jetsonTX2 nx配置tensorRT加速yolov5推理
环境说明
Ubuntu 18+conda环境python3.9+cuda10.2,硬件平台是Jetson tx2 nx
前提你已经能运行YOLOV5代码后,再配置tensorRT进行加速。
目前只试了图片检测和C++打开USB摄像头进行视频检测,希望是使用python配合D435i深度相机来实现检测,后续再更新。
一、安装TensorRT
- 安装git和cmake(已经安装了忽略这一步)
sudo apt-get install libpython3-dev python3-numpy
- 克隆源码
连接不上就挂个梯子
git clone https://github.com/dusty-nv/jetson-inference
- 安装附属文件
git submodule update --init
- 添加jetson-inference需要的包
- 先下载相关包:百度网盘分享 提取码:s75z
下载后拷贝到jetson tx2中,将所有包复制到刚刚克隆的jetson-inference下的data/networks
- 然后cd进入到data/networks文件夹,解压相关包
cd jetson-inference/data/networks
for tar in *.tar.gz; do tar xvf $tar; done
- 再编辑 jetson-inference/CMakePrebuild.sh文件,把./download-models.sh 注释掉
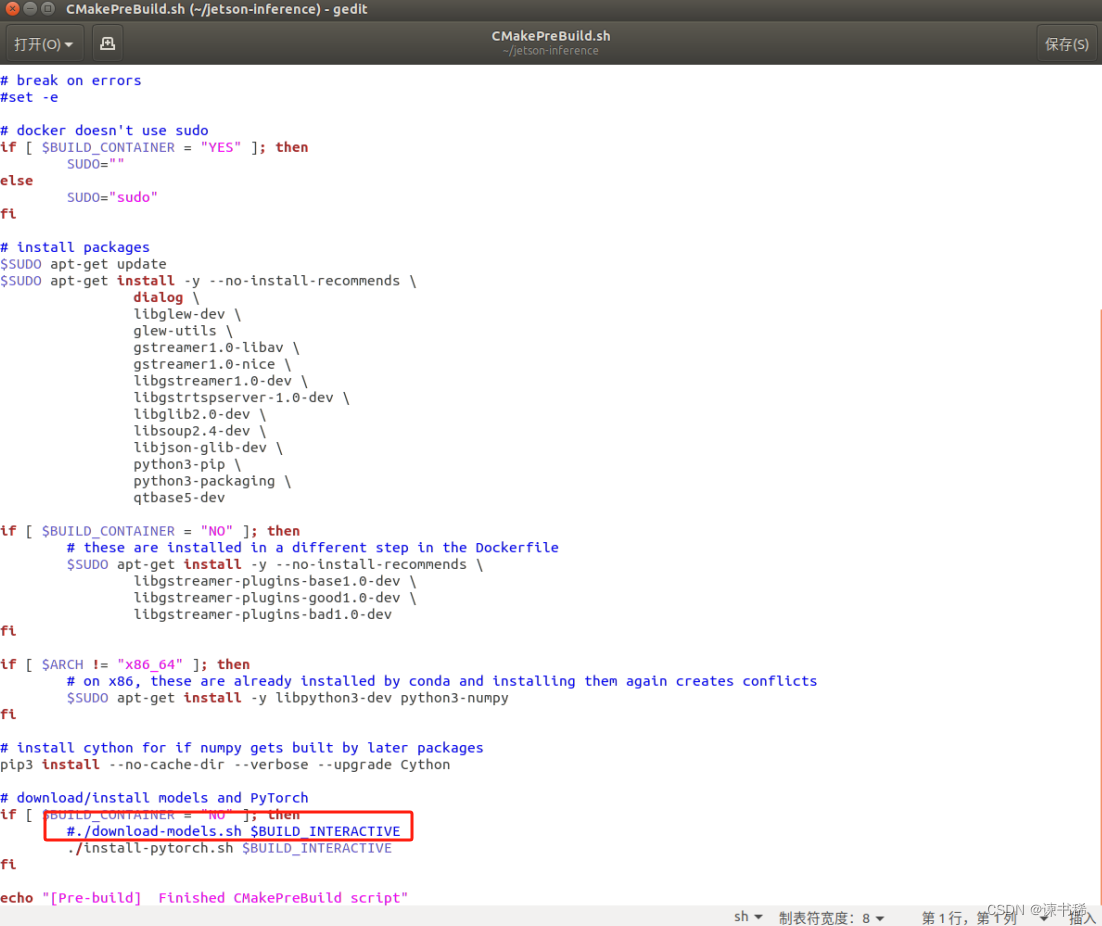
- 编译
- 在 jetson-inference文件夹里面创建build文件夹
mkdir build
- 进入build中进行cmake
cd build
cmake ../
运行过程中弹出该页面跳过即可
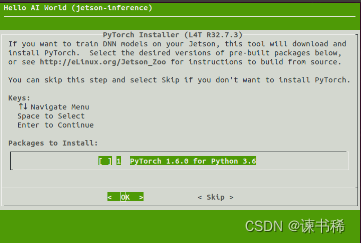
cmake过程中报错,克隆不成功,就删除jetson-inference文件夹,再试一遍
- cmake成功后
# 可能有点慢,耐心等待
make
make成功后
sudo make install
- 测试
安装成功后,进行测试
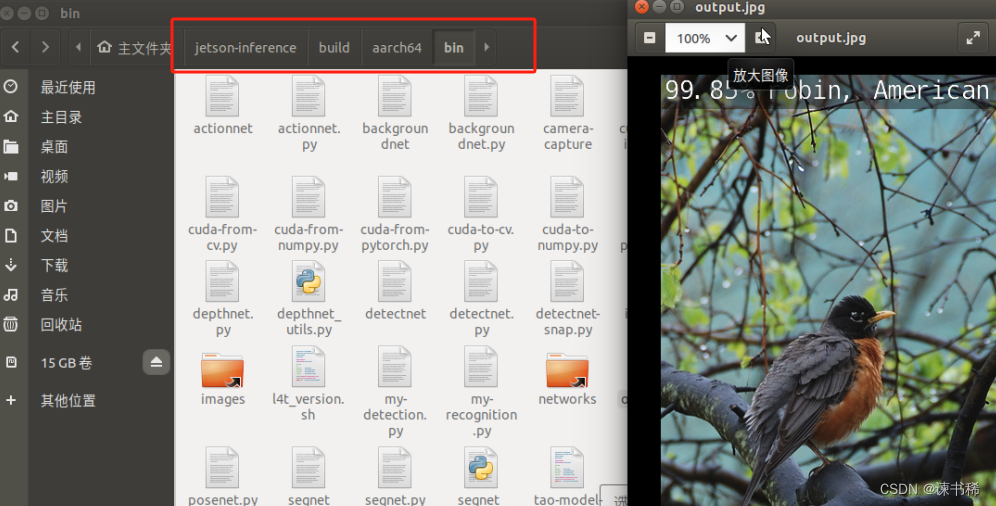
cd jetson-inference/build/aarch64/bin
./imagenet-console ./images/bird_0.jpg output.jpg
参考博主:https://blog.csdn.net/qq_42078934/article/details/129669965?spm=1001.2014.3001.5506
- 如果出现在下载Googlenet.tar.gz相关,并且最终下载失败,报错,需要先中断执行;
- 然后在networks文件夹中新建Googlenet文件夹,将networks文件夹中的bvlc_googlenet.caffemodel、googlenet.prototxt和googlenet_noprob.prototxt剪切到新建的Googlenet文件夹;
- 最后在Googlenet文件夹新建networks文件夹,将ilsvrc12_synset_words.txt剪切到新建networks文件夹
再次进行测试:
二、TensorRT加速YOLOV5
- 安装pycuda包
这个包是使用python编写加速的一个包,本文还只实验了C++版本的,但可以先把这个包安装上
python3 -m pip install 'pycuda<2020.1'
用这个命令直接安装的2019.1版本的,网上有些教程是下载包再进行安装,我这样发现安装的包在虚拟环境中用不了,建议直接进入到需要安装的虚拟环境中,直接用这条命令进行安装。
安装完后测试:

- 下载tensorrt的YOLOV5代码
这里我是想把自己训练好的模型,用tensorrt做一个加速,自己训练模型的yolov5版本是6.0,所以这里也下载6.0版本的tensorrt yolov5。下载链接
- 生成wts文件
自己训练的模型是.pt,这里先转换成.wts文件。
- 把刚刚下载的tensorrt yolo文件中yolov5下的gen_wts.py复制到你自己yolov5代码的文件夹下(这里应该存放了你自己训练的.pt权重文件)

- 执行gen_wts.py生成.wts文件。
python3 gen_wts.py weights/yolov5s.pt # 后面是自己的权重的名字
这里如果遇到报错,参考解决办法:解决办法
- 生成部署引擎
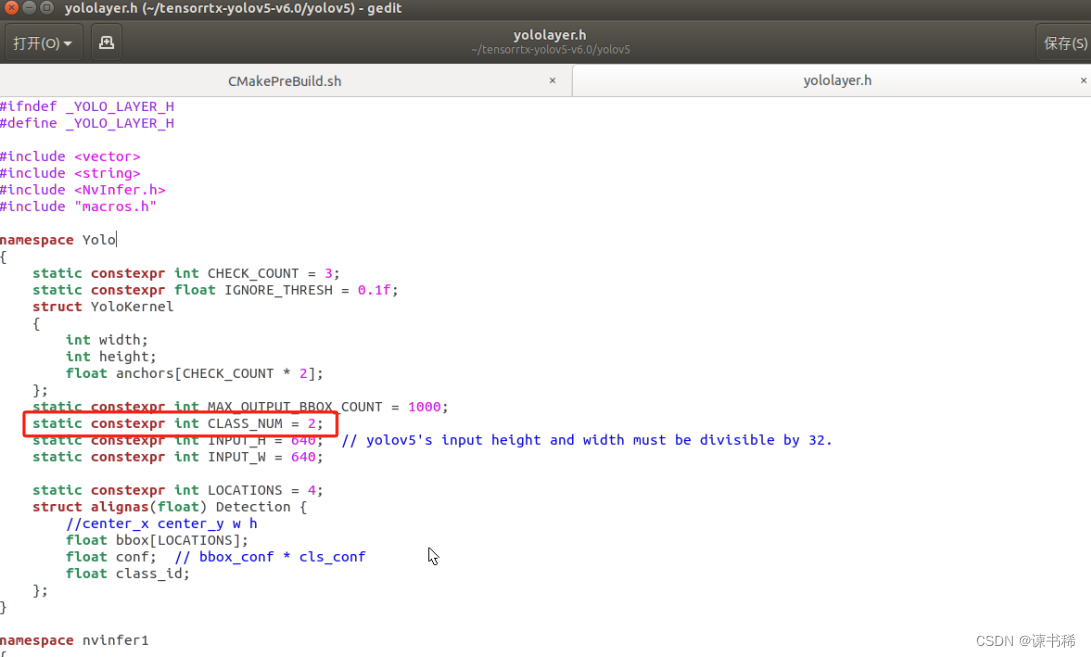
- 先将yolov5s.wts文件(上一步生成的文件)放到tensorrtx-yolov5-v6.0/yolov5文件夹中。
- 然后打开yololayer.h文件,修改num总数,根据你训练模型的类个数来,这里我是两类,所以改为2
- 编译相关
cd tensorrtx-yolov5-v6.0/yolov5
mkdir build
cd build
cmake ..
make
sudo ./yolov5 -s ../yolov5s.wts yolov5s.engine s
# sudo ./yolov5 -s [.wts] [.engine] [s/m/l/x/s6/m6/l6/x6 or c/c6 gd gw]
# s代表用的是yolov5s,是什么就改成什么
到这里便通过tensorrt生成了基于C++的engine部署引擎文件,后缀.engine
- 使用图片测试
将yolov5源代码的data文件夹中的images文件夹整个复制到tensorrtx/yolov5文件夹,在build文件夹里执行下面的代码。
sudo ./yolov5 -d yolov5s.engine ../samples
#sudo ./yolov5 -d [.engine] [image folder]
执行后,结果会在build中看到。如果图形没有画框,可能是因为s模型所产生的置信度一般在0.2-0.4之间,在yolov5.cpp文件中置信度conf_thresh设置在0.5,低于0.5的检测框会被排除。
- 使用USB摄像头
这里是采用的C++的版本,替换tensorrtx-yolov5-v6.0\yolov5\yolov5.cpp文件中的内容为(注意修改为自己的分类类别):
#include <iostream>
#include <chrono>
#include "cuda_utils.h"
#include "logging.h"
#include "common.hpp"
#include "utils.h"
#include "calibrator.h"#define USE_FP16 // set USE_INT8 or USE_FP16 or USE_FP32
#define DEVICE 0 // GPU id
#define NMS_THRESH 0.4
#define CONF_THRESH 0.5
#define BATCH_SIZE 1// stuff we know about the network and the input/output blobs
static const int INPUT_H = Yolo::INPUT_H;
static const int INPUT_W = Yolo::INPUT_W;
static const int CLASS_NUM = Yolo::CLASS_NUM;
static const int OUTPUT_SIZE = Yolo::MAX_OUTPUT_BBOX_COUNT * sizeof(Yolo::Detection) / sizeof(float) + 1; // we assume the yololayer outputs no more than MAX_OUTPUT_BBOX_COUNT boxes that conf >= 0.1
const char* INPUT_BLOB_NAME = "data";
const char* OUTPUT_BLOB_NAME = "prob";
static Logger gLogger;//修改为自己的类别
char *my_classes[]={"person", "bicycle"};static int get_width(int x, float gw, int divisor = 8) {//return math.ceil(x / divisor) * divisorif (int(x * gw) % divisor == 0) {return int(x * gw);}return (int(x * gw / divisor) + 1) * divisor;
}static int get_depth(int x, float gd) {if (x == 1) {return 1;}else {return round(x * gd) > 1 ? round(x * gd) : 1;}
}//#创建engine和network
ICudaEngine* build_engine(unsigned int maxBatchSize, IBuilder* builder, IBuilderConfig* config, DataType dt, float& gd, float& gw, std::string& wts_name) {INetworkDefinition* network = builder->createNetworkV2(0U);// Create input tensor of shape {3, INPUT_H, INPUT_W} with name INPUT_BLOB_NAMEITensor* data = network->addInput(INPUT_BLOB_NAME, dt, Dims3{ 3, INPUT_H, INPUT_W });assert(data);std::map<std::string, Weights> weightMap = loadWeights(wts_name);/* ------ yolov5 backbone------ */auto focus0 = focus(network, weightMap, *data, 3, get_width(64, gw), 3, "model.0");auto conv1 = convBlock(network, weightMap, *focus0->getOutput(0), get_width(128, gw), 3, 2, 1, "model.1");auto bottleneck_CSP2 = C3(network, weightMap, *conv1->getOutput(0), get_width(128, gw), get_width(128, gw), get_depth(3, gd), true, 1, 0.5, "model.2");auto conv3 = convBlock(network, weightMap, *bottleneck_CSP2->getOutput(0), get_width(256, gw), 3, 2, 1, "model.3");auto bottleneck_csp4 = C3(network, weightMap, *conv3->getOutput(0), get_width(256, gw), get_width(256, gw), get_depth(9, gd), true, 1, 0.5, "model.4");auto conv5 = convBlock(network, weightMap, *bottleneck_csp4->getOutput(0), get_width(512, gw), 3, 2, 1, "model.5");auto bottleneck_csp6 = C3(network, weightMap, *conv5->getOutput(0), get_width(512, gw), get_width(512, gw), get_depth(9, gd), true, 1, 0.5, "model.6");auto conv7 = convBlock(network, weightMap, *bottleneck_csp6->getOutput(0), get_width(1024, gw), 3, 2, 1, "model.7");auto spp8 = SPP(network, weightMap, *conv7->getOutput(0), get_width(1024, gw), get_width(1024, gw), 5, 9, 13, "model.8");/* ------ yolov5 head ------ */auto bottleneck_csp9 = C3(network, weightMap, *spp8->getOutput(0), get_width(1024, gw), get_width(1024, gw), get_depth(3, gd), false, 1, 0.5, "model.9");auto conv10 = convBlock(network, weightMap, *bottleneck_csp9->getOutput(0), get_width(512, gw), 1, 1, 1, "model.10");auto upsample11 = network->addResize(*conv10->getOutput(0));assert(upsample11);upsample11->setResizeMode(ResizeMode::kNEAREST);upsample11->setOutputDimensions(bottleneck_csp6->getOutput(0)->getDimensions());ITensor* inputTensors12[] = { upsample11->getOutput(0), bottleneck_csp6->getOutput(0) };auto cat12 = network->addConcatenation(inputTensors12, 2);auto bottleneck_csp13 = C3(network, weightMap, *cat12->getOutput(0), get_width(1024, gw), get_width(512, gw), get_depth(3, gd), false, 1, 0.5, "model.13");auto conv14 = convBlock(network, weightMap, *bottleneck_csp13->getOutput(0), get_width(256, gw), 1, 1, 1, "model.14");auto upsample15 = network->addResize(*conv14->getOutput(0));assert(upsample15);upsample15->setResizeMode(ResizeMode::kNEAREST);upsample15->setOutputDimensions(bottleneck_csp4->getOutput(0)->getDimensions());ITensor* inputTensors16[] = { upsample15->getOutput(0), bottleneck_csp4->getOutput(0) };auto cat16 = network->addConcatenation(inputTensors16, 2);auto bottleneck_csp17 = C3(network, weightMap, *cat16->getOutput(0), get_width(512, gw), get_width(256, gw), get_depth(3, gd), false, 1, 0.5, "model.17");// yolo layer 0IConvolutionLayer* det0 = network->addConvolutionNd(*bottleneck_csp17->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.0.weight"], weightMap["model.24.m.0.bias"]);auto conv18 = convBlock(network, weightMap, *bottleneck_csp17->getOutput(0), get_width(256, gw), 3, 2, 1, "model.18");ITensor* inputTensors19[] = { conv18->getOutput(0), conv14->getOutput(0) };auto cat19 = network->addConcatenation(inputTensors19, 2);auto bottleneck_csp20 = C3(network, weightMap, *cat19->getOutput(0), get_width(512, gw), get_width(512, gw), get_depth(3, gd), false, 1, 0.5, "model.20");//yolo layer 1IConvolutionLayer* det1 = network->addConvolutionNd(*bottleneck_csp20->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.1.weight"], weightMap["model.24.m.1.bias"]);auto conv21 = convBlock(network, weightMap, *bottleneck_csp20->getOutput(0), get_width(512, gw), 3, 2, 1, "model.21");ITensor* inputTensors22[] = { conv21->getOutput(0), conv10->getOutput(0) };auto cat22 = network->addConcatenation(inputTensors22, 2);auto bottleneck_csp23 = C3(network, weightMap, *cat22->getOutput(0), get_width(1024, gw), get_width(1024, gw), get_depth(3, gd), false, 1, 0.5, "model.23");IConvolutionLayer* det2 = network->addConvolutionNd(*bottleneck_csp23->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.2.weight"], weightMap["model.24.m.2.bias"]);auto yolo = addYoLoLayer(network, weightMap, "model.24", std::vector<IConvolutionLayer*>{det0, det1, det2});yolo->getOutput(0)->setName(OUTPUT_BLOB_NAME);network->markOutput(*yolo->getOutput(0));// Build enginebuilder->setMaxBatchSize(maxBatchSize);config->setMaxWorkspaceSize(16 * (1 << 20)); // 16MB
#if defined(USE_FP16)config->setFlag(BuilderFlag::kFP16);
#elif defined(USE_INT8)std::cout << "Your platform support int8: " << (builder->platformHasFastInt8() ? "true" : "false") << std::endl;assert(builder->platformHasFastInt8());config->setFlag(BuilderFlag::kINT8);Int8EntropyCalibrator2* calibrator = new Int8EntropyCalibrator2(1, INPUT_W, INPUT_H, "./coco_calib/", "int8calib.table", INPUT_BLOB_NAME);config->setInt8Calibrator(calibrator);
#endifstd::cout << "Building engine, please wait for a while..." << std::endl;ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);std::cout << "Build engine successfully!" << std::endl;// Don't need the network any morenetwork->destroy();// Release host memoryfor (auto& mem : weightMap){free((void*)(mem.second.values));}return engine;
}ICudaEngine* build_engine_p6(unsigned int maxBatchSize, IBuilder* builder, IBuilderConfig* config, DataType dt, float& gd, float& gw, std::string& wts_name) {INetworkDefinition* network = builder->createNetworkV2(0U);// Create input tensor of shape {3, INPUT_H, INPUT_W} with name INPUT_BLOB_NAMEITensor* data = network->addInput(INPUT_BLOB_NAME, dt, Dims3{ 3, INPUT_H, INPUT_W });assert(data);std::map<std::string, Weights> weightMap = loadWeights(wts_name);/* ------ yolov5 backbone------ */auto focus0 = focus(network, weightMap, *data, 3, get_width(64, gw), 3, "model.0");auto conv1 = convBlock(network, weightMap, *focus0->getOutput(0), get_width(128, gw), 3, 2, 1, "model.1");auto c3_2 = C3(network, weightMap, *conv1->getOutput(0), get_width(128, gw), get_width(128, gw), get_depth(3, gd), true, 1, 0.5, "model.2");auto conv3 = convBlock(network, weightMap, *c3_2->getOutput(0), get_width(256, gw), 3, 2, 1, "model.3");auto c3_4 = C3(network, weightMap, *conv3->getOutput(0), get_width(256, gw), get_width(256, gw), get_depth(9, gd), true, 1, 0.5, "model.4");auto conv5 = convBlock(network, weightMap, *c3_4->getOutput(0), get_width(512, gw), 3, 2, 1, "model.5");auto c3_6 = C3(network, weightMap, *conv5->getOutput(0), get_width(512, gw), get_width(512, gw), get_depth(9, gd), true, 1, 0.5, "model.6");auto conv7 = convBlock(network, weightMap, *c3_6->getOutput(0), get_width(768, gw), 3, 2, 1, "model.7");auto c3_8 = C3(network, weightMap, *conv7->getOutput(0), get_width(768, gw), get_width(768, gw), get_depth(3, gd), true, 1, 0.5, "model.8");auto conv9 = convBlock(network, weightMap, *c3_8->getOutput(0), get_width(1024, gw), 3, 2, 1, "model.9");auto spp10 = SPP(network, weightMap, *conv9->getOutput(0), get_width(1024, gw), get_width(1024, gw), 3, 5, 7, "model.10");auto c3_11 = C3(network, weightMap, *spp10->getOutput(0), get_width(1024, gw), get_width(1024, gw), get_depth(3, gd), false, 1, 0.5, "model.11");/* ------ yolov5 head ------ */auto conv12 = convBlock(network, weightMap, *c3_11->getOutput(0), get_width(768, gw), 1, 1, 1, "model.12");auto upsample13 = network->addResize(*conv12->getOutput(0));assert(upsample13);upsample13->setResizeMode(ResizeMode::kNEAREST);upsample13->setOutputDimensions(c3_8->getOutput(0)->getDimensions());ITensor* inputTensors14[] = { upsample13->getOutput(0), c3_8->getOutput(0) };auto cat14 = network->addConcatenation(inputTensors14, 2);auto c3_15 = C3(network, weightMap, *cat14->getOutput(0), get_width(1536, gw), get_width(768, gw), get_depth(3, gd), false, 1, 0.5, "model.15");auto conv16 = convBlock(network, weightMap, *c3_15->getOutput(0), get_width(512, gw), 1, 1, 1, "model.16");auto upsample17 = network->addResize(*conv16->getOutput(0));assert(upsample17);upsample17->setResizeMode(ResizeMode::kNEAREST);upsample17->setOutputDimensions(c3_6->getOutput(0)->getDimensions());ITensor* inputTensors18[] = { upsample17->getOutput(0), c3_6->getOutput(0) };auto cat18 = network->addConcatenation(inputTensors18, 2);auto c3_19 = C3(network, weightMap, *cat18->getOutput(0), get_width(1024, gw), get_width(512, gw), get_depth(3, gd), false, 1, 0.5, "model.19");auto conv20 = convBlock(network, weightMap, *c3_19->getOutput(0), get_width(256, gw), 1, 1, 1, "model.20");auto upsample21 = network->addResize(*conv20->getOutput(0));assert(upsample21);upsample21->setResizeMode(ResizeMode::kNEAREST);upsample21->setOutputDimensions(c3_4->getOutput(0)->getDimensions());ITensor* inputTensors21[] = { upsample21->getOutput(0), c3_4->getOutput(0) };auto cat22 = network->addConcatenation(inputTensors21, 2);auto c3_23 = C3(network, weightMap, *cat22->getOutput(0), get_width(512, gw), get_width(256, gw), get_depth(3, gd), false, 1, 0.5, "model.23");auto conv24 = convBlock(network, weightMap, *c3_23->getOutput(0), get_width(256, gw), 3, 2, 1, "model.24");ITensor* inputTensors25[] = { conv24->getOutput(0), conv20->getOutput(0) };auto cat25 = network->addConcatenation(inputTensors25, 2);auto c3_26 = C3(network, weightMap, *cat25->getOutput(0), get_width(1024, gw), get_width(512, gw), get_depth(3, gd), false, 1, 0.5, "model.26");auto conv27 = convBlock(network, weightMap, *c3_26->getOutput(0), get_width(512, gw), 3, 2, 1, "model.27");ITensor* inputTensors28[] = { conv27->getOutput(0), conv16->getOutput(0) };auto cat28 = network->addConcatenation(inputTensors28, 2);auto c3_29 = C3(network, weightMap, *cat28->getOutput(0), get_width(1536, gw), get_width(768, gw), get_depth(3, gd), false, 1, 0.5, "model.29");auto conv30 = convBlock(network, weightMap, *c3_29->getOutput(0), get_width(768, gw), 3, 2, 1, "model.30");ITensor* inputTensors31[] = { conv30->getOutput(0), conv12->getOutput(0) };auto cat31 = network->addConcatenation(inputTensors31, 2);auto c3_32 = C3(network, weightMap, *cat31->getOutput(0), get_width(2048, gw), get_width(1024, gw), get_depth(3, gd), false, 1, 0.5, "model.32");/* ------ detect ------ */IConvolutionLayer* det0 = network->addConvolutionNd(*c3_23->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.33.m.0.weight"], weightMap["model.33.m.0.bias"]);IConvolutionLayer* det1 = network->addConvolutionNd(*c3_26->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.33.m.1.weight"], weightMap["model.33.m.1.bias"]);IConvolutionLayer* det2 = network->addConvolutionNd(*c3_29->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.33.m.2.weight"], weightMap["model.33.m.2.bias"]);IConvolutionLayer* det3 = network->addConvolutionNd(*c3_32->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.33.m.3.weight"], weightMap["model.33.m.3.bias"]);auto yolo = addYoLoLayer(network, weightMap, "model.33", std::vector<IConvolutionLayer*>{det0, det1, det2, det3});yolo->getOutput(0)->setName(OUTPUT_BLOB_NAME);network->markOutput(*yolo->getOutput(0));// Build enginebuilder->setMaxBatchSize(maxBatchSize);config->setMaxWorkspaceSize(16 * (1 << 20)); // 16MB
#if defined(USE_FP16)config->setFlag(BuilderFlag::kFP16);
#elif defined(USE_INT8)std::cout << "Your platform support int8: " << (builder->platformHasFastInt8() ? "true" : "false") << std::endl;assert(builder->platformHasFastInt8());config->setFlag(BuilderFlag::kINT8);Int8EntropyCalibrator2* calibrator = new Int8EntropyCalibrator2(1, INPUT_W, INPUT_H, "./coco_calib/", "int8calib.table", INPUT_BLOB_NAME);config->setInt8Calibrator(calibrator);
#endifstd::cout << "Building engine, please wait for a while..." << std::endl;ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);std::cout << "Build engine successfully!" << std::endl;// Don't need the network any morenetwork->destroy();// Release host memoryfor (auto& mem : weightMap){free((void*)(mem.second.values));}return engine;
}void APIToModel(unsigned int maxBatchSize, IHostMemory** modelStream, float& gd, float& gw, std::string& wts_name) {// Create builderIBuilder* builder = createInferBuilder(gLogger);IBuilderConfig* config = builder->createBuilderConfig();// Create model to populate the network, then set the outputs and create an engineICudaEngine* engine = build_engine(maxBatchSize, builder, config, DataType::kFLOAT, gd, gw, wts_name);assert(engine != nullptr);// Serialize the engine(*modelStream) = engine->serialize();// Close everything downengine->destroy();builder->destroy();config->destroy();
}void doInference(IExecutionContext& context, cudaStream_t& stream, void** buffers, float* input, float* output, int batchSize) {// DMA input batch data to device, infer on the batch asynchronously, and DMA output back to hostCUDA_CHECK(cudaMemcpyAsync(buffers[0], input, batchSize * 3 * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));context.enqueue(batchSize, buffers, stream, nullptr);CUDA_CHECK(cudaMemcpyAsync(output, buffers[1], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));cudaStreamSynchronize(stream);
}bool parse_args(int argc, char** argv, std::string& engine) {if (argc < 3) return false;if (std::string(argv[1]) == "-v" && argc == 3) {engine = std::string(argv[2]);}else {return false;}return true;
}int main(int argc, char** argv) {cudaSetDevice(DEVICE);//std::string wts_name = "";std::string engine_name = "";//float gd = 0.0f, gw = 0.0f;//std::string img_dir;if (!parse_args(argc, argv, engine_name)) {std::cerr << "arguments not right!" << std::endl;std::cerr << "./yolov5 -v [.engine] // run inference with camera" << std::endl;return -1;}std::ifstream file(engine_name, std::ios::binary);if (!file.good()) {std::cerr << " read " << engine_name << " error! " << std::endl;return -1;}char* trtModelStream{ nullptr };size_t size = 0;file.seekg(0, file.end);size = file.tellg();file.seekg(0, file.beg);trtModelStream = new char[size];assert(trtModelStream);file.read(trtModelStream, size);file.close();// prepare input data ---------------------------static float data[BATCH_SIZE * 3 * INPUT_H * INPUT_W];//for (int i = 0; i < 3 * INPUT_H * INPUT_W; i++)// data[i] = 1.0;static float prob[BATCH_SIZE * OUTPUT_SIZE];IRuntime* runtime = createInferRuntime(gLogger);assert(runtime != nullptr);ICudaEngine* engine = runtime->deserializeCudaEngine(trtModelStream, size);assert(engine != nullptr);IExecutionContext* context = engine->createExecutionContext();assert(context != nullptr);delete[] trtModelStream;assert(engine->getNbBindings() == 2);void* buffers[2];// In order to bind the buffers, we need to know the names of the input and output tensors.// Note that indices are guaranteed to be less than IEngine::getNbBindings()const int inputIndex = engine->getBindingIndex(INPUT_BLOB_NAME);const int outputIndex = engine->getBindingIndex(OUTPUT_BLOB_NAME);assert(inputIndex == 0);assert(outputIndex == 1);// Create GPU buffers on deviceCUDA_CHECK(cudaMalloc(&buffers[inputIndex], BATCH_SIZE * 3 * INPUT_H * INPUT_W * sizeof(float)));CUDA_CHECK(cudaMalloc(&buffers[outputIndex], BATCH_SIZE * OUTPUT_SIZE * sizeof(float)));// Create streamcudaStream_t stream;CUDA_CHECK(cudaStreamCreate(&stream));//#读取本地视频//cv::VideoCapture capture("/home/nano/Videos/video.mp4");//#调用本地usb摄像头,我的默认参数为1,如果1报错,可修改为0.cv::VideoCapture capture(0);if (!capture.isOpened()) {std::cout << "Error opening video stream or file" << std::endl;return -1;}int key;int fcount = 0;while (1){cv::Mat frame;capture >> frame;if (frame.empty()){std::cout << "Fail to read image from camera!" << std::endl;break;}fcount++;//if (fcount < BATCH_SIZE && f + 1 != (int)file_names.size()) continue;for (int b = 0; b < fcount; b++) {//cv::Mat img = cv::imread(img_dir + "/" + file_names[f - fcount + 1 + b]);cv::Mat img = frame;if (img.empty()) continue;cv::Mat pr_img = preprocess_img(img, INPUT_W, INPUT_H); // letterbox BGR to RGBint i = 0;for (int row = 0; row < INPUT_H; ++row) {uchar* uc_pixel = pr_img.data + row * pr_img.step;for (int col = 0; col < INPUT_W; ++col) {data[b * 3 * INPUT_H * INPUT_W + i] = (float)uc_pixel[2] / 255.0;data[b * 3 * INPUT_H * INPUT_W + i + INPUT_H * INPUT_W] = (float)uc_pixel[1] / 255.0;data[b * 3 * INPUT_H * INPUT_W + i + 2 * INPUT_H * INPUT_W] = (float)uc_pixel[0] / 255.0;uc_pixel += 3;++i;}}}// Run inferenceauto start = std::chrono::system_clock::now();//#获取模型推理开始时间doInference(*context, stream, buffers, data, prob, BATCH_SIZE);auto end = std::chrono::system_clock::now();//#结束时间//std::cout << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << std::endl;int fps = 1000.0 / std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();std::vector<std::vector<Yolo::Detection>> batch_res(fcount);for (int b = 0; b < fcount; b++) {auto& res = batch_res[b];nms(res, &prob[b * OUTPUT_SIZE], CONF_THRESH, NMS_THRESH);}for (int b = 0; b < fcount; b++) {auto& res = batch_res[b];//std::cout << res.size() << std::endl;//cv::Mat img = cv::imread(img_dir + "/" + file_names[f - fcount + 1 + b]);for (size_t j = 0; j < res.size(); j++) {cv::Rect r = get_rect(frame, res[j].bbox);cv::rectangle(frame, r, cv::Scalar(0x27, 0xC1, 0x36), 2);std::string label = my_classes[(int)res[j].class_id];cv::putText(frame, label, cv::Point(r.x, r.y - 1), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);std::string jetson_fps = "FPS: " + std::to_string(fps);cv::putText(frame, jetson_fps, cv::Point(11, 80), cv::FONT_HERSHEY_PLAIN, 3, cv::Scalar(0, 0, 255), 2, cv::LINE_AA);}//cv::imwrite("_" + file_names[f - fcount + 1 + b], img);}cv::imshow("yolov5", frame);key = cv::waitKey(1);if (key == 'q') {break;}fcount = 0;}capture.release();// Release stream and bufferscudaStreamDestroy(stream);CUDA_CHECK(cudaFree(buffers[inputIndex]));CUDA_CHECK(cudaFree(buffers[outputIndex]));// Destroy the enginecontext->destroy();engine->destroy();runtime->destroy();return 0;
}修改完后执行:
cd build
make
sudo ./yolov5 -v yolov5s.engine # 后面是自己生成的部署引擎文件
基于python的有时间了再弄
相关文章:
jetsonTX2 nx配置tensorRT加速yolov5推理
环境说明 Ubuntu 18conda环境python3.9cuda10.2,硬件平台是Jetson tx2 nx 前提你已经能运行YOLOV5代码后,再配置tensorRT进行加速。 目前只试了图片检测和C打开USB摄像头进行视频检测,希望是使用python配合D435i深度相机来实现检测ÿ…...

<<C++primer>>函数模板与类模板相关知识点整理
1.类型萃取的原理 类型萃取利用模板形参的推演方式使得类型去掉了引用性质: //消除引用,保留原始特性 //类型萃取 /// </summary> /// <param name"it"></param> template<class _Ty> struct my_remove_reference …...

一小时学习 Git 笔记
一小时Git教程传送门 git 基础 1. 起始配置 # 配置自己的姓名 git config --global user.name "Your Name" # 配置自己的邮箱 git config --global user.email "emailexample.com" 注意1.命令之间有空格2.上面的两个命令只需要运行一次即可, 如果输入错…...
简单漂亮的登录页面
效果图 说明 开发环境:vue3,sass 代码 <template><div class"container"><div class"card-container"><div class"card-left"><span><h1>Dashboard</h1><p>Lorem ip…...
Leetcode-145 二叉树的后序遍历
递归 /*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this…...

详解JDBC
JDBC简介 概念: jdbc就是使用java语言操作关系型数据库的一套API 全称 : (Java DataBase Connectivity) Java数据库连接 本质: 官方(sun公司)定义的一套操作所有关系型数据库的规则,即接口; 各个数据库厂商实现这套接口,提供数据库驱动j…...

江门車馬炮汽车金融中心 11月11日开张
江门车马炮汽车金融中心于11月11日正式开张,这是江门市汽车金融服务平台,旨在为广大车主提供更加便捷、高效的汽车金融服务。 江门市作为广东省的一个经济发达城市,汽车保有量持续增长,但车主在购车、用车、养车等方面仍存在诸多不…...

Arthas设置参数以Json形式输出
进入arthas控制台后,先输入options json-format true命令,即可让结果、参数以json的方式输出,比如之后用watch命令查看参数,输出的形式就会是json了,这样的格式,就比较好复制出参数,在本地复现试…...

优雅关闭TCP的函数shutdown效果展示
《TCP关闭的两种方法概述》里边理论基础,下边是列出代码,并且进行实验。 服务端代码graceserver.c的内容如下: #include "lib/common.h"static int count;static void sig_int(int signo) {printf("\nreceived %d datagrams\…...

商品管理幻灯图片更换实现
<?xml version"1.0" encoding"UTF-8" ?> <!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace"com.java1234.mapper.ProductMappe…...
tomcat下载与使用教程
1. tomcat下载 官网:https://tomcat.apache.org/ 镜像地址:https://mirrors.huaweicloud.com/apache/tomcat/ 1、选择一个版本下载,官网下载速度缓慢,推荐镜像 2、对压缩包进行解压,无需进行安装,解压放…...

通过 Elasticsearch 和 Go 使用混合搜索进行地鼠狩猎
作者:CARLY RICHMOND,LAURENT SAINT-FLIX 就像动物和编程语言一样,搜索也经历了不同实践的演变,很难在其中做出选择。 在本系列的最后一篇博客中,Carly Richmond 和 Laurent Saint-Flix 将关键字搜索和向量搜索结合起…...
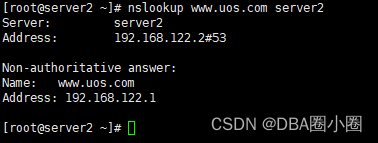
【LIUNX】配置缓存DNS服务
配置缓存DNS服务 A.安装bind bind-utils1.尝试修改named.conf配置文件2.测试nslookup B.修改named.conf配置文件1.配置文件2.再次测试 缓存DNS服务器:只提供域名解析结果的缓存功能,目的在于提高数据查询速度和效率,但是没有自己控制的区域地…...
)
Arduino驱动A01NYUB防水超声波传感器(超声波传感器)
目录 1、传感器特性 2、控制器和传感器连线图 3、通信协议 4、驱动程序 A01NYUB超声波测距传感器是一款通过发射和接收机械波来感应物体距离的电子传感器。该款产品具有监测距离远、范围广、防水等优点,且具有一定的穿透能力(烟雾、粉尘等)。该产品带有可拆卸式喇叭口,安…...

curl(八)时间和环境变量以及配置
一 时间 ① --connect-timeout 连接超时时间 ② -m | --max-time 数据最大传输时间 -m: 限制curl 完成时间(overall time limit)-m,--max-time <seconds> 整个交互完成的超时时间场景: 通过设置-m参数,可以避免请求时间过长而导致的超时错误…...
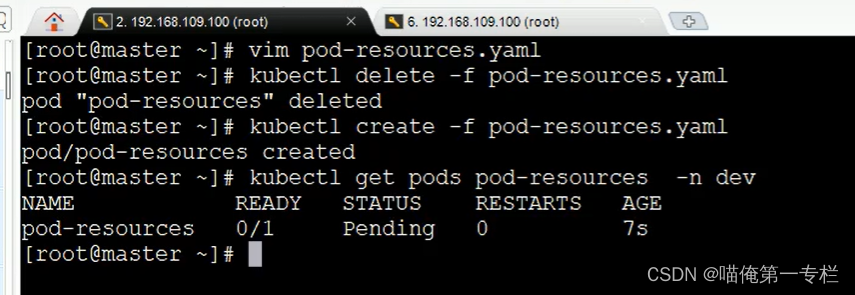
K8S知识点(十)
(1)Pod详解-启动命令 创建Pod,里面的两个容器都正常运行 (2)Pod详解-环境变量 (3)Pod详解-端口设置 (4)Pod详解-资源配额 修改:memory 不满足条件是不能正常…...
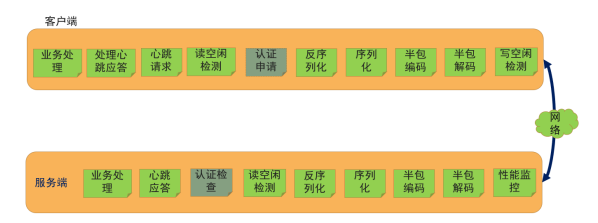
Netty实现通信框架
一、LengthFieldBasedFrameDecoder的参数解释 1、LengthFieldBasedFrameDecoder的构造方法参数 看下最多参数的构造方法 /*** Creates a new instance.** param byteOrder* the {link ByteOrder} of the length field* param maxFrameLength* the maximum len…...

【OpenCV实现图像:用OpenCV图像处理技巧之白平衡算法】
文章目录 概要加载样例图像统计数据分析White Patch Algorithm小结 概要 白平衡技术在摄影和图像处理中扮演着至关重要的角色。在不同的光照条件下,相机可能无法准确地捕捉到物体的真实颜色,导致图像呈现出暗淡、色调不自然或者褪色的效果。为了解决这个…...
文件包含 [ZJCTF 2019]NiZhuanSiWei1
打开题目 代码审计 if(isset($text)&&(file_get_contents($text,r)"welcome to the zjctf")){ 首先isset函数检查text参数是否存在且不为空 用file_get_contents函数读取text制定的文件内容并与welcome to the zjctf进行强比较 echo "<br><h…...

Java网络编程基础内容
IP地址 域名解析: 本机访问域名时,会从本地的DNS上解析数据(每个电脑都有),如果有,获取其对应的IP,通过IP访问服务器。如果本地没有,会去网络提供商的DNS找域名对应的IP࿰…...

小说下载器终极指南:一站式解决100+网站小说保存难题
小说下载器终极指南:一站式解决100网站小说保存难题 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,你是否曾因小说突然下架、网站404或网络中…...

CentOS 7下‘Development Tools’和‘开发工具’组有区别吗?实测告诉你答案
CentOS 7下‘Development Tools’与‘开发工具’的隐藏关联:技术细节全解析在Linux系统管理中,yum的软件包组功能一直是个既实用又充满谜团的领域。特别是当系统语言环境与软件包元数据语言不一致时,开发者们常常会遇到一个有趣的现象&#x…...
)
保姆级教程:在ROS2 Humble/Foxy的Gazebo中配置RGB-D相机(附解决点云颜色/坐标问题)
ROS2 Humble/Foxy中Gazebo深度相机仿真全攻略:从配置到点云问题解决在机器人仿真开发中,深度相机(RGB-D)是不可或缺的传感器之一。它能够同时提供彩色图像和深度信息,为SLAM、物体识别、避障等任务提供关键数据支持。本…...

League Akari:如何通过LCU API实现英雄联盟游戏流程的智能化管理?
League Akari:如何通过LCU API实现英雄联盟游戏流程的智能化管理? 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit Leag…...

Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间
Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾为Windows系统越来越慢而烦…...

大厂校招变了:AI 能力正在进入笔试和面试
最近不少同学投递校招时,应该已经发现一个变化: 以前 JD 里写的是“熟悉 Python / Java / SQL / Office 优先”。 现在越来越多岗位开始出现新的描述: “熟练使用 AI 工具者优先” “了解大模型应用者优先” “具备 AI 辅助编程经验优先” “…...

如何快速实现U盘文件自动备份:USBCopyer终极指南
如何快速实现U盘文件自动备份:USBCopyer终极指南 【免费下载链接】USBCopyer 😉 用于在插上U盘后自动按需复制该U盘的文件。”备份&偷U盘文件的神器”(写作USBCopyer,读作USBCopier) 项目地址: https://gitcode.…...

第十五章:Agent产品的监控与可观测性:如何构建“看得见、管得住“的AI系统
导读 想象一下:你上线了一个客服Agent,第一个月运行平稳。第二个月开始,你陆续收到用户投诉说"答案不对"。但你的监控系统显示:请求量正常、延迟正常、错误率正常。你打开日志,发现Agent确实"成功"处理了每个请求——只是它给错了答案。 这不是监控…...

Windows 11终极优化指南:Win11Debloat一键清理系统提升51%性能
Windows 11终极优化指南:Win11Debloat一键清理系统提升51%性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutte…...
功能才是宝藏)
Unity Cinemachine相机系统深度使用:除了自动跟随,它的边界限制(Confiner)功能才是宝藏
Unity Cinemachine Confiner:解锁专业级镜头边界控制的实战指南在游戏开发中,镜头控制往往是被低估的艺术。许多开发者对Cinemachine的印象停留在"智能跟随相机"层面,却不知道它的Confiner功能能够彻底改变游戏镜头的专业度。想象一…...