【Python数据挖掘入门】2.2文本分析-中文分词(jieba库cut方法/自定义词典load_userdict/语料库分词)
中文分词就是将一个汉字序列切分成一个一个单独的词。例如:

另外还有停用词的概念,停用词是指在数据处理时,需要过滤掉的某些字或词。

一、jieba库
安装过程见:https://blog.csdn.net/momomuabc/article/details/128198306
jieba库的基础与实例:https://blog.csdn.net/momomuabc/article/details/128219592
jieba库基础功能
1.分词函数jieba.cut
import jiebafor i in jieba.cut("我爱python"):print(i,end=' ')#利用end参数取消换行
--输出
我 爱 python
2.向词库添加词jieba.add_word()
如果想添加一些专业词汇进入词库,可以使用jieba.add_word()函数
例如:
import jiebaseg_list=jieba.cut("真武七截阵和天罡北斗阵哪个更厉害呢?")
for i in seg_list:print(i,end=" ")
--此时输出
真武 七截阵 和 天罡 北斗 阵 哪个 更 厉害 呢 ?
--可以看到真武七截阵和天罡北斗阵两个专业词汇被拆分开了,那么进行词组添加
jieba.add_word("真武七截阵")
jieba.add_word("天罡北斗阵")
seg_list=jieba.cut("真武七截阵和天罡北斗阵哪个更厉害呢?")
for i in seg_list:print(i,end=" ")
--再次输出后,可以看到真武七截阵和天罡北斗阵已经被识别为单独的词
真武七截阵 和 天罡北斗阵 哪个 更 厉害 呢 ?
3.导入词库jieba.load_userdict()
当需要大量导入专业词汇时,使用jieba.add_word()一个个添加会过于麻烦,可以使用jieba.load_userdict()方法将词库一次性导入。
词库中的单词需已每行一个词的方式保存,例如:

jieba.load_userdict("D:\\2.2 中文分词\\2.2\\金庸武功招式.txt")
二、文章分词
1.搭建语料库
上一节已经导入了语料库:https://blog.csdn.net/momomuabc/article/details/129183499
代码如下:
import os
import os.path#读取文件路径
import codecs#转换文件读取格式
import pandasfilePaths = []#设置存储文件路径的变量
fileContents = []#存储文件内容的变量
for root, dirs, files in os.walk("D:\SogouC.mini\Sample"):#os.walk()返回文件的目录,子目录,文件名,详情见上篇for name in files:filePath = os.path.join(root, name)#将目录和子目录拼接为目前的文件路径filePaths.append(filePath)#将文件路径存入路径变量f = codecs.open(filePath, "r", "utf-8")#以utf-8的格式打开当前路径下的文件fileContent = f.read()#读取文件内容f.close()#关闭文件fileContents.append(fileContent)#将文件内容存入内容变量
#将文件路径和内容存入DataFrame中
corpos=pandas.DataFrame({"filePath":filePaths,"fileContent":fileContents
}
)2.语料库分词
分词后需要注明,每个分词的来源,因此需要取上面的corpos对象里的filepath,并对filecontent进行分词。
import jieba
Path=[]
segments=[]
for index,row in corpos.iterrows():#返回corpos的内容filepath=row["filePath"]#取其中的filepath字段segs=jieba.cut(row["fileContent"])#取其中的filecontent字段,并进行分词for seg in segs:#将分词后的内容遍历segments.append(seg)#存入segmentsPath.append(filepath)#同时存储filepath
segmentDataFrame=pandas.DataFrame(#将分词结果存为数据框{"filepath":Path,"segment":segments}
)
iterrow()方法可以返回所有的行索引index,以及该行的所有内容row。
相关文章:
【Python数据挖掘入门】2.2文本分析-中文分词(jieba库cut方法/自定义词典load_userdict/语料库分词)
中文分词就是将一个汉字序列切分成一个一个单独的词。例如: 另外还有停用词的概念,停用词是指在数据处理时,需要过滤掉的某些字或词。 一、jieba库 安装过程见:https://blog.csdn.net/momomuabc/article/details/128198306 ji…...
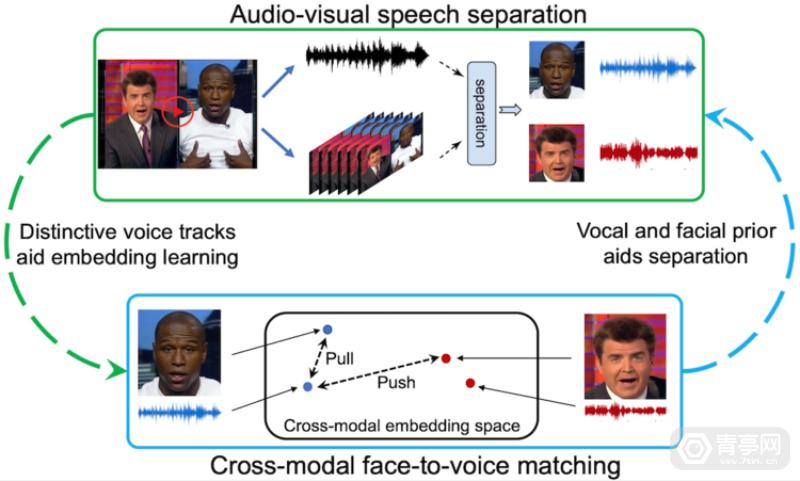
Meta利用视觉信息来优化3D音频模型,未来将用于AR/VR
我们知道,Meta为了给AR眼镜打造智能助手,专门开发了第一人称视觉模型和数据集。与此同时,该公司也在探索一种将视觉和语音融合的AI感知方案。相比于单纯的语音助手,同时结合视觉和声音数据来感知环境,可进一步增强智能…...
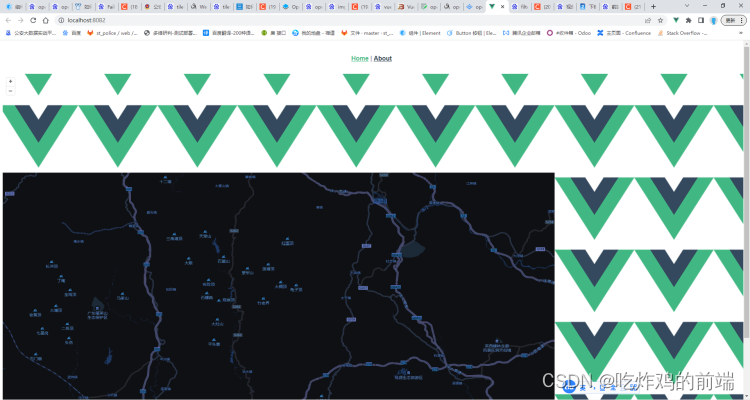
openlayers加载离线地图并实现深色地图
问题背景 我们自己一直使用的openlayergeoserver自己发布的地图,使用的是矢量地图。但是由于政府地图大都使用为天地图,所以需要将geoserver的矢量地图更改为天地图,并且依旧是搭配openlayers来使用。 解决步骤 一:加载离线地图&a…...

socket,tcp,http三者之间的区别和原理
目录 一、OSI模型也称七层网络模型 1、TCP/IP连接 1.1三次握手与四次挥手的简单理解:(面试重点) 1.2面试考题:如果已经建立了连接,但是客户端突然出现故障了怎么办? 1.3 socket、tcp、http三者之间有什…...

红日(vulnstack)1 内网渗透ATTCK实战
环境准备 靶机链接:百度网盘 请输入提取码 提取码:sx22 攻击机系统:kali linux 2022.03 网络配置: win7配置: kali配置: kali 192.168.1.108 192.168.111.129 桥接一块,自定义网卡4 win7 1…...

ik 分词器怎么调用缓存的词库
IK 分词器是一个基于 Java 实现的中文分词器,它支持在分词时调用缓存的词库。 要使用 IK 分词器调用缓存的词库,你需要完成以下步骤: 创建 IK 分词器实例 首先,你需要创建一个 IK 分词器的实例。可以通过以下代码创建一个 IK 分…...
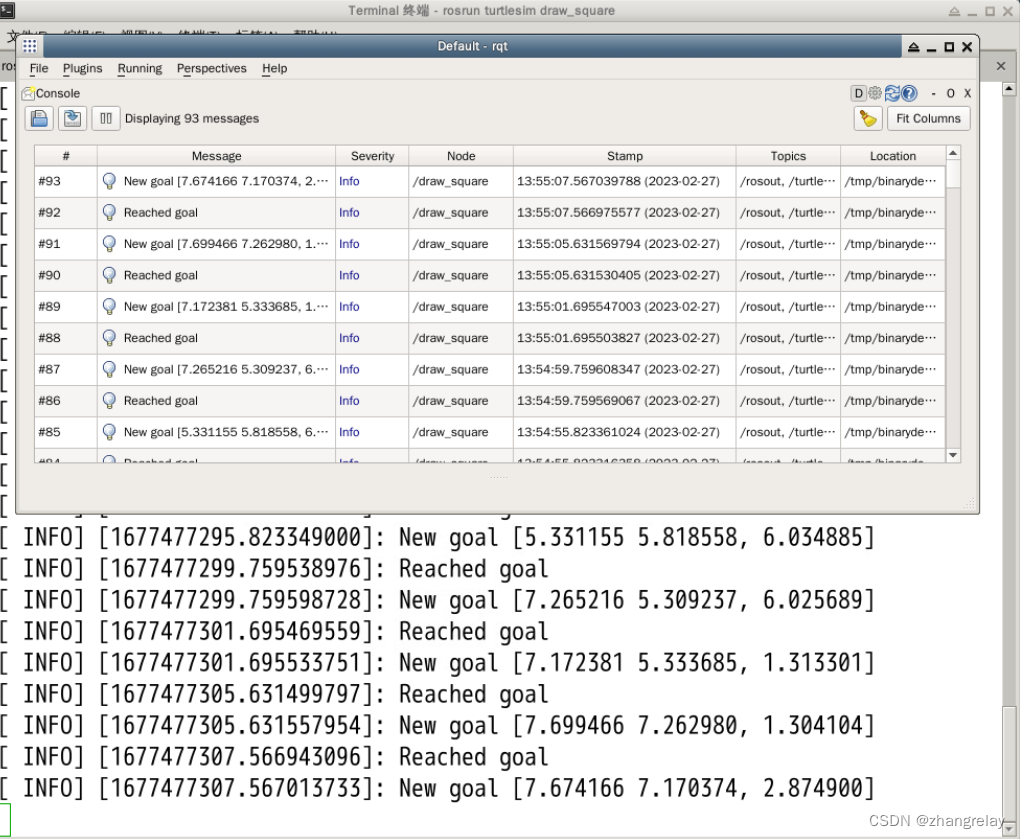
ROS1/2机器人操作系统与时间Time的不解之缘
时间对于机器人操作系统非常重要。所有机器人类的编程中所涉及的变量如果需要在网络中传输都需要这个数据结构的时间戳。宏观上,ROS1、ROS2各版本都有官方支持的时间节点。ROS时钟--支持时间倒计时小工具效果如下:如果要部署机器人操作系统,R…...
)
华为OD机试真题2022(JAVA)
华为机试题库已换 →→→ 华为OD机试2023(JAVA) 以下题目为旧版题库,供大家课外消遣 基础题: 序号题目分值1查找众数及中位数1002出错的或电路1003连续字母长度1004分班1005计算面积1006最远足迹1007判断一组不等式是否满足约束…...
【3】MyBatis+Spring+SpringMVC+SSM整合一套通关
三、SpringMVC 1、SpringMVC简介 1.1、什么是MVC MVC是一种软件架构的思想,将软件按照模型、视图、控制器来划分 M:Model,模型层,指工程中的JavaBean,作用是处理数据 JavaBean分为两类: 一类称为实体…...
)
20道前端高频面试题(附答案)
ES6新特性 1.ES6引入来严格模式变量必须声明后在使用函数的参数不能有同名属性, 否则报错不能使用with语句 (说实话我基本没用过)不能对只读属性赋值, 否则报错不能使用前缀0表示八进制数,否则报错 (说实话我基本没用过)不能删除不可删除的数据, 否则报错不能删除变量delete p…...
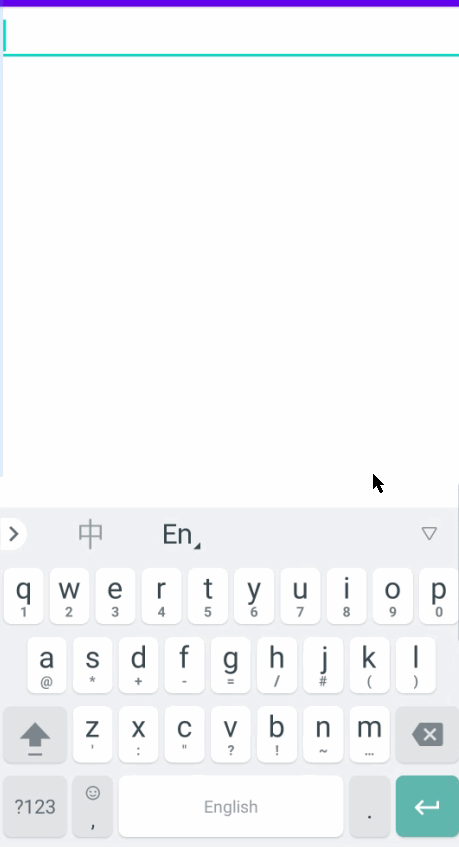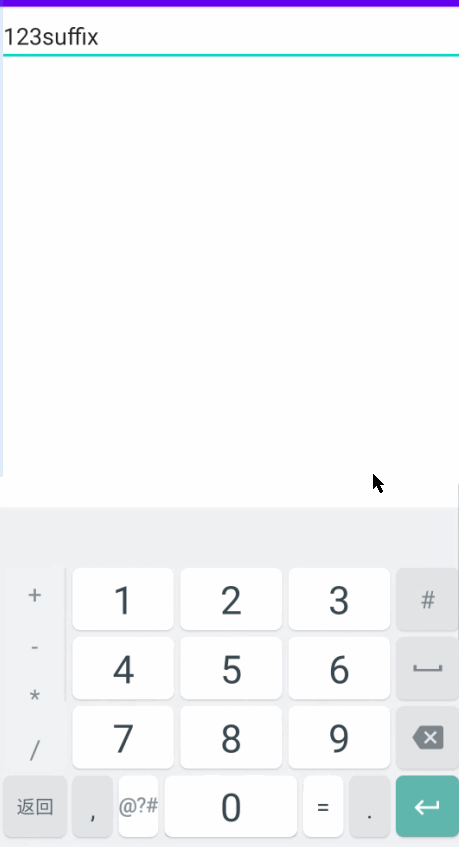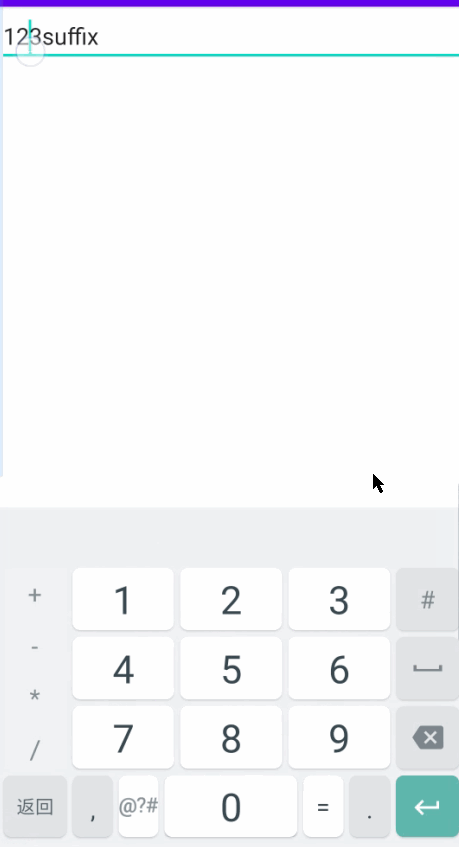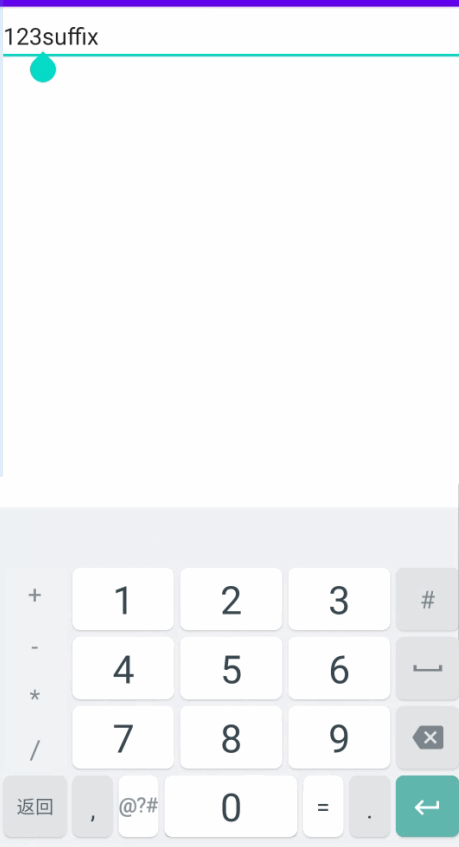
android EditText设置后缀
有两种实现方案。 方案一:是自己写一个TextWatcher。 方案二:是重写TextView的getOffsetForPosition方法,返回一个计算好的offset。 我在工作时,使用的是方案一。在离职之后,我还是对这个问题耿耿于怀,所以…...
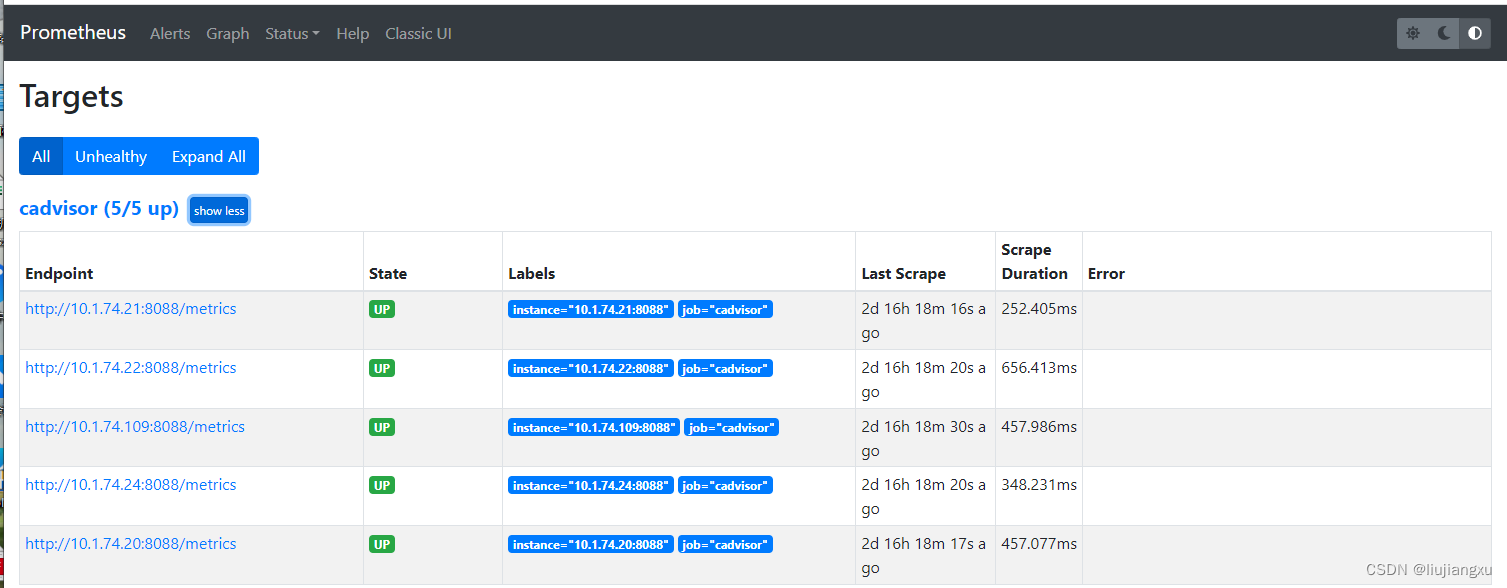
prometheus+cadvisor监控docker
官方解释 cAdvisor(ContainerAdvisor)为容器用户提供了对其运行容器的资源使用和性能特性的了解。它是一个正在运行的守护程序,用于收集、聚合、处理和导出有关正在运行的容器的信息。具体来说,它为每个容器保存资源隔离参数、历史…...
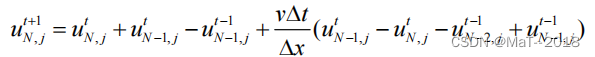
正演(1): 二维声波正演模拟程序(中心差分)Python实现
目录 1、原理: 1)二维声波波动方程: 编辑 2)收敛条件(不是很明白) 3)雷克子波 4)二维空间衰减函数 5)边界吸收条件 (不是很明白。。) 2、编程实现 1)参数设置&…...

珠海数据智能监控器+SaaS平台 轻松实现SMT生产管控
数据智能监控器 兼容市面上99%的SMT设备 直接读取设备生产数据与状态,如:计划产出、实际产出、累计产出、停机、节拍、线利用率、直通率、停产时间、工单状态、OEE…… 产品功能价值 ◎ OEE不达标报警,一手掌握生产效能 ◎ 首检/巡检/成…...

习题22对前面21节的归纳总结
笨方法学python --习题22 Vi---Rum 于 2021-01-12 14:16:10 发布 python 习题22 这节内容主要是归纳总结 ex1.py 第一次学习 1.print:打印 2.# :是注释的意思,井号右边的内容不再执行 3.end"":,在句子结尾加上这个就不会再换行…...

使用Vite快速构建前端React项目
一、Vite简介 Vite是一种面向现代浏览器的一个更轻、更快的前端构建工具,能够显著提升前端开发体验。除了Vite外,前端著名的构建工具还有Webpack和Gulp。目前,Vite已经发布了Vite3,Vite全新的插件架构、丝滑的开发体验,可以和Vue3完美结合。 相比Webpack和Gulp等构建工具…...

人工智能高等数学--人工智能需要的数学知识_微积分_线性代数_概率论_最优化---人工智能工作笔记0024
然后我们看一下人工智能中需要的数学知识 数学知识是重要的,对于理解人工智能底层原理来说很重要,但是工作中 工作中一般都不会涉及的自己写算法之类的,只是面试,或者理解底层原理的时候需要 然后看一下人工智能需要哪些数学知识 这里需要微积分 线性代数 概率论 最优化的知识…...
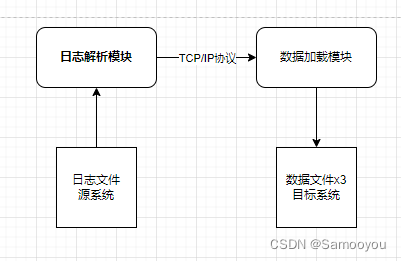
阿里大数据之路总结
一、数据采集 二、数据同步 2.1、数据同步方式: 数据同步的三种方式:直连方式、数据文件同步、数据库日志解析方式 关系型数据库的结构化数据:MYSQL、Oracle、DB2、SQL Server非关系型数据库的非结构化数据(数据库表形式存储&am…...
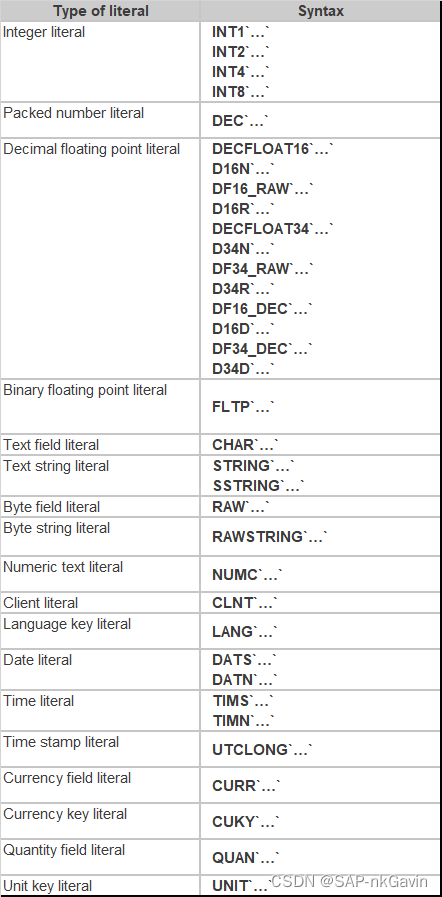
ABAP中Literals的用法(untyped literal vs. typed literal)
1. 什么是Literals ? Literals的字面意思即“文字”。其实,Literals就是在ABAP代码中直接指定的一个字符串,但注意哦,这个字符串并不意味着其类型一定是string哦。 要弄清这个概念,就要清楚ABAP对于Literals 的定义和处理方式。…...

tensorflow1.14.0安装教程
1首先电脑安装好Anaconda3(Anaconda介绍、安装及使用教程 - 知乎 (zhihu.com),) 蟒蛇 |全球最受欢迎的数据科学平台 (anaconda.com) 2打开Anaconda Prompt(本人更新win11后,主菜单不再显示,那么我们可以打…...

如何快速实现NCM文件批量转换:ncmdumpGUI完整使用指南
如何快速实现NCM文件批量转换:ncmdumpGUI完整使用指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否下载了网易云音乐却发现文件是NCM格式…...

技术创始人如何选择CEO:谦逊、互补与权力交接的艺术
1. 从技术专家到掌舵者:CEO角色转变的深层逻辑 在EDA(电子设计自动化)和半导体设计这个高度技术驱动的领域里,创业公司的故事每天都在上演。你可能会在DAC(设计自动化大会)上看到上百家初创公司,…...
)
若依框架实战:参数验证异常处理(手机号码格式验证案例)
一、前言在后端开发中,参数校验是保证接口健壮性的第一道防线。若依(Ruoyi)框架作为主流的 Java 后台管理系统框架,内置了完善的参数验证与全局异常处理机制。本文将以用户管理模块的手机号码格式验证为例,从触发验证、…...

JSON数据高效处理:命令行工具jsoncut的查询、过滤与投影实战
1. 项目概述:一个专为JSON数据“瘦身”的利器在前后端开发、API接口调试、数据迁移或者日志分析的日常工作中,JSON格式的数据几乎无处不在。它结构清晰、易于阅读和解析,是现代数据交换的绝对主力。但随之而来的一个常见痛点就是:…...

GTA5线上小助手:终极免费工具完整使用指南,快速提升游戏体验
GTA5线上小助手:终极免费工具完整使用指南,快速提升游戏体验 【免费下载链接】GTA5OnlineTools GTA5线上小助手 项目地址: https://gitcode.com/gh_mirrors/gt/GTA5OnlineTools 想要在《侠盗猎车手5》线上模式中摆脱繁琐操作,享受更流…...

避开BUUCTF《Life on Mars》的思维陷阱:当information_schema查询结果‘不对劲’时,你的排查清单应该有哪些?
破解BUUCTF《Life on Mars》的数据库迷局:当information_schema说谎时的七种侦查策略 在CTF赛场上,SQL注入类题目往往不会按教科书上的剧本发展。当你在BUUCTF《Life on Mars》这道题中执行group_concat(database()) from information_schema.schemata却…...

SAPO Ink UI组件实战:10个常用交互组件快速上手
SAPO Ink UI组件实战:10个常用交互组件快速上手 【免费下载链接】Ink An HTML5/CSS3 framework used at SAPO for fast and efficient website design and prototyping 项目地址: https://gitcode.com/gh_mirrors/ink2/Ink SAPO Ink是一个由SAPO开发的HTML5/…...
复现论文:Landsat8波段组合如何影响土地覆盖分类精度?)
用Google Earth Engine (GEE)复现论文:Landsat8波段组合如何影响土地覆盖分类精度?
基于Google Earth Engine的Landsat8波段组合优化实验:从理论到实践 在遥感影像分析领域,波段选择一直是影响分类精度的关键因素。传统方法往往直接使用所有可用波段作为输入特征,却忽视了波段间可能存在的冗余信息。本文将通过Google Earth E…...

RISC-V汽车电子开发:功能安全认证工具链的挑战与实践
1. 项目概述:RISC-V在汽车领域的破局与挑战最近和几个在主机厂和Tier 1做嵌入式开发的老朋友聊天,话题总绕不开芯片选型和开发工具。大家普遍的感觉是,传统的Arm架构虽然生态成熟,但在追求极致能效比和定制化的今天,成…...

从DataOperation接口到QuickSort实现:探究适配器模式在算法整合中的应用
1. 适配器模式:解决接口不兼容的桥梁 想象一下你从国外带回来一个三脚插头的电器,但家里的插座都是两孔的。这时候你会怎么做?大多数人会选择买一个转换插头。在编程世界里,适配器模式就是这个万能的"转换插头"。 最近我…...