大数据框架之Hadoop:MapReduce(三)MapReduce框架原理——Join多种应用
3.7.1Reduce Join
1、工作原理
Map端的主要工作:为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。
Reduce端的主要工作:在Reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在Map阶段已经达标)分开,最后进行合并就ok了。
3.7.2Reduce Join案例实操
1、需求
将商品信息表中数据根据商品pid合并到订单数据表中。
1)输入
order.txt
1001 01 1
1002 02 2
1003 03 3
1004 01 4
1005 02 5
1006 03 6
pd.txt
01 小米
02 华为
03 格力
2)输出
1001 小米 1
1001 小米 1
1002 华为 2
1002 华为 2
1003 格力 3
1003 格力 3
2、需求分析
通过将关联条件作为Map输出的key,将两表满足Join条件的数据并携带数据所来源的文件信息,发往同一个ReduceTask,在Reduce中进行数据的串联,如图4-20所示。
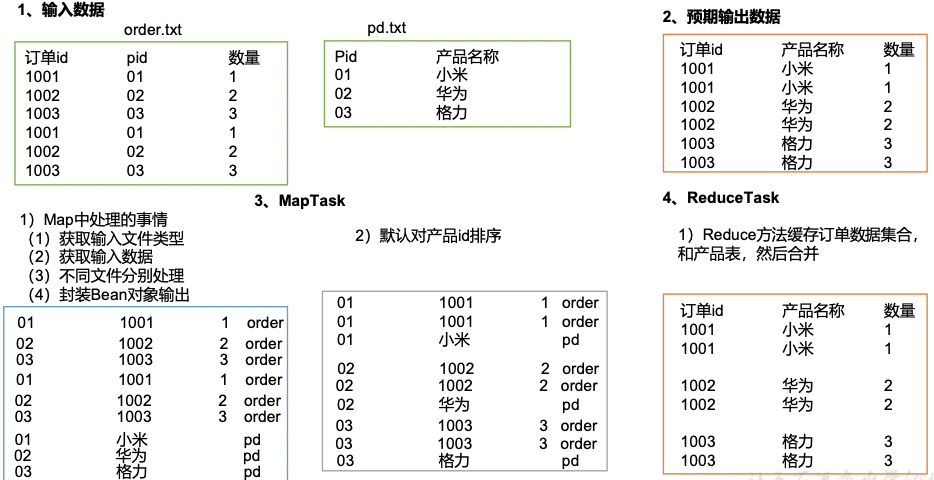
3、代码实现
1)创建商品和订合并后的Bean类
package com.cuiyf41.join;import org.apache.hadoop.io.Writable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;public class TableBean implements Writable {private String order_id; // 订单idprivate String p_id; // 产品idprivate int amount; // 产品数量private String pname; // 产品名称private String flag; // 表的标记public TableBean() {super();}public TableBean(String order_id, String p_id, int amount, String pname, String flag) {super();this.order_id = order_id;this.p_id = p_id;this.amount = amount;this.pname = pname;this.flag = flag;}@Overridepublic void write(DataOutput out) throws IOException {out.writeUTF(order_id);out.writeUTF(p_id);out.writeInt(amount);out.writeUTF(pname);out.writeUTF(flag);}@Overridepublic void readFields(DataInput in) throws IOException {order_id = in.readUTF();p_id = in.readUTF();amount = in.readInt();pname = in.readUTF();flag = in.readUTF();}@Overridepublic String toString() {return order_id + "\t" + pname + "\t" + amount;}public String getOrder_id() {return order_id;}public void setOrder_id(String order_id) {this.order_id = order_id;}public String getP_id() {return p_id;}public void setP_id(String p_id) {this.p_id = p_id;}public int getAmount() {return amount;}public void setAmount(int amount) {this.amount = amount;}public String getPname() {return pname;}public void setPname(String pname) {this.pname = pname;}public String getFlag() {return flag;}public void setFlag(String flag) {this.flag = flag;}
}
2)编写TableMapper类
package com.cuiyf41.join;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;import java.io.IOException;public class TableMapper extends Mapper<LongWritable, Text, Text, TableBean> {String name;TableBean bean = new TableBean();Text k = new Text();@Overrideprotected void setup(Mapper<LongWritable, Text, Text, TableBean>.Context context) throws IOException, InterruptedException {// 1 获取输入文件切片FileSplit split = (FileSplit) context.getInputSplit();// 2 获取输入文件名称name = split.getPath().getName();}@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, TableBean>.Context context) throws IOException, InterruptedException {// 1 获取输入数据String line = value.toString();// 2切割String[] fields = line.split("\t");// 3 不同文件分别处理if (name.startsWith("order")) {// 订单表处理// 3.1 封装bean对象bean.setOrder_id(fields[0]);bean.setP_id(fields[1]);bean.setAmount(Integer.parseInt(fields[2]));bean.setPname("");bean.setFlag("order");k.set(fields[1]);} else {// 产品表处理// 3.2 封装bean对象bean.setP_id(fields[0]);bean.setPname(fields[1]);bean.setFlag("pd");bean.setAmount(0);bean.setOrder_id("");k.set(fields[0]);}// 4 写出context.write(k, bean);}
}
3)编写TableReducer类
package com.cuiyf41.join;import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
import java.util.ArrayList;public class TableReducer extends Reducer<Text,TableBean, TableBean, NullWritable> {@Overrideprotected void reduce(Text key, Iterable<TableBean> values, Reducer<Text, TableBean, TableBean, NullWritable>.Context context) throws IOException, InterruptedException {// 1准备存储订单的集合ArrayList<TableBean> orderBeans = new ArrayList<>();// 2 准备bean对象TableBean pdBean = new TableBean();for (TableBean bean : values) {if ("order".equals(bean.getFlag())) {// 订单表// 拷贝传递过来的每条订单数据到集合中TableBean tmpBean = new TableBean();try {BeanUtils.copyProperties(tmpBean, bean);} catch (Exception e) {e.printStackTrace();}orderBeans.add(tmpBean);} else {// 产品表try {// 拷贝传递过来的产品表到内存中BeanUtils.copyProperties(pdBean, bean);} catch (Exception e) {e.printStackTrace();}}}// 3 表的拼接for(TableBean bean:orderBeans) {bean.setPname(pdBean.getPname());// 4 数据写出去context.write(bean, NullWritable.get());}}
}
4)编写TableDriver类
package com.cuiyf41.join;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class TableDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {// 0 根据自己电脑路径重新配置args = new String[]{"e:/input/inputtable","e:/output1"};// 1 获取配置信息,或者job对象实例Configuration conf = new Configuration();Job job = Job.getInstance(conf);// 2 指定本程序的jar包所在的本地路径job.setJarByClass(TableDriver.class);// 3 指定本业务job要使用的Mapper/Reducer业务类job.setMapperClass(TableMapper.class);job.setReducerClass(TableReducer.class);// 4 指定Mapper输出数据的kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(TableBean.class);// 5 指定最终输出的数据的kv类型job.setOutputKeyClass(TableBean.class);job.setOutputValueClass(NullWritable.class);// 6 指定job的输入原始文件所在目录Path input = new Path(args[0]);Path output = new Path(args[1]);// 如果输出路径存在,则进行删除FileSystem fs = FileSystem.get(conf);if (fs.exists(output)) {fs.delete(output,true);}FileInputFormat.setInputPaths(job, input);FileOutputFormat.setOutputPath(job, output);// 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行boolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}
4、测试
运行程序查看结果
1001 小米 1
1001 小米 1
1002 华为 2
1002 华为 2
1003 格力 3
1003 格力 3
5、总结
缺点:这种方式中,合并的操作是在Reduce阶段完成的,Reduce端的处理压力太大,Map节点的运算负载则很低,资源利用率不高,且在Reduce杰顿极易产生数据倾斜。
解决方案:Map端实现数据合并。
Mapper:// 1 获取输入数据
3.7.3Map Join
一、概述
1)使用场景
Map Join适用于一张表十分小、一张表很大的场景。
2)优点
思考:在Reduce端处理过多的表,非常容易产生数据倾斜。怎么办?
在Map端缓存多张表,提前处理业务逻辑,这样增加Map端业务,减少Reduce端数据的压力,尽可能的减少数据倾斜。
3)具体办法:采用DistributedCache
(1)在Mapper的setup阶段,将文件读取到缓存集合中。
(2)在驱动函数中加载缓存。
// 缓存普通文件到Task运行节点。
job.addCacheFile(new URI("file://e:/cache/pd.txt"))
二、Map Join案例实操
1、需求
将商品信息表中数据根据商品pid合并到订单数据表中。
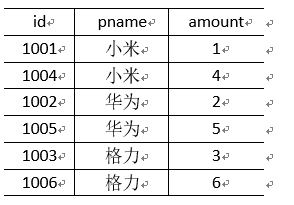
1)输入数据
order.txt
1001 01 1
1002 02 2
1003 03 3
1004 01 4
1005 02 5
1006 03 6
pd.txt
01 小米
02 华为
03 格力
2)输出数据
2、需求分析
MapJoin适用于关联表中有小表的情形。

3、实现代码
(1)先在驱动模块中添加缓存文件
package com.cuiyf41.mapjoin;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;public class DistributedCacheDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, URISyntaxException {// 0 根据自己电脑路径重新配置args = new String[]{"e:/input/inputtable2", "e:/output1"};// 1 获取job信息Configuration configuration = new Configuration();Job job = Job.getInstance(configuration);// 2 设置加载jar包路径job.setJarByClass(DistributedCacheDriver.class);// 3 关联mapjob.setMapperClass(DistributedCacheMapper.class);// 4 设置最终输出数据类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);// 5 设置输入输出路径FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));// 6 加载缓存数据job.addCacheFile(new URI("file:///e:/input/inputcache/pd.txt"));// 7 Map端Join的逻辑不需要Reduce阶段,设置reduceTask数量为0job.setNumReduceTasks(0);// 8 提交boolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}
(2)读取缓存的文件数据
package com.cuiyf41.mapjoin;import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;public class DistributedCacheMapper extends Mapper<LongWritable, Text, Text, NullWritable> {Map<String, String> pdMap = new HashMap<>();Text k = new Text();@Overrideprotected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {// 1 获取缓存的文件URI[] cacheFiles = context.getCacheFiles();String path = cacheFiles[0].getPath().toString();BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(path), "UTF-8"));String line;while(StringUtils.isNotEmpty(line = reader.readLine())){// 2 切割String[] fields = line.split("\t");// 3 缓存数据到集合pdMap.put(fields[0], fields[1]);}// 4 关流reader.close();}@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {// 1 获取一行String line = value.toString();// 2 截取String[] fields = line.split("\t");// 3 获取产品idString pId = fields[1];// 4 获取商品名称String pdName = pdMap.get(pId);// 5 拼接k.set(line + "\t"+ pdName);// 6 写出context.write(k, NullWritable.get());}
}
相关文章:
大数据框架之Hadoop:MapReduce(三)MapReduce框架原理——Join多种应用
3.7.1Reduce Join 1、工作原理 Map端的主要工作:为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。 Reduce端的主要工作:在Reduc…...

SSRF漏洞原理、危害以及防御与修复
一、SSRF漏洞原理漏洞概述SSRF(Server-side Request Forge,服务端请求伪造)是一种由攻击者构造形成由服务端发起请求的安全漏洞。一般情况下,SSRF攻击的目标是从外网无法访问的内部系统。正是因为它是由服务端发起的,所…...

CV学习笔记-ResNet
ResNet 文章目录ResNet1. ResNet概述1.1 常见卷积神经网络1.2 ResNet提出背景2. ResNet网络结构2.1 Residual net2.2 残差神经单元2.3 Shortcut2.4 ResNet50网络结构3. 代码实现3.1 Identity Block3.2 Conv Block3.3 ResNet网络定义3.4 整体代码测试1. ResNet概述 1.1 常见卷积…...
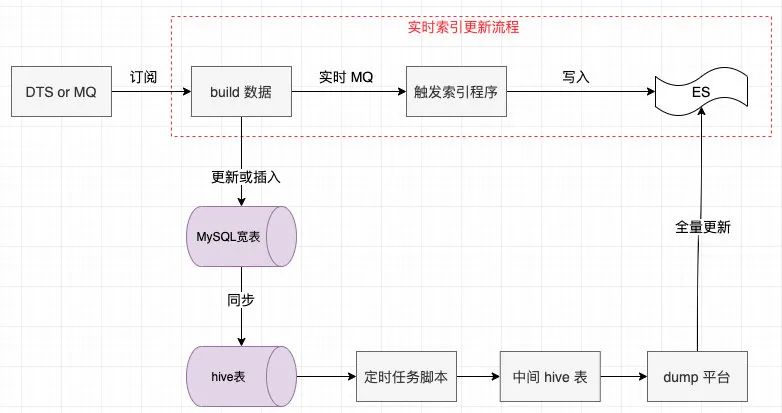
百亿数据,毫秒级返回查询优化
近年来公司业务迅猛发展,数据量爆炸式增长,随之而来的的是海量数据查询等带来的挑战,我们需要数据量在十亿,甚至百亿级别的规模时依然能以秒级甚至毫秒级的速度返回,这样的话显然离不开搜索引擎的帮助,在搜…...
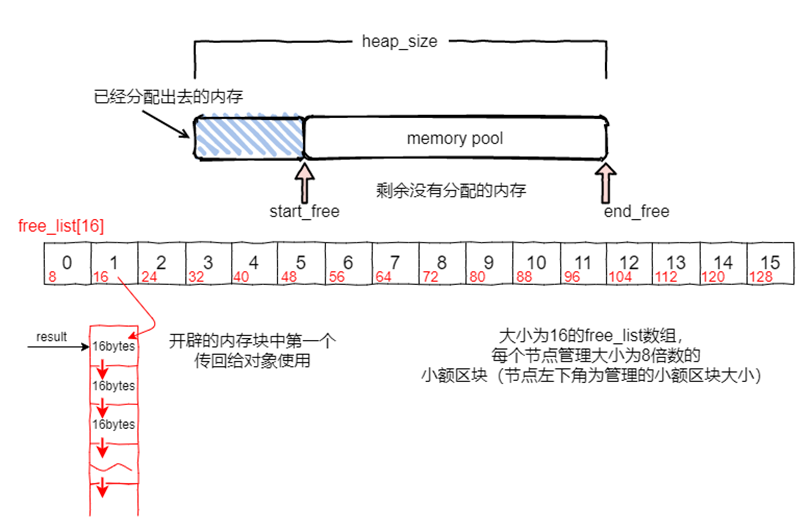
cpp之STL
STL原理 STL ⼀共提供六⼤组件,包括容器,算法,迭代器,仿函数,适配器和空间配置器,彼此可以组合套⽤。容器通过配置器取得数据存储空间,算法通过迭代器存取容器内容,仿函数可以协助算…...

基于Spring Boot开发的资产管理系统
文章目录 项目介绍主要功能截图:登录首页信息软件管理服务器管理网络设备固定资产明细硬件管理部分代码展示设计总结项目获取方式🍅 作者主页:Java韩立 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目…...

Markdown总结
文字的着重标记与段落的层次划分 Tab键可以缩进列表; shift Tab:取消缩进列表 加粗(****)、斜体(**)高亮:xxx$$:特殊标记删除:~~xxx~~多级标题:######无序列…...
字节跳动软件测试岗4轮面经(已拿34K+ offer)...
没有绝对的天才,只有持续不断的付出。对于我们每一个平凡人来说,改变命运只能依靠努力幸运,但如果你不够幸运,那就只能拉高努力的占比。 2021年10月,我有幸成为了字节跳动的一名测试工程师,从外包辞职了历…...

docker - 搭建redis集群和Etcd
概述 由于业务需要,需要把之前的分布式架构调整成微服务,把老项目迁移到k8s的服务中,再开始编码之前,需要再本地环境里做相应的准备工作,使用docker搭建redis集群,Etcd主要是注册本地的rpc服务。 Liunx O…...
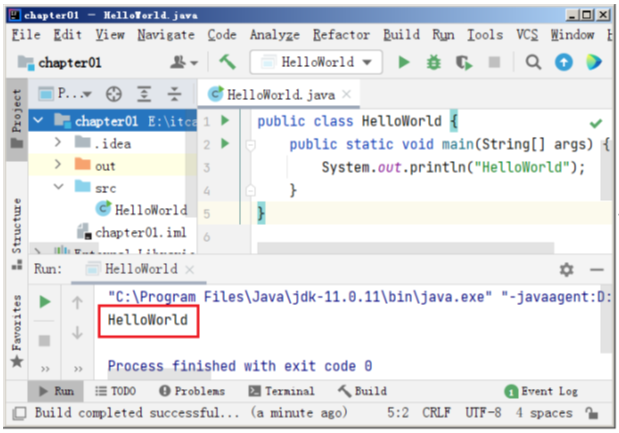
Java程序开发中如何使用lntelliJ IDEA?
完成了IDEA的安装与启动,下面使用IDEA创建一个Java程序,实现在控制台上打印HelloWorld!的功能,具体步骤如下。 1.创建Java项目 进入New Project界面后,单击New Project选项按钮创建新项目,弹出New Project对话框&…...
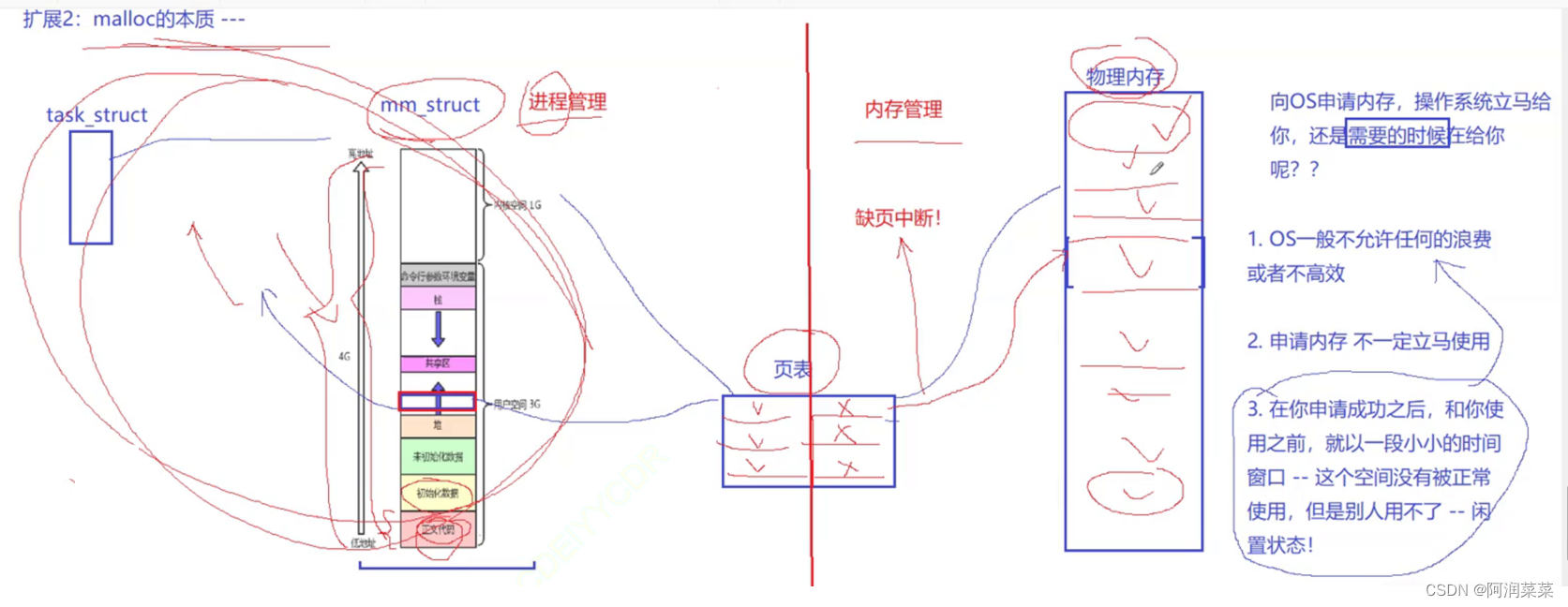
【Linux】理解进程地址空间
🍎作者:阿润菜菜 📖专栏:Linux系统编程 我们在学习C语言的时候,都学过内存区域的划分如栈、堆、代码区、数据区这些。但我们其实并不真正理解内存 — 我们之前一直说的内存是物理上的内存吗? 前言 我们…...

Unity脚本 --- 常用API(类)--- GameObject类 和
第一部分 --- GameObject类 1.在Hierarchy 层级面板中添加游戏物体其实就相当于在场景中添加游戏物体 2.每一个场景都有一个自己的Hierarchy层级面板,用来管理场景中的所有游戏物体 3.是的,我们可以创建多个场景 1.首先上面这两个变量都是布尔变量&am…...

HTML标签——表格标签
HTML标签——表格标签 目录HTML标签——表格标签一、表格标题和表头单元格标签场景:注意点:案例实操小结二、表格的结构标签场景:注意点:案例实操:三、合并单元格思路场景:代码实现一、表格标题和表头单元格…...

Telerik JustMock 2023 R1 Crack
Telerik JustMock 2023 R1 Crack 制作单元测试的最快、最灵活和模拟选项。 Telerik JustLock也很简单,可以使用一个模拟工具来帮助您更快地生成更好的单元测试。JustLock使您更容易创建对象并建立对依赖关系的期望,例如,互联网服务需求、数据…...

筑基八层 —— 问题思考分析并解决
目录 零:移步 一.修炼必备 二.问题思考(先思考) 三.问题解答 零:移步 CSDN由于我的排版不怎么好看,我的有道云笔记相当的美观,请移步有道云笔记 一.修炼必备 1.入门必备:VS2019社区版&#x…...

【面试题】当面试官问 Vue2与Vue3的区别,你该怎么回答?
大厂面试题分享 面试题库后端面试题库 (面试必备) 推荐:★★★★★地址:前端面试题库被问到 《vue2 与 vue3 的区别》应该怎么回答Vue 内部根据功能可以被分为三个大的模块:响应性 reactivite、运行时 runtime、编辑器…...

使用Python对excel中的数据进行处理
一、读取excel中的数据首先引入pandas库,没有的话使用控制台安装 —— pip install pandas 。import pandas as pd #引入pandas库,别名为pd#read_excel用于读取excel中的数据,这里只列举常用的两个参数(文件所在路径ÿ…...
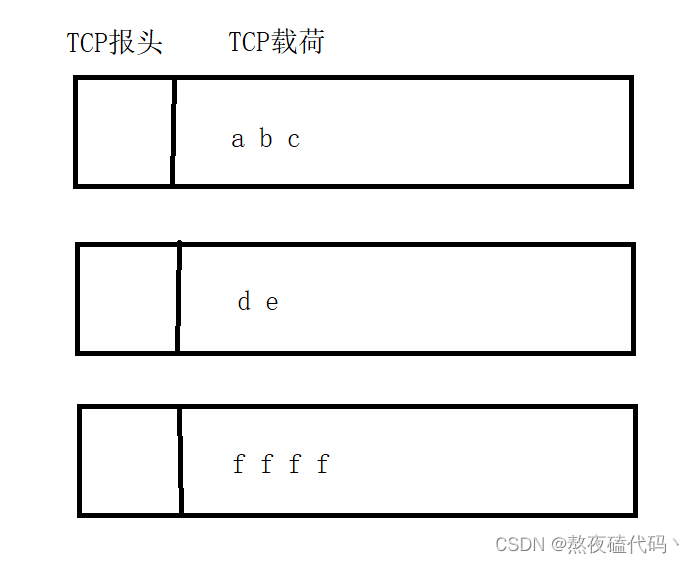
TCP协议原理三
文章目录七、延时应答八、捎带应答九、面向字节流粘包问题十、TCP异常情况总结七、延时应答 如果说滑动窗口的关键是让窗口大一些,传输速度就快一些。那么延时应答就是在接收方能够处理的前提下,尽可能把ack返回的窗口大小尽可能大一些。 如果在接受数据…...
mac在命令行里获取root权限
1、为什么要获取root权限? 答:一些命令在正常状态下没有权限会报错,只有获取了root权限才能正常操作。 比如我们想修改一些系统的文件: vim /etc/shells 1 修改后保存,发现没权限,报错了。如下图…...
文献阅读 Improving Seismic Data Resolution with Deep Generative Networks
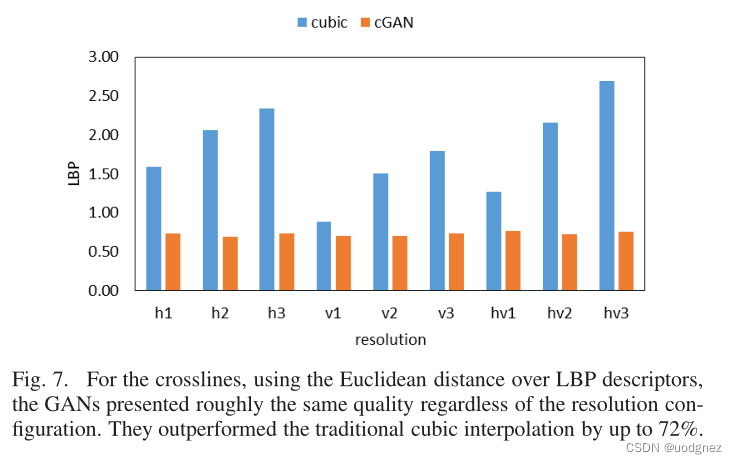
题目 Improving Seismic Data Resolution with Deep Generative Networks 使用深度生成网络提高地震数据分辨率 摘要 叠前数据的使用,通常可以来解决噪声迹线、覆盖间隙或不规则/不适当的迹线间距等问题。但叠前数据并不总是可用的。作为替代方案,叠后…...

ColorMemLCD电子纸驱动库:面向LPM013M126A的嵌入式低功耗显示方案
1. ColorMemLCD 库概述ColorMemLCD 是一款专为 JDI(Japan Display Inc.)LPM013M126A 型彩色内存式 LCD 显示模块设计的嵌入式图形驱动库。该库并非从零构建,而是继承自 ARM mbed OS 生态中广泛使用的GraphicDisplay抽象基类,延续了…...

EN50155以太网交换机的X键位M12插座在PCB板上同一高度方法
在轨道交通车载EN50155以太网交换机的PCB设计中,X键位M12插座(千兆/万兆接口)常需多个并排或阵列布局。由于X编码插座引脚数较多(8芯)且结构复杂,确保所有插座在PCB板上的同一高度(共面性&#…...

深蓝词库转换:如何实现20+输入法词库的一键互通
深蓝词库转换:如何实现20输入法词库的一键互通 【免费下载链接】imewlconverter ”深蓝词库转换“ 一款开源免费的输入法词库转换程序 项目地址: https://gitcode.com/gh_mirrors/im/imewlconverter 你是否曾因更换输入法而不得不放弃多年积累的个人词库&…...

Redis未授权访问漏洞实战:从SSH公钥到反弹shell的5种利用方式详解
Redis未授权访问漏洞深度攻防:5种高阶利用与防御方案 Redis作为高性能键值数据库,其未授权访问漏洞长期位居企业安全风险Top 10。本文将突破常规教程框架,从攻击者视角剖析5种实战利用手法,同时提供企业级防御方案。不同于基础复现…...

免费内容解锁工具:提升信息获取效率的技术解决方案
免费内容解锁工具:提升信息获取效率的技术解决方案 【免费下载链接】bypass-paywalls-chrome-clean 项目地址: https://gitcode.com/GitHub_Trending/by/bypass-paywalls-chrome-clean 在信息爆炸的数字时代,专业内容与普通用户之间往往隔着一道…...
)
保姆级教程:在RK3568开发板上配置RK809-5 PMIC的Android设备树(附完整代码)
RK3568开发板实战:RK809-5 PMIC设备树配置全流程解析 当你在RK3568开发板上第一次按下电源键,却只看到一片黑屏时,作为嵌入式工程师的直觉会告诉你:PMIC配置出了问题。RK809-5这颗电源管理芯片就像系统的"心脏"…...

Rainmeter皮肤主题用户行为分析:使用数据统计
Rainmeter皮肤主题用户行为分析:使用数据统计 【免费下载链接】rainmeter Desktop customization tool for Windows 项目地址: https://gitcode.com/gh_mirrors/ra/rainmeter Rainmeter作为一款强大的Windows桌面自定义工具,允许用户通过皮肤主题…...

抖音无水印视频智能下载与高效管理解决方案:从技术原理到行业应用
抖音无水印视频智能下载与高效管理解决方案:从技术原理到行业应用 【免费下载链接】douyin-downloader 项目地址: https://gitcode.com/GitHub_Trending/do/douyin-downloader 一、行业痛点与技术破局:重新定义视频内容获取效率 你是否曾遇到这…...

Joy-Con Toolkit:让Switch玩家掌控设备的开源管理方案
Joy-Con Toolkit:让Switch玩家掌控设备的开源管理方案 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit 为什么Switch玩家需要专属管理工具? 当你插入Switch游戏卡带时,是否担心…...

手把手教你用STM32驱动迪文屏:从RS232配置到页面控件交互全流程
STM32与迪文屏深度开发实战:工业级GUI交互全解析 迪文屏作为工业控制领域广泛采用的HMI解决方案,其与STM32的协同工作能力已成为嵌入式开发者的必备技能。不同于传统TFT-LCD的简单驱动,迪文屏通过串口协议实现的动态交互,为设备控…...