在linux安装单机版hadoop-3.3.6
一、下载hadoop
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/core/hadoop-3.3.6/二、配置环境变量
1、配置java环境变量
2、配置hadoop环境变量
export HADOOP_HOME=/usr/local/bigdata/hadoop-3.3.6
export HBASE_HOME=/usr/local/bigdata/hbase-2.5.6
export JAVA_HOME=/usr/local/jdk-11
export CLASSPATH=.:$JAVA_HOME/lib
export PATH=.:$JAVA_HOME/bin:$HBASE_HOME/bin:$HADOOP_HOME/bin:$PATH
3、配置host
192.168.42.142 node4
三、修改hadoop对应的配置文件
3.1、在hadoop目录下创建目录
mkdir logs mkdir datamkdir -p data/namenode/mkdir -p data/datanodemkdir -p data/tmp
3.2、修改hadoop-env.sh
进入etc/hadoop目录下,修改hadoop-env.sh文件
export JAVA_HOME=/usr/local/jdk-11/
export HADOOP_HOME=/usr/local/bigdata/hadoop-3.3.6
3.3、修改yarn-site.xml
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>yarn.resourcemanager.hostname</name><value>node4</value></property>
3.4、修改 hdfs-site.xml
<property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>//usr/local/bigdata/hadoop-3.3.6/data/namenode</value> //注意前面部分路径修改为自己的</property><property><name>dfs.datanode.data.dir</name><value>//usr/local/bigdata/hadoop-3.3.6/data/datanode</value> //注意前面部分路径修改为自己的</property><property><name>dfs.permissions.enabled</name><value>false</value></property><property><name>dfs.umaskmode</name><value>022</value></property><property><name>dfs.permissions</name><value>false</value></property><property><name>dfs.namenode.acls.enabled</name><value>false</value></property><property><name>dfs.namenode.xattrs.enabled</name><value>false</value></property><property><name>dfs.namenode.http-address</name><value>http://node4:9870</value></property>
3.5、修改mapred-site.xml
<property><name>mapreduce.framework.name</name><value>yarn</value></property>3.6、修改core-site.xml
<property><name>hadoop.tmp.dir</name><value>//usr/local/bigdata/hadoop-3.3.6/data/tmp</value> //注意前面部分路径修改为自己的</property><property><name>fs.defaultFS</name><value>hdfs://node4:9000</value></property><property><name>hadoop.http.authentication.simple.anonymous.allowed</name><value>true</value></property><property><name>hadoop.proxyuser.hwf.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.hwf.groups</name><value>*</value></property><property> <name>fs.hdfs.impl</name> <value>org.apache.hadoop.hdfs.DistributedFileSystem</value> <description>The FileSystem for hdfs: uris.</description> </property>
3.7、在start-dfs.sh,stop-dfs.sh 文件中增加
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=root
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
3.8、在start-yarn.sh 和stop-yarn.sh 中增加
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=root
YARN_NODEMANAGER_USER=root
注意:这里是测试环境,所以直接用root,生产需要创建对应的用户和用户组
四、格式化文件
输入hdfs namenode -format格式化
hdfs namenode -format2023-11-09 22:48:25,218 INFO namenode.FSDirectory: XATTR serial map: bits=24 maxEntries=16777215
2023-11-09 22:48:25,229 INFO util.GSet: Computing capacity for map INodeMap
2023-11-09 22:48:25,229 INFO util.GSet: VM type = 64-bit
2023-11-09 22:48:25,229 INFO util.GSet: 1.0% max memory 944 MB = 9.4 MB
2023-11-09 22:48:25,229 INFO util.GSet: capacity = 2^20 = 1048576 entries
2023-11-09 22:48:25,230 INFO namenode.FSDirectory: ACLs enabled? false
2023-11-09 22:48:25,230 INFO namenode.FSDirectory: POSIX ACL inheritance enabled? true
2023-11-09 22:48:25,230 INFO namenode.FSDirectory: XAttrs enabled? false
2023-11-09 22:48:25,231 INFO namenode.NameNode: Caching file names occurring more than 10 times
2023-11-09 22:48:25,235 INFO snapshot.SnapshotManager: Loaded config captureOpenFiles: false, skipCaptureAccessTimeOnlyChange: false, snapshotDiffAllowSnapRootDescendant: true, maxSnapshotLimit: 65536
2023-11-09 22:48:25,236 INFO snapshot.SnapshotManager: SkipList is disabled
2023-11-09 22:48:25,239 INFO util.GSet: Computing capacity for map cachedBlocks
2023-11-09 22:48:25,239 INFO util.GSet: VM type = 64-bit
2023-11-09 22:48:25,239 INFO util.GSet: 0.25% max memory 944 MB = 2.4 MB
2023-11-09 22:48:25,239 INFO util.GSet: capacity = 2^18 = 262144 entries
2023-11-09 22:48:25,244 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10
2023-11-09 22:48:25,244 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10
2023-11-09 22:48:25,245 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
2023-11-09 22:48:25,247 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
2023-11-09 22:48:25,247 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
2023-11-09 22:48:25,248 INFO util.GSet: Computing capacity for map NameNodeRetryCache
2023-11-09 22:48:25,248 INFO util.GSet: VM type = 64-bit
2023-11-09 22:48:25,248 INFO util.GSet: 0.029999999329447746% max memory 944 MB = 290.0 KB
2023-11-09 22:48:25,248 INFO util.GSet: capacity = 2^15 = 32768 entries
Re-format filesystem in Storage Directory root= /usr/local/bigdata/hadoop-3.3.6/data/namenode; location= null ? (Y or N) Y
2023-11-09 22:48:27,082 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1461429317-192.168.42.142-1699541307072
2023-11-09 22:48:27,082 INFO common.Storage: Will remove files: [/usr/local/bigdata/hadoop-3.3.6/data/namenode/current/VERSION, /usr/local/bigdata/hadoop-3.3.6/data/namenode/current/seen_txid, /usr/local/bigdata/hadoop-3.3.6/data/namenode/current/fsimage_0000000000000000000.md5, /usr/local/bigdata/hadoop-3.3.6/data/namenode/current/fsimage_0000000000000000000]
2023-11-09 22:48:27,093 INFO common.Storage: Storage directory /usr/local/bigdata/hadoop-3.3.6/data/namenode has been successfully formatted.
2023-11-09 22:48:27,129 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/bigdata/hadoop-3.3.6/data/namenode/current/fsimage.ckpt_0000000000000000000 using no compression
2023-11-09 22:48:27,198 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/bigdata/hadoop-3.3.6/data/namenode/current/fsimage.ckpt_0000000000000000000 of size 399 bytes saved in 0 seconds .
2023-11-09 22:48:27,206 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2023-11-09 22:48:27,222 INFO namenode.FSNamesystem: Stopping services started for active state
2023-11-09 22:48:27,222 INFO namenode.FSNamesystem: Stopping services started for standby state
2023-11-09 22:48:27,228 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2023-11-09 22:48:27,229 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node4/192.168.42.142
************************************************************/
五、启动hadoop单机版
进入sbin目录下输入./start-all.sh
[root@node4 sbin]# ./start-all.sh
Starting namenodes on [node4]
上一次登录:四 11月 9 22:21:08 CST 2023pts/0 上
Starting datanodes
上一次登录:四 11月 9 22:22:49 CST 2023pts/0 上
Starting secondary namenodes [node4]
上一次登录:四 11月 9 22:22:51 CST 2023pts/0 上
Starting resourcemanager
上一次登录:四 11月 9 22:22:55 CST 2023pts/0 上
Starting nodemanagers
上一次登录:四 11月 9 22:23:00 CST 2023pts/0 上
六、查看启动界面
http://192.168.42.142:8088/
http://192.168.42.142:9870/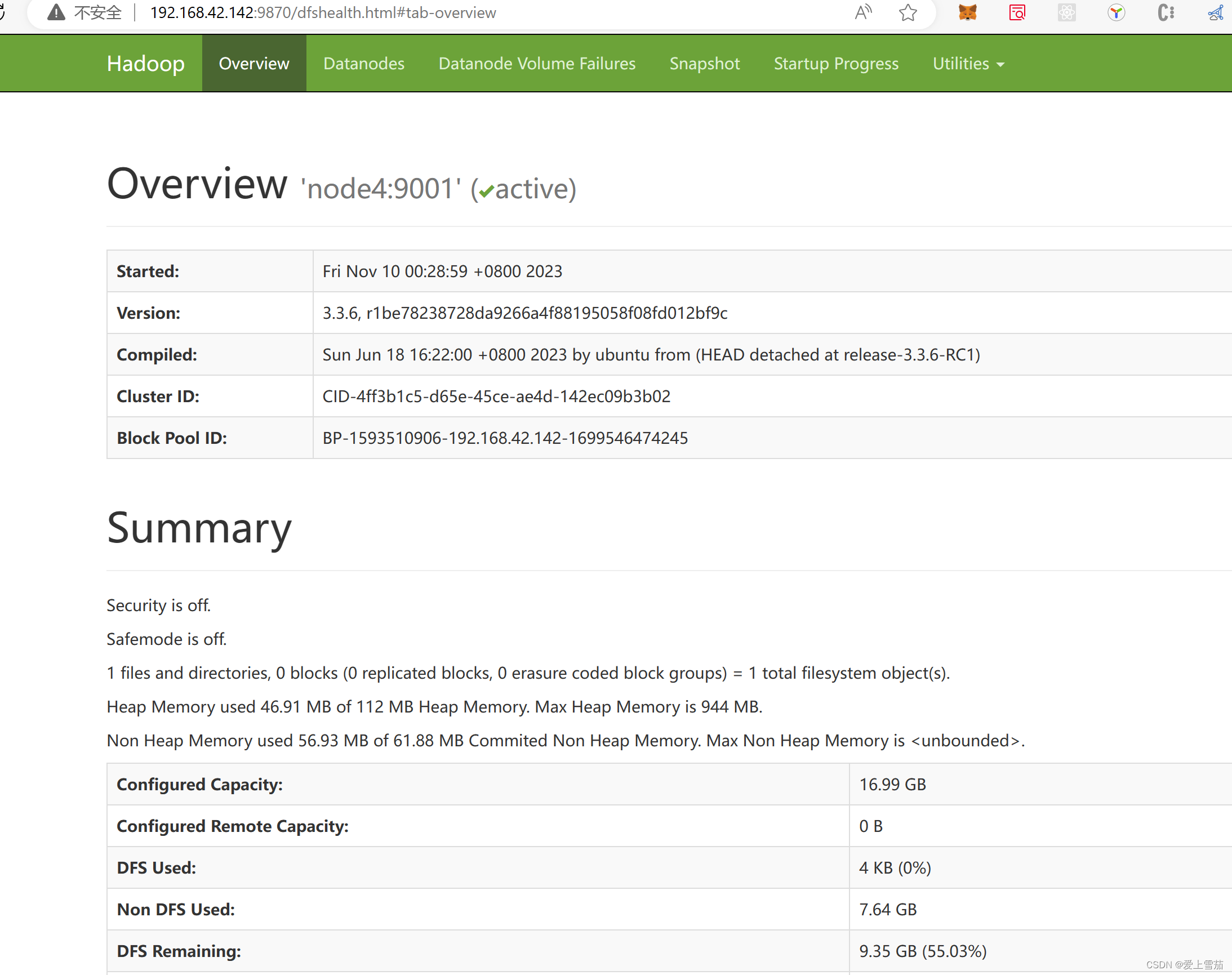
相关文章:
在linux安装单机版hadoop-3.3.6
一、下载hadoop https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/core/hadoop-3.3.6/ 二、配置环境变量 1、配置java环境变量 2、配置hadoop环境变量 export HADOOP_HOME/usr/local/bigdata/hadoop-3.3.6 export HBASE_HOME/usr/local/bigdata/hbase-2.5.6 export JA…...

Hadoop相关
hdfs getconf -confKey dfs.namenode.http-address 查看Hadoop工作端口的信息 hdfs getconf -confKey dfs.datanode.http.address 查看HDFS的NameNode组件的HTTP端口。...

ArcGIS 气象风场等示例 数据制作、服务发布及前端加载
1. 原始数据为多维数据 以nc数据为例。 首先在pro中需要以多维数据的方式去添加多维数据,这里的数据包含uv方向: 加载进pro的效果: 这里注意 数据属性需要为矢量uv: 如果要发布为服务,需要导出存储为tif格式&…...
【Axure高保真原型】树切换动态面板案例
今天和大家分享树切换动态面板的原型模板,点击树的箭头可以打开或者收起子节点,点击最后一级人物节点,可以切换右侧面板的状态到对应的页面,左侧的树是通过中继器制作的,使用简单,只需要按要求填写中继器表…...
安装pr提示VCRUNTIME140.dll丢失的修复方法,3个有效的方法
在学习和工作中,我们经常需要使用到PR和PS。然而,在安装这些软件时,有时会遇到一些错误提示,其中之一就是“VCRUNTIME140.dll丢失”,无法运行启动软件程序。那么,如何解决VCRUNTIME140.dll丢失的问题呢&…...

Linux进程控制(2)
Linux进程控制(2) 📟作者主页:慢热的陕西人 🌴专栏链接:Linux 📣欢迎各位大佬👍点赞🔥关注🚓收藏,🍉留言 本博客主要内容讲解了进程等待收尾内容和进程的程序…...
Android Glide transform旋转rotate圆图CircleCrop,Kotlin
Android Glide transform旋转rotate圆图CircleCrop,Kotlin import android.graphics.Bitmap import android.os.Bundle import android.util.Log import android.widget.ImageView import androidx.appcompat.app.AppCompatActivity import com.bumptech.glide.load…...
如何让群晖Audio Station公开共享的本地音频公网可访问?
文章目录 1. 本教程使用环境:2. 制作音频分享链接3. 制作永久固定音频分享链接: 之前文章我详细介绍了如何在公网环境下使用pc和移动端访问群晖Audio Station: 公网访问群晖audiostation听歌 - cpolar 极点云 群晖套件不仅能读写本地文件&a…...

生态环境领域基于R语言piecewiseSEM结构方程模型
结构方程模型(Sructural Equation Modeling,SEM)可分析系统内变量间的相互关系,并通过图形化方式清晰展示系统中多变量因果关系网,具有强大的数据分析功能和广泛的适用性,是近年来生态、进化、环境、地学、…...
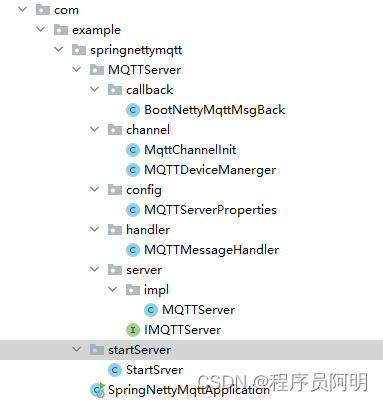
spring boot+netty 搭建MQTT broken
一、项目结构 二、安装依赖 <!-- netty包 --><dependency><groupId>io.netty</groupId><artifactId>netty-all</artifactId><version>4.1.75.Final</version></dependency><!-- 常用JSON工具包 --><…...
从零开始搭建React+TypeScript+webpack开发环境-使用iconfont构建图标库
创建iconfont项目 进入iconfont官网,完成注册流程,即可创建项目。 无法访问iconfont可尝试将电脑dns改为阿里云镜像223.5.5.5和223.6.6.6 添加图标 在图标库里选择图标,加入购物车 将图标添加到之前创建的项目中 生成代码 将代码配置到项目…...

微服务之初始微服务
文章目录 一、服务架构演变1.单体架构2.分布式架构 二、认识微服务三、总结四、微服务技术对比五、SpringCloud注意 一、服务架构演变 1.单体架构 单体架构:将业务的所有功能集中在一个项目中开发,打成一个包部署。 优点: 架构简单部署成本…...

大口径智能水表支持最高水流量是多少?
随着科技的不断发展,我国城市化进程的加快,水资源管理日益受到重视。作为一种先进的用水计量设备,大口径智能水表凭借其高精度、低误差、远程抄表等优点,在市场上备受青睐。那么接下来,小编就来为大家详细的介绍一下大…...

在Spring Boot中使用MyBatis访问数据库
MyBatis,这个对各位使用Java开发的开发者来说还是蛮重要的,我相信诸位在企业开发项目的时候,大多数采用的是Mybatis。使用MyBatis帮助我们解决各种问题,实际上这篇文章,基本上默认为可以跳过的一篇,但是为了…...

懒羊羊闲话2
前言: 笔者谈不上是某个领域的高手,也不是大厂的某个神秘高手,一直游离于小型公司,写下这篇文章献给那些无法接触到好的学习环境,苦恼自己原地踏步的coder。 1、如何快速熟悉某个行业 作为一个编码多年的程序员&#…...

多路转接(上)——select
目录 一、select接口 1.认识select系统调用 2.对各个参数的认识 二、编写select服务器 1.两个工具类 2.网络套接字封装 3.服务器类编写 4.源文件编写 5.运行 一、select接口 1.认识select系统调用 int select(int nfds, fd_set readfds, fd_set writefds, fd_set ex…...
基于SSM的图书管理借阅系统设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:采用JSP技术开发 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目&#x…...

Python的内存优化
在Python中,内存管理和优化是一个复杂的话题,因为它涉及到Python解释器的内部机制,特别是Python的垃圾收集和内存分配策略。Python通过自动垃圾收集机制管理内存,主要包括引用计数和标记-清除算法。 Python内存管理机制ÿ…...

蓝桥杯-回文日期[Java]
目录: 学习目标: 学习内容: 学习时间: 题目: 题目描述: 输入描述: 输出描述: 输入输出样例: 示例 1: 运行限制: 题解: 思路: 学习目标: 刷蓝桥杯题库日记 学习内容: 编号498题目回文日期难度…...

acwing算法基础之搜索与图论--树与图的遍历
目录 1 基础知识2 模板3 工程化 1 基础知识 树和图的存储:邻接矩阵、邻接表。 树和图的遍历:dfs、bfs。 2 模板 树是一种特殊的图(即,无环连通图),与图的存储方式相同。 对于无向图中的边ab,…...

别光看手册了!实战教你用Synopsys AXI VIP的Port Monitor搭建高效Scoreboard
实战指南:用Synopsys AXI VIP的Port Monitor构建高可靠Scoreboard 在复杂SoC验证环境中,AXI总线事务的准确捕获与高效比对是验证工程师面临的核心挑战之一。许多工程师虽然熟悉Synopsys AXI VIP的基本用法,却在将其深度集成到验证环境时遇到瓶…...

Steam成就管理器:为什么SAM是游戏成就管理的终极解决方案
Steam成就管理器:为什么SAM是游戏成就管理的终极解决方案 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager Steam成就管理器(Steam A…...

SAP ABAP开发实战:手把手教你用F4_PROG_SUBPROGRAM函数搞定FORM子例程搜索帮助
SAP ABAP实战:动态获取FORM子例程的三种高效方案 在ABAP开发中,动态调用FORM子例程是常见需求。想象这样一个场景:你需要开发一个通用报表程序,允许用户从下拉列表中选择不同的数据处理逻辑——这些逻辑都以FORM子例程的形式存在。…...

使用LaTeX撰写技术报告:如何优雅呈现cv_unet_image-colorization实验数据
使用LaTeX撰写技术报告:如何优雅呈现cv_unet_image-colorization实验数据 写技术报告或者论文,最头疼的往往不是实验本身,而是怎么把那些辛辛苦苦跑出来的数据、图表、结果,清晰又专业地呈现出来。你肯定遇到过这种情况ÿ…...

3步解锁OCRmyPDF多语言OCR:让中文日文韩文PDF从此可搜索可编辑
3步解锁OCRmyPDF多语言OCR:让中文日文韩文PDF从此可搜索可编辑 【免费下载链接】OCRmyPDF OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched 项目地址: https://gitcode.com/GitHub_Trending/oc/OCRmyPDF 你是否曾经面对…...

抖音直播保存终极指南:douyin-downloader完整解决方案
抖音直播保存终极指南:douyin-downloader完整解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppo…...

第 8 集:PR Review:让 Claude Code 辅助代码审查
为什么需要AI辅助Review? 在软件开发中,代码审查(Code Review)是确保代码质量的关键环节。传统的人工审查虽然全面,但存在效率瓶颈:工程师需要投入大量时间处理重复性任务,如检查命名规范、测试覆盖率和代码重复等。这些任务往往机械且耗时,容易分散对核心问题的注意力…...

egergergeeert惊艳效果:银发少女插画中发丝细节、布料褶皱、光影过渡展示
egergergeeert惊艳效果:银发少女插画中发丝细节、布料褶皱、光影过渡展示 1. 效果亮点概览 egergergeeert文生图镜像在角色插画创作中展现出惊人的细节表现力,特别是在以下三个方面尤为突出: 发丝细节:能够生成单根分明的发丝效…...
)
皮带轮零件机械加工工艺规程制订及工艺装备设计毕业设计(说明书+CAD图纸+SolidWorks图纸+其它相关资料)
在机械制造领域,皮带轮作为传动系统的核心零件,其加工质量直接影响设备运行的稳定性与效率。针对这一关键零件的机械加工工艺规程制订及工艺装备设计,需系统整合材料特性、加工精度要求、设备性能等多维度因素,形成一套科学、规范…...

AI编程代理平台Kilo:从代码补全到自动化工程实践
1. 项目概述:Kilo,一个全能的AI编程代理平台如果你和我一样,每天都在和代码打交道,那你肯定也经历过这样的时刻:面对一个复杂的重构任务,或者一个需要大量重复操作的脚本编写,心里会想“要是能有…...