Stream流的groupingBy
Stream流的groupingBy
简单使用
业务场景:现在有100个人,这些人都年龄分部在18-30岁之间。现要求把他们按照年龄进行分组
key:年龄
value:数据列表
public void listToMapGroup() {//这里假设通过listStreamService.list();方法查询了这100人List<Perple> list = perpleService.list();//按照age进行分组Map<Integer, List<Perple>> result = list.stream().collect(Collectors.groupingBy(Perple::getAge));//打印结果result.forEach((k, v) -> {System.out.println(k);System.out.println(v);System.out.println("--------------------");});
}
效果相当于是,把list这个集合里面存放的100个人每个人都调用Perple的getAge方法,按照getAge方法的返回值进行分组。每个组是一个Map<Integer, List>类型的对象。Map<Integer, List>的键是getAge的返回值,即,分组的依据。Map<Integer, List>的值是这个年龄对应组中的成员。
如果要进行排序
分组之后,是不能对每个分组进行比较的(也就无法排序),因为groupingBy是一个终结流。
Collectors.groupingBy(Function<? super T, ? extends K> classifier, Collector<? super T, A, D> downstream)
这里有两个思路:
1:提前排序,再进行分组
2:分组后,对Map进行处理,对其每个value排序
做法一:
提前排序,再进行分组.
这里还展示了一些groupingBy方法的扩展用法。
import com.alibaba.fastjson.JSONObject;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;public class Test {public static void main(String[] args) {Student student1 = new Student(1, 1);Student student2 = new Student(1, 1);Student student3 = new Student(2, 2);Student student4 = new Student(2, 3);Student student5 = new Student(3, 3);Student student6 = new Student(3, 4);Student student7 = new Student(4, 1);Student student8 = new Student(4, 1);Student student9 = new Student(4, 2);Student student10 = new Student(4, 1);List<Student> list = Arrays.asList(student1, student2, student3, student4, student5, student6, student7, student8, student9, student10);System.out.println("--------- 根据字段分组,求每个分组的sum ----------");Map<Integer, Integer> collect = list.stream().collect(Collectors.groupingBy(Student::getId, Collectors.summingInt(Student::getScore)));System.out.println(collect.toString());System.out.println("--------- 根据字段分组,求每个分组的count ----------");Map<Integer, Long> countMap = list.stream().collect(Collectors.groupingBy(Student::getId, Collectors.counting()));System.out.println(countMap.toString());System.out.println("--------- 根据字段分组,每个分组为:对象的指定字段 ----------");Map<Integer, List<Integer>> groupMap = list.stream().collect(Collectors.groupingBy(Student::getId, Collectors.mapping(Student::getScore, Collectors.toCollection(ArrayList::new))));System.out.println(groupMap.toString());System.out.println("--------- 根据字段分组,默认分组 ----------");Map<Integer, List<Student>> defaultGroupMap = list.stream().collect(Collectors.groupingBy(Student::getId));System.out.println(JSONObject.toJSONString(defaultGroupMap));System.out.println("--------- 根据字段分组,每个分组按照指定字段进行生序排序 ----------");Map<Integer, List<Student>> sortGroupMap = list.stream().sorted(Comparator.comparing(Student::getScore)).collect(Collectors.groupingBy(Student::getId));System.out.println(JSONObject.toJSONString(sortGroupMap));System.out.println("--------- 先排序,再分组 ----------");Map<Integer, List<Student>> reversedSortGroupMap = list.stream().sorted(Comparator.comparing(Student::getScore).reversed()).collect(Collectors.groupingBy(Student::getId));System.out.println(JSONObject.toJSONString(reversedSortGroupMap));}
}class Student {private Integer id;private Integer score;public Integer getId() {return id;}public void setId(Integer id) {this.id = id;}public Integer getScore() {return score;}public void setScore(Integer score) {this.score = score;}public Student(Integer id, Integer score) {this.id = id;this.score = score;}
}执行结果:
--------- 根据字段分组,求每个分组的sum ----------
{1=2, 2=5, 3=7, 4=5}
--------- 根据字段分组,求每个分组的count ----------
{1=2, 2=2, 3=2, 4=4}
--------- 根据字段分组,每个分组为:对象的指定字段 ----------
{1=[1, 1], 2=[2, 3], 3=[3, 4], 4=[1, 1, 2, 1]}
--------- 根据字段分组,默认分组 ----------
{1:[{"id":1,"score":1},{"id":1,"score":1}],2:[{"id":2,"score":2},{"id":2,"score":3}],3:[{"id":3,"score":3},{"id":3,"score":4}],4:[{"id":4,"score":1},{"id":4,"score":1},{"id":4,"score":2},{"id":4,"score":1}]}
--------- 根据字段分组,每个分组按照指定字段进行生序排序 ----------
{1:[{"id":1,"score":1},{"id":1,"score":1}],2:[{"id":2,"score":2},{"id":2,"score":3}],3:[{"id":3,"score":3},{"id":3,"score":4}],4:[{"id":4,"score":1},{"id":4,"score":1},{"id":4,"score":1},{"id":4,"score":2}]}
--------- 先排序,再分组 ----------
{1:[{"id":1,"score":1},{"id":1,"score":1}],2:[{"id":2,"score":3},{"id":2,"score":2}],3:[{"id":3,"score":4},{"id":3,"score":3}],4:[{"id":4,"score":2},{"id":4,"score":1},{"id":4,"score":1},{"id":4,"score":1}]}做法二:
先分组,再排序。
先将数据进行groupingBy,得到Map<Long, List>
在通过forEach对每个List进行排序
Map<Long, List<StreamMapEntity>> map = getMap();System.out.println("------ flatMap 处理Map<Long,List<StreamMapEntity>> ------");System.out.println();System.out.println("初始数据:" + JSONObject.toJSONString(map));System.out.println();map.keySet().forEach(key -> map.computeIfPresent(key, (k, v) -> v.stream().sorted(Comparator.comparing(StreamMapEntity::getId).reversed()).collect(Collectors.toList())));System.out.println("处理map:对map内的每个list进行排序:");System.out.println(JSONObject.toJSONString(map));执行结果:
------ flatMap 处理Map<Long,List<StreamMapEntity>> ------初始数据:{1111:[{"id":1,"name":"aa"},{"id":2,"name":"bb"},{"id":3,"name":"cc"},{"id":4,"name":"dd"}],2222:[{"id":5,"name":"ee"},{"id":6,"name":"ff"},{"id":7,"name":"gg"},{"id":8,"name":"hh"}]}处理map:对map内的每个list进行排序:
{1111:[{"id":4,"name":"dd"},{"id":3,"name":"cc"},{"id":2,"name":"bb"},{"id":1,"name":"aa"}],2222:[{"id":8,"name":"hh"},{"id":7,"name":"gg"},{"id":6,"name":"ff"},{"id":5,"name":"ee"}]}相关文章:

Stream流的groupingBy
Stream流的groupingBy 简单使用 业务场景:现在有100个人,这些人都年龄分部在18-30岁之间。现要求把他们按照年龄进行分组 key:年龄 value:数据列表 public void listToMapGroup() {//这里假设通过listStreamService.list();方法…...

如何在不结束tcpdump的情况下复制完整的pcap
tcpdump正在运行的时候,他写入的pcap可能是不完整的,通常我们要结束掉tcpdump才能拿到完整的pcap,否则wireshark打开的时候会提示:The capture file appears to have been cut short in the middle of a packet。这可能是因为tcpd…...

maven POM文件总体配置说明
<project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd "> <!-- 父项目的坐…...
)
49.批处理命令(1/2)
目录 一批处理。 (1)批处理定义。 (2)常见命令。 (2.1)rem和:: (2.2)echo和。 (2.3)pause。 (2.4)errorlevel。 (…...
react类式组件的生命周期和useEffect实现函数组件生命周期
概念 生命周期是一个组件丛创建,渲染,更新,卸载的过程,无论是vue还是react都具有这个设计概念,也是开发者必须熟练运用的,特别是业务开发,不同的生命周期做不同的事是很重要的. ....多说两句心得,本人是先接触vue的,无论是vue2还是vue3的生命周期,在理解和学习上都会比react更…...
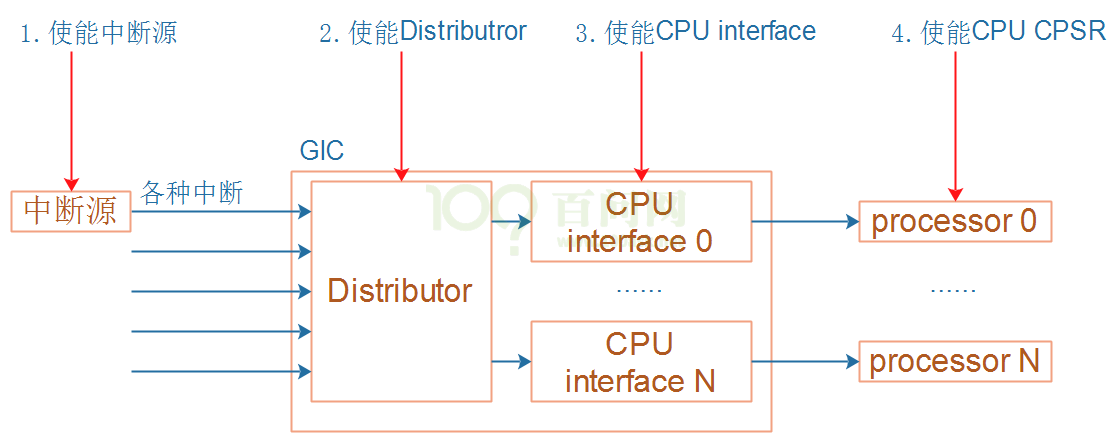
ARM 基础学习记录 / 异常与GIC介绍
GIC概念 念课本(以下内容都是针对"通用中断控制器(GIC)"而言,直接摘录的,有的地方可能不符人类的理解方式): 通用中断控制器(GIC)架构提供了严格的规范&…...

java压缩pdf体积,图片体积
pdf整体进行压缩,图片进行压缩 // 生成主证书的PDF路径 创建一个文件String pdfPath UploadDown.createFile(".pdf");outputStream new FileOutputStream(pdfPath);bufferedOutputStream new BufferedOutputStream(outputStream);writer PdfWriter.getInstance(…...
 安装最新版本的 GCC)
Ubuntu(WSL2) 安装最新版本的 GCC
要在 Ubuntu 上安装最新版本的 GCC,可以通过以下步骤进行操作: 1. 打开终端(Terminal) 2. 更新软件包列表,确保系统使用最新的软件包信息,运行以下命令: sudo apt update 3. 安装 GCC 软件包…...
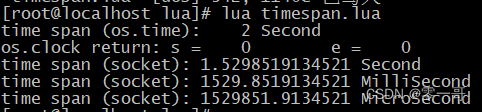
lua 时间差功能概略
简介 在进行程序设计过程中,经常需要对某些函数、某些程序片断从开始运行到运行结束所耗费的时间进行一些量化。这种量化实际上就是计算时间差。 获取函数耗时情景如下: function time_used() --开始计时-- do something at here. --结束计时--时间差&…...

【C++11】左值引用,右值引用,移动/复制构造,完美转发
左值与右值 字面意思是可以放在等号左边的就是左值,只能放在等号右边的就是右值(为何是“可以”“只能”?例如i是左值,但他依然可以放在等号右边)。 严格上的定义:可以取地址的就是左值,反之为…...
解决找不到x3daudio1_7.dll的方法,快速解决x3daudio1_7.dll丢失问题
在计算机使用过程中,我们经常会遇到一些错误提示,其中之一就是“找不到x3daudio1_7.dll”。这个问题可能是由于多种原因引起的,例如文件丢失、损坏或被病毒感染等。下面将详细介绍如何解决这个问题。 首先,我们需要了解x3daudio1_…...
)
LeetCode:2300. 咒语和药水的成功对数(C++)
目录 2300. 咒语和药水的成功对数 题目描述: 实现代码与解析: 二分 原理思路: 2300. 咒语和药水的成功对数 题目描述: 给你两个正整数数组 spells 和 potions ,长度分别为 n 和 m ,其中 spells[i] 表…...

【Spring生命周期核心底层源码之剖析】
文章目录 一、Spring生命周期核心底层源码剖析—扫描1.1、Spring底层扫描机制doScan方法源码剖析 一、Spring生命周期核心底层源码剖析—扫描 1.1、Spring底层扫描机制doScan方法源码剖析 其源代码如下: protected Set<BeanDefinitionHolder> doScan(Strin…...

关于Thread.sleep方法的一些使用
Thread.sleep方法的作用就是使当前线程暂停执行一段指定的时间。 它的参数是以ms为单位的时间参数,表示暂停时间长度。如Thread.sleep(1000);表示暂停1s。 这个方法通常用在以下一些情况: 1、模拟延迟:在某些情况下,我们希望在…...

MeterSphere | 前端入参加密
项目场景: 在 MeterSphere 开源框架中,解决前端手机号入参加密 解决方案: 导入 JavaScript 包采用加密算法 导入网上 JavaScript 包 // 1. 通过cdn加载网上的js文件 g new Packages.org.mozilla.javascript.tools.shell.Global(Packages.o…...

微服务如何做负载均衡?
笔者在参与联通某子公司时,遇到了这样一个问题。感觉比较实际,特来记录一波。 先看腾讯混元的解答: 微服务架构中,负载均衡是必不可少的。在微服务中,负载均衡可以通过以下几种方式来实现: 1. DNS轮询&am…...

C++高级编程:构建高效稳定接口与深入对象设计技巧
C高级编程:构建高效稳定接口与深入对象设计技巧 建立稳定接口 类是C中的主要抽象单位。你应该将抽象原则应用于你的类,尽可能将接口与实现分离。具体来说,你应该使所有数据成员私有,并可选择性地提供getter和setter方法。这就是…...
Qt——连接mysql增删查改(仓库管理极简版)
目录 UI布局设计 .pro文件 mainwindow.h main.cpp UI布局设计 .pro文件 QT core gui QT core gui sql QT sqlgreaterThan(QT_MAJOR_VERSION, 4): QT widgetsCONFIG c11# The following define makes your compiler emit warnings if you use # any …...

Panda3d 场景管理
Panda3d 场景管理 文章目录 Panda3d 场景管理有关分层场景图的重要信息NodePathNodePath 以及 Node 的函数调用模型文件文件格式加载模型文件将模型放置在场景图中模型缓存压缩模型异步加载模型通过回调函数进行 常见的状态变化修改节点的位置和姿态改变父级节点改变颜色隐藏和…...

京东数据分析(京东销量):2023年9月京东投影机行业品牌销售排行榜
鲸参谋监测的京东平台9月份投影机市场销售数据已出炉! 根据鲸参谋电商数据分析平台的相关数据数据显示,9月份,京东平台投影机的销量为13万,环比下滑约17%,同比下滑约25%;销售额将近2.6亿,环比下…...

Redis 缓存穿透、击穿、雪崩解决方案
在互联网高并发场景下,Redis 作为缓存层已经成为系统性能的核心命脉。然而,当缓存层遭遇异常情况时,原本作为“盾牌”的缓存可能瞬间变成系统崩溃的导火索。在业界,有三个经典的缓存问题被称为“三大杀手”——缓存穿透、缓存击穿…...

PEG-HA-COOH-Fe₃O₄ NPs,聚乙二醇-透明质酸-羧基修饰四氧化三铁纳米颗粒,化学结构特点
PEG-HA-COOH-Fe₃O₄ NPs,聚乙二醇-透明质酸-羧基修饰四氧化三铁纳米颗粒,化学结构特点PEG-HA-COOH-Fe₃O₄ NPs是一类以四氧化三铁(Fe₃O₄)纳米颗粒为无机核心,在其表面依次构建透明质酸(Hyaluronic acid…...

如何实现跨设备音频共享?Scream虚拟声卡网络传输终极指南
如何实现跨设备音频共享?Scream虚拟声卡网络传输终极指南 【免费下载链接】scream Virtual network sound card for Microsoft Windows 项目地址: https://gitcode.com/gh_mirrors/sc/scream 你是否曾想过将电脑音频无线传输到其他设备播放?无论是…...
|类与对象基础(封装、构造 / 析构函数,面试必考))
C++ 从 0 入门(三)|类与对象基础(封装、构造 / 析构函数,面试必考)
大家好,我是网域小星球。 本篇是 C 面向对象的核心开篇,也是 C 面试重中之重 —— 类与对象基础。面试官几乎都会问封装、构造函数、析构函数的用法,甚至让手撕代码。本篇全程聚焦面试考点,不冗余、只讲核心,代码 VS2…...

RabbitMQ实战:插件扩展机制全解析——常用插件、安装启用、管理、生产推荐
RabbitMQ实战:插件扩展机制全解析——常用插件、安装启用、管理、生产推荐一、前言二、基础认知:RabbitMQ插件机制是什么2.1 插件定义2.2 插件核心特点2.3 插件扩展流程图三、RabbitMQ插件:安装、启用、禁用、管理全流程3.1 插件核心目录3.2 …...

vivo X300 Ultra长焦套件集市游玩体验佳,小巧轻便成家庭出游必备!
vivo X300 Ultra长焦套件体验:集市游玩拍出惊喜,小巧轻便再游必备!原本我以为 vivo X300 系列只是个博眼球、难促销售的噱头概念。然而,带着这部手机和精心设计、造型奇特的小镜头套件度过一个周末后,我玩得十分尽兴。…...

Spug开源运维平台终极完整安装配置指南:高效实现企业级自动化运维
Spug开源运维平台终极完整安装配置指南:高效实现企业级自动化运维 【免费下载链接】spug 开源运维平台:面向中小型企业设计的轻量级无Agent的自动化运维平台,整合了主机管理、主机批量执行、主机在线终端、文件在线上传下载、应用发布部署、在…...

PyQt5入门实战:安装、QtDesigner设计与PyUIC转换完整指南
PyQt5 入门实战:安装、QtDesigner 设计与 PyUIC 转换完整指南环境说明:Python 3.9 PyQt5 5.15.4 PyCharm(Community/Professional 均适用)一、什么是 PyQt5? PyQt5 是 Qt5 框架的 Python 绑定,由 Riverba…...

如何在3分钟内免费获得Apex Legends终极压枪助手
如何在3分钟内免费获得Apex Legends终极压枪助手 【免费下载链接】Apex-NoRecoil-2021 Scripts to reduce recoil for Apex Legends. (auto weapon detection, support multiple resolutions) 项目地址: https://gitcode.com/gh_mirrors/ap/Apex-NoRecoil-2021 还在为Ap…...

终极跨平台漫画阅读器:nhentai-cross完全指南,5分钟解锁全设备同步阅读体验
终极跨平台漫画阅读器:nhentai-cross完全指南,5分钟解锁全设备同步阅读体验 【免费下载链接】nhentai-cross A nhentai client 项目地址: https://gitcode.com/gh_mirrors/nh/nhentai-cross 还在为在不同设备间切换阅读漫画而烦恼吗?…...