大数据技术与原理实验报告(MapReduce 初级编程实践)
MapReduce 初级编程实践
验环境:
- 操作系统:Linux(建议Ubuntu16.04);
Hadoop版本:3.2.2;
(一)编程实现文件合并和去重操作
对于两个输入文件,即文件 A 和文件 B,请编写 MapReduce 程序,对两个文件进行合并,
并剔除其中重复的内容,得到一个新的输出文件 C。下面是输入文件和输出文件的一个样例 供参考。
输入文件 A 的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 x
输入文件 B 的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入文件 A 和 B 合并得到的输出文件 C 的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 x
实现上述操作的 Java 代码如下:
1.import java.io.IOException;
2.
3.import org.apache.hadoop.conf.Configuration;
4.import org.apache.hadoop.fs.Path;
5.import org.apache.hadoop.io.IntWritable;
6.import org.apache.hadoop.io.Text;
7.import org.apache.hadoop.mapreduce.Job;
8.import org.apache.hadoop.mapreduce.Mapper;
9.import org.apache.hadoop.mapreduce.Reducer;
10.import org.apache.hadoop.util.GenericOptionsParser;
11.import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
12.import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
13.
14.public class Merge {
15.
16. /**
17. * @param args
18. * 对A,B两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C
19. */
20. //在这重载map函数,直接将输入中的value复制到输出数据的key上 注意在map方法中要抛出异常:throws IOException,InterruptedException
21. public static class Map extends Mapper<Object, Text, Text, Text> {
22. private static Text text = new Text();
23. public void map(Object key, Text value, Context content) throws IOException, InterruptedException {
24.
25. text = value;
26. content.write(text, new Text(""));
27. }
28. }
29. //在这重载reduce函数,直接将输入中的key复制到输出数据的key上 注意在reduce方法上要抛出异常:throws IOException,InterruptedException
30. public static class Reduce extends Reducer<Text, Text, Text, Text> {
31. public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
32. context.write(key, new Text(""));
33. }
34. }
35.
36. public static void main(String[] args) throws Exception{
37.
38. // TODO Auto-generated method stub
39. Configuration conf = new Configuration();
40. conf.set("fs.defaultFS","hdfs://localhost:9000");
41. String[] otherArgs = new String[]{"input","output"}; /* 直接设置输入参数 */
42. if (otherArgs.length != 2) {
43. System.err.println("Usage: wordcount <in> <out>");
44. System.exit(2);
45. }
46. Job job = Job.getInstance(conf,"Merge and duplicate removal");
47. job.setJarByClass(Merge.class);
48. job.setMapperClass(Map.class);
49. job.setCombinerClass(Reduce.class);
50. job.setReducerClass(Reduce.class);
51. job.setOutputKeyClass(Text.class);
52. job.setOutputValueClass(Text.class);
53. FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
54. FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
55. System.exit(job.waitForCompletion(true) ? 0 : 1);
56. }
}运行结果:
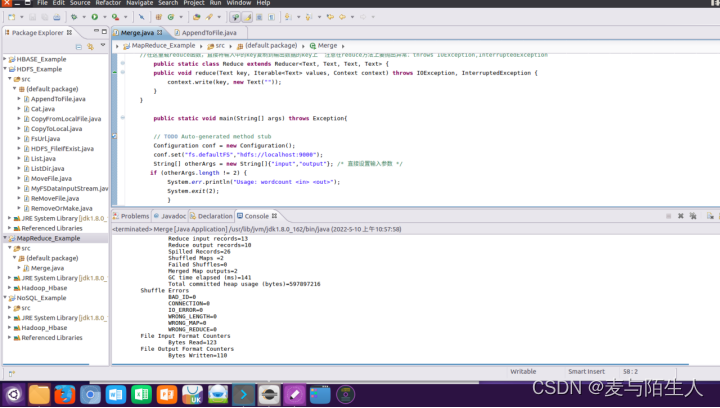
图1:文件合并去重java运行结果

图2:文件合并输出结果
- 二 编程实现对输入文件的排序
现在有多个输入文件,每个文件中的每行内容均为一个整数。要求读取所有文件中的整
数,进行升序排序后,输出到一个新的文件中,输出的数据格式为每行两个整数,第一个数
字为第二个整数的排序位次,第二个整数为原待排列的整数。下面是输入文件和输出文件的
一个样例供参考。
输入文件 1 的样例如下:
33
37
12
40
输入文件 2 的样例如下:
4
16
39
5
输入文件 3 的样例如下:
1
45
25
根据输入文件 1、2 和 3 得到的输出文件如下:
1 1
2 4
3 5
4 12
5 16
6 25
7 33
54
8 37
9 39
10 40
11 45
JAVA代码如下:
1.import java.io.IOException;
2.import org.apache.hadoop.conf.Configuration;
3.import org.apache.hadoop.fs.Path;
4.import org.apache.hadoop.io.IntWritable;
5.import org.apache.hadoop.io.Text;
6.import org.apache.hadoop.mapreduce.Job;
7.import org.apache.hadoop.mapreduce.Mapper;
8.import org.apache.hadoop.mapreduce.Partitioner;
9.import org.apache.hadoop.mapreduce.Reducer;
10.import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
11.import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
12.import org.apache.hadoop.util.GenericOptionsParser;
13.
14.
15.public class MergeSort {
16. /**
17. * @param args
18. * 输入多个文件,每个文件中的每行内容均为一个整数
19. * 输出到一个新的文件中,输出的数据格式为每行两个整数,第一个数字为第二个整数的排序位次,第二个整数为原待排列的整数
20. */
21. //map函数读取输入中的value,将其转化成IntWritable类型,最后作为输出key
22. public static class Map extends Mapper<Object, Text, IntWritable, IntWritable>{
23.
24. private static IntWritable data = new IntWritable();
25. public void map(Object key, Text value, Context context) throws IOException,InterruptedException{
26. String text = value.toString();
27. data.set(Integer.parseInt(text));
28. context.write(data, new IntWritable(1));
29. }
30. }
31.
32. //reduce函数将map输入的key复制到输出的value上,然后根据输入的value-list中元素的个数决定key的输出次数,定义一个全局变量line_num来代表key的位次
33. public static class Reduce extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable>{
34. private static IntWritable line_num = new IntWritable(1);
35. public void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException,InterruptedException{
36. for(IntWritable val : values){
37. context.write(line_num, key);
38. line_num = new IntWritable(line_num.get() + 1);
39. }
40. }
41. }
42.
43. //自定义Partition函数,此函数根据输入数据的最大值和MapReduce框架中Partition的数量获取将输入数据按照大小分块的边界,然后根据输入数值和边界的关系返回对应的Partiton ID
44. public static class Partition extends Partitioner<IntWritable, IntWritable>{
45. public int getPartition(IntWritable key, IntWritable value, int num_Partition){
46. int Maxnumber = 65223;//int型的最大数值
47. int bound = Maxnumber/num_Partition+1;
48. int keynumber = key.get();
49. for (int i = 0; i<num_Partition; i++){
50. if(keynumber<bound * (i+1) && keynumber>=bound * i){
51. return i;
52. }
53. }
54. return -1;
55. }
56. }
57.
58. public static void main(String[] args) throws Exception{
59. // TODO Auto-generated method stub
60. Configuration conf = new Configuration();
61. conf.set("fs.default.name","hdfs://localhost:9000");
62. String[] otherArgs = new String[]{"input","output"}; /* 直接设置输入参数 */
63. if (otherArgs.length != 2) {
64. System.err.println("Usage: wordcount <in><out>");
65. System.exit(2);
66. }
67. Job job = Job.getInstance(conf,"Merge and sort");
68. job.setJarByClass(MergeSort.class);
69. job.setMapperClass(Map.class);
70. job.setReducerClass(Reduce.class);
71. job.setPartitionerClass(Partition.class);
72. job.setOutputKeyClass(IntWritable.class);
73. job.setOutputValueClass(IntWritable.class);
74. FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
75. FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
76. System.exit(job.waitForCompletion(true) ? 0 : 1);
77. }
78.} 运行结果 :

图3:文件内容排序运行结果
- (三 )对给定的表格进行信息挖掘
下面给出一个 child-parent 的表格,要求挖掘其中的父子辈关系,给出祖孙辈关系的
表格。
输入文件内容如下:
child parent
Steven Lucy
Steven Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Frank
Jack Alice
Jack Jesse
David Alice
David Jesse
Philip David
Philip Alma
Mark David
Mark Alma
输出文件内容如下:
grandchild grandparent
Steven Alice
Steven Jesse
Jone Alice
Jone Jesse
Steven Mary
Steven Frank
Jone Mary
Jone Frank
Philip Alice
Philip Jesse
Mark Alice
Mark Jesse
JAVA代码如下:
1.import java.io.IOException;
2.import java.util.*;
3.
4.import org.apache.hadoop.conf.Configuration;
5.import org.apache.hadoop.fs.Path;
6.import org.apache.hadoop.io.IntWritable;
7.import org.apache.hadoop.io.Text;
8.import org.apache.hadoop.mapreduce.Job;
9.import org.apache.hadoop.mapreduce.Mapper;
10.import org.apache.hadoop.mapreduce.Reducer;
11.import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
12.import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
13.import org.apache.hadoop.util.GenericOptionsParser;
14.
15.public class simple_data_mining {
16. public static int time = 0;
17.
18. /**
19. * @param args
20. * 输入一个child-parent的表格
21. * 输出一个体现grandchild-grandparent关系的表格
22. */
23. //Map将输入文件按照空格分割成child和parent,然后正序输出一次作为右表,反序输出一次作为左表,需要注意的是在输出的value中必须加上左右表区别标志
24. public static class Map extends Mapper<Object, Text, Text, Text>{
25. public void map(Object key, Text value, Context context) throws IOException,InterruptedException{
26. String child_name = new String();
27. String parent_name = new String();
28. String relation_type = new String();
29. String line = value.toString();
30. int i = 0;
31. while(line.charAt(i) != ' '){
32. i++;
33. }
34. String[] values = {line.substring(0,i),line.substring(i+1)};
35. if(values[0].compareTo("child") != 0){
36. child_name = values[0];
37. parent_name = values[1];
38. relation_type = "1";//左右表区分标志
39. context.write(new Text(values[1]), new Text(relation_type+"+"+child_name+"+"+parent_name));
40. //左表
41. relation_type = "2";
42. context.write(new Text(values[0]), new Text(relation_type+"+"+child_name+"+"+parent_name));
43. //右表
44. }
45. }
46. }
47.
48. public static class Reduce extends Reducer<Text, Text, Text, Text>{
49. public void reduce(Text key, Iterable<Text> values,Context context) throws IOException,InterruptedException{
50. if(time == 0){ //输出表头
51. context.write(new Text("grand_child"), new Text("grand_parent"));
52. time++;
53. }
54. int grand_child_num = 0;
55. String grand_child[] = new String[10];
56. int grand_parent_num = 0;
57. String grand_parent[]= new String[10];
58. Iterator ite = values.iterator();
59. while(ite.hasNext()){
60. String record = ite.next().toString();
61. int len = record.length();
62. int i = 2;
63. if(len == 0) continue;
64. char relation_type = record.charAt(0);
65. String child_name = new String();
66. String parent_name = new String();
67. //获取value-list中value的child
68.
69. while(record.charAt(i) != '+'){
70. child_name = child_name + record.charAt(i);
71. i++;
72. }
73. i=i+1;
74. //获取value-list中value的parent
75. while(i<len){
76. parent_name = parent_name+record.charAt(i);
77. i++;
78. }
79. //左表,取出child放入grand_child
80. if(relation_type == '1'){
81. grand_child[grand_child_num] = child_name;
82. grand_child_num++;
83. }
84. else{//右表,取出parent放入grand_parent
85. grand_parent[grand_parent_num] = parent_name;
86. grand_parent_num++;
87. }
88. }
89.
90. if(grand_parent_num != 0 && grand_child_num != 0 ){
91. for(int m = 0;m<grand_child_num;m++){
92. for(int n=0;n<grand_parent_num;n++){
93. context.write(new Text(grand_child[m]), new Text(grand_parent[n]));
94. //输出结果
95. }
96. }
97. }
98. }
99. }
100. public static void main(String[] args) throws Exception{
101. // TODO Auto-generated method stub
102. Configuration conf = new Configuration();
103. conf.set("fs.default.name","hdfs://localhost:9000");
104. String[] otherArgs = new String[]{"input","output"}; /* 直接设置输入参数 */
105. if (otherArgs.length != 2) {
106. System.err.println("Usage: wordcount <in><out>");
107. System.exit(2);
108. }
109. Job job = Job.getInstance(conf,"Single table join");
110. job.setJarByClass(simple_data_mining.class);
111. job.setMapperClass(Map.class);
112. job.setReducerClass(Reduce.class);
113. job.setOutputKeyClass(Text.class);
114. job.setOutputValueClass(Text.class);
115. FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
116. FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
117. System.exit(job.waitForCompletion(true) ? 0 : 1);
118. }
119.} 运行结果:
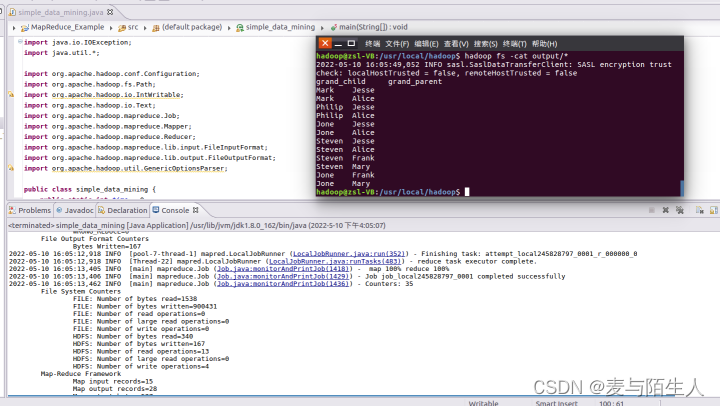 图4:简单文件信息挖掘运行结果
图4:简单文件信息挖掘运行结果
出现的问题:
1、做第一个实验的时候,输出文件的内容是一长串文本:Apache License 2.0

图5:第一个实验文件合并去重输出结果
2、做第二个实验的时候忘记删除output输出文件夹导致程序运行报错
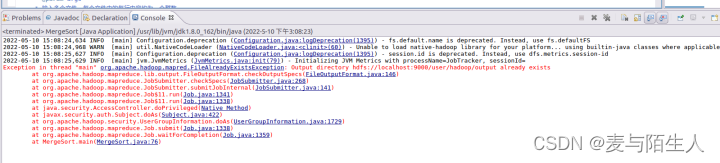
图6:第二个实验java程序运行报错
3、做第二个实验的时候,删除了output输出文件夹依然有报错:For input string = “”
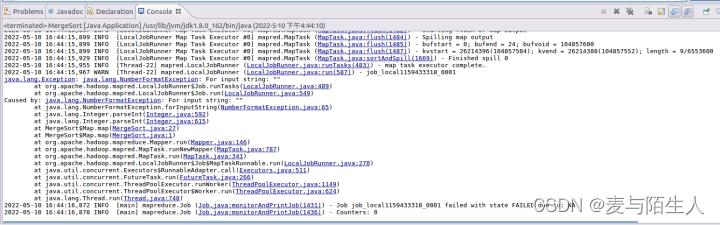
图7:第二个实验java程序运行报错信息
解决方案(列出遇到的问题和解决办法,列出没有解决的问题):
1、

图8:第一个实验的输入文件夹input当中的内容
上传输入文本到HDFS的时候,input文件夹还遗留了一个文本LICENSE.txt文件没有删除,导致这三个文本进行了合并操作,删除该文件后再运行java程序输出结果正确。
2、
再次运行程序,如果不删除上一次运行结束后的输出文件夹,就报错,每次手动去删除输出文件夹简直太麻烦了。在run()方法或者main()方法(视个人程序结构而定)中加入如下代码就可以让程序在运行时先自动删除与设定的输出文件夹同名的文件夹。
1.Path in = new Path(args1[0]);
2.Path out = new Path(args1[1]);
3.FileSystem fileSystem = FileSystem.get(new URI(in.toString()), new Configuration());
4. if (fileSystem.exists(out)) {
5. fileSystem.delete(out, true);
6. } 希望大家适当的利用。
相关文章:
大数据技术与原理实验报告(MapReduce 初级编程实践)
MapReduce 初级编程实践 验环境: 操作系统:Linux(建议Ubuntu16.04); Hadoop版本:3.2.2; (一)编程实现文件合并和去重操作 对于两个输入文件,即文件 A 和…...
Redis 5大数据类型命令解读
目录 Redis key的命令 1、redis字符串(String) 2、redis列表(List) 3、redis哈希表(Hash) 4、redis集合(Set) 5、redis有序集合(ZSet) Redis 命令网站:redis中文文档 Redis key的命令 命令说明示例keys *查看当前库所有的keykeys *…...

数据可视化新秀 DataEase 可否替代 Tableau?
每年数以千计的企业在数据可视化工具中选择 Tableau,但是你知道还有一款强大的工具DataEase,可能会成为你的更佳选择吗?下面是 Tableau 与 DataEase 的功能对比: 1 功能对比 Tableau DataEase 安装包支持平台 Windows MacOS Li…...

Java源码分析(三)ArrayList
ArrayList是我们经常用到的一个集合类。数组在创建时就要给一个明确的大小,而ArrayList的长度是可以动态调整的,因此,也叫动态数组。那么本篇我们一起学习下ArrayList的源码。 一、创建ArrayList 首先,我们从创建ArrayList开始。…...
冒泡排序
贵阳这个地方的天气变化好大呀,前两天晒大太阳,今天就冷的脚抖,简直不要太冷,但是不管怎么样,还是要学习的哟! 冬天来了,春天确实还有一点远! 好了,话不多说,…...

docker基于debian11基础环境安装libreoffice
首先下载指定版本的libreoffice,注意debian11下需要选择Linux (64-bit) (deb) 官方下载地址:https://www.libreoffice.org/download/download-libreoffice/?typedeb-x86_64&version7.6.2&langzh-CN 将文件上传到服务器并解压缩备用,…...

【正点原子STM32连载】 第五十章 FATFS实验 摘自【正点原子】APM32F407最小系统板使用指南
1)实验平台:正点原子stm32f103战舰开发板V4 2)平台购买地址:https://detail.tmall.com/item.htm?id609294757420 3)全套实验源码手册视频下载地址: http://www.openedv.com/thread-340252-1-1.html## 第五…...

12. 机器学习——评价指标
机器学习面试题汇总与解析——评价指标 本章讲解知识点 什么是评价指标?机器学习本专栏适合于Python已经入门的学生或人士,有一定的编程基础。本专栏适合于算法工程师、机器学习、图像处理求职的学生或人士。本专栏针对面试题答案进行了优化,尽量做到好记、言简意赅。这才是…...
、322. 零钱兑换、279.完全平方数)
代码随想录算法训练营第23期day45|70. 爬楼梯 (进阶)、322. 零钱兑换、279.完全平方数
目录 一、(leetcode 70)爬楼梯 二、(leetcode 322)零钱兑换 三、(leetcode 279)完全平方数 一、(leetcode 70)爬楼梯 力扣题目链接 状态:查看思路后AC 除…...

uniapp公共css
/* 弹性布局 */ .flex{display: flex; } .a-c{align-items: center; } .a-s{align-items: flex-start; } .a-e{align-items: flex-end; } .j-c{justify-content: center; } .j-sb{justify-content: space-between; } .j-s{justify-content: flex-start; } .j-e{justify-content…...

C语言—i++、++i、条件运算符、goto语句、注释
i和i #include <stdio.h> int main() {int i5,j;j i;printf("i%d,j%d\n", i, j);i 5;j i;printf("i%d,j%d\n", i, j);system("pause");return 0;}i6,j6 i6,j5 请按任意键继续. . .条件运算符 goto语句 #include <stdio.h> int …...
Java自学第8课:电商项目(3) - 重新搭建环境
由于之前用的jdk和eclipse,以及mysql并不是视频教程所采用的,在后面运行源码和使用作者提供源码时,总是报错,怀疑: 1 数据库有问题 2 jdk和引入的jar包不匹配 3 其他什么未知的错误? 所以决定卸载jdk e…...

深度学习_11_softmax_图片识别代码原理解析
完整代码: import torch from d2l import torch as d2l"创建训练集&创建检测集合" batch_size 256 train_iter, test_iter d2l.load_data_fashion_mnist(batch_size)"每个图片长度,以及图片种类" num_inputs 784 num_output…...
Java Web——前端HTML入门
目录 HTML&CSS3&JavaScript简述 1. HTML概念 2. 超文本 3. 标记语言 4. HTML基础结构 5. HTML基础词汇 6. HTML语法规则 7. VS Code 推荐使用的插件 8. 在线帮助文档 HTML&CSS3&JavaScript简述 HTML 主要用于网页主体结构的搭建,像一个毛坯…...
华为ensp:为vlan配置ip
配置对应vlan的ip vlan1 interface Vlanif 1 进入vlan1 ip address 192.168.1.254 24配置IP为192.168.1.254 子网掩码为24位 这样就配置上ip了 vlan2 interface Vlanif 2 ip address 192.168.2.254 24 vlan3 interface Vlanif 3 ip address 192.168.3.254 24 查看结果 …...

laravel8-rabbitmq消息队列-实时监听跨服务器消息
使用场景介绍: 1)用于实时监听远程服务器发出的消息(json格式消息),接受并更新消息状态,存储到本地服务器 2)环境:lNMP(laravel8) 3)服务器需要开…...

git清除历史提交记录保持本地文件不变
https://www.cnblogs.com/langkyeSir/p/14528857.html git删除历史版本,保留当前状态。 有时候,我们误提交了某些隐私文件,使用git rm xxx删除后,其实版本库中是有历史记录的,想要删除这些记录,但是又不想…...
SOME/IP学习笔记2
1. SOME/IP 协议 SOME/IP目前支持UDP(用户传输协议)和TCP(传输控制协议), PS:UDP和TCP区别如下 TCP面向连接的,可靠的数据传输服务;UDP面向无连接的,尽最大努力的数据传输服务&…...
python实现FINS协议的TCP服务端(篇一)
python实现FINS协议的TCP服务端是一件稍微麻烦点的事情。它不像modbusTCP那样,可以使用现成的pymodbus模块去实现。但是,我们可以根据协议帧进行组包,自己去实现帧的格式,而这一切可以基于socket模块。本文为第一篇。 一、了解FI…...
给 Android 开发带来的那些‘坑‘与应对策略)
从 ‘Unable to make field...‘ 错误聊聊 Java 模块化(JPMS)给 Android 开发带来的那些‘坑‘与应对策略
从 "Unable to make field..." 错误解析 Java 模块化对 Android 开发的深层影响 当你在 Android Studio 中看到 "Unable to make field private final java.lang.String java.io.File.path accessible" 这样的错误时,表面上看是一个简单的反射访…...

图解Simple-BEV核心模块:从2D图像到3D BEV特征图的完整数据流解析
图解Simple-BEV核心模块:从2D图像到3D BEV特征图的完整数据流解析 想象一下,当你驾驶汽车时,眼睛看到的只是前方有限的视野,而大脑却能神奇地将这些二维画面重构为三维空间感知。这正是自动驾驶系统中BEV(鸟瞰图&#…...

Windows与Office激活终极指南:告别弹窗烦恼的完整解决方案
Windows与Office激活终极指南:告别弹窗烦恼的完整解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾经遇到过Windows系统突然弹出激活提示,或者Office软件…...

C语言完美演绎7-7
/* 范例:7-7 */#include <stdio.h>int main(){int a;int b;int *ptr; /* 定义指针变量,这里的星号间接运算符 (*)并不作“依址操作”动作 */a 5; b a; ptr &b; /* 变量b的地址,赋值给指针变量ptr *//* 下面是把a、b、ptr的内…...

Tensorflow-101词嵌入Word2Vec终极教程:从简单到复杂的文本处理
Tensorflow-101词嵌入Word2Vec终极教程:从简单到复杂的文本处理 【免费下载链接】Tensorflow-101 项目地址: https://gitcode.com/gh_mirrors/te/Tensorflow-101 Tensorflow-101是一个全面的TensorFlow学习项目,其中词嵌入Word2Vec技术是文本处理…...

Redis Sentinel高可用实战:主从自动故障转移
一、Sentinel 核心概念 监控:持续检查主从节点是否正常 通知:节点异常时通知管理员或其他程序 自动故障转移:主节点下线时,自动选举新的主节点 配置提供者:客户端通过 Sentinel 获取当前主节点地址 回到顶部 二、…...

3步彻底解决Windows系统卡顿问题:开源系统清理工具实战指南
3步彻底解决Windows系统卡顿问题:开源系统清理工具实战指南 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否也经历过这样的场景:工作…...

足球数据API实战指南:Understat异步采集框架与战术分析应用
足球数据API实战指南:Understat异步采集框架与战术分析应用 【免费下载链接】understat An asynchronous Python package for https://understat.com/. 项目地址: https://gitcode.com/gh_mirrors/un/understat 在足球数据分析领域,高效获取结构化…...
SQL 常用语句总结)
高斯数据库(GaussDB)SQL 常用语句总结
高斯数据库(GaussDB)SQL 常用语句总结 高斯数据库(GaussDB)是华为基于 PostgreSQL 开源生态开发的企业级分布式关系型数据库,兼容标准 SQL 92/99/2003,同时支持 PostgreSQL 语法,还自带分布式、高可用特性。 下面按日常开发高频场景整理最实用的 SQL 语句,直接复制就…...

随笔——视觉惯性SLAM方法比较
一、方法分类概览 视觉SLAM根据前端匹配方式主要分为: 特征点法:提取角点/边缘,计算描述子匹配 → 精度高、鲁棒,但地图稀疏、弱纹理易失败。直接法:直接使用像素灰度值 → 计算快、弱纹理可用,但对光照/…...