SpringBoot整合(五)HikariCP、Druid数据库连接池—多数据源配置
在项目中,数据库连接池基本是必不可少的组件。在目前数据库连接池的选型中,主要是
- Druid ,为监控而生的数据库连接池。
- HikariCP ,号称性能最好的数据库连接池。
在Spring Boot 2.X 版本,默认采用 HikariCP 连接池。而阿里大规模采用 Druid 。下面介绍在SpringBoot中使用HikariCP、Druid连接池。
1、HikariCP数据库连接池
1.1 HikariCP单数据源配置
1.1.1 pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.1.3.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><modelVersion>4.0.0</modelVersion><artifactId>HikariCP-Boot</artifactId><dependencies><!-- 实现对数据库连接池的自动化配置 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.48</version></dependency><!-- 写单元测试 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies></project>
- 无需主动引入 HikariCP 的依赖。因为在 Spring Boot 2.X 中,
spring-boot-starter-jdbc默认引入com.zaxxer.HikariCP依赖。
1.1.2 yml配置
server:port: 7890spring:# datasource 数据源配置内容,对应 DataSourceProperties 配置属性类datasource:url: jdbc:mysql://127.0.0.1:3306/test?useSSL=false&useUnicode=true&characterEncoding=UTF-8driver-class-name: com.mysql.jdbc.Driverusername: root # 数据库账号password: root # 数据库密码# HikariCP 自定义配置,对应 HikariConfig 配置属性类hikari:minimum-idle: 10 # 池中维护的最小空闲连接数,默认为 10 个。maximum-pool-size: 10 # 池中最大连接数,包括闲置和使用中的连接,默认为 10 个。
- 在
spring.datasource配置项下,我们可以添加数据源的通用配置。 - 在
spring.datasource.hikari配置项下,我们可以添加 HikariCP 连接池的自定义配置。然后DataSourceConfiguration.Hikari会自动化配置 HikariCP 连接池。
1.1.3 主启动类
package com.yyds;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;@SpringBootApplication
public class ApplicationBak implements CommandLineRunner {private Logger logger = LoggerFactory.getLogger(ApplicationBak.class);@Autowiredprivate DataSource dataSource;public static void main(String[] args) {// 启动 Spring Boot 应用SpringApplication.run(ApplicationBak.class, args);}@Overridepublic void run(String... args) {try (Connection conn = dataSource.getConnection()) {// 这里,可以做点什么logger.info("[run][获得连接:{}]", conn);} catch (SQLException e) {throw new RuntimeException(e);}}}
通过实现 CommandLineRunner接口,应用启动完成后,回调 #run(String... args) 方法,输出 Connection 信息。
1.2 HikariCP多数据源配置
1.2.1 pom文件
如1.2.1所示。
1.2.2 yml配置
spring:# datasource 数据源配置内容datasource:# 订单数据源配置orders:url: jdbc:mysql://127.0.0.1:3306/test_orders?useSSL=false&useUnicode=true&characterEncoding=UTF-8driver-class-name: com.mysql.jdbc.Driverusername: rootpassword: root# HikariCP 自定义配置,对应 HikariConfig 配置属性类hikari:minimum-idle: 20 # 池中维护的最小空闲连接数,默认为 10 个。maximum-pool-size: 20 # 池中最大连接数,包括闲置和使用中的连接,默认为 10 个。# 用户数据源配置users:url: jdbc:mysql://127.0.0.1:3306/test_users?useSSL=false&useUnicode=true&characterEncoding=UTF-8driver-class-name: com.mysql.jdbc.Driverusername: rootpassword: root# HikariCP 自定义配置,对应 HikariConfig 配置属性类hikari:minimum-idle: 15 # 池中维护的最小空闲连接数,默认为 10 个。maximum-pool-size: 15 # 池中最大连接数,包括闲置和使用中的连接,默认为 10 个。
1.2.3 主启动类
package com.yyds;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;import javax.annotation.Resource;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;@SpringBootApplication
public class Application implements CommandLineRunner {private Logger logger = LoggerFactory.getLogger(Application.class);@Resource(name = "ordersDataSource")private DataSource ordersDataSource;@Resource(name = "usersDataSource")private DataSource usersDataSource;public static void main(String[] args) {// 启动 Spring Boot 应用SpringApplication.run(Application.class, args);}@Overridepublic void run(String... args) {// orders 数据源try (Connection conn = ordersDataSource.getConnection()) {// 这里,可以做点什么logger.info("[run][ordersDataSource 获得连接:{}]", conn);} catch (SQLException e) {throw new RuntimeException(e);}// users 数据源try (Connection conn = usersDataSource.getConnection()) {// 这里,可以做点什么logger.info("[run][usersDataSource 获得连接:{}]", conn);} catch (SQLException e) {throw new RuntimeException(e);}}}1.2.4 配置类
package com.yyds.config;import com.zaxxer.hikari.HikariDataSource;
import org.springframework.boot.autoconfigure.jdbc.DataSourceProperties;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.util.StringUtils;import javax.sql.DataSource;@Configuration
public class DataSourceConfig {/*** 创建 orders 数据源的配置对象*/@Primary@Bean(name = "ordersDataSourceProperties")@ConfigurationProperties(prefix = "spring.datasource.orders") // 读取 spring.datasource.orders 配置到 DataSourceProperties 对象public DataSourceProperties ordersDataSourceProperties() {return new DataSourceProperties();}/*** 创建 orders 数据源*/@Bean(name = "ordersDataSource")@ConfigurationProperties(prefix = "spring.datasource.orders.hikari") // 读取 spring.datasource.orders 配置到 HikariDataSource 对象public DataSource ordersDataSource() {// <1.1> 获得 DataSourceProperties 对象DataSourceProperties properties = this.ordersDataSourceProperties();// <1.2> 创建 HikariDataSource 对象return createHikariDataSource(properties);}/*** 创建 users 数据源的配置对象*/@Bean(name = "usersDataSourceProperties")@ConfigurationProperties(prefix = "spring.datasource.users") // 读取 spring.datasource.users 配置到 DataSourceProperties 对象public DataSourceProperties usersDataSourceProperties() {return new DataSourceProperties();}/*** 创建 users 数据源*/@Bean(name = "usersDataSource")@ConfigurationProperties(prefix = "spring.datasource.users.hikari")public DataSource usersDataSource() {// 获得 DataSourceProperties 对象DataSourceProperties properties = this.usersDataSourceProperties();// 创建 HikariDataSource 对象return createHikariDataSource(properties);}private static HikariDataSource createHikariDataSource(DataSourceProperties properties) {// 创建 HikariDataSource 对象HikariDataSource dataSource = properties.initializeDataSourceBuilder().type(HikariDataSource.class).build();// 设置线程池名if (StringUtils.hasText(properties.getName())) {dataSource.setPoolName(properties.getName());}return dataSource;}}
ordersDataSourceProperties()方法,创建orders数据源的DataSourceProperties配置对象。
-
@Primary注解,保证项目中有一个主的DataSourceProperties Bean。
-
加上 @Bean(name = “ordersDataSourceProperties”)注解,会创建一个名字位ordersDataSourceProperties的DataSourceProperties Bean
-
@ConfigurationProperties(prefix = “spring.datasource.orders”)注解,会将spring.datasource.orders配置项,逐个属性赋值给DataSourceProperties Bean
ordersDataSource()方法,创建orders数据源。
-
DataSourceProperties properties = this.ordersDataSourceProperties();获取orders数据源的DataSourceProperties配置对象 -
createHikariDataSource()方法创建HikariDataSource对象,这样,
"spring.datasource.orders"配置项,逐个属性赋值给 HikariDataSource Bean 。 -
搭配上
@Bean(name = "ordersDataSource")注解,会创建一个名字为"ordersDataSource"的 HikariDataSource Bean 。 -
@ConfigurationProperties(prefix = "spring.datasource.orders.hikari")注解,会将 HikariCP 的"spring.datasource.orders.hikari"自定义配置项,逐个属性赋值给 HikariDataSource Bean 。

2、Druid数据库连接池
2.1 Druid单数据源配置
2.1.1 pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.1.3.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><modelVersion>4.0.0</modelVersion><artifactId>Druid-Boot</artifactId><dependencies><!-- 保证 Spring JDBC 的依赖健全 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId></dependency><!-- 实现对 Druid 连接池的自动化配置 --><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.21</version></dependency><dependency> <groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.48</version></dependency><!-- 实现对 Spring MVC 的自动化配置,因为我们需要看看 Druid 的监控功能 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- 方便等会写单元测试 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies></project>
2.1.2 yml配置
spring:# datasource 数据源配置内容,对应 DataSourceProperties 配置属性类datasource:url: jdbc:mysql://127.0.0.1:3306/test?useSSL=false&useUnicode=true&characterEncoding=UTF-8driver-class-name: com.mysql.jdbc.Driverusername: root # 数据库账号password: root # 数据库密码type: com.alibaba.druid.pool.DruidDataSource # 设置类型为 DruidDataSource# Druid 自定义配置,对应 DruidDataSource 中的 setting 方法的属性druid:min-idle: 0 # 池中维护的最小空闲连接数,默认为 0 个。max-active: 20 # 池中最大连接数,包括闲置和使用中的连接,默认为 8 个。filter:stat: # 配置 StatFilter ,对应文档 https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_StatFilterlog-slow-sql: true # 开启慢查询记录slow-sql-millis: 5000 # 慢 SQL 的标准,单位:毫秒stat-view-servlet: # 配置 StatViewServlet ,对应文档 https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_StatViewServlet%E9%85%8D%E7%BD%AEenabled: true # 是否开启 StatViewServletlogin-username: root # 账号login-password: root # 密码
2.1.3主启动类
package com.yyds;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;import javax.sql.DataSource;@SpringBootApplication
public class ApplicationBak implements CommandLineRunner {private Logger logger = LoggerFactory.getLogger(ApplicationBak.class);@Autowiredprivate DataSource dataSource;public static void main(String[] args) {// 启动 Spring Boot 应用SpringApplication.run(ApplicationBak.class, args);}@Overridepublic void run(String... args) {logger.info("[run][获得数据源:{}]", dataSource.getClass());}}2.1.4 监控
因为做了如下操作:
- 通过
spring.datasource.filter.stat配置了 StatFilter ,统计监控信息。 - 通过
spring.datasource.filter.stat-view-servlet配置了 StatViewServlet ,提供监控信息的展示的 html 页面和 JSON API
所以我们在启动项目后,访问 http://127.0.0.1:8080/druid 地址,账户密码为配置的root,可以看到监控 html 页面。

- 在界面的顶部,提供了数据源、SQL 监控、SQL 防火墙等功能。
- 每个界面上,可以通过 [View JSON API]获得数据的来源。
- 因为监控信息是存储在 JVM 内存中,在 JVM 进程重启时,信息将会丢失。如果我们希望持久化到 MySQL、Elasticsearch、HBase 等存储器中,可以通过 StatViewServlet 提供的 JSON API 接口,采集监控信息。
Druid 的文档:https://github.com/alibaba/druid/wiki/ 。
2.2 Druid多数据源配置
2.2.1 pom文件
如2.1.1
2.2.2 yml配置
spring:# datasource 数据源配置内容datasource:# 订单数据源配置orders:url: jdbc:mysql://127.0.0.1:3306/test_orders?useSSL=false&useUnicode=true&characterEncoding=UTF-8driver-class-name: com.mysql.jdbc.Driverusername: rootpassword:type: com.alibaba.druid.pool.DruidDataSource # 设置类型为 DruidDataSource# Druid 自定义配置,对应 DruidDataSource 中的 setting 方法的属性min-idle: 0 # 池中维护的最小空闲连接数,默认为 0 个。max-active: 20 # 池中最大连接数,包括闲置和使用中的连接,默认为 8 个。# 用户数据源配置users:url: jdbc:mysql://127.0.0.1:3306/test_users?useSSL=false&useUnicode=true&characterEncoding=UTF-8driver-class-name: com.mysql.jdbc.Driverusername: rootpassword: roottype: com.alibaba.druid.pool.DruidDataSource # 设置类型为 DruidDataSource# Druid 自定义配置,对应 DruidDataSource 中的 setting 方法的属性min-idle: 0 # 池中维护的最小空闲连接数,默认为 0 个。max-active: 20 # 池中最大连接数,包括闲置和使用中的连接,默认为 8 个。# Druid 自定已配置druid:# 过滤器配置filter:stat: # 配置 StatFilter ,对应文档 https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_StatFilterlog-slow-sql: true # 开启慢查询记录slow-sql-millis: 5000 # 慢 SQL 的标准,单位:毫秒# StatViewServlet 配置stat-view-servlet: # 配置 StatViewServlet ,对应文档 https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_StatViewServlet%E9%85%8D%E7%BD%AEenabled: true # 是否开启 StatViewServletlogin-username: root # 账号login-password: root # 密码
2.2.3主启动类
package com.yyds;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;import javax.annotation.Resource;
import javax.sql.DataSource;@SpringBootApplication
public class Application implements CommandLineRunner {private Logger logger = LoggerFactory.getLogger(Application.class);@Resource(name = "ordersDataSource")private DataSource ordersDataSource;@Resource(name = "usersDataSource")private DataSource usersDataSource;public static void main(String[] args) {// 启动 Spring Boot 应用SpringApplication.run(Application.class, args);}@Overridepublic void run(String... args) {// orders 数据源logger.info("[run][获得数据源:{}]", ordersDataSource.getClass());// users 数据源logger.info("[run][获得数据源:{}]", usersDataSource.getClass());}}2.2.4 配置类
package com.yyds.config;import com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceBuilder;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;import javax.sql.DataSource;@Configuration
public class DataSourceConfig {/*** 创建 orders 数据源*/@Primary@Bean(name = "ordersDataSource")@ConfigurationProperties(prefix = "spring.datasource.orders") public DataSource ordersDataSource() {return DruidDataSourceBuilder.create().build();}/*** 创建 users 数据源*/@Bean(name = "usersDataSource")@ConfigurationProperties(prefix = "spring.datasource.users")public DataSource usersDataSource() {return DruidDataSourceBuilder.create().build();}}可以看到数据源加载成功。

相关文章:
SpringBoot整合(五)HikariCP、Druid数据库连接池—多数据源配置
在项目中,数据库连接池基本是必不可少的组件。在目前数据库连接池的选型中,主要是 Druid ,为监控而生的数据库连接池。HikariCP ,号称性能最好的数据库连接池。 在Spring Boot 2.X 版本,默认采用 HikariCP 连接池。而…...
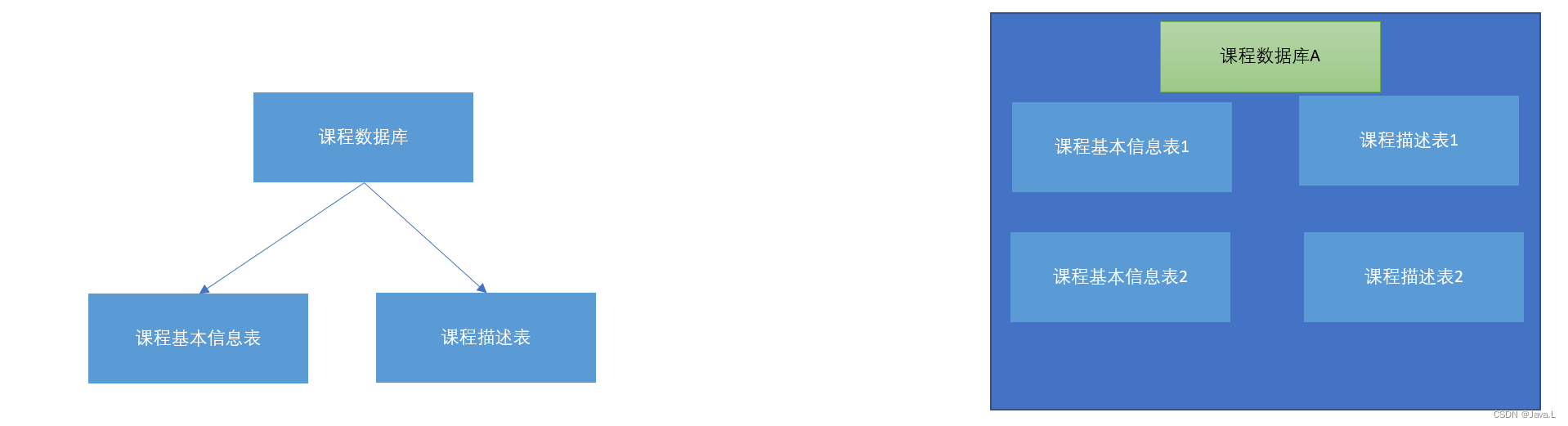
ShardingSphere水平、垂直分库、分表和公共表
目录一、ShardingSphere简介二、ShardingSphere-分库分表1、垂直拆分(1)垂直分库(2)垂直分表2、水平拆分(1)水平分库(2)水平分表三、水平分库操作1、创建数据库和表2、配置分片的规则…...

《分布式技术原理与算法解析》学习笔记Day24
分布式缓存 在计算机领域,缓存是一个非常重要的、用来提升性能的技术。 什么是分布式缓存? 缓存技术是指用一个更快的存储设备存储一些经常用到的数据,供用户快速访问。 分布式缓存是指在分布式环境或者系统下,把一些热门数据…...

强化学习RL 02: Value-based Reinforcement Learning
DQN和TD更新算法。 目录 Review 1. Deep Q-Network(DQN) 1.1 Approximate the Q*(s,a) Function 1.2 Apply DQN to Play Game 1.3 Temporal Difference(TD) Learning 1.4 TD Learning for DQN 1.4.1 TD使用条件 condition 1.4.2 Train DQN using TD learning 1.5 summ…...
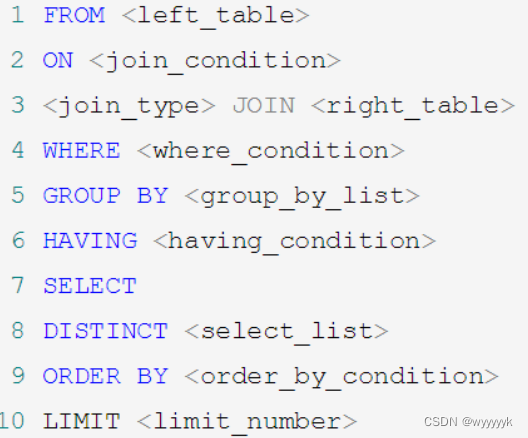
08_MySQL聚合函数
1. 聚合函数介绍什么是聚合函数聚合函数作用于一组数据,并对一组数据返回一个值。聚合函数类型AVG()SUM()MAX()MIN()COUNT()注意:聚合函数不能嵌套调用。比如不能出现类似“AVG(SUM(字段名称))”形式的调用。1.1 AVG和SUM函数可以对数值型数据使用AVG 和…...

「TCG 规范解读」词汇表
可信计算组织(Ttrusted Computing Group,TCG)是一个非盈利的工业标准组织,它的宗旨是加强在相异计算机平台上的计算环境的安全性。TCG于2003年春成立,并采纳了由可信计算平台联盟(the Trusted Computing Platform Alli…...
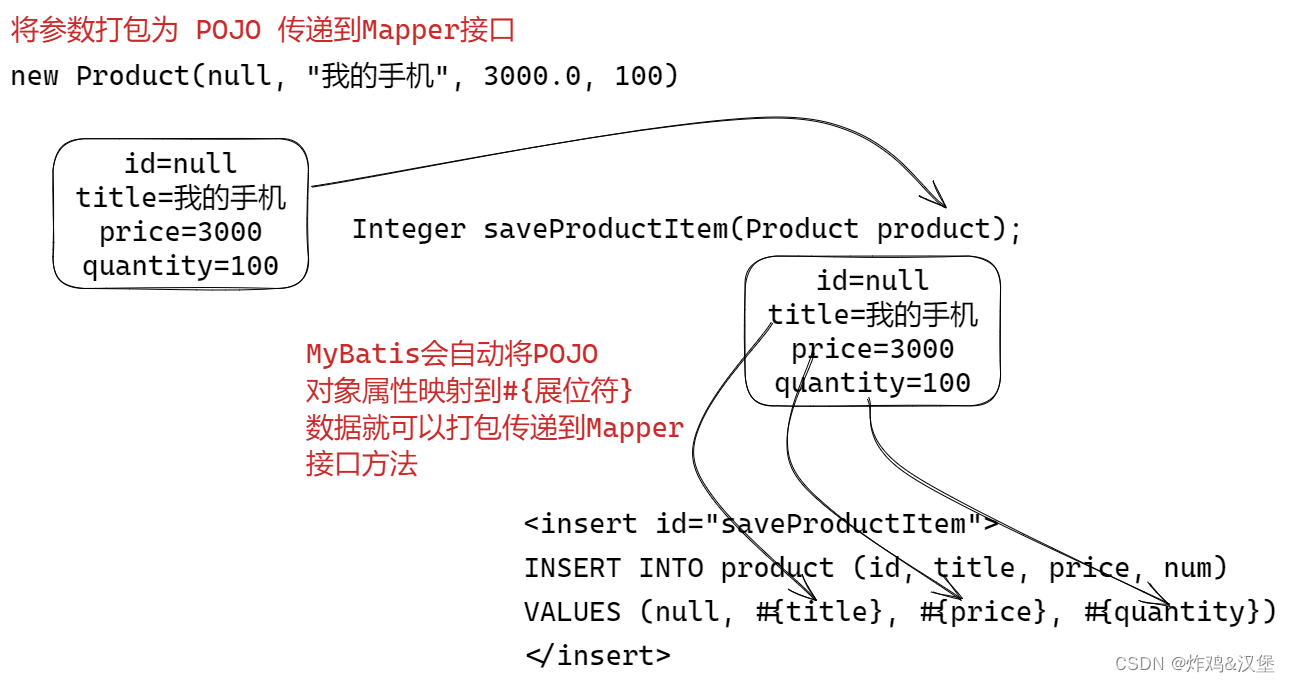
第三阶段-03MyBatis 中使用XML映射文件详解
MyBatis 中使用XML映射文件 什么是XML映射 使用注解的映射SQL的问题: 长SQL需要折行,不方便维护动态SQL查询拼接复杂源代码中的SQL,不方便与DBA协作 MyBatis建议使用XML文件映射SQL才能最大化发挥MySQL的功能 统一管理SQL, 方…...

从0开始学python -41
Python3 命名空间和作用域 命名空间 先看看官方文档的一段话: A namespace is a mapping from names to objects.Most namespaces are currently implemented as Python dictionaries。 命名空间(Namespace)是从名称到对象的映射,大部分的命名空间都是…...
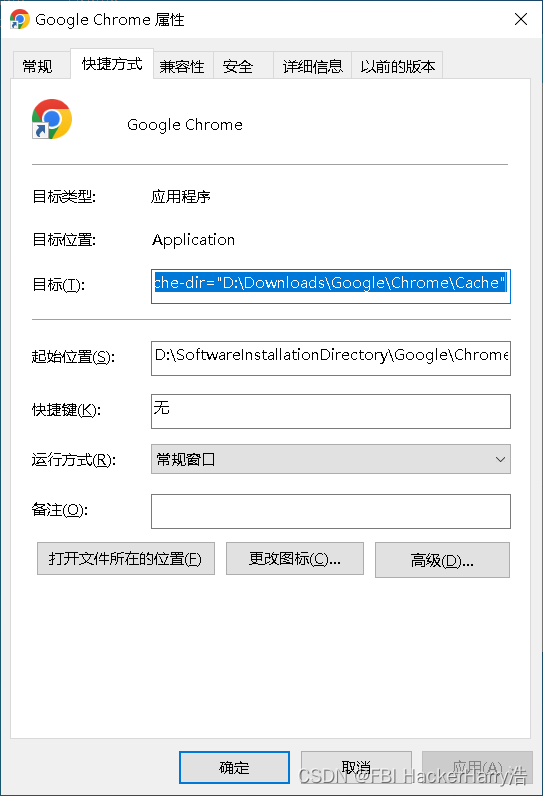
如何将Google浏览器安装到D盘(内含教学视频)
如何将Google浏览器安装到D盘(内含教学视频) 教学视频下载链接地址:https://download.csdn.net/download/weixin_46411355/87503968 目录如何将Google浏览器安装到D盘(内含教学视频)教学视频下载链接地址:…...

三战阿里测试岗,成功上岸,面试才是测试员涨薪真正的拦路虎...
第一次面试阿里记得是挂在技术面上,当时也是技术不扎实,准备的不充分,面试官出的面试题确实把我问的一头雾水,还没结束我就已经知道我挂了这次面试。 第二次面试,我准备的特别充分,提前刷了半个月的面试题…...
)
Java代码弱点与修复之——ORM persistence error(对象关系映射持久错误)
弱点描述 ORM persistence error, ORM 持久化错误 。表示 ORM 工具在尝试将对象保存到数据库中时出现了问题。可能的原因包括: 数据库连接错误:ORM 工具无法连接到数据库,或者连接到数据库的权限不足。数据库表结构错误:ORM 工具无法正确映射对象和数据库表之间的关系,可…...
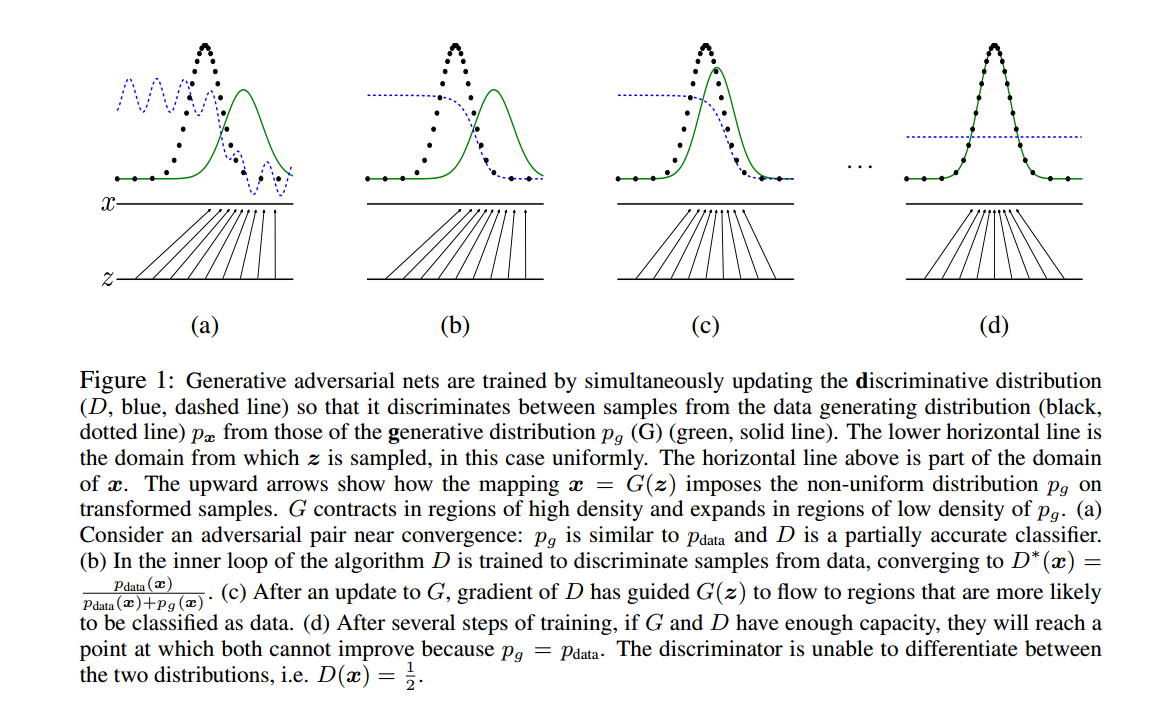
原始GAN-pytorch-生成MNIST数据集(原理)
文章目录1. GAN 《Generative Adversarial Nets》1.1 相关概念1.2 公式理解1.3 图片理解1.4 熵、交叉熵、KL散度、JS散度1.5 其他相关(正在补充!)1. GAN 《Generative Adversarial Nets》 Ian J. Goodfellow, Jean Pouget-Abadie, Yoshua Be…...

Vue下载安装步骤的详细教程(亲测有效) 1
目录 一、【准备工作】nodejs下载安装(npm环境) 1 下载安装nodejs 2 查看环境变量是否添加成功 3、验证是否安装成功 4、修改模块下载位置 (1)查看npm默认存放位置 (2)在 nodejs 安装目录下,创建 “node_global…...

[Android Studio] Android Studio生成数字证书,为应用签名
🟧🟨🟩🟦🟪 Android Debug🟧🟨🟩🟦🟪 Topic 发布安卓学习过程中遇到问题解决过程,希望我的解决方案可以对小伙伴们有帮助。 📋笔记目…...

应用IC 卡继续教育网络管理系统前后影响因素比较
3.1 实现了继续护理教育网络化管理近年来,随着一些医院继续护理教育管理信息系统的建立,有效改进了学分档案管理模式和教学模式,但这些继续护理教育管理信息系统一般为局域网,仅能达到满足自身管理的基本需求,而系统如…...
Clickhouse学习(一):MergeTree概述
MergeTree一、Clickhouse表引擎概述二、MergeTree表引擎<一>、ReplacingMergeTree引擎<二>、SummingMergeTree引擎<三>、AggregatingMergeTree引擎三、MergeTree分区一、Clickhouse表引擎概述 MergeTree表引擎:允许根据日期和主键创建索引 1、ReplacingMerge…...

Windows离线安装rust
目前rust安装常用的方式就是通过Rustup安装,此安装方式需要访问互联网。在生产环境中由于网络限制,不能直接访问互联网或者不能访问目标网站,这时候需要用离线安装的方式,本文将详细介绍离线安装步骤,并给出了vscode如…...
Android与flutter混合开发
这里我使用的android studio版本是2020.3.1;flutter版本2.5.3。此前在网上搜索的很多教教程版本都不一样,新版的IDE和SDK让我遇到了很多坑故这里整理一下。一、创建项目1.在Android项目中点击File->New->New Flutter Project。File->New->Ne…...

Linux和C语言的学习方法你真的知道吗?
★Linux的使用 第一天,就给我们讲了为什么要先学c、学linux:因为嵌入式的根本就是软件驱动硬件,而C语言是最接近硬件的语言、有指针的概念、可以直接操作硬件,另外,功能复杂的硬件是含有操作系统的,这就需…...

代码随想录day42
1049. 最后一块石头的重量 II https://leetcode.cn/problems/last-stone-weight-ii/ 这个自己还是没想出来01背包对应。 本题其实就是尽量让石头分成重量相同的两堆,相撞之后剩下的石头最小,这样就化解成01背包问题了。 stones [2,7,4,1,8,1]也就是sum…...

论文降AIGC教程:从标红区到安全线,2026最新3步攻略与工具测评
今年的交稿季有一点很磨人:除了文章重复率,AIGC检测率几乎也成了各处的标配,很多小伙伴接到通知直接懵了。 我之前也有过长文盲改失败的经历:刚拿到初稿就开始一通操作,觉得把文段里面的词语换换同义词就行࿰…...

数据分析进阶——【连载 5/9】《Power BI数据分析与可视化案例教程》项目5 数据建模
Power BI 数据建模教程|推介总结 适应人群:数据分析师、业务分析人员、财务 / 运营 / 销售岗、高校学生、企业内训学员、Power BI 进阶学习者。 重要性总结:本文档是 Power BI 数据建模核心实操教程,系统讲解数据建模全流程&#…...

ChatGPT和Gemini聊天记录导出
AI对话记录导出技术演进:从碎片化到结构化管理的范式突破 一、技术革命带来的新痛点:AI对话资产的管理困境 在生成式AI技术日臻成熟的今天,开发者与AI的交互频率呈指数级增长。以ChatGPT日均处理30亿次查询、Gemini日均生成内容超2亿次的数…...

String、StringBuilder、StringBuffer 学习与深入
1 学习的知识是什么 String:字符串,一旦创建里面的内容就不可变,每次使用拼接都创建一个新的对象而原有的对象依旧存在。 StringBuilder:可变字符串线程不安全,…...

Intelli开源智能代理框架:从核心概念到生产部署全解析
1. 项目概述:Intelli 是什么,以及它为何值得关注最近在开源社区里,一个名为intelligentnode/Intelli的项目开始引起不少开发者的注意。乍一看这个标题,你可能会有点困惑:Intelli?是某种新的智能代理框架&am…...
原理与创新设计解析)
内容可寻址存储器(CAM)原理与创新设计解析
1. 内容可寻址存储器基础解析在传统计算机架构中,我们通常使用随机存取存储器(RAM)通过地址来访问数据。但有一种特殊的存储结构打破了这种范式——内容可寻址存储器(Content-Addressable Memory, CAM)。它的独特之处在…...

技能包管理器:开发者工具链标准化与版本隔离解决方案
1. 项目概述:一个为开发者赋能的技能包管理器在软件开发的世界里,我们每天都在与各种工具、库和依赖项打交道。从构建工具到代码格式化器,从静态分析器到部署脚本,一个现代项目的开发环境往往由数十个、甚至上百个独立的命令行工具…...
)
【限时解密】Photoshop 25.5 Beta隐藏功能+Midjourney API私有化接入指南(含已验证Webhook配置模板与错误码速查表)
更多请点击: https://intelliparadigm.com 第一章:Midjourney与Photoshop整合方案的演进逻辑与架构全景 随着生成式AI在创意工作流中的深度渗透,Midjourney与Photoshop的协同已从“图像导出→手动精修”的离散模式,演进为基于API…...

Godot引擎开发实战:高效利用代码食谱仓库加速游戏原型设计
1. 项目概述:一个为Godot开发者量身定制的“食谱”仓库如果你正在使用Godot引擎,无论是刚入门的新手,还是已经摸爬滚打了一段时间的开发者,大概率都经历过这样的时刻:脑子里有一个很酷的游戏机制想法,比如“…...

【可口可乐全球设计中心认证流程】:从Prompt工程到DPI输出的12小时高保真印相交付链
更多请点击: https://intelliparadigm.com 第一章:【可口可乐全球设计中心认证流程】:从Prompt工程到DPI输出的12小时高保真印相交付链 可口可乐全球设计中心(Coca-Cola Global Design Hub)采用端到端AI增强型印前认证…...