【论文阅读】DALL·E: Zero-Shot Text-to-Image Generation
OpenAI第一代文本生成图片模型
paper:https://arxiv.org/abs/2102.12092
DALL·E有120亿参数,基于自回归transformer,在2.5亿 图片-文本对上训练的。实现了高质量可控的text to image,同时也有zero-shot的能力。
DALL-E没有使用扩散模型,而是dVAE(discrete variational autoencoder离散变分自动编码器)。文中主要和GAN相关模型进行比较,如AttnGAN、DM-GAN、DF-GAM。
1. 介绍
自回归式的模型处理图片的时候,如果直接把像素拉成序列,当成image token来处理,如果图片分辨率过高,一方面会占用过多的内存,另一方面Likelihood的目标函数会倾向于建模短程的像素间的关系,因而会学到更多的高频细节,而不是更能被人辨认的低频结构。
与 GPT-3 一样,DALL·E是一个 Transformer 语言模型。它将文本和图像作为单个数据序列接收,通过Transformer进行自回归。
Zero-Shot:对于GPT-3来说,我们可以指示它仅根据描述和提示执行多种任务,来生成我们想要的答案,而无需任何额外的培训。例如,当提示“here is the sentence 'a person walk his dog in the park' translated into French: ”时,GPT-3 会回答“un homme qui promène son chien dans le parc”。这种能力称为零样本推理。研究者发现 DALL·E 将这种能力扩展到了视觉领域,在以正确的方式提示时,它能够执行多种图像到图像的转换工作。比如最直接的方法是输入一张照片,然后用文本描述“粉红色的照片”或“倒影的照片”,这也往往是最可靠的,尽管照片通常没有被完美地复制或反映,但也从一定程度上表明这个功能有望实现。实现图像版GPT-3。
功能一,创造拟人的器具

功能二,Dall-E能够很聪明地捕捉到每个事物的特性,并且合理地组织在了一起。

功能三,根据文本自动渲染真实场景图片,其仿真程度与真实照片十分接近

功能四,根据文本指令改变和转换现有图片风格。
 不同于GAN(生成式对抗网络)的一点是,虽然GAN能够替换视频里的人脸,但其仅仅限制于人脸的范畴,而Dalle是将概念和概念之间做了关联,这在以往也是从未被实现过的。
不同于GAN(生成式对抗网络)的一点是,虽然GAN能够替换视频里的人脸,但其仅仅限制于人脸的范畴,而Dalle是将概念和概念之间做了关联,这在以往也是从未被实现过的。
2. 方法
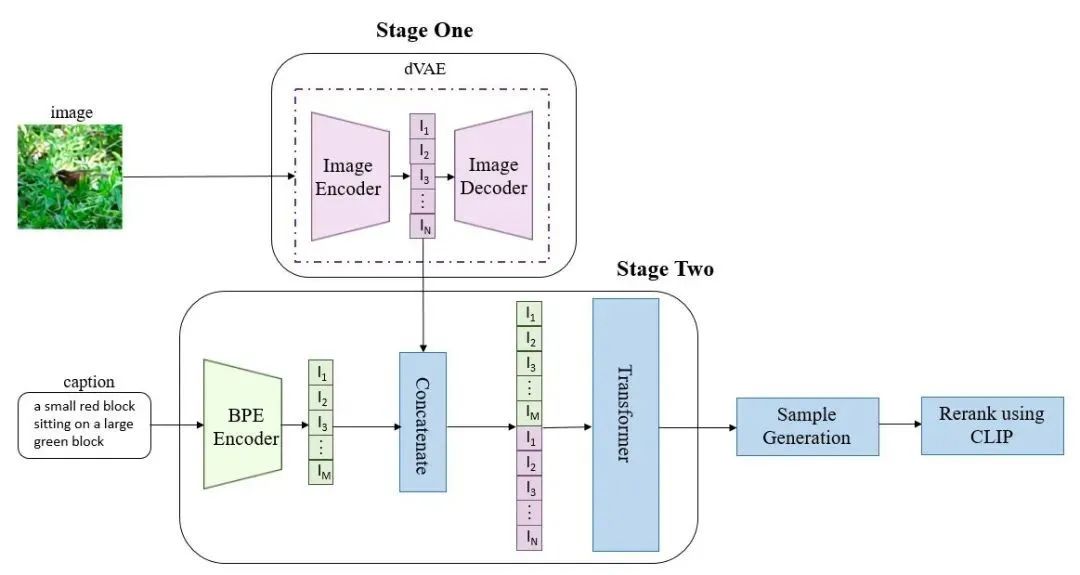
整体流程如下:
1.第一个阶段,训练一个dVAE(discrete variational autoencoder离散变分自动编码器),其将256*256的RGB图片转换为32*32的图片token。目的:降低图片的分辨率,从而解决计算量的问题。图片token的词汇量大小是8192个,即每个位置有8192种可能的取值(也就是说dVAE的encoder输出是维度为32x32x8192的logits,然后通过logits索引codebook的特征进行组合,codebook的embedding是可学习的)。第一阶段同时训练dVAE编码器和dVAE解码器。
2.第二阶段,用BPE Encoder对文本进行编码,得到最多256个文本token,token数不满256的话padding到256,然后将256个文本token与1024个图像token(32*32=1024)进行拼接,得到长度为1280的数据,用拼接的数据去训练一个自回归transformer来建模文本和图片token的联合分布。

3.最后的推理阶段,给定一张候选图片和一条文本,通过transformer可以得到融合后的token,然后用dVAE的decoder生成图片,最后通过预训练好的CLIP计算出文本和生成图片的匹配分数,得到不同采样图片的分数排序,最终找到跟文本最匹配的图片。
从以上流程可知,dVAE、Transformer和CLIP三个模型都是不同阶段独立训练的。下面讲一下dVAE、Transformer和CLIP三个部分。
3. 组成
3. 1 dVAE
由于图像特征的密集性和冗余性,不能直接提供给Transformer进行训练。目前主流的方式,例如ViT,Swin-Transformer等都是将图像的Patch作为模型的输入,然后通过一个步长等于Patch大小的大卷积核得到每个Patch的特征向量。
DALL-E提供的方案是使用离散的变分自编码器(dVAE)将大小为256x256的RGB图像压缩到大小为32x32的,通道数为8192的one-hot token的分布,变分自编码器的架构如图2所示。换句话说,阶段1的作用是将图像映射到一个大小为8192的图表中。这里通道数为8192的one-hot向量可以看做是一个词表,它的思想是通过离散VAE,实现图像特征空间想文本特征空间的映射。
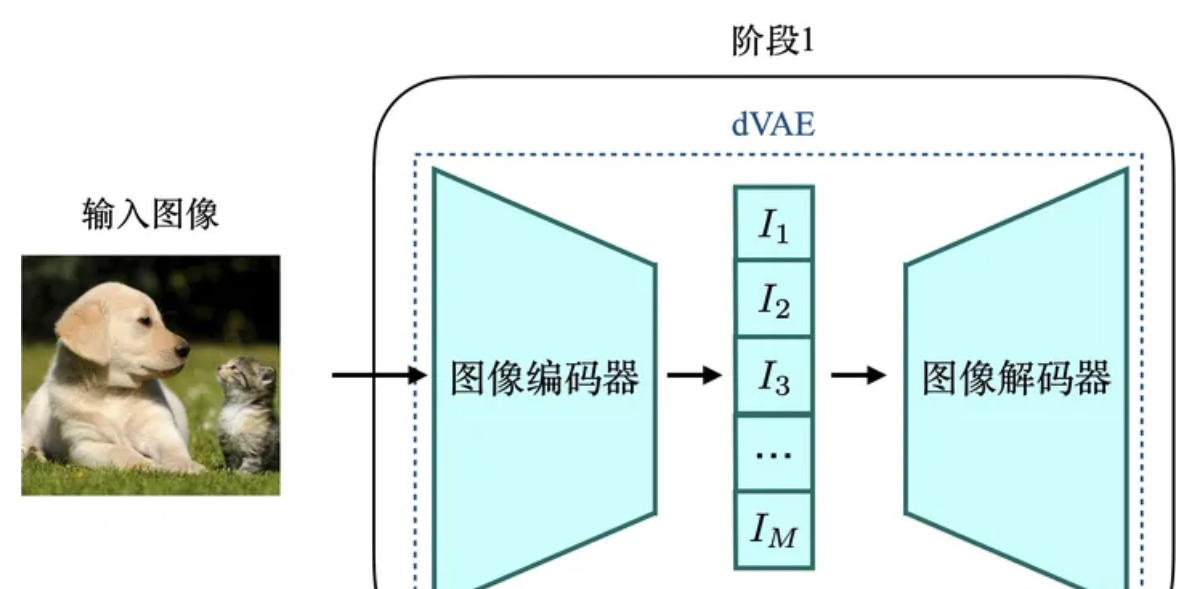
不同于AE的是,VAE的预测不再是一个值,而是一个分布,通过在分布上的随机采样便可以解码成不同的生成内容。给定一个输入x,VAE的编码器的输出应该是特征z的后验分布![]() 。
。
VQVAE:
通过Encoder学习出中间编码,然后通过最邻近搜索将中间编码映射为codebook中K个向量之一,然后通过Decoder对latent code进行重建。
另外由于最邻近搜索使用argmax来找codebook中的索引位置,导致不可导问题,VQVAE通过stop gradient操作来避免最邻近搜索的不可导问题,也就是latent code的梯度跳过最近邻搜索直接复制到中间编码上。
VQVAE相比于VAE最大的不同是,直接找每个属性的离散值,通过类似于查表的方式,计算codebook和中间编码的最近邻作为latent code。由于维护了一个codebook,编码范围更加可控,VQVAE相对于VAE,可以生成更大更高清的图片(这也为后续DALLE和VQGAN的出现做了铺垫)。

作用:
dVAE主要用来为图像的每个patch生成token表示,这次openAI开出的代码就是dVAE的推理代码。dVAE的encoder和decoder的机构较为简单,都是由bottleneck-style的resblock组成,相比于普通的VAE,dVAE有两点区别:
1.和VQVAE方法相似,dVAE的encoder是将图像的patch映射到8192的词表中,论文中将其分布设为在词表向量上的均匀分类分布,这是一个离散分布,由于不可导,此时不能采用重参数技巧,DALL·E使用Gumbel Softmax trick来解决这个问题。
2、在重建图像时,真实的像素值是在一个有界区间内,而VAE中使用的Gaussian分布和Laplace分布都是在整个实数集上,这造成了不匹配的问题。为了解决这个问题,论文中提出了logit-Laplace分布,如下式所示:
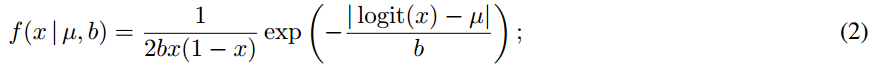
3.2 Transformer
Dall-E中的Transformer结构由64层attention层组成,每层的注意力头数为62,每个注意力头的维度为64,因此,每个token的向量表示维度为3968。如图2所示,attention层使用了行注意力mask、列注意力mask和卷积注意力mask三种稀疏注意力。

图2 Transformer使用的3种稀疏注意力
训练方法是用seq2seq的方法,用前面的序列预测下一个token,结合上mask的设计,可以实现行预测或者列预测。
Transformer的输入如图3所示,其中pad embd通过学习得到,根据论文介绍,为每个位置都训练了一个pad embd,即256个pad embd,在对文本token进行pad时,使用对应位置的pad embd。

图3 Transformer输入示意图(假设文本最大长度6)
训练目标:采用Evidence Lower BOund (ELBO,推导详见文章最下面)。如下: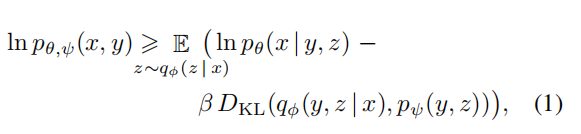
x指图片,y指文本,z指对编码的图片(用于生成图片)。

3.3 CLIP
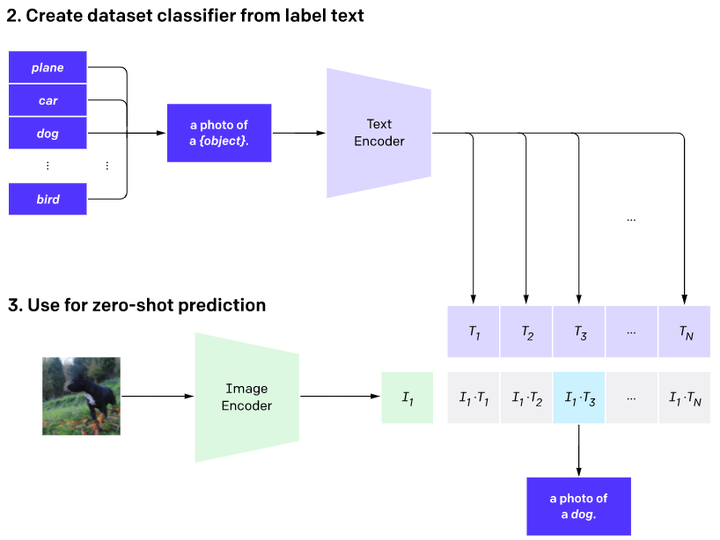
CLIP的推理过程:
1.先将预训练好的CLIP迁移到下游任务,如图(2)所示,先将下游任务的标签构建为一批带标签的文本(例如 A photo of a {plane}),然后经过Text Encoder编码成一批相应的word embedding。
2.然后将没有见过的图片进行zero-shot预测,如图(3)所示,通过Image Encoder将一张小狗的图片编码成一个feature embedding,然后跟(2)编码的一批word embedding先归一化然后进行点积,最后得到的logits中数值最大的位置对应的标签即为最终预测结果。
在DALL·E中,CLIP的用法跟上述过程相反,提供输入文本和一系列候选图片,先通过Stage One和Stage Two生成文本和候选图片的embedding,然后通过文本和候选图片的匹配分数进行排序,最后找到跟文本最匹配的图片。
总结:总的来说,目前公开的DALL-E的实现在模型结构上并没有太多创新,而是合理利用了现有的模型结构进行组合,并采用了一些trick解决了遇到的问题,从而在大数据集上训练得到超大规模的模型,取得了令人惊艳的效果,这也符合openAI的一贯风格。但无论如何,DALL-E在深度学习能力边界探索的道路上又前进了一步,也再一次展示了大数据和超大规模模型的魅力。美中不足的是,DALL-E包含了三个模块,更像是一个pipeline,而对于普通的研究者来说,要运行这样一个复杂的大规模模型是一件很困难的事情。
参考:DALL·E: Zero-Shot Text-to-Image Generation - 知乎
如何评价DALL-E模型的实现? - 知乎
相关文章:
【论文阅读】DALL·E: Zero-Shot Text-to-Image Generation
OpenAI第一代文本生成图片模型 paper:https://arxiv.org/abs/2102.12092 DALLE有120亿参数,基于自回归transformer,在2.5亿 图片-文本对上训练的。实现了高质量可控的text to image,同时也有zero-shot的能力。 DALL-E没有使用扩…...

说一下 toRef、toRefs,以及他们的区别
toRef:创建一个新的Ref变量,转换Reactive对象的某个字段为Ref变量 toRefs:创建一个新的对象,它的每个字段都是Reactive对象各个字段的Ref变量 说一下toRef 先定义一个reactive对象 interface Member {id: numbername: string } c…...
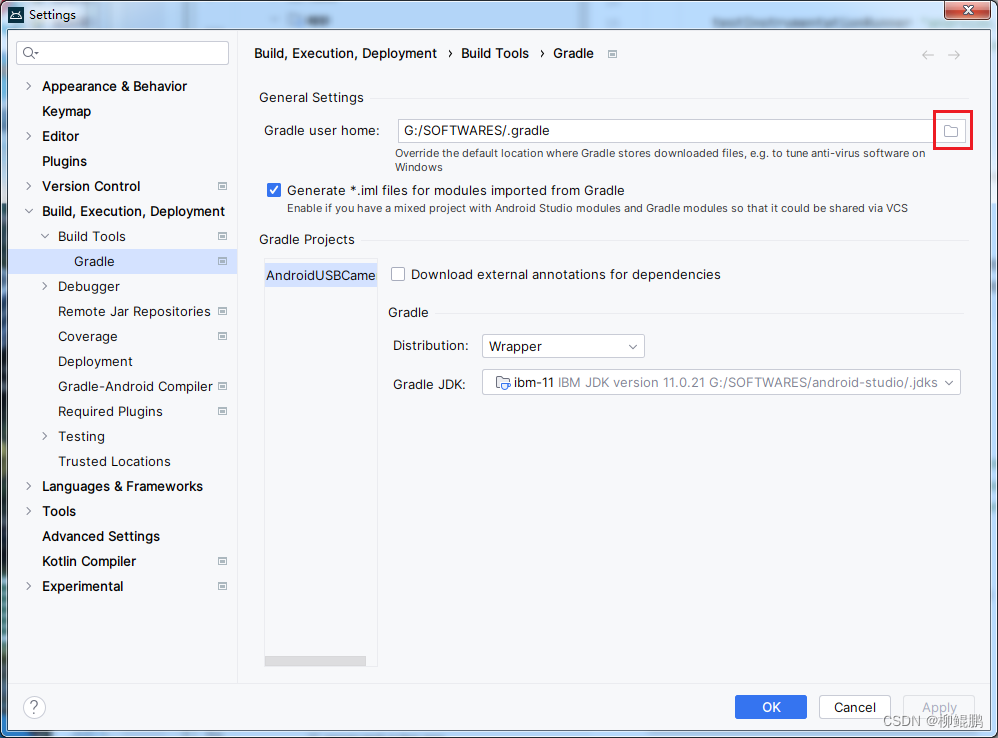
修改Android Studio默认的gradle目录
今天看了一下,gradle在C盘占用了40多G。我C盘是做GHOST的,放在这里不方便。所以就要修改。 新建目录名(似乎无必要) ANDROID_SDK_HOMEG:\SOFTWARES\android-sdk GRADLE_USER_HOMEG:\SOFTWARES\.gradle 修改目录 File->Setti…...

鲁大师电动车智能化测评报告第二十三期:实测续航95km,九号Q90兼顾个性与实用
鲁大师第二十三期智能化电动车测评排行榜数据来源于鲁大师智慧实验室,测评的车型均为市面上主流品牌的主流车型。截止目前,鲁大师智能化电动车测评的车型高达130余台,且还在不断增加和丰富中。 一、测评依据 鲁大师电动车智能化测评体系包含车辆的状态采集与管理硬件系统、车辆…...
)
初始化项目骨架(Web3项目一实战之一)
暌违将近一年的时光,也该是时候来几个项目实践。要不,当再次翻看 玩以太坊链上项目的必备技能(…solidity之旅X) ,却未曾见有关于 Web3 项目的实战博文,不免让人唏嘘! 其实,在我敲下玩以太坊链上项目的必备技能这些文字时,心中早有了势必要弄出一个Web3的项目(当然,通…...

在opencv OpenCV中打开相机摄像头,用分水岭算法实时实现图像的分割与提取
import cv2 import numpy as np# 定义回调函数 def callback(x):pass# 打开摄像头 cap cv2.VideoCapture(0)# 创建窗口和控件 cv2.namedWindow(image) cv2.createTrackbar(threshold, image, 0, 255, callback)# 初始化参数 bgdModel np.zeros((1, 65), np.float64) fgdModel…...
CodeWhisperer 的正确使用
1、重点: 重点1: 推出 Amazon Bedrock。这项新服务允许用户通过 API 访问来自 AI21 Labs、Anthropic、Stability AI 和亚马逊的基础模型。(Anthropic 就是之前跟 ChatGPT 掰手腕的 Claude 的模型。Stability AI 就是 Stable Diffusion 背后的…...

selenium xpath定位
selenium-xpath定位 <span style"background-color:#2d2d2d"><span style"color:#cccccc"><code class"language-javascript">element_xpath <span style"color:#67cdcc"></span> driver<span styl…...
「我在淘天做技术」音视频技术及其在淘宝内容业务中的应用
作者:李凯 一、前言 近年来,内容电商似乎已经充分融入到人们的生活中:在闲暇时间,我们已经习惯于拿出手机,从电商平台的直播间、或者短视频链接下单自己心仪的商品。 尽管优质的货品、实惠的价格、精致的布景、有趣的…...

el-input 输入后失去焦点
说了是无情,写了更无情,你说你看了不点赞是不是更绝情?遇到这种神奇的BUG,也是大家无奈的神情。 来分析看代码: <div class"card-item input-item" :class"{ w-100: followRadio 2 }"v-for&…...
docker创建并访问本地前端
docker创建并访问本地前端,直接上命令: 安装nginx镜像: docker pull nginx 查看已安装的nginx: docker images 创建DockerFile文件,直接在当前文件夹种创建 touch Dockerfile 在Dockerfile写入内容: F…...

数据结构之单链表基本操作
🤷♀️🤷♀️🤷♀️ 今天给大家分享的是单链表的基本操作。 清风的个人主页 🎉欢迎👍点赞✍评论❤️收藏 😛😛😛希望我的文章能对你有所帮助,有不足的地方还请各位…...

Python 实践
文章目录 一、HttpRequests 一、Http Requests python——Request模块...
使用easyui前端框架快速构建一个crud应用
本篇文章将会详细介绍jquery easyui前端框架的使用,通过创建一个crud应用来带大家快速掌握easyui的使用。 easyui是博主最喜欢的前端框架,没有之一,因为它提供了多种主题,而且有圆润的各种组件。 一、快速开始 easyui的官网地址&…...

Logback从添加依赖,到配置给中打印级别,archive相关信息配置,在项目中的常见的用法,一个完整的过程
添加Logback依赖: 在您的Maven或Gradle项目中,添加Logback依赖。例如,在Maven中,可以将以下依赖添加到pom.xml文件中: <dependency><groupId>ch.qos.logback</groupId><artifactId>logback-c…...

虚假内容检测,谣言检测,不实信息检测,事实核查;纯文本,多模态,多语言;数据集整理
本博客系博主个人理解和整理所得,包含内容无法详尽,如有补充,欢迎讨论。 这里只提供数据集相关介绍和来源出处,或者下载地址等,因版权原因不提供数据集所含的元数据。如有需要,请自行下载。 “Complete d…...
数据结构:单链表
文章目录 🍉前言🍉基本概念🍉链表的分类🍌单链表节点的结构🍌创建节点🍌打印链表🍌插入和删除🥝尾插🥝头插🥝尾删🥝头删🥝指定位置之前…...
官媒代运营:让大众倾听品牌的声音
在当今数字时代,媒体的影响力和多样性远远超出了以往的范畴。品牌和企业越来越依赖媒体来传播信息、建立声誉以及与大众互动。而媒体矩阵成为了现代品牌传播的关键策略,使大众能够倾听品牌的声音。媒体矩阵:多元化的传播渠道 媒体矩阵是指利…...

postgresql 实现计算日期间隔排除周末节假日方案
前置条件:需要维护一张节假日日期表。例如创建holiday表保存当年假期日期 CREATE TABLE holiday (id BIGINT(10) ZEROFILL NOT NULL DEFAULT 0,day TIMESTAMP NULL DEFAULT NULL,PRIMARY KEY (id) ) COMMENT假期表 COLLATEutf8mb4_0900_ai_ci ;返回日期为xx日xx时x…...
金融工作怎么做?低代码如何助力金融行业
10月30日至31日,中央金融工作会议在北京举行。金融是国民经济的“血脉”,是国家核心竞争力的重要组成部分。会议指出,党的十八大以来,在党中央集中统一领导下,金融系统有力支撑经济社会发展大局,坚决打好防…...

Apache Kylin Cube设计实战:从销售数据模型出发,手把手教你规划维度和度量
Apache Kylin Cube设计实战:销售数据分析的维度与度量艺术 当企业积累了大量销售数据后,如何快速获取业务洞察成为关键挑战。传统Hive查询在面对亿级数据时响应缓慢,而Apache Kylin通过预计算技术将查询速度提升百倍。本文将基于典型的销售数…...

网站怎么创建?
网站怎么创建?现在很多公司企业都会有自己的网站,即使是没有网站的公司也抓紧时间纷纷入局,希望能在互联网的流量中分到一杯羹。那么网站怎么创建呢?下面给大家简单说一说。网站怎么创建步骤1:首先我们准备好一个域名。…...
data-transfer-object集合处理技巧:数组和DTO集合的智能转换
data-transfer-object集合处理技巧:数组和DTO集合的智能转换 【免费下载链接】data-transfer-object Data transfer objects with batteries included 项目地址: https://gitcode.com/gh_mirrors/da/data-transfer-object data-transfer-object是一款功能强大…...

别再死记硬背了!用Python的combinations函数玩转数据组合,从抽奖到密码生成都能搞定
用Python的combinations函数解锁数据组合的无限可能 在数据处理和分析中,组合操作是一个常见但容易被低估的工具。Python标准库中的itertools.combinations函数提供了一种高效的方式来生成所有可能的组合,而无需手动编写复杂的嵌套循环。这个看似简单的函…...

避坑指南:赛元单片机触摸库配置,SOCAPI_SET_TOUCHKEY_CHANNEL和阈值到底怎么设?
赛元单片机触摸库实战:从参数解析到抗干扰配置全指南 第一次接触赛元单片机的电容触摸功能时,面对那一堆十六进制参数和模糊的文档说明,我盯着示波器上跳动的信号波形整整三天没睡好觉。电机干扰导致的误触发、阈值设置不当引发的响应迟钝、…...
)
农业边缘计算新范式(Docker 27原生支持ARM64+实时数据流容器化大揭秘)
第一章:农业边缘计算新范式与Docker 27演进全景农业智能化正从中心云向田间地头迁移,边缘计算不再仅是“补充”,而是成为精准灌溉、病虫害实时识别、农机协同调度的核心基础设施。在低带宽、高时延、设备异构的农田环境中,轻量、可…...

暗黑破坏神2存档编辑神器:5分钟掌握角色定制与装备管理
暗黑破坏神2存档编辑神器:5分钟掌握角色定制与装备管理 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 想要彻底掌控暗黑破坏神2的单机游戏体验吗?d2s-editor为您打开了一扇通往无限可能的大门࿰…...
)
保姆级教程:在Ubuntu 22.04上用Docker一键部署CloudCanal社区版(附端口占用排查)
保姆级教程:在Ubuntu 22.04上零障碍部署CloudCanal社区版 当你第一次听说CloudCanal这个数据同步工具时,可能和我当初一样既兴奋又忐忑。兴奋的是它号称能简化数据库之间的数据流动,忐忑的是部署过程会不会暗藏玄机。作为过来人,我…...

快速搭建本地语音识别:FireRedASR Pro一键部署,支持中文高精度识别
快速搭建本地语音识别:FireRedASR Pro一键部署,支持中文高精度识别 1. 项目概述 FireRedASR Pro是一款基于工业级语音识别模型开发的本地化ASR工具,特别针对中文语音识别场景进行了优化。它采用Streamlit构建交互界面,集成了强大…...
)
别再只会AB实验了!数据分析师必懂的5种因果推断方法(含PSM/DID实战避坑)
数据分析师进阶指南:5种超越AB实验的因果推断实战方法 当业务团队追问"这个功能上线后究竟带来了多少增量价值"时,你是否还在为无法进行随机分组实验而苦恼?作为经历过数百次业务分析的老兵,我深刻理解数据分析师面对非…...