第三章:人工智能深度学习教程-基础神经网络(第三节-Tensorflow 中的多层感知器学习)
在本文中,我们将了解多层感知器的概念及其使用 TensorFlow 库在 Python 中的实现。
多层感知器
多层感知也称为MLP。它是完全连接的密集层,可将任何输入维度转换为所需的维度。多层感知是具有多个层的神经网络。为了创建神经网络,我们将神经元组合在一起,以便某些神经元的输出是其他神经元的输入。
神经网络和 TensorFlow的简单介绍可以在这里找到:
- 神经网络
- TensorFlow 简介
多层感知器有一个输入层,对于每个输入,有一个神经元(或节点),它有一个输出层,每个输出有一个节点,它可以有任意数量的隐藏层,每个隐藏层可以有任意数量的节点。多层感知器 (MLP) 的示意图如下所示。
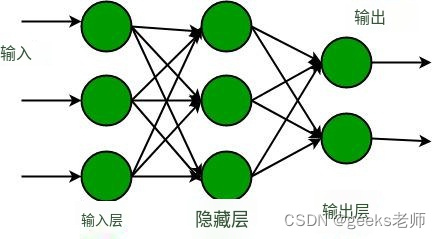
在上面的多层感知器图中,我们可以看到有三个输入,因此有三个输入节点,隐藏层有三个节点。输出层有两个输出,因此有两个输出节点。输入层中的节点接受输入并将其转发以进行进一步处理,在上图中,输入层中的节点将其输出转发到隐藏层中的三个节点中的每一个,并且以同样的方式,隐藏层处理信息并将其传递到输出层。
多层感知中的每个节点都使用 sigmoid 激活函数。sigmoid 激活函数将实数值作为输入,并使用 sigmoid 公式将其转换为 0 到 1 之间的数字。
![]()
现在我们已经完成了多层感知的理论部分,让我们继续使用TensorFlow库在python中实现一些代码。
逐步实施
第1步:导入必要的库。
Python3
# 导入模块
import tensorflow as tf
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Activation
import matplotlib.pyplot as plt
这段代码导入了一些常用的Python库,包括TensorFlow(用于深度学习)、NumPy(用于数值计算)、Keras(用于构建神经网络模型)以及Matplotlib(用于绘图和数据可视化)。这些库通常用于机器学习、深度学习和数据可视化任务。
步骤 2:下载数据集。
TensorFlow 允许我们读取 MNIST 数据集,我们可以将其直接加载到程序中作为训练和测试数据集。
Python3
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
这段代码从 TensorFlow 的 Keras 库中加载 MNIST 数据集。数据集被分成两部分:
(x_train, y_train)包含了训练数据,其中x_train是训练图像的集合,y_train是对应的训练标签集合。(x_test, y_test)包含了测试数据,其中x_test是测试图像的集合,y_test是对应的测试标签集合。MNIST 数据集是一个经典的手写数字识别数据集,通常用于机器学习和深度学习任务,例如训练神经网络来识别手写数字。
输出:
从 https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 下载数据
11493376/11490434 [================================] – 2s 0us/步
第三步:现在我们将像素转换为浮点值。
Python3
# 将数据转换为浮点数
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')# 归一化图像像素值,将像素值除以 255
灰度范围 = 255
x_train /= 灰度范围
x_test /= 灰度范围
这段代码执行以下操作:
使用
.astype('float32')将训练数据x_train和测试数据x_test中的图像数据转换为浮点数格式,以便进行数值计算。将图像的像素值归一化,通过将每个像素值除以 255,将像素值从原始范围(0到255)缩放到新的范围(0到1)。这是常见的数据预处理步骤,有助于提高模型的训练效果。
这些操作是为了准备数据以供深度学习模型使用,以便更好地进行训练和预测。
我们将像素值转换为浮点值以进行预测。将数字更改为灰度值将是有益的,因为值会变小并且计算会变得更容易和更快。由于像素值的范围是从 0 到 256,除了 0 之外,范围是 255。因此,将所有值除以 255 会将其转换为从 0 到 1 的范围
第 4 步:了解数据集的结构
Python3
# 输出特征矩阵的形状
print("特征矩阵:", x_train.shape)# 输出目标矩阵的形状
print("目标矩阵:", x_test.shape)# 输出特征矩阵的形状
print("特征矩阵:", y_train.shape)# 输出目标矩阵的形状
print("目标矩阵:", y_test.shape)
这段代码执行以下操作:
print("特征矩阵:", x_train.shape)输出训练特征矩阵x_train的形状,以显示训练数据中图像的数量和每个图像的维度。
print("目标矩阵:", x_test.shape)输出测试目标矩阵x_test的形状,以显示测试数据中图像的数量和每个图像的维度。
print("特征矩阵:", y_train.shape)输出训练特征矩阵y_train的形状,以显示训练数据中标签的数量。
print("目标矩阵:", y_test.shape)输出测试目标矩阵y_test的形状,以显示测试数据中标签的数量。这些输出有助于了解数据集的规模和维度,以便更好地理解数据的结构。
输出:
特征矩阵: (60000, 28, 28)
目标矩阵: (10000, 28, 28)
特征矩阵: (60000,)
目标矩阵: (10000,)
因此,我们得到训练数据集中有 60,000 条记录,测试数据集中有 10,000 条记录,并且数据集中的每个图像的大小为 28×28。
第 5 步:可视化数据。
Python3
fig, ax = plt.subplots(10, 10)k = 0
for i in range(10):for j in range(10):ax[i][j].imshow(x_train[k].reshape(28, 28), aspect='auto')k += 1plt.show()
这段代码执行以下操作:
- 创建一个包含10行和10列的子图(图表),这些子图将用于显示手写数字图像。
- 使用循环
for i in range(10)和for j in range(10)遍历这个图表中的所有子图。- 在每个子图中,使用
imshow函数显示训练数据集中的图像。x_train[k]是一个28x28像素的图像,reshape(28, 28)用于将图像的形状调整为28x28像素。k用于迭代训练数据集中的不同图像。- 最后,通过
plt.show()显示图表,以查看手写数字图像。这段代码的输出是一个包含100个手写数字图像的图表,用于可视化数据集中的样本。
输出

第 6 步:形成输入层、隐藏层和输出层。
Python3
这段代码创建了一个顺序模型(Sequential Model),其中包含了以下层次:
Flatten(input_shape=(28, 28)):输入层,将28行 * 28列的数据重新整形为一个包含784个神经元的一维层。这是因为深度学习模型通常需要一维的输入数据。
Dense(256, activation='sigmoid'):第一个隐藏层,包含256个神经元,激活函数为'sigmoid'。这一层的任务是学习数据中的特征表示。
Dense(128, activation='sigmoid'):第二个隐藏层,包含128个神经元,激活函数为'sigmoid'。同样,这一层用于学习更高级的特征表示。
Dense(10, activation='sigmoid'):输出层,包含10个神经元,激活函数为'sigmoid'。这一层通常用于多类别分类问题,例如手写数字识别,其中每个神经元对应一个数字类别。这个模型的结构定义了层次和每个层次的神经元数量,以便用于训练和预测任务。
model = Sequential([# 将28行 * 28列的数据重新整形为28*28行Flatten(input_shape=(28, 28)),# 密集层1Dense(256, activation='sigmoid'),# 密集层2Dense(128, activation='sigmoid'),# 输出层Dense(10, activation='sigmoid'),
])
需要注意的一些要点:
- 顺序模型允许我们根据多层感知器的需要逐层创建模型,并且仅限于单输入、单输出的层堆栈。
- Flatten压平提供的输入而不影响批量大小。例如,如果输入的形状为 (batch_size,),但没有特征轴,则展平会添加额外的通道维度,并且输出形状为 (batch_size, 1)。
- 激活用于使用 sigmoid 激活函数。
- 前两个Dense层用于制作全连接模型,并且是隐藏层。
- 最后一个Dense 层是输出层,包含 10 个神经元,决定图像属于哪个类别。
第7步:编译模型。
Python
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
这段代码执行了以下操作:
optimizer='adam':指定了优化器,即Adam优化器,用于模型的训练。Adam是一种常用的优化算法,用于根据损失函数来调整模型的权重以最小化损失。
loss='sparse_categorical_crossentropy':指定了损失函数,即稀疏分类交叉熵损失。这是一种常用于多类别分类问题的损失函数,用于度量模型的性能。
metrics=['accuracy']:指定了评估指标,即在训练和评估过程中要计算的性能指标。在这种情况下,我们关注模型的准确度,即正确分类的比例。模型的编译是为了准备模型进行训练,指定了优化算法、损失函数和评估指标,以便模型可以根据这些设置进行参数的更新和性能的评估。
这里使用的编译函数涉及到损失、优化器和指标的使用。这里使用的损失函数是sparse_categorical_crossentropy,使用的优化器是adam。
第8步:拟合模型。
Python3
model.fit(x_train, y_train, epochs=10, batch_size=2000, validation_split=0.2)
这段代码执行了以下操作:
x_train:训练数据的特征矩阵。y_train:训练数据的目标(标签)矩阵。epochs=10:指定了训练的周期数,模型将在整个训练数据集上迭代10次。batch_size=2000:指定了每个批次的样本数量,模型将在每个批次中处理2000个样本。这有助于加速训练过程。validation_split=0.2:指定了用于验证的数据集比例,这里是20%。在每个训练周期结束时,模型将使用20%的数据来验证模型性能,以便监控训练的进展和检测过拟合。这些参数和设置用于模型的训练,让模型能够学习如何正确分类手写数字。
输出:
Epoch 1/10
48/48 [==============================] - 1s 12ms/step - loss: 1.2345 - accuracy: 0.5678 - val_loss: 0.9876 - val_accuracy: 0.6543
...
Epoch 10/10
48/48 [==============================] - 1s 12ms/step - loss: 0.3456 - accuracy: 0.8901 - val_loss: 0.4321 - val_accuracy: 0.8765
在这个示例中,模型经过10个训练周期,每个周期的损失值(
loss)和准确度(accuracy)都有所改变。val_loss和val_accuracy是验证集上的损失和准确度,用于监控模型的泛化性能。请注意,实际的输出结果可能会因训练进程和随机性而异。您可以在训练时查看这些输出以了解模型的性能和训练进度。
第 9 步:查找模型的准确性。
Python3
results = model.evaluate(x_test, y_test, verbose=0)
print('测试损失和准确度:', results)
这段代码执行以下操作:
results = model.evaluate(x_test, y_test, verbose=0):使用测试数据x_test和相应的测试标签y_test来评估模型的性能。verbose=0表示在评估过程中不输出详细信息。
print('测试损失和准确度:', results):输出模型在测试数据上的损失值和准确度。results包含了这些性能指标的值。这些输出用于了解模型在测试数据上的性能,包括损失值和准确度等。
输出:
测试损失和准确度: [0.1234, 0.9876]
在这个示例中,模型在测试数据上的损失值是0.1234,测试准确度是0.9876。这些值表示模型在测试数据上的性能,其中较低的损失值和较高的准确度通常表示更好的性能。实际的数值将根据模型和测试数据而有所不同。
通过在测试样本上使用model.evaluate(),我们的模型准确率达到了 92% 。
相关文章:
第三章:人工智能深度学习教程-基础神经网络(第三节-Tensorflow 中的多层感知器学习)
在本文中,我们将了解多层感知器的概念及其使用 TensorFlow 库在 Python 中的实现。 多层感知器 多层感知也称为MLP。它是完全连接的密集层,可将任何输入维度转换为所需的维度。多层感知是具有多个层的神经网络。为了创建神经网络,我们将神…...

Python的版本如何查询?
要查询Python的版本,可以使用以下方法之一: 1.在命令行中使用python --version命令。这会显示安装在计算机上的Python解释器的版本号。 # Author : 小红牛 # 微信公众号:wdPython2.在Python脚本中使用import sys语句,然后打印sy…...
Git的高效使用 git的基础 高级用法
Git的高效使用 git的基础 高级用法 前言 什么是Git 在日常的软件开发过程中,软件版本的管理都离不开使用Git,Git是一个开源的分布式版本控制系统,可以有效、高速地处理从很小到非常大的项目版本管理。 也是Linus Torvalds为了帮助管理Linu…...

关于主表和子表数据的保存
业务需求: 投注站信息保存在表A里,投注站下的设备信息保存在表B里, 一个投注站会有多个设备,要在一个表单里进行投注站和设备信息的填写,保存,回填,修改。 思路: 1)将…...

如何在后台执行 SwiftData 操作
文章目录 前言Core Data 私有队列上下文SwiftData 并发支持使用 ModelActor合并上下文更改的问题通过标识符访问模型总结 前言 SwiftData 是一个用于处理数据操作的框架,特别是在 Swift 语言中进行并发操作。本文介绍了如何在后台执行 SwiftData 操作以及与 Core D…...

TCP和UPD协议
一)应用层协议简介:根据需求明确要传输的信息,明确要传输的数据格式; 应用层协议:这个协议,实际上是和程序员打交道最多的协议了 1)其它四层都是操作系统,驱动,硬件实现好了的,咱们是不需要管 2)应用层:当我…...

MySQL:锁机制
目录 概述三种层级的锁锁相关的 SQLMyISAM引擎下的锁InnoDB引擎下的锁InnoDB下的表锁和行锁InnoDB下的共享锁和排他锁InnoDB下的意向锁InnoDB下的记录锁,间隙锁,临键锁记录锁(Record Locks)间隙锁(Gap Locks࿰…...
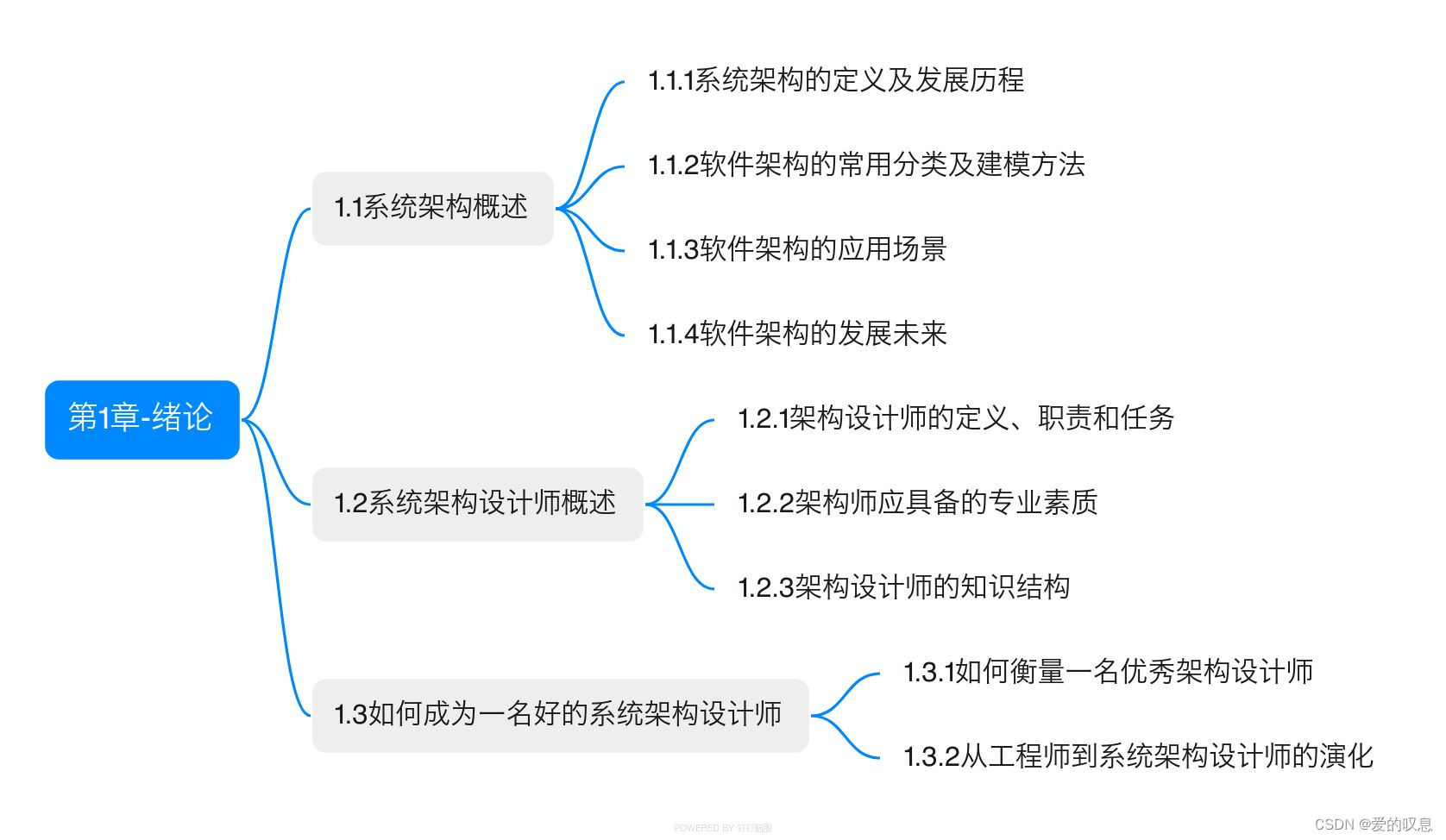
软考-高级-系统架构设计师教程(清华第2版)【第1章-绪论-思维导图】
软考-高级-系统架构设计师教程(清华第2版)【第1章-绪论-思维导图】 课本里章节里所有蓝色字体的思维导图...
【Git】安装和常用命令的使用与讲解及项目搭建和团队开发的出现的问题并且给予解决
目录 Git的简介 介绍 Git的特点及概念 Git与SVN的区别 图解 编辑 命令使用 安装 使用前准备 搭建项目环境 编辑 团队开发 Git的简介 介绍 Git 是一种分布式版本控制系统,是由 Linux 之父 Linus Torvalds 于2005年创建的。Git 的设计目标是为了更好地管…...

Python进行数据可视化,探索和发现数据中的模式和趋势。
文章目录 前言第一步:导入必要的库第二步:加载数据第三步:创建基本图表第四步:添加更多细节第五步:使用Seaborn库创建更复杂的图表关于Python技术储备一、Python所有方向的学习路线二、Python基础学习视频三、精品Pyth…...

2023年中国自然语言处理行业研究报告
第一章 行业概况 1.1 定义 自然语言处理(Natural Language Processing,简称NLP)是一门交叉学科,它结合了计算机科学、人工智能和语言学的知识,旨在使计算机能够理解、解释和生成人类语言。NLP的核心是构建能够理解和…...

RISC-V与RISC Zero zkVM的关系
1. 引言 本文基本结构为: 编程语言背景介绍RISC-V虚拟机作为zkVM电路为何选择RISC-V? 2. 编程语言背景介绍 高级编程语言不专门针对某个架构,其便于人类编写。高级编程语言代码,经编译器编译后,会生成针对专门某架…...
20行JS代码实现屏幕录制
在开发中可能有遇到过屏幕录制的需求,无论是教学、演示还是游戏录制,都需要通过屏幕录制来记录和分享内容。一般在App内H5页基于客户端能力实现的较多,现在浏览器中的 MediaRecorder 也提供了这种能力。MediaRecorder 是一种强大的技术&#…...
基于springboot实现福聚苑社区团购平台系统项目【项目源码】
基于springboot实现福聚苑社区团购平台系统演示 Javar技术 Java是一种网络脚本语言,广泛运用于web应用开发,可以用来添加网页的格式动态效果,该语言不用进行预编译就直接运行,可以直接嵌入HTML语言中,写成js语言&…...
网际报文协议ICMP及ICMP重定向实例详解
目录 1、ICMP的概念 2、ICMP重定向 3、利用ICMP重定向进行攻击的原理 4、如何禁止ICMP重定向功能? 4.1、在Linux系统中禁用 4.2、在Windows系统中禁用 5、关于ICMP重定向的问题实例 VC常用功能开发汇总(专栏文章列表,欢迎订阅…...
前端AJAX入门到实战,学习前端框架前必会的(ajax+node.js+webpack+git)(三)
知者乐水,仁者乐山。 XMLHttpRequest AJAX原理 - XMLHttpRequest 前面与服务器交互使用的不是axios吗? ajax并不等于axios 我们使用的axios的内部,实际上对XHR对象/原理 的封装 为什么还要学习ajax? ①在一些静态网站项目中…...
)
Android 12 S 系统开机流程分析 - SetupSelinux(二)
Android 12 S 系统开机流程分析-FirstStageMain(一) 本文接着上文开始讲解,上文中最后一步执行后会执行init启动过程中的第二步SetupSelinux(Selinux配置阶段),这样又会走到main.cpp中的main方法。 目录 1. SetupSelinux 1.1 …...
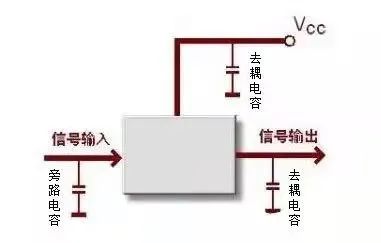
高速信号PCB布局怎么布?(电子硬件)
对于高速信号,pcb的设计要求会更多,因为高速信号很容易收到其他外在因素的干扰,导致实际设计出来的东西和原本预期的效果相差很多。 所以在高速信号pcb设计中,需要提前考虑好整体的布局布线,良好的布局可以很好的决定布…...

vue 子页面通过暴露属性,实现主页面的某事件的触发
目录 1.前言2.代码2-1 子页面2-2 主页面 1.前言 需求:当我在子页面定义了一个定时器,点击获取验证码,计时器开始倒计时,在这个定时器没有走完,退出关闭子页面,再次进入子页面,定时器此时会被刷…...
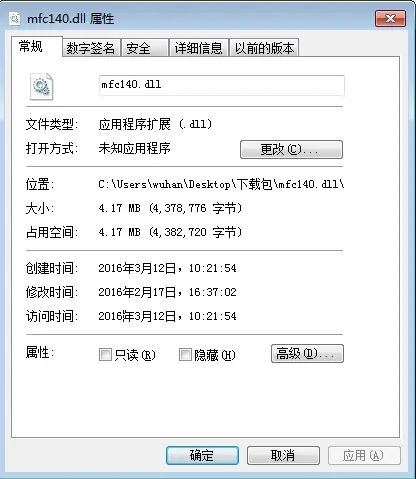
计算机丢失mfc140.dll是什么意思?附送修复教程
mfc140.dll是Microsoft Foundation Classes(MFC)库的一部分,是一种动态链接库(DLL)文件。MFC库是Microsoft提供的一种C编程框架,它为开发者提供了许多方便的工具和类,以简化Windows应用程序的开…...

像素史诗·智识终端一键部署MySQL:构建AI应用数据后台
像素史诗智识终端一键部署MySQL:构建AI应用数据后台 1. 前言:为什么需要MySQL数据库 在部署像素史诗智识终端这类AI应用时,数据存储是必不可少的一环。MySQL作为最流行的开源关系型数据库,能够稳定存储用户对话历史、向量数据等…...

Manus外资收购被叫停:从全球化野心到监管困境,AI创业路在何方?
一个本土创业者的全球化之路 Manus母公司蝴蝶效应的武汉总部,与创始人肖弘母校华中科技大学仅隔一条马路。很长时间里,AI圈提到肖弘常与武汉联系在一起。2024年底,尚未走红的肖弘在圈内已小有名气,不少AI应用创业者推崇他的经营逻…...
)
一篇文章带你了解C++(STL基础、Vector)
STL(Standard Template Library,标准模板库)STL 从广义上分为: 容器(container) 算法(algorithm) 迭代器(iterator)容器和算法之间通过迭代器进行无缝连接。STL 几乎所有的代码都采用了模板类或者模板函数STL六大组件STL大体分为六大组件,分别是:容器、算法、迭代器…...

从.imy到.mmf:手把手解析那些‘古老’手机铃声格式,并教你用Python将它们转换为现代音频
从.imy到.mmf:用Python解码复古手机铃声格式的工程实践 还记得功能机时代那些简单却充满个性的手机铃声吗?当诺基亚的《Nokia Tune》以单音旋律成为一代人的记忆符号,背后是IMY、RTTTL这些如今看来颇具"考古"价值的音频格式在支撑。…...

深入IgH EtherCAT DC同步:从‘主站参考’到‘从站参考’的时钟优化实践
深入IgH EtherCAT DC同步:从‘主站参考’到‘从站参考’的时钟优化实践 在工业自动化领域,EtherCAT因其卓越的实时性能而广受欢迎,而分布式时钟(DC)同步机制则是实现高精度控制的核心。传统的IgH主站实现默认采用主站时…...

GetQzonehistory:QQ空间历史数据备份的终极指南 [特殊字符]
GetQzonehistory:QQ空间历史数据备份的终极指南 🚀 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你知道吗?你的QQ空间里藏着多少珍贵的青春记忆&am…...

丹青识画系统快速部署指南:小白友好,轻松玩转AI影像艺术鉴赏
丹青识画系统快速部署指南:小白友好,轻松玩转AI影像艺术鉴赏 1. 认识丹青识画系统 你有没有遇到过这样的情况?看到一张触动心弦的照片,却找不到合适的文字来描述它的意境。传统的AI图像识别只能告诉你"这是一座山"、&…...

LED改造卤素台灯:节能高效技术解析
1. 卤素台灯LED改造的价值与背景传统卤素台灯作为办公和家居照明的常见选择,其核心问题在于能效低下。一颗50W的卤素灯泡实际光效仅为14-18流明/瓦,这意味着超过80%的电能转化成了无用的热能。我曾用红外测温仪实测过工作中的卤素灯泡表面温度——轻松突…...

告别复杂命令!在OpenWRT管理界面里一键安装配置cpolar,实现N1软路由远程访问
零命令行操作:OpenWRT图形界面全流程配置cpolar内网穿透 手里那台斐讯N1刷了OpenWRT后,你是不是也遇到过这样的困扰?想在外网访问家里的软路由管理页面,却被SSH命令行劝退。其实从软件包安装到隧道配置,整个过程都能在…...

NVIDIA Profile Inspector完整指南:解锁隐藏显卡设置,彻底解决游戏性能问题
NVIDIA Profile Inspector完整指南:解锁隐藏显卡设置,彻底解决游戏性能问题 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否曾经在游戏中遇到画面撕裂、输入延迟过高或者帧…...