Elasticsearch:在 ES|QL 中使用 DISSECT 和 GROK 进行数据处理
目录
DISSECT 还是 GROK? 或者两者兼而有之?
使用 DISSECT 处理数据
Dissect pattern
术语
例子
DISSECT 关键修饰符
右填充修饰符 (->)
附加修饰符 (+)
添加顺序修饰符(+ 和 /n)
命名的跳过键(?)
参考键(* 和 &)
使用 GROK 处理数据
Grok pattern
正则表达式
例子
Grok 调试器
局限性
你的数据可能包含你想要结构化的非结构化字符串。 这使得分析数据变得更加容易。 例如,日志消息可能包含你想要提取的 IP 地址,以便你可以找到最活跃的 IP 地址。
对于使用过 Logstash 及 Ingest pipeline 的开发者来说,DISSECT 及 GROK 对你们来说并不陌生。你可以参阅如下的文章:
-
Elasticsearch:深入理解 Dissect ingest processor
-
Elasticsearch:Dissect 和 Grok 处理器之间的区别
-
Logstash:使用 dissect 导入 CSV 格式文档
-
Logstash:日志解析的 Grok 模式示例
Elasticsearch 可以在索引时或查询时构建数据。 在索引时,你可以使用 Dissect 和 Grok 摄取处理器,或 Logstash Dissect 和 Grok 过滤器。 在查询时,你可以使用 ES|QL DISSECT 和 GROK 命令。
DISSECT 还是 GROK? 或者两者兼而有之?
DISSECT 的工作原理是使用基于分隔符的模式分解字符串。 GROK 的工作原理类似,但使用正则表达式。 这使得 GROK 更强大,但通常也更慢。 当数据可靠地重复时,DISSECT 效果很好。 当你确实需要正则表达式的强大功能时,例如当文本的结构因行而异时,GROK 是更好的选择。
你可以将 DISSECT 和 GROK 用于混合用例。 例如,当一行的一部分可靠地重复时,但整行则不然。 DISSECT 可以解构重复的行条部分。 GROK 可以使用正则表达式处理剩余的字段值。
使用 DISSECT 处理数据
DISSECT 处理命令将字符串与基于分隔符的模式进行匹配,并将指定的键提取为列。
例如,以下模式:
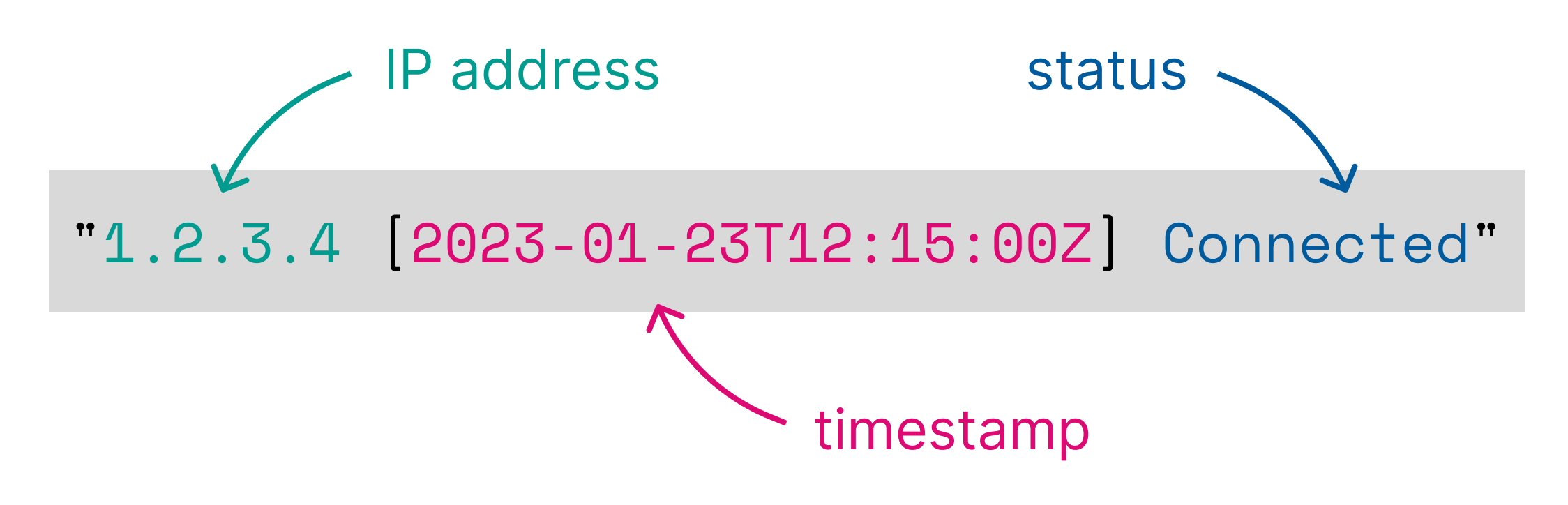
%{clientip} [%{@timestamp}] %{status}匹配以下格式的日志行:
1.2.3.4 [2023-01-23T12:15:00.000Z] Connected并将以下列添加到输入表中:
| clientip:keyword | @timestamp:keyword | status:keyword |
|---|---|---|
| 1.2.3.4 | 2023-01-23T12:15:00.000Z | Connected |
Dissect pattern
Dissect pattern 由将被丢弃的字符串部分定义。 在前面的示例中,要丢弃的第一个部分是单个空格。 Dissect 找到这个空间,然后为该空间之前的所有内容分配 clientip 的值。 接下来,dissect 匹配 [ 和 ],然后将 @timestamp 分配给 [ 和 ] 之间的所有内容。 特别注意要丢弃的字符串部分将有助于构建成功的 dissect patterns。
空键 %{} 或
命名的跳过键可用于匹配值,但从输出中排除该值。
所有匹配的值都作为关键字字符串数据类型输出。 使用类型转换函数转换为另一种数据类型。
Dissect 还支持可以更改 dissect 默认行为的键修饰符 (key modifier)。 例如,你可以指示 dissect 忽略某些字段、追加字段、跳过填充等。
术语
| 名称 | 描述 |
|---|---|
| dissect pattern | 描述文本格式的字段和分隔符集。 也称为 dissection。 使用一组 %{} 部分来描述 dissection:%{a} - %{b} - %{c} |
| 字段 | 从 %{ 到 }(含)的文本。 |
| 分隔符 | } 和接下来的 %{ 字符之间的文本。 除 %{、'not }' 或 } 之外的任何字符集都是分隔符。 |
| key | %{ 和 } 之间的文本,不包括 ?、+、& 前缀和序数后缀。 例子:
|
例子
以下示例解析包含时间戳、一些文本和 IP 地址的字符串:
ROW a = "2023-01-23T12:15:00.000Z - some text - 127.0.0.1"
| DISSECT a "%{date} - %{msg} - %{ip}"
| KEEP date, msg, ip| date:keyword | msg:keyword | ip:keyword |
|---|---|---|
| 2023-01-23T12:15:00.000Z | some text | 127.0.0.1 |
默认情况下,DISSECT 输出 keyword 字符串列。 要转换为其他类型,请使用类型转换函数:
ROW a = "2023-01-23T12:15:00.000Z - some text - 127.0.0.1"
| DISSECT a "%{date} - %{msg} - %{ip}"
| KEEP date, msg, ip
| EVAL date = TO_DATETIME(date)| msg:keyword | ip:keyword | date:date |
|---|---|---|
| some text | 127.0.0.1 | 2023-01-23T12:15:00.000Z |
DISSECT 关键修饰符
键修饰符可以更改 dissect 的默认行为。 键修饰符可能位于 %{keyname} 的左侧或右侧,且始终位于 %{ 和 } 内。 例如 %{+keyname ->} 具有追加和右填充修饰符。
| Modifier | Name | Position | Example | Description | Details |
|---|---|---|---|---|---|
|
| Skip right padding | (far) right |
| 向右跳过所有重复的字符 | link |
|
| Append | left |
| 将两个或多个字段附加在一起 | link |
|
| Append with order | left and right |
| 按指定的顺序将两个或多个字段附加在一起 | link |
|
| Named skip key | left |
| 跳过输出中的匹配值。 与 %{} 相同的行为 | link |
|
| Reference keys | left |
| 将输出键设置为 * 值和 & 输出值 | link |
右填充修饰符 (->)
执行解析的算法非常严格,因为它要求模式中的所有字符都与源字符串匹配。 例如,模式 %{fookey} %{barkey} (1 个空格)将匹配字符串 “foo bar”(1 个空格),但不会匹配字符串“foo. bar”(2 个空格),因为该模式只有 1 个空格,源字符串有 2 个空格。
正确的填充修饰符有助于解决这种情况。 将右侧填充修饰符添加到模式 %{fookey->} %{barkey},现在它将匹配“foo bar”(1 个空格)和 “foo bar”(2 个空格),甚至“foo bar”(10 个空格) )。
使用右侧填充修饰符以允许在 %{keyname->} 之后重复字符。
右填充修饰符可以与任何其他修饰符一起放置在任何键上。 它应该始终是最右边的修饰符。 例如:%{+keyname/1->} 和 %{->}
右填充修饰符示例:
| Pattern |
|
| Input | 1998-08-10T17:15:42,466 WARN |
| Result |
|
右侧填充修饰符可以与空键一起使用,以帮助跳过不需要的数据。 例如,相同的输入字符串,但用括号括起来,需要使用空的右填充键来实现相同的结果。
带有空键的右填充修饰符示例
| Pattern |
|
| Input | [1998-08-10T17:15:42,466] [WARN] |
| Result |
|
附加修饰符 (+)
Dissect 支持将两个或多个结果附加在一起以进行输出。 值从左到右附加。 可以指定附加分隔符。 在此示例中,append_separator 被定义为空格。
附加修饰符示例:
| Pattern |
|
| Input | john jacob jingleheimer schmidt |
| Result |
|
添加顺序修饰符(+ 和 /n)
Dissect 支持将两个或多个结果附加在一起以进行输出。 值根据定义的顺序 (/n) 附加。 可以指定附加分隔符。 在此示例中,append_separator 被定义为逗号。
附加顺序修饰符示例:
| Pattern |
|
| Input | john jacob jingleheimer schmidt |
| Result |
|
命名的跳过键(?)
Dissect 支持忽略最终结果中的匹配项。 这可以使用空键 %{} 来完成,但为了可读性,可能需要为该空键命名。
命名的跳过键修饰符示例:
| Pattern |
|
| Input | 1.2.3.4 - - [30/Apr/1998:22:00:52 +0000] |
| Result |
|
参考键(* 和 &)
Dissect 支持使用解析值作为结构化内容的 key/value。 想象一个部分记录 key/value 对的系统。 引用键允许你维护该键/值关系。
参考键修饰符示例:
| Pattern |
|
| Input | [2018-08-10T17:15:42,466] [ERR] ip:1.2.3.4 error:REFUSED |
| Result |
|
使用 GROK 处理数据
GROK 处理命令将字符串与基于正则表达式的模式进行匹配,并将指定的键提取为列。
例如,以下模式:
%{IP:ip} \[%{TIMESTAMP_ISO8601:@timestamp}\] %{GREEDYDATA:status}匹配以下格式的日志行:
1.2.3.4 [2023-01-23T12:15:00.000Z] Connected并将以下列添加到输入表中:
| @timestamp:keyword | ip:keyword | status:keyword |
|---|---|---|
| 2023-01-23T12:15:00.000Z | 1.2.3.4 | Connected |
Grok pattern
Grok 模式的语法是 %{SYNTAX:SEMANTIC}
SYNTAX 是与你的文本匹配的模式的名称。 例如,3.44 通过 NUMBER 模式匹配,55.3.244.1 通过 IP 模式匹配。 语法就是你如何匹配。
语义是你为匹配的文本片段提供的标识符。 例如,3.44 可能是事件的持续时间,因此你可以将其简称为 duration。 此外,字符串 55.3.244.1 可以标识发出请求的 client。
默认情况下,匹配的值作为关键字字符串数据类型输出。 要转换语义的数据类型,请在其后面加上目标数据类型的后缀。 例如 %{NUMBER:num:int},它将 num 语义从字符串转换为整数。 目前唯一支持的转换是 int 和 float。 对于其他类型,请使用类型转换函数。
有关可用模式的概述,请参阅 GitHub。 你还可以使用 REST API 检索所有模式的列表。
正则表达式
Grok 基于正则表达式。 任何正则表达式在 grok 中也有效。 Grok 使用 Oniguruma 正则表达式库。 有关完整支持的正则表达式语法,请参阅 Oniguruma GitHub 存储库。
注意:特殊的正则表达式字符如 [ 和 ] 需要用 \ 转义。 例如,在之前的模式中:
%{IP:ip} \[%{TIMESTAMP_ISO8601:@timestamp}\] %{GREEDYDATA:status}在 ES|QL 查询中,反斜杠字符本身是一个特殊字符,需要用另一个 \ 进行转义。 对于此示例,相应的 ES|QL 查询变为:
ROW a = "1.2.3.4 [2023-01-23T12:15:00.000Z] Connected" | GROK a "%{IP:ip} \\[%{TIMESTAMP_ISO8601:@timestamp}\\] %{GREEDYDATA:status}"
定制 patterns
如果 grok 没有你需要的模式,你可以使用 Oniguruma 语法进行命名捕获,它可以让你匹配一段文本并将其保存为一列:
(?<field_name>the pattern here)例如,postfix 日志的 queue id 是 10 或 11 个字符的十六进制值。 可以使用以下命令将其捕获到名为 queue_id 的列中:
(?<queue_id>[0-9A-F]{10,11})例子
以下示例解析包含时间戳、IP 地址、电子邮件地址和数字的字符串:
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 some.email@foo.com 42"
| GROK a "%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num}"
| KEEP date, ip, email, num| date:keyword | ip:keyword | email:keyword | num:keyword |
|---|---|---|---|
| 2023-01-23T12:15:00.000Z | 127.0.0.1 | some.email@foo.com | 42 |
默认情况下,GROK 输出关键字字符串列。 int 和 float 类型可以通过将 :type 附加到模式中的语义来转换。 例如 {NUMBER:num:int}:
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 some.email@foo.com 42"
| GROK a "%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num:int}"
| KEEP date, ip, email, num| date:keyword | ip:keyword | email:keyword | num:integer |
|---|---|---|---|
| 2023-01-23T12:15:00.000Z | 127.0.0.1 | some.email@foo.com | 42 |
对于其他类型转换,请使用类型转换函数:
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 some.email@foo.com 42"
| GROK a "%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num:int}"
| KEEP date, ip, email, num
| EVAL date = TO_DATETIME(date)| ip:keyword | email:keyword | num:integer | date:date |
|---|---|---|---|
| 127.0.0.1 | some.email@foo.com | 42 | 2023-01-23T12:15:00.000Z |
Grok 调试器
要编写和调试 grok 模式,你可以使用 Grok 调试器。 它提供了一个用于根据示例数据测试模式的 UI。 在幕后,它使用与 GROK 命令相同的引擎。
局限性
GROK 命令不支持配置自定义模式或多个模式。 GROK 命令不受 Grok 看门狗设置的约束。
相关文章:
Elasticsearch:在 ES|QL 中使用 DISSECT 和 GROK 进行数据处理
目录 DISSECT 还是 GROK? 或者两者兼而有之? 使用 DISSECT 处理数据 Dissect pattern 术语 例子 DISSECT 关键修饰符 右填充修饰符 (->) 附加修饰符 () 添加顺序修饰符( 和 /n) 命名的跳过键(?…...

基于自适应自回归模型的高级人工智能概念及其实现
基于自适应自回归模型的高级人工智能概念及其实现 摘要:一、引言:二、方法:三、讨论:四、结论:草稿实现计算摘要: 在人工智能研究领域中,预测未来的信息往往会遇到信息不明确的问题,尤其是在自回归模型中,这一问题尤为突出。本研究提出一个新颖的假设,将能自主解决信…...
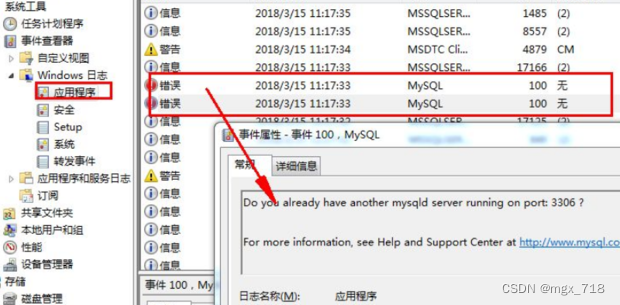
windows的mysql启动错误,查看windows日志
1、点击左下角开始按钮,计算机上右键,点击【管理】。 2、在计算机管理界面依次找到【系统工具】,选择【时间查看器】,打开【windows日志】,点击【应用程序】 3、在右侧找到,最新的mysql错误信息。双击查看。…...
centos7部署Canal与Canal集成使用
1、简介 canal [kə’nl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费 早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigge…...
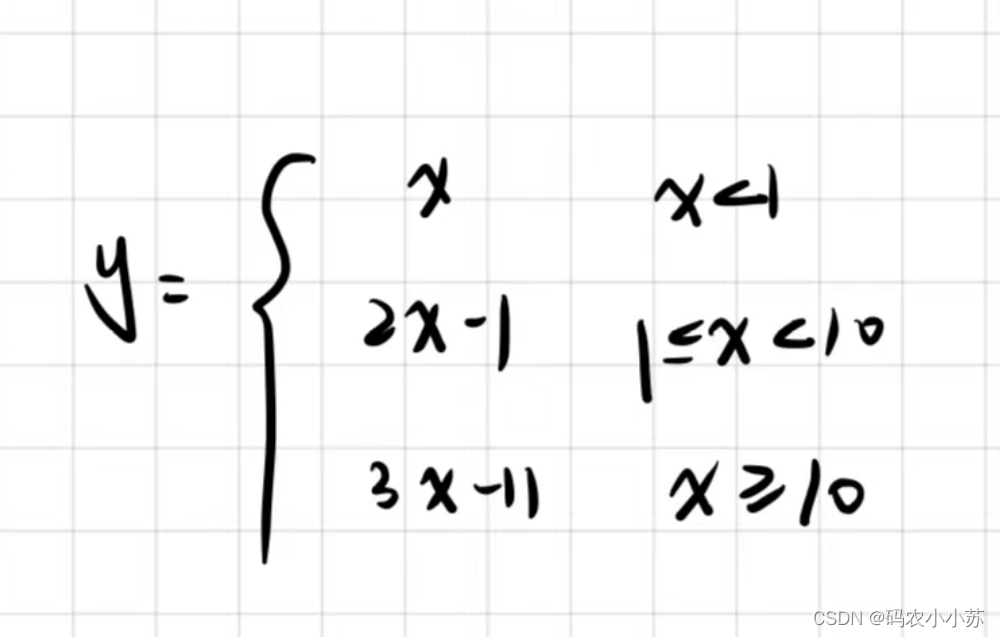
C语言--分段函数--switch语句
如何用switch语句写分段函数呢?⭐️ 首先介绍一下switch语句的语法规则⭐️ switch(整形表达式) {case 常量表达式1; //标签必须唯一语句块1;break;case 常量表达式2; //if(a0),而case中时系统自动加语句块2;break;c…...
)
动态规划31(Leetcode188买卖股票的最佳时机4)
代码: 我的状态方程: buy[i][j]max{buy[i−1][j],sell[i−1][j-1]−price[i]} 题解里的: buy[i][j]max{buy[i−1][j],sell[i−1][j]−price[i]} ..没理解题解的 但我的通过了 class Solution {public int maxProfit(int k, int[] pric…...

npm包管理相关命令
前置条件,准备npm账号,并登录,npm login 或者 npm adduser (这一行同样需要输入账号密码登录,之后就不用登录了) 验证是否登录:npm whoami 还可以查看用户简介:npm profile get …...
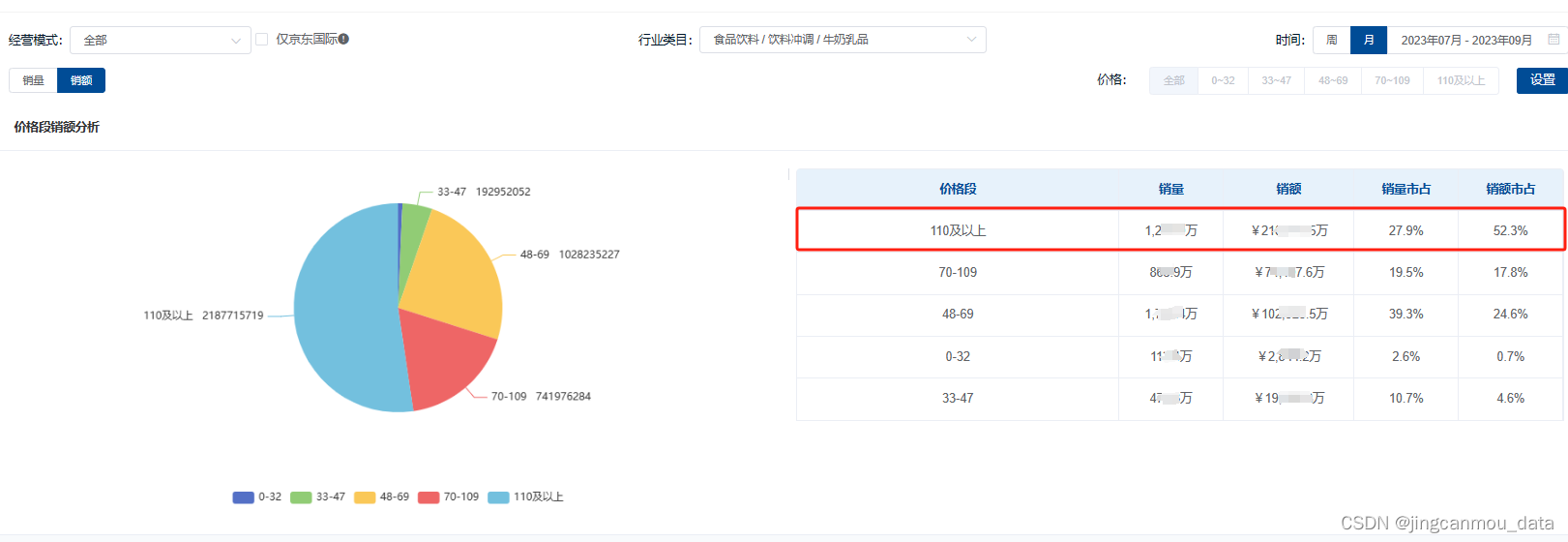
2023年Q3乳品行业数据分析(乳品市场未来发展趋势)
随着人们生活水平的不断提高以及对健康生活的追求不断增强,牛奶作为优质蛋白和钙的补充品,市场需求逐年增加。 今年Q3,牛奶乳品市场仍呈增长趋势。根据鲸参谋电商数据分析平台的相关数据显示,2023年7月-9月,牛奶乳品市…...
)
软考 系统架构设计师系列知识点之边缘计算(2)
接前一篇文章:软考 系统架构设计师系列知识点之边缘计算(1) 所属章节: 第11章. 未来信息综合技术 第4节. 边缘计算概述 3. 边缘计算的特点 边缘计算是在靠近物或数据源头的网络边缘侧,融合网络、计算、存储、应用核心…...
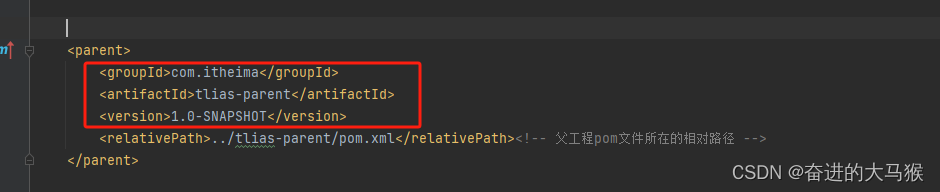
Maven中的继承与聚合
一,继承 前面我们将项目拆分成各个小模块,但是每个小模块中有很多相同的依赖于是我们创建一个父工程将模块中相同的依赖定义在父工程中,然后子工程继承父工程Maven作用:简化依赖配置,统一依赖管理,可以实现多重继承像J…...
第三章 UI开发的点点滴滴
一、常用控件的使用方法 1.TextView android:gravity"center" 可选值:top、bottom、left、right、center等,可以用"|"来同时指定多个值,center表示文字在垂直和水平方向都居中 android:textSize 指定文字的大小&#…...
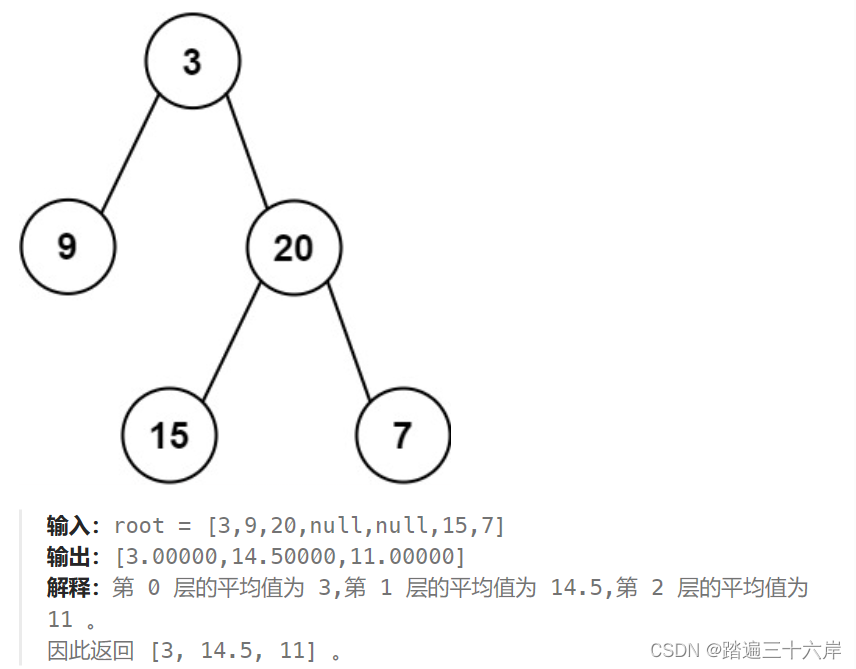
637. 二叉树的层平均值
描述 : 给定一个非空二叉树的根节点 root , 以数组的形式返回每一层节点的平均值。与实际答案相差 10-5 以内的答案可以被接受。 题目 : 637. 二叉树的层平均值 分析 : 这个题和前面的几个一样,只不过是每层都先将元素保存下来,最后求平均就行了: 解…...
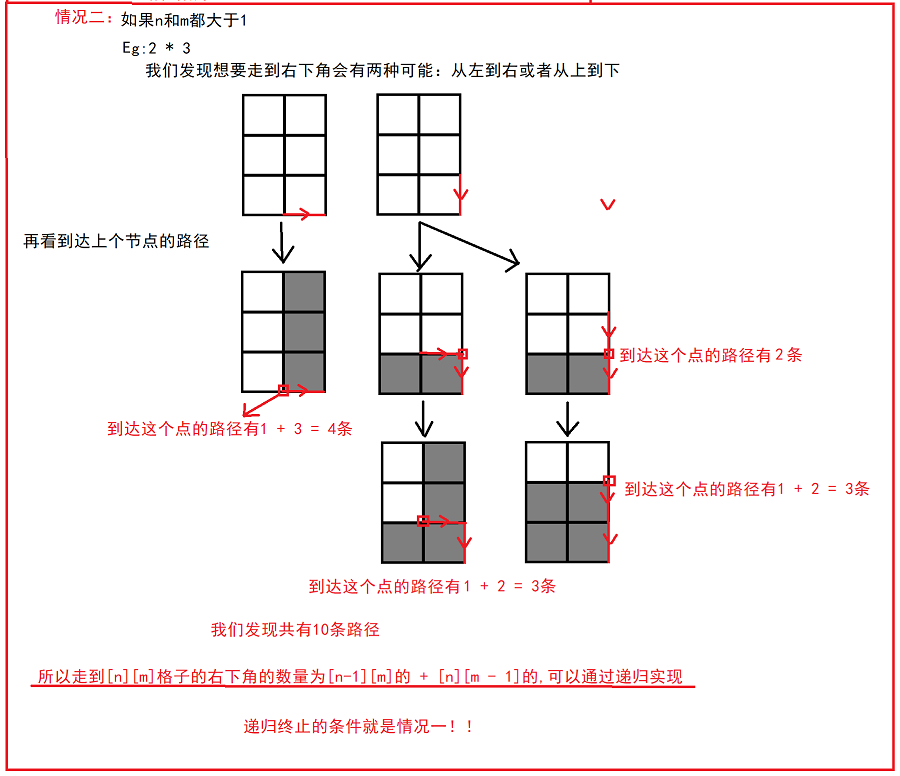
【Java笔试强训】Day9(CM72 另类加法、HJ91 走方格的方案数)
CM72 另类加法 链接:另类加法 题目: 给定两个int A和B。编写一个函数返回AB的值,但不得使用或其他算数运算符。 题目分析: 代码实现: package Day9;public class Day9_1 {public int addAB(int A, int B) {// wr…...

django REST框架- Django-ninja
Django 是我学习的最早的web框架,大概在2014年,当时选他原因也很简单就是网上资料比较丰富,自然是遇到问题更容易找答案,直到 2018年真正开始拿django做项目,才对他有了更全面的了解。他是一个入门有门槛,学…...

数据结构与算法C语言版学习笔记(3)-线性表的链式结构:链表
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言:回顾顺序表的优缺点:为什么要引入链式结构的线性表? 一、什么是链表?二、链表的分类①为什么要设置头节点&…...
)
Web学习笔记-Vue3(环境配置、概念、整体布局设计)
笔记内容转载自 AcWing 的 Web 应用课讲义,课程链接:AcWing Web 应用课。 CONTENTS 1. 环境配置2. 基本概念3. 导航栏4. 页面创建5. 用户动态页面实现 Vue 官网:Vue.js。 Vue.js 是一款用于构建用户界面的 JavaScript 框架。它基于标准 HTML…...
【React-Native开发3D应用】React Native加载GLB格式3D模型并打包至Android手机端
【React-Native开发3D应用】React Native加载GLB格式3D模型并打包至Android手机端 【加载3D模型】**React Native上如何加载glb格式的模型**第零步,选择相关模型第一步,导入相关模型加载库第二步,自定义GLB模型加载钩子第三步,借助…...

python的列表
定义 列表 是python中的一种数据类型,可以存放多个数据,列表中的数据可以是任意类型的。 格式 格式: my_list [] my_list list() 定义一个空的列表,有如上两种方式 遍历 for 循环 while循环 列表添加操作 列表添加操作有…...

[100天算法】-最短无序连续子数组(day 66)
题目描述 给定一个整数数组,你需要寻找一个连续的子数组,如果对这个子数组进行升序排序,那么整个数组都会变为升序排序。你找到的子数组应是最短的,请输出它的长度。示例 1:输入: [2, 6, 4, 8, 10, 9, 15] 输出: 5 解释: 你只需要…...
001. 变量、环境变量
1、在终端中显示输出 shell脚本通常以shebang起始:#!/bin/bash/ shebang是一个文本行,其中#!位于解释器路径之前。/bin/bash是Bash的解释器命令路径。bash将以#符号开头的行视为注释。脚本中只有第一行可以使用shebang来定义解释该脚本所使…...

5分钟彻底清理Windows 11:Win11Debloat终极免费优化指南
5分钟彻底清理Windows 11:Win11Debloat终极免费优化指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and …...

KMS智能激活工具:三步实现Windows和Office永久激活的完整方案
KMS智能激活工具:三步实现Windows和Office永久激活的完整方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突然…...
)
大模型面试通关秘籍:面试官亲划的5大核心考点(附满分回答模板)
别再背500页的面试宝典了!Transformer、RAG、Agent、工程化...真正能帮你拿Offer的,只有这5张表前言:面试官到底想听什么?很多候选人面试大模型岗位时,最大的误区就是“背概念而不是讲逻辑”。举个例子:问“…...

日常实用娱乐向|无需下载任何播放器!万能M3U8在线播放神器,追剧看直播永久备用
开篇前言 不管是电脑办公闲暇追剧,还是手机随身看各类直播源、高清影视资源,很多优质流媒体资源都是M3U8格式。但用过的朋友都知道,这种格式非常特殊,电脑自带播放器无法直接打开,手机普通视频软件也不支持解析。专门…...

智能运维+多模型服务能力,阿里云 RDS AI 助手旗舰版正式上线!
数据库运维团队常常面临两大难题:一是混杂在阿里云、自建和他云上的各类数据库难以统一管理;二是想利用大模型能力提升运维效率,却要分别对接多个厂商的 API、管理多套密钥、承担高昂的集成成本。 RDS AI 助手旗舰版在 RDS AI 助手专业版智能…...

【技术视角】从0到1拆解机乎AI:AI社交平台的技术架构与产品设计
前言最近在研究AI社交赛道,发现了一个有意思的产品——机乎AI。作为国内头部的AI社交平台,它的架构设计和产品逻辑有不少值得学习的地方。今天从技术视角做一个深度拆解,聊聊它的核心机制和技术实现思路。一、产品定位与技术选型机乎AI的产品…...

告别信号衰减!PCIe 5.0硬件设计实战:从板材选择到玻纤效应的完整避坑指南
PCIe 5.0硬件设计实战:从板材选择到玻纤效应的完整避坑指南 当32GT/s的高速信号在PCB走线上疾驰时,每一个设计细节都可能成为性能的绊脚石。作为经历过三代PCIe标准迭代的硬件工程师,我至今记得第一次看到PCIe 5.0眼图崩溃时的震撼——那些理…...
)
别再死记硬背了!用Python快速查询和解析DICOM Tag(附常用标签速查表)
用Python高效解析DICOM标签的工程实践指南 在医学影像处理领域,DICOM文件就像一座数据金矿,而标签(Tag)则是打开这座金矿的钥匙。但面对上千个可能的标签,开发者常常陷入两难:要么依赖厚重的DICOM标准文档缓…...

HTML函数在多GPU系统中如何调用_显卡切换机制说明【汇总】
cudaSetDevice()必须在任何CUDA上下文创建前调用,否则无效;CUDA_VISIBLE_DEVICES是设备重映射而非过滤;PyTorch与TensorFlow需硬隔离或内存增长配置;NCCL通信依赖硬件拓扑与环境变量对齐。GPU设备索引不生效:为什么cud…...

从Navicat 16.3降级到15.0:老版本更香?一份平滑降级与数据迁移的实操指南
Navicat版本降级实战:从16.3回退15.0的全流程解析 当Navicat 16.3的注册问题成为工作流程中的绊脚石时,许多用户开始重新审视版本升级的必要性。作为数据库管理工具,Navicat的每个大版本更新确实会带来新功能,但并非所有用户都需要…...