AdaBoost 算法:理解、实现和掌握 AdaBoost
一、介绍
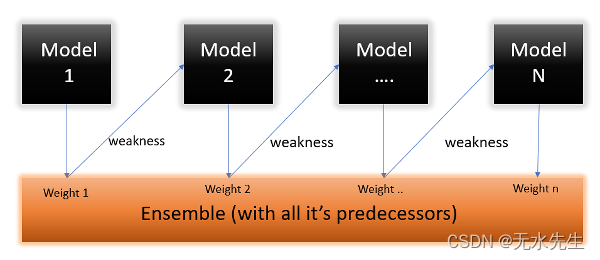
Boosting 是一种集成建模技术,由 Freund 和 Schapire 于 1997 年首次提出。从那时起,Boosting 就成为解决二元分类问题的流行技术。这些算法通过将大量弱学习器转换为强学习器来提高预测能力 。
Boosting 算法背后的原理是,我们首先在训练数据集上构建一个模型,然后构建第二个模型来纠正第一个模型中存在的错误。继续此过程,直到且除非错误被最小化并且数据集被正确预测。Boosting 算法以类似的方式工作,它结合多个模型(弱学习器)来达到最终输出(强学习器)。
学习目标
- 了解 AdaBoost 算法是什么及其工作原理。
- 了解什么是树桩。
- 了解增强算法如何帮助提高 ML 模型的准确性。
本文作为数据科学博客马拉松的一部分发表
目录
- 介绍
- 什么是 AdaBoost 算法?
- 了解 AdaBoost 算法的工作原理
- 第 1 步:分配权重
- 第 2 步:对样本进行分类
- 步骤 3:计算影响力
- 第 4 步:计算 TE 和性能
- 第 5 步:减少错误
- 第 6 步:新数据集
- 第 7 步:重复前面的步骤
- 结论
- 经常问的问题
二、什么是 AdaBoost 算法?
有许多机器学习算法可供选择用于您的问题陈述。其中一种用于预测建模的算法称为 AdaBoost。
AdaBoost 算法是 Adaptive Boosting 的缩写,是 一种在机器学习中用作集成方法的 Boosting 技术。它被称为自适应提升,因为权重被重新分配给每个实例,更高的权重分配给错误分类的实例。

该算法的作用是构建一个模型并为所有数据点赋予相同的权重。然后,它为错误分类的点分配更高的权重。现在,所有权重较高的点在下一个模型中都会变得更加重要。它将继续训练模型,直到收到较低的错误为止。
让我们举个例子来理解这一点,假设您在泰坦尼克号数据集上构建了一个决策树算法,并且从那里您获得了 80% 的准确率。之后,您应用不同的算法并检查准确性,结果显示 KNN 为 75%,线性回归为 70%。
当我们在同一数据集上构建不同的模型时,我们发现准确性有所不同。但是如果我们使用所有这些算法的组合来做出最终预测呢?通过取这些模型结果的平均值,我们将获得更准确的结果。我们可以通过这种方式来提高预测能力。
如果您想直观地理解这一点,我强烈建议您阅读这篇文章。
这里我们将更加关注数学直觉。
还有另一种集成学习算法称为梯度提升算法。在此算法中,我们尝试减少误差而不是权重,如 AdaBoost 中那样。但在本文中,我们将仅关注 AdaBoost 的数学直觉。
三、了解 AdaBoost 算法的工作原理
让我们通过以下教程了解该算法的原理和工作原理。
第 1 步:分配权重
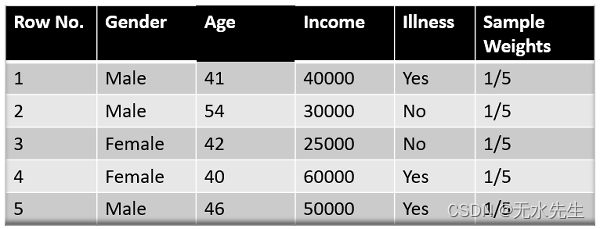
下面显示的图像是我们数据集的实际表示。由于目标列是二元的,因此这是一个分类问题。首先,这些数据点将被分配一些权重。最初,所有权重都是相等的。
样本权重的计算公式为:

其中 N 是数据点的总数
这里由于我们有 5 个数据点,因此分配的样本权重将为 1/5。
第 2 步:对样本进行分类
我们首先查看“性别”对样本进行分类的效果如何,然后查看变量(年龄、收入)如何对样本进行分类。
我们将为每个特征创建一个决策树桩,然后计算每棵树的基尼指数。基尼指数最低的树将是我们的第一个树桩。
在我们的数据集中,假设性别具有最低的基尼指数,因此它将是我们的第一个树桩。
第 3 步:计算影响力
现在,我们将使用以下公式计算该分类器在对数据点进行分类时的“发言量”或“重要性”或“影响力” :
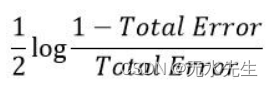
总误差只不过是错误分类的数据点的所有样本权重的总和。
在我们的数据集中,我们假设有 1 个错误的输出,因此我们的总误差将为 1/5,并且 alpha(树桩的性能)将为:
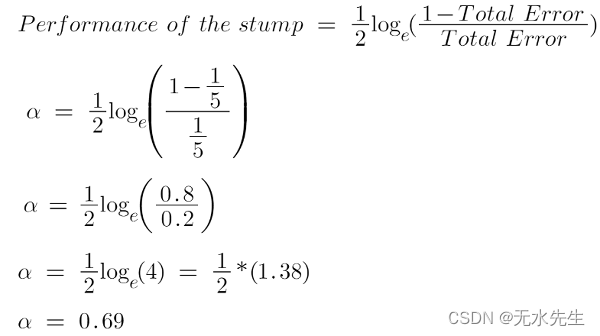
注意:总误差始终在 0 和 1 之间。
0 表示完美的树桩,1 表示糟糕的树桩。
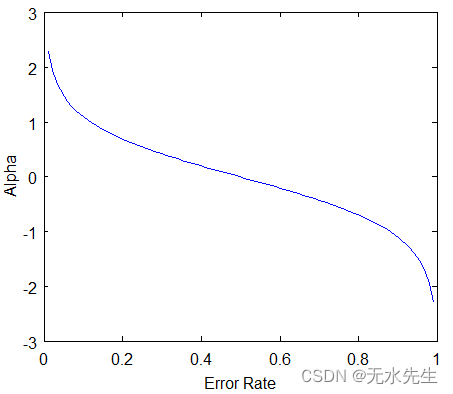
从上图中,我们可以看到,当没有错误分类时,我们就没有错误(Total Error = 0),因此“a amount of say (alpha)”将是一个很大的数字。
当分类器预测一半正确一半错误时,则总误差 = 0.5,并且分类器的重要性(可以说)将为 0。
如果所有样本都被错误分类,那么错误将非常高(大约为 1),因此我们的 alpha 值将是负整数。
第 4 步:计算 TE 和性能
您一定想知道为什么需要计算树桩的 TE 和性能。答案很简单,我们需要更新权重,因为如果将相同的权重应用于下一个模型,那么收到的输出将与第一个模型中收到的输出相同。
错误的预测将被赋予更高的权重,而正确的预测权重将被降低。现在,当我们在更新权重后构建下一个模型时,将更优先考虑权重较高的点。
在找到分类器的重要性和总误差后,我们最终需要更新权重,为此,我们使用以下公式:
![]()
当样本被正确分类时,例如(alpha)的数量将为负。
当样本被错误分类时,例如(alpha)的量将为正。
有 4 个正确分类的样本,1 个错误分类的样本。这里, 该数据点的样本权重是1/5,性别树桩的发言/表现 量是0.69。
正确分类样本的新权重为:
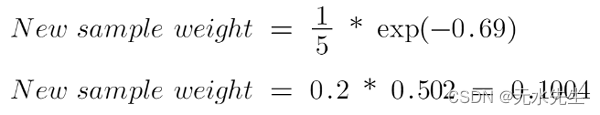
对于错误分类的样本,更新后的权重为:
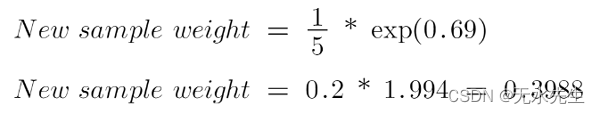
笔记
当我输入值时请查看 alpha 的符号,当数据点正确分类时alpha 为负,这会将样本权重从 0.2 降低到 0.1004。当存在错误分类时为正,这会将样本权重从 0.2 增加到 0.3988
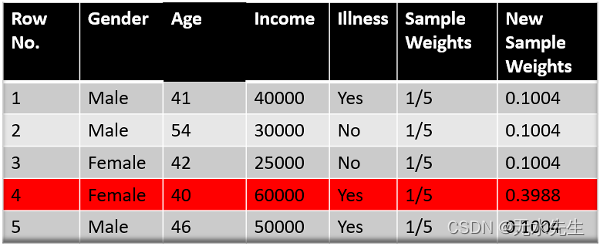
我们知道样本权重的总和必须等于 1,但是这里如果我们将所有新样本权重相加,我们将得到 0.8004。为了使这个总和等于 1,我们将所有权重除以更新权重的总和(即 0.8004)来标准化这些权重。因此,对样本权重进行归一化后,我们得到了这个数据集,现在总和等于 1。

第 5 步:减少错误
现在,我们需要创建一个新的数据集来查看错误是否减少。为此,我们将删除“样本权重”和“新样本权重”列,然后根据“新样本权重”将数据点划分为多个桶。
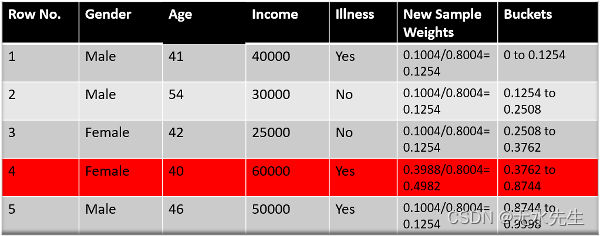
第 6 步:新数据集
我们快完成了。现在,该算法所做的是从 0-1 中选择随机数。由于错误分类的记录具有较高的样本权重,因此选择这些记录的概率非常高。
假设我们的算法采用的 5 个随机数是 0.38,0.26,0.98,0.40,0.55。
现在我们将看到这些随机数落在桶中的位置,并根据它,我们将制作如下所示的新数据集。
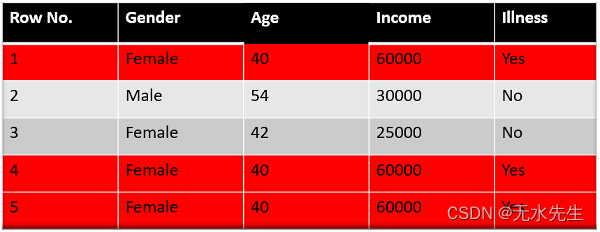
这是我们的新数据集,我们看到错误分类的数据点已被选择 3 次,因为它的权重较高。
第 7 步:重复前面的步骤
现在这作为我们的新数据集,我们需要重复上述所有步骤,即
- 为所有数据点 分配相同的权重。
- 通过查找基尼指数并选择基尼指数最低的树桩,找到对新样本集合进行分类的最佳树桩。
- 计算“Amount of Say”和“Total error”来更新之前的样本权重。
- 标准化新样本权重。
迭代这些步骤,直到达到较低的训练误差。
假设对于我们的数据集,我们按顺序构建了 3 个决策树(DT1、DT2、DT3) 。如果我们现在发送测试数据,它将通过所有决策树,最后,我们将看到哪个类占多数,并基于此,我们将对
测试数据集进行预测。
四、结论
如果你理解了本文的每一行,你就终于掌握了这个算法。
我们首先向您介绍什么是 Boosting 以及它的各种类型,以确保您了解 Adaboost 分类器以及 AdaBoost 的准确位置。然后我们应用简单的数学并了解公式的每个部分是如何工作的。
在下一篇文章中,我将解释梯度下降和极限梯度下降算法,它们是一些更重要的增强预测能力的Boosting技术。
如果您想从头开始了解 AdaBoost 机器学习模型初学者的 Python 实现,请访问Analytics vidhya 的完整指南。本文提到了bagging和boosting的区别,以及AdaBoost算法的优缺点。
点
- 在本文中,我们了解了 boosting 的工作原理。
- 我们了解 adaboost 背后的数学原理。
- 我们了解了如何使用弱学习器作为估计器来提高准确性。
五、常见的问题
答:Adaboost 属于机器学习的监督学习分支。这意味着训练数据必须有一个目标变量。使用adaboost学习技术,我们可以解决分类和回归问题。
答:需要较少的预处理,因为您不需要缩放自变量。AdaBoost 算法中的每次迭代都使用决策树桩作为单独的模型,因此所需的预处理与决策树相同。AdaBoost 也不太容易出现过度拟合。除了增强弱学习器之外,我们还可以微调这些集成技术中的超参数(例如learning_rate)以获得更好的准确性。
答:与随机森林、决策树、逻辑回归和支持向量机分类器非常相似,AdaBoost 也要求训练数据具有目标变量。该目标变量可以是分类变量或连续变量。scikit-learn 库包含 Adaboost 分类器和回归器;因此我们可以使用Python中的sklearn来创建adaboost模型。
相关文章:
AdaBoost 算法:理解、实现和掌握 AdaBoost
一、介绍 Boosting 是一种集成建模技术,由 Freund 和 Schapire 于 1997 年首次提出。从那时起,Boosting 就成为解决二元分类问题的流行技术。这些算法通过将大量弱学习器转换为强学习器来提高预测能力 。 Boosting 算法背后的原理是,我们首先…...
基于ssm+vue设备配件检修管理系统
摘要 随着工业设备的日益复杂和多样化,设备配件的检修管理成为保障生产运行和设备寿命的关键环节。本研究基于SSM框架(Spring Spring MVC MyBatis),致力于设计和实现一套全面、高效的设备配件检修管理系统。该系统不仅能够提高设…...
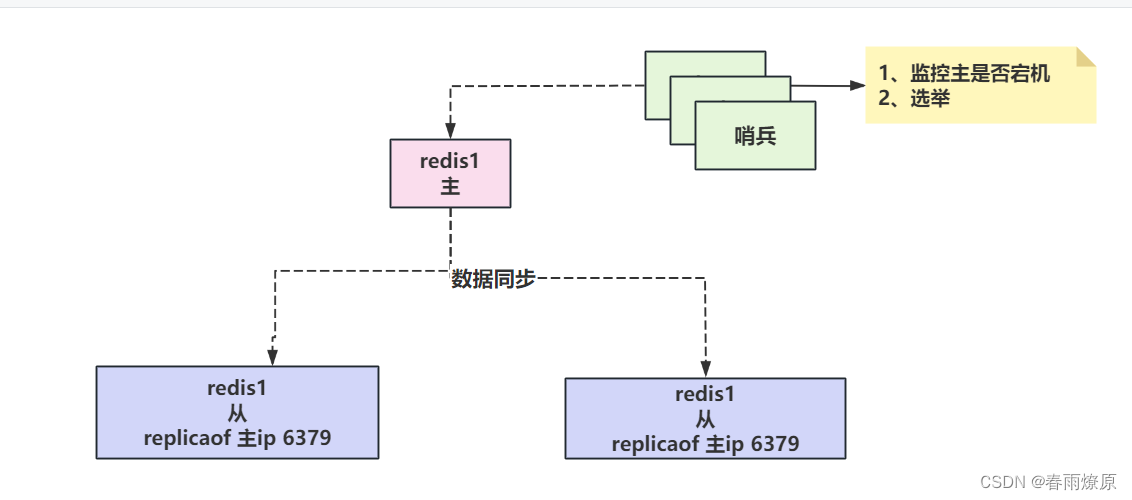
Reids集群
目录 一、集群的概念 1.为什么要搭建集群? 2.Redis搭建集群是否需要考虑状态同步的问题? 二、Redis集群的模式 1.redis集群--主从模式 1.1什么是Redis的主从模式? 1.2.主从模式它们之间的数据是怎么实现一个同步的? 1.3.主…...

自定义指令基础
除了 Vue 内置的一系列指令 (比如 v-model 或 v-show) 之外,Vue 还允许你注册自定义的指令 (Custom Directives) 选项式API_自定义指令 <template><h3>自定义指令</h3><p v-author>文本信息</p> </template> <script> e…...
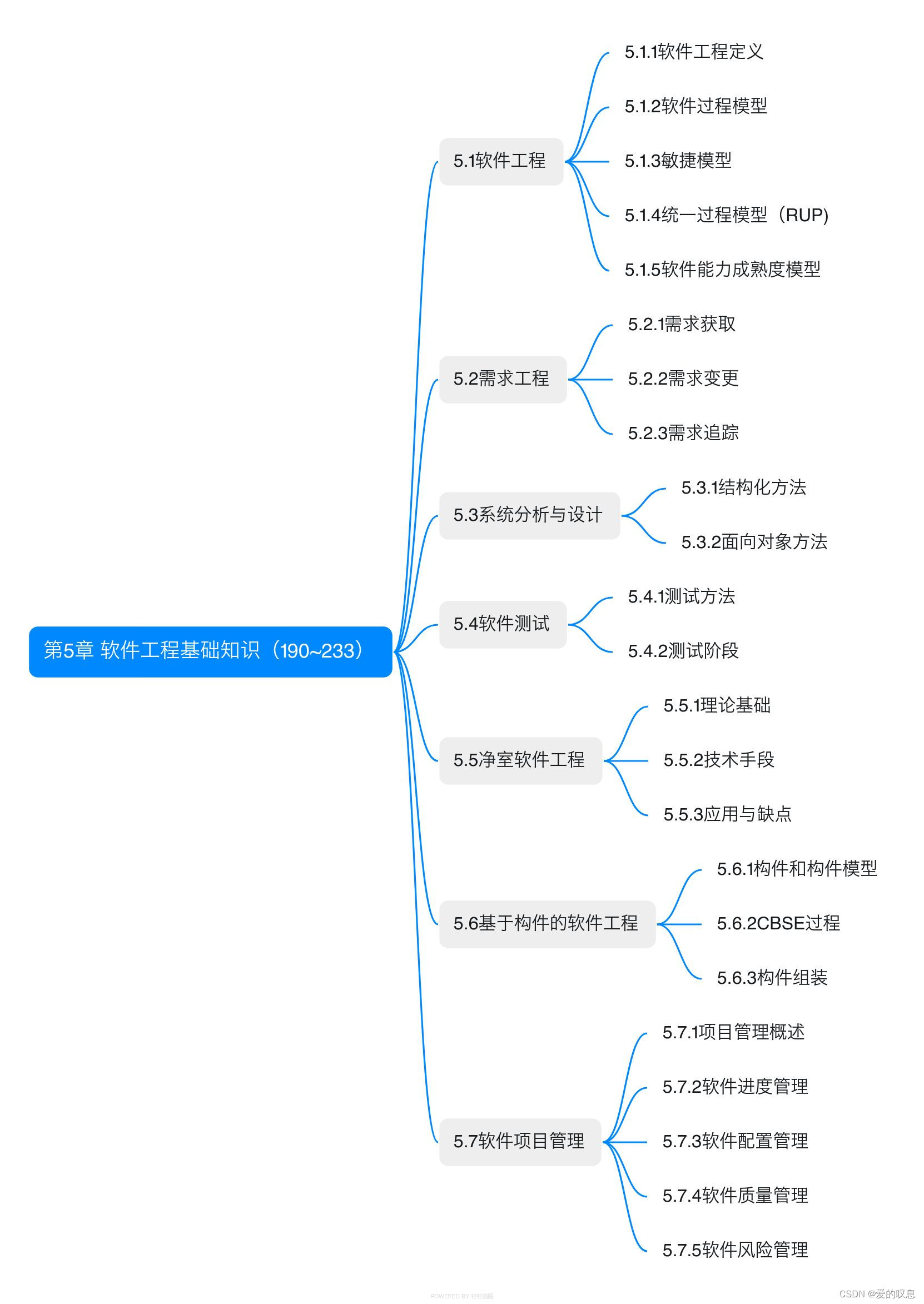
软考-高级-系统架构设计师教程(清华第2版)【第5章 软件工程基础知识(190~233)-思维导图】
软考-高级-系统架构设计师教程(清华第2版)【第5章 软件工程基础知识(190~233)-思维导图】 课本里章节里所有蓝色字体的思维导图...
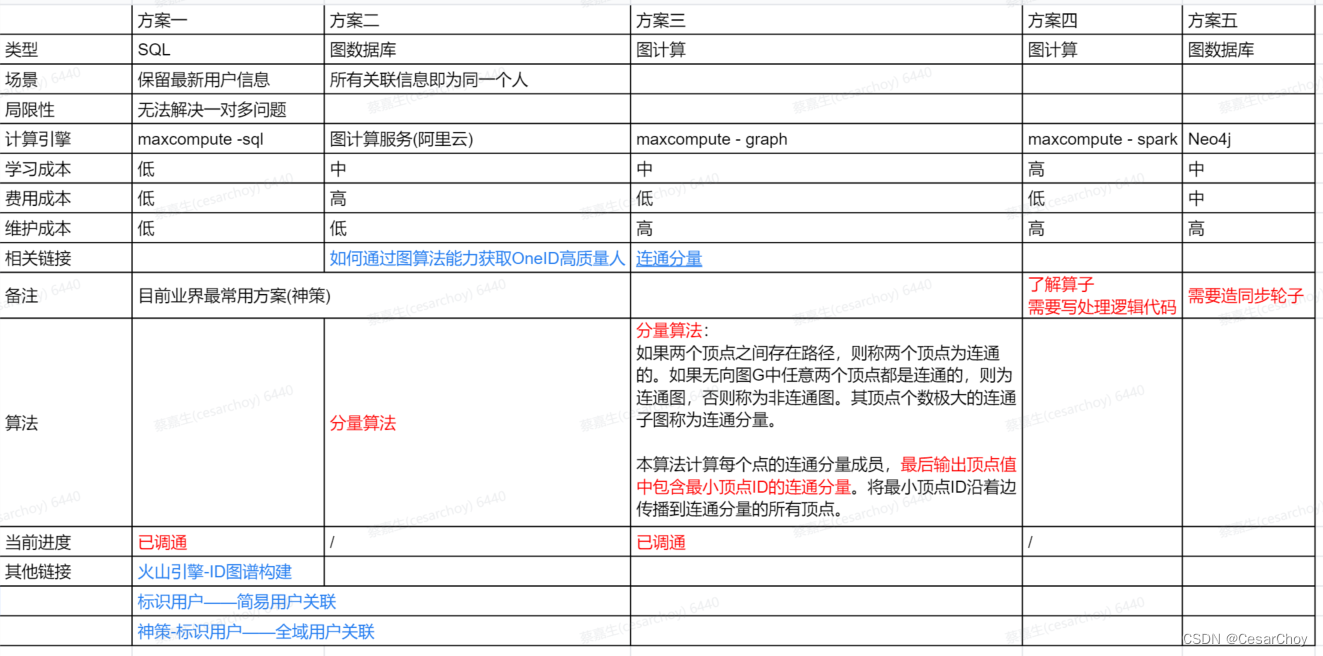
Oneid方案
一、前文 用户画像的前提是标识出用户,存在以下场景:不同业务系统对同一个人的标识,匿名用户行为的行为归因;本文提供多种解决方案,提供大家思考。 二、方案矩阵 三、其他 相关连接: 如何通过图算法能力获…...
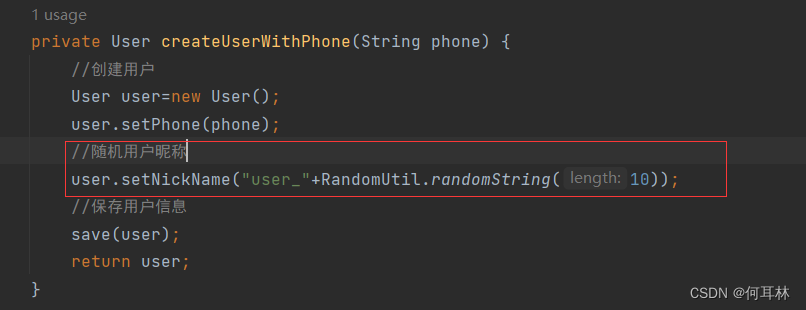
【超好用的工具库】hutool-all工具库的基本使用
简介(可不看): hutool-all是一个Java工具库,提供了许多实用的工具类和方法,用于简化Java开发过程中的常见任务。它包含了各种模块,涵盖了字符串操作、日期时间处理、加密解密、文件操作、网络通信、图片处…...

趣学python编程 (一、计算机基础知识科普)
未来是高度科技化和智能化的时代。过去不识字的叫“文盲”,如今不懂点计算机知识,则可能是新时代的“文盲”。不论从事什么行业,了解下计算机和编程都是有益的。Python 连续多年占据最受欢迎的编程语言榜首,未来Python有机会成为像…...
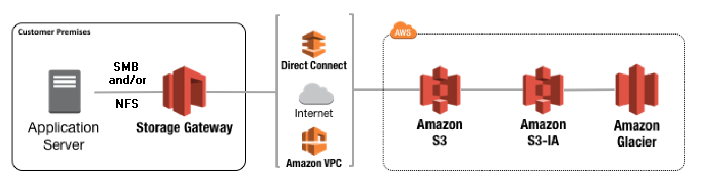
亚马逊云科技云存储服务指南
文章作者:Libai 高效的云存储服务对于现代软件开发中的数据管理至关重要。亚马逊云科技云存储服务提供了强大的工具,可以简化工作流程并增强数据管理能力。 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏…...
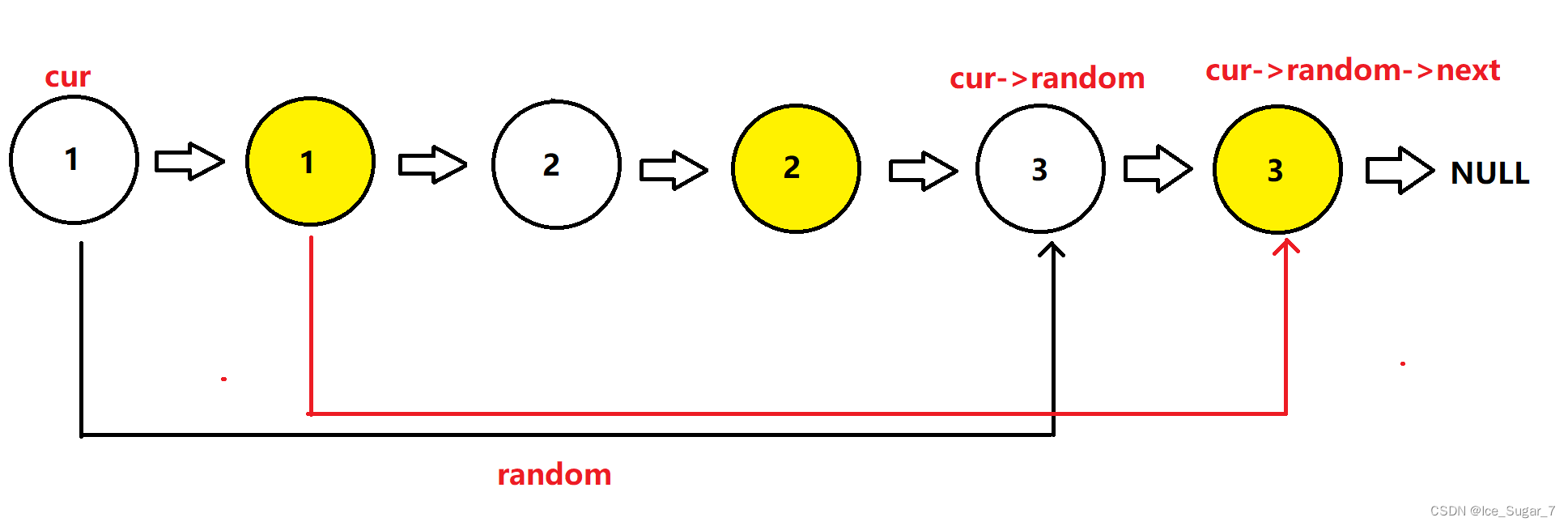
随机链表的复制
文章目录 🍉前言🍉题目🍉分析🍉思路一:暴力解法🍉思路二:很绝的办法 🍉前言 果然,力扣的简单题不一定简单,但是中等和较难的题一定很麻烦。 这道题相当综合&…...

树莓派4b编译FFmpeg支持硬件编解码
ffmpeg h264_omx解码器充分发挥树莓派gpu性能 准备 树莓派4b ,64位系统 修改树莓派的启动设置文件(/boot/config.txt)进行如下的调整: gpu_mem=256 framebuffer_depth=16安装依赖 常规依赖: sudo apt update sudo apt upgrade sudo apt -y install autoconf automake …...

开启CentOS/Debian自带的TCP BBR加速
BBR 是什么我就不多做介绍了。如果系统自带内核高于4.9 则默认已包含 BBR。 操作方法: 1、使用 root 权限运行下面代码 uname -r //内核版本高于 4.9 就行。2、开启BBR echo "net.core.default_qdiscfq" >> /etc/sysctl.conf echo "net.ip…...
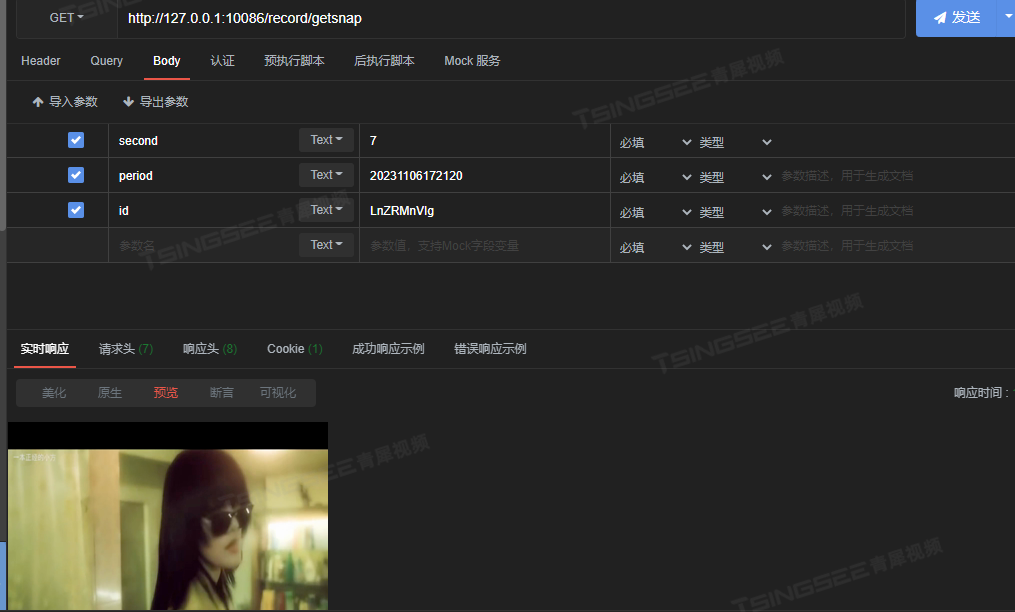
视频推拉流EasyDSS直播点播平台获取指定时间快照的实现方法
视频推拉流直播点播系统EasyDSS平台,可提供流畅的视频直播、点播、视频推拉流、转码、管理、分发、录像、检索、时移回看等功能,可兼容多操作系统,在直播点播领域具有广泛的场景应用。为了便于用户集成、调用与二次开发。 今天我们来介绍下在…...

CSS---关于font文本属性设置样式总结
目录 1、color属性 2、font-size属性 3、font-weight属性 4、font-family属性 5、text-align属性 6、line-height属性 7、text-indent属性 8、letter-spacing属性 9、word-spacing属性 10、word-break属性 11、white-space属性 12、text-transform 12、writing-mo…...

7、使用真机调试鸿蒙项目
此处以华为手机为例,版本为鸿蒙4.0. 一、打开手机调试功能 1、打开开发者模式 打开“设置”—“关于手机”,连续点击“软件版本”可打开开发者模式 2、开启USB调试功能 打开“设置”—“系统更新”—“开发者选项”,下拉找到“USB调试”…...
)
GPT实战系列-P-Tuning本地化训练ChatGLM2等LLM模型,到底做了什么?(一)
GPT实战系列-如何使用P-Tuning本地化训练ChatGLM2等LLM模型? 文章目录 GPT实战系列-如何使用P-Tuning本地化训练ChatGLM2等LLM模型?P-Tuning微调训练概述1、预训练模型或者是torch模型2、训练器的超参数3、数据预处理工具4、加载数据5、分词处理6、数据预…...

【Python】爬虫代理IP的使用+建立代理IP池
目录 前言 一、代理IP 1. 代理IP的获取 2. 代理IP的验证 3. 代理IP的使用 二、建立代理IP池 1. 代理IP池的建立 2. 动态维护代理IP池 三、完整代码 总结 前言 在进行网络爬虫开发时,我们很容易遭遇反爬虫机制的阻碍。为了规避反爬虫机制,我们…...
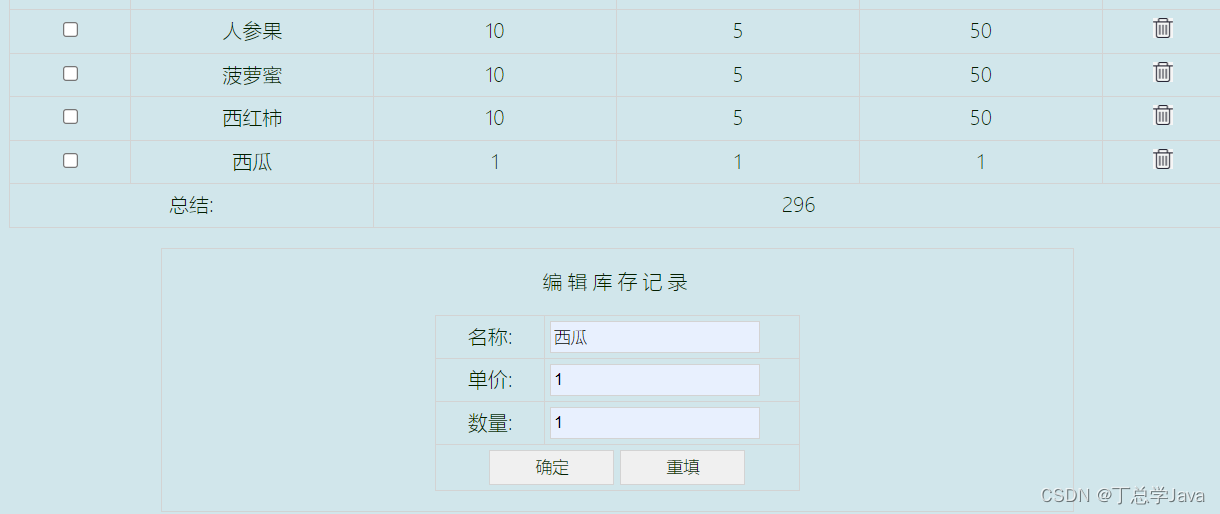
JS-项目实战-新增水果库存功能实现
1、fruit.js function $(name) {if (name) {//假设name是 #fruit_tblif (name.startsWith("#")) {name name.substring(1); //fruit_tblreturn document.getElementById(name);} else {return document.getElementsByName(name); //返回的是NodeList类型}} }//当…...

mysql 常见操作指令
use k_order – 查看版本 select version(); – 查看所有数据库 show databases; – 查看所有执行引擎 show engines; – 查看当前数据库 select database(); – 查看所有table show tables; – 查看默认存储引擎 SHOW VARIABLES LIKE ‘default_storage_engine’; – 系…...
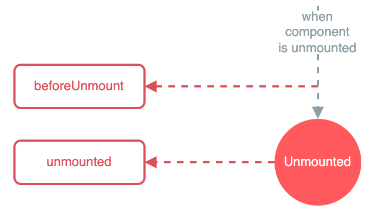
Vue3 生命周期
如下是Vue3的生命周期函数图: 一、Vue2生命周期和Vue3声明周期的区别 1. Vue2 中,只要创建Vue实例对象而不需要挂载就可以实现beforeCreate 和 created 生命周期函数。 Vue3中必须要将Vue实例对象挂载完成,所有的准备工作做完,…...
)
Verilog specify语法实战:如何用5分钟搞定模块路径延时配置(附常见坑点)
Verilog specify语法实战:5分钟掌握模块路径延时配置与避坑指南 在数字电路设计中,精确控制信号传播延迟是确保时序收敛的关键环节。作为硬件描述语言的核心特性之一,Verilog的specify块提供了一种声明式方法来定义模块引脚间的路径延迟&…...

**发散创新:基于Python的鲁棒水印技术实战解析与代码实现**在多
发散创新:基于Python的鲁棒水印技术实战解析与代码实现 在多媒体内容日益泛滥的今天,数字水印技术已成为版权保护、防伪溯源和内容认证的核心手段之一。本文将深入探讨一种基于离散余弦变换(DCT)的鲁棒图像水印嵌入与提取算法&…...

如何3步搞定黑苹果?这款零代码工具让你告别3天煎熬
如何3步搞定黑苹果?这款零代码工具让你告别3天煎熬 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 你是不是也曾被黑苹果配置折磨得焦头烂…...

5分钟搞定foobar2000美化:foobox-cn让你的音乐播放器焕然一新!
5分钟搞定foobar2000美化:foobox-cn让你的音乐播放器焕然一新! 【免费下载链接】foobox-cn DUI 配置 for foobar2000 项目地址: https://gitcode.com/GitHub_Trending/fo/foobox-cn 厌倦了千篇一律的音乐播放器界面?想让你的foobar200…...

Spring Cloud Hystrix 详细示-元一软件
Hystrix 是 Spring Cloud 中实现服务熔断、降级、隔离的核心组件,用于解决微服务架构中的雪崩效应,核心是快速失败、优雅降级、自动恢复。以下从环境搭建、基础使用、高级配置、Feign 整合、监控5 个维度提供完整示例。一、项目环境准备1. 依赖引入&…...

深入解析DSP的多通道缓冲串口McBSP数据通路与控制通路
1. McBSP基础概念与核心功能 多通道缓冲串口(McBSP)是数字信号处理器(DSP)中用于高速串行通信的关键外设模块。我第一次接触这个模块是在开发音频处理系统时,当时为了搞定I2S音频数据传输,花了整整两周时间…...
)
用Python从零实现一个卡尔曼滤波器(附完整代码与可视化)
用Python从零实现一个卡尔曼滤波器(附完整代码与可视化) 卡尔曼滤波是工程领域最经典的状态估计算法之一,广泛应用于导航、控制、信号处理等领域。但对于初学者而言,面对复杂的矩阵运算和抽象的概率推导常常无从下手。本文将用Pyt…...

03 AgentSkills 生态体系与跨平台支持全景
03 AgentSkills 生态体系与跨平台支持全景 关键词:AgentSkills 生态、跨平台支持、Claude Code、Cursor、GitHub Copilot、VS Code、Spring AI、SkillsMP、Skill Seekers、技能共享、Symlink、官方技能库一、从标准到生态:一项规范的生命力 衡量一个技术…...

Linux内存管理:malloc与free实现原理详解
Linux内存管理:malloc和free的实现原理深度解析1. 动态内存分配基础1.1 malloc和free函数原型void* malloc(size_t size); void free(void* ptr);malloc函数分配指定字节数的内存空间,返回指向该空间的void指针。由于返回的是通用指针,使用时…...

别再死记硬背公式了!用Python+SymPy手把手推导平面2R机器人动力学方程
用PythonSymPy实战推导平面2R机器人动力学方程 在机器人学领域,动力学方程的推导往往是理论学习中最令人头疼的环节。传统教材中密密麻麻的偏微分符号和冗长的代数运算,让许多初学者望而却步。本文将带你用Python的SymPy符号计算库,从零开始完…...