ElasticStack日志分析平台-ES 集群、Kibana与Kafka
一、Elasticsearch
1、介绍:
Elasticsearch 是一个开源的分布式搜索和分析引擎,Logstash 和 Beats 收集的数据可以存储在 Elasticsearch 中进行搜索和分析。
Elasticsearch为所有类型的数据提供近乎实时的搜索和分析:一旦数据被索引,它就可以立即被搜索和分析,这种实时性使得用户能够即时获取最新数据的搜索结果和分析信息。
2、概念:
① 文档:文档是 Elasticsearch中所有可搜索数据的最小的数据单元。它是以JSON 格式表示的一条数据记录,每个文档都有一个唯一的ID来标识,文档可以包含各种字段,例如文本、数字、日期、嵌套对象等。

② 文档元数据:文档除了包含实际的数据外,还有一些元数据信息。这些信息包括文档的版本号、索引的时间戳、路由信息等。

③ 索引(Index):索引是一组具有相似特征的文档的集合,每个索引都有一个唯一的名称,用于标识和检索其中的文档。

二、ES 集群:
1、概念:
Elasticsearch(ES)集群是由一个或多个Elasticsearch节点组成的集合。这些节点协同工作,共同承载数据存储、处理和搜索的负载。
(1) Master Node 和 Master-eligible Node:
① Master Node:主节点负责管理整个集群的状态和拓扑结构;
② Master-eligible Node:有资格成为主节点的节点。
ES 集群每个节点启动后,默认就是一个 Master eligible node,Master-eligible node 可以参加选主流程,成为 Master Node ;当第一个节点启动时,它会将自己选举成 Master Node,每个节点上都保存了集群的状态,只有 Master Node 才能修改集群的状态信息。
(2) Date Node 和 Coordinating Node:
① Data Node:数据节点,这些节点负责存储数据分片;
② Coordinating Node:协调节点,负责接收来自客户端的请求,将请求转发到适当的数据节点,并将数据节点的响应整合后返回给客户端。
(3) 主分片与副本分片:
分片(Shards)是将数据水平分割和分布式存储的机制,它允许将大量数据分散到集群中的多个节点上,以提高性能、扩展性和可用性。
① 主分片(Primary Shard):主分片是索引的原始数据分片,在创建索引时,可以指定主分片的数量,一旦创建后,主分片的数量将保持不变。
② 副本分片(Replica Shard):副本分片是主分片的复制品,用于提供数据的冗余备份和高可用性。副本分片数量可以随时更改,通过增加或减少副本的数量,可以影响集群服务的可用性。
2、集群配置:
(1) 域名解析:

(2) 节点设置(以 ela1 为例):
vim /etc/elasticsearch/elasticsearch.yml
① cluster.name: elk 集群名称,各节点的集群名称相同
② node.name: ela1 节点名称,各节点需要设置独立的节点名称
③ node.data: true 指示节点为数据节点
④ network.host: 0.0.0.0 ;http.port: 9200 节点所绑定的ip和提供服务的端口
⑤ discovery.seed_hosts 指定集群成员,用于主动发现他们
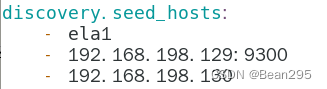
⑥ cluster.initial_master_nodes: ["ela1", "ela2", "ela3"] 指定集群初始化主节点
2号、3号节点的 yml 文件除了 node.name 需要修改,其他都与 ela1 保持一致
(3) 查集群:
systemctl start elasticsearch.service
● 查看集群健康状态:
curl -X GET "localhost:9200/_cat/health?v"

状态含义:
绿色表示健康状态良好,黄色表示有一些问题但仍在正常运行,红色表示存在严重问题。
● 查看集群节点信息:
curl -X GET "localhost:9200/_cat/nodes?v"

3、集群测试
使用 Filebeat 搜集日志,输出到 Logstash, 再由 Logstash 处理完数据后输出到 Elasticsearch。
(1) Logstash配置:

(2) 启动服务,查看输出:

验证Elasticsearch是否创建索引:
curl ‐X GET "192.168.19.20:9200/_cat/indices"
![]()
(3) 自定义索引:
用户可自定义索引,例如把访问日志 access.log 中的内容单独放到一个索引中。
 三、Kibana
三、Kibana
1、简介:
Kibana是一个开源的数据可视化工具,它是Elastic Stack的一部分,Kibana主要用于对Elasticsearch中的数据进行可视化和分析。
2、Kibana 部署
(1) 编辑配置文件:
vim /usr/local/kibana/config/kibana.yml
① server.port: 5601 ;server.host: 0.0.0.0
② elasticsearch.hosts: ["http://192.168.198.128:9200"]
用于连接到 ES 集群的地址和端口
③ logging.dest: /var/log/kibana/kibana.log
配置日志文件路径
④ i18n.locale: "zh-CN"
设置页面字体为中文
(2) 创建用户并修改属主和属组:
默认情况下 kibana 不以 root 用户运行,需要创建应该普通用户
useradd ela
mkdir /run/kibana /var/log/kibana/
chown -R ela.ela /run/kibana/
chown -R ela.ela /var/log/kibana/
chown -R ela.ela /usr/local/kibana/
(3) 切换到 ela 用户运行:
su ‐ ela
/usr/local/kibana/bin/kibana
kibana web 界面:

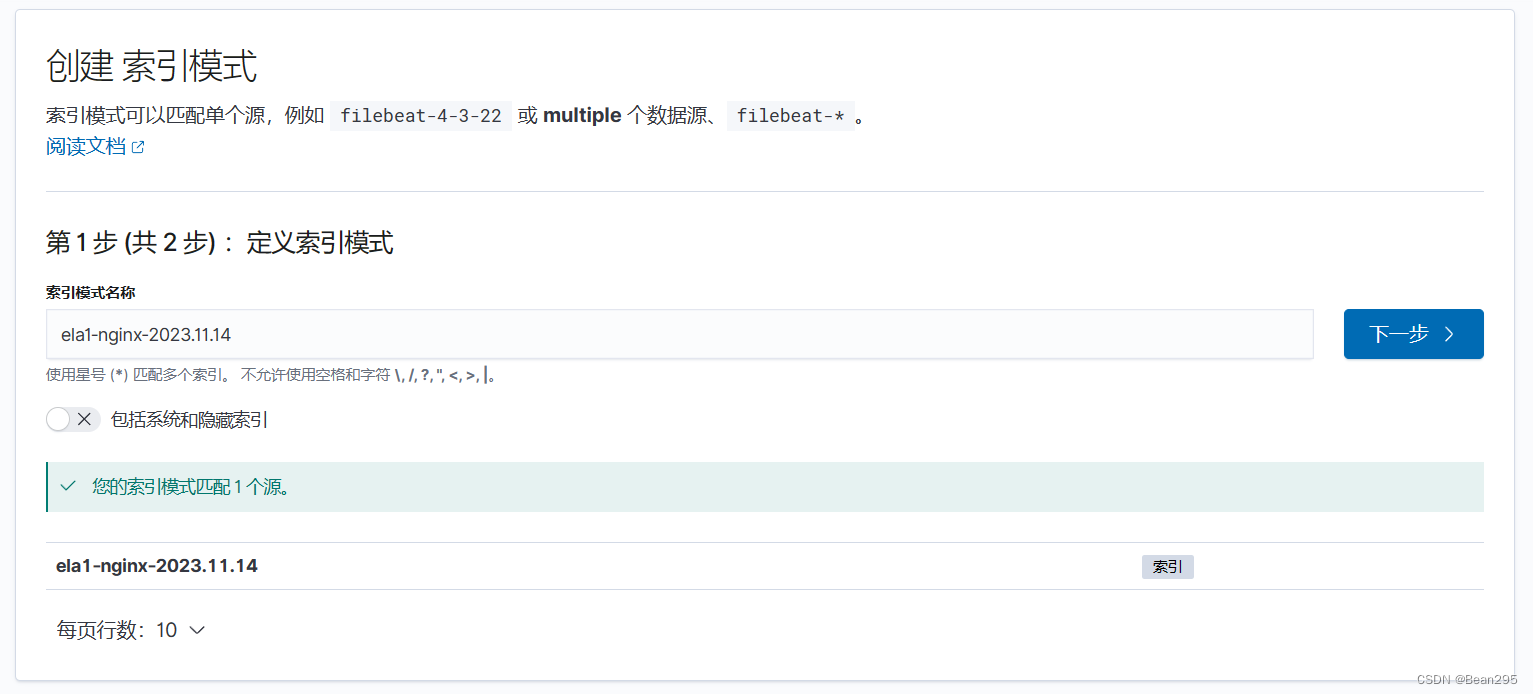
① 创建索引模式:
Kibana 中创建索引模式时,你需要指定一个或多个索引模式名称,这些名称匹配 Elasticsearch中 的一个或多个索引。通过指定索引模式,可以在Kibana中执行搜索、创建可视化图表和构建仪表板。


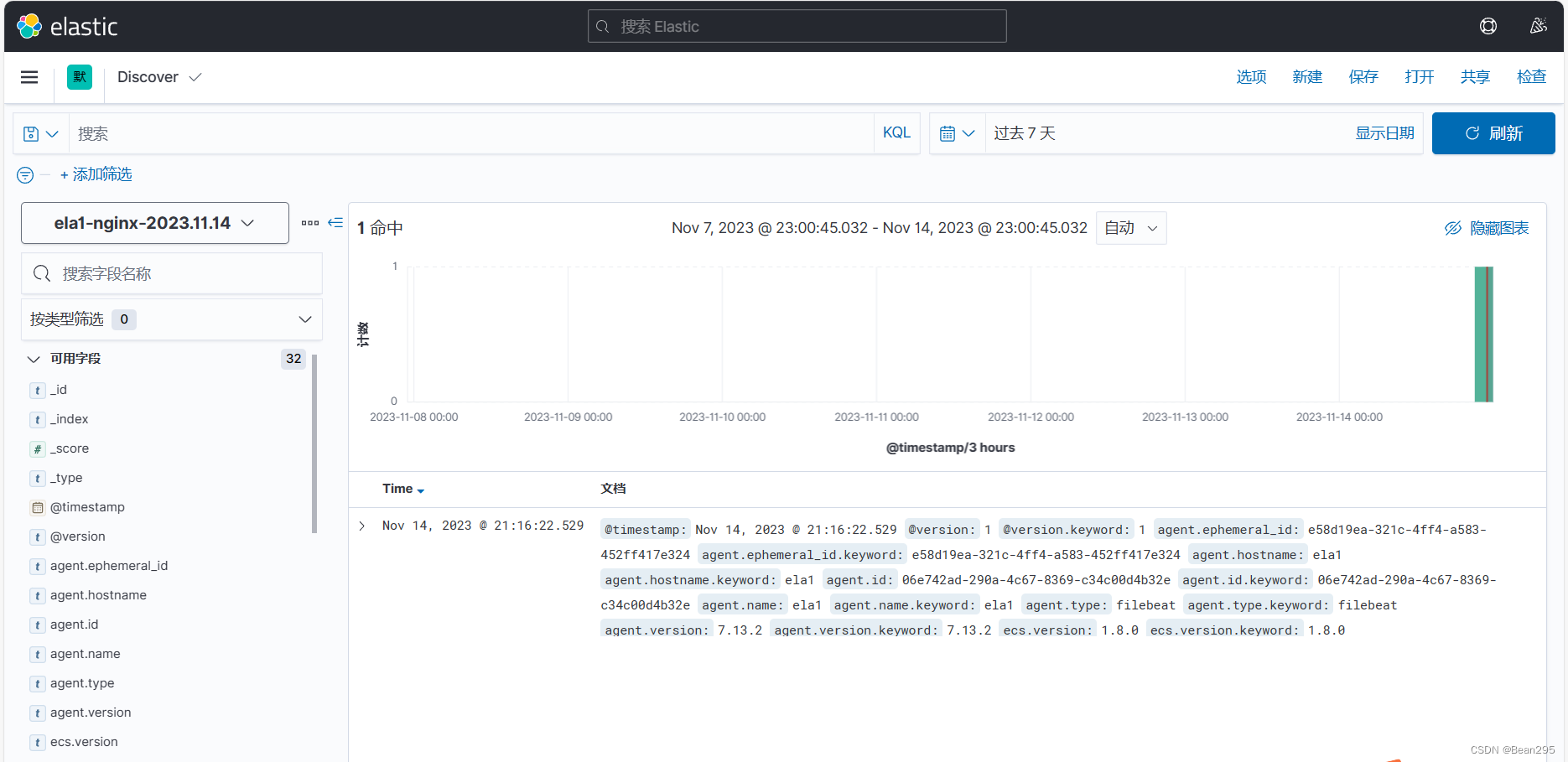
② 查看日志:
四、Kafka 集群
1、简介:
(1) 概念:
Kafka是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它可以实时的处理大量数据以满足各种需求场景,提高了可扩展性。具有峰值处理能力,能够使关键组件顶住突发的访问压力,不会因为超负荷的请求而完全崩溃。
(2) 特性:
高吞吐量:kafka每秒可以处理几十万条消息
可扩展性:kafka集群支持热扩展- 持久性
可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
高并发:支持数千个客户端同时读写
(3) 组件:
① 话题 (topic):特定类型的消息流,Kafka消息被发布到话题,消费者可以订阅并从主题中读取数据(kafka 是面向 topic的)
② 生产者 (Producer) :负责将数据发布到Kafka的话题中,生产者可以将消息发送到一个或多个话题。
③ 消费者 (Consumer):订阅一个或多个话题,并处理从这些话题中接收到的消息。
④ 代理 (Broker):Kafka集群由多个服务器节点组成,每个节点称为代理。它们负责存储已发布消息记录,并处理生产者和消费者之间的数据传输。
⑤ 分区 (Partition):每个主题可以分为多个分区,每个分区在多个服务器节点上进行副本备份,确保数据的可靠性和容错性。
⑥ 复制 (Replication):Kafka使用复制机制来确保数据的可靠性和容错性,复制允许将相同分区的数据副本保存在多个Broker上。
⑦ 领导者 (Leader):对于每个分区,Kafka中有一个 Leader ,它负责处理所有的读写请求,所有的生产者和消费者都与 Leader 交互。
⑧ 跟随者 (Follower):Follower 是 Leader 的复制品,Follower 会从 Leader 中拉取数据,并保持数据的同步,以便在 Leader 副本失败时接管服务。
⑨ ZooKeeper:ZooKeeper是一个开源的分布式协调服务,用于管理和协调Kafka集群中的Broker节点。ZooKeeper负责维护Kafka集群中各个Broker的状态信息,包括分区分配、Leader选举等,确保Kafka集群的稳定运行。
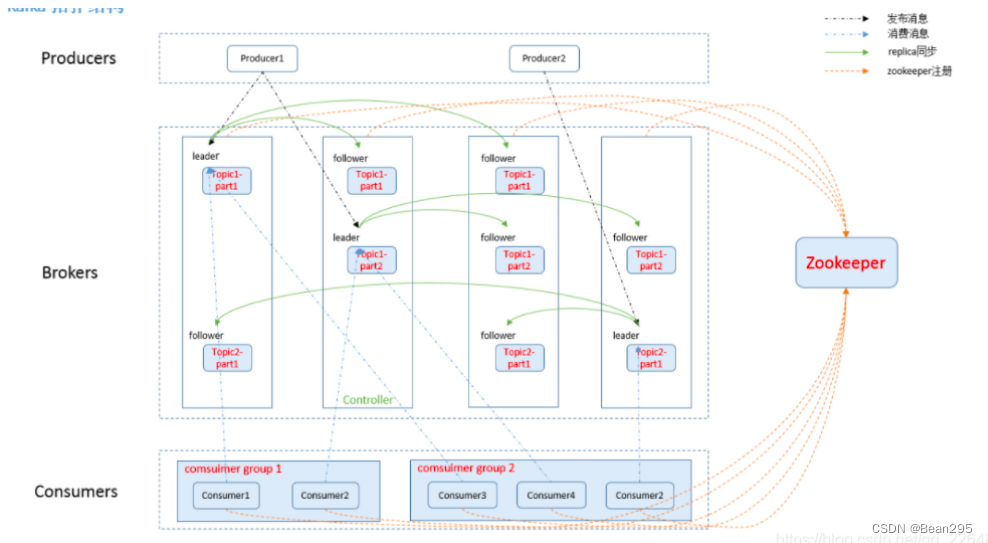
2、集群部署:
(1) 域名解析:

配置jdk8:yum install -y java-1.8.0-openjdk
(2) 配置 ZK(以 es01 为例):
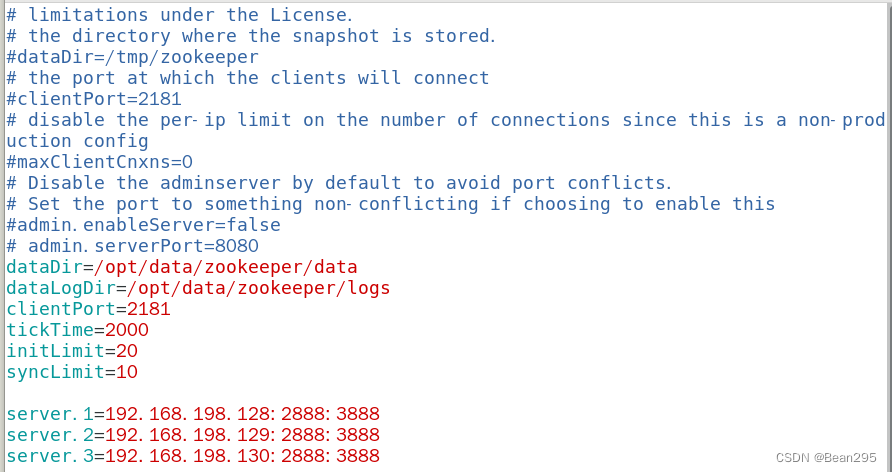
vim /usr/local/kafka/config/zookeeper.properties
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
dataDir:指定 ZooKeeper 数据存储的目录;
dataLogDir:指定 ZooKeeper 日志文件存储的目录;
clientPort:ZooKeeper 客户端连接到服务器的端口号;
tickTime:ZooKeeper 服务器之间的心跳时间以及超时时间 (ms);
initLimit:当 ZooKeeper 服务器启动时,等待接收来自 Leader 的初始化连接的时间 (以 tickTime 的倍数为单位);
syncLimit:在 ZooKeeper 集合中的 Follower 节点同步到 Leader 节点的时间限制 (以 tickTime 的倍数为单位)。
server.1=192.168.198.128:2888:3888
server.2=192.168.198.129:2888:3888
server.3=192.168.198.130:2888:3888
kafka集群IP:Port
● 创建data、log目录:
mkdir ‐p /opt/data/zookeeper/{data,logs}
![]()
● 创建myid文件:
指定该设备在集群中的编号
echo 1 > /opt/data/zookeeper/data/myid

es02、es03 的配置信息与 es01 相同
mkdir -p /opt/data/zookeeper/{data,logs}
echo 2 > /opt/data/zookeeper/data/myid
echo 3 > /opt/data/zookeeper/data/myid
(3) 配置 Kafka(以 es01 为例):
vim /usr/local/kafka/config/server.properties
broker.id=1
listeners=PLAINTEXT://192.168.198.128:9092
num.network.threads=3
num.io.threads=8
broker.id:配置了 Kafka broker(代理)的唯一标识符,每个 Kafka broker 通过 broker.id 来标识自己在集群中的位置;
listeners=PLAINTEXT://192.168.198.128:9092:配置了 Kafka broker 监听客户端连接的网络接口和地址(配置本机);
num.network.threads:这个参数设置了 Kafka broker 处理消息的最大线程数。
num.io.threads:这个参数定义了 Kafka broker 处理磁盘 I/O 操作的线程数。
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
socket.send.buffer.bytes:设置了 Kafka 发送数据时的缓存大小;
socket.receive.buffer.bytes:设置了 Kafka 接收数据时的缓存大小;
socket.request.max.bytes:设置了 Kafka 单个请求可以包含的最大字节量。
log.dirs=/opt/data/kafka/logs
num.partitions=6
num.recovery.threads.per.data.dir=1
log.dirs:Kafka 的日志存储目录配置;
num.partition:指定 Kafka 话题的分区数量;
num.recovery.threads.per.data.dir:配置每个数据目录(data.dirs)下用于日志恢复的线程数。
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
offsets.topic.replication.factor:指定了存储位置的复制方式,设置为 2 数据会被复制两份;
transaction.state.log.replication.factor ;transaction.state.log.min.isr:设置了事务状态日志数据备份数量为1份,只要有一个备份是活跃的就可以进行写入操作。
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
log.retention.hours:日志的保留时间 168小时(7天);
log.segment.bytes:定义了日志段的大小(存储消息的字节数);
log.retention.check.interval.ms:定义了检查日志保留策略的时间间隔,每300,000毫秒 (5分钟) 检查并清理过期的日志段。
zookeeper.connect=192.168.198.128:2181,192.168.198.129:2181,192.168.198.130:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
zookeeper.connect:指定了 Kafka 使用的 ZooKeeper 的连接信息;
zookeeper.connection.timeout.ms:定义了连接 ZooKeeper 的超时时间;
group.initial.rebalance.delay.ms:定义了消费者组的初始重新平衡(rebalance)的延迟时间,为 0 毫秒意味着当有新的消费者加入或退出消费者组时,Kafka 将立即开始重新平衡分配分区(partitions)给消费者。
mkdir -p /opt/data/kafka/logs
● 配置 es02 和 es03:
scp -r /usr/local/kafka/config/server.properties es02:/usr/local/kafka/config/
scp -r /usr/local/kafka/config/server.properties es03:/usr/local/kafka/config/
分别修改 broker.id 和 listeners。
mkdir -p /opt/data/kafka/logs
(4) 三台机器启动 zookeeper:
cd /usr/local/kafka
nohup bin/zookeeper‐server‐start.sh config/zookeeper.properties &
![]()
(5) 三台集群启动 kafka:
cd /usr/local/kafka
nohup bin/kafka‐server‐start.sh config/server.properties &
(6) 验证效果:
① 在1号机(128)上创建topic:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testtopicBean
![]()
② 在其他机器上查看 topic:
bin/kafka-topics.sh --zookeeper 192.168.198.128:2181 --list

③ 模拟消息生产和消费 (128 发送消息,129接收):
128:bin/kafka-console-producer.sh --broker-list 192.168.198.129:9092 --topic testtopicBean
129:bin/kafka-console-consumer.sh --bootstrap-server 192.168.198.128:9092 --topic testtopicBean --from-beginning


相关文章:
ElasticStack日志分析平台-ES 集群、Kibana与Kafka
一、Elasticsearch 1、介绍: Elasticsearch 是一个开源的分布式搜索和分析引擎,Logstash 和 Beats 收集的数据可以存储在 Elasticsearch 中进行搜索和分析。 Elasticsearch为所有类型的数据提供近乎实时的搜索和分析:一旦数据被索引&#…...
微机原理_10
一、单项选择题(本大题共15小题,每小题3分,共45分。在每小题给出的四个备选项中,选出一个正确的答案。) 1,将二进制数110110.01转换为十六进制为() A. 66.1H B. 36.4H C. 66.4 D. 36.2 2,一台计算机的字长是4个字节,含义是() A.能处理的最大…...
第八章:SpringMVC程序开发)
(SpringBoot)第八章:SpringMVC程序开发
文章目录 一:Spring MVC概述(1)什么是Spring MVC(2)什么是MVC(3)Spring MVC和SpringBoot(4)如何学习Spring MVC二:Spring MVC创建和连接(1)Spring MVC项目创建(2)@RequestMapping注解三:Spring MVC处理参数(1)传递简单参数(2)传递对象(3)@RequestParam:重…...
)
openssl + 3DES开发实例(linux)
文章目录 一、3DES介绍3DES 的特点:3DES 加密的步骤:3DES 的应用场景: 二、3DES原理1. DES 原理回顾:2. 3DES 原理:3. 3DES 的加密流程: 三、openssl 3DES开发实例 一、3DES介绍 3DES(Triple …...

遵循开源软件安全路线图
毫无疑问,开源软件对于满足联邦任务所需的开发和创新至关重要,因此其安全性至关重要。 OSS(运营支持系统) 支持联邦政府内的每个关键基础设施部门。 联邦政府认识到这一点,并正在采取措施优先考虑 OSS 安全ÿ…...

294_C++_
1、全部大致解析: struct alarminfo_t {unsigned int alarmid;INTF_ALARM_INFO_S pAlarm; };typedef enum{INTF_IO_ALARM_E= 0, //I/O探头告警开始INTF_MOTION_ALARM_E, //移动侦测告警开始INTF_AI_ALARM_E,...
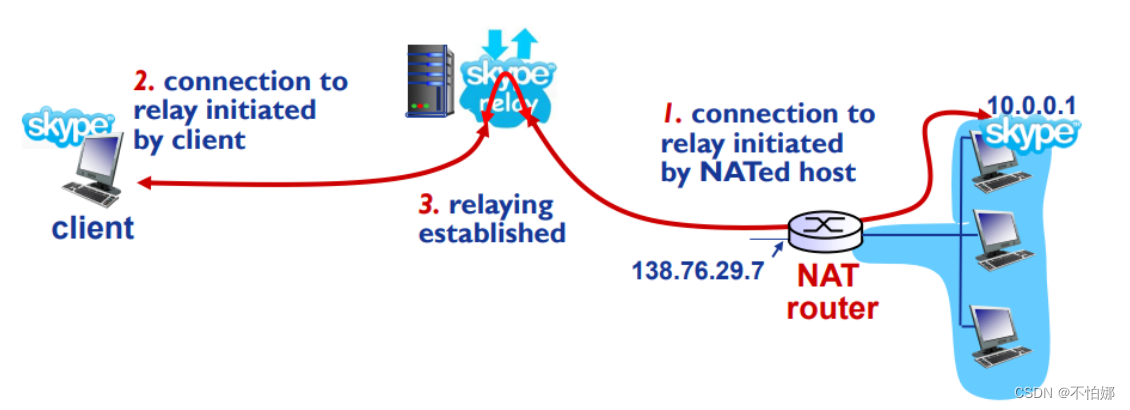
【计算机网络笔记】网络地址转换(NAT)
系列文章目录 什么是计算机网络? 什么是网络协议? 计算机网络的结构 数据交换之电路交换 数据交换之报文交换和分组交换 分组交换 vs 电路交换 计算机网络性能(1)——速率、带宽、延迟 计算机网络性能(2)…...
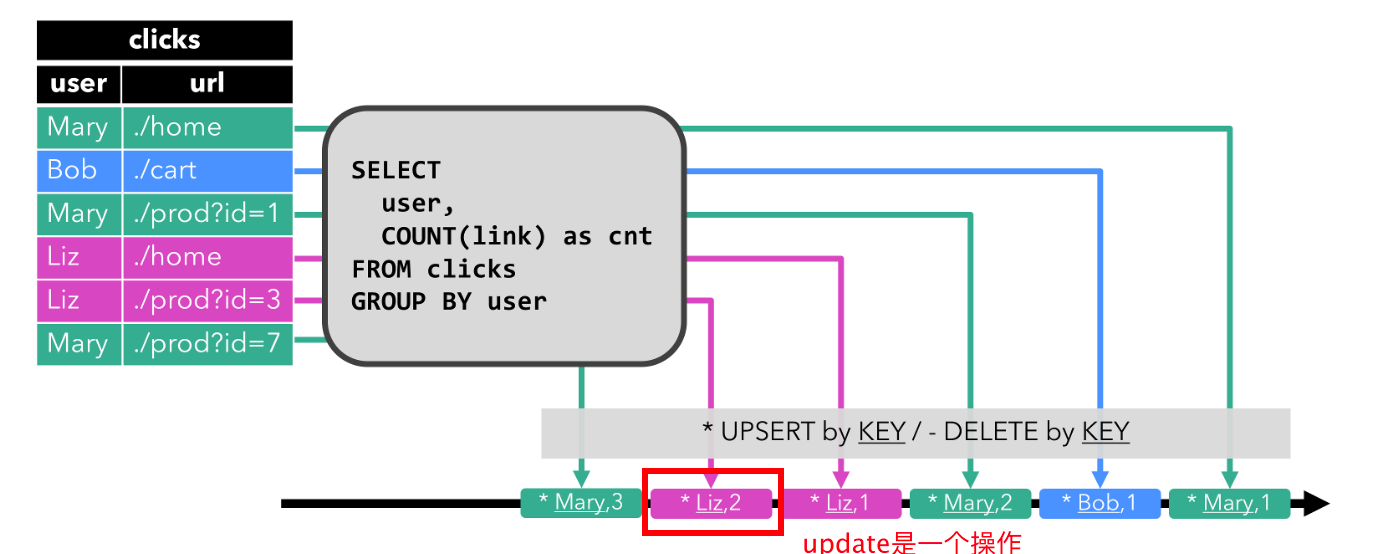
【flink理论】动态表:关系查询处理流的思路:连续查询、状态维护;表转换为流需要编码编码
文章目录 一. 使用关系查询处理流的讨论二. 动态表 & 连续查询(Continuous Query)三. 在流上定义表1. 连续查询2. 查询限制2.1. 维护状态2.2. 计算更新 四. 表到流的转换1. Append-only 流2. Retract 流3. Upsert 流 本文主要讨论了: 讨论通过关系查询处理无界流…...

2023年09月 Python(六级)真题解析#中国电子学会#全国青少年软件编程等级考试
Python等级考试(1~6级)全部真题・点这里 一、单选题(共25题,每题2分,共50分) 第1题 以下选项中,不是tkinter变量类型的是?( ) A: IntVar() B: StringVar() C: DoubleVar() D: FloatVar() 答案:D tkinter 无 FloatVar()变量类型。 第2题 关于tkinter,以下说…...
Ubuntu16.04上安装Docker
Ubuntu16.04上安装Docker 更新 apt 包索引: sudo apt-get update安装依赖包,以便使用 HTTPS 仓库 sudo apt-get install apt-transport-https ca-certificates curl software-properties-common添加 Docker GPG 密钥 curl -fsSL https://download.docker.com/linux/ubuntu…...
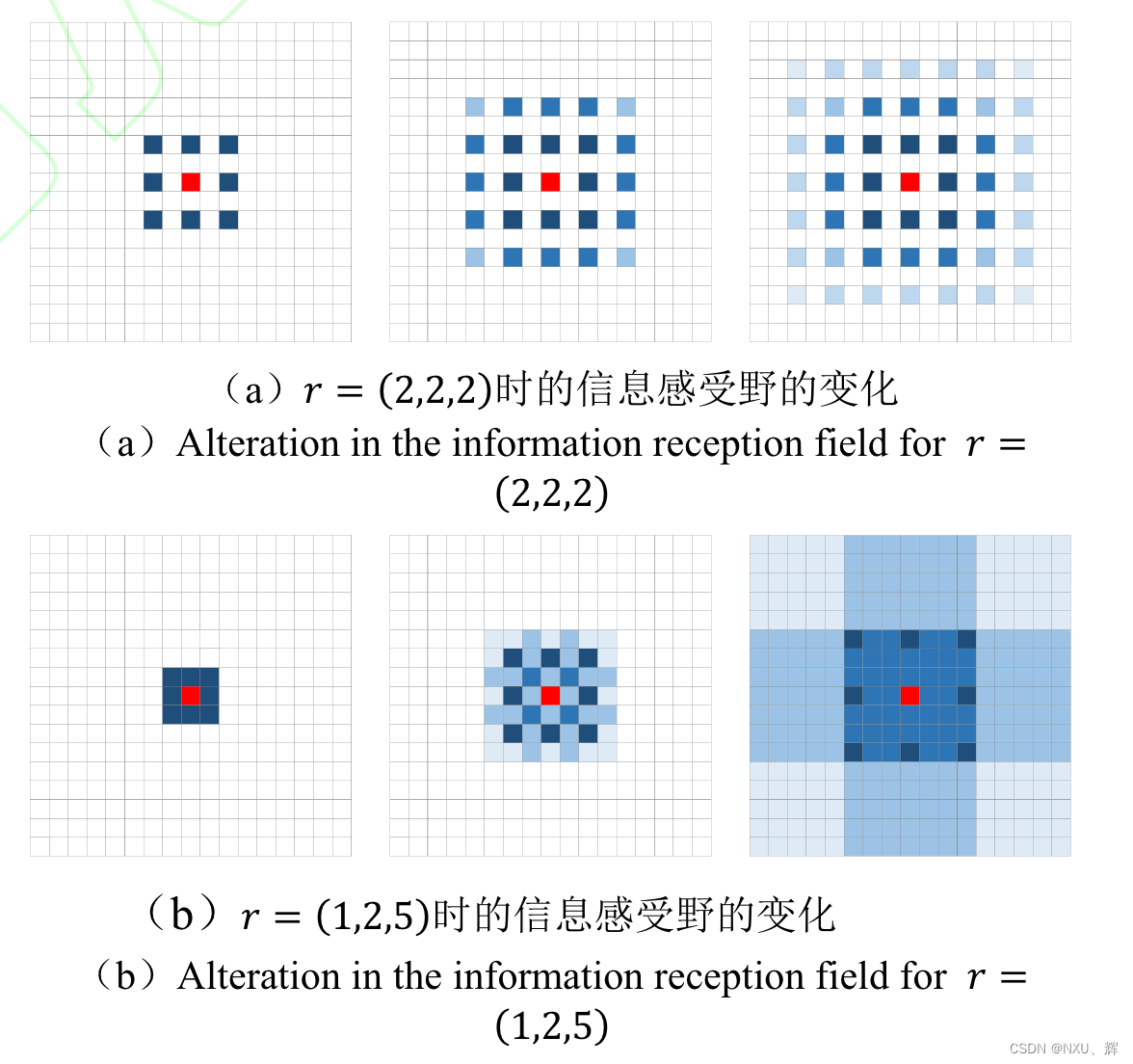
FSOD论文阅读 - 基于卷积和注意力机制的小样本目标检测
来源:知网 标题:基于卷积和注意力机制的小样本目标检测 作者:郭永红,牛海涛,史超,郭铖 郭永红,牛海涛,史超,郭铖.基于卷积和注意力机制的小样本目标检测 [J/OL].兵工学报. https://…...
Windows系统中搭建docker (ubuntu,Docker-desktop)
一、docker安装前的准备工作 1. 开启CPU虚拟化,新电脑该默认是开启的,如果没开启可以根据自己电脑型号品牌搜索如克开启CPU虚拟化。当开启成功后可在设备管理器中看到。 2.开通Hyper-V 通过 Windows 控制面板 --> 程序和功能 -->启用或关闭…...

使用记录-MongoDB
find常用方法 在 MongoDB 的 find 方法中,可以使用各种查询操作符来执行不同类型的查询。其中之一是 $in 操作符,它用于在一个字段中匹配多个值。 $eq 操作符: 用于匹配字段值等于指定值的文档。 // 查询 age 字段等于 25 的文档 db.colle…...
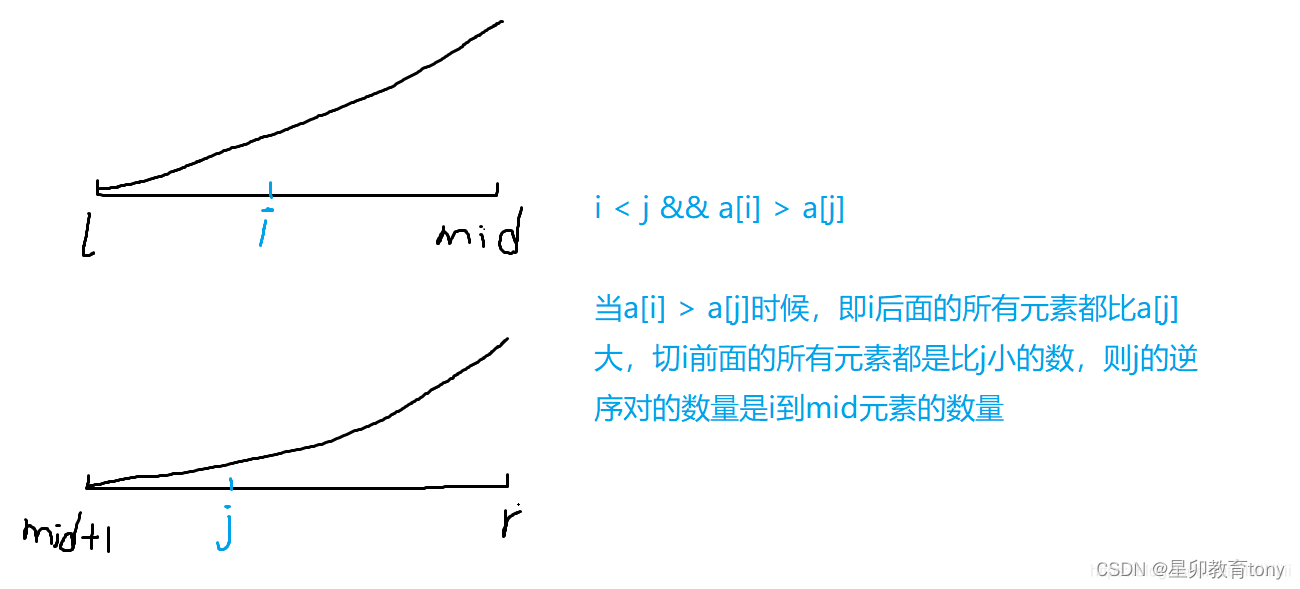
用归并排序算法merge_sort( )求解 逆序对的数量 降低时间复杂度为 nlogn
题目简述 给定一个序列有n个数,求n个数中逆序对的个数,逆序对的定义:i < j && a[i] > a[j]。 输入格式 第一行包含一个整数n。 第二行包含 n 个整数(所有整数均在1~1e9范围内),表示整数数…...

大功率电源芯片WD5030L
电源管理芯片作为现代电子设备中最关键的元件之一,直接影响着设备的性能和效率。而大功率电源芯片作为电源管理芯片中的一种,其性能和应用领域更加广泛。本文将介绍一款具有宽VIN输入范围、高效率和多种优良性能的大功率电源芯片WD5030L,并探…...
Spring Boot使用EhCache完成一个缓存集群
在上一篇在SpringBoot中使用EhCache缓存,我们完成了在Spring Boot中完成了对EhCaChe的使用,这篇,我们将对EhCache的进一步了解,也就是搭建一个EhCache的缓存集群。 集群 在搭建一个EhCache的时候,我们需要先了解&…...

yolov5模型代码怎么修改
yaml配置文件 深度乘积因子 宽度乘积因子 所有版本只有这两个参数的不同,s m l x逐渐加宽加深 各种类型层参数对照 backbone里的各层,在这里解析,只需要改.yaml里的各层参数就能控制网络结构 修改网络结构 第一步:把新加的模块…...
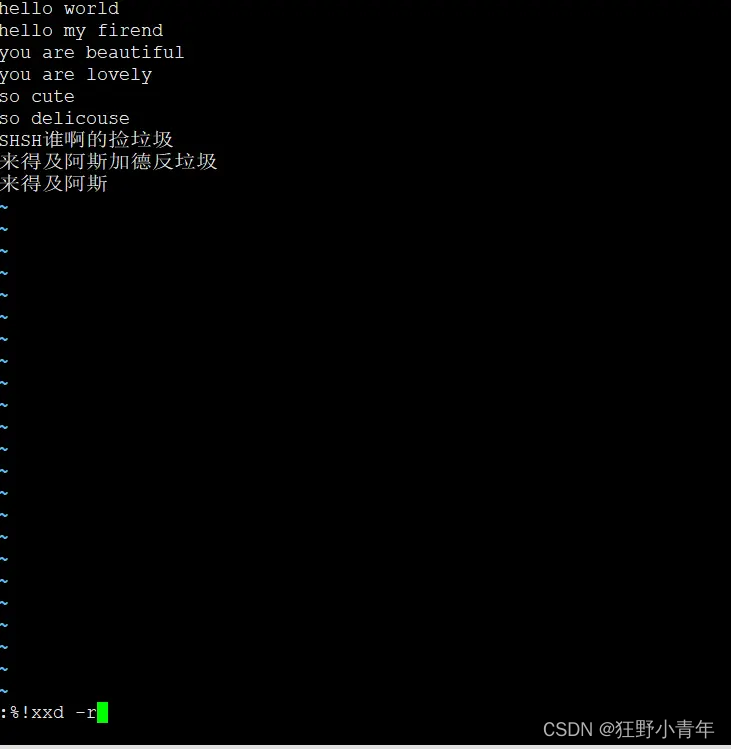
VIM去掉utf-8 bom头
Windows系统的txt文件在使用utf-8编码保存时会默认在文件开头插入三个不可见的字符(0xEF 0xBB 0xBF)称为BOM头 BOM头文件 0.加上BOM标记: :set bomb 1.查询当前UTF-8编码的文件是否有BOM标记: :set bomb? :set bomb? 2.BOM头:文…...

Go 使用Viper处理Go应用程序的配置
在开发Go应用程序时,处理配置是一个常见的需求。配置可能来自于配置文件、环境变量、命令行参数等等。Viper是一个强大的库,可以帮助我们处理这些配置。 什么是Viper? Viper是一个应用程序配置解决方案,用于Go应用程序。它支持JS…...

hadoop安装网址
Hadoop是什么 1)Hadoop是一个有Apache基金会所开发的分布式系统基础架构。 2)主要解决海量数据的存储和海量数据的分析计算问题。 3)广义上来说,Hadoop通常是指一个更广泛的概念---Hadoop生态圈。 Hadoop发行版本 Hadoop发行的…...

AI量化交易中的信号相关性与认知依赖:系统性风险与应对策略
1. 项目概述:当AI成为市场共识,系统性风险如何被“编程”?在金融市场的交易大厅和量化部门的代码仓库里,一场静默的变革已经持续了十年。这不是关于某个算法战胜了市场,而是关于市场本身正在被算法重新定义。核心矛盾在…...

Mootdx架构深度解析:Python金融数据接口的工程化实践
Mootdx架构深度解析:Python金融数据接口的工程化实践 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在金融科技快速发展的今天,数据获取的便捷性与稳定性成为量化分析的基…...

对比体验使用Taotoken聚合接口与直连原厂API的延迟与稳定性差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比体验使用Taotoken聚合接口与直连原厂API的延迟与稳定性差异 1. 引言 在集成大模型能力到实际业务时,开发者除了关…...

【反演】基于粒子群算法PSO进行反演附Matlab代码和报告
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

数据结构太难了?用画图的方式理解链表和栈和树和图
别怕,把它们画出来,你会发现数据结构就是一堆积木。👋 你好,我是 Evan,一名计算机专业的学长,也是《大一突围》专栏的作者。还记得大一第一次见到“链表”时,我被指针绕晕了。后来我试着一个节点…...

2026年,探寻靠谱体育器材的终极指南
在追求健康与活力的时代,体育器材成为了我们运动生活中的重要伙伴。但面对市场上琳琅满目的品牌和产品,如何选择靠谱的体育器材成为了许多人的难题。今天,让我们一同探寻 2026 年靠谱体育器材的终极指南。一、品质与口碑沧州九牌体育用品制造…...

将Taotoken作为统一网关整合到企业现有微服务架构中的设计考量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 将Taotoken作为统一网关整合到企业现有微服务架构中的设计考量 当企业内部多个业务线或团队开始独立探索和应用大模型能力时&#…...

让薪酬跟着人才走:国企核心人才激励保留的五个管理命题
当前,国有企业三项制度改革已进入攻坚深化期。劳动合同签订率、岗位说明书覆盖率、绩效考核实施率等量化指标普遍处于高位,制度框架的“四梁八柱”已基本确立。但在改革向纵深推进过程中,核心人才流失问题却时有发生。据调研反映,…...

告别PyTorch依赖:手把手教你用C++ CUDA实现LeNet推理,从Python模型导出到C++部署全流程
从PyTorch到C CUDA:工业级LeNet模型部署全流程实战 在深度学习模型开发中,Python生态提供了丰富的训练工具,但生产环境往往需要高性能的C实现。本文将完整演示如何将PyTorch训练的LeNet模型部署到C CUDA环境,涵盖模型导出、内存管…...

如何永久激活IDM?免费IDM激活脚本终极指南
如何永久激活IDM?免费IDM激活脚本终极指南 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 还在为IDM试用期到期而烦恼吗?IDM Activation …...