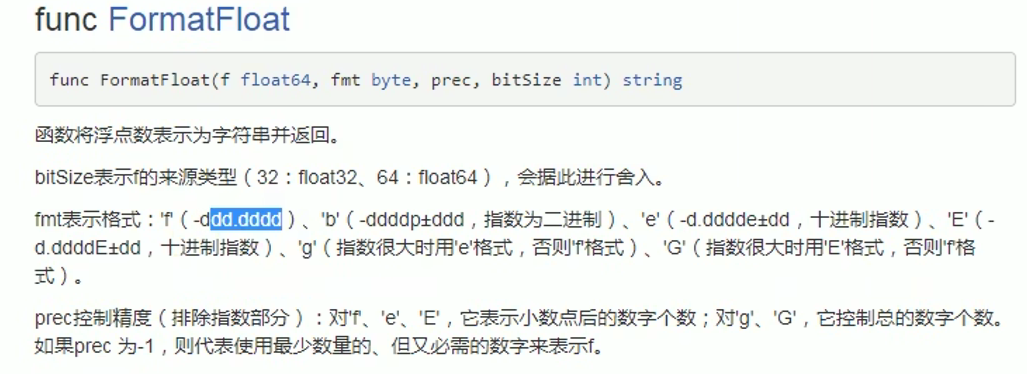
03【保姆级】-GO语言变量和数据类型和相互转换
03【保姆级】-GO语言变量和数据类型 一、变量1.1 变量的定义:1.2 变量的声明、初始化、赋值1.3 变量使用的注意事项 插播-关于fmt.Printf格式打印%的作用二、 变量的数据类型2.1整数的基本类型2.1.1 有符号类型 int8/16/32/642.1.2 无符号类型 int8/16/32/642.1.3 整…...
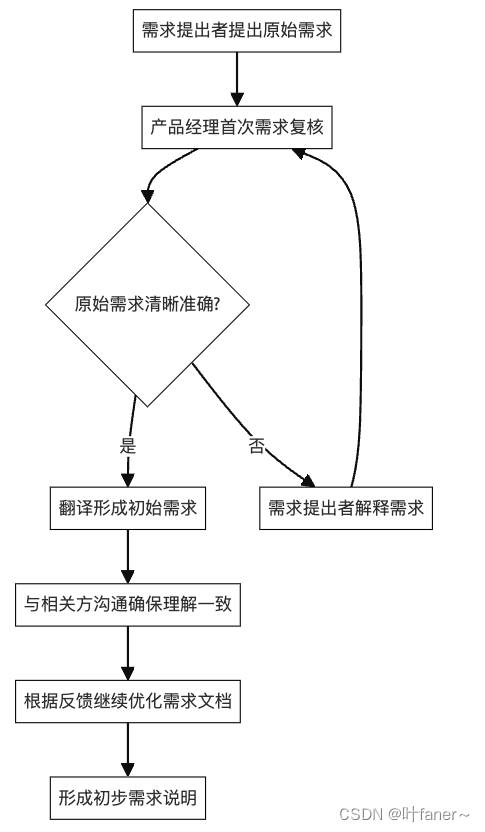
mermaid学习第一天/更改主题颜色和边框颜色/《需求解释流程图》
mermaid 在线官网: https://mermaid-js.github.io/ 在线学习文件: https://mermaid.js.org/syntax/quadrantChart.html 1、今天主要是想做需求解释的流程图,又不想自己画,就用了,框框不能直接进行全局配置࿰…...
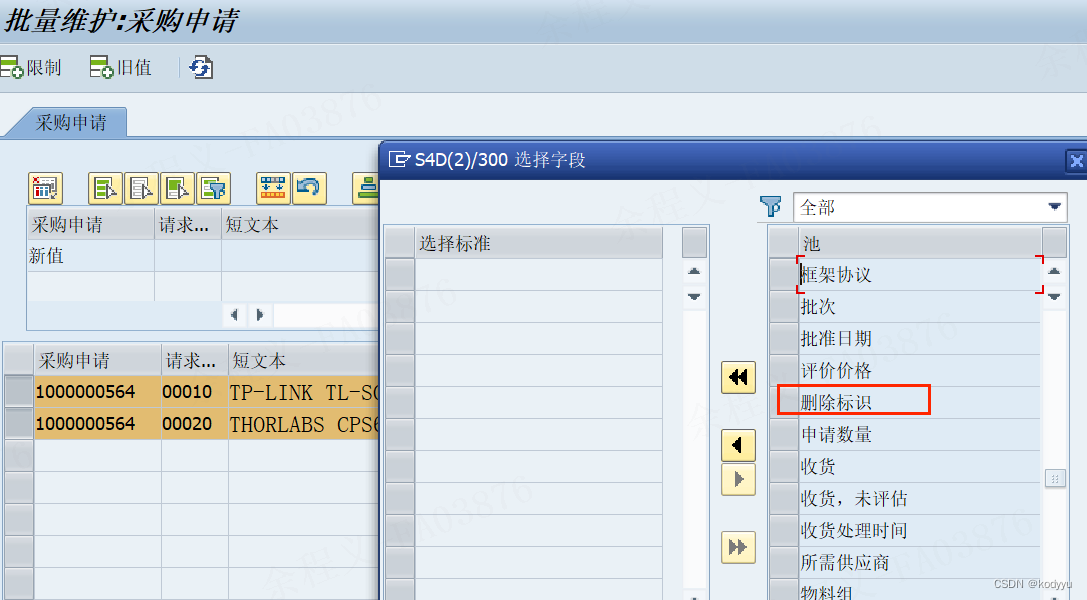
SAP MASS增加PR字段-删除标识
MASS->BUS2105->发现没有找到PR删除标识字段 SAP MASS增加PR字段-删除标识 1.tcode:MASSOBJ 选中BUS2105 点“应用程序表” 点“字段列表” 2.选中一行进行参考 3.修改字段为删除标识 LOEKZ,保存即可。 4.然后MASS操作,批量设置删除标识&…...

【手把手教你】训练YOLOv8分割模型
1.下载文件 在github上下载YOLOV8模型的文件,搜索yolov8,star最多这个就是 2. 准备环境 环境要求python>3.8,PyTorch>1.8,自行安装ptyorch环境即可 2. 制作数据集 制作数据集,需要使用labelme这个包&#…...
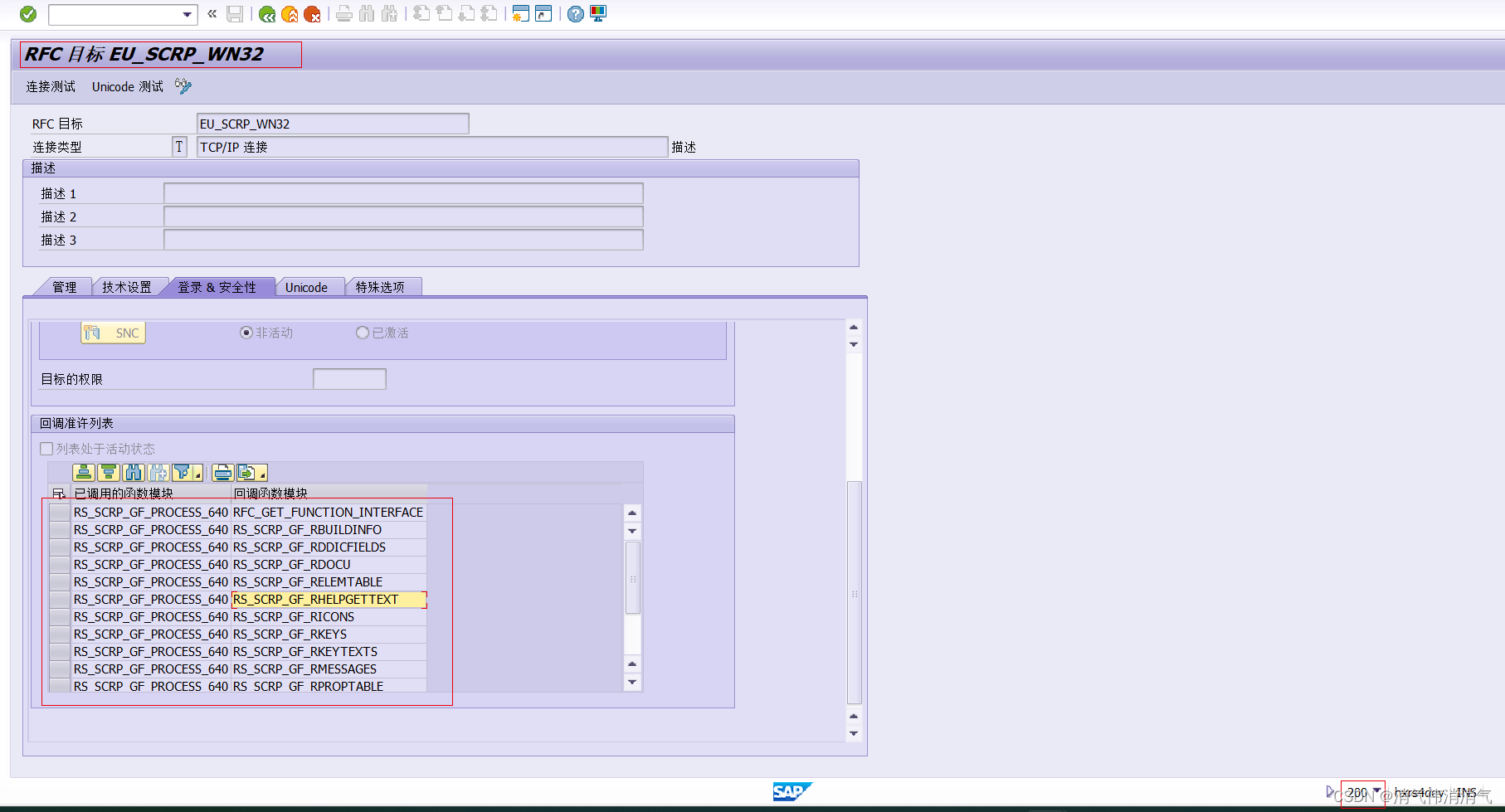
物料主数据增强屏幕绘制器DUMP
问题描述 在做完物料主数据增强后,配置和代码传Q,在Q进入增强屏幕绘制器报错。 错误 CALLBACK_REJECTED_BY_WHITELIST RFC callback call rejected by positive list An RFC callback has been prevented due to no corresponding positive list en…...

vue 实现在线预览Excel-LuckyExcel/LuckySheet实现方案
一、准备工作 1. npm安装 luckyexcel npm i -D luckyexcel 2.引入luckysheet 注意:引入luckysheet,只能通过CDN或者直接引入静态资源的形式,不能npm install。 个人建议直接下载资源引入。我给你们提供一个下载资源的地址: …...

AIGPT重大升级,界面重新设计,功能更加饱满,用户体验升级
AIGPT AIGPT是一款功能强大的人工智能技术处理软件,不但拥有其他模型处理文本认知的能力还有AI绘画模型、拥有自身的插件库。 我们都知道使用ChatGPT是需要账号以及使用魔法的,实现其中的某一项对我们一般的初学者来说都是一次巨大的挑战,但…...
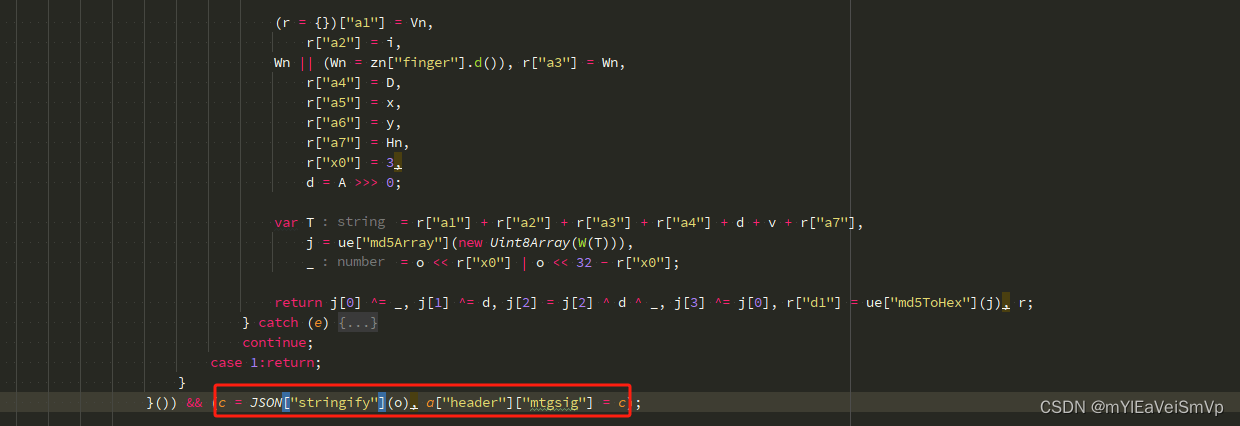
Web逆向-mtgsig1.2简单分析
{"a1": "1.2", # 加密版本"a2": new Date().valueOf() - serverTimeDiff, # 加密过程中用到的时间戳. 这次服主变坏了, 时间戳需要减去一个 serverTimeDiff(见a3) ! "a3": "这是把xxx信息加密后提交给服务器, 服主…...

【蓝桥杯省赛真题41】Scratch电脑开关机 蓝桥杯少儿编程scratch图形化编程 蓝桥杯省赛真题讲解
目录 scratch电脑开关机 一、题目要求 编程实现 二、案例分析 1、角色分析...

第10章 Java常用类
目录 内容说明 章节内容 一、Object类 二、String类和StringBuffer类 三、Math类和Random类...
.getPackageInfo 返回null)
Android 11 getPackageManager().getPackageInfo 返回null
Android11 之后, 在查找用户手机是否有安装app,进行查询包名是否存在时,getPackageManager().getPackageInfo()这个函数一直返回null ,Android 11增加了权限要求。 1、只是查询指定的App 包 只需要在Andro…...

信息系统项目管理师核心知识点精讲
一、项目整合管理(重点:项目章程与项目管理计划) 知识点详解: 项目整体管理是项目管理知识体系的核心,它确保项目各要素协调统一。在考试中,特别要掌握项目章程和项目管理计划的区别与联系。 项目章程是项目的“出生证明”,由项目发起人发布。它正式授权项目,赋予项…...

别再死记硬背SMO公式了!用Python手写一个SVM分类器,带你一步步拆解SMO核心逻辑
用Python手写SVM分类器:代码驱动理解SMO算法核心在机器学习领域,支持向量机(SVM)以其优秀的分类性能和坚实的数学基础著称。然而,许多学习者在理解其核心算法——序列最小优化(SMO)时,往往被复杂的数学推导所困扰。本文将采用一种…...

微信小程序3D开发框架技术对比:XR-Frame与threejs-miniprogram
随着微信小程序逐步支持3D渲染与AR能力,开发者面临两个主要官方方案:自研的XR-Frame和适配Three.js的threejs-miniprogram。本文将从架构设计、渲染机制、功能集成、开发模式及适用场景等维度进行技术分析,为技术选型提供参考。一、XR-Frame&…...

Python基础语法:常用内置函数
round():四舍五入 # 省略 ndigits print(round(3.14)) # 输出 3(int) print(round(3.66)) # 输出 4# 指定 ndigits print(round(3.14159, 2)) # 输出 3.14(float) print(round(3.666, 2)) # 输出 3.67# …...

LeagueAkari:英雄联盟终极自动化助手革命性指南
LeagueAkari:英雄联盟终极自动化助手革命性指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否在英雄联盟游戏中反复经历这…...

3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南
3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的…...

Python strip 与 rstrip 函数区别
Python strip 与 rstrip 函数区别 文章目录Python strip 与 rstrip 函数区别一、核心作用二、基础语法三、基础使用示例四、指定删除特定字符五、常用业务场景一、核心作用 函数作用范围strip()移除字符串首尾空白字符rstrip()仅移除字符串右侧末尾字符,左侧保持不…...

Java网络编程基础分享
在学习 Java 的过程中,网络编程是非常重要的一环。无论是后端开发、分布式系统、即时通讯、文件传输,还是游戏服务、物联网设备,都离不开网络通信一、计算机网络基础1.1 什么是计算机网络把不同地理位置、具有独立功能的计算机,通…...

《关于 AI Agent 基础设施的一些奇思妙想》
目录 目录 目录 一、AI Agent 容器 问题背景 想法思路:API 中转站模式 多 Agent 切换 二、手机端操控 AI Agent(手机与电脑互联) 三、AI 开发依赖管理工具 总结 最近 AI Agent 越来越火,我作为一个重度使用者,…...

完整解决方案:PL2303 Windows 10驱动快速安装指南
完整解决方案:PL2303 Windows 10驱动快速安装指南 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 如果你正在Windows 10系统上使用PL-2303HXA或PL-2303XA芯…...