卷积神经网络(1)
目录
卷积
1 自定义二维卷积算子
2 自定义带步长和零填充的二维卷积算子
3 实现图像边缘检测
4 自定义卷积层算子和汇聚层算子
4.1 卷积算子
4.2 汇聚层算子
5 学习torch.nn.Conv2d()、torch.nn.MaxPool2d();torch.nn.avg_pool2d(),简要介绍使用方法。
6 分别用自定义卷积算子和torch.nn.Conv2d()编程实现下面的卷积运算
总结
卷积
考虑到使用全连接前馈网络来处理图像时,会出现如下问题:
1. 模型参数过多,容易发生过拟合。在全连接前馈网络中,隐藏层的每个神经元都要跟该层所有输入的神经元相连接。随着隐藏层神经元数量的增多,参数的规模也会急剧增加,导致整个神经网络的训练效率非常低,也很容易发生过拟合。
2. 难以提取图像中的局部不变性特征。 自然图像中的物体都具有局部不变性特征,比如尺度缩放、平移、旋转等操作不影响其语义信息。而全连接前馈网络很难提取这些局部不变性特征。
卷积神经网络有三个结构上的特性:局部连接、权重共享和汇聚。这些特性使得卷积神经网络具有一定程度上的平移、缩放和旋转不变性。和前馈神经网络相比,卷积神经网络的参数也更少。因此,通常会使用卷积神经网络来处理图像信息。
卷积是分析数学中的一种重要运算,常用于信号处理或图像处理任务。本节以二维卷积为例来进行实践。
1 自定义二维卷积算子
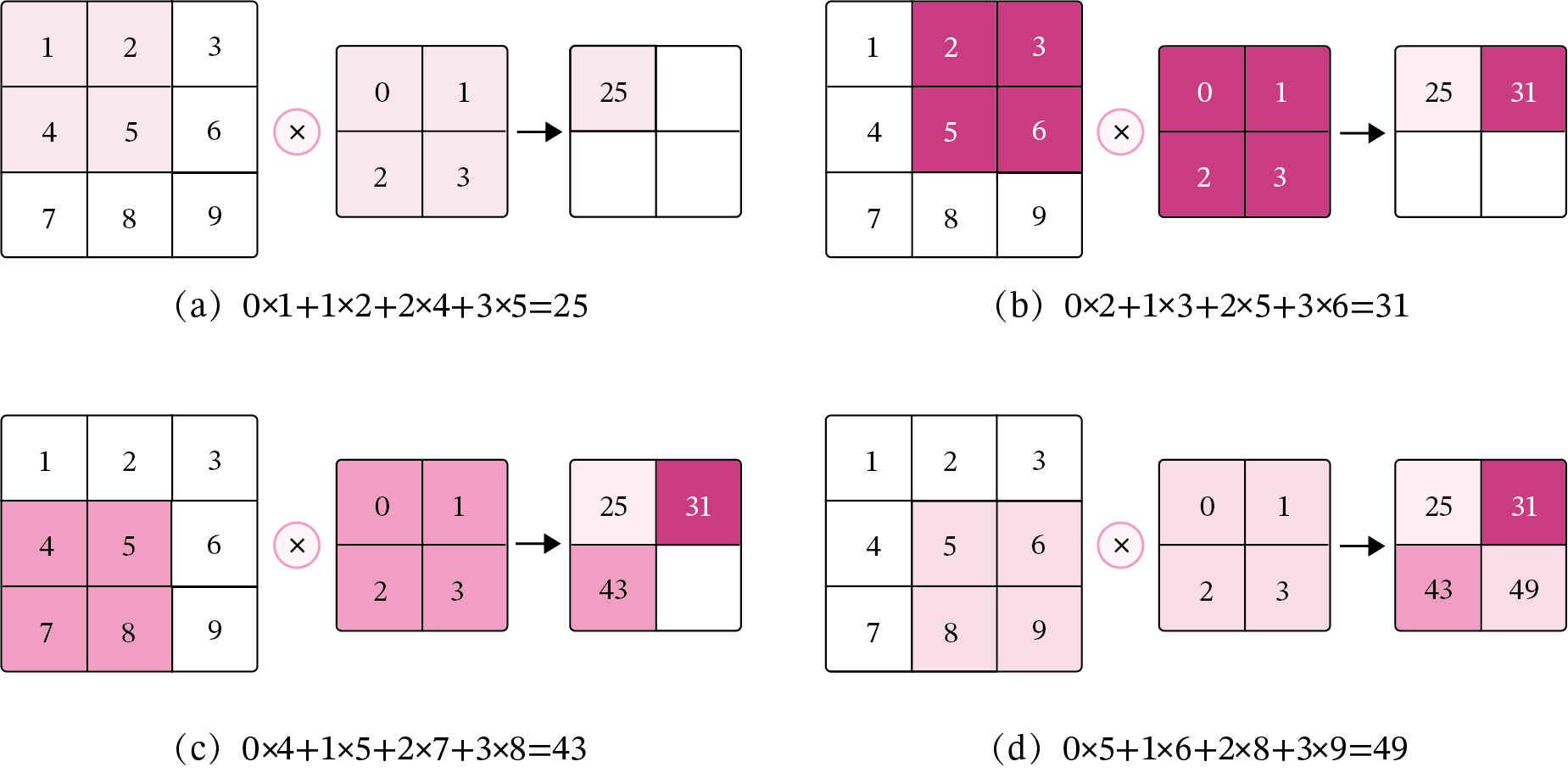
在机器学习和图像处理领域,卷积的主要功能是在一个图像(或特征图)上滑动一个卷积核,通过卷积操作得到一组新的特征。在计算卷积的过程中,需要进行卷积核的翻转,而这也会带来一些不必要的操作和开销。因此,在具体实现上,一般会以数学中的互相关(Cross-Correlatio)运算来代替卷积。
在神经网络中,卷积运算的主要作用是抽取特征,卷积核是否进行翻转并不会影响其特征抽取的能力。特别是当卷积核是可学习的参数时,卷积和互相关在能力上是等价的。因此,很多时候,为方便起见,会直接用互相关来代替卷积。
在本案例之后的描述中,除非特别声明,卷积一般指“互相关”。
对于一个输入矩阵![]() 和一个滤波器
和一个滤波器![]() ,他们的卷积为:
,他们的卷积为:
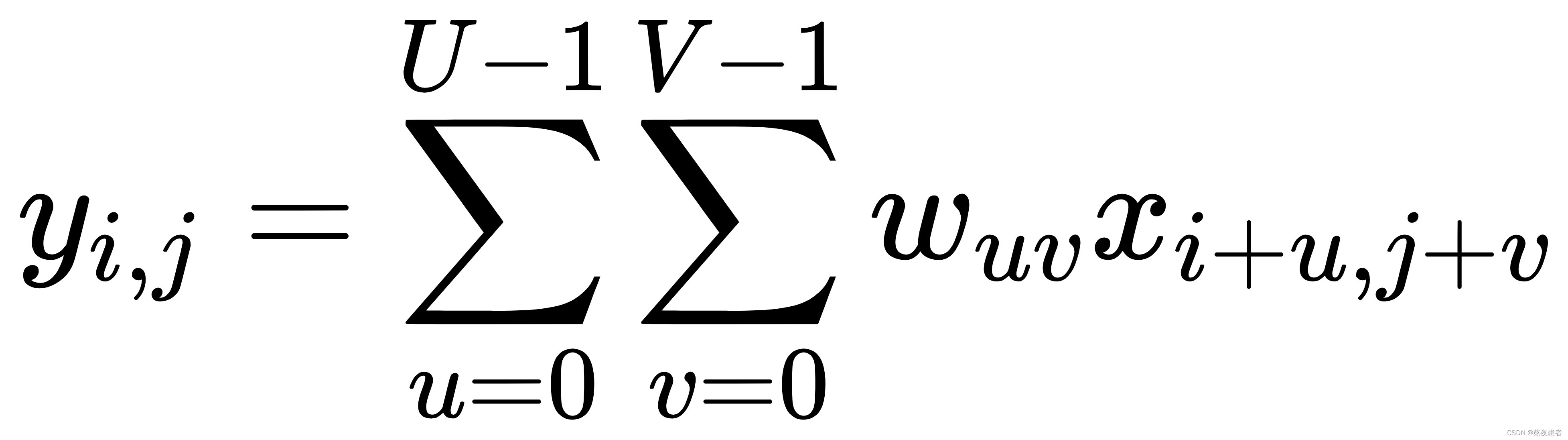
此时图片的输出大小为:
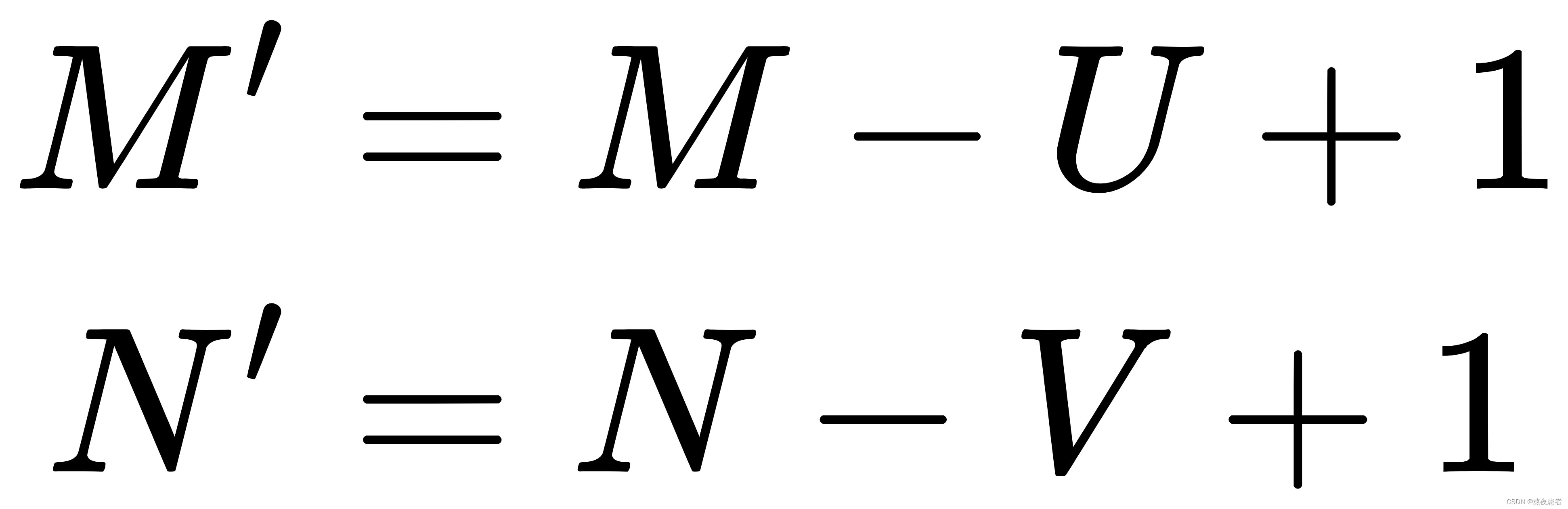
计算量为:
![]()
import torch
import numpy as np
import torch.nn as nnclass Conv2D(nn.Module):def __init__(self, kernel_size, stride=1, padding=0, ):super(Conv2D, self).__init__()w = torch.tensor(np.array([[0., 1.], [2., 3.]], dtype='float32').reshape([kernel_size, kernel_size]))self.weight = torch.nn.Parameter(w, requires_grad=True)def forward(self, X):"""输入:- X:输入矩阵,shape=[B, M, N],B为样本数量输出:- output:输出矩阵"""u, v = self.weight.shapeoutput = torch.zeros([X.shape[0], X.shape[1] - u + 1, X.shape[2] - v + 1])for i in range(output.shape[1]):for j in range(output.shape[2]):output[:, i, j] = torch.sum(X[:, i:i + u, j:j + v] * self.weight, dim=[1, 2])return output# 随机构造一个二维输入矩阵inputs = torch.tensor([[[1., 2., 3.], [4., 5., 6.], [7., 8., 9.]]])
conv2d = Conv2D(kernel_size=2)
outputs = conv2d(inputs)
print("input: {}, \noutput: {}".format(inputs, outputs))

2 自定义带步长和零填充的二维卷积算子
在计算卷积时,可以在所有维度上每间隔个元素计算一次,
称为卷积运算的步长(Stride),也就是卷积核在滑动时的间隔。
在二维卷积运算中,零填充(Zero Padding)是指在输入矩阵周围对称地补上个
。
对于一个输入矩阵和一个滤波器
,,步长为
,对输入矩阵进行零填充,那么最终输出矩阵大小则为

计算量为:
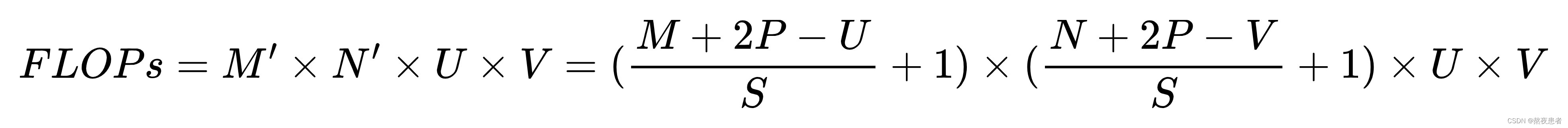
一般常用的卷积有三种:
1. 窄卷积:步长,两端不补零
,卷积后输出尺寸为:
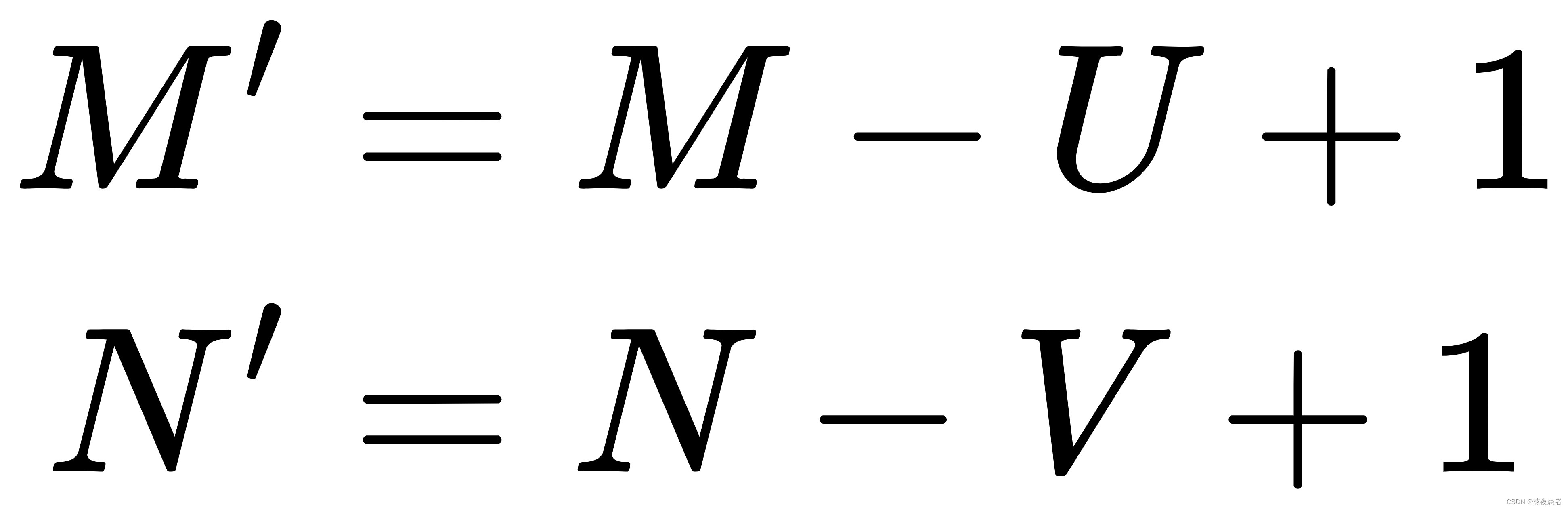
2. 宽卷积:步长,两端补零
,卷积后输出尺寸为:
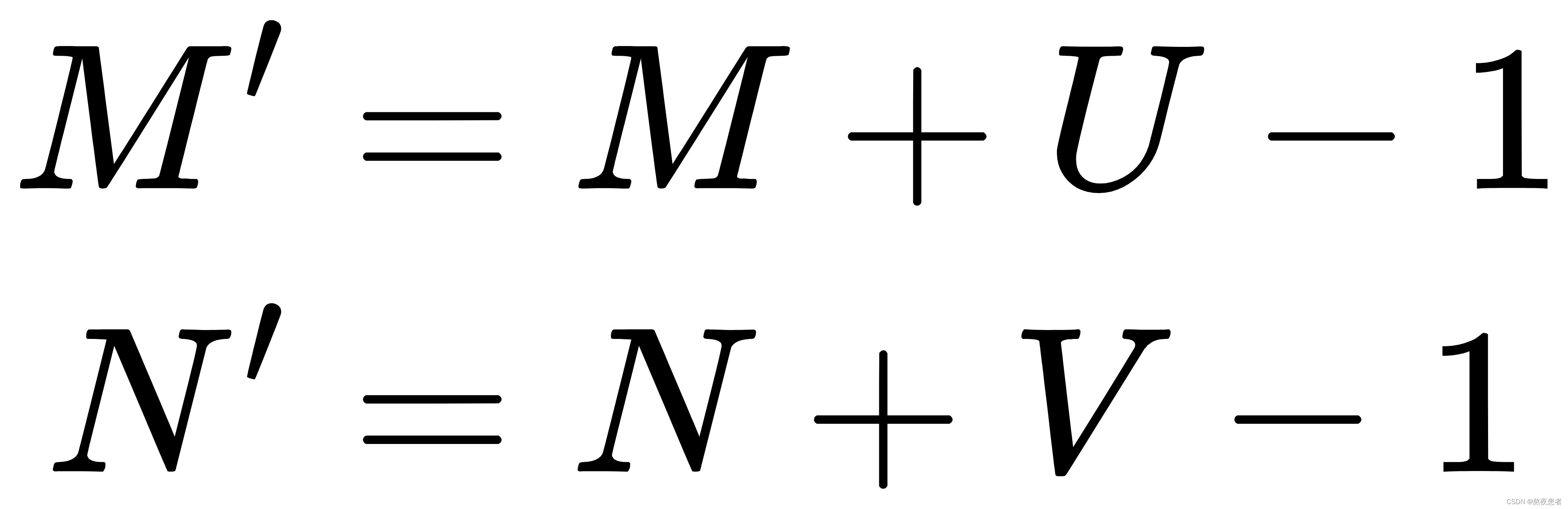
3. 等宽卷积:步长,两端补零
,卷积后输出尺寸为:

import torch
import numpy as np
import torch.nn as nnclass Conv2D(nn.Module):def __init__(self, kernel_size, stride=1, padding=0, ):super(Conv2D, self).__init__()w = torch.tensor(np.array([[1., 1., 1.], [1., 1., 1.], [1., 1., 1.]], dtype='float32').reshape([kernel_size, kernel_size]))self.weight = torch.nn.Parameter(w, requires_grad=True)# 步长self.stride = stride# 零填充self.padding = paddingdef forward(self, X):"""输入:- X:输入矩阵,shape=[B, M, N],B为样本数量输出:- output:输出矩阵"""new_X = torch.zeros([X.shape[0], X.shape[1] + 2 * self.padding, X.shape[2] + 2 * self.padding]) # 创建一个M'*N'的零矩阵new_X[:, self.padding:X.shape[1] + self.padding, self.padding:X.shape[2] + self.padding] = X # 将原数据放回u, v = self.weight.shapeoutput_w = (new_X.shape[1] - u) // self.stride + 1output_h = (new_X.shape[2] - v) // self.stride + 1output = torch.zeros([X.shape[0], output_w, output_h])for i in range(0, output.shape[1]):for j in range(0, output.shape[2]):output[:, i, j] = torch.sum(new_X[:, self.stride * i:self.stride * i + u, self.stride * j:self.stride * j + v] * self.weight,dim=[1, 2])return output# 随机构造一个二维输入矩阵inputs = torch.randn([2, 8, 8])
conv2d_padding = Conv2D(kernel_size=3, padding=1)
outputs = conv2d_padding(inputs)
print("When kernel_size=3, padding=1 stride=1, input's shape: {}, output's shape: {}".format(inputs.shape, outputs.shape))
conv2d_stride = Conv2D(kernel_size=3, stride=2, padding=1)
outputs = conv2d_stride(inputs)
print("When kernel_size=3, padding=1 stride=2, input's shape: {}, output's shape: {}".format(inputs.shape, outputs.shape))

从输出结果看出,使用大小卷积,padding为1,当stride=1时,模型的输出特征图可以与输入特征图保持一致;当stride=2时,输出特征图的宽和高都缩小一倍。
3 实现图像边缘检测
在图像处理任务中,常用拉普拉斯算子对物体边缘进行提取,拉普拉斯算子为一个大小为的卷积核,中心元素值是
,其余元素值是
。
考虑到边缘其实就是图像上像素值变化很大的点的集合,因此可以通过计算二阶微分得到,当二阶微分为0时,像素值的变化最大。此时,对方向和
方向分别求取二阶导数:
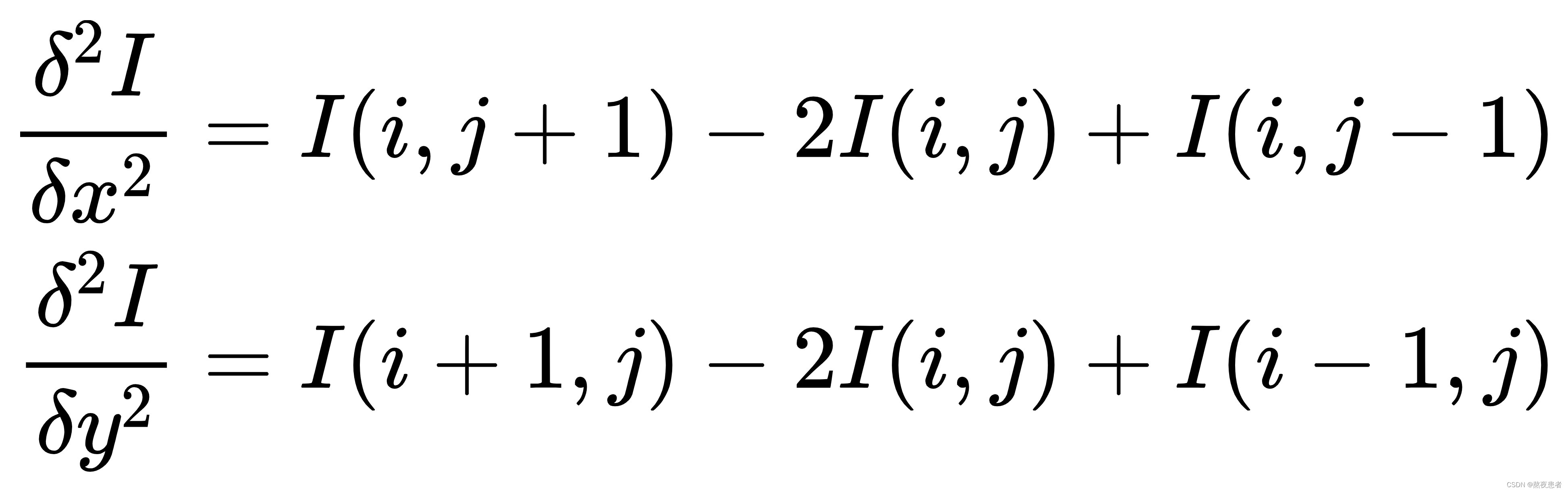
完整的二阶微分公式为:
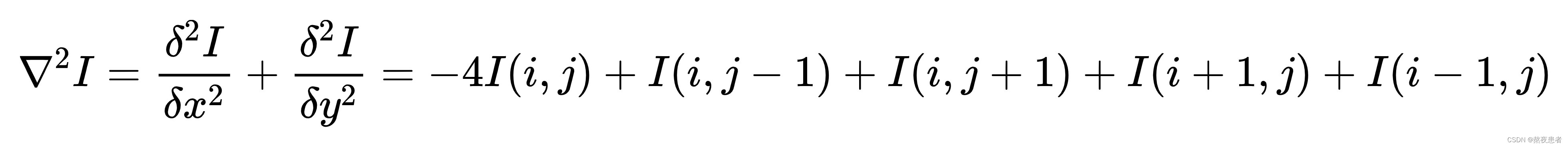
上述公式也被称为拉普拉斯算子,对应的二阶微分卷积核为:
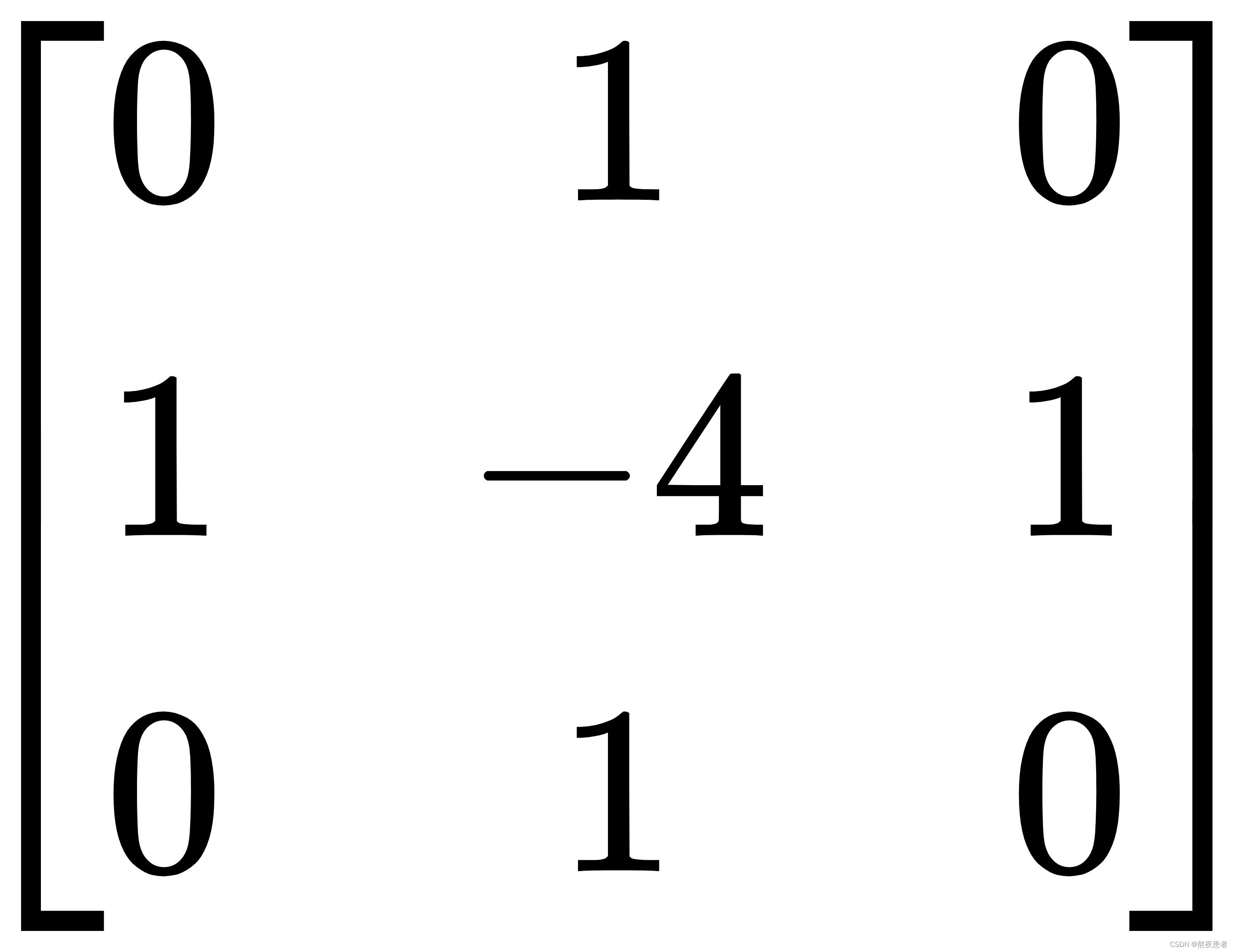
对上述算子全部求反也可以起到相同的作用,此时,该算子可以表示为:
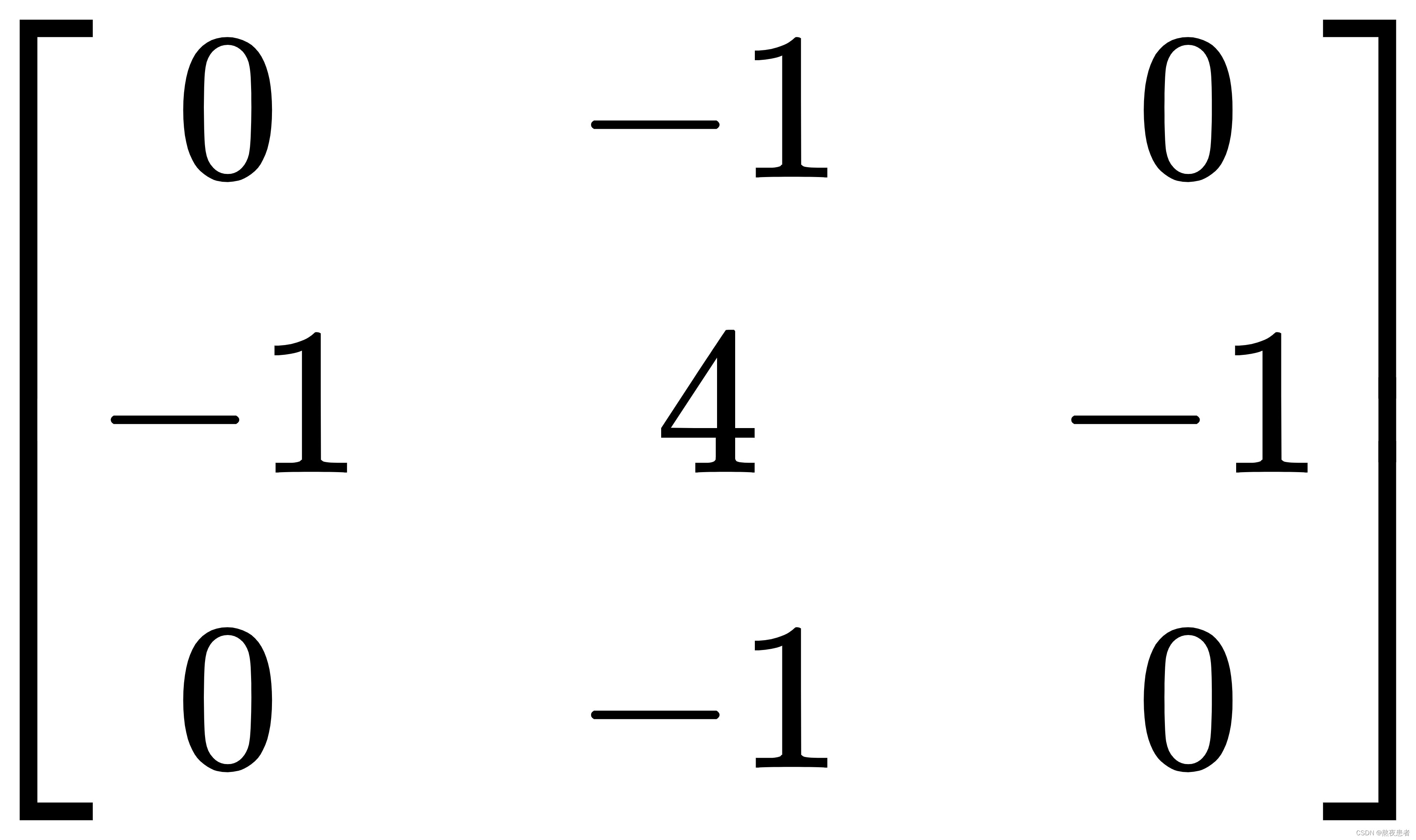
也就是一个点的四邻域拉普拉斯的算子计算结果是自己像素值的四倍减去上下左右的像素的和,将这个算子旋转后与原算子相加,就变成八邻域的拉普拉斯算子,也就是一个像素自己值的八倍减去周围一圈八个像素值的和,做为拉普拉斯计算结果,此时,该算子可以表示为:

代码如下:
import torchimport matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import torch.nn as nnclass Conv2d(nn.Module):def __init__(self, kernel_size, stride=1, padding=0):super(Conv2d, self).__init__()# 设置卷积核参数w = np.array([[-1, -1, -1], [-1, 8, -1], [-1, -1, -1]], dtype='float32').reshape((3, 3))w = torch.from_numpy(w)self.weight = torch.nn.Parameter(w, requires_grad=True)self.stride = strideself.padding = paddingdef forward(self, X):# 零填充new_X = torch.zeros([X.shape[0], X.shape[1] + 2 * self.padding, X.shape[2] + 2 * self.padding])new_X[:, self.padding:X.shape[1] + self.padding, self.padding:X.shape[2] + self.padding] = Xu, v = self.weight.shapeoutput_w = (new_X.shape[1] - u) // self.stride + 1output_h = (new_X.shape[2] - v) // self.stride + 1output = torch.zeros([X.shape[0], output_w, output_h])for i in range(0, output.shape[1]):for j in range(0, output.shape[2]):output[:, i, j] = torch.sum(new_X[:, self.stride * i:self.stride * i + u, self.stride * j:self.stride * j + v] * self.weight,dim=[1, 2])return output# 读取图片
img = Image.open('OIP-C.jpg').convert('L')
inputs = np.array(img, dtype='float32')
# 创建卷积算子,卷积核大小为3x3,并使用上面的设置好的数值作为卷积核权重的初始化参数
conv = Conv2d(kernel_size=3, stride=1, padding=0)
print("bf to_tensor, inputs:", inputs)
# 将图片转为Tensor
inputs = torch.tensor(inputs)
print("bf unsqueeze, inputs:", inputs)
inputs = torch.unsqueeze(inputs, dim=0)
print("af unsqueeze, inputs:", inputs)
outputs = conv(inputs)
print(outputs)
# 可视化结果
plt.figure(figsize=(8, 4))
f = plt.subplot(121)
f.set_title('input image', fontsize=15)
plt.imshow(img)
f = plt.subplot(122)
f.set_title('output feature map', fontsize=15)
plt.imshow(outputs.squeeze().detach().numpy(), cmap='gray')
plt.show()

4 自定义卷积层算子和汇聚层算子
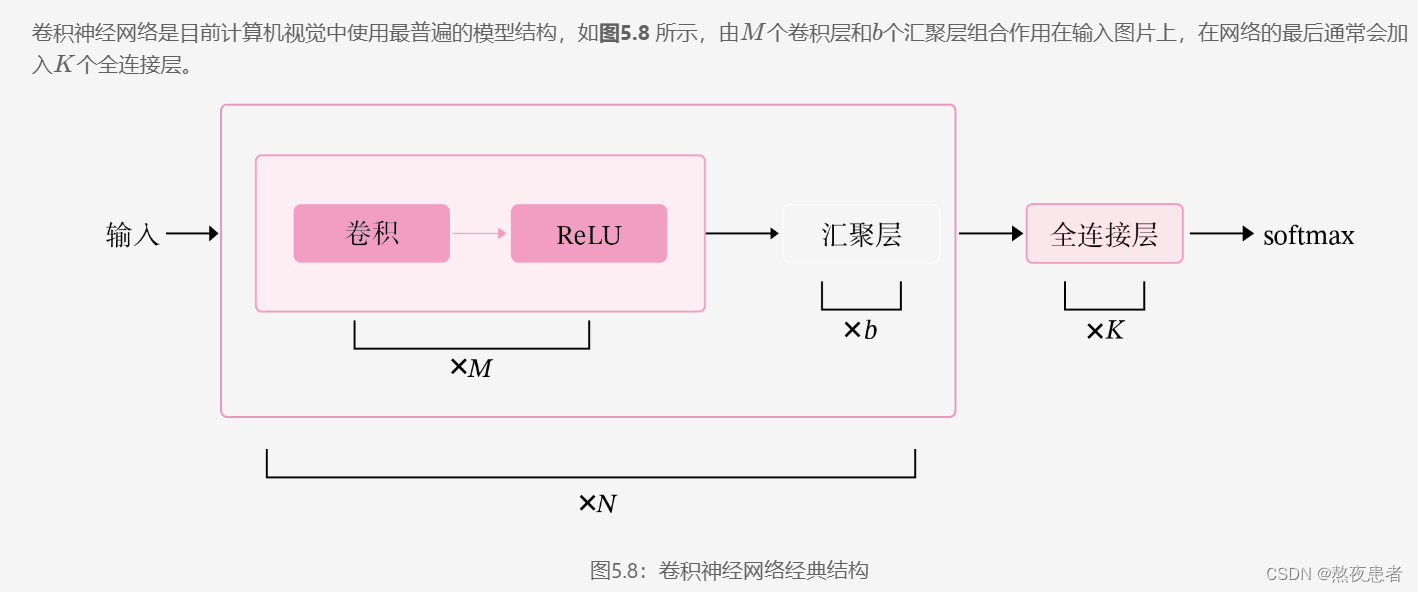
从上图可以看出,卷积网络是由多个基础的算子组合而成。下面我们先实现卷积网络的两个基础算子:卷积层算子和汇聚层算子。
4.1 卷积算子
卷积层是指用卷积操作来实现神经网络中一层。为了提取不同种类的特征,通常会使用多个卷积核一起进行特征提取。
在前面介绍的二维卷积运算中,卷积的输入数据是二维矩阵。但实际应用中,一幅大小为的图片中的每个像素的特征表示不仅仅只有灰度值的标量,通常有多个特征,可以表示为
维的向量,比如RGB三个通道的特征向量。因此,图像上的卷积操作的输入数据通常是一个三维张量,分别对应了图片的高度
、宽度
和深度
,其中深度
通常也被称为输入通道数
。如果输入如果是灰度图像,则输入通道数为1;如果输入是彩色图像,分别有
三个通道,则输入通道数为3。
此外,由于具有单个核的卷积每次只能提取一种类型的特征,即输出一张大小为的特征图(Feature Map)。而在实际应用中,我们也希望每一个卷积层能够提取多种不同类型的特征,所以一个卷积层通常会组合多个不同的卷积核来提取特征,经过卷积运算后会输出多张特征图,不同的特征图对应不同类型的特征。输出特征图的个数通常将其称为输出通道数
。
PS:假设一个卷积层的输入特征图,其中
为特征图的尺寸,
代表通道数;卷积核为
,其中
为卷积核的尺寸,
代表输入通道数,
代表输出通道数。

多张输出特征图的计算,如下图所示,具体的对这个不明确的可以翻翻我之前的博客,对这个解释的比较详细.
class Conv2D(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):super(Conv2D, self).__init__()# 创建卷积核weight = torch.zeros([out_channels, in_channels, kernel_size, kernel_size], dtype=torch.float32)weight = nn.init.constant_(weight, val=1.0)self.weight = nn.Parameter(weight)# 创建偏置bias = torch.zeros([out_channels, 1], dtype=torch.float32)self.bias = nn.init.constant_(bias, val=0.0) # 值可调整self.bias = nn.Parameter(bias)# 步长self.stride = stride# 零填充self.padding = padding# 输入通道数self.in_channels = in_channels# 输出通道数self.out_channels = out_channelsdef single_forward(self, X, weight):"""输入:- X:输入矩阵,shape=[B, M, N],B为样本数量输出:- output:输出矩阵"""new_X = torch.zeros([X.shape[0], X.shape[1] + 2 * self.padding, X.shape[2] + 2 * self.padding]) # 创建一个M'*N'的零矩阵new_X[:, self.padding:X.shape[1] + self.padding, self.padding:X.shape[2] + self.padding] = X # 将原数据放回u, v = weight.shapeoutput_w = (new_X.shape[1] - u) // self.stride + 1output_h = (new_X.shape[2] - v) // self.stride + 1output = torch.zeros([X.shape[0], output_w, output_h])for i in range(0, output.shape[1]):for j in range(0, output.shape[2]):output[:, i, j] = torch.sum(new_X[:, self.stride * i:self.stride * i + u, self.stride * j:self.stride * j + v] * weight,dim=[1, 2])return outputdef forward(self, inputs):"""输入:- inputs:输入矩阵,shape=[B, D, M, N]- weights:P组二维卷积核,shape=[P, D, U, V]- bias:P个偏置,shape=[P, 1]"""feature_maps = []# 进行多次多输入通道卷积运算p = 0for w, b in zip(self.weight, self.bias): # P个(w,b),每次计算一个特征图Zpmulti_outs = []# 循环计算每个输入特征图对应的卷积结果for i in range(self.in_channels):single = self.single_forward(inputs[:, i, :, :], w[i])multi_outs.append(single)# print("Conv2D in_channels:",self.in_channels,"i:",i,"single:",single.shape)# 将所有卷积结果相加feature_map = torch.sum(torch.stack(multi_outs), dim=0) + b # Zpfeature_maps.append(feature_map)# print("Conv2D out_channels:",self.out_channels, "p:",p,"feature_map:",feature_map.shape)p += 1# 将所有Zp进行堆叠out = torch.stack(feature_maps, 1)return out

4.2 汇聚层算子
汇聚层的作用是进行特征选择,降低特征数量,从而减少参数数量。由于汇聚之后特征图会变得更小,如果后面连接的是全连接层,可以有效地减小神经元的个数,节省存储空间并提高计算效率。
常用的汇聚方法有两种,分别是:平均汇聚和最大汇聚。
- 平均汇聚:将输入特征图划分为
大小的区域,对每个区域内的神经元活性值取平均值作为这个区域的表示;
- 最大汇聚:使用输入特征图的每个子区域内所有神经元的最大活性值作为这个区域的表示。
 汇聚层输出的计算尺寸与卷积层一致,对于一个输入矩阵
汇聚层输出的计算尺寸与卷积层一致,对于一个输入矩阵和一个运算区域大小为
的汇聚层,步长为
,对输入矩阵进行零填充,那么最终输出矩阵大小则为

由于过大的采样区域会急剧减少神经元的数量,也会造成过多的信息丢失。目前,在卷积神经网络中比较典型的汇聚层是将每个输入特征图划分为大小的不重叠区域,然后使用最大汇聚的方式进行下采样。
由于汇聚是使用某一位置的相邻输出的总体统计特征代替网络在该位置的输出,所以其好处是当输入数据做出少量平移时,经过汇聚运算后的大多数输出还能保持不变。比如:当识别一张图像是否是人脸时,我们需要知道人脸左边有一只眼睛,右边也有一只眼睛,而不需要知道眼睛的精确位置,这时候通过汇聚某一片区域的像素点来得到总体统计特征会显得很有用。这也就体现了汇聚层的平移不变特性。
汇聚层的参数量和计算量
由于汇聚层中没有参数,所以参数量为;最大汇聚中,没有乘加运算,所以计算量为
,而平均汇聚中,输出特征图上每个点都对应了一次求平均运算.
class Pool2D(nn.Module):def __init__(self, size=(2, 2), mode='max', stride=1):super(Pool2D, self).__init__()# 汇聚方式self.mode = modeself.h, self.w = sizeself.stride = stridedef forward(self, x):output_w = (x.shape[2] - self.w) // self.stride + 1output_h = (x.shape[3] - self.h) // self.stride + 1output = torch.zeros([x.shape[0], x.shape[1], output_w, output_h])# 汇聚for i in range(output.shape[2]):for j in range(output.shape[3]):# 最大汇聚if self.mode == 'max':value_m = max(torch.max(x[:, :, self.stride * i:self.stride * i + self.w, self.stride * j:self.stride * j + self.h],dim=3).values[0][0])output[:, :, i, j] = torch.tensor(value_m)# 平均汇聚elif self.mode == 'avg':output[:, :, i, j] = torch.mean(x[:, :, self.stride * i:self.stride * i + self.w, self.stride * j:self.stride * j + self.h],dim=[2, 3])return outputinputs = torch.tensor([[[[1., 2., 3., 4.], [5., 6., 7., 8.], [9., 10., 11., 12.], [13., 14., 15., 16.]]]])
pool2d = Pool2D(stride=2)
outputs = pool2d(inputs)
print("input: {}, \noutput: {}".format(inputs.shape, outputs.shape))# 比较Maxpool2D与paddle API运算结果
maxpool2d_torch = nn.MaxPool2d(kernel_size=(2, 2), stride=2)
outputs_torch = maxpool2d_torch(inputs)
# 自定义算子运算结果
print('Maxpool2D outputs:', outputs)
# paddle API运算结果
print('nn.Maxpool2D outputs:', outputs_torch)# 比较Avgpool2D与torch API运算结果
avgpool2d_torch = nn.AvgPool2d(kernel_size=(2, 2), stride=2)
outputs_torch = avgpool2d_torch(inputs)
pool2d = Pool2D(mode='avg', stride=2)
outputs = pool2d(inputs)
# 自定义算子运算结果
print('Avgpool2D outputs:', outputs)
# paddle API运算结果
print('nn.Avgpool2D outputs:', outputs_torch)
5 学习torch.nn.Conv2d()、torch.nn.MaxPool2d();torch.nn.avg_pool2d(),简要介绍使用方法。
torch.nn.Conv2d()参数如下:

torch.nn.MaxPool2d()参数如下:

torch.nn.AvgPool2d()参数如下:

具体的使用可以参照卷积层算子和池化层算子的代码中,有将调用库函数做比较~
6 分别用自定义卷积算子和torch.nn.Conv2d()编程实现下面的卷积运算
import torch.nn as nn
import torch
class Conv2D(nn.Module):def __init__(self, in_channels, Kernel, out_channels, kernel_size, stride=1, padding=0):super(Conv2D, self).__init__()self.weight = nn.Parameter(Kernel)# 创建偏置self.bias = nn.Parameter(torch.tensor([1, 0], dtype=torch.float32))# 步长self.stride = stride# 零填充self.padding = padding# 输入通道数self.in_channels = in_channels# 输出通道数self.out_channels = out_channelsdef single_forward(self, X, weight):"""输入:- X:输入矩阵,shape=[B, M, N],B为样本数量输出:- output:输出矩阵"""new_X = torch.zeros([X.shape[0], X.shape[1] + 2 * self.padding, X.shape[2] + 2 * self.padding]) # 创建一个M'*N'的零矩阵new_X[:, self.padding:X.shape[1] + self.padding, self.padding:X.shape[2] + self.padding] = X # 将原数据放回u, v = weight.shapeoutput_w = (new_X.shape[1] - u) // self.stride + 1output_h = (new_X.shape[2] - v) // self.stride + 1output = torch.zeros([X.shape[0], output_w, output_h])for i in range(0, output.shape[1]):for j in range(0, output.shape[2]):output[:, i, j] = torch.sum(new_X[:, self.stride * i:self.stride * i + u, self.stride * j:self.stride * j + v] * weight,dim=[1, 2])return outputdef forward(self, inputs):"""输入:- inputs:输入矩阵,shape=[B, D, M, N]- weights:P组二维卷积核,shape=[P, D, U, V]- bias:P个偏置,shape=[P, 1]"""feature_maps = []# 进行多次多输入通道卷积运算p = 0for w, b in zip(self.weight, self.bias): # P个(w,b),每次计算一个特征图Zpmulti_outs = []# 循环计算每个输入特征图对应的卷积结果for i in range(self.in_channels):single = self.single_forward(inputs[:, i, :, :], w[i])multi_outs.append(single)# print("Conv2D in_channels:",self.in_channels,"i:",i,"single:",single.shape)# 将所有卷积结果相加feature_map = torch.sum(torch.stack(multi_outs), dim=0) + b # Zpfeature_maps.append(feature_map)# print("Conv2D out_channels:",self.out_channels, "p:",p,"feature_map:",feature_map.shape)p += 1# 将所有Zp进行堆叠out = torch.stack(feature_maps, 1)return outx = torch.tensor([[[0, 1, 1, 0, 2],[2, 2, 2, 2, 1],[1, 0, 0, 2, 0],[0, 1, 1, 0, 0],[1, 2, 0, 0, 2]],[[1, 0, 2, 2, 0],[0, 0, 0, 2, 0],[1, 2, 1, 2, 1],[1, 0, 0, 0, 0],[1, 2, 1, 1, 1]],[[2, 1, 2, 0, 0],[1, 0, 0, 1, 0],[0, 2, 1, 0, 1],[0, 1, 2, 2, 2],[2, 1, 0, 0, 1]]], dtype=torch.float32).reshape([1, 3, 5, 5])
Kernel = torch.tensor([[[[-1, 1, 0],[0, 1, 0],[0, 1, 1]],[[-1, -1, 0],[0, 0, 0],[0, -1, 0]],[[0, 0, -1],[0, 1, 0],[1, -1, -1]]],[[[1, 1, -1],[-1, -1, 1],[0, -1, 1]],[[0, 1, 0],[-1, 0, -1],[-1, 1, 0]],[[-1, 0, 0],[-1, 0, 1],[-1, 0, 0]]]], dtype=torch.float32).reshape([2, 3, 3, 3])
conv2d = Conv2D(in_channels=3, Kernel=Kernel, out_channels=2, kernel_size=3, padding=1, stride=2)
print("inputs shape:",x.shape)
outputs = conv2d(x)
print("Conv2D outputs shape:",outputs.shape)
print(outputs)conv2d_2 = nn.Conv2d(in_channels=3, out_channels=2, kernel_size=3, padding=1, stride=(2, 2), bias=True)
conv2d_2.weight = torch.nn.Parameter(Kernel)
conv2d_2.bias = torch.nn.Parameter(torch.tensor([1, 0], dtype=torch.float32))
out = conv2d_2(x)
print(out)
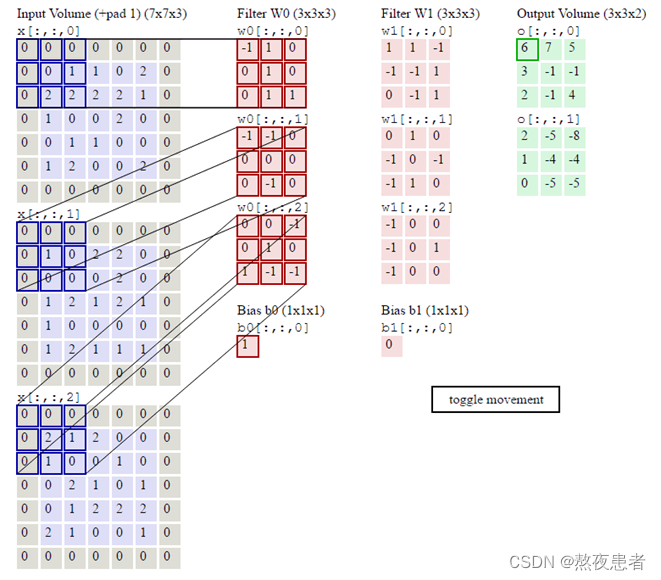
运行结果如下:
 好了到这儿,最蒙圈的地方来了,下面是老师给的图,但是怎么算这也不对啊
好了到这儿,最蒙圈的地方来了,下面是老师给的图,但是怎么算这也不对啊
总结
本次实验较为有难度,通过再次对池化层、卷积层,手推和调用库函数的代码的整理书写,对整个流程也更为明确了,就最后一个实践的时候有一点点困难,对于变量初始化、传入值的维度还是不明确这里总结一下。
对于卷积层的输入x:[batch_size(样本数), in_channel(图片的通道数), H, W(分别代表宽高)]
卷积核w:[out_channel(输出通道,输出需要有几个通道), in_channel(输入通道数,图片有几个通道, H, W(卷积核的宽高)]
偏置b:[1, out_channel(输出通道数)]
相关文章:
卷积神经网络(1)
目录 卷积 1 自定义二维卷积算子 2 自定义带步长和零填充的二维卷积算子 3 实现图像边缘检测 4 自定义卷积层算子和汇聚层算子 4.1 卷积算子 4.2 汇聚层算子 5 学习torch.nn.Conv2d()、torch.nn.MaxPool2d();torch.nn.avg_pool2d(),简要介绍使用方…...

Mysql中名叫infomaiton_schema的数据库是什么东西?
在 MySQL 中,information_schema 是一个系统数据库,用于存储关于数据库服务器元数据的信息。它并不存储用户数据,而是包含有关数据库、表、列、索引、权限等方面的元数据信息。这些信息可以通过 SQL 查询来获取,用于了解和管理数据…...
Django(复习篇)
项目创建 1. 虚拟环境 python -m venv my_env cd my_env activate/deactivate pip install django 2. 项目和app创建 cd mypros django-admin startproject Pro1 django-admin startapp app1 3. settings配置INSTALLED_APPS【app1"】TEMPLATES【 DIRS: [os.pat…...

MySQL里对时间的加减操作及常用语法
查询当前时间: select NOW(); //2023-11-14 11:36:03 select CURDATE(); //2023-11-14 SELECT CURTIME(); //11:36:03日期加日期: select date_add(NOW(), interval 1 year); //加1年 select date_add(NOW(), interval 1 month); …...

『MySQL快速上手』-⑨-复合查询
文章目录 1.基本查询回顾2.多表查询案例3.自链接案例4.子查询4.1 单行子查询4.2 多行子查询4.3 多列子查询4.4 在from子句中使用子查询5.合并查询5.1 union5.2 union all6.表的内连和外连6.1 内连接6.2 外连接6.2.1 左外连接6.2.2 右外连接...
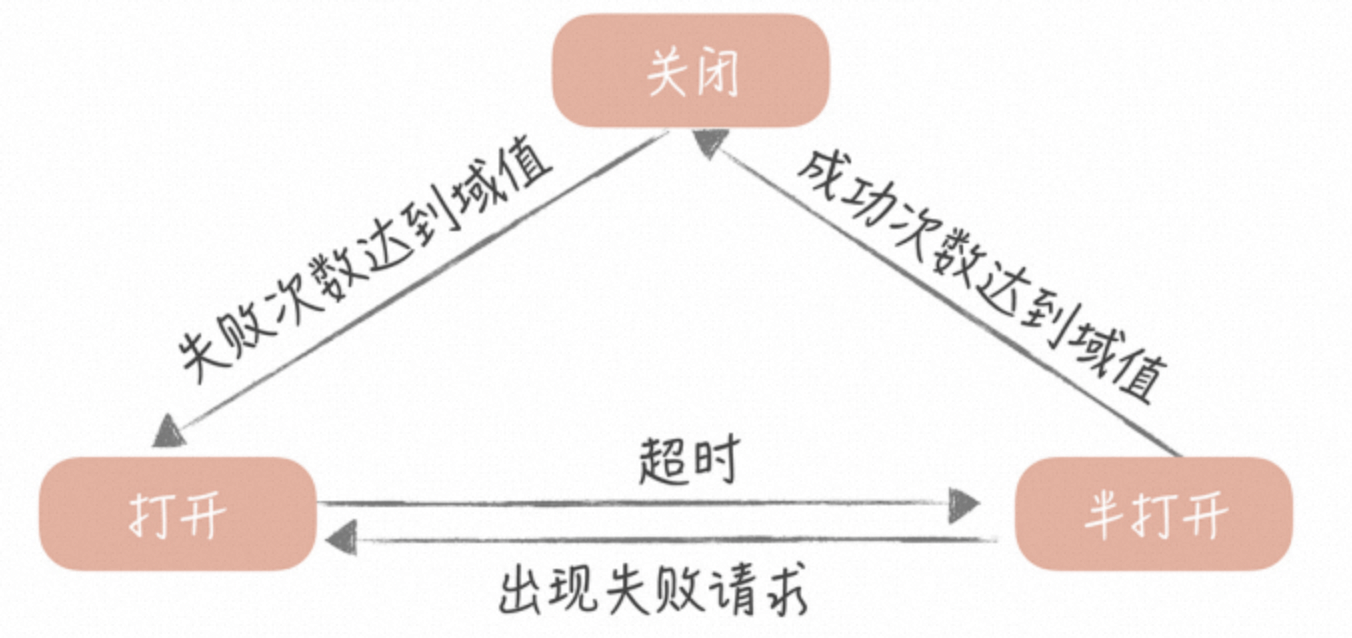
高并发架构设计(三大利器:缓存、限流和降级)
引言 高并发背景 互联网行业迅速发展,用户量剧增,系统面临巨大的并发请求压力。 软件系统有三个追求:高性能、高并发、高可用,俗称三高。三者既有区别也有联系,门门道道很多,全面讨论需要三天三夜&#…...
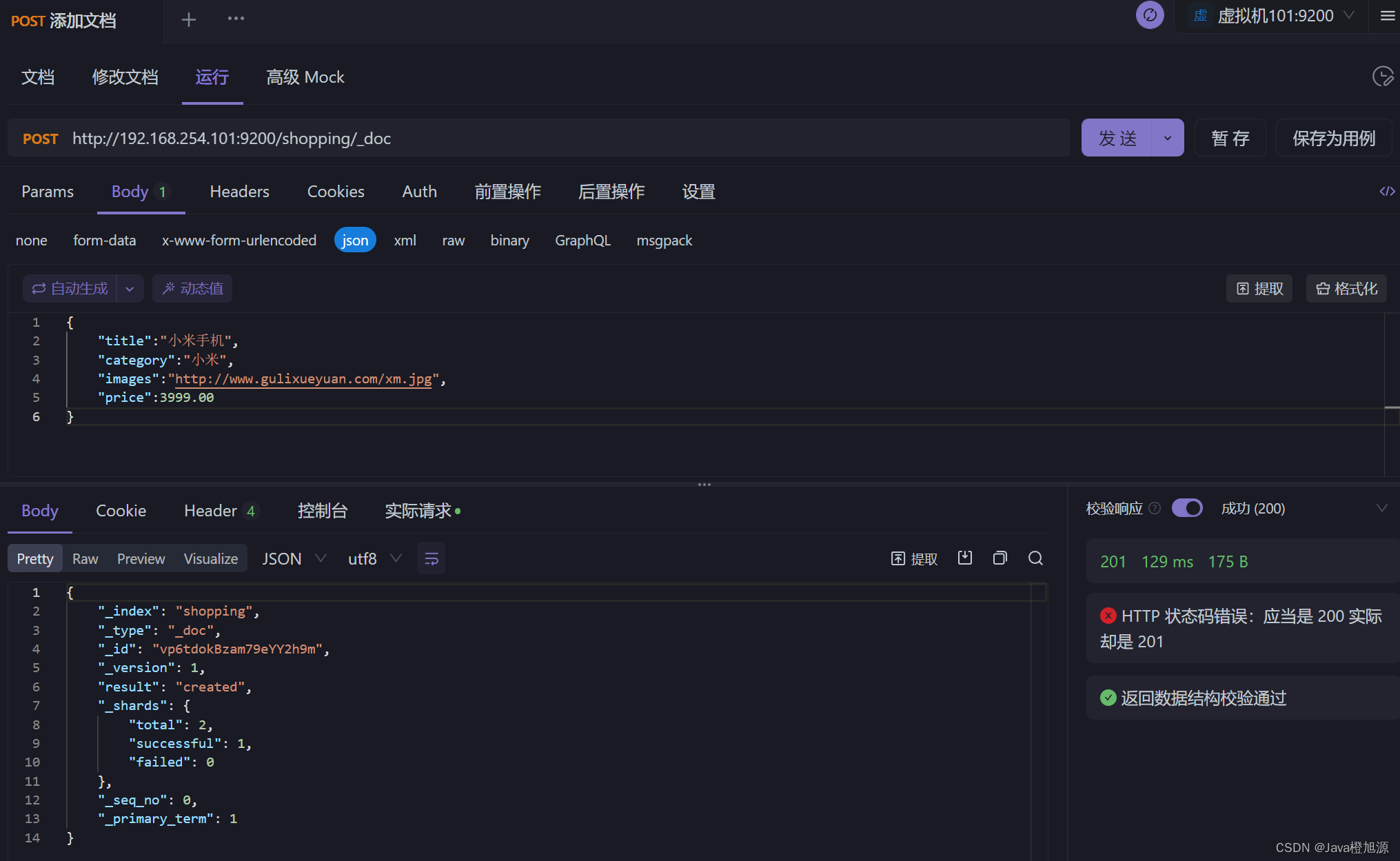
ElasticSearch7.x - HTTP 操作 - 文档操作
创建文档(添加数据) 索引已经创建好了,接下来我们来创建文档,并添加数据。这里的文档可以类比为关系型数 据库中的表数据,添加的数据格式为 JSON 格式 向 ES 服务器发 POST 请求 :http://192.168.254.101:9200/shopping/_doc 请求体内容为: {"title":"小…...
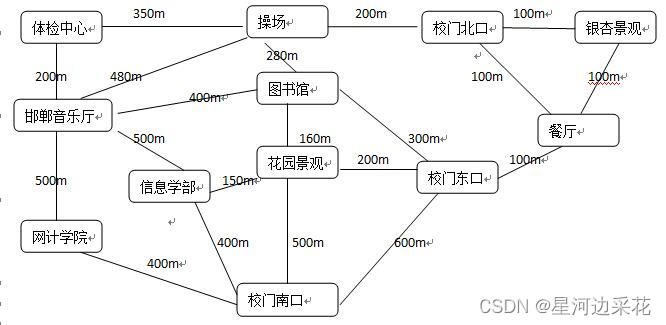
[数据结构大作业]HBU 河北大学校园导航
校园导航实验报告 问题描述: 以我校为例,设计一个校园导航系统,主要为来访的客人提供信息查询。系统有两类登陆账号,一类是游客,使用该系统方便校内路线查询;一类是管理员,可以使用该系统查询…...

立体库堆垛机控制程序手动功能实现
手动操作功能模块 手动前后保护锁 *************提升手动程序段 手动上升,下降保护锁 **********货叉手动程序段...

git commit提交报错
git commit -m 名字’时报一下错误: [FAILED] npm run lint-staged:js [FAILED] [FAILED] npm run lint-staged:js [FAILED] [SUCCESS] Running tasks for staged files..npm ERR! code EPERM npm ERR! syscall open npm ERR! path C:\Program Files\nodejs\node_c…...

OpenSIPS自定义统计项目
有朋友问,怎么统计ops每日的呼叫量 这就是需要自定义统计项目 我第一感觉是dialog模块 后来又查了下资料,statistics模块更合适,Kamailio也有同名模块...

python数据结构与算法-02_数组和列表
线性结构 本节我们从最简单和常用的线性结构开始,并结合 Python 语言本身内置的数据结构和其底层实现方式来讲解。 虽然本质上数据结构的思想是语言无关的,但是了解 Python 的实现方式有助于你避免一些坑。 我们会在代码中注释出操作的时间复杂度。 数…...
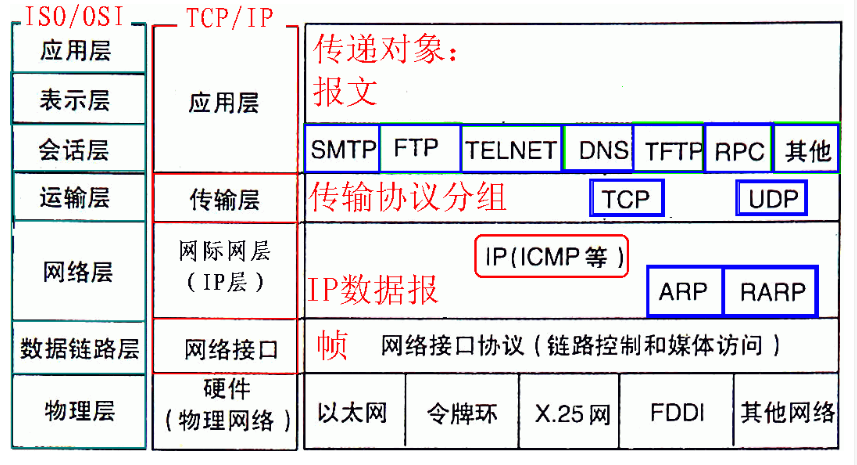
计算机网络基础知识-网络协议
一:计算机网络层次划分 1. 网络层次划分 2. OSI七层网络模型 1)物理层(Physical Layer):及硬件设备,物理层确保原始的数据可在各种物理媒体上传输,常见的设备名称如中继器(Repeater,也叫放大器)和集线器; 2)数据链路层(Data Link Layer):数据链路层在物理层提…...

【Vue3】scoped 和样式穿透
我们使用很多 vue 的组件库(element-plus、vant),在修改样式的时候需要进行其他操作才能成功更改样式,此时就用到了样式穿透。 而不能正常更改样式的原因就是 scoped 标记。 scoped 的渲染规则: <template>&l…...

Python 邮件发送(163为例)
代码 import smtplib import socket from email.mime.text import MIMEText from email.header import Headerdef send_mail():# 设置发件人、收件人、主题、内容from_address 18847097110163.comto_address 963268595qq.comsubject test emailbody hahahhahaha# SMTP邮件…...
BlendTree动画混合算法详解
【混合本质】 如果了解骨骼动画就知道,某一时刻角色的Pose是通过两个邻近关键帧依次对所有骨骼插值而来,换句话说就是由两个关键帧混合而来。 那么可不可以由多个关键帧混合而来呢?当然可以。 更多的关键帧可以来自不同的动画片段…...

2013年01月16日 Go生态洞察:并发不是并行
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

CRM销售管理软件哪个好,该如何选择?(一)
销售团队对于任何一家企业来说都是重中之重,因此我们说一款可以辅助销售人员维护好客户的工具是企业发展的刚需。那么CRM销售管理软件哪个好,该如何选择,从从哪里方面去入手?来看看这两点吧: 功能方面 完整的功能可以…...
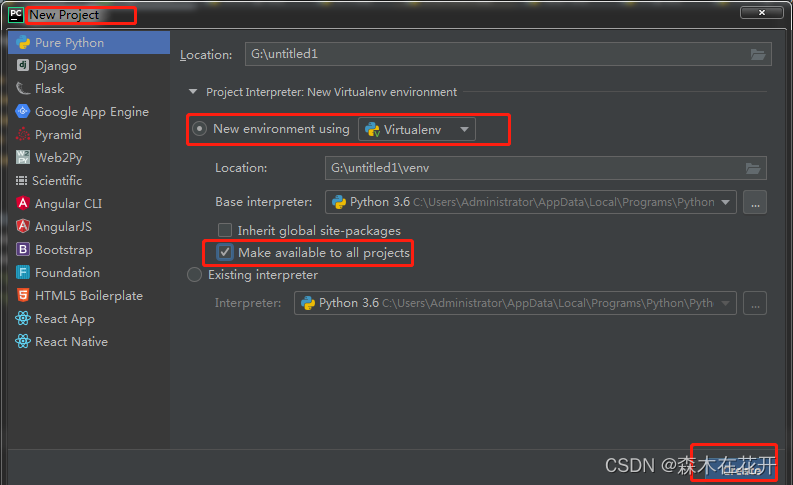
Django路由层解析
路由层(urls.py) Django的路由层是用于将URL映射到视图函数的机制。它用于确定请求URL(HTTP请求)应该被哪个视图函数处理。 Django的路由层包括两个部分: URL模式:匹配请求URL,决定应该使用哪个视图函数来处理请求。UR…...
(中))
高教社杯数模竞赛特辑论文篇-2023年A题:定日镜场的输出功率优化(附获奖论文及MATLAB代码实现)(中)
目录 6.4定日镜平均输出热功率优化模型的求解 6.5问题二求解结果 6.6 结果分析...

无机布防火卷帘门价格怎么算?按尺寸定制,按需报价
无机布防火卷帘门作为建筑防火分区的核心设备,价格一直是工程采购的关注重点。很多用户在询价时,会发现不同厂家的报价差异较大,这是因为无机布防火卷帘门的价格并非按统一单价计算,而是完全根据项目的实际需求定制化核算。 &…...

对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异 对于个人开发者或项目管理者而言,在接入大模型服务时&a…...

0.2毫秒快速启动的操作系统
在工业控制以及航空航天等核心场景,极速启动就是高可靠系统的生命线。0.2毫秒超快启动搭配硬件看门狗,让设备在掉电重启、异常恢复时瞬时归位,关键任务永不延误! https://www.bilibili.com/video/BV11mLY6VERt/?spm_id_from333.1…...

XML 服务器
XML 服务器 引言 XML(可扩展标记语言)服务器在现代互联网技术中扮演着至关重要的角色。它为数据的传输和处理提供了灵活且高效的方式。本文将深入探讨XML服务器的概念、工作原理、应用场景及其在软件开发中的重要性。 什么是XML服务器? XML服务器是一种用于存储、处理和…...

从开题到定稿零焦虑:okbiye AI 论文写作,帮你把毕业季的 “大山” 变成坦途
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 毕业季的深夜,宿舍台灯下的屏幕亮着刺眼的光,文档里的字数停留在三位数,而 deadline 正一天天逼近。你是…...

Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现
Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现 【免费下载链接】vue2-verify vue的验证码插件 项目地址: https://gitcode.com/gh_mirrors/vu/vue2-verify 在当今Web应用开发中,验证码作为防止自动化攻击的关键安全组件&…...

DAIR-V2X-V数据集深度评测:与KITTI、nuScenes比,它到底强在哪?
DAIR-V2X-V数据集深度评测:与KITTI、nuScenes比,它到底强在哪? 当技术团队着手开发面向中国道路的自动驾驶系统时,数据集的选择往往成为第一个关键决策点。过去十年间,KITTI和nuScenes等国际数据集一直是行业标杆&…...

Java项目中如何提升整体系统性能?
性能优化可以说是我们程序员的必修课,如果你想要跳出CRUD的苦海,成为一个更“高级”的程序员的话,性能优化这一关你是无论无何都要去面对的。为了提升系统性能,开发人员可以从系统的各个角度和层次对系统进行优化。除了最常见的代…...

零基础怎么学Agent?这个工程师考试内容拆给你看
站在 AI Agent(智能体)爆发的十字路口,很多既没有深厚算法背景、也没有丰富写代码经验的“小白”常常感到迷茫:动辄谈及的大模型交互、复杂的业务编排,零基础真的能学会吗? 事实上,智能体开发早…...

Windows 11 LTSC安装微软商店的终极解决方案:3步恢复完整应用生态
Windows 11 LTSC安装微软商店的终极解决方案:3步恢复完整应用生态 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore LTSC-Add-MicrosoftStor…...