Flink -- 状态与容错
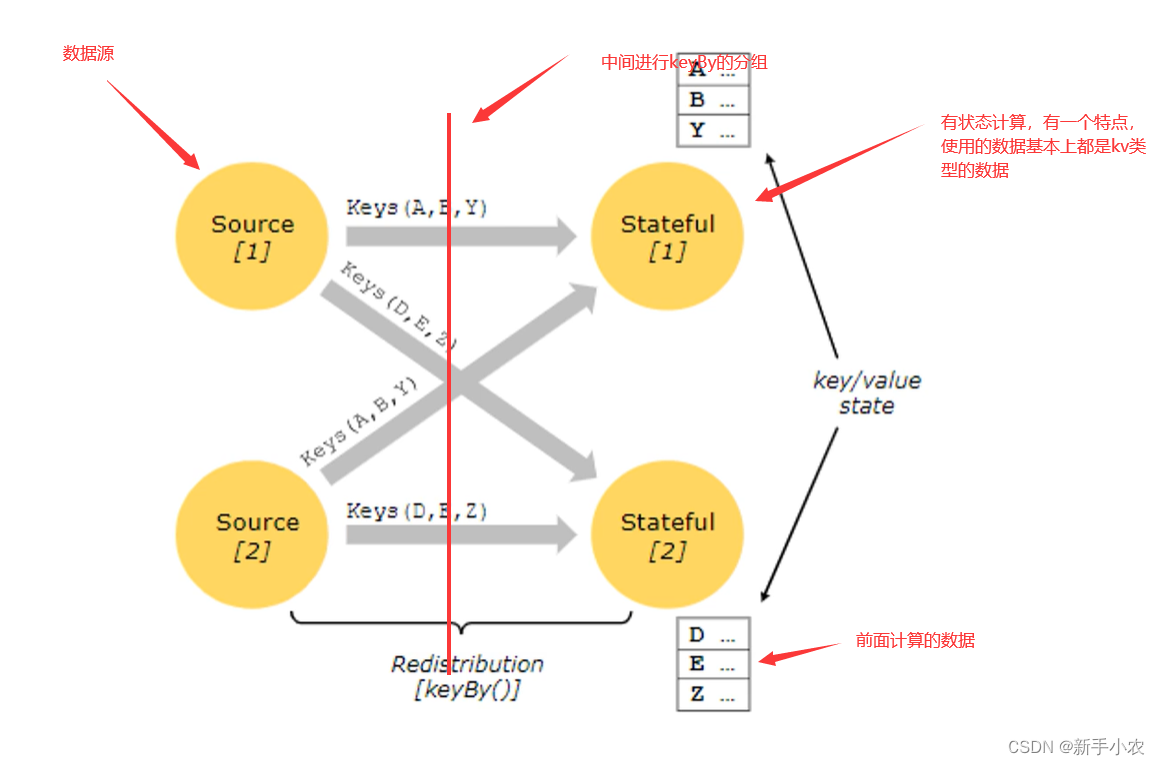
1、Stateful Operations 有状态算子:
有状态计算,使用到前面的数据,常见的有状态的算子:例如sum、reduce,因为它们在计算的时候都是用到了前面的计算的结果
总结来说,有状态计算并不是独立存在的,每一次的计算都与前面的数据是有关系的。所有的聚合算子都是有状态算子。
2、CheckPoint:
1、CheckPoint:定时将Flink的计算的状态持久化到Hdfs上,如果Flink的任务失败可以基于Hdfs中保存的状态恢复任务,能够保证任务的计算状态不丢失。checkpoint可以维护TB级别的计算状态。
2、Fllink会将计算状体存储两份,一份是存储在Flink内存中,放在内存中是为了获取查询更新,因为Flink在处理数据的是过程中,计算状态会改变,第二份是通过CheckPoint将计算状态持久化的存储到Hdfs中,这样可以保证Flink任务失败的时候可以基于Hdfs中存储的计算状态恢复任务。
总结:就是原先Flink的计算的状态是存储在内存中,但是为了防止计算状态丢失,就将Flink的计算状态持久化到Hdfs中。当任务中途失败后,找到最新的一个checkpoint,基于这个checkpoint中存储的数据作为计算状态恢复任务。
3、CheckPoint的开启方式:
1、在代码中单独开启checkpoint:
// 每 10000ms 开始一次 checkpoint
env.enableCheckpointing(10000)// 高级选项:
// 设置模式为精确一次 (这是默认值)
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)// 确认 checkpoints 之间的时间会进行 500 ms
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)// Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig.setCheckpointTimeout(60000)// 允许两个连续的 checkpoint 错误
env.getCheckpointConfig.setTolerableCheckpointFailureNumber(2)// 同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)// 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留
env.getCheckpointConfig.setExternalizedCheckpointCleanup(
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)//增量快照
env.setStateBackend(new EmbeddedRocksDBStateBackend(true))//将状态保存到hdfs中env.getCheckpointConfig.setCheckpointStorage("hdfs://master:9000/file/checkpoint")
public class Demo01CheckPoint {public static void main(String[] args) throws Exception{/*** 使用checkpoint来保存计算状态*///构建Flink环境:StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//开socketDataStreamSource<String> lineDS = env.socketTextStream("master", 8888);//开启checkpoint//指定10秒拍一次checkpointenv.enableCheckpointing(10000);//使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);//将计算状态保存到hdfs中env.getCheckpointConfig().setCheckpointStorage("hdfs://master:9000/file/checkpoint");//指定计算状态在Flink中的存储的位置:是基于磁盘还是存储在内存中//HashMapStateBackend(),表示的是数据存储在Flink的内存中env.setStateBackend(new HashMapStateBackend());//做wordCountSingleOutputStreamOperator<String> wordDS = lineDS.flatMap((line, out) -> {String[] split = line.split(",");for (String word : split) {//将数据循环发送到下游:out.collect(word);}},Types.STRING);//将上游传输过来的数据构建成kv形式的数据:SingleOutputStreamOperator<Tuple2<Object, Integer>> mapDS = wordDS.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT));//将构建好的数据进行分组KeyedStream<Tuple2<Object, Integer>, Object> keyByDS = mapDS.keyBy(kv -> kv.f0);//统计数量SingleOutputStreamOperator<Tuple2<Object, Integer>> countDS = keyByDS.sum(1);//打印数据countDS.print();//执行Flink:env.execute();}
}
2、在集群中统一开启checkpoint:
修改flink-conf.yaml配置文件# 修改以下配置
execution.checkpointing.interval: 5000
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
execution.checkpointing.max-concurrent-checkpoints: 1
execution.checkpointing.min-pause: 0
execution.checkpointing.mode: EXACTLY_ONCE
execution.checkpointing.timeout: 10min
execution.checkpointing.tolerable-failed-checkpoints: 0
execution.checkpointing.unaligned: false
state.backend: hashmap
state.checkpoints.dir: hdfs://master:9000/file/checkpoint
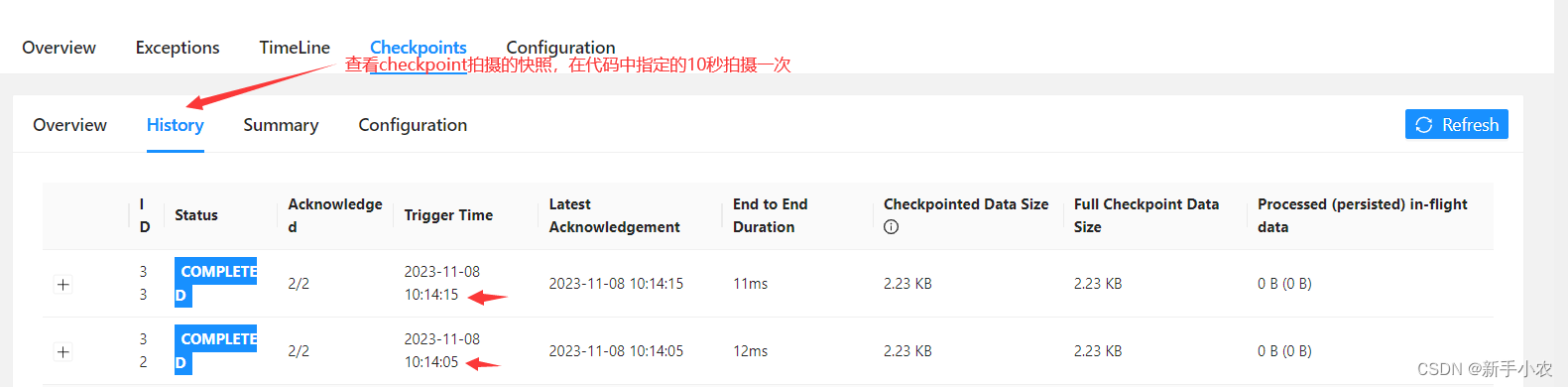
在hdfs中查看checkpoint文件:
hdfs dfs -ls /file/checkpoint/用可视化界面查看checkpoint的信息:
 3、提交任务
3、提交任务
例如: 使用yarn-session.sh -d 启动Flink集群:提交jar包,两种方式,第一种是通过网页的自动提交,第二种是通过session命令提交。
第一次提交任务:在使用命令行的模式提交jar包的时候需要注意的是:第一次提交任务的时候可以直接提交:例如:
使用session提交任务:flink run -t yarn-session -Dyarn.application.id=application_1698996244566_0009 -c flink.core.Demo1WordCount flink-1.0.jar当第一次提交后并失败,重启任务:当任务失败过后,并且开启了checkpoint,重启任务:
flink run -t yarn-session -Dyarn.application.id=application_1698996244566_0009 -s hdfs://master:9000/file/checkpoint/deed690403e740b734ea62fcd1963daf/chk-33 -c flink.core.Demo1WordCount flink-1.0.jar当选择在页面再次提交任务,需要指定最新的checkpoint的文件的位置:

需要注意的是当使用checkpoint做快照的时候,会在指定的时间拍一次快照,并生成一个新文件来覆盖前面旧的文件存储在hdfs上面。

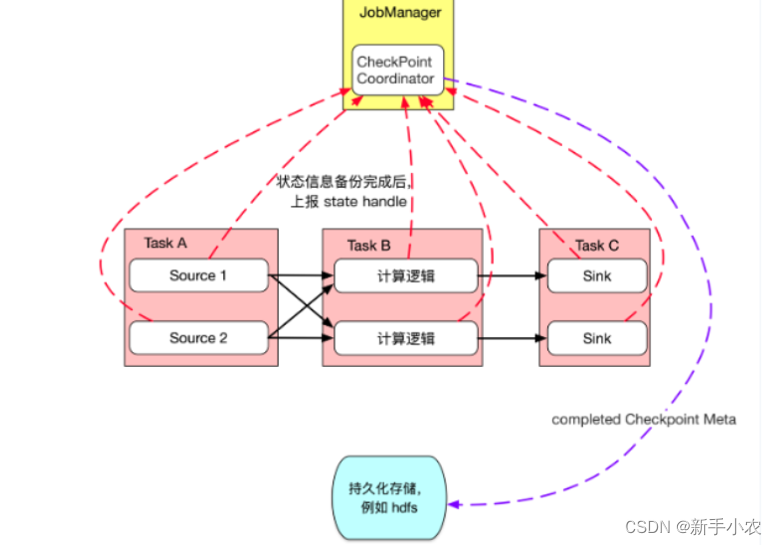
3、checkpoint的原理:
1、首先JobManager中的checkpoint Coonaotr checkpoint控制器会定期的向source task 发送checkpoint trigger
2、source task 就会在数据流中安插checkpoint barrier,就像一个挡板一样的
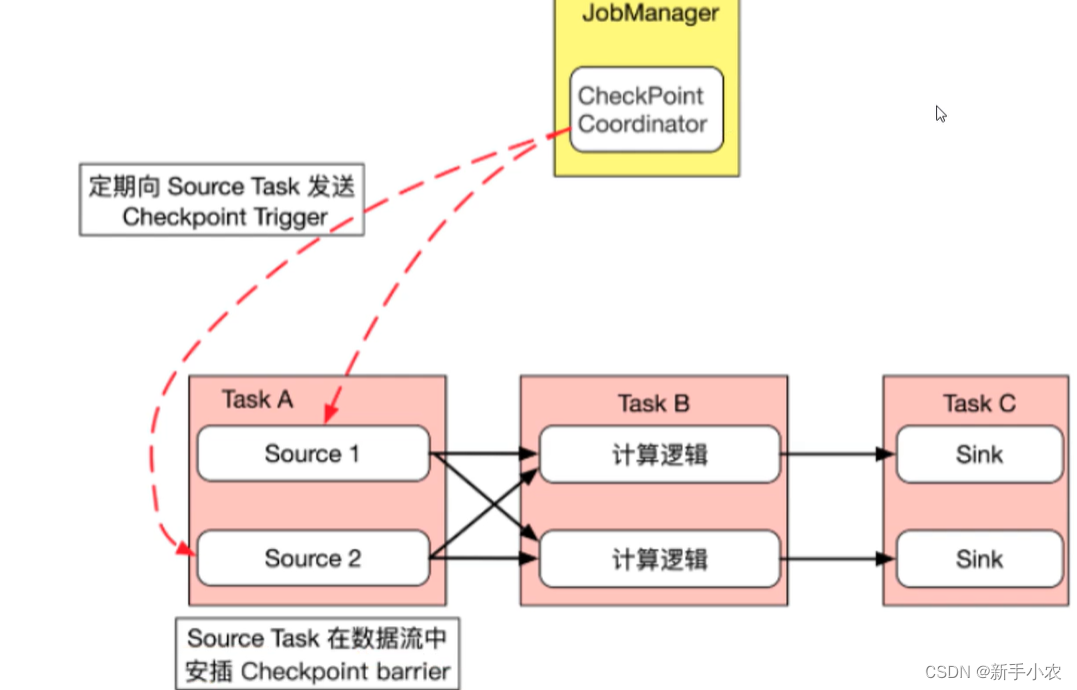
3、source task 向下游传递barrier,自生也会同步快照,并将状态持久化写入到hdfs中。
4、Task B接收到上游Task A所有实例发送的barrier 时,会继续向下游传递barrier,自身同步进行快照,并将状态持久化写入到hdfs中
5、Task C接收到上游Task B发送的 barrier时,自身同步进行快照,并将状态异步写持久化写入到hdfs中
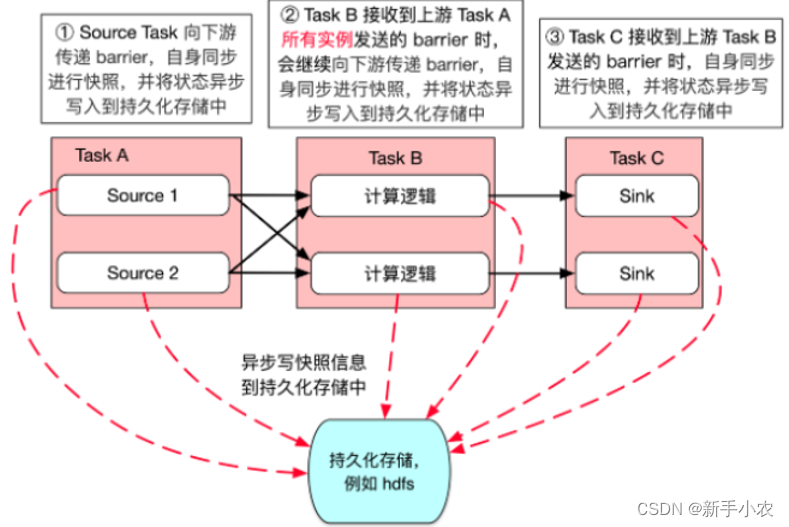
6、状态信息备份完成以后上报state handle
4、Keyed State
1、ValueState(单值状态):
保存一个可以更新和检索的值(例如每一个值都对应到当前的输入数据key,因此算子接收到的每一个key都有可能对应一个值),这个值可以通过updata进行更新,可以通过value进行检索。flink的ValueState状态,会对每一个key都保存一个值,并且可以更新,数据会被checkpoint定期的存储到hdfs中做持久化。
public class Demo02ValueState {public static void main(String[] args) throws Exception{StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);DataStream<String> wordsDS = env.socketTextStream("master", 8888);//安装单词分组KeyedStream<String, String> keyByDS = wordsDS.keyBy(word -> word);DataStream<Tuple2<String, Integer>> countDS = keyByDS.process(new KeyedProcessFunction<String, String, Tuple2<String, Integer>>() {//Flink中的单值状态valueState,对于Flink来说,如果使用的是HashMap来说,虽然对于不同的key是可以用来存储// 但是数据是存储在内存中,如果中途任务失败,那么任务重新启动的难度会比较大//flink的ValueState状态,会对每一个key都保存一个值,并且可以更新,数据会被checkpoint定期的存储到hdfs中做持久化。//需要重写open方法:是每一个task启动的时候会执行一次,用于对任务的初始化ValueState<Integer> state;@Overridepublic void open(Configuration parameters) throws Exception {//获取flink的执行上下文对象,使用上下文对象进行初始化RuntimeContext context = getRuntimeContext();//创建描述对象,描述状态的类型和名称:ValueStateDescriptor<Integer> count = new ValueStateDescriptor<>("count", Types.INT);//获取状态state = context.getState(count);}@Overridepublic void processElement(String word,KeyedProcessFunction<String, String, Tuple2<String, Integer>>.Context ctx,Collector<Tuple2<String, Integer>> out) throws Exception {//从中间获取单词的数量,返回值的类型是一个包装类,所以返回的值如果是空就会使用null表示Integer count = state.value();if(count==null){count=0;}count++;//将单词的数量返回出去state.update(count);//将结果返回到下游:out.collect(Tuple2.of(word,count));}});countDS.print();env.execute();}
}
2、ListState<T>:
保存一个元素的列表。可以往这个列表中追加数据,并在当前的列表上进行检索,可以通过add或者是addall进行添加元素,通过Iterable get ()获取整个列表,还可以通过update(list<T>)来覆盖当前的列表。
3、ReducingState<T>:
保存一个值,表示添加到状态的所有值的聚合。接口与ListState类似,但是使用add添加元素,时使用提供的ReduceFuncation进行聚合。
4、AggregatingState<IN,OUT>:
保留一个单值,表示添加到状态的所有值的集合。与ReducingState相反,聚合类可能与添加到状态的元素的类型不同,接口与ListState类似,但是使用add(IN)天机的元素会使用指定的AggregateFunction进行聚合
5、MapState<UK,UV>:
维护了一个映射列表,可以添加键值对到状态中,也可以获得反映当前所有映射的迭代器。使用put(UK,UV)或者是ptuALL(Map<UK,UV>)添加映射。 使用get(UK)检索特定的key。 使用 entries(),keys() 和 values() 分别检索映射、键和值的可迭代视图。你还可以通过 isEmpty() 来判断是否包含任何键值对。
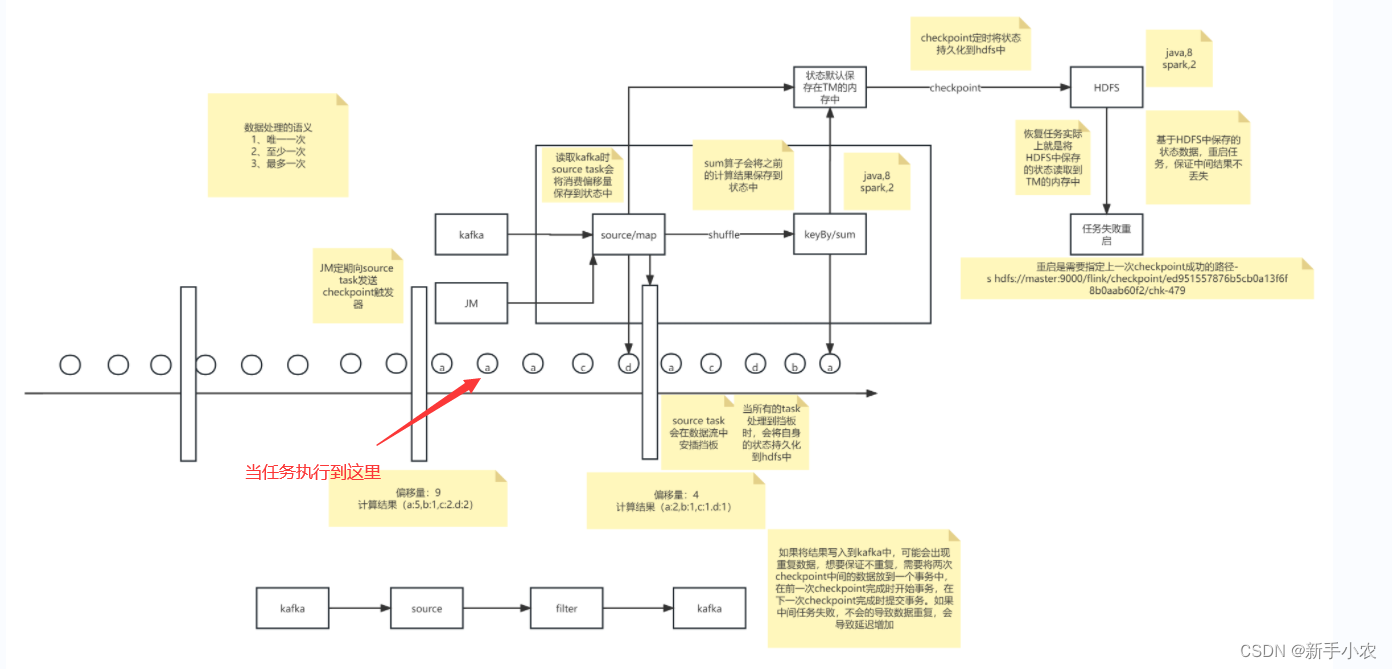
5、数据处理的语义:
1、主要分成三种:Exactly Once(唯一一次)、至少一次、最多一次
2、Exactly Once:指的是数据不多不少只会被处理一次
3、kafka唯一一次:
1、数据生产端唯一一次:
a、kafka 0.11之后,Producer的send操作现在是幂等的,保证了数据的不重复,在任何导致producer重试的情况下,相同的消息,如果被producer发送多次,也只会被写入Kafka一次。
b、ACKS机制+副本,保证数据不丢失
副本:保证存储到kafka副本中的数据不会丢失
ACKS机制:
acks机制:acks=1 (一般默认)第一个副本写入成功后就会返回成功,可能会丢失会丢失数据acks=0 生产者只负责写入数据,不负责验证数据是否成功,可能会丢失数据acks=-1/all 当所有的副本都同步成功之后才会返回成功kafka端保证数据的唯一一次:1、幂等性:保证数据不重复2、副本:保证成功存入的数据不丢失3、acks机制:当acks的结果是all的时候数据不丢失4、事务:保证数据不重复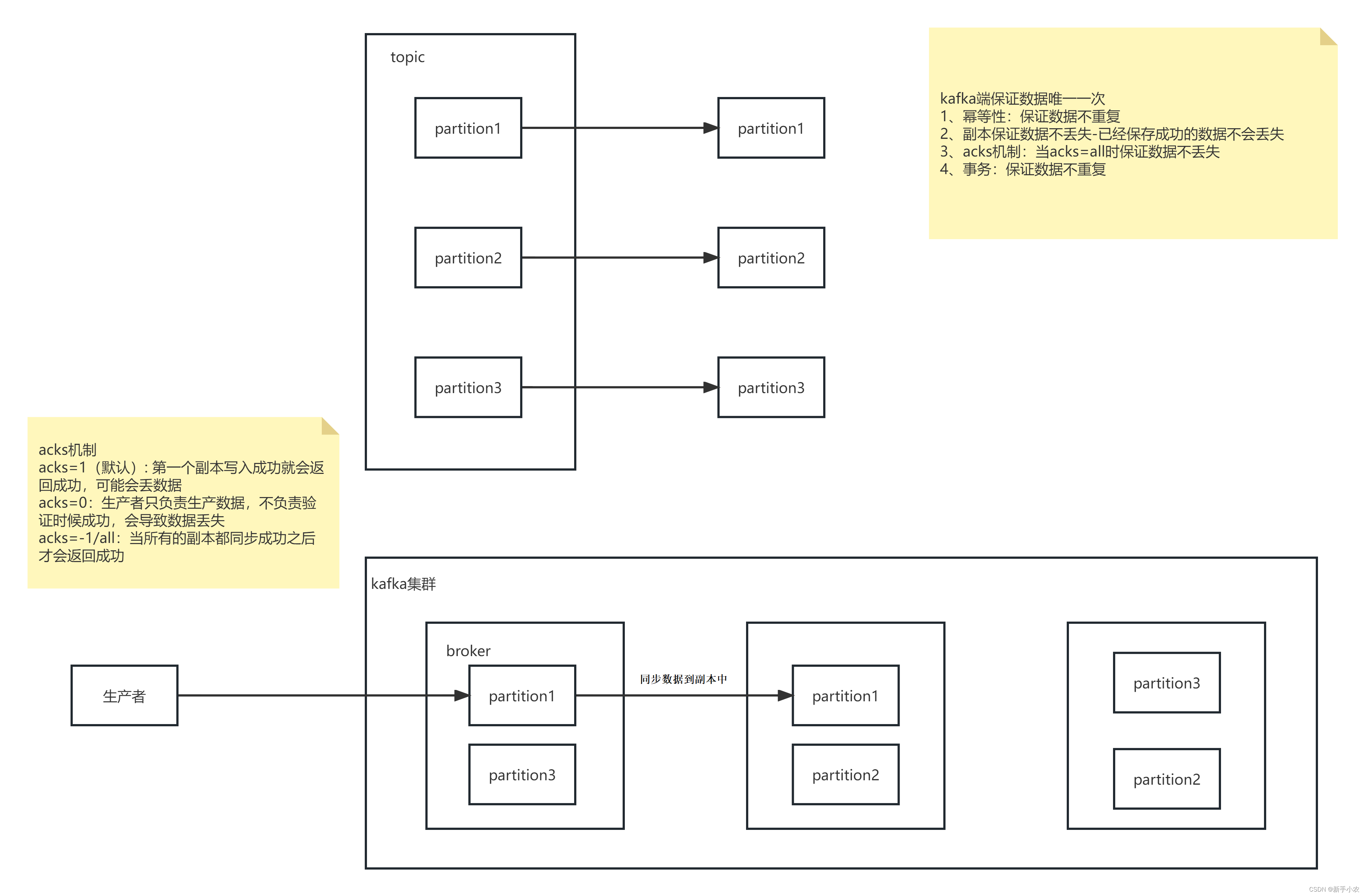

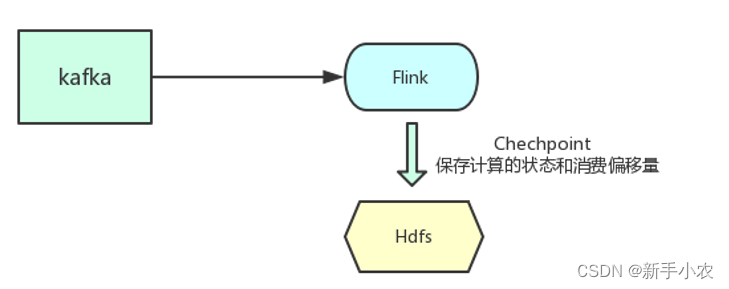
2、数据消费端:
a、Flink 分布式快照保存数据计算的状态和消费的偏移量,保证程序重启之后不丢失状态和消费偏移量
3、Sink端:
a、将Flink的结果数据再写入到kafka中
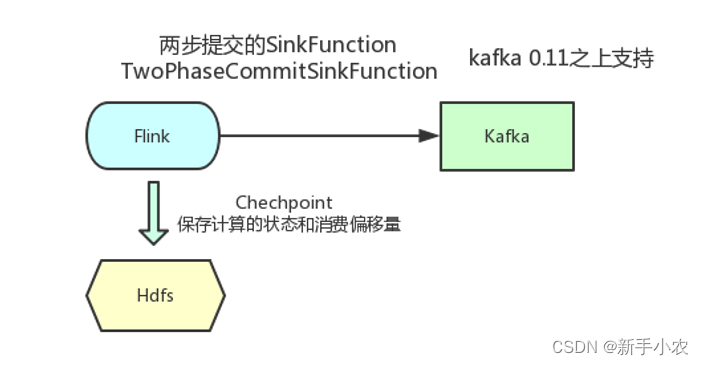

如果任务在执行过程中失败,恢复到原先的状态,此时在将结果写入到Kafka中,就有可能会有重复的数据,想要保证数据的不重复,就在两个checkpoint中间的数据存放一个事务中。当前一个事务开始,到后面的一个事务提交,一个事务才算提交完成,如果中间出现错误,此时任务就会失败,就不会导致数据重复,但是会产生延迟。
b、将数据写入kafka的唯一一次
public class Demo5KafkaExactlyOnce {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//构建kafka sourceKafkaSource<String> source = KafkaSource.<String>builder()//指定broker列表.setBootstrapServers("master:9092,node1:9092,node2:9092")//指定topic.setTopics("in")//消费者组.setGroupId("my-group")//指定读取数据的位置:earliest:读取最早的数据, latest: 读取最新的数据.setStartingOffsets(OffsetsInitializer.earliest())//读取数据的格式.setValueOnlyDeserializer(new SimpleStringSchema()).build();//使用 kafka sourceDataStreamSource<String> kafkaDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");//堆数据进行清洗过滤SingleOutputStreamOperator<String> filterDS = kafkaDS.filter(word -> !"java".equals(word));Properties properties = new Properties();//设置事务超时时间properties.setProperty("transaction.timeout.ms", String.valueOf(10 * 60 * 1000));//创建kafka sinkKafkaSink<String> sink = KafkaSink.<String>builder()//kafka broker列表.setBootstrapServers("master:9092,node1:9092,node2:9092")//指定而外的配置.setKafkaProducerConfig(properties)//指定数据的格式.setRecordSerializer(KafkaRecordSerializationSchema.builder()//指定topic,如果topic不存在会自动创建一个分区为1副本为1的topic.setTopic("out1")//指定数据格式.setValueSerializationSchema(new SimpleStringSchema()).build())//指定数据处理的语义//EXACTLY_ONCE:唯一一次,flink会将两次checkpoint中间的结果放到一个事务中,要么都成功要么都失败.setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE).build();filterDS.sinkTo(sink);env.execute();}
} #向kafka中生产新的数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic in#1、第一次直接提交
flink run -t yarn-per-job -c flink.state.Demo5KafkaExactlyOnce flink-1.0.jar#2、任务执行失败重启
flink run -t yarn-per-job -c flink.state.Demo2ExactlyOnce -s hdfs://master:9000/flink/checkpoint/3c1e5dcabcd934a6d93ab6af04f10ca9/chk-5 flink-1.0.jar#消费数据时需要设置只读已提交
# read_committed: 读已提交数据,
kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --isolation-level read_committed --from-beginning --topic out6、checkpoint的主要流程:
1、首先Flink在计算的过程中会产生有状态算子,首先会默认将状态算子存储到TaskManager内存中,如果数据源是来时Kafka,此时Kafksa中的source task会将偏移量也保存到状态中,一同存储到TaskManager内存中。
为什么会存储偏移量:任务失败重启过后,可以通过偏移量获取失败前任务读取数据的位置,再从这个位置开始读取数据。
2、然后在被checkpoint定时持久化到Hdfs中
3、当任务失败重启后,基于HDFS中的存储的数据,重启启动任务,会将HDFS中存储的状态读取到TaskManager内存中。
7、数据容错的过程,保证数据不丢失的:
对于上游的Task和下游的Task是同时做checkpoint还是在同一条数据做checkpoint?
Flink的流处理的过程中时Task是在同一条数据做checkpoint,例如图所示,
1、在使用kafka当作数据源的时候,source task 会在数据里中安插一个挡板
2、当上游的Task任务和下游的Task都到达第一个挡板的位置时都会做checkpoint,此时在内存中状态入图所示就是[偏移量:4 ,计算的结果是:a:2,b:1,c:1,d:1]
3、当任务在执行的过程中,任务失败,此时就会将状态恢复到第一次checkpoint的位置,再重新启动任务读取数据。
4、需要注意的是对于数据源,必须是可重复读取的数据源,假设任务指定到图中箭头位置失败,此时在会恢复到快照的位置,如果数据不能重复读,那么中间的数据就会丢失。
相关文章:
Flink -- 状态与容错
1、Stateful Operations 有状态算子: 有状态计算,使用到前面的数据,常见的有状态的算子:例如sum、reduce,因为它们在计算的时候都是用到了前面的计算的结果 总结来说,有状态计算并不是独立存在的…...
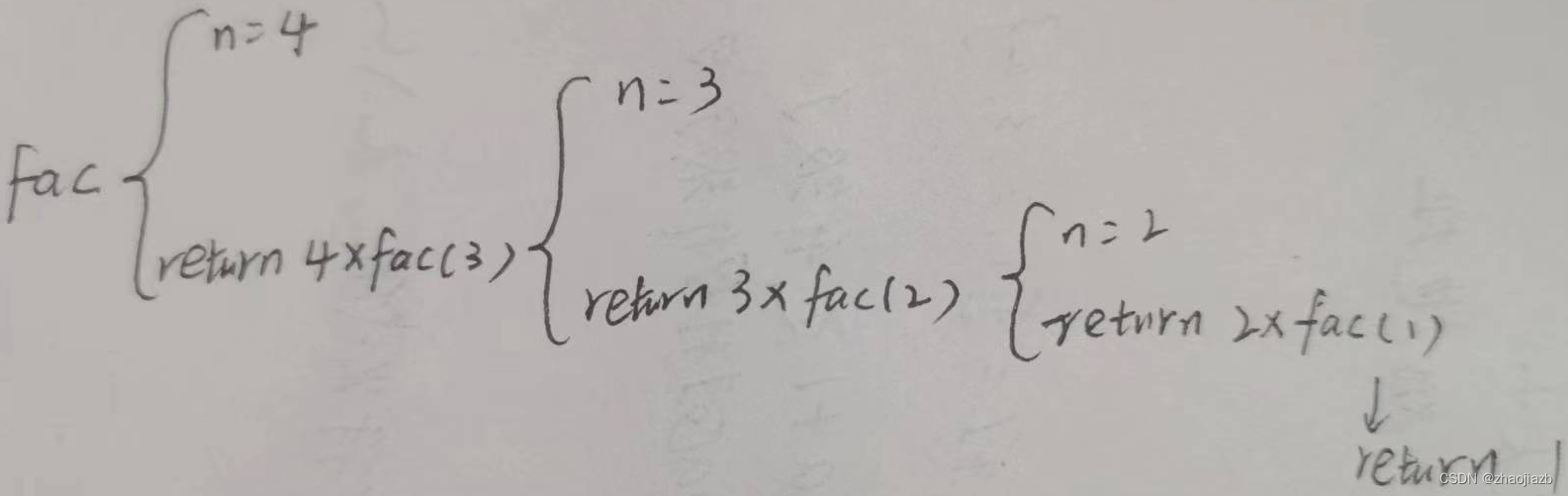
Linux C语言进阶-D15递归函数和函数指针
递归函数 指一个函数的函数体中直接或间接调用了该函数本身 执行过程分为两个过程: 递推过程:从原问题出发,按递归公式递推从未知到已知,最终达到递推终止条件 回归阶段:按递归终止条件求出结果,逆向逐步…...

LeetCode算法心得——全排列(回溯型排列)
大家好,我是晴天学长,排列型的回溯,需要的小伙伴可以关注支持一下哦!后续会继续更新的。💪💪💪 1) .全排列 给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按…...

读取W25Q64的设备ID时输出0xff
发现的问题 读取W25Q64的设备ID时输出0xff 找到的不同解决方法 检查MISO和MOSI是否接对。MISO->DO,MOSI->DI检查程序在初始化spi时是否将SS拉高、SCK拉低如果是硬件spi那么检查SPI的初始化函数中,时钟极性SPI_CPOL误选为SPI_CPOL_Low࿰…...
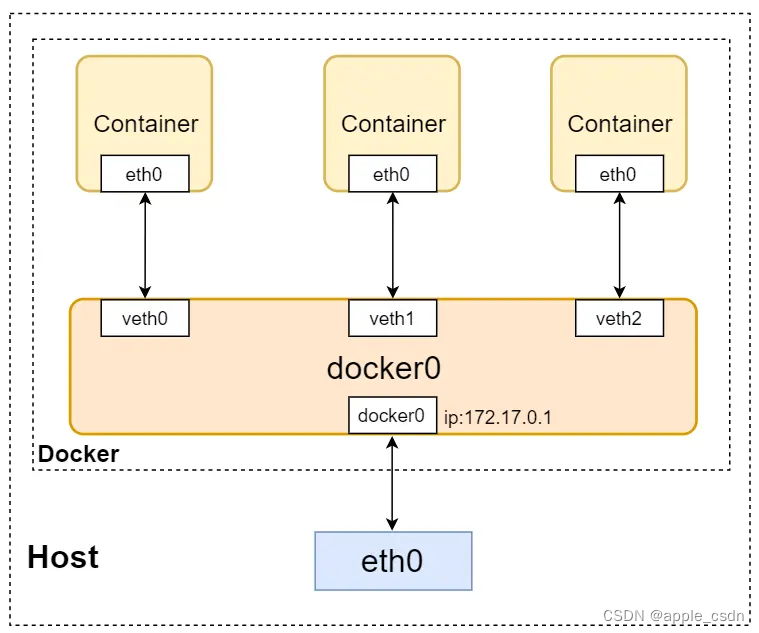
【Docker】Docker 网络
引言 Docker是一个开源的应用容器引擎,它允许开发者将应用及其依赖打包到一个可移植的容器中,然后发布到任何流行的Linux机器或Windows机器上,也可以实现虚拟化。Docker的主要优势之一是其网络功能,而网络功能的核心就是网络驱动…...

Flutter学习:使用CustomPaint绘制路径
Flutter学习:认识CustomPaint组件和Paint对象 Flutter学习:使用CustomPaint绘制路径 Flutter学习:使用CustomPaint绘制图形 Flutter学习:使用CustomPaint绘制文字 Flutter学习:使用CustomPaint绘制图片 drawPath 绘制路…...
软件模拟SPI协议的理解和使用编写W25Q64
SPI软件模拟的时序 SPI协议中,NSS、SCK、MOSI由主机产生,MISO由从机产生,在SCK每个时钟周期MOSI、MISO传输一位数据,数据的输入输出是同时进行的,所以读写数据也可以视作交换数据。所以读写时对数据位的控制都是用同一…...

SQLI手动注入和python sqlmap代码注入
sql教程: https://www.w3school.com.cn/sql/index.asp数据库: mysql oracle mssql常用方法 system_user() 系统用户名 user() 用户名 current_user() 当前用户名 session_user() 连接数据库的用户名 d…...
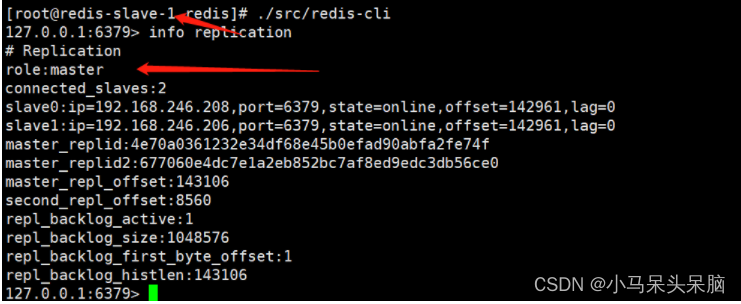
MemcachedRedis构建缓存服务器 (数据持久化,主从同步,哨兵模式)
Memcached/redis是高性能的分布式内存缓存服务器,通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web等应用的速度、 提高可扩展性。降低数据库读的压力 Nsql的优点:高可扩展性,分布式计算,低成本,…...
Python语法基础(变量 注释 数据类型 输入与输出 运算符 缩进)
目录 变量变量命名规则变量的类型变量的创建变量的作用域 注释的方法数据类型对象和引用的概念Number(数字)数据转换 输入与输出输入函数输出函数输出函数的end参数输出格式多行语句 运算符算术运算符赋值运算符三目运算符运算符的优先级 缩进缩进格式注意事项层级嵌套 变量 标…...
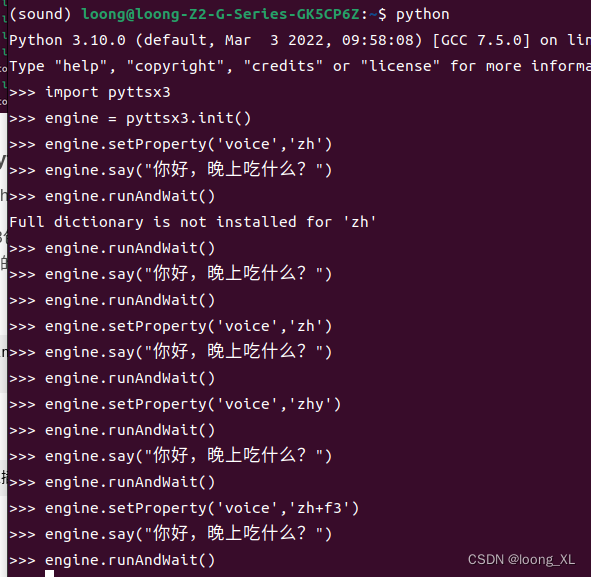
linux espeak语音tts;pyttsx3 ubuntu使用
整体使用espeak声音很机械不太自然 1、linux espeak语音tts 安装: sudo apt install espeak使用: #中文男声 espeak -v zh 你好 #中文女声 espeak -v zhf3 你好 #粤语男声 espeak -v zhy 你好注意:espeak -v zh 你好 (Full d…...

小白该如何学习Linux操作系统?
💂 个人网站:【工具大全】【游戏大全】【神级源码资源网】🤟 前端学习课程:👉【28个案例趣学前端】【400个JS面试题】💅 寻找学习交流、摸鱼划水的小伙伴,请点击【摸鱼学习交流群】 Linux作为一种开源操作系…...

2023双十一:实体门店闯入,第二战场全面开战
“闺女,吃饺子了吗?”11月8日,立冬,忙碌一天的陈曦回家路上接到母亲电话,才想起来家里冷冻水饺没了,又不想再去超市,直接打开美团买菜买了两袋,回家就煮了吃。当然,最终她…...
操作系统·处理机调度死锁
3.1 处理机调度概述 3.1.1 处理机调度概述 高级调度 (High level Scheduling)决定把外存上哪些作业调入内存、创建进程、分配资源。高级调度又称作业调度、长程调度或宏观调度。只在批处理系统中有高级调度。 中级调度 (Middle level Scheduling)完成进程的部分或全部在内、…...
SQL第四次上机实验
1.查询借阅了计算机类或者文学类图书的读者的借书证号 USE TSGL GO SELECT DISTINCT Reader.Lno FROM Book,Lend,Reader WHERE Book.ISBNLend.ISBN AND Lend.LnoReader.Lno AND Class 计算机类 OR Class 文学类2.查询同时借阅了计算机类和文学类图书的读者的借书证号 USE T…...

读书笔记:彼得·德鲁克《认识管理》第11章 若干例外及经验教训
一、章节内容概述 例外的服务机构不仅表明服务机构实现卓越绩效不是天方夜谭,而 且指明了实现的方法。这一课,是美国电话电报公司给“自然垄断行业”上的;是19世纪后期处于创建阶段的美国现代大学给学校或医院类机构上的;是20世纪30年代的田纳西河流域管…...

JVM-虚拟机的故障处理与调优案例分析
案例1:大内存硬件上的程序部署策略 一个15万PV/日左右的在线文档类型网站最近更换了硬件系统,服务器的硬件为四路志强处理器、16GB物理内存,操作系统为64位CentOS 5.4,Resin作为Web服务器。整个服务器暂时没有部署别的应用&#…...
JMeter 相关的面试题
📢专注于分享软件测试干货内容,欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!📢交流讨论:加入1000人软件测试技术学习交流群📢资源分享:进了字节跳动之后,才…...
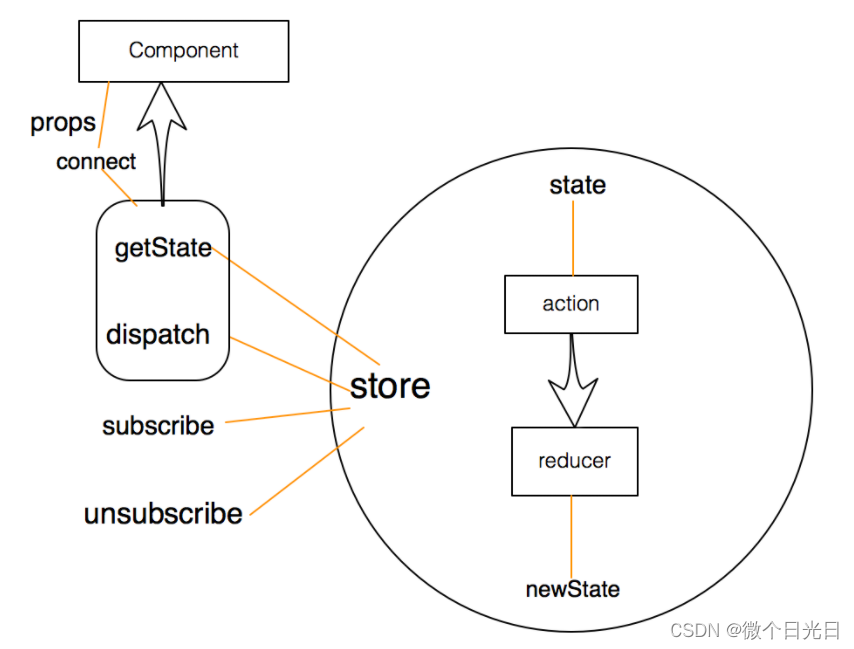
你在React项目中是如何使用Redux的? 项目结构是如何划分的?
一、背景 在前面文章了解中,我们了解到redux是用于数据状态管理,而react是一个视图层面的库 如果将两者连接在一起,可以使用官方推荐react-redux库,其具有高效且灵活的特性 react-redux将组件分成: 容器组件&#…...

[每周一更]-(第71期):DevOps 是什么?
Wiki的解释: DevOps(Development和Operations的混成词)是一种重视“软件开发人员(Dev)”和“IT运维技术人员(Ops)”之间沟通合作的文化、运动或惯例。 通过自动化“软件交付”和“架构变更”的…...

从D3 0_到MSM:RTCM3.2协议帧结构深度解析与实战解码
1. RTCM3.2协议入门:从"D3 0_"开始的导航数据之旅 第一次看到RTCM3.2数据流时,那串以"D3 0_"开头的十六进制代码让我完全摸不着头脑。就像面对一本用外星语言写成的密码本,每个字节都像是在嘲笑我的无知。但当我真正理解…...

魔兽争霸3终极优化指南:5分钟让经典游戏在现代电脑上完美运行
魔兽争霸3终极优化指南:5分钟让经典游戏在现代电脑上完美运行 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代电脑上…...

从一次vSAN报警深入:图解vSAN对象状态机,帮你彻底看懂‘正常’、‘降级’与‘不可访问’
深入解析vSAN对象状态机:从报警诊断到运维实战 那天凌晨三点,值班手机突然响起刺耳的警报声。监控系统显示某金融客户的核心交易集群出现"未知对象类型不可访问"的vSAN报警。作为经历过多次vSAN故障的老兵,我深知这种报警背后可能隐…...

机房摸鱼指南:手把手教你用C++卸载LibTDProcHook64.dll,绕过极域64位进程保护
深入解析极域64位系统下的进程保护机制与应对策略 在计算机教室或培训机构的日常使用中,极域电子教室软件作为教学管理工具被广泛采用。这款软件的设计初衷是为了方便教师统一控制学生机,实现屏幕广播、文件分发和远程协助等功能。然而,当学生…...
)
AD9361 LVDS接口时序详解:手把手教你搞定FPGA与射频收发器的数据对齐(附时序图分析)
AD9361 LVDS接口时序深度解析:从理论到实战的FPGA数据对齐指南 当射频工程师第一次将AD9361与FPGA平台对接时,往往会被LVDS接口的时序问题困扰——明明SPI配置正确,示波器上的差分信号也看似完美,但FPGA接收到的数据却总是出现错位…...

用ILA抓波形:手把手调试XC7K325T的XDMA PCIe AXI总线读写时序
用ILA抓波形:手把手调试XC7K325T的XDMA PCIe AXI总线读写时序 在FPGA开发中,PCIe接口与AXI总线的交互调试往往是项目成败的关键节点。当XDMA IP核与AXI总线握手出现问题时,传统的软件调试手段往往力不从心,这时就需要搬出硬件调试…...

Windows系统下Java环境管理指南:如何让BurpSuite 2022.8.2与旧版Java项目和平共处?
Windows系统下Java多版本共存实战:BurpSuite 2022与老旧工具兼容指南 你是否遇到过这样的场景:刚装好BurpSuite 2022.8.2准备测试,突然发现手头的AWVS旧版扫描器无法启动了?或者SQLMap的图形化界面报错提示Java版本不兼容…...

2026 AI安全左移再进化:从IDE插件到CI门禁,悬镜灵境AIDR的全流程集成实践
摘要“安全左移”已提出多年,但在AI智能体开发场景下面临全新挑战。智能体的“源码”不仅包括代码,还包括提示词、模型依赖和工具定义。传统SAST/DAST无法理解这些新型资产。本文基于悬镜灵境AIDR在IDE插件、CI流水线、运行时护栏三个环节的集成实践&…...

C#怎么实现图片缩略图生成 C#如何批量生成图片的缩略图指定尺寸保持比例不变形【图像】
最可靠缩略图生成法是手动用Graphics.DrawImage:先等比计算尺寸并居中,再创建Bitmap画布,设置高质量插值后绘制;加载时用File.ReadAllBytesMemoryStream避免文件锁;保存时显式指定JPEG编码器及质量参数;所有…...

零成本构建移动服务器:基于Termux的安卓Web服务实战
1. 为什么选择安卓手机搭建Web服务器? 最近几年,我发现身边不少开发者朋友都在寻找低成本的服务器解决方案。作为一个常年折腾各种技术的"老司机",我强烈推荐大家试试用闲置安卓手机搭建Web服务器。你可能要问:手机也能…...