postgreSQL中的高速缓存
1. 高速缓存简介
如下图所示,当一个postgreSQL进程读取一个元组时,需要获取表的基本信息(例如:表的oid、索引信息和统计信息等)及元组的模式信息,这些信息被分别记录在多个系统表中。通常一个表的模式信息在设定好后的变化频率很低,因此在对同一个表的多个元组操作时,每次都去读取系统表的元组来构建模式信息显然是没有必要的,这也会降低元组的操作效率。为了减少对系统表的访问,在每个进程的本地内存区域设置了两种cache,一种是用来存储系统表的元组,一种是用来存储表的基本信息,从而可以让进程更快的构建出表的基本信息和元组的模式信息。cache在某一个进程对系统表发生更改时其他的 backend 进程要能够感知到,需要有一套维护cache 一致性的机制,也就是 PG 的 InvalidMessage机制。
用户表是如何被管理的,参考:https://zhuanlan.zhihu.com/p/623283855

2. SysCache
syscache主要用来缓存最近使用过的系统表的元组。从代码实现看,syscache就是一个catcache数组,数组的长度为系统表的个数,每一个系统表唯一的对应catcache数组的一个元素。
- catcache数据结构
typedef struct catcache
{int id; /* catcache id */int cc_nbuckets; /* # of hash buckets in this cache */TupleDesc cc_tupdesc; /* tuple descriptor (copied from reldesc) */dlist_head *cc_bucket; /* hash buckets */CCHashFN cc_hashfunc[CATCACHE_MAXKEYS]; /* hash function for each key */CCFastEqualFN cc_fastequal[CATCACHE_MAXKEYS]; /* fast equal function for* each key */int cc_keyno[CATCACHE_MAXKEYS]; /* AttrNumber of each key */dlist_head cc_lists; /* list of CatCList structs */int cc_ntup; /* # of tuples currently in this cache */int cc_nkeys; /* # of keys (1..CATCACHE_MAXKEYS) */const char *cc_relname; /* name of relation the tuples come from */Oid cc_reloid; /* OID of relation the tuples come from */Oid cc_indexoid; /* OID of index matching cache keys */bool cc_relisshared; /* is relation shared across databases? */slist_node cc_next; /* list link */ScanKeyData cc_skey[CATCACHE_MAXKEYS]; /* precomputed key info for heap* scans *//** Keep these at the end, so that compiling catcache.c with CATCACHE_STATS* doesn't break ABI for other modules*/
#ifdef CATCACHE_STATSlong cc_searches; /* total # searches against this cache */long cc_hits; /* # of matches against existing entry */long cc_neg_hits; /* # of matches against negative entry */long cc_newloads; /* # of successful loads of new entry *//** cc_searches - (cc_hits + cc_neg_hits + cc_newloads) is number of failed* searches, each of which will result in loading a negative entry*/long cc_invals; /* # of entries invalidated from cache */long cc_lsearches; /* total # list-searches */long cc_lhits; /* # of matches against existing lists */
#endif
} CatCache;
2.1 syscache初始化
在对postgres进程初始化时,会对syscache进行初始化,将查找系统表元组的关键信息写入到catcache数组的元素中。
涉及到的数据结构如下:
-
cacheinfo:存储所有系统表的catcache描述信息
struct cachedesc {Oid reloid; /* OID of the relation being cached */Oid indoid; /* OID of index relation for this cache */int reloidattr; /* attr number of rel OID reference, or 0 */int nkeys; /* # of keys needed for cache lookup */int key[4]; /* attribute numbers of key attrs */int nbuckets; /* number of hash buckets for this cache */ };static const struct cachedesc cacheinfo[] = {{AggregateRelationId, /* AGGFNOID */AggregateFnoidIndexId,1,{Anum_pg_aggregate_aggfnoid,0,0,0},16},...} -
catcacheheader:catcache使用cc_next字段构成一个单向链表,头部使用此结构体记录
typedef struct catcacheheader {slist_head ch_caches; /* head of list of CatCache structs */int ch_ntup; /* # of tuples in all caches */ } CatCacheHeader;
初始化阶段1:使用cacheinfo初始化catcache数组
typedef struct catcache
{...TupleDesc cc_tupdesc; /* tuple descriptor (copied from reldesc) */int cc_nbuckets; /* # of hash buckets in this cache */dlist_head *cc_bucket; /* hash buckets */int cc_keyno[CATCACHE_MAXKEYS]; /* AttrNumber of each key */int cc_nkeys; /* # of keys (1..CATCACHE_MAXKEYS) */Oid cc_reloid; /* OID of relation the tuples come from */Oid cc_indexoid; /* OID of index matching cache keys */...
}
初始化阶段2:根据对应的系统表填充catcache中元组描述信息(cc_tupdesc)、系统表名(cc_relname)和查找关键字的相关字段
typedef struct catcache
{...CCHashFN cc_hashfunc[CATCACHE_MAXKEYS]; /* hash function for each key */CCFastEqualFN cc_fastequal[CATCACHE_MAXKEYS]; /* fast equal function for each key */const char *cc_relname; /* name of relation the tuples come from */bool cc_relisshared; /* is relation shared across databases? */ScanKeyData cc_skey[CATCACHE_MAXKEYS]; /* precomputed key info for heap scans */...
}
2.2 catcache中缓存元组的组织
每个catcache元素中cc_bucket数组是一个Hash桶数组,元组的键值可以通过hash函数映射到cc_bucket数组的下标。每个hash桶都被组织成一个双向链表Dllist,其中的节点为Dlelem类型,Dlelem是一个包装过的缓存元组,其dle_val字段指向一个CatCTup形式的缓存元组。

CatCache中的缓存元组将先包装成CatCTup形式,然后再包装成Dlelem形式,最后加入到其所在的hash桶链表中。
typedef struct dlist_node dlist_node;
struct dlist_node
{dlist_node *prev;dlist_node *next;
};
typedef struct catctup
{int ct_magic; /* for identifying CatCTup entries */
#define CT_MAGIC 0x57261502uint32 hash_value; /* hash value for this tuple's keys */Datum keys[CATCACHE_MAXKEYS];dlist_node cache_elem; /* list member of per-bucket list */int refcount; /* number of active references */bool dead; /* dead but not yet removed? 标记删除*/bool negative; /* negative cache entry? 表示实际并不存在的元组*/HeapTupleData tuple; /* tuple management header */struct catclist *c_list; /* containing CatCList, or NULL if none */CatCache *my_cache; /* link to owning catcache */
} CatCTup;
2.3 在catcache中查找元组
在catcache查找元组有两种方式:精确匹配和部分匹配。
- 精确匹配
精确匹配由SearchCatCache函数实现:
HeapTuple
SearchCatCache(CatCache *cache,Datum v1,Datum v2,Datum v3,Datum v4);
- 首先遍历catcacheheader链表,根据系统表名称或者oid查找到系统表对应的catcache元素。
- 查找元组键值进行hash,根据hash值找到catcache在cc_bucket数组中对应的hash桶下标。
- 遍历hash桶链表,找到满足需求的Dlelem,并将其结构体中dle_val强制转换为CatCTup类型,CatCTup中的HeapTupleData就是要查找的元组的头部。
- 将该Dlelem移动到hash桶链表的头部,并将catcache的cc_hits加1。
- 如果在hash桶链表中没有找到满足条件的元组,需要进一步扫描物理系统表:
- 如果在物理系统表中查找到元组,将元组包装成Dlelem,添加到hash桶链表的头部;
- 否则,说明元组不存在,构建一个“负元组”,并将它包装好,添加到hash桶链表的头部。

2. 部分匹配
部分匹配由SearchCatCacheList实现:
SearchCatCacheList(CatCache *cache,int nkeys,Datum v1,Datum v2,Datum v3)
该函数返回一个CatCList数据结构,返回的所有结果通过链表的方式管理。
typedef struct catclist
{int cl_magic; /* for identifying CatCList entries */
#define CL_MAGIC 0x52765103uint32 hash_value; /* hash value for lookup keys */dlist_node cache_elem; /* list member of per-catcache list *//** Lookup keys for the entry, with the first nkeys elements being valid.* All by-reference are separately allocated.*/Datum keys[CATCACHE_MAXKEYS];int refcount; /* number of active references */bool dead; /* dead but not yet removed? */bool ordered; /* members listed in index order? */short nkeys; /* number of lookup keys specified */int n_members; /* number of member tuples */CatCache *my_cache; /* link to owning catcache */CatCTup *members[FLEXIBLE_ARRAY_MEMBER]; /* members */
} CatCList;查找过程:

3. RelCache
RelCache存放的不是元组,而是RelationData数据,每一个RelationData结构表示一个表的模式信息,这些信息由系统表元组中的信息构造而来。
typedef struct RelationData
{RelFileNode rd_node; /* relation physical identifier */struct SMgrRelationData *rd_smgr; /* 表的文件句柄 */
。 ...Form_pg_class rd_rel; /* 表在pg_class系统表中对应的元组里的信息 */TupleDesc rd_att; /* 表的元组描述符,描述了表的各个属性 */Oid rd_id; /* relation's object id */List *rd_indexlist; /* list of OIDs of indexes on relation */Bitmapset *rd_indexattr; /* identifies columns used in indexes */Oid rd_oidindex; /* OID of unique index on OID, if any */...Form_pg_index rd_index; /* pg_index tuple describing this index */...
} RelationData;
由于RelationData数据结构是不变的,采用了hash表维持这个结构。这个hash表也是 PG 内部应用最多最广的 hash 数据结构,其性能和稳定性在PostgreSQL 近三十年的生涯中历经磨练。这个 hash表的实现也是非常值得学习的工业级数据结。
动态hash表介绍参考:https://zhmin.github.io/posts/postgresql-dynamic-hash/
3.1 relcache初始化
初始化阶段1:调用RelationCacheInitialize函数进行初始化,创建hash表。
初始化阶段2:将必要的系统表和系统表索引的模式加入到RelCache中,包括pg_class、pg_attribute、pg_proc、pg_type。
3.2 relcache的操作
-
插入新打开的表
当打开新表时,需要把RelationData加入到RelCache中,该操作通过宏
RelationCacheInsert来实现。 -
查找hash表
查找hash表通过宏定义
RelationIdCacheLookup来实现,调用函数hash_search。relation_openRelationIdGetRelationRelationIdCacheLookup(relationId, rd);RelationBuildDesc -- no reldesc in the cache, RelationBuildDesc() build one and add it.RelationBuildTupleDesc....RelationCacheInsert(relation); -
从hash表中删除
从hash表中删除元素通过宏定义RelationCacheDelete实现。RelationClearRelationRelationCacheDelete
相关文章:
postgreSQL中的高速缓存
1. 高速缓存简介 如下图所示,当一个postgreSQL进程读取一个元组时,需要获取表的基本信息(例如:表的oid、索引信息和统计信息等)及元组的模式信息,这些信息被分别记录在多个系统表中。通常一个表的模式信…...

我把MySQL运行在Docker上,差点完了……
容器的定义:容器是为了解决“在切换运行环境时,如何保证软件能够正常运行”这一问题。 目前,容器和 Docker 依旧是技术领域最热门的词语,无状态的服务容器化已经是大势所趋,同时也带来了一个热点问题被大家所争论不以&…...

【华为OD题库-023】文件目录大小-java
题目 一个文件目录的数据格式为:目录id,本目录中文件大小,(子目录id列表)。其中目录id全局唯一, 取值范围[1 ,200],本目录中文件大小范围[1,1000],子目录id列表个数[0,10] 例如: 1 20 (2,3)表示目录1中文件总大小是20,有两个子目录…...
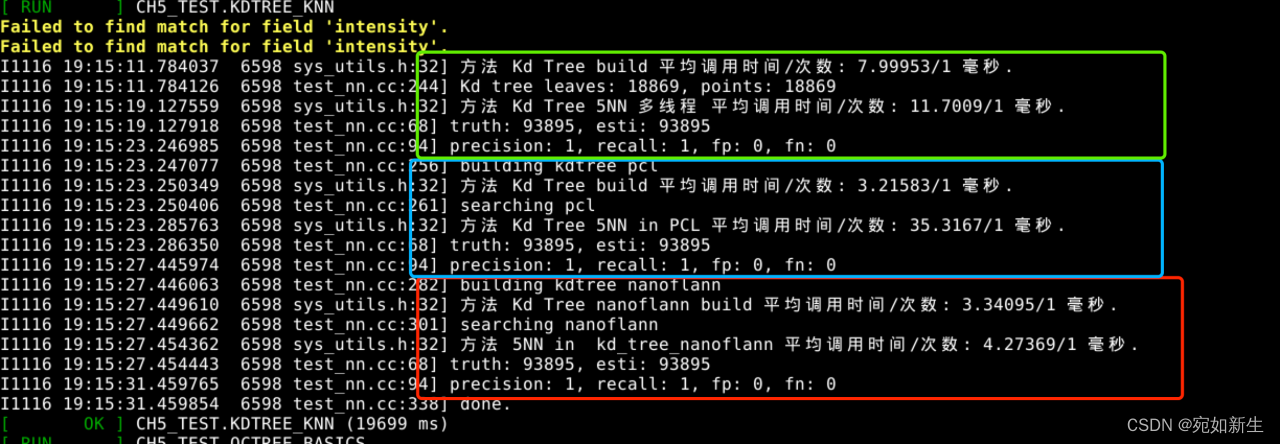
4. 【自动驾驶与机器人中的SLAM技术】点云中的拟合问题和K近邻
目录 1.在三维体素中定义 NEARBY14,实现 14 格最近邻的查找。2.推导arg max||Ad||22的解为ATA的最大特征向量或者奇异向量。3. 将本节的最近邻算法与一些常见的近似最近邻算法进行对比,比如nanoflann,给出精度指标和时间效率指标。4. 也欢迎大…...

正点原子嵌入式linux驱动开发——Linux ADC驱动
在之前的笔记中,学习了如何给ICM20608编写IIO驱动,ICM20608本质就是ADC,因此纯粹的ADC驱动也是IIO驱动框架的。本章就学习一下如何使用STM32MP1内部的ADC,并且在学习巩固一下IIO驱动。 ADC简介 ADC ADC,Analog to D…...

自动化测试介绍和分类,看这一篇就够了
📢专注于分享软件测试干货内容,欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!📢交流讨论:欢迎加入我们一起学习!📢资源分享:耗时200小时精选的「软件测试」资…...

Debian中执行脚本 提示没有那个文件或目录
原因是在脚本头有句: ~/.bash_profile这个在CentOS里执行是正常的,但在Debian中是没有的,它改成了: ~/.profile一、区别: 1、/etc/profile: 此文件为系统的每个用户设置环境信息,当用户第一次登录时,该文…...
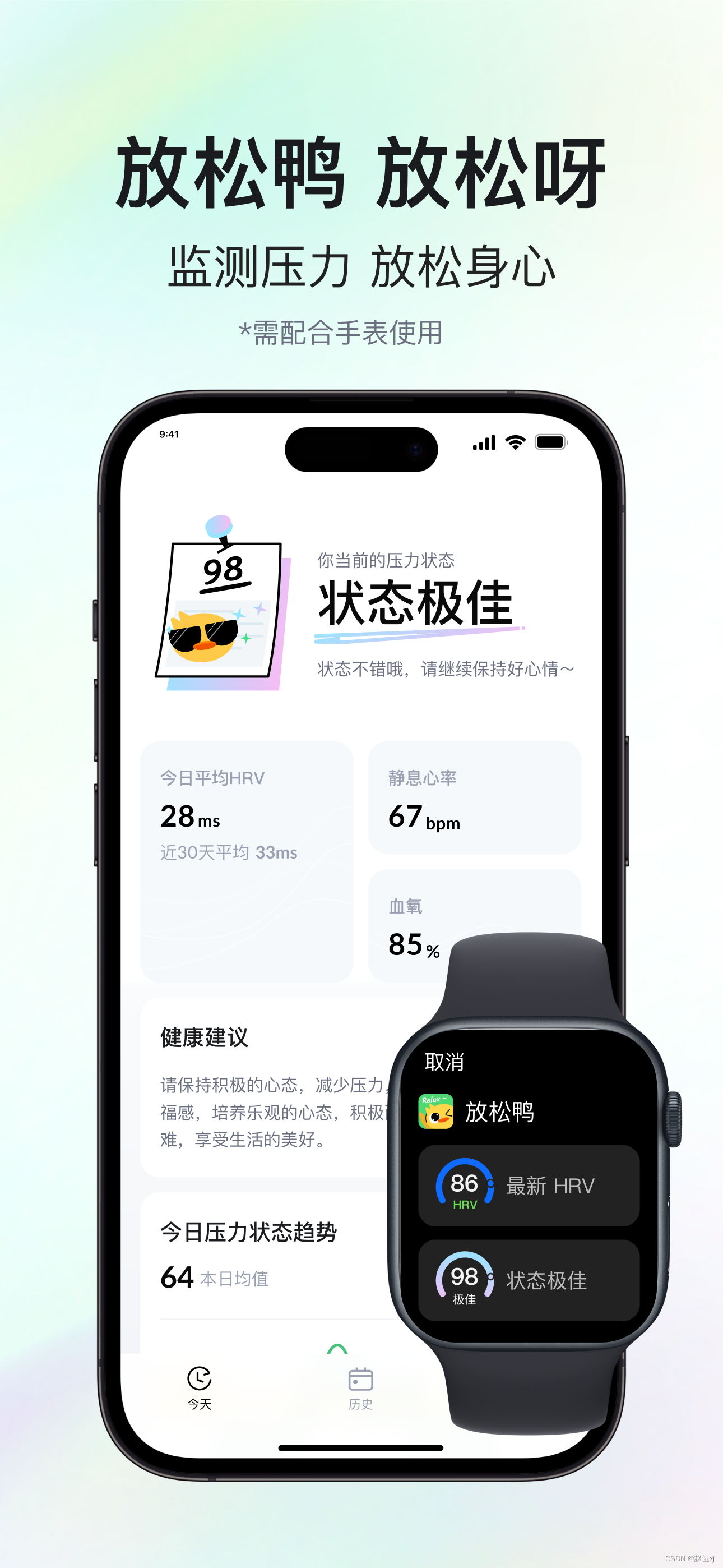
放松鸭-技术支持
“放松鸭”利用苹果手表的HRV心率变异性和静息心率等数据进行分析,帮助您了解当前身体疲劳和心理压力程度,并及时提醒您的压力状态。我们的目标是让您更好地感知、管理和应对压力,让您的身心得到平静和放松。通过读取您的心脏数据,…...

Vue 报错error:0308010C:digital envelope routines::unsupported
你遇到的错误,error:0308010C:digital envelope routines::unsupported,与 OpenSSL 相关,表明在你的 Vue.js 应用中可能存在与加密操作相关的问题。这种错误通常出现在 OpenSSL 库存在不匹配或问题的情况下。 以下是解决此问题的一些建议&am…...

Android 9.0 隐藏设置中一级菜单“已连接的设备”
Android 9.0 隐藏设置中一级菜单“已连接的设备” 接到客户反馈需要隐藏设备设置中的“已连接的设备”一级菜单,具体修改参照如下: /vendor/mediatek/proprietary/packages/apps/MtkSettings/src/com/android/settings/SettingsActivity.java somethin…...
)
Hive开窗函数根据特定条件取上一条最接近时间的数据(根据条件取窗口函数的值)
一、Hive开窗函数根据特定条件取上一条最接近时间的数据(单个开窗函数,实际取两个窗口) 针对于就诊业务,一次就诊,多个处方,处方结算时间可能不一致,然后会有多个AI助手推荐用药,会…...

指针与函数
指针函数:函数的返回值可以是整型值、浮点型值、字符型值等,在C语言中还允许一个函数的返回值是一个指针(地址),这种返回指针的函数称为指针函数。 指针函数语法格式: 基类型 * 函数名(参数列…...
GBase8a-GDCA-第二次阶段测试
文章目录 主要内容在这里插入图片描述 在这里插入图片描述 总结 主要内容 GBase8a-GDCA-第二次阶段测试及答案 总结 以上是今天要讲的内容,GBase8a-GDCA-第二次阶段测试…...

Go 理解零值
在 Go 语言中,零值(Zero Value)是指在声明变量但没有显式赋值的情况下,变量会被自动赋予一个默认值。这个默认值取决于变量的类型,不同类型的变量会有不同的零值。零值是 Go 语言中的一个重要概念,因为它确…...

SQL编写规范【干货】
编写本文档的目的是保证在开发过程中产出高效、格式统一、易阅读、易维护的SQL代码。 1 编写目 2 SQL书写规范 3 SQL编写原则 获取所有软件开发资料:点我获取...
2.5 Windows驱动开发:DRIVER_OBJECT对象结构
在Windows内核中,每个设备驱动程序都需要一个DRIVER_OBJECT对象,该对象由系统创建并传递给驱动程序的DriverEntry函数。驱动程序使用此对象来注册与设备对象和其他系统对象的交互,并在操作系统需要与驱动程序进行交互时使用此对象。DRIVER_OB…...

[ubuntu]ubuntu上安装jdk1.8教程
首先需要去官方网站去下载对应jdk1.8版本: https://www.oracle.com/java/technologies/downloads/ 您也可以去csdn搜索我提供jdk安装包 这里以jdk-8u201-linux-x64.tar.gz为例子,首先下载安装后解压 tar -zxvf jdk-8u201-linux-x64.tar.gz 比如我解…...
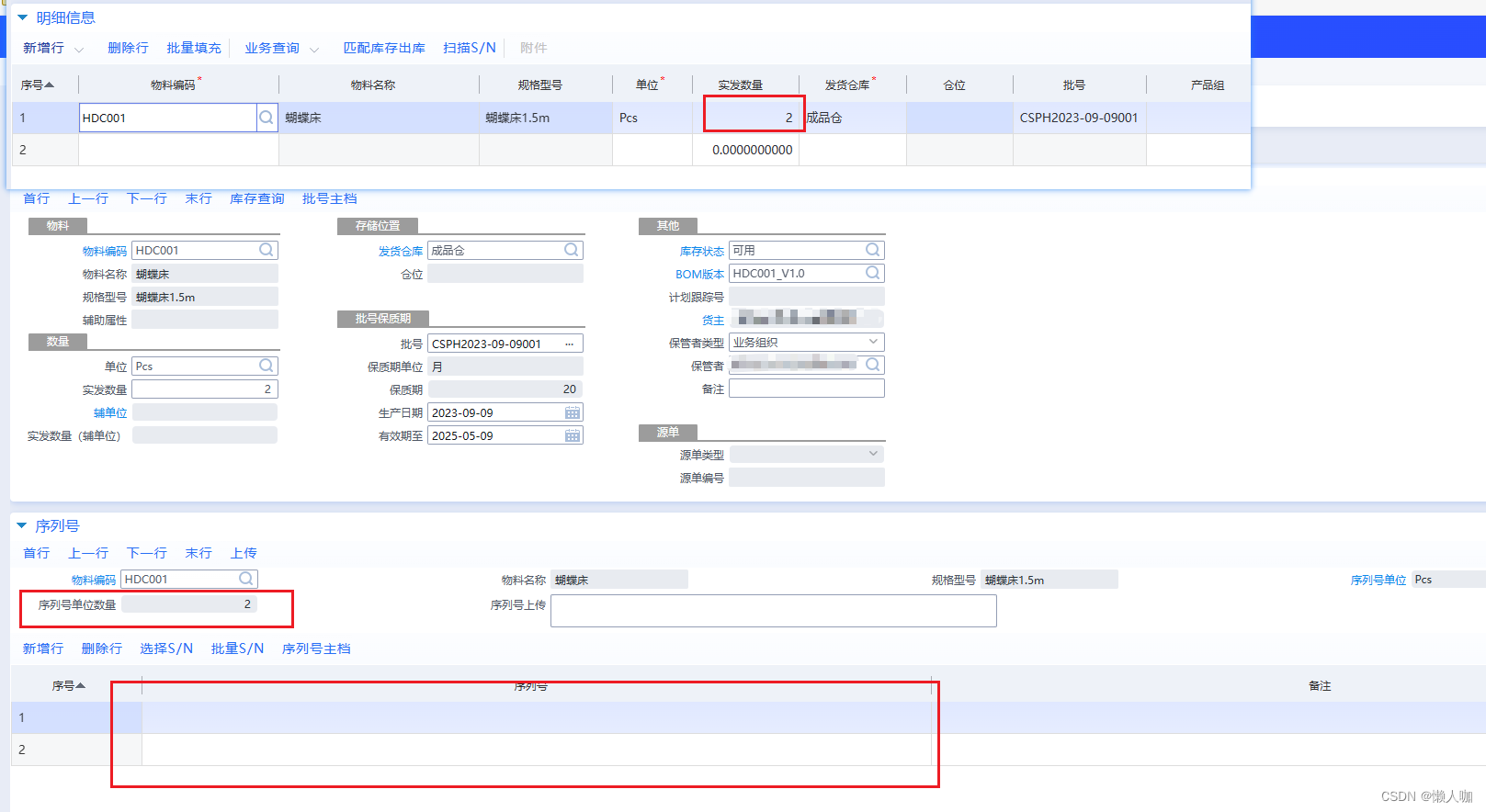
金蝶云星空其他出库单保存提示序列号不一致
文章目录 金蝶云星空其他出库单保存提示序列号不一致保存报错初步分析总结 金蝶云星空其他出库单保存提示序列号不一致 保存报错 显示单据数量0.序列号数量3 初步分析 输入实发数量没有触发序列号数量的计算 检查实发数量的值更新事件 实发数量和序列号数量的转换ÿ…...

FBI:皇家勒索软件要求350名受害者支付2.75亿美元
导语 最近,FBI和CISA联合发布的一份通告中透露,自2022年9月以来,皇家勒索软件(Royal ransomware)已经入侵了全球至少350家组织的网络。这次更新的通告还指出,这个勒索软件团伙的赎金要求已经超过了2.75亿美…...

Layout工程师们--Allegro X AI实现pcb自动布局布线
Cadence 推出 Allegro X AI,旨在加速 PCB 设计流程,可将周转时间缩短 10 倍以上 楷登电子(美国 Cadence 公司,NASDAQ:CDNS)今日宣布推出 Cadence Allegro X AI technology,这是 Cadence 新一代…...

告别打包焦虑:UE5 Windows与安卓打包速度优化与稳定性提升全攻略
告别打包焦虑:UE5 Windows与安卓打包速度优化与稳定性提升全攻略在虚幻引擎5(UE5)开发流程中,打包环节往往是开发者体验的分水岭——顺畅的打包过程能保持创作心流,而频繁的报错和漫长等待则会严重消耗开发热情。本文将…...

JMeter接口功能测试实战:从契约解码到全链路断言
1. 这不是“点点点”的接口测试,而是用JMeter把业务逻辑钉在验证线上 很多人第一次打开JMeter,看到那个树形结构、一堆监听器和配置元件,下意识就把它当成“高级版Postman”——填个URL、加几个参数、点“启动”,看绿色小三角跑起…...

Java的背景知识及快速入门
Java的背景知识1.Java的历史知识Java是哪家公司的产品?Java是美国Sun(Stanford University Network,斯坦福大学网络公司)公司在1995年推出的一 门计算机高级编程语言。但是在2009年是Sun公司被Oracle(甲骨文࿰…...
)
【AI问答/前端】前端瞒天过海局(三)
问三:还有一件事,就是浏览器按钮的前进后退,他真实还原了js改前端的过程,就好像真的有过访问纪录,这个是JS纪录下了自己的路由操作历史,改的浏览器地址栏?还是这个路由操作历史真的是写进了浏览…...

Web渗透信息收集实战:从被动侦察到精准测绘
1. 这不是“黑客速成班”,而是Web渗透工程师的日常切片很多人点开“精通 Kali Linux Web 渗透测试”这个标题,第一反应是:又要教怎么黑进某个网站了?其实恰恰相反——我带过的二十多个渗透测试新人里,前两周最常犯的错…...

网络技术05-TCP拥塞控制算法——从CUBIC到BBR的性能进化
🚗 一句话总结:TCP拥塞控制就像开车——看到前面堵车就减速(拥塞避免),路通畅了就慢慢加速(慢启动)。CUBIC是"看到堵车就猛踩刹车",BBR是"根据路况预测提前调整"…...

告别低效写作:盘点2026年顶尖配置的的降AI率网站
轻松降低论文AI率在2026年已不再是难题。最新实测数据显示,2026年降AI率网站正以惊人的效率改变写作方式,覆盖AI痕迹消除、文本优化、降重处理等关键场景,真正实现高效去AI化,让论文修改不再费时费力。 一、全流程王者:…...

2026论文写作工具红黑榜:AI论文工具怎么选?别再瞎找了!
2026年论文写作工具红黑榜出炉,红榜优先推荐千笔AI、ThouPen、豆包,适配国内学术规范,提升写作效率;黑榜需避开低质免费工具、无真实引用平台、过度依赖全文生成的工具。选择时应按需求匹配三维模型(需求匹配度 - 数据…...

终极指南:5分钟快速上手Eclipse Ditto数字孪生平台
终极指南:5分钟快速上手Eclipse Ditto数字孪生平台 【免费下载链接】ditto Eclipse Ditto™: Digital Twin framework of Eclipse IoT - main repository 项目地址: https://gitcode.com/gh_mirrors/ditto6/ditto 想要在物联网项目中轻松管理成千上万的设备吗…...
【含Matlab源码 15560期】)
【流体】对沼气厂管道系统进行流体动力学设计和成本优化(最小化总年化成本TAC)【含Matlab源码 15560期】
💥💥💥💥💥💥💥💥💞💞💞💞💞💞💞💞💞Matlab武动乾坤博客之家💞…...