ElasticSearch的集群、节点、索引、分片和副本
Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档。为了方便大家理解,我们将Elasticsearch里存储文档数据和关系型数据库MySQL存储数据的概念进行一个类比

ES里的Index可以看做一个库,而Types相当于表,Documents则相当于表的行。
这里Types的概念已经被逐渐弱化,Elasticsearch 6.X中,一个index下已经只能包含一个type,Elasticsearch 7.X中, Type的概念已经被删除了。
1. 集群(Cluster)
1.1 集群简介
分布式系统的可用性与扩展性
高可用性
服务可用性一允许有节点停止服务
数据可用性-部分节点丢失,不会丢失数据
可扩展性
请求量提升一数据的不断增长(将数据分布到所有节点上)
Easticsearch 的分布式架构的好处
存储的水平扩容
提高系统的可用性,部分节点停止服务,整人集群的服务不受影响
Elasticsearch的分布式架构
不同的集群通过不同的名字来区分,默认名字“elasticsearch"
通过配置文件修改,或者在命令行中-E cluster.name=cluster_name 进行设定
一人集群可以有一人或者多人节点
一个集群就是由一个或多个服务器节点组织在一起,共同持有整个的数据,并一起提供索引和搜索功能。
一个Elasticsearch集群有一个唯一的名字标识,这个名字默认就是”elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。
1.1 集群健康状态
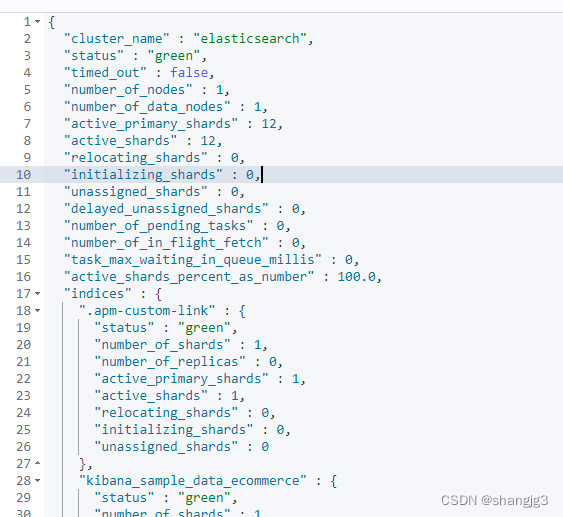
# 获取集群健康状态
GET _cluster/health
# 获取集群健康状态,精确到索引
GET _cluster/health?level=indices
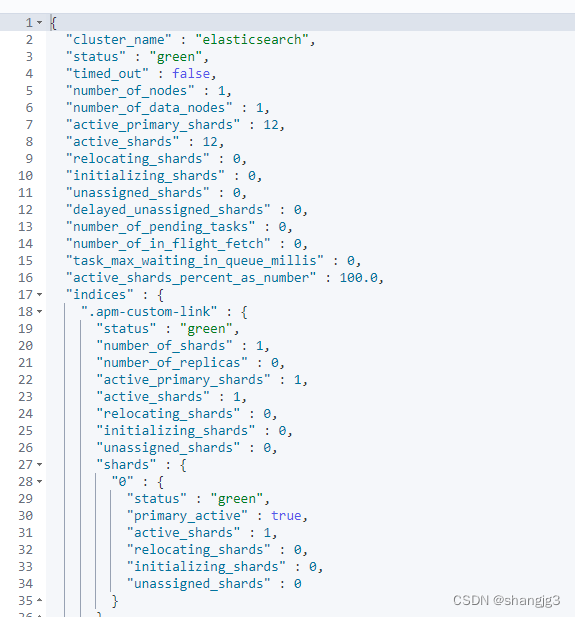
# 获取集群健康状态,精确到分片
GET _cluster/health?level=shards
# 获取集群健康状态,精确到某几个索引
GET /_cluster/health/kibana_sample_data_ecommerce,kibana_sample_data_flights
# 获取集群健康状态,精确到某个索引的分片
GET /_cluster/health/kibana_sample_data_flights?level=shards{"cluster_name" : "elasticsearch","status" : "green","timed_out" : false,"number_of_nodes" : 1,"number_of_data_nodes" : 1,"active_primary_shards" : 12,"active_shards" : 12,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 0,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 100.0
}
1.2 集群详细信息
GET _cluster/state
1.3 集群的统计信息
GET _cluster/stats返回结果包含集群、节点、索引的详细统计信息。

1.3 集群的设置信息
GET /_cluster/settings
# 包含默认值设置
GET /_cluster/settings?include_defaults=true{"persistent" : { },"transient" : { }
}
2. 节点(Node)
2.1 节点简介
节点是一个 Elasticsearch 的实例,本质上就是一个JAVA进程。
一台机器上可以运行多个Elasticsearch 进程,但是生产环境一般建议一台机器上只运
行一个 Elasticsearch 实例。
每一个节点都有名字,通过配置文件配置,或者启动时候-E node.name=node1指定。
每一个节点在启动之后,会分配一个 UID,保存在 data 目录下。
集群中包含很多服务器,一个节点就是其中的一个服务器。作为集群的一部分,它存储数据,参与集群的索引和搜索功能。
一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
| 节点类型 | 描述 |
| Master-eligible nodes 和 Master Node | 每个节点启动后,默认就是一个Master eligible节点,可以设置 node.master:false 禁止 Master-eligible节点可以参加选主流程,成为Master节点 当第一个节点启动时候,它会将自己选举成Master节点 每个节点上都保存了集群的状态,只有Master节点才能修改集群的状态信息 集群状态(Cluster State),维护了一个集群中,必要的信息 1)所有的节点信息 2)所有的索引和其相关的 Mapping 与 Setting 信息 3)分片的路由信息 任意节点都能修改信息会导致数据的不一致性 |
| Data Node | 可以保存数据的节点,叫做Data Node。负责保存分片数据。在数据扩展上起到了至关重要的作用 |
| Coordinating Node | 负责接受Client的请求,将请求分发到合适的节点,最终把结果汇集到一起,每个节点默认都起到了 Coordinating Node的职贵 |
| Hot & Warm Node | 不同硬件配置的 Data Node,用来实现 Hot & Warm 架构,降低集群部署的成本 |
| Machine Learning Node | 负责跑 机器学习的Job,用来做异常检测 |
| Tribe Node | (5.3 开始使用 Cross Cluster Serarch)Tribe Node 连接到不同的 Elasticsearch 集群,并且支持将这些集群当成一个单独的集群处理 |
2.2 节点基本信息
GET _cat/nodes?v
GET /_cat/nodes?v&h=id,ip,port,v,m

2.3 获取单个节点的详细信息
GET /_nodes/node-1
3. 索引(Index)
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。
能搜索的数据必须索引,这样的好处是可以提高查询速度,比如:新华字典前面的目录就是索引的意思,目录可以提高查询速度。
Elasticsearch索引的精髓:一切设计都是为了提高搜索的性能。
3.1 页面查看索引信息
页面查看索引信息,左侧菜单打开StackManagement

包括隐藏的索引
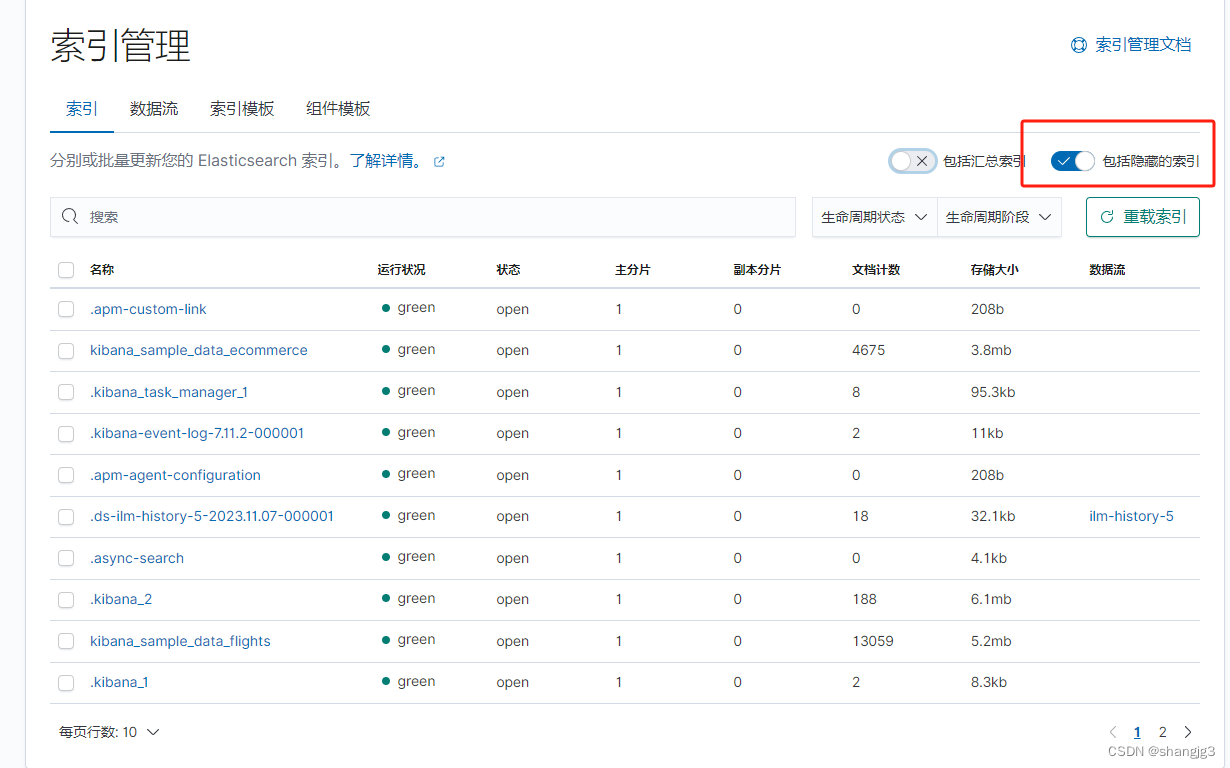
3.2 命令查看索引信息
或者可以切换到开发工具视图,用开发工具查询
GET /_cat/indices
3.3 查看kibana前缀的索引信息
GET /_cat/indices/kibana*?v&s=index
3.4 查看状态为健康的索引信息
GET /_cat/indices?v&health=green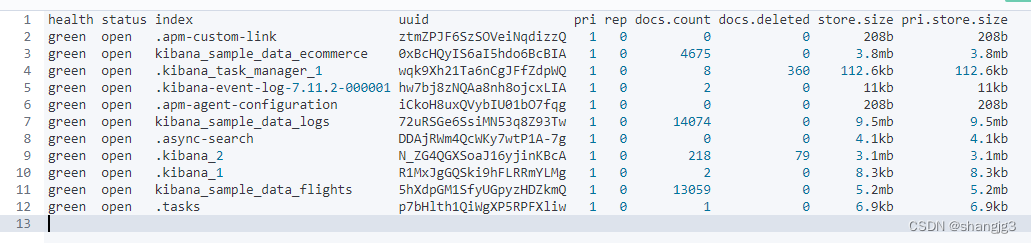
3.5 索引文档数量排序
GET /_cat/indices?v&s=docs.count:desc
3.6 查看单个索引的详细信息
GET kibana_sample_data_ecommerce在这里会列出索引的别名、映射和设置信息。
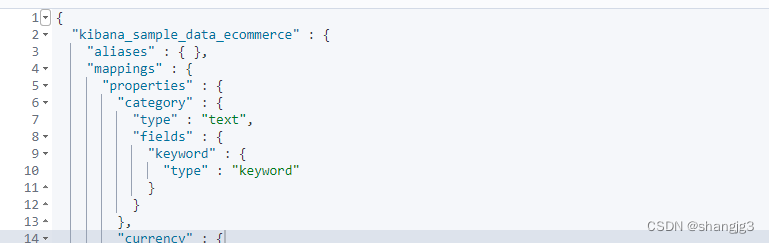
3.7 查看索引的文档总数
#查看索引的文档总数
GET kibana_sample_data_ecommerce/_count{"count" : 4675,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0
}
}
3.8 查看索引的前10条文档
#查看前10条文档,了解文档格式
POST kibana_sample_data_ecommerce/_search3.9 创建索引
PUT myindex
3.10 删除索引
DELETE myindex
4.分片(Shards)
4.1 分片简介
一个索引可以存储超出单个节点硬件限制的大量数据。比如,一个具有10亿文档数据的索引占据1TB的磁盘空间,而任一节点都可能没有这样大的磁盘空间。或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,每一份就称之为分片。
当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片很重要,主要有两方面的原因:
1)允许你水平分割 / 扩展你的内容容量。
2)允许你在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合和搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的,无需过分关心。
被混淆的概念是,一个 Lucene 索引 我们在 Elasticsearch 称作 分片 。 一个 Elasticsearch 索引 是分片的集合。 当 Elasticsearch 在索引中搜索的时候, 他发送查询到每一个属于索引的分片(Lucene 索引),然后合并每个分片的结果到一个全局的结果集。
总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。默认情况下,Elasticsearch中的每个索引被分片1个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有1个主分片和另外1个复制分片(1个完全拷贝),这样的话每个索引总共就有2个分片,我们需要根据索引需要确定分片个数。
4.2 主分片(Primary Shard )和副本分片(Replica Shard)
主分片,用以解决数据水平扩展的问题。通过主分片,可以将数据分布到集群内的所有节点之
一个分片是一人运行的 Lucene 的实例
主分片数在索引创建时指定,后续不允许修改,除非 Reindex副本,用以解决数据高可用的问题。分片是主分片的拷贝。
副本分片数,可以动态题调整。
增加副本数,还可以在一定程度上提高服务的可用性(读取的吞吐)。
4.3 分片设定策略

一个三节点的集群中,blogs 索引的分片分布情况,思考:增加一个节点或改大主分片数对系统的影响?
对于生产环境中分片的设定,需要提前做好容量规划
| 分片数设置过小 | 1)后续无法增加节点实现水品扩展 2)单个分片的数据量太大,导致数据重新分配耗时 |
| 分片数设置过大 | 1)影响搜索结果的相关性打分,影响统计结果的准确性 2)单个节点上过多的分片,会导致资源浪费,同时也会影响性能 3)7.0开始,默认主分片设置成1,解决了over-sharding的问题 |
GET _cat/shards
GET _cat/shards?h=index,shard,prirep,state,unassigned.reason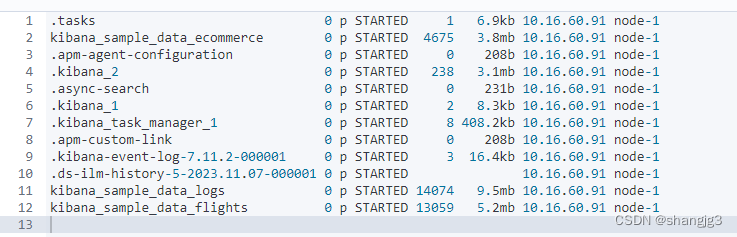
5.副本(Replicas)
在一个网络 / 云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片(副本)。
复制分片之所以重要,有两个主要原因:
1)在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。
2)扩展你的搜索量/吞吐量,因为搜索可以在所有的副本上并行运行。
总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。默认情况下,Elasticsearch中的每个索引被分片1个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有1个主分片和另外1个复制分片(1个完全拷贝),这样的话每个索引总共就有2个分片,我们需要根据索引需要确定分片个数。
相关文章:
ElasticSearch的集群、节点、索引、分片和副本
Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档。为了方便大家理解,我们将Elasticsearch里存储文档数据和关系型数据库MySQL存储数据的概念进行一个类比 ES里的Index可以看做一个库,而Types相当于表,Documents则相当…...

std::cout无法打印uint8_t类型的数据
std::cout在处理uint8_t变量类型的时候默认输出字符,刚好数字0-10对应的ascii字符都是不可打印的 解决: 使用static_cast std::cout << static_cast<int>(time) << std::endl;参考文章:https://blog.csdn.net/weixin_459…...
浅谈泛在电力物联网在智能配电系统应用
贾丽丽 安科瑞电气股份有限公司 上海嘉定 201801 摘要:在社会经济和科学技术不断发展中,配电网实现了角色转变,传统的单向供电服务形式已经被双向能流服务形式取代,社会多样化的用电需求也得以有效满足。随着物联网技术的发展&am…...

已解决:云原生领域的超时挂载Bug — Kubernetes深度剖析
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

概念解析 | 高光谱图像:揭开自然世界的神秘面纱
注1:本文系“概念解析”系列之一,致力于简洁清晰地解释、辨析复杂而专业的概念。本次辨析的概念是:高光谱图像 高光谱图像:揭开自然世界的神秘面纱 Hyperspectral imaging - Wikipedia 背景介绍 我们生活的世界充满了丰富多彩的颜色。这些颜色来源于各种物体反射或吸收不同波长…...
Java类和对象(1)
🐵本篇文章将会开始对类和对象的第一部分讲解 一、简单描述类和对象 对象可以理解为一个实体,在现实生活中,比如在创建一个建筑之前,要先有一个蓝图,这个蓝图用来描述这个建筑的各种属性;此时蓝图就是类&a…...

百度上海智能研发中心一面
Prometheus告警机制原理 介绍hashmap和concurrentHashmap concurrentHashmap和hashmap如果线程1在遍历 另一个线程对这个map进行修改操作 会发生什么现象 对线程安全的理解 通过什么方法解决线程安全 除了上锁 CAS等还有其他手段 不用锁的话 (集合的类设计成一…...
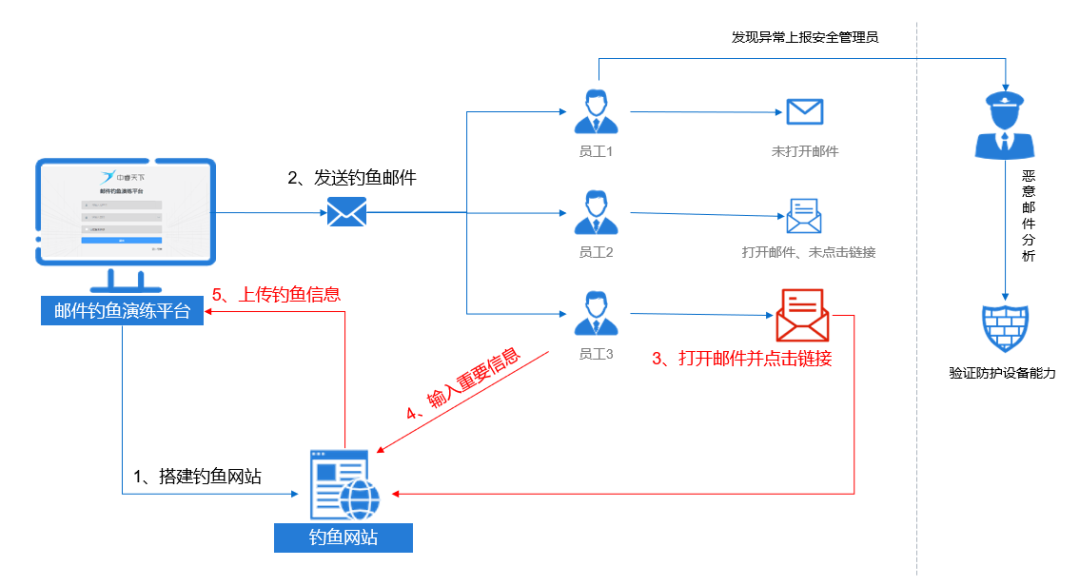
硝烟后的茶歇 | 中睿天下谈攻防演练之邮件攻击溯源实战分享
近日,由中国信息协会信息安全专业委员会、深圳市CIO协会、PCSA安全能力者联盟主办的《硝烟后的茶歇广东站》主题故事会在深圳成功召开。活动已连续举办四年四期,共性智慧逐步形成《年度红蓝攻防系列全景图》、《三化六防“挂图作战”》等共性研究重要成果…...
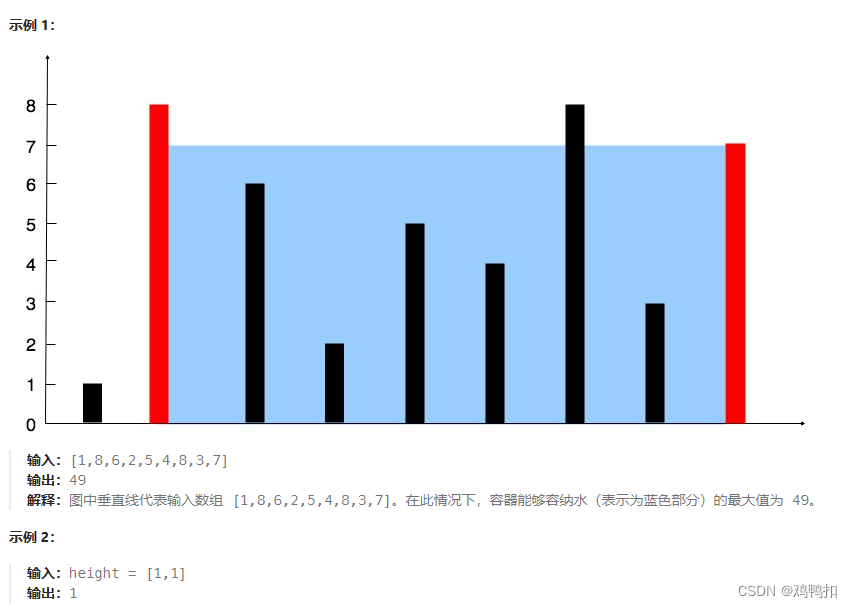
Leetcode Hot 100之四:283. 移动零+11. 盛最多水的容器
283.移动零 题目: 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请注意 ,必须在不复制数组的情况下原地对数组进行操作。 示例 1: 输入: nums [0,1,0,3,12] 输出: [1,3,12,0,0] …...

景联文科技助力金融机构强化身份验证,提供高质量人像采集服务
随着社会的数字化和智能化进程的加速,人像采集在金融机构身份认证领域中发挥重要作用,为人们的生活带来更多便利和安全保障。 金融机构在身份验证上的痛点主要包括以下方面: 身份盗用和欺诈风险:传统身份验证方式可能存在漏洞&am…...
Spring Cloud LoadBalancer基础知识
LoadBalancer 概念常见的负载均衡策略使用随机选择的负载均衡策略创建随机选择负载均衡器配置 Nacos 权重负载均衡器创建 Nacos 负载均衡器配置 自定义负载均衡器(根据IP哈希策略选择)创建自定义负载均衡器封装自定义负载均衡器配置 缓存 概念 LoadBalancer(负载均衡器)是一种…...
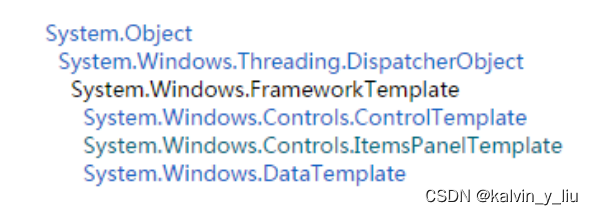
剖析WPF模板机制的内部实现
剖析WPF模板机制的内部实现 众所周知,在WPF框架中,Visual类是可以提供渲染(render)支持的最顶层的类,所有可视化元素(包括UIElement、FrameworkElment、Control等)都直接或间接继承自Visual类。…...

计算机网络常见的名词解释
计算机网络常见的名词解释 1.应用层2.传输层3. 网络层4.链路层5. 无线网络和移动网络6.计算机网络中的安全 1.应用层 API (Application Programming Interface)应用程序编程接口HTTP (Hyper Text Transfer Protocol) 超文本传输协…...
Android Studio导入,删除第三方库
Android项目经常用到无私的程序员们提供的第三方类库。本篇博客就是实现第三方库的导入和删除。 一、导入第三方库 1、将需要的库下载到本地; 2、新建Moudle (1)File --- New Moudle (2)选择Android Library --- Next (3)填写Moudle名 --- Finish。一个新的Mou…...

生成指定长度的随机数字,用对方法精准提效数10倍!
生成指定长度的随机数字这一函数功能可能在以下情况下被使用: 密码生成:在需要生成随机密码时,可以使用该功能生成指定长度的随机数字作为密码。 随机数生成:在需要生成一定长度的随机数列时,可以使用该功能生成随机…...
Vue3 + Naive-ui Data Table 分页页码显示不全
当使用naive-ui 表格并且使用分页组件的时候 需要增加 remote...
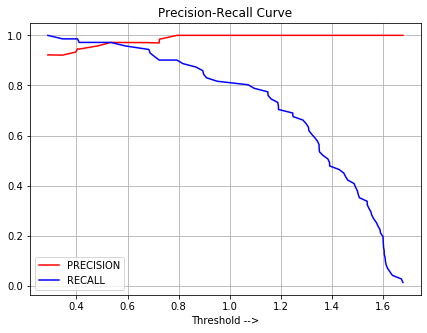
机器学习中的决策阈值
什么是决策阈值? sklearn不允许我们直接设置决策阈值,但它允许我们访问用于进行预测的决策分数(决策函数o/p)。我们可以从决策函数输出中选择最佳得分并将其设置为决策阈值,并且将小于该决策阈值的所有那些决策得分值…...
mongodb导出聚合查询的数据
❗️❗️❗️在正文之前先要讲一个坑,就是mongoexport这个命令工具不支持导出聚合查询的数据,比如通过某某字段来分组 我查了一天关于mongoexport怎么来导出聚合查询的结果集,最终还是gpt给了我答案 😭 既然mongoexport不支持&…...

U-Mail信创邮件系统解决方案
近年来,在国家政策的大力引导和自身数字化转型需求驱动下,国产化成为国内数字化发展道路上的关键词,企业不断加强自主创新能力,进行信创建设,实现软硬件系统国产化替代,已成为大势所趋。邮件系统作为企业管…...
GUI:贪吃蛇
以上是准备工作 Data import javax.swing.*; import java.net.URL;public class Data {public static URL headerURLData.class.getResource("static/header.png");public static ImageIcon header new ImageIcon(headerURL);public static URL upURLData.class.getR…...

CardEditor:桌游卡牌设计的革命性批量生成解决方案
CardEditor:桌游卡牌设计的革命性批量生成解决方案 【免费下载链接】CardEditor 一款专为桌游设计师开发的批处理数值填入卡牌生成器/A card batch generator specially developed for board game designers 项目地址: https://gitcode.com/gh_mirrors/ca/CardEdi…...

FLUX.1-Krea-Extracted-LoRA实操手册:Streamlit前端CSS美化与交互优化
FLUX.1-Krea-Extracted-LoRA实操手册:Streamlit前端CSS美化与交互优化 1. 模型概述与快速部署 FLUX.1-Krea-Extracted-LoRA 是一款基于 FLUX.1-dev 基础模型的风格迁移工具,通过提取的 LoRA 权重为生成的图像注入专业摄影级别的真实感。相比普通AI生成…...

RISC-V实战:手把手教你为蜂鸟E203设计一个简单的矩阵累加协处理器
RISC-V实战:从零构建蜂鸟E203矩阵累加协处理器 在嵌入式系统设计中,性能优化始终是开发者面临的核心挑战。当标准处理器无法满足特定算法的计算需求时,定制化硬件加速器便成为提升效率的关键。本文将带领您完成一个完整的RISC-V协处理器开发项…...

百度网盘高速下载终极方案:3分钟免费解锁全速下载
百度网盘高速下载终极方案:3分钟免费解锁全速下载 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘下载速度慢如蜗牛而烦恼吗?今天我要分…...

SMT工厂数字孪生落地:2026实战选型手册
本手册提供从认知到执行的完整行动清单。第一部分:落地前的认知统一明确核心价值主张:提升OEE、缩短换线时间、实现零缺陷传递。接受渐进式路线:从一条线做起,快速验证、迭代。确立内部责任人:指定既懂生产又具项目管理…...

从 ng-content 到聚合机制,SAP UI5 里有没有 Angular 式内容投影
我每次把一个 Angular 组件的思路搬到 SAP UI5 里,最容易卡住的地方,往往不是属性绑定,也不是事件,而是这种很像 slot 的内容投放能力。Angular 官方把 ng-content 定义得非常明确,它不是一个普通的 DOM 元素,也不是组件,而是一个专门告诉框架把外部子内容渲染到哪里去的…...

从Datawhale的Vibe镜像看数据科学协作环境的Docker化实践
1. 项目概述:从开源镜像名到数据科学协作生态最近在整理自己的开发环境,准备搭建一个用于数据分析和可视化的新项目。在寻找合适的工具和资源时,我习惯性地会去各大开源镜像站看看,比如清华的TUNA、阿里云的开源镜像站。就在这个过…...

深入STM32以太网DMA与MAC内核:如何用标准库和LWIP实现高效零拷贝网络通信
深入STM32以太网DMA与MAC内核:零拷贝网络通信实战指南 1. 底层架构解析:从硬件加速到协议栈优化 在嵌入式网络通信领域,STM32的以太网外设提供了一套完整的硬件加速方案。MAC内核与专用DMA控制器的协同工作机制,为资源受限环境下的…...

AI试衣系统源码-一键换衣换装-支持姿态识别+纹理融合-批量生成-SAAS模式-电商创业利器
温馨提示:文末有资源获取方式在电商竞争日益激烈的今天,商品展示效果直接决定着转化率的高低。尤其是服装类目,传统的模特拍摄不仅成本高昂,而且周期长、效率低。针对这一市场难题,我们团队倾力打造了一款革命性的AI试…...

告别Windows Terminal单调CMD:用Oh My Zsh打造你的高效WSL2开发终端
告别Windows Terminal单调CMD:用Oh My Zsh打造你的高效WSL2开发终端 每次在Windows Terminal里敲命令时,看着那个灰扑扑的CMD界面,是不是总觉得少了点什么?作为一名长期在Windows和WSL2之间切换的开发者,我深刻理解那…...