PSP - 蛋白质复合物结构预测 模版配对(Template Pair) 逻辑的特征分析
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/134328447
在 蛋白质复合物结构预测 的过程中,模版 (Template) 起到重要作用,提供预测结果的关于三维结构的先验信息,在多链的情况,需要进行模版配对,即 Template Pair,核心函数是 template_pair_embedder,结合 AlphaFold2 的论文,分析具体输入与输出的特征。
核心逻辑 template_pair_embedder(),输入和输出特征维度:
[CL] TemplateEmbedderMultimer - template_dgram: torch.Size([1, 1102, 1102, 39])
[CL] TemplateEmbedderMultimer - z: torch.Size([1102, 1102, 128])
[CL] TemplateEmbedderMultimer - pseudo_beta_mask: torch.Size([1, 1102])
[CL] TemplateEmbedderMultimer - backbone_mask: torch.Size([1, 1102])
[CL] TemplateEmbedderMultimer - multichain_mask_2d: torch.Size([1102, 1102])
[CL] TemplateEmbedderMultimer - unit_vector: torch.Size([1, 1102, 1102])
[CL] TemplateEmbedderMultimer - pair_act: torch.Size([1, 1102, 1102, 64])
函数:
# openfold/model/embedders.py
pair_act = self.template_pair_embedder(template_dgram,aatype_one_hot,z,pseudo_beta_mask,backbone_mask,multichain_mask_2d,unit_vector,
)t = torch.sum(t, dim=-4) / n_templ
t = torch.nn.functional.relu(t)
t = self.linear_t(t) # 从 c_t 维度 转换 成 c_z 维度,更新 z
template_embeds["template_pair_embedding"] = t# openfold/model/model.py
template_embeds = self.template_embedder(template_feats,z,pair_mask.to(dtype=z.dtype),no_batch_dims,chunk_size=self.globals.chunk_size,multichain_mask_2d=multichain_mask_2d,use_fa=self.globals.use_fa,
)
z = z + template_embeds["template_pair_embedding"] # line 13 in Alg.2
逻辑图:
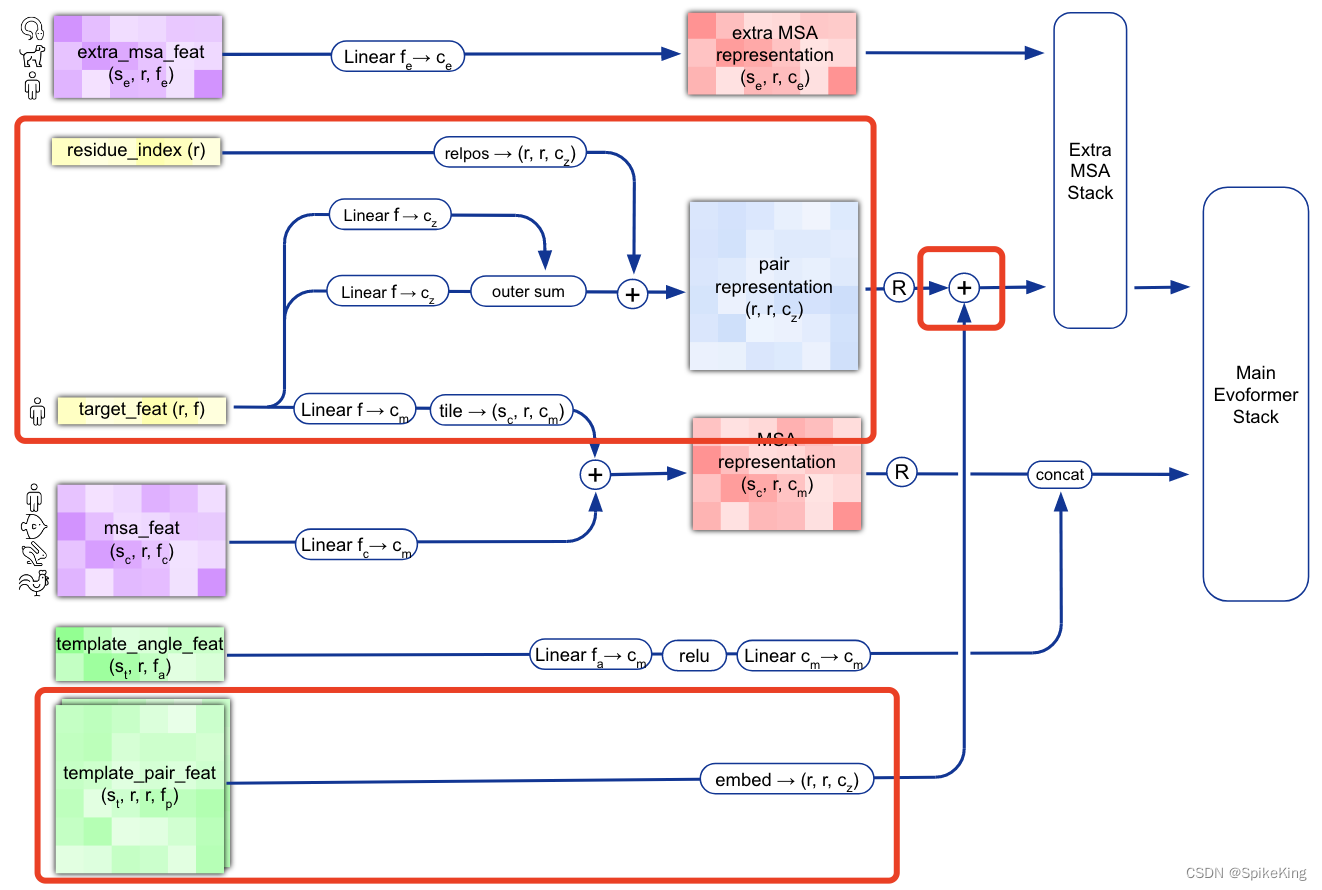
1. template_dgram 特征
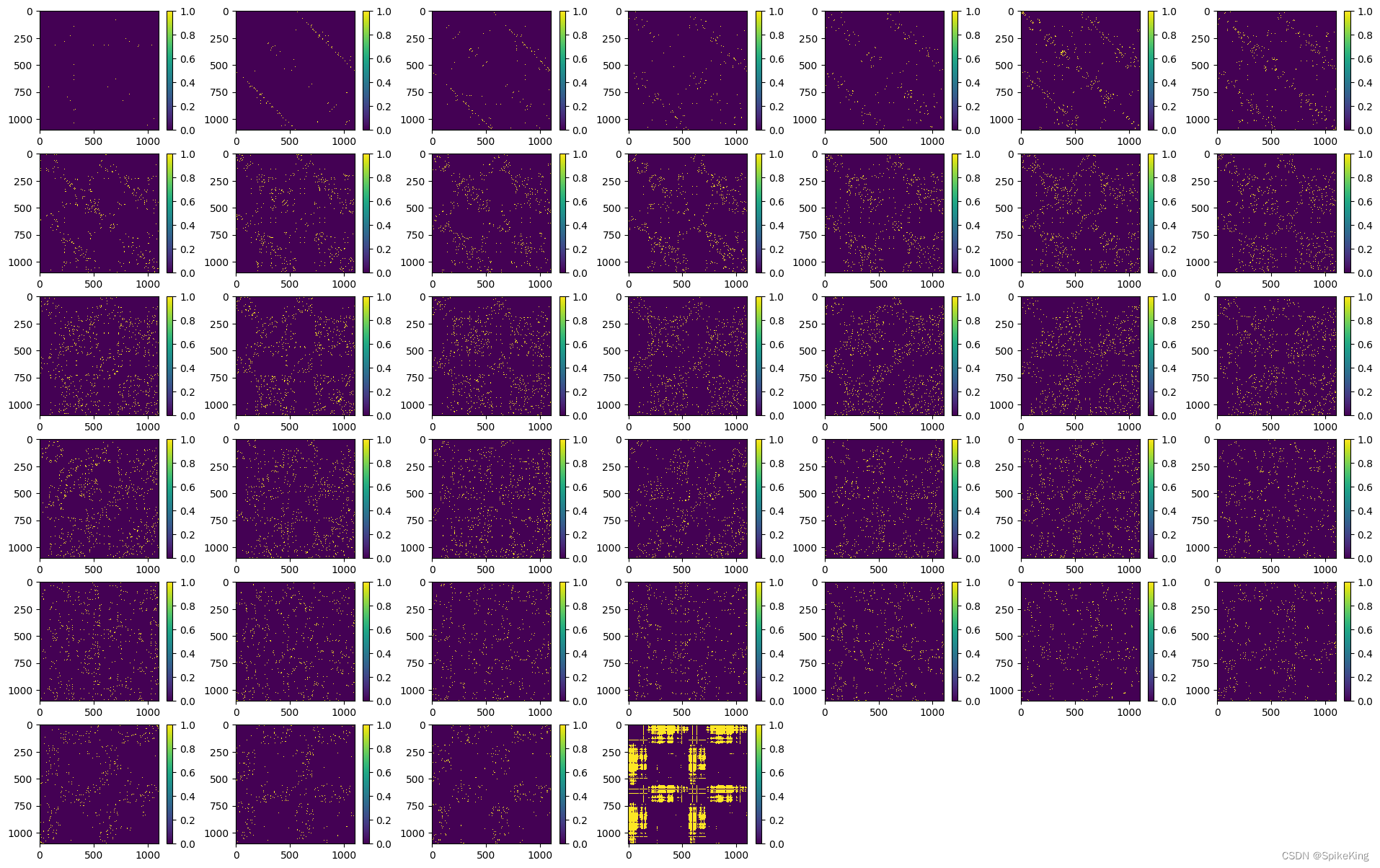
template_dgram特征计算,不同点距离其他点的远近划分,共划分 39 个bin,Template 的 no_bin 是 1.25 计算 1 个值,即 (50.75 - 3.25) / 38 = 1.25,即:
template_dgram = dgram_from_positions(template_positions,inf=self.config.inf,**self.config.distogram,
)def dgram_from_positions(pos: torch.Tensor,min_bin: float = 3.25,max_bin: float = 50.75,no_bins: float = 39,inf: float = 1e8,
):dgram = torch.sum((pos[..., None, :] - pos[..., None, :, :]) ** 2, dim=-1, keepdim=True)lower = torch.linspace(min_bin, max_bin, no_bins, device=pos.device) ** 2upper = torch.cat([lower[1:], lower.new_tensor([inf])], dim=-1)dgram = ((dgram > lower) * (dgram < upper)).type(dgram.dtype)return dgram
Template 的 no_bin 是 1.25 计算 1 个值,即 (50.75 - 3.25) / 38 = 1.25,长度是 39。
其中,template_positions 特征,如下:
- 输入
template_pseudo_beta与template_pseudo_beta_mask - 输出坐标
template_positions,即template_pseudo_beta的值
template_positions, pseudo_beta_mask = (single_template_feats["template_pseudo_beta"],single_template_feats["template_pseudo_beta_mask"],
)
其中pseudo_beta 特征的处理,来源于 openfold/data/data_transforms_multimer.py 即:
- 输入特征:
template_aatype、template_all_atom_positions、template_all_atom_mask - 原理是:选择 CA 或 CB 原子的坐标与 Mask
源码即调用关系如下:
# 输入特征,模型预测结构
# run_pretrained_openfold.py
processed_feature_dict, _ = feature_processor.process_features(feature_dict, is_multimer, mode="predict"
)
output_dict = predict_structure_single_dev(args,model_name,current_model,fasta_path,processed_feature_dict,config,
)# openfold/data/feature_pipeline.py
processed_feature, label = np_example_to_features_multimer(np_example=raw_features,config=self.config,mode=mode,
)# openfold/data/feature_pipeline.py
features, label = input_pipeline_multimer.process_tensors_from_config(tensor_dict,cfg.common,cfg[mode],cfg.data_module,
)# openfold/data/input_pipeline_multimer.py
nonensembled = nonensembled_transform_fns(common_cfg,mode_cfg,
)
tensors = compose(nonensembled)(tensors)# openfold/data/input_pipeline_multimer.py
operators.extend([data_transforms_multimer.make_atom14_positions,data_transforms_multimer.atom37_to_frames,data_transforms_multimer.atom37_to_torsion_angles(""),data_transforms_multimer.make_pseudo_beta(""),data_transforms_multimer.get_backbone_frames,data_transforms_multimer.get_chi_angles,]
)# openfold/data/data_transforms_multimer.py
def make_pseudo_beta(protein, prefix=""):"""Create pseudo-beta (alpha for glycine) position and mask."""assert prefix in ["", "template_"](protein[prefix + "pseudo_beta"],protein[prefix + "pseudo_beta_mask"],) = pseudo_beta_fn(protein["template_aatype" if prefix else "aatype"],protein[prefix + "all_atom_positions"],protein["template_all_atom_mask" if prefix else "all_atom_mask"],)return protein# openfold/data/data_transforms_multimer.py
def pseudo_beta_fn(aatype, all_atom_positions, all_atom_mask):"""Create pseudo beta features."""if aatype.shape[0] > 0:is_gly = torch.eq(aatype, rc.restype_order["G"])ca_idx = rc.atom_order["CA"]cb_idx = rc.atom_order["CB"]pseudo_beta = torch.where(torch.tile(is_gly[..., None], [1] * len(is_gly.shape) + [3]),all_atom_positions[..., ca_idx, :],all_atom_positions[..., cb_idx, :],)else:pseudo_beta = all_atom_positions.new_zeros(*aatype.shape, 3)if all_atom_mask is not None:if aatype.shape[0] > 0:pseudo_beta_mask = torch.where(is_gly, all_atom_mask[..., ca_idx], all_atom_mask[..., cb_idx])else:pseudo_beta_mask = torch.zeros_like(aatype).float()return pseudo_beta, pseudo_beta_maskelse:return pseudo_beta
template_pseudo_beta_mask: Mask indicating if the beta carbon (alpha carbon for glycine) atom has coordinates for the template at this residue.
template_dgram 特征 [1, 1102, 1102, 39],即:
2. z 特征
z 特征作为输入,直接传入,来源于 protein["target_feat"],来源于protein[]"between_segment_residues"], 即:
- 日志
target_feat:torch.Size([1102, 21]),不包括 “-”,只包括21=20+1个氨基酸,包括X - 将
[1102, 21]经过线性层,转换成c_z维度,即128维。 - 再通过
outer sum操作 转换成 LxLxC 维度,其实 z 就是 Pair Representation,即[1102, 1102, 128]维度。
# openfold/model/embedders.py
def forward(self,batch,z,padding_mask_2d,templ_dim,chunk_size,multichain_mask_2d,use_fa=False,
):# openfold/model/model.py
template_embeds = self.template_embedder(template_feats,z,pair_mask.to(dtype=z.dtype),no_batch_dims,chunk_size=self.globals.chunk_size,multichain_mask_2d=multichain_mask_2d,use_fa=self.globals.use_fa,
)# openfold/model/model.py
m, z = self.input_embedder(feats)# openfold/model/embedders.py#InputEmbedderMultimer
def forward(self, batch) -> Tuple[torch.Tensor, torch.Tensor]:"""# ...Returns:msa_emb:[*, N_clust, N_res, C_m] MSA embeddingpair_emb:[*, N_res, N_res, C_z] pair embedding"""tf = batch["target_feat"]msa = batch["msa_feat"]# [*, N_res, c_z]tf_emb_i = self.linear_tf_z_i(tf)tf_emb_j = self.linear_tf_z_j(tf)# [*, N_res, N_res, c_z]pair_emb = tf_emb_i[..., None, :] + tf_emb_j[..., None, :, :]pair_emb = pair_emb + self.relpos(batch) # 计算相对位置# [*, N_clust, N_res, c_m]n_clust = msa.shape[-3]tf_m = (self.linear_tf_m(tf).unsqueeze(-3).expand(((-1,) * len(tf.shape[:-2]) + (n_clust, -1, -1))))msa_emb = self.linear_msa_m(msa) + tf_mreturn msa_emb, pair_emb# openfold/data/data_transforms_multimer.py
def create_target_feat(batch):"""Create the target features"""batch["target_feat"] = torch.nn.functional.one_hot(batch["aatype"], 21).to(torch.float32)return batch# openfold/data/input_pipeline_multimer.py
operators.extend([data_transforms_multimer.cast_to_64bit_ints,# todo: randomly_replace_msa_with_unknown may need to be confirmed and tried in training.# data_transforms_multimer.randomly_replace_msa_with_unknown(0.0),data_transforms_multimer.make_msa_profile,data_transforms_multimer.create_target_feat,data_transforms_multimer.make_atom14_masks,]
)
InputEmbedderMultimer 的框架图:
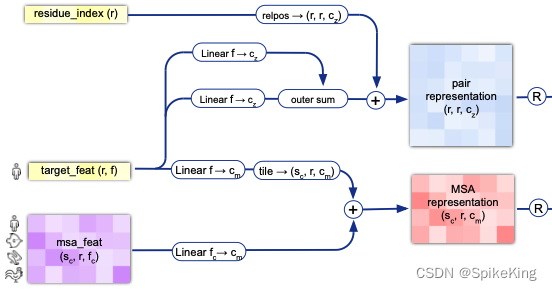
其中的 21 个氨基酸,即:
ID_TO_HHBLITS_AA = {0: "A",1: "C", # Also U.2: "D", # Also B.3: "E", # Also Z.4: "F",5: "G",6: "H",7: "I",8: "K",9: "L",10: "M",11: "N",12: "P",13: "Q",14: "R",15: "S",16: "T",17: "V",18: "W",19: "Y",20: "X", # Includes J and O.21: "-",
}
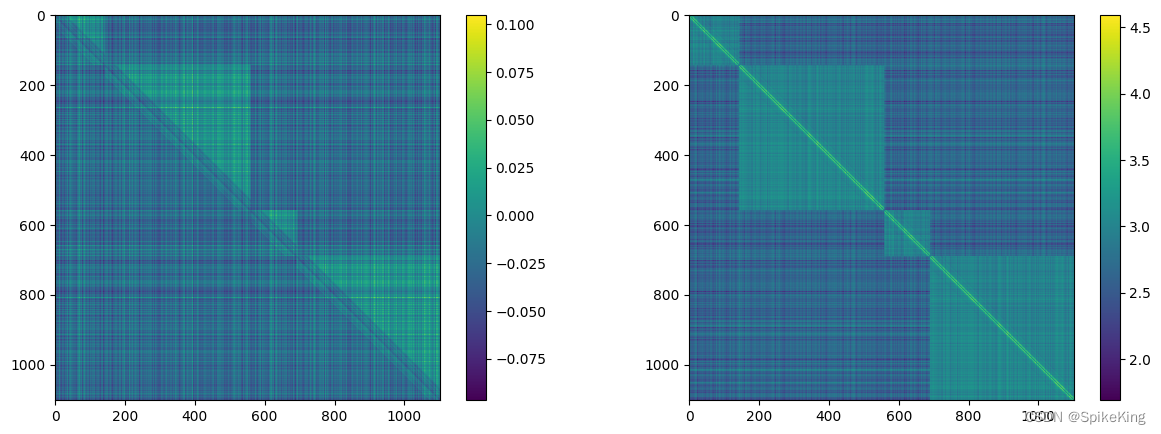
z 特征 (mean 和 max),[1102, 1102, 128],即:
3. pseudo_beta_mask 与 backbone_mask 特征
pseudo_beta_mask 特征 参考 template_dgram 的 template_pseudo_beta 部分的源码:
- 关注 CA 与 CB 的 Mask 信息
# openfold/data/data_transforms_multimer.py
def make_pseudo_beta(protein, prefix=""):"""Create pseudo-beta (alpha for glycine) position and mask."""assert prefix in ["", "template_"](protein[prefix + "pseudo_beta"],protein[prefix + "pseudo_beta_mask"],) = pseudo_beta_fn(protein["template_aatype" if prefix else "aatype"],protein[prefix + "all_atom_positions"],protein["template_all_atom_mask" if prefix else "all_atom_mask"],)return protein# openfold/data/data_transforms_multimer.py
def pseudo_beta_fn(aatype, all_atom_positions, all_atom_mask):"""Create pseudo beta features."""if aatype.shape[0] > 0:is_gly = torch.eq(aatype, rc.restype_order["G"])ca_idx = rc.atom_order["CA"]cb_idx = rc.atom_order["CB"]pseudo_beta = torch.where(torch.tile(is_gly[..., None], [1] * len(is_gly.shape) + [3]),all_atom_positions[..., ca_idx, :],all_atom_positions[..., cb_idx, :],)else:pseudo_beta = all_atom_positions.new_zeros(*aatype.shape, 3)if all_atom_mask is not None:if aatype.shape[0] > 0:pseudo_beta_mask = torch.where(is_gly, all_atom_mask[..., ca_idx], all_atom_mask[..., cb_idx])else:pseudo_beta_mask = torch.zeros_like(aatype).float()return pseudo_beta, pseudo_beta_maskelse:return pseudo_beta
其中,openfold/data/msa_pairing.py#merge_chain_features(), 合并(merge)多链特征,输出 Template Feature,即:
[CL] template features, template_aatype : (4, 1102)
[CL] template features, template_all_atom_positions : (4, 1102, 37, 3)
[CL] template features, template_all_atom_mask : (4, 1102, 37)
注意 template_all_atom_mask,即 37 个原子的 mask 信息。
其中,37 个原子(Atom):
{'N': 0, 'CA': 1, 'C': 2, 'CB': 3, 'O': 4, 'CG': 5, 'CG1': 6, 'CG2': 7, 'OG': 8, 'OG1': 9, 'SG': 10,
'CD': 11, 'CD1': 12, 'CD2': 13, 'ND1': 14, 'ND2': 15, 'OD1': 16, 'OD2': 17, 'SD': 18, 'CE': 19, 'CE1': 20,
'CE2': 21, 'CE3': 22, 'NE': 23, 'NE1': 24, 'NE2': 25, 'OE1': 26, 'OE2': 27, 'CH2': 28, 'NH1': 29, 'NH2': 30,
'OH': 31, 'CZ': 32, 'CZ2': 33, 'CZ3': 34, 'NZ': 35, 'OXT': 36}
backbone_mask 特征,只关注 N、CA、C 三类原子的 Mask 信息,参考:
- 一般情况下都与
pseudo_beta_mask相同,因为要么存在残基,要么不存在残基。
# openfold/utils/all_atom_multimer.py
def make_backbone_affine(positions: geometry.Vec3Array,mask: torch.Tensor,aatype: torch.Tensor,
) -> Tuple[geometry.Rigid3Array, torch.Tensor]:a = rc.atom_order["N"]b = rc.atom_order["CA"]c = rc.atom_order["C"]rigid_mask = mask[..., a] * mask[..., b] * mask[..., c]rigid = make_transform_from_reference(a_xyz=positions[..., a],b_xyz=positions[..., b],c_xyz=positions[..., c],)return rigid, rigid_mask
pseudo_beta_mask 与 backbone_mask 相同,[1, 1102],即:
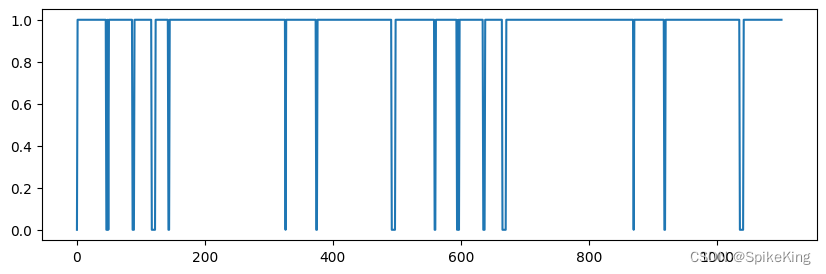
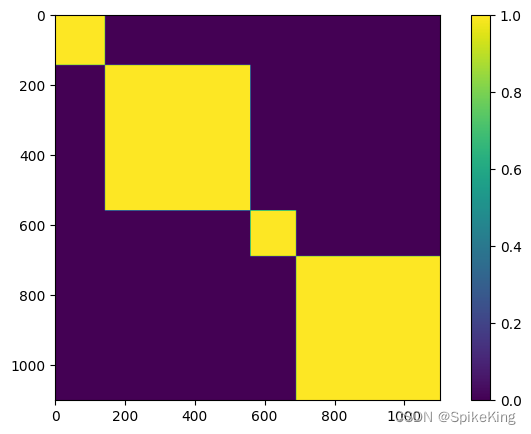
4. multichain_mask_2d 特征
非常简单,就是链内 Mask,源码:
# openfold/model/model.py
multichain_mask_2d = (asym_id[..., None] == asym_id[..., None, :]
) # [N_res, N_res]
multichain_mask_2d,[1102, 1102],即:
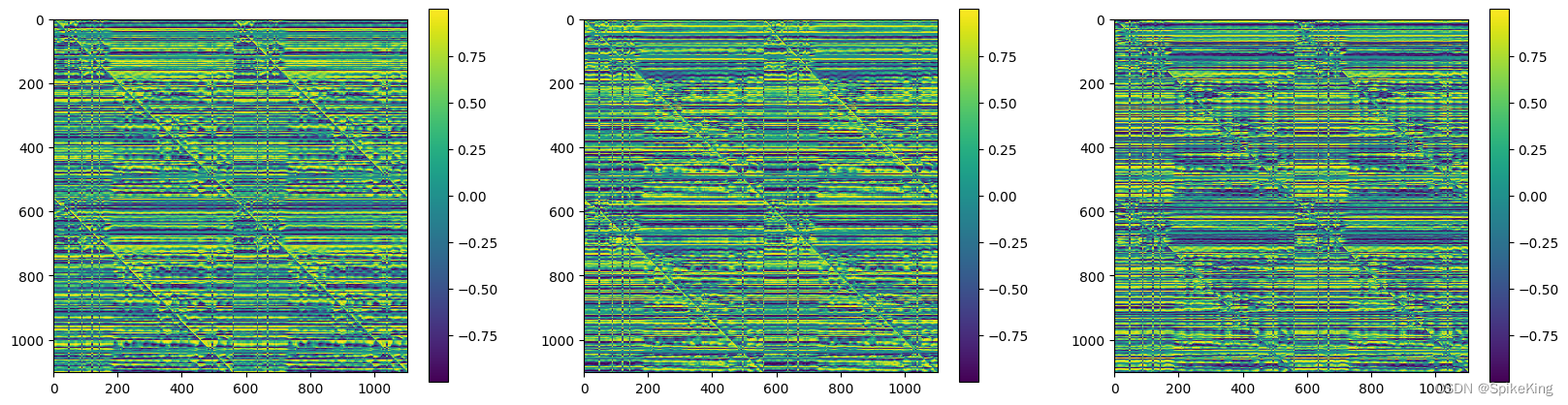
5. unit_vector 特征
unit_vector 是 Rot3Array 对象,与角度相关的单位向量,源码:
# openfold/model/embedders.py
rigid, backbone_mask = all_atom_multimer.make_backbone_affine(atom_pos,single_template_feats["template_all_atom_mask"],single_template_feats["template_aatype"],
)
points = rigid.translation
rigid_vec = rigid[..., None].inverse().apply_to_point(points)
unit_vector = rigid_vec.normalized()# openfold/utils/all_atom_multimer.py
def make_backbone_affine(positions: geometry.Vec3Array,mask: torch.Tensor,aatype: torch.Tensor,
) -> Tuple[geometry.Rigid3Array, torch.Tensor]:a = rc.atom_order["N"]b = rc.atom_order["CA"]c = rc.atom_order["C"]rigid_mask = mask[..., a] * mask[..., b] * mask[..., c]rigid = make_transform_from_reference(a_xyz=positions[..., a],b_xyz=positions[..., b],c_xyz=positions[..., c],)return rigid, rigid_mask# openfold/utils/all_atom_multimer.py
def make_transform_from_reference(a_xyz: geometry.Vec3Array, b_xyz: geometry.Vec3Array, c_xyz: geometry.Vec3Array
) -> geometry.Rigid3Array:"""Returns rotation and translation matrices to convert from reference.Note that this method does not take care of symmetries. If you provide thecoordinates in the non-standard way, the A atom will end up in the negativey-axis rather than in the positive y-axis. You need to take care of suchcases in your code.Args:a_xyz: A Vec3Array.b_xyz: A Vec3Array.c_xyz: A Vec3Array.Returns:A Rigid3Array which, when applied to coordinates in a canonicalizedreference frame, will give coordinates approximately equalthe original coordinates (in the global frame)."""rotation = geometry.Rot3Array.from_two_vectors(c_xyz - b_xyz, a_xyz - b_xyz)return geometry.Rigid3Array(rotation, b_xyz)# openfold/utils/geometry/rotation_matrix.py
@classmethod
def from_two_vectors(cls, e0: vector.Vec3Array, e1: vector.Vec3Array) -> Rot3Array:"""Construct Rot3Array from two Vectors.Rot3Array is constructed such that in the corresponding frame 'e0' lies onthe positive x-Axis and 'e1' lies in the xy plane with positive sign of y.Args:e0: Vectore1: VectorReturns:Rot3Array"""# Normalize the unit vector for the x-axis, e0.e0 = e0.normalized()# make e1 perpendicular to e0.c = e1.dot(e0)e1 = (e1 - c * e0).normalized()# Compute e2 as cross product of e0 and e1.e2 = e0.cross(e1)return cls(e0.x, e1.x, e2.x, e0.y, e1.y, e2.y, e0.z, e1.z, e2.z)
解释:每个残基的局部框架内所有残基的 α \alpha α 碳原子位移的单位向量。 这些局部框架的计算方式与目标结构相同。
The unit vector of the displacement of the alpha carbon atom of all residues within the local frame of each residue. These local frames are computed in the same way as for the target structure.
计算逻辑:

unit_vector 包括x、y、z等3个分量,[1, 1102, 1102, 3],即:
相关文章:
PSP - 蛋白质复合物结构预测 模版配对(Template Pair) 逻辑的特征分析
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/134328447 在 蛋白质复合物结构预测 的过程中,模版 (Template) 起到重要作用,提供预测结果的关于三维结构的先验信息&…...

喜报不断!箱讯平台获评2023年上海市促进现代航运服务业创新示范项目
近期,可谓捷报频传!在箱讯科技子公司苏州箱讯获评苏州市软件和信息服务业 “头雁”培育企业没过多久,就又迎来好消息! 日前,上海市交通委发布“2023年上海市促进现代航运服务业创新项目”评选结果,箱讯An…...
SOME/IP学习笔记3
目录 1.SOMEIP Transformer 1.1 SOME/IP on-wire format 1.2 协议指定 2. SOMEIP TP 2.1 SOME/IP TP Header 3.小结 1.SOMEIP Transformer 根据autosar CP 相关规范,SOME/IP Transformer主要用于将SOME/IP格式的数据序列化,相当于一个转换器。总体…...

【ATTCK】ATTCK开源项目Caldera学习笔记
CALDERA是一个由python语言编写的红蓝对抗工具(攻击模拟工具)。它是MITRE公司发起的一个研究项目,该工具的攻击流程是建立在ATT&CK攻击行为模型和知识库之上的,能够较真实地APT攻击行为模式。 通过CALDERA工具,安全…...

黑窗口连接远程服务
ssh root192.168.x.x 回车输入密码 查看docker docker ps 停止正在运行的服务 docker stop xxxxx 删除服务 docker rm xxxxx 查看镜像 docker images 删除镜像 docker rmi xxxxx 删除镜像 启动并运行整个服务 docker compose up -d jar包名称 idea 使用tcp方式连接docker 配置d…...

好消息!2023年汉字小达人市级比赛在线模拟题大更新:4个组卷+11个专项,助力孩子更便捷、有效、有趣地备赛
自从《中文自修》杂志社昨天发通知,官宣了2023年第十届汉字小达人市级比赛的日期和安排后,各路学霸们闻风而动,在自己本就繁忙的日程中又加了一项:备赛汉字小达人市级比赛,11月30日,16点-18点。 根据这几年…...

SAP 70策略测试简介
在前面的文章中我们已经测试了10、11、20、40、50、52、60、62策略的测试,接下来我们需要对70策略进行测试,很多的项目中也都会用到70策略。 70策略是一种比较常见的、基于按库存且主要用于半成品或者原材料的计划策略。 我们还是按照之前的惯例,先看下70策略的后台配置 我…...
uniapp+vue3+ts+vite+echarts开发图表类小程序,将echarts导入项目使用的详细步骤,耗时一天终于弄好了
想在uniapp和vue3环境中使用echarts是一件相当前卫的事情,官方适配的还不是很好,echarts的使用插件写的是有些不太清晰的,这里我花费了一天的时间,终于将这个使用步骤搞清楚了,并且建了一个仓库,大家可以直…...

分布式服务器架构的优点有哪些?
在当今数字化时代,随着互联网的普及和技术的不断进步,企业和组织面临着处理越来越多的数据和用户请求的挑战。为了应对这些挑战,分布式服务器架构应运而生。分布式服务器架构通过将任务和数据分散到多个服务器上,提供了许多优点&a…...

Zephyr-7B论文解析及全量训练、Lora训练
文章目录 一、Zephyr:Direct Distillation of LM Alignment1.1 开发经过1.1.1 Zephyr-7B-alpha1.1.2 Zephyr-7B-beta 1.2 摘要1.3 相关工作1.4 算法1.4.1 蒸馏监督微调(dSFT)1.4.2 基于偏好的AI反馈 (AIF)1.4.3 直接蒸馏偏好优化&…...
如何使用群晖虚拟机部署本地网页文件实现公网远程访问?
文章目录 前言1. 安装网页运行环境1.1 安装php1.2 安装webstation 2. 下载网页源码文件2.1 访问网站地址并下载压缩包2.2 解压并上传至群辉NAS 3. 配置webstation3.1 配置网页服务3.2 配置网络门户 4. 局域网访问静态网页配置成功5. 使用cpolar发布静态网页,实现公网…...
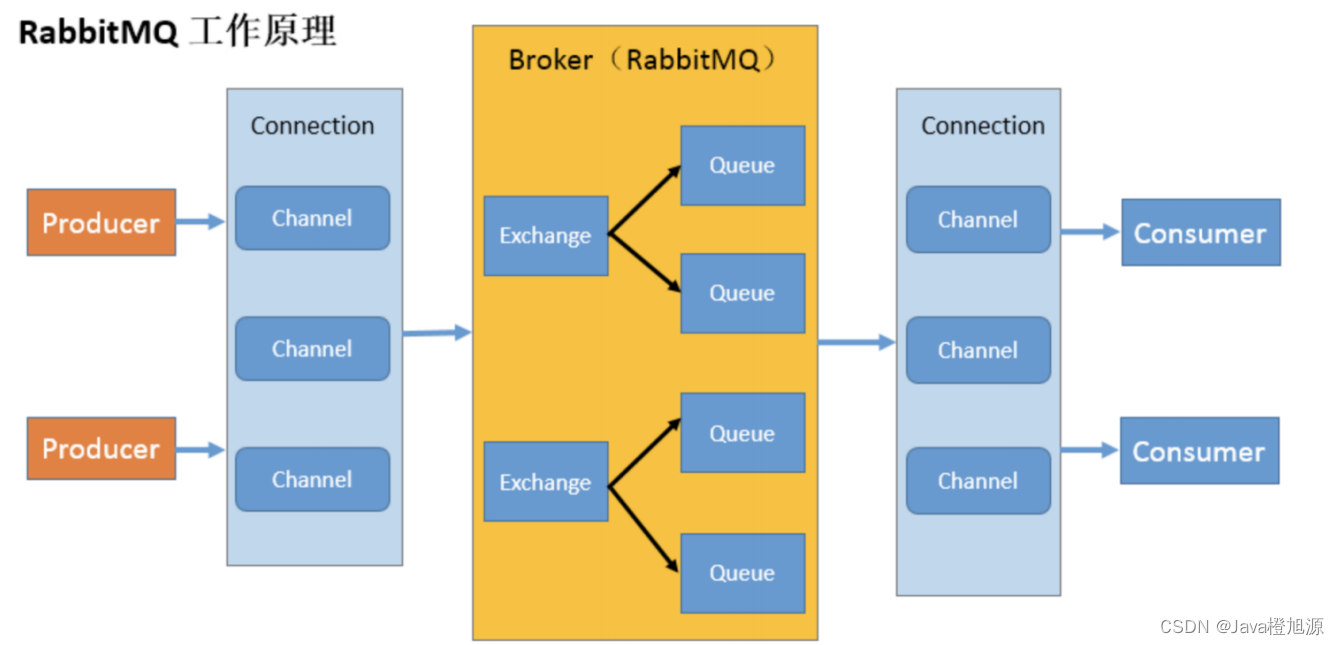
初识RabbitMQ - 安装 - 搭建基础环境
RabbitMQ 各个名词介绍 Broker:接收和分发消息的应用,RabbitMQ Server 就是 Message Broker Virtual host:出于多租户和安全因素设计的,把 AMQP 的基本组件划分到一个虚拟的分组中,类似于网络中的 namespace 概念。当…...

C/C++ #运算符、##运算符、变参宏 ...和_ _VA_ARGS_ _
文章目录 用宏参数创建字符串:#运算符函数宏#号作为一个预处理运算符,可以把记号转换成字符串 预处理器粘合剂:##运算符变参宏:...和_ _VA_ARGS_ _参考 用宏参数创建字符串:#运算符 函数宏 下面是一个类函数宏&#…...

【全网首发】【Python】Python控制parrot ARDrone 2.0无人机
🎉欢迎来到Python专栏~Python控制parrot ARDrone 2.0无人机 ☆* o(≧▽≦)o *☆嗨~我是小夏与酒🍹 ✨博客主页:小夏与酒的博客 🎈该系列文章专栏:Python学习专栏 文章作者技术和水平有限,如果文中出现错误…...
DPU国产生态版图又双叒扩大了
DPU朋友圈迎来30新伙伴!近期,中科驭数已与联想、中科可控、统信、欧拉、龙蜥社区、新支点、亚信科技、人大金仓、瀚高、南大通用、GreatSQL、阿里云、曙光云等超30家关键厂商完成兼容性互认证。测试报告显示,中科驭数DPU系列产品在产品兼容性…...

YOLOv5算法进阶改进(3)— 引入深度可分离卷积C3模块 | 轻量化网络
前言:Hello大家好,我是小哥谈。深度可分离卷积是一种卷积神经网络中的卷积操作,它可以将标准卷积分解为两个较小的卷积操作:深度卷积和逐点卷积。深度卷积是在每个输入通道上分别执行卷积,而逐点卷积是在所有通道上执行卷积。这种分解可以大大减少计算量和参数数量,从而提…...

Linux的root用户
拥有最大权限的用户名为root su和exit命令 su命令就是用于账户切换的系统命令Switch user 语法:su - [用户名] -符号可选,表示是否在切换用户后加载环境变量,建议带上 参数:用户名,表示要切换的用户,用…...

linux环境安装SVN,以及常用的SVN操作
1、检查系统是否已经安装如果安装就卸载 检查: svnserve --version 卸载: yum remove subversion 2、安装 yum install subversion 3、建立SVN库(文件位置可自由) 创建仓库文件夹: mkdir -p /opt/svn/repositor…...

30天精通Nodejs--第十天:OS
目录 引言OS 模块简介核心概念基本用法获取 CPU 架构获取内存信息获取系统平台高级特性CPUS网络接口引言 os 模块是一个非常重要的组成部分,它提供了一系列用于获取和处理操作系统信息的工具函数,使得我们能够在 Node.js环境中获取有关系统的各种信息。在本文中,将深入介绍…...
C#使用时序数据库 InfluxDB
一、安装 https://docs.influxdata.com/influxdb/v2/install/?tWindows 解压后使用cmd运行 访问 localhost:8086 配置 第一次登入会初始化 配置登入账号 保存TOKEN 这个TOKEN用于后期代码链接访问数据库,忘记了只能删除重新生成 点击QUCK START进入管理页面 …...

64_《智能体微服务架构企业级实战教程》授权与认证之授权认证集成测试
前言 配套视频教程: 在 Bilibili课堂、CSDN课程、51CTO学堂 同步发售,提供:源码+部署脚本+文档。 bilibili课堂视频教程:智能体微服务架构企业级实战教程_哔哩哔哩_bilibili CSDN课程视频教程:智能体微服务架构企业级实战教程_在线视频教程-CSDN程序员研修院 51CTO学堂…...

科华UPS电源全品类汇总:选型与场景适配指南
科华UPS电源作为国内智慧电能领域的主流产品,覆盖家用、办公、机房、工业等全场景,产品系列丰富、规格齐全,但多数用户在选型时,常因分不清系列差异、功率适配、架构类型而踩坑。本文系统汇总科华UPS电源的核心分类、主流系列、核…...

基于Arduino与nRF24L01+的无线传感器平台设计与部署指南
1. 项目概述与设计思路如果你和我一样,喜欢在阳台或者小院子里种点蔬菜瓜果,那你肯定也遇到过这样的烦恼:出门几天,心里总惦记着家里的番茄苗是不是缺水了,小温室里的温度会不会太高。传统的温湿度计只能让你在现场读数…...

AI率总超标?2026年AI写作辅助网站排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重不过关?别慌!2026 年最新 AI 论文写作工具合集来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!🏆…...

如何快速掌握Avidemux:新手完整入门指南与5个核心技巧
如何快速掌握Avidemux:新手完整入门指南与5个核心技巧 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 Avidemux是一款功能强大且完全开源的专业视频编辑工具,专为快速剪辑、…...

Style-Bert-VITS2未来发展方向:从语音克隆到实时语音转换的技术演进路线
Style-Bert-VITS2未来发展方向:从语音克隆到实时语音转换的技术演进路线 【免费下载链接】Style-Bert-VITS2 Style-Bert-VITS2: Bert-VITS2 with more controllable voice styles. 项目地址: https://gitcode.com/gh_mirrors/st/Style-Bert-VITS2 Style-Bert…...

Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式 对于技术管理者或项目负责人而言,清晰了解团队的AI…...

开源三角洲机器人Delta-Robot One:从入门到精通的创客实践指南
1. 项目概述:一个为学习而生的开源三角洲机器人如果你对机器人感兴趣,但又觉得它高深莫测、无从下手,那么Delta-Robot One(我们亲切地称它为“One”)可能就是为你量身打造的入门项目。这不是一个遥不可及的工业设备&am…...

从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法
从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法在MOBA游戏中,野怪沿着固定路线巡逻时突然转向追击玩家;RTS战场上,上百个单位向同一目标点移动却能保持整齐队形;潜行游戏中&…...

鸿蒙HarmonyOS 5与Unity跨运行时通信实战指南
1. 这不是“调个API”那么简单:为什么鸿蒙Unity通信总在临门一脚卡住我第一次把Unity打包的AR模块塞进HarmonyOS 5 App里时,信心满满——毕竟文档里写着“支持JS/ArkTS调用Native能力”,Unity也标榜“跨平台通用”。结果呢?App一启…...