Alphago Zero的原理及实现:Mastering the game of Go without human knowledge
近年来强化学习算法广泛应用于游戏对抗上,通用的强化学习模型一般包含了Actor模型和Critic模型,其中Actor模型根据状态生成下一步动作,而Critic模型估计状态的价值,这两个模型通过相互迭代训练(该过程称为Generalized Policy Iteration GPI过程),最终将收敛到某个近优的点。
但对于围棋游戏来说,早些年很多人作为通过计算机来战胜人类顶尖棋手是不可能的,因为围棋总共下法大概在范围,比可观测宇宙的原子数目都要大很多,如此巨大的状态空间和动作空间,通过传统的强化学习方法来进行探索几乎是不可能的。
早期Alphago所采用方法是先通过监督学习专家决策序列,然后再通过强化学习策略来优化。而Alphago Zero是Alphago的升级版,它完全依赖自我对弈的强化学习,无需人类专家的动作监督。
Alphago Zero通过采用MCTS策略,从大量的动作空间中搜索当前最优的动作序列,然后让模型根据这些最优动作序列进行训练,不需要先监督学习专家决策,就能通过自我学习达成最优的效果。
Alphago Zero的训练主要分为了self-play、训练网络和网络评估三个阶段:
1. self-play阶段
在self-play阶段,采用了一种高效样本探索策略MCTS(Monte Carlo Tree Search),其从庞大的动作空间中寻找出当前最优的动作序列,并将其作为后续强化模型训练的优质样本。通过这种方式,MCTS能够在大规模、复杂的环境中做出明智且有效的决策,并帮忙逐步优化强化模型的学习。
在每轮self-play过程中,都会通过MCTS策略采样生成一系列的游戏轮数,每轮游戏都是指游戏结束(直接出现获胜者)或者游戏步数达到设定最大值(以当前游戏得分判定获胜者)。
每轮游戏都包含围棋双方在整轮过程全部(状态State、动作Action、价值Value)元组,其都是根据MCTS策略进行决策和计算的。每轮游戏在开始前,会构建一个搜索树,然后依次根据当前状态决策动作,具体决策动作方式:
在每轮self-play过程中,通过MCTS策略进行采样,生成一系列的游戏轮次。每轮游戏以两种方式结束:一是游戏直接出现获胜者,二是游戏步数达到设定的最大值,此时根据当前游戏得分判定获胜者。
每轮游戏都会记录下围棋双方的完整过程,包括每步中状态State、动作Action和价值Value等信息,这些数据都是基于MCTS策略进行决策和计算的。
-
状态State:这是围棋的当前局面,包括棋盘上的黑白棋子布局、提子情况等。
-
动作Action:这是围棋的下一步行动(如落子在棋盘的某个位置)。
-
价值Value:当前状态下的获胜概率
每轮游戏在开始之前会构建一个搜索树,然后根据当前状态依次决策动作。具体决策动作的方式如下:
- 动作选择概率
计算,其中
是归一化因子,
是温度控制的超参数,可以随着本轮动作进行,会越趋向于选择概率最大的动作。
的计算逻辑:
- 如果
已经在搜索树中,即该轮游戏已经探索。
- 选择最优的动作,此时为
的一次访问
是一个平衡先验后验动作概率的超参数。
-
表示当前状态-动作的价值估计累计值,
表示当未探索结点为对手状态时取负号,否则为正号。
-
表示当前状态-动作在本轮游戏的访问次数,每轮访问后$+1$
-
表示当前状态的本轮游戏的访问次数
-
-
表示归一化的模型先验预估动作概率
- 选择最优的动作,此时为
-
如果
-
通过模型求解
、
,并返回。
-
-
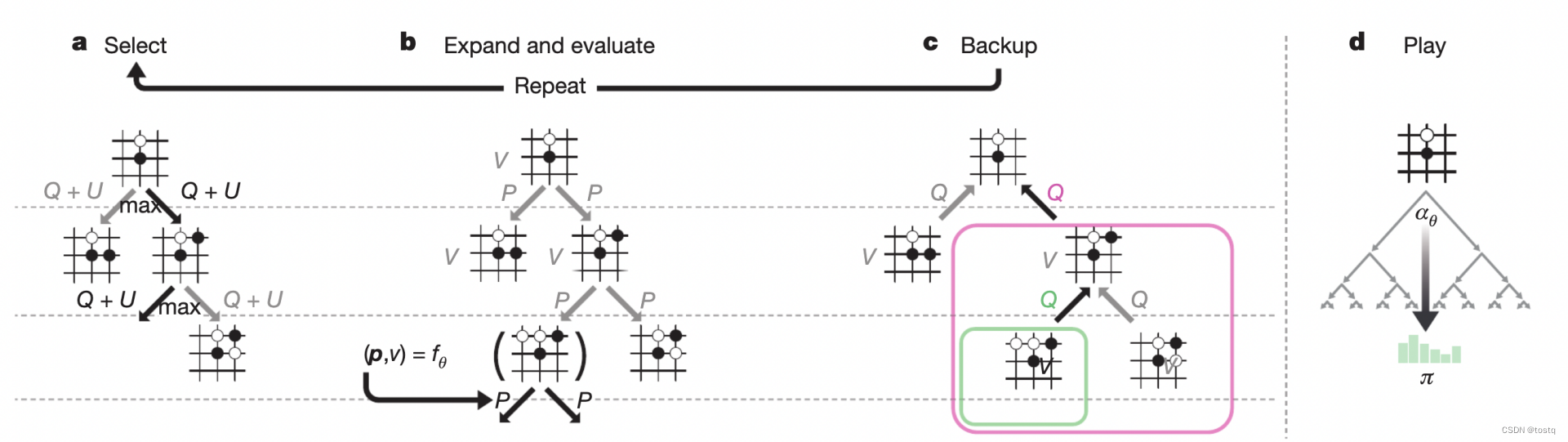
上述过程也可以用select、expand、Backup、play四个阶段来表示:
- Select:表示选择最优的动作
- Expand:表示在选择最优动作后,一直继续探索直到一个未探索的结点,通过模型预估其先验动作概率
及状态价值
,如果是中途遇到已探索的结点,通过Select选择最优的动作。
- Backup:表示在探索直到一个未探索的结点后,沿路径更新树上各状态结点的
、
- Play:该轮游戏采样并确定动作,进入下一状态。
- Select:表示选择最优的动作
2. 训练网络阶段
经过每轮self-play后,会生成一系列的游戏轮数,每轮游戏都会保存正反双方在每步的状态、动作概率
、价值
,作为此轮网络训练阶段的数据,其中:
-
表示当前状态
,分别表示负平胜。
-
表示根据该轮游戏在过程中的双方的得分数归一化的值。
-
表示该轮游戏总共的走子数,该项主要是为了平衡初始开局的噪声。
最终loss包含了三个部分:动作分类交叉熵损失、价值预估的MSE损失、参数正则项
3. 网络评估阶段
该阶段主要判断上述经过新一轮训练后的新模型是否是最优,如果是最优的替换最优模型进入下一轮的self-play阶段。
评估最优的方式同self-play阶段是类似的,每一步动作都是还需要通过MCTS策略来进行决策。只不过正反双方分别基于基线模型和更新模型来进行比较。
4. 特征组织形式

-
状态
,其中
表示围棋棋盘的二维结构,并在第3维叠加黑白双方在过去8步的位置信息,另外为了区分当前走子是黑子还是白子,增加了一维来标识。
-
动作
的维度为
,表示在
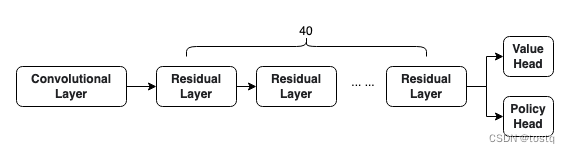
5. 模型结构
-
输入卷积层:

-
残差模块层

-
policy层

-
value层

相关文章:
Alphago Zero的原理及实现:Mastering the game of Go without human knowledge
近年来强化学习算法广泛应用于游戏对抗上,通用的强化学习模型一般包含了Actor模型和Critic模型,其中Actor模型根据状态生成下一步动作,而Critic模型估计状态的价值,这两个模型通过相互迭代训练(该过程称为Generalized …...
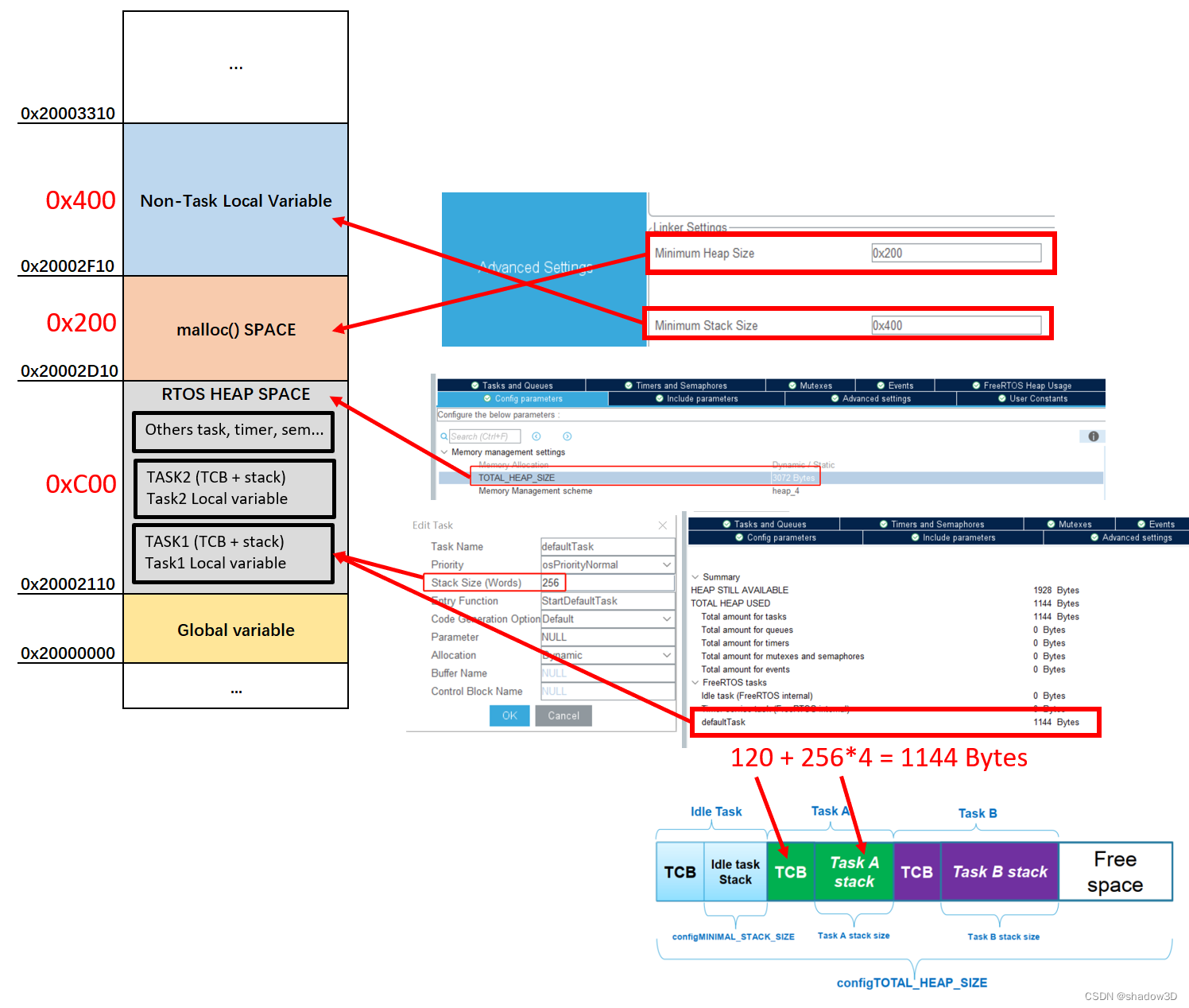
STM32 堆栈空间分布
参考 运行时访问__initial_sp和__heap_base 无RTOS时的情况 在以上配置的情况下,生成工程。在工程的startup.s文件中,由如下代码: Stack_Size EQU 0x400AREA STACK, NOINIT, READWRITE, ALIGN3 __Stack_top ; 自己添加 Stack_Mem…...

小程序制作(超详解!!!)第十五节 自动随机变化的三色旗
1.例题描述 设计一个小程序,开始时界面上显示一个三色旗和一个按钮,当点击按钮时,三色旗的颜色会发生随机变化,即使不点击按钮,三色旗的颜色也会每隔一定时间自动发生变化。 2.index.wxml <view class"box&…...

MySQL_主从复制_环境搭建
MySQL主从复制配置 CentOS 7 配置 阿里云 yum 源 sudo mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup sudo wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo sudo yum clean all sudo yum makeca…...
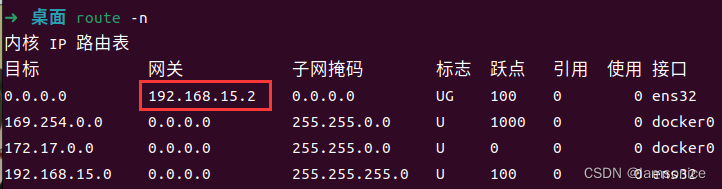
Linux 设置静态IP(Ubuntu 20.04/18.04)
以Ubuntu20.04示例 第一步:查看当前网络信息 ifconfig 本机网卡名为:ens32,IP地址为:192.168.15.133,子网掩码为:255.255.255.0 第二步:查看当前网关信息 route -n 网关地址为:1…...
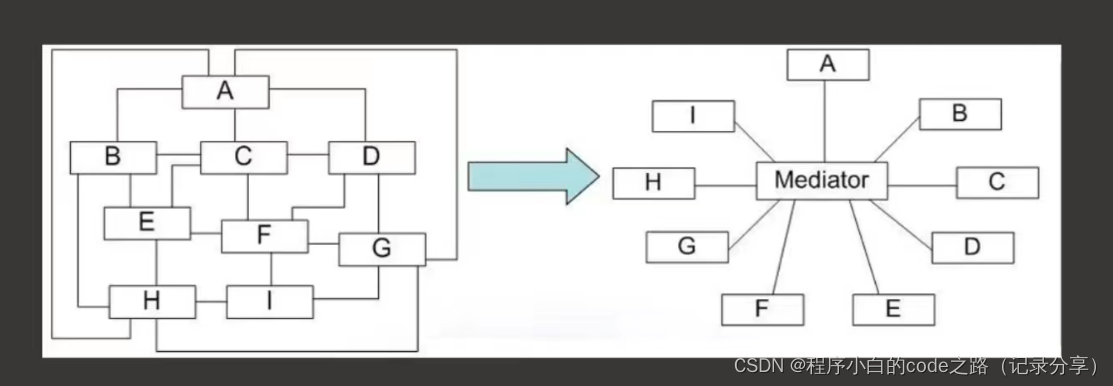
计网----累积应答,TCP的流量控制--滑动窗口,粘包问题,心跳机制,Nagle算法,拥塞控制,TCP协议总结,UDP和TCP对比,中介者模式
计网----累积应答,TCP的流量控制–滑动窗口,粘包问题,心跳机制,Nagle算法,拥塞控制,TCP协议总结,UDP和TCP对比,中介者模式 一.累积应答 1.什么是累计应答 每次发一些包࿰…...

OpenCV 直方图和归一化
直方图可以反映图片的整体统计信息, 使用函数 CalcHist() 实现. 但CalcHist() 统计出的数量信息和图像大小相关, 如果要剔除图像大小因素, 需要做归一化处理, 归一化处理后的信息, 反映出各个颜色值得占比情况, 这样更方便不同size图像做对比, 归一化的函数为 Normalize(). ///…...
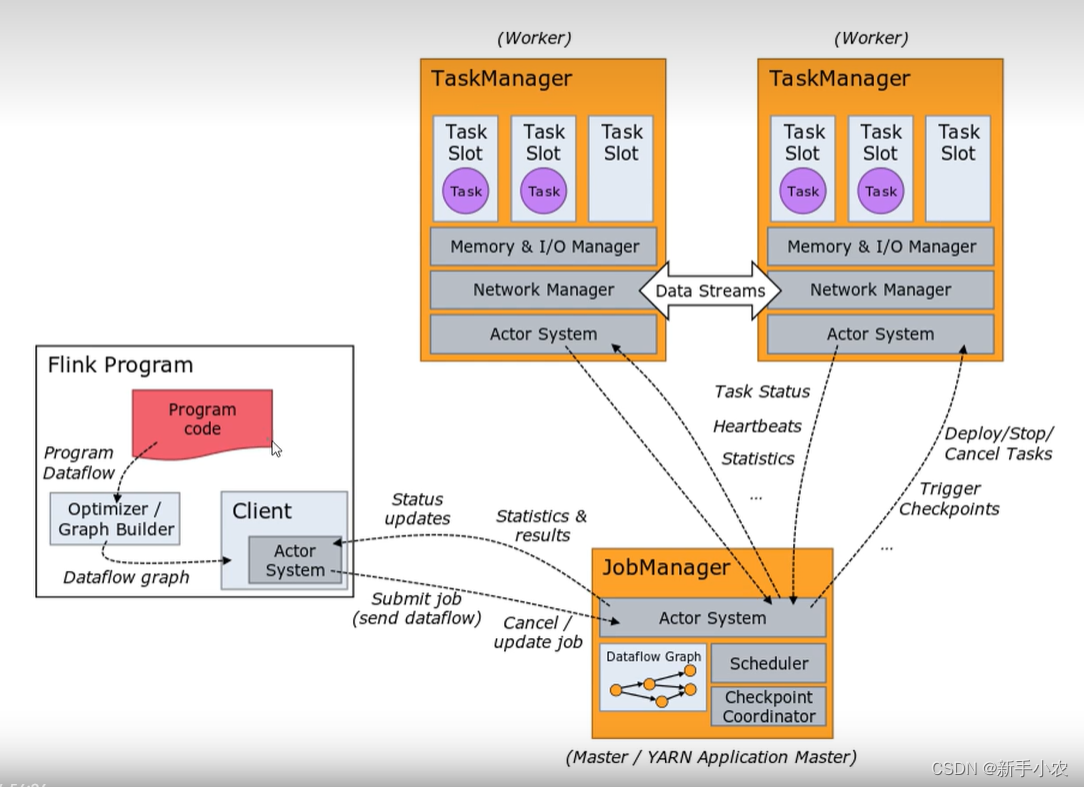
Flink架构
1、Apache Flink集群的核心架构: 1、client(作业客户端):提交任务的地方叫做客户端 2、JobManager(作业管理器):作用是用于管理集群中任务 3、TaskManager(任务管理器)&a…...

Packet Tracer路由器连接终端设备怎么配置?
在Packet Tracer中配置一台路由器和三台终端设备可以帮助你建立一个简单的局域网,以下是配置的基本步骤: 打开Packet Tracer,从左侧设备栏中拖拽一个路由器和三个终端设备到工作区。 连接设备:使用网线将路由器的端口与每台终端设…...

评估APP网页小程序代码UI开发H5估价师怎么评估开发精确研发价格?
作为一名应用程序开发评估师,可能涉及到的主要任务是为特定的应用程序提供估算开发成本和所需时间预测。为了为一个应用程序更准确地评估价格,须遵循以下几个步骤: 问: 如何让一个App更好、更精确地评估出价格? 答: 以下是一个可…...

16 Linux 内核定时器
一、Linux 时间管理和内核定时器简介 1. 内核时间管理简介 Linux 内核中有大量的函数需要时间管理,比如周期性的调度程序、延时程序、定时器等。 硬件定时器提供时钟源,时钟源的频率可以设置,设置好以后就周期性的产生定时中断,系…...

C++11 shared_ptr类型智能指针学习
智能指针和普通指针的用法类似,但是智能指针可以在适当时机自动释放分配的内存。 C++11有三种类型的智能指针,shared_ptr、unique_ptr 以及 weak_ptr; 先学习shared_ptr类型; shared_ptr<T> 的定义位于<memory>头文件,并位于 std 命名空间中; T 表示指针指…...

网络流量分类概述
1. 什么是网络流量? 一条网络流量是指在一段特定的时间间隔之内,通过网络中某一个观测点的所有具有相同五元组(源IP地址、目的IP地址、传输层协议、源端口和目的端口)的分组的集合。 比如(10.134.113.77,47.98.43.47,TLSv1.2&…...

JavaWeb篇_02——服务器简介及Tomcat服务器简介
服务器简介 硬件服务器的构成与一般的PC比较相似,但是服务器在稳定性、安全性、性能等方面都要求更高,因为CPU、芯片组、内存、磁盘系统、网络等硬件和普通PC有所不同。软件服务器(英文名称Server),也称伺服器。指一个…...

2311d游戏引擎适配ios
原文 通过遵循arsd:simpledisplay(v11.0.0之前)上的一些旧代码,Apple的文档和Jacob的这一惊人贡献桥, 我已从金属绑定中删除了所有extern(Objective-C)代码,现在,所有Objective-C桥接代码都是使用D的反射生成的. 因此,给定此例代码: import core.attribute : selector; extern…...
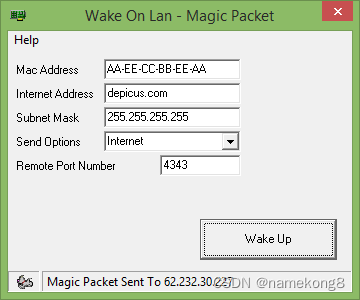
网络唤醒(Wake-on-LAN, WOL)
远程唤醒最简单的方法:DDNSTOOpenwrt网络唤醒,完美实现。 原帖-远程唤醒_超详细windows设置远程唤醒wol远程连接(远程开机) WOL Web# 访问 Wake on Lan Over The Interweb by Depicus 可以无需借助软件很方便的从网页前端唤醒远…...

接口测试框架实战(一) | Requests 与接口请求构造
Requests 是一个优雅而简单的 Python HTTP 库,其实 Python 内置了用于访问网络的资源模块,比如urllib,但是它远不如 Requests 简单优雅,而且缺少了许多实用功能。所以,更推荐掌握 Requests 接口测试实战技能࿰…...
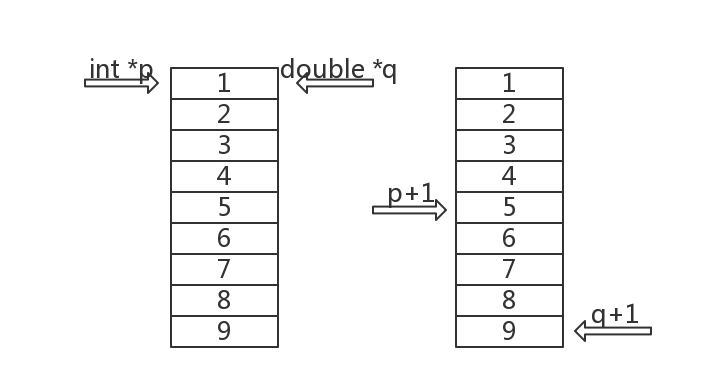
【C++】详解 void*
文章目录 1. void *是什么?2. void*详解3. 和void的区别4. 应用场景4.1 函数传参时不确定类型,或者要支持多类型的传参;4.2 当函数的返回值不考虑类型指关心大小的时候 5. 总结 今天看到一段代码,觉得非常有意思。 void* say_hell…...

Linux家目录变成了-bash-4.2$
Linux家目录变成了-bash-4.2$ Mark a workarround: 使用root用户,执行cp -a /etc/skel/. /home/zookeeper/(不是root用户也可以) 其中/home/zookeeper/目录是对应自己的家目录地址~ 若有帮到你,记得点赞,收藏呀…...

Python和SQLite游标处理多行数据
如果您需要处理多行数据,使用游标或其他适当的方法是更好的选择。以下是一些处理多行数据的方法: 使用游标:游标可以逐行处理查询结果,这对于大量数据或需要逐行处理的场景非常有用。以下是一个使用Python和SQLite的游标示例&…...

NVIDIA Profile Inspector 完整指南:解锁显卡隐藏性能的10个专业技巧
NVIDIA Profile Inspector 完整指南:解锁显卡隐藏性能的10个专业技巧 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector 是一款强大的开源工具,专为追求极…...

微信语音导出mp3全攻略:手机免电脑、在线工具、格式工厂三种方法实测对比
微信语音导出MP3全攻略:三种方法实测与避坑指南 每次听到微信里珍贵的语音消息时,你是否想过把它们永久保存下来?无论是孩子第一次叫"爸爸妈妈"的稚嫩声音,还是商务谈判中的关键承诺,这些语音都值得用更通用…...
)
从零搭建数控数据采集平台:一个开源工具搞定Fanuc、三菱、广数等12种系统(跨平台部署指南)
开源数控数据采集平台实战:12种系统兼容与跨平台部署全解析 走进任何一家现代化机加工车间,你会听到此起彼伏的机床运转声,看到闪烁的数控系统操作面板。这些设备可能来自Fanuc、三菱、马扎克等不同厂商,每台机床都像一座数据孤岛…...
2026-04-28 全国各地响应最快的 BT Tracker 服务器(移动版)
数据来源:https://bt.me88.top 序号Tracker 服务器地域网络响应(毫秒)1http://211.75.205.188:6969/announce广东广州移动342http://211.75.205.187:80/announce广东佛山移动373http://211.75.210.221:6969/announce广东惠州移动374udp://107.189.7.165:6969/annou…...

注塑件变形怎么调优?全尺寸3D检测如何助力精密注塑“减废增效”
汽车灯具全尺寸 3D 测量技术报告 / 3D Metrology for Automotive Lighting[!TIP] 请选择阅读语言 / Please select your language:🇨🇳 点击展开:中文版 (Click to Expand: Chinese Version) 技术报告:基于拍照式蓝光三维扫描的汽…...
)
别再只改Dockerfile了!:云原生Java函数冷启动性能瓶颈定位手册(火焰图+Arthas trace+eBPF syscall监控三件套)
更多请点击: https://intelliparadigm.com 第一章:云原生 Java 函数冷启动毫秒级优化 核心瓶颈定位 Java 函数在 Serverless 平台(如 Knative、OpenFaaS 或 AWS Lambda)中冷启动延迟主要来自 JVM 初始化、类加载、字节码验证及 …...

3步解锁IDM永久试用:开源激活脚本的完整解决方案
3步解锁IDM永久试用:开源激活脚本的完整解决方案 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script Internet Download Manager(IDM…...

从Python小白到全栈:聊聊PyCharm专业版里那些社区版没有的‘生产力神器’
从Python小白到全栈:聊聊PyCharm专业版里那些社区版没有的‘生产力神器’ 第一次用PyCharm社区版调试Django项目时,我在控制台输出了整整三页的SQL查询日志——这些本该在Database Tools面板里直观展示的关系数据,最终以密密麻麻的文本形式淹…...

Chapter 18: System Reset
Chapter 18: System Reset 书籍: PCI Express Technology 3.0 (MindShare Press, 2012) 页码: Book Pages 641-680 | PDF Pages 700-740 学习日期: 2026-04-13本章概要 本章描述 PCIe 的系统复位机制,包括 Hot Reset、Warm Reset、Cold Reset、Fundamental Reset 以…...

Textractor:重新定义游戏文本提取的智能革命
Textractor:重新定义游戏文本提取的智能革命 【免费下载链接】Textractor Extracts text from video games and visual novels. Highly extensible. 项目地址: https://gitcode.com/gh_mirrors/te/Textractor 在游戏世界中,语言障碍往往成为玩家体…...