pytorch单精度、半精度、混合精度、单卡、多卡(DP / DDP)、FSDP、DeepSpeed模型训练
pytorch单精度、半精度、混合精度、单卡、多卡(DP / DDP)、FSDP、DeepSpeed(环境没搞起来)模型训练代码,并对比不同方法的训练速度以及GPU内存的使用
代码:pytorch_model_train
FairScale(你真的需要FSDP、DeepSpeed吗?)
在了解各种训练方式之前,先来看一下 FairScale 给出的一个模型训练方式选择的流程,选择适合自己的方式,就是最好的。

训练环境设置
- 模型:预训练的Resnet50
- 数据集:Cifar10
- 硬件资源:一台4卡Tesla P40
- 训练设置:5 epoch、128 batch size
- 观察指标:显存占用、GPU使用率、训练时长、模型训练结果
备注:
- 由于P40硬件限制,不支持半精度fp16的训练,在fp16条件下训练的速度会受到影
响 - ResNet50模型较小,batch_size=1时单卡仅占用 0.34G显存,绝大部分显存都被输入数据,以及中间激活占用
测试基准(batch_size=1)
- 单卡显存占用:0.34 G
- 单卡GPU使用率峰值:60%
单卡单精度训练
- 代码文件:pytorch_SingleGPU.py
- 单卡显存占用:11.24 G
- 单卡GPU使用率峰值:100%
- 训练时长(5 epoch):1979 s
- 训练结果:准确率85%左右

单卡半精度训练
- 代码文件:pytorch_half_precision.py
- 单卡显存占用:5.79 G
- 单卡GPU使用率峰值:100%
- 训练时长(5 epoch):1946 s
- 训练结果:准确率75%左右

备注: 单卡半精度训练的准确率只有75%,单精度的准确率在85%左右
单卡混合精度训练
AUTOMATIC MIXED PRECISION PACKAGE - TORCH.AMP
CUDA AUTOMATIC MIXED PRECISION EXAMPLES
PyTorch 源码解读之 torch.cuda.amp: 自动混合精度详解
如何使用 PyTorch 进行半精度、混(合)精度训练
如何使用 PyTorch 进行半精度训练
pytorch模型训练之fp16、apm、多GPU模型、梯度检查点(gradient checkpointing)显存优化等
Working with Multiple GPUs
- 代码文件:pytorch_auto_mixed_precision.py
- 单卡显存占用:6.02 G
- 单卡GPU使用率峰值:100%
- 训练时长(5 epoch):1546 s
- 训练结果:准确率85%左右

- 混合精度训练过程

- 混合精度训练基本流程
- 维护一个 FP32 数值精度模型的副本
- 在每个iteration
- 拷贝并且转换成 FP16 模型
- 前向传播(FP16 的模型参数)
- loss 乘 scale factor s
- 反向传播(FP16 的模型参数和参数梯度)
- 参数梯度乘 1/s
- 利用 FP16 的梯度更新 FP32 的模型参数
- autocast结合GradScaler用法
# Creates model and optimizer in default precision
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)# Creates a GradScaler once at the beginning of training.
scaler = GradScaler()for epoch in epochs:for input, target in data:optimizer.zero_grad()# Runs the forward pass with autocasting.with autocast(device_type='cuda', dtype=torch.float16):output = model(input)loss = loss_fn(output, target)# Scales loss. Calls backward() on scaled loss to create scaled gradients.# Backward passes under autocast are not recommended.# Backward ops run in the same dtype autocast chose for corresponding forward ops.scaler.scale(loss).backward()# scaler.step() first unscales the gradients of the optimizer's assigned params.# If these gradients do not contain infs or NaNs, optimizer.step() is then called,# otherwise, optimizer.step() is skipped.scaler.step(optimizer)# Updates the scale for next iteration.scaler.update()
- 基于GradScaler进行梯度裁剪
scaler.scale(loss).backward()
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
scaler.step(optimizer)
scaler.update()
- autocast用法
# Creates some tensors in default dtype (here assumed to be float32)
a_float32 = torch.rand((8, 8), device="cuda")
b_float32 = torch.rand((8, 8), device="cuda")
c_float32 = torch.rand((8, 8), device="cuda")
d_float32 = torch.rand((8, 8), device="cuda")with torch.autocast(device_type="cuda"):# torch.mm is on autocast's list of ops that should run in float16.# Inputs are float32, but the op runs in float16 and produces float16 output.# No manual casts are required.e_float16 = torch.mm(a_float32, b_float32)# Also handles mixed input typesf_float16 = torch.mm(d_float32, e_float16)# After exiting autocast, calls f_float16.float() to use with d_float32
g_float32 = torch.mm(d_float32, f_float16.float())
- autocast嵌套使用
# Creates some tensors in default dtype (here assumed to be float32)
a_float32 = torch.rand((8, 8), device="cuda")
b_float32 = torch.rand((8, 8), device="cuda")
c_float32 = torch.rand((8, 8), device="cuda")
d_float32 = torch.rand((8, 8), device="cuda")with torch.autocast(device_type="cuda"):e_float16 = torch.mm(a_float32, b_float32)with torch.autocast(device_type="cuda", enabled=False):# Calls e_float16.float() to ensure float32 execution# (necessary because e_float16 was created in an autocasted region)f_float32 = torch.mm(c_float32, e_float16.float())# No manual casts are required when re-entering the autocast-enabled region.# torch.mm again runs in float16 and produces float16 output, regardless of input types.g_float16 = torch.mm(d_float32, f_float32)
4卡 DP(Data Parallel)
- 代码文件:pytorch_DP.py
- 单卡显存占用:3.08 G
- 单卡GPU使用率峰值:99%
- 训练时长(5 epoch):742 s
- 训练结果:准确率85%左右

4卡 DDP(Distributed Data Parallel)
pytorch-multi-gpu-training
/ddp_train.py
DISTRIBUTED COMMUNICATION PACKAGE - TORCH.DISTRIBUTED
- 代码文件:pytorch_DDP.py
- 单卡显存占用:3.12 G
- 单卡GPU使用率峰值:99%
- 训练时长(5 epoch):560 s
- 训练结果:准确率85%左右

- 代码启动命令(单机 4 GPU)
python -m torch.distributed.launch --nproc_per_node=4 --nnodes=1 pytorch_DDP.py
基于accelerate的 DDP
huggingface/accelerate
Hugging Face开源库accelerate详解
- 代码文件:accelerate_DDP.py
- 单卡显存占用:3.15 G
- 单卡GPU使用率峰值:99%
- 训练时长(5 epoch):569 s
- 训练结果:准确率85%左右

- accelerate配置文件default_DDP.yml
compute_environment: LOCAL_MACHINE
distributed_type: MULTI_GPU
downcast_bf16: 'no'
gpu_ids: all
machine_rank: 0
main_training_function: main
mixed_precision: 'no'
num_machines: 1
num_processes: 4
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
- 代码启动命令(单机 4 GPU)
accelerate launch --config_file ./config/default_DDP.yml accelerate_DDP.py
Pytorch + FSDP(Fully Sharded Data Parallel)
Pytorch FULLY SHARDED DATA PARALLEL (FSDP) 初识
2023 年了,大模型训练还要不要用 PyTorch 的 FSDP ?
GETTING STARTED WITH FULLY SHARDED DATA PARALLEL(FSDP)
-
batch_size == 1
- 单卡显存占用:0.19 G,相比基准测试的 0.34G 有减少,但是没有达到4倍
- 单卡GPU使用率峰值:60%
-
batch_size == 128
- 单卡显存占用:2.88 G
- 单卡GPU使用率峰值:99%
-
代码文件:pytorch_FSDP.py
-
训练时长(5 epoch):581 s
-
训练结果:准确率85%左右
备注: pytorch里面的FSDP的batchsize是指单张卡上的batch大小

- 代码启动命令(单机 4 GPU)
python -m torch.distributed.launch --nproc_per_node=4 --nnodes=1 pytorch_FSDP.py
- FSDP包装后的模型
代码中指定对Resnet50中的Linear和Conv2d层应用FSDP。

基于accelerate的 FSDP(Fully Sharded Data Parallel)
-
batch_size == 1
- 单卡显存占用:0.38 G,相比基准测试的 0.34G 并没有减少
- 单卡GPU使用率峰值:60%
-
batch_size == 128
- 单卡显存占用:2.90 G
- 单卡GPU使用率峰值:99%
-
代码文件:accelerate_FSDP.py
-
训练时长(5 epoch):576 s,对于这个小模型速度和DDP相当
-
训练结果:准确率85%左右

- accelerate配置文件default_FSDP.yml
compute_environment: LOCAL_MACHINE
distributed_type: FSDP
downcast_bf16: 'no'
fsdp_config:fsdp_auto_wrap_policy: SIZE_BASED_WRAPfsdp_backward_prefetch_policy: BACKWARD_PREfsdp_forward_prefetch: truefsdp_min_num_params: 1000000fsdp_offload_params: falsefsdp_sharding_strategy: 1fsdp_state_dict_type: SHARDED_STATE_DICTfsdp_sync_module_states: truefsdp_use_orig_params: true
machine_rank: 0
main_training_function: main
mixed_precision: 'no'
num_machines: 1
num_processes: 4
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
- 代码启动命令(单机 4 GPU)
accelerate launch --config_file ./config/default_FSDP.yml accelerate_FSDP.py
Pytorch + DeepSpeed(环境没搞起来,哈哈哈)
[BUG] error: unrecognized arguments: --deepspeed ./ds_config.json #3961
fused_adam.so: cannot open shared object file: No such file or directory #119
DeepSpeedExamples/training/cifar/
Getting Started
-
代码文件:pytorch_DeepSpeed.py
-
单卡显存占用:
-
单卡GPU使用率峰值:
-
训练时长(5 epoch):
-
训练结果:
-
代码启动命令(单机 4 GPU)
deepspeed pytorch_DeepSpeed.py --deepspeed_config ./config/zero_stage2_config.json
基于accelerate的 DeepSpeed(环境没搞起来,哈哈哈)
DeepSpeed介绍
深度解析:如何使用DeepSpeed加速PyTorch模型训练
DeepSpeed
- 代码文件:accelerate_DeepSpeed.py
- 单卡显存占用:
- 单卡GPU使用率峰值:
- 训练时长(5 epoch):
- 训练结果:
相关文章:
pytorch单精度、半精度、混合精度、单卡、多卡(DP / DDP)、FSDP、DeepSpeed模型训练
pytorch单精度、半精度、混合精度、单卡、多卡(DP / DDP)、FSDP、DeepSpeed(环境没搞起来)模型训练代码,并对比不同方法的训练速度以及GPU内存的使用 代码:pytorch_model_train FairScale(你真…...
基于PHP的纺织用品商城系统
有需要请加文章底部Q哦 可远程调试 基于PHP的纺织用品商城系统 一 介绍 此纺织用品商城系统基于原生PHP开发,数据库mysql,前端bootstrap。用户可注册登录,购物下单,评论等。管理员登录后台可对纺织用品,用户…...

Go使用命令行输出二维码
引言 二维码(QR code)是一种矩阵条码的标准,广泛应用于商业、移动支付和数据存储等领域。在开发过程中,我们可能需要在命令行中显示二维码,这可以帮助我们快速生成和分享二维码信息。本文将介绍如何使用Go语言生成二维…...

最长连续序列[中等]
优质博文:IT-BLOG-CN 一、题目 给定一个未排序的整数数组nums,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。请你设计并实现时间复杂度为O(n)的算法解决此问题。 示例 1: 输入:nums […...
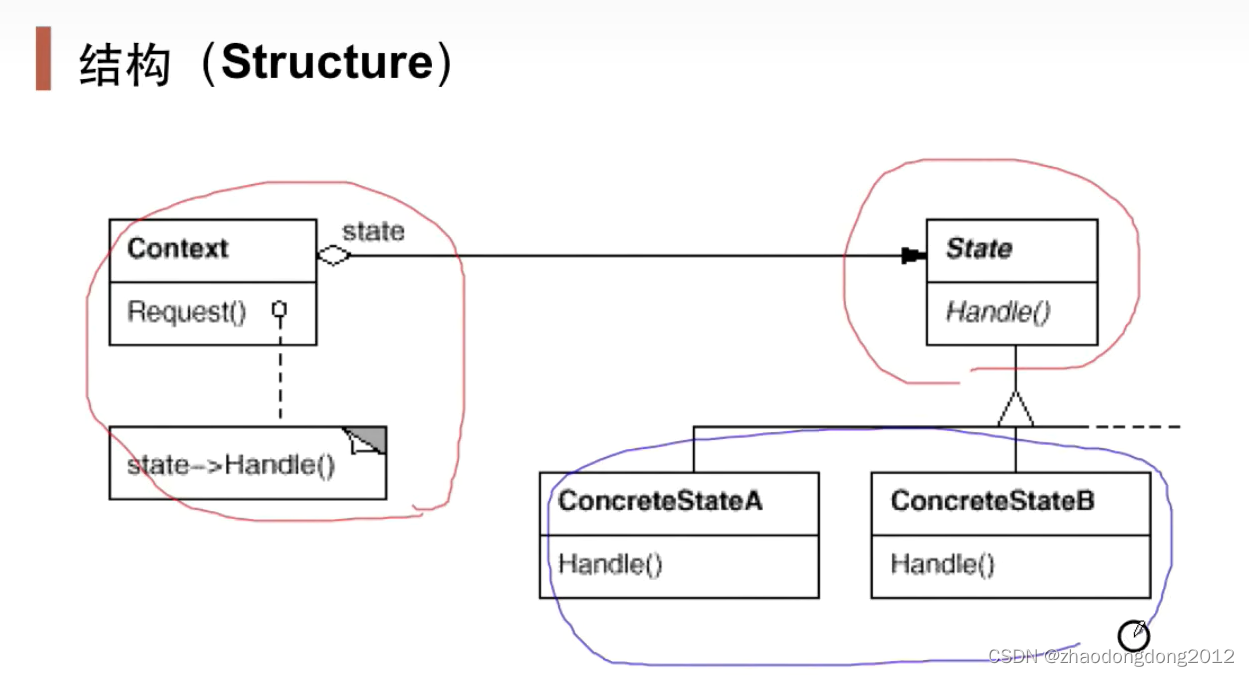
设计模式-状态模式-笔记
状态模式State 在组件构建过程中,某些对象的状态经常面临变化,如何对这些变化进行有效的管理?同时又维持高层模块的稳定?“状态变化”模式为这一问题提供了一种解决方案。 经典模式:State、Memento 动机(…...

Java中for、foreach、stream区别和性能比较
文章目录 性能比较区别使用方式和行为 性能比较 最终总结:如果数据在1万以内的话,for循环效率高于foreach和stream;如果数据量在10万的时候,stream效率最高,其次是foreach,最后是for。另外需要注意的是如果数据达到10…...
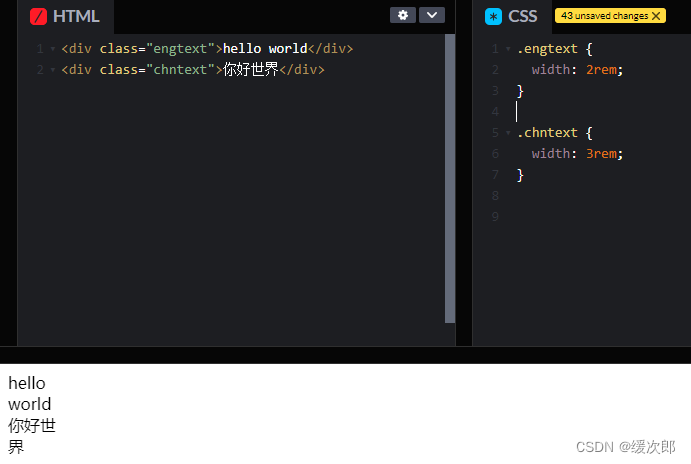
[CSS] 文本折行
文本折行一般分为两种情况: CJK(Chinese/Japanese/Korean) 字符和非 CJK 字符。一般非 CJK 字符折行发生在两个单词的空格中间,见下图: 图中文本 “hello world” 包裹容器的宽度为 2rem,但是 hello 并没有…...
)
033-从零搭建微服务-日志插件(一)
写在最前 如果这个项目让你有所收获,记得 Star 关注哦,这对我是非常不错的鼓励与支持。 源码地址(后端):mingyue: 🎉 基于 Spring Boot、Spring Cloud & Alibaba 的分布式微服务架构基础服务中心 源…...
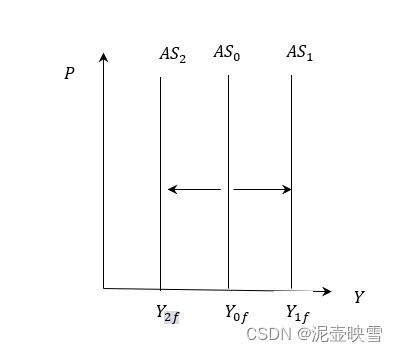
短期经济波动:均衡国民收入决定理论(三)
短期经济波动:国民收入决定理论(三) 文章目录 短期经济波动:国民收入决定理论(三)[toc]1 总需求曲线及其变动1.1 总需求曲线含义1.2 总需求曲线推导1.2.1 代数推导1.2.2 几何推导 1.3 AD曲线及其变动1.3.1 扩张性财政政策1.3.2 扩张性货币政策 2 总供给曲…...

电力感知边缘计算网关产品设计方案-网关软件架构
边缘计算网关采用ARM定制硬件平台架构,包含上位机端(内网)和FPGA网关端(外网)两部分,通过芯片间的高速信号总线实现边缘计算网关工业数据采集、数据实时传输、数据存储、网关状态信息收集等功能。 边缘计算网关上位机端(内网)重点完成工业数据采集、业务软件运算、客户…...
最新AI创作系统ChatGPT系统运营源码/支持最新GPT-4-Turbo模型/支持DALL-E3文生图
一、AI创作系统 SparkAi创作系统是基于OpenAI很火的ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如…...

Java使用Redis的几种客户端介绍
Redis是一种高性能的内存数据库,可以提供快速的数据读写操作。在Java中使用Redis,需要使用Redis客户端。目前,Java中常用的Redis客户端有以下几种: Jedis Jedis是Java中最流行的Redis客户端之一,它提供了丰富的API和…...

程序员的护城河
程序员的护城河 算法,一定是过硬的算法!!!举个栗子:算法不硬吃大亏写在最后 算法,一定是过硬的算法!!! 其实会什么技术不重要,掌握多少种编程语言也不重要&a…...
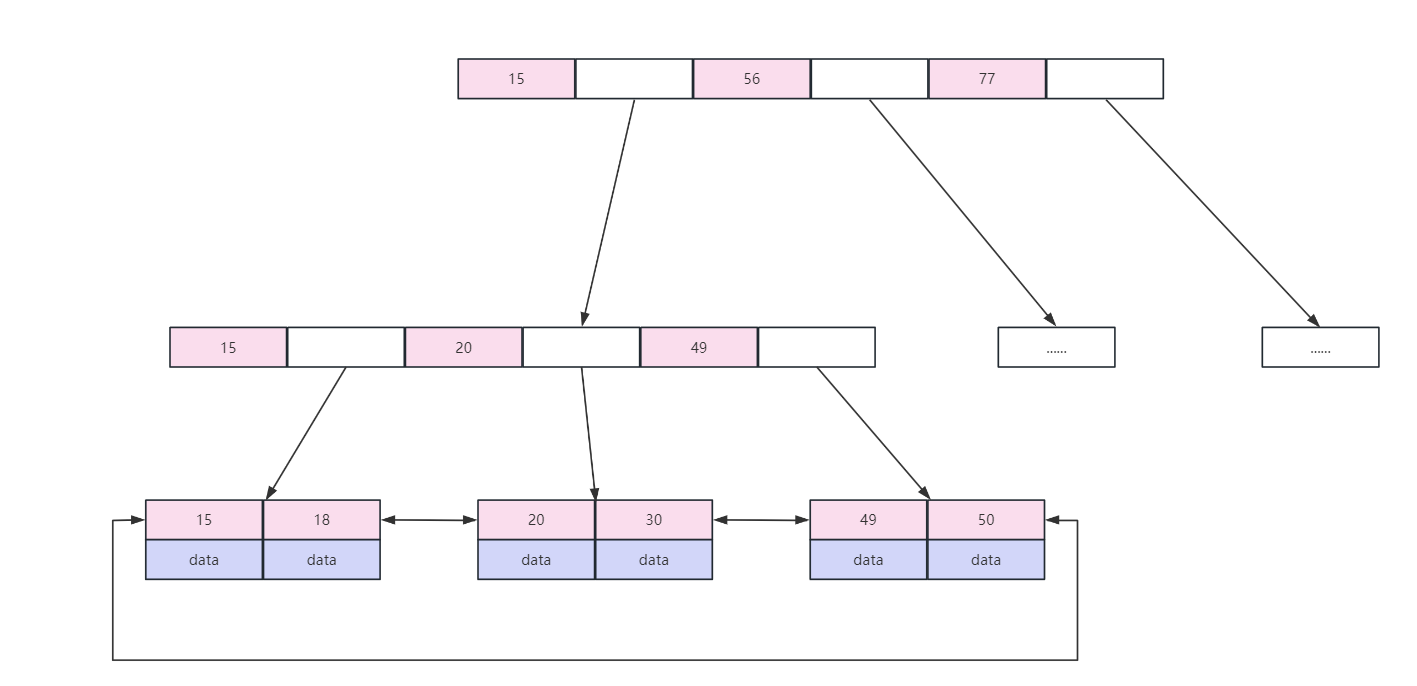
常见面试题-MySQL软删除以及索引结构
为什么 mysql 删了行记录,反而磁盘空间没有减少? 答: 在 mysql 中,当使用 delete 删除数据时,mysql 会将删除的数据标记为已删除,但是并不去磁盘上真正进行删除,而是在需要使用这片存储空间时…...
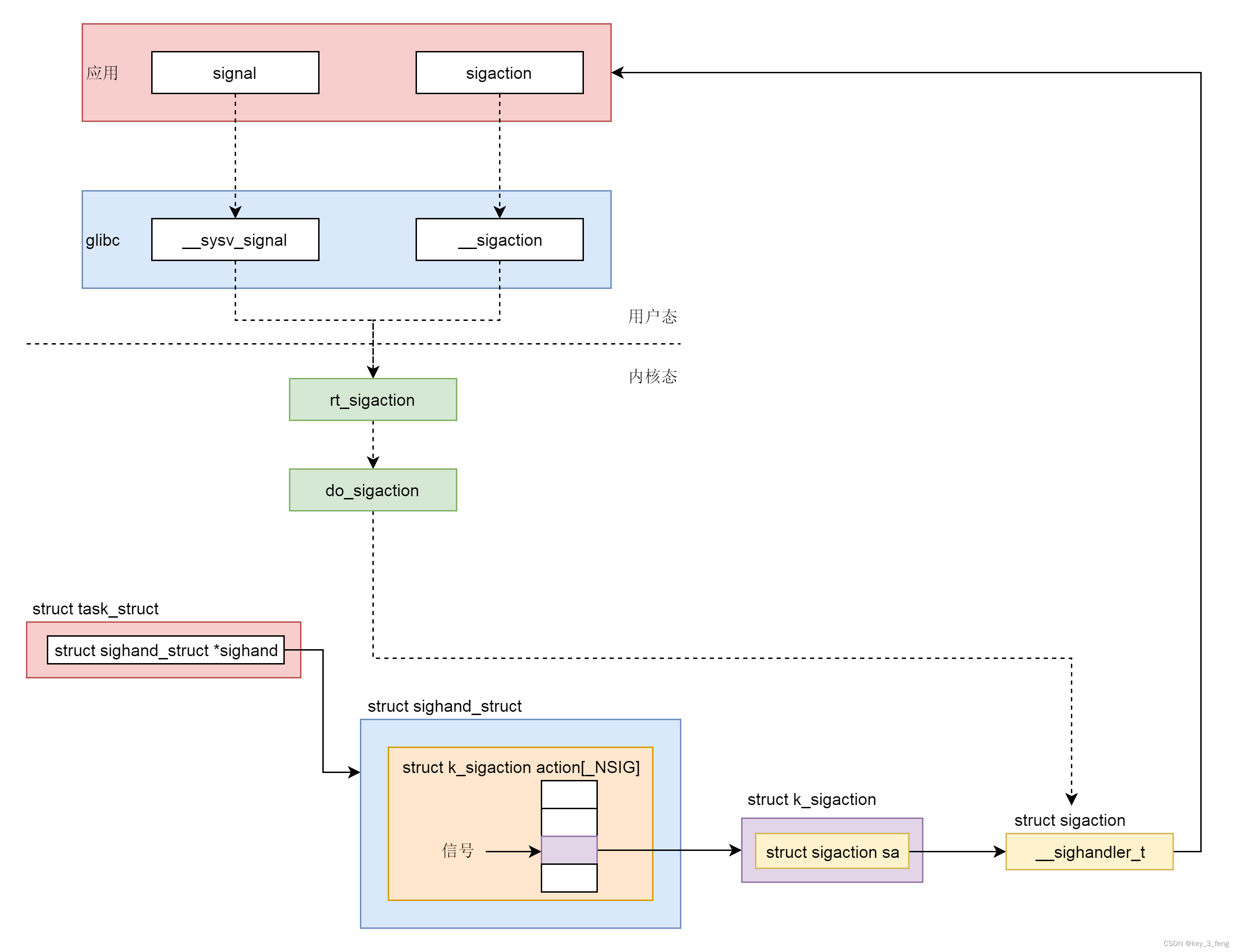
信号的机制——信号处理函数的注册
在 Linux 操作系统中,为了响应各种各样的事件,也是定义了非常多的信号。我们可以通过 kill -l 命令,查看所有的信号。 # kill -l1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP6) SIGABRT 7) SIGBUS …...
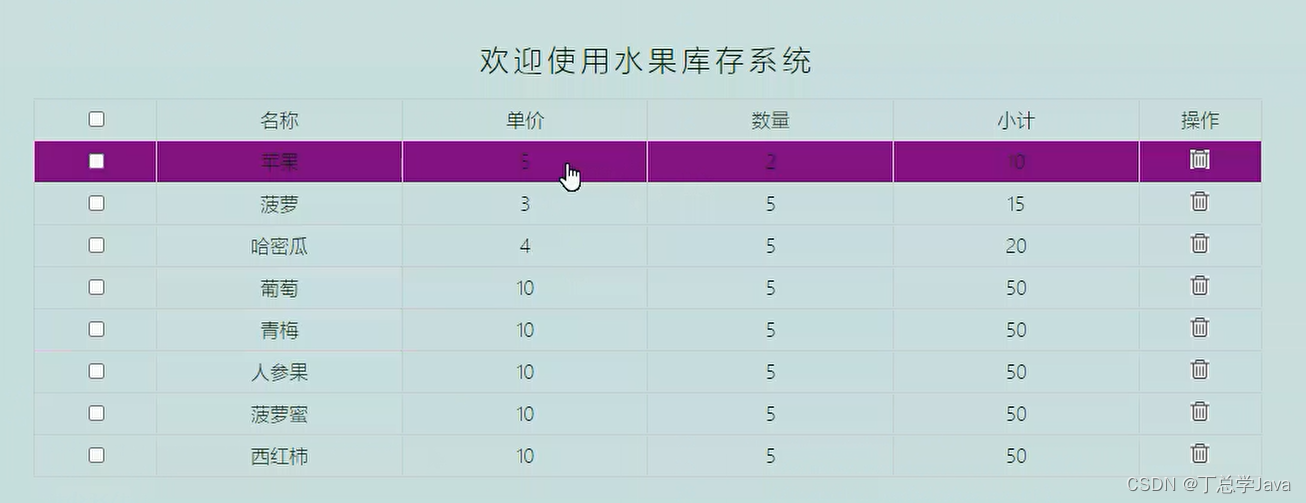
JS-项目实战-鼠标悬浮变手势(鼠标放单价上生效)
1、鼠标悬浮和离开事件.js //当页面加载完成后执行后面的匿名函数 window.onload function () {//get:获取 Element:元素 By:通过...方式//getElementById()根据id值获取某元素let fruitTbl document.getElementById("fruit_tbl");//table.rows:获取这个表格…...

redis运维(十一) python操作redis
一 python操作redis ① 安装pyredis redis常见错误 说明:由于redis服务器是5.0.8的,为了避免出现问题,默认最高版本的即可 --> 适配 ② 操作流程 核心:获取redis数据库连接对象 ③ Python 字符串前面加u,r,b的含义 原因: 字符串在…...
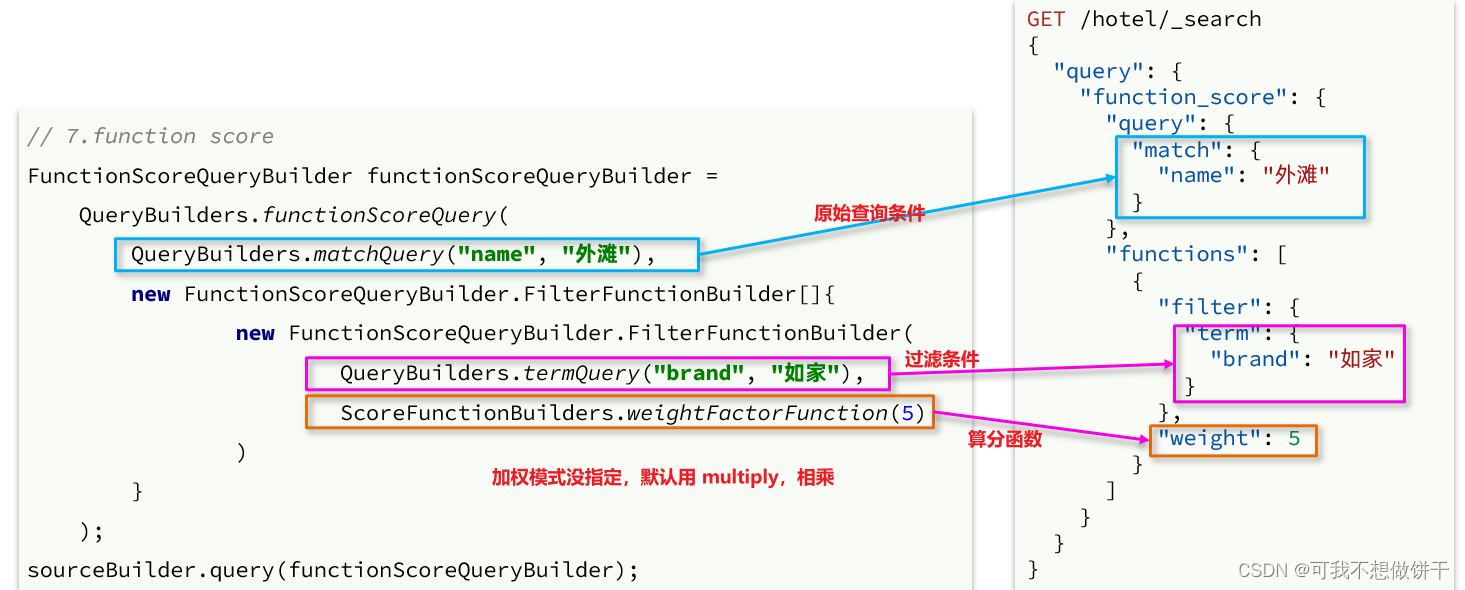
黑马程序员微服务 第五天课程 分布式搜索引擎2
分布式搜索引擎02 在昨天的学习中,我们已经导入了大量数据到elasticsearch中,实现了elasticsearch的数据存储功能。但elasticsearch最擅长的还是搜索和数据分析。 所以今天,我们研究下elasticsearch的数据搜索功能。我们会分别使用DSL和Res…...

什么是UV贴图?
UV 是与几何图形的顶点信息相对应的二维纹理坐标。UV 至关重要,因为它们提供了表面网格与图像纹理如何应用于该表面之间的联系。它们基本上是控制纹理上哪些像素对应于 3D 网格上的哪个顶点的标记点。它们在雕刻中也很重要。 为什么UV映射很重要? 默认情…...
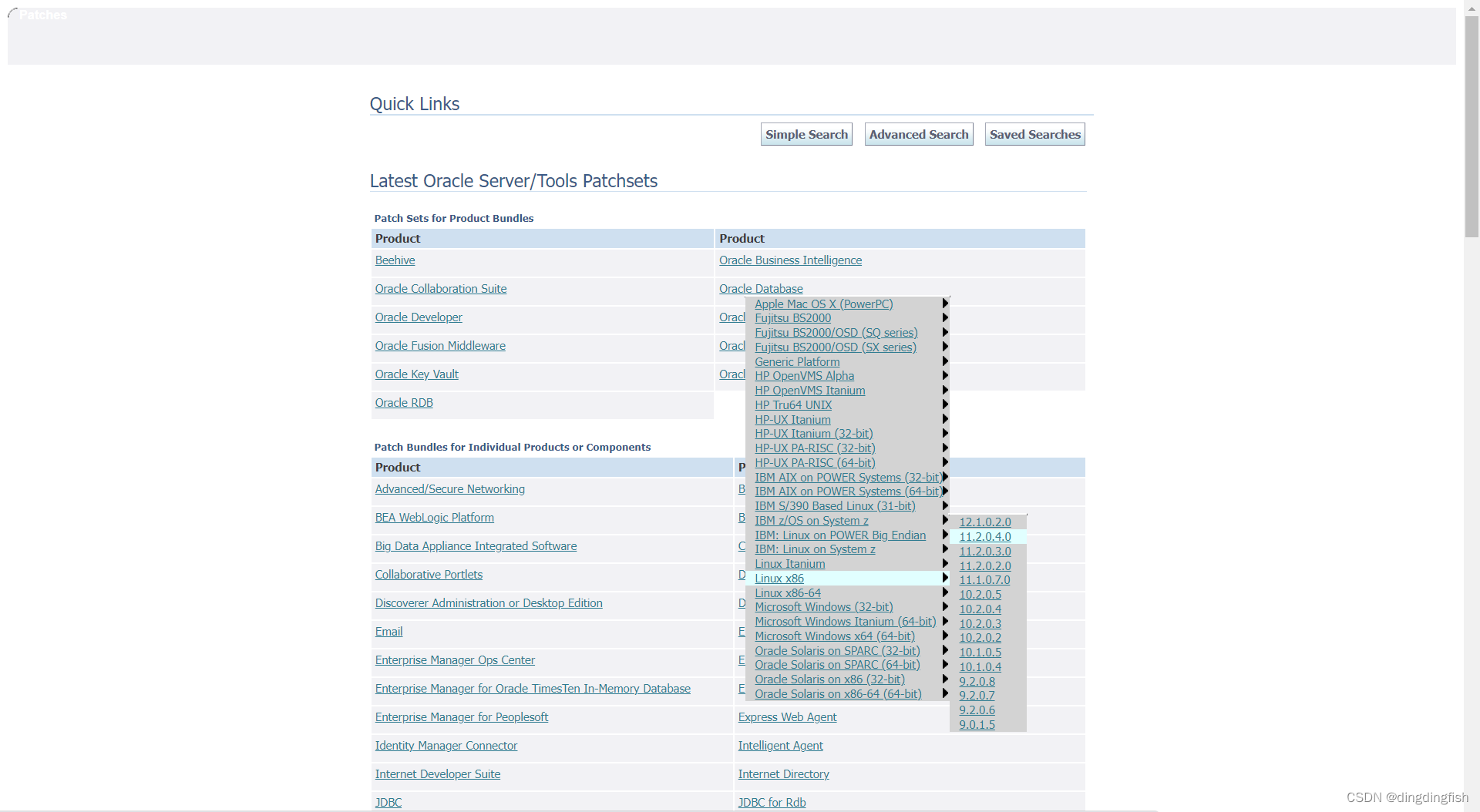
从哪里下载 Oracle database 11g 软件
登入My Oracle Support,选择Patches & Updates 标签页,点击下方的Latest Patchsets链接: 然后单击Oracle Database,就可以下载11g软件了: 安装单实例数据库需要1和2两个zip文件,安装GI需要第3个zip文…...

PicView图片浏览器完整指南:从零开始掌握高效图片管理技巧
PicView图片浏览器完整指南:从零开始掌握高效图片管理技巧 【免费下载链接】PicView Fast, free and customizable image viewer for Windows 10 and 11. 项目地址: https://gitcode.com/gh_mirrors/pi/PicView PicView是一款专为Windows 10和11设计的快速、…...
)
ESP32 Bootloader配置实战:如何优化启动时间与内存占用(附实测数据)
ESP32 Bootloader深度调优:从启动时间压缩到内存占用的实战指南 当你的ESP32设备在冷启动时需要等待超过500ms才能响应第一个用户指令,或是因内存不足频繁触发看门狗复位时,问题的根源往往隐藏在Bootloader的配置层。本文将带你穿透menuconfi…...

CentOS8网络管理大变革:从network.service到NetworkManager的全面解析
CentOS8网络管理架构深度解析:从传统命令到NetworkManager的进化之路 如果你是一位长期使用CentOS的系统管理员,最近升级到CentOS8后可能会遇到一个令人困惑的问题:当你习惯性地输入systemctl restart network命令时,系统却无情地…...

gemma-3-12b-it镜像开箱即用:3分钟完成多模态服务启动与测试
gemma-3-12b-it镜像开箱即用:3分钟完成多模态服务启动与测试 1. 快速了解Gemma-3-12b-it 如果你正在寻找一个既能理解文字又能看懂图片的AI模型,而且希望它能在普通电脑上运行,那么Gemma-3-12b-it就是为你准备的。 Gemma是Google推出的轻量…...
)
别再手动打字了!用uniapp+百度语音识别,5分钟搞定语音转文字功能(附完整代码)
用UniApp百度语音识别实现高效语音转文字功能 在移动应用开发中,语音输入正逐渐成为提升用户体验的关键功能。想象一下,用户无需费力敲击虚拟键盘,只需轻按按钮说话,文字就能自动出现在输入框中——这种交互方式不仅自然流畅&…...

Cadence Virtuoso仿真避坑指南:从网表生成到FFT分析的20个常见错误解决方案
Cadence Virtuoso仿真避坑指南:从网表生成到FFT分析的20个常见错误解决方案 在集成电路设计领域,Cadence Virtuoso作为行业标准工具链的核心组件,其仿真功能的正确使用直接关系到设计效率与结果可靠性。本文将系统梳理从网表生成到FFT分析全流…...

快速上手腾讯混元OCR:部署过程常见错误及解决方法合集
快速上手腾讯混元OCR:部署过程常见错误及解决方法合集 1. 认识腾讯混元OCR 腾讯混元OCR(HunyuanOCR)是一款基于腾讯混元原生多模态架构的端到端OCR专家模型。作为一款轻量级但功能强大的文字识别工具,它仅用1B参数就实现了多项业…...

Xinference-v1.17.1GPU算力优化:显存自动分片+KV Cache压缩,72B模型显存占用降40%
Xinference v1.17.1 GPU算力优化:显存自动分片KV Cache压缩,72B模型显存占用降40% 1. 引言:大模型部署的显存困境与曙光 如果你尝试过在单张消费级显卡上部署一个超过70B参数的大语言模型,大概率会看到一个熟悉的错误提示&#…...

Docker Desktop部署Weaviate向量数据库:从配置到生产环境全流程
在Docker Desktop上部署Weaviate向量数据库的全流程。通过Docker Compose实现容器化,涵盖持久化存储、安全认证配置及text2vec-openai集成。提供Python/Java客户端连接示例,并针对端口冲突、数据持久化等常见问题给出实用解决方案,助力快速搭…...
)
别只盯着心跳了!CANopen主站用SDO还能配置这些关键参数(附PDO映射实例)
别只盯着心跳了!CANopen主站用SDO还能配置这些关键参数(附PDO映射实例) 在工业自动化领域,CANopen协议因其高可靠性和灵活性成为设备互联的首选方案之一。许多工程师对通过SDO(服务数据对象)配置心跳时间已…...