信息检索与数据挖掘 | 【实验】检索评价指标MAP、MRR、NDCG
文章目录
- 📚实验内容
- 📚知识梳理
- 📚实验步骤
- 🐇前情提要
- 🐇MAP评价指标函数
- 🐇MRR 评价指标函数
- 🐇NDCG评价指标函数
- 🐇调试结果
📚实验内容
- 实现以下指标评价,并对Experiment2的检索结果进行评价
- Mean Average Precision (
MAP) - Mean Reciprocal Rank (
MRR) - Normalized Discounted Cumulative Gain (
NDCG)
- Mean Average Precision (
📚知识梳理
- MAP(Mean Average Precision):平均准确率,是衡量检索结果排序质量的指标。
- 计算方式是对于每个查询,计算被正确检索的文档的
平均精确率,再对所有查询的平均值取均值。 - 存在意义是衡量对于一个查询,检索结果的平均精确率,适用于评估排序结果精确度的情况。
- 计算方式是对于每个查询,计算被正确检索的文档的
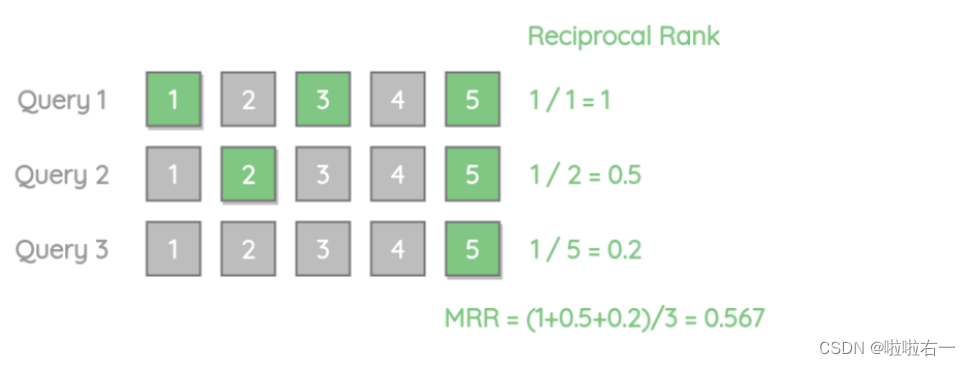
- MRR(Mean Reciprocal Rank):平均倒数排名,是衡量检索结果排序质量的指标。
- 计算方式是对于每个查询,计算被正确检索的文档的
最高排名的倒数的平均值,再对所有查询的平均值取均值。 - 存在意义是衡量对于一个查询,检索结果的排名,适用于评估检索结果排序效果好坏的情况。
- 计算方式是对于每个查询,计算被正确检索的文档的
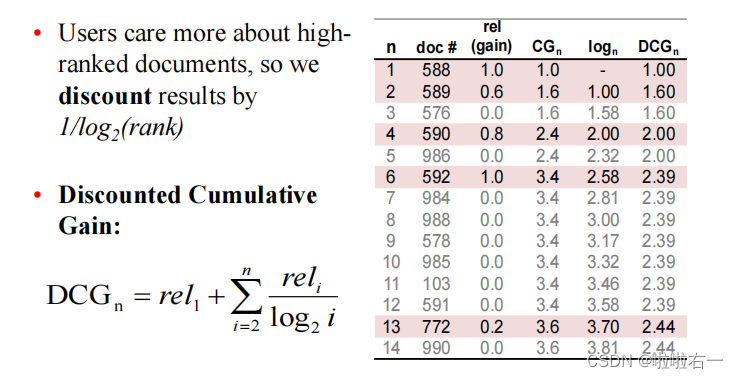
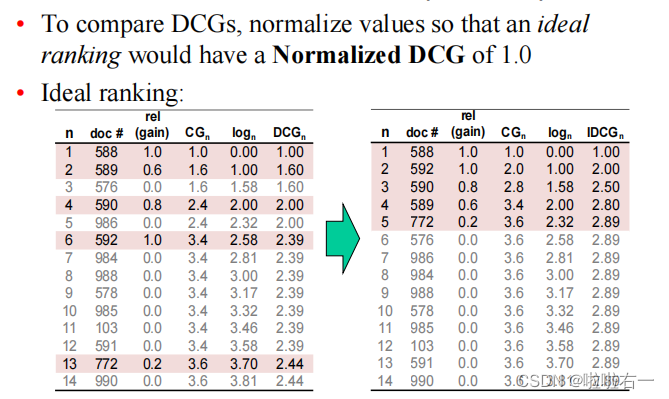
- NDCG(Normalized Discounted Cumulative Gain):归一化折损累积增益,是衡量检索结果排序质量的指标。
- 计算方式是对于每个查询,对每个被检索到的结果计算其
相对于理想排序的增益值,然后对这些相对增益值进行加权求和,再除以理想排序的增益值。 - 存在意义是衡量对于一个查询,检索结果的绝对和相对排序质量,适用于评估排序结果的质量与排名准确度的情况。
- 计算方式是对于每个查询,对每个被检索到的结果计算其
- 这三个指标各有侧重,根据不同的评估需要和数据特征选择合适的指标。例如,对于特定领域的文档检索,可能更关注排名准确度和检索结果的可靠度,因此MRR和NDCG可能比较适合。对于广泛领域的文档检索,可能更关注精确度,因此MAP比较适合。
📚实验步骤
🐇前情提要
- 本次实验是补充式实验,先给出了
qrels_dict和test_dict - 构建
qrels_dict,根据 qrel.txt 中的 query_id 和对应库中真正相关的 doc_id 的信息构建qrels_dict={query_id:{doc_id:gain,doc_id:gain,……}}。 遍历文件中的每一行,完成遍历后,返回 qrels_dict:- 使用 split(’ ') 将行按空格分隔成列表 ele。
- 检查
ele[0](query_id)是否已经在 qrels_dict 中。如果不在,将其作为新的查询ID键添加到 qrels_dict 中,并将其对应的值设置为空字典。 - 检查
ele[3](gain)是否大于0。如果是,将ele[2](doc_id)作为新的相关文档ID键添加到查询ID键对应的值中,并将其对应的值设置为 ele[3] 的整数形式。
def generate_tweetid_gain(file_name):qrels_dict = {}with open(file_name, 'r', errors='ignore') as f:for line in f:# 按空格划分ele = line.strip().split(' ')# ele[0]中存放的是query_idif ele[0] not in qrels_dict:qrels_dict[ele[0]] = {}# ele[3]存放的是gain,ele[2]存放的是doc_id# 将gain大于0的存入if int(ele[3]) > 0:qrels_dict[ele[0]][ele[2]] = int(ele[3])return qrels_dict - 构建
test_dict,根据 result.txt 文档中 query 和对应的检索到的 doc 文档对应信息构建test_dict={query_id:{doc_id,doc_id,……}}。遍历文件中的每一行,完成遍历后,返回 test_dict:- 使用 split(’ ') 将行按空格分隔成列表 ele。
- 检查
ele[0](query_id)是否已经在 test_dict 中。如果不在,将其作为新的查询ID键添加到 test_dict 中,并将其对应的值设置为一个空列表。 - 将
ele[1](doc_id)添加到查询ID键对应的列表中。
def read_tweetid_test(file_name):# 输入格式为:query_id doc_idtest_dict = {}with open(file_name, 'r', errors='ignore') as f:for line in f:# 按空格划分ele = line.strip().split(' ')# 这里的ele[0]是query_id,ele[1]是doc_idif ele[0] not in test_dict:test_dict[ele[0]] = []test_dict[ele[0]].append(ele[1])return test_dict
🐇MAP评价指标函数
-
获取检索到的(test_dict)相关文档信息
-
获取库中(qrels_dict)所有相关文档的信息
-
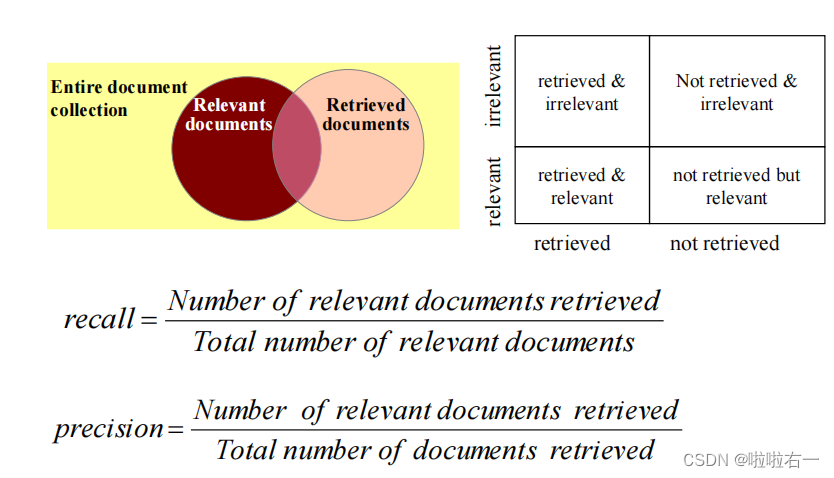
进行 P@K评估计算
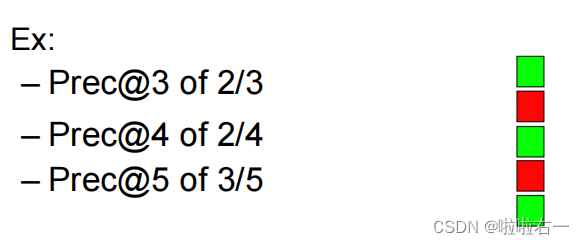
-
进行 AP 评估计算
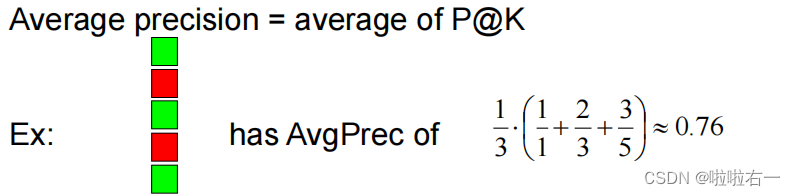
-
进行 MAP 均值评估计算。


def MAP_eval(qrels_dict, test_dict, k = 100):# MAP是对AP评价结果进行平均,AP基于P(Precision@K)评估AP_result = [] for query in qrels_dict:# 获取相关信息test_result = test_dict[query] # 检索文档true_list = set(qrels_dict[query].keys()) # 相关文档use_length = min(k, len(test_result)) # 用不超过100条文档计算if use_length <= 0:print('query:', query, '未找到')return []# 声明变量P_result = [] total = 0 the_true = 0 # P@K 评估for doc_id in test_result[0: use_length]:total += 1if doc_id in true_list:# 如果是相关的the_true += 1P_result.append(the_true / total)# AP评估if P_result:AP = np.sum(P_result) / len(true_list)# print('query:', query, '的AP评估结果:', AP)AP_result.append(AP)else:print('query:', query, ' 就没有相关的┭┮﹏┭┮')AP_result.append(0)# MAP就是AP的平均值return np.mean(AP_result)
🐇MRR 评价指标函数
-
获取检索到的(test_dict)相关文档信息
-
获取库中(qrels_dict)所有相关文档的信息
-
计算排序倒数(第一个相关结果的位置倒数)
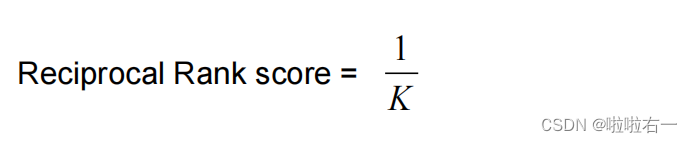
-
进行 RR 评估计算

-
进行 MRR 均值评估计算。
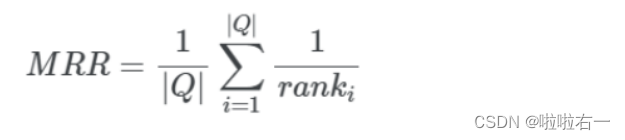
def MRR_eval(qrels_dict, test_dict, k = 100):# MRR是对RR评价结果进行平均,RR基于排序倒数RR_result = []for query in qrels_dict:# 获取相关信息test_result = test_dict[query] # 检索文档true_list = set(qrels_dict[query].keys()) # 相关文档use_length = min(k, len(test_result)) # 用不超过100条文档计算if use_length <= 0:print('query:', query, '未找到')return []# 声明变量R_result = []rank = 0# 计算排序倒数for doc_id in test_result[0: use_length]:rank += 1if doc_id in true_list:R_result.append(1 / rank)break# RR评估if R_result:RR = np.sum(R_result)/1.0# print('query:', query, '的RR评估结果:', RR)RR_result.append(RR)else:print('query:', query, ' 就没有相关的┭┮﹏┭┮') RR_result.append(0)# MRR就是RR的平均值return np.mean(RR_result)
🐇NDCG评价指标函数
- 获取检索到的(test_dict)相关文档信息
- 获取库中(qrels_dict)所有相关文档的gain(也就是下边的rel)信息
- 按gain(rel)倒序排列(理想化,用于计算IDCG)
- 先计算出 DCG和 IDCG,二者相除得到NDCG,取均值后返回。

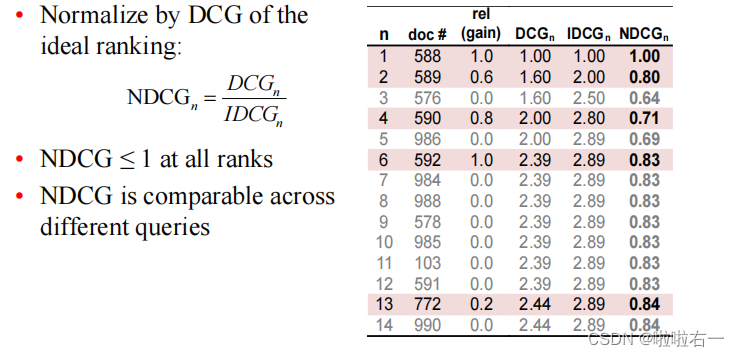
def NDCG_eval(qrels_dict, test_dict, k = 100):# NDCG@K = DCG@K / IDCG@K# DCG = rel(1) + sum(rel(i)/log(i))# IDCG就是按rel排序之后的DCGNDCG_result = []for query in qrels_dict:# 获取相关信息 test_result = test_dict[query] # 检索文档true_list = list(qrels_dict[query].values()) # 相关文档的gain列表true_list = sorted(true_list, reverse=True) # 按gain(rel)倒序排列use_length = min(k, len(test_result),len(true_list)) # 用不超过100条文档计算if use_length <= 0:print('query:', query, '未找到')return []# 声明变量i = 1DCG = 0.0 IDCG = 0.0# 计算DCG和IDCGrel1 = qrels_dict[query].get(test_result[0], 0)DCG += rel1for doc_id in test_result[1: use_length]:i += 1rel = qrels_dict[query].get(doc_id, 0)DCG += rel / math.log(i, 2)IDCG += true_list[i - 2] / math.log(i, 2)NDCG = DCG / IDCG# print('query:', query, '的NDCG评估结果:', NDCG)NDCG_result.append(NDCG)# 取平均值后返回return np.mean(NDCG_result)
🐇调试结果

参考博客:信息检索实验3- IR Evaluation
相关文章:
信息检索与数据挖掘 | 【实验】检索评价指标MAP、MRR、NDCG
文章目录 📚实验内容📚知识梳理📚实验步骤🐇前情提要🐇MAP评价指标函数🐇MRR 评价指标函数🐇NDCG评价指标函数🐇调试结果 📚实验内容 实现以下指标评价,并对…...

读书笔记:彼得·德鲁克《认识管理》第24章 管理岗位的设计与内容
一、章节内容概述 管理岗位应该始终基于必要的任务,应该是一份实实在在的工作,为企业的整体目标做出可见的(如果不是可衡量的话)贡献,还应该具有尽可能广泛的权威和范围。管理者应该接受绩效目标而不是上级领导 的指导和控制。在设计管理岗位…...
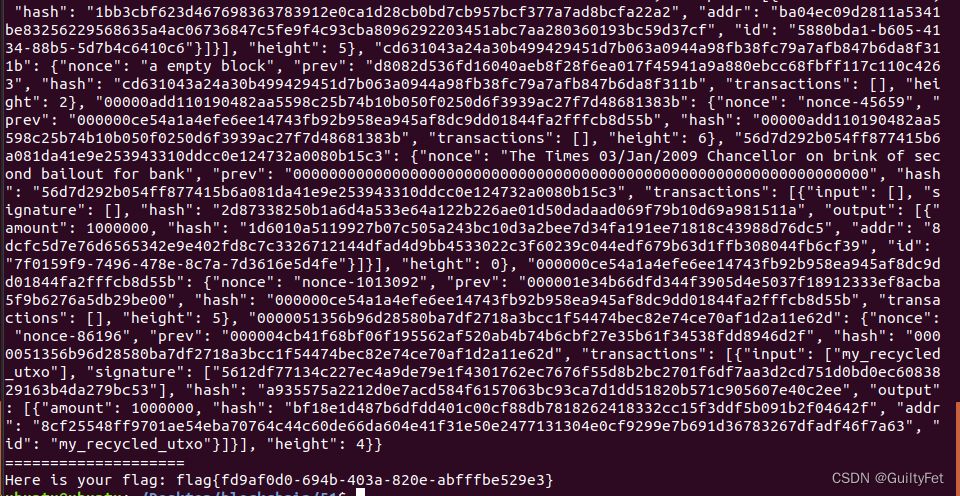
某60区块链安全之51%攻击实战学习记录
区块链安全 文章目录 区块链安全51%攻击实战实验目的实验环境实验工具实验原理攻击过程 51%攻击实战 实验目的 1.理解并掌握区块链基本概念及区块链原理 2.理解区块链分又问题 3.理解掌握区块链51%算力攻击原理与利用 4.找到题目漏洞进行分析并形成利用 实验环境 1.Ubuntu1…...
为什么原生IP可以降低Google play账号关联风险?企业号解决8.3/10.3账号关联问题?
在Google paly应用上架的过程中,相信大多数开发者都遇到过开发者账号因为关联问题,导致应用包被拒审和封号的情况。 而众所周知,开发者账号注册或登录的IP地址及设备是造成账号关联的重要因素之一。酷鸟云最新上线的原生IP能有效降低账号因I…...
和A(n,m)理解及代码实现)
排列组合C(n,m)和A(n,m)理解及代码实现
排列组合C(n,m)和A(n,m)理解及代码实现-CSDN博客...

EasyExcel导入从第几行开始
//获得工作簿 read EasyExcel.read(inputStream, Student.class, listener); //获得工作表 又两种形形式可以通过下标也可以通过名字2003Excel不支持名字 ExcelReaderSheetBuilder sheet read.sheet(); sheet.headRowNumber(2);...

均匀光源积分球的应用领域有哪些
均匀光源积分球的主要作用是收集光线,并将其用作一个散射光源或用于测量。它可以将光线经过积分球内部的均匀分布后射出,因此积分球也可以当作一个光强衰减器。同时,积分球可以实现均匀的朗伯体漫散射光源输出,整个输出口表面的亮…...
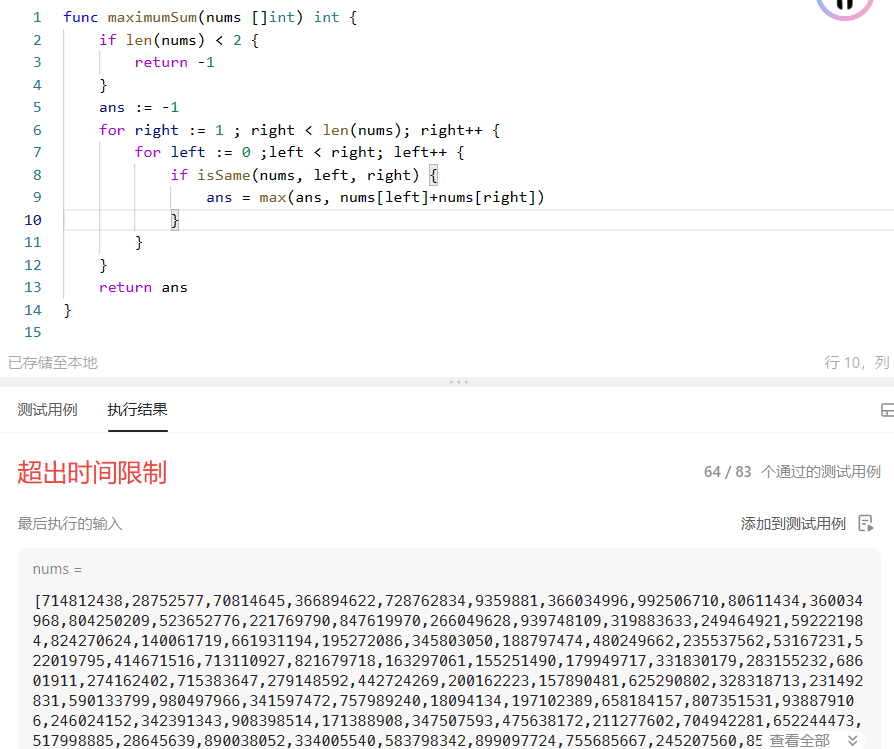
【LeetCode】每日一题 2023_11_18 数位和相等数对的最大和(模拟/哈希)
文章目录 刷题前唠嗑题目:数位和相等数对的最大和题目描述代码与解题思路思考解法偷看大佬题解结语 刷题前唠嗑 LeetCode? 启动!!! 本月已经过半了,每日一题的全勤近在咫尺~ 题目:数位和相等数对的最大和…...

【喵叔闲扯】--迪米特法则
迪米特法则,也称为最少知识原则(Law of Demeter),是面向对象设计中的一个原则,旨在降低对象之间的耦合性,提高系统的可维护性和可扩展性。该原则强调一个类不应该直接与其它不相关的类相互交互,…...
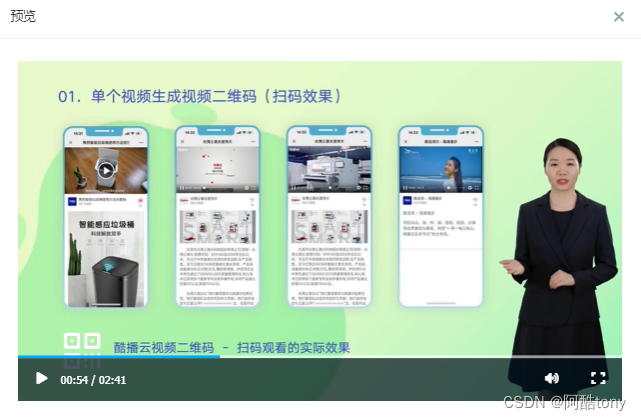
企业视频数字人有哪些应用场景
来做个数字人吧,帮我干点活吧。 国内的一些数字人: 腾讯智影 腾讯智影数字人是一种基于人工智能技术的数字人物形象,具有逼真的外观、语音和行为表现,可以应用于各种场景,如新闻播报、文娱推介、营销、教育等。 幻…...
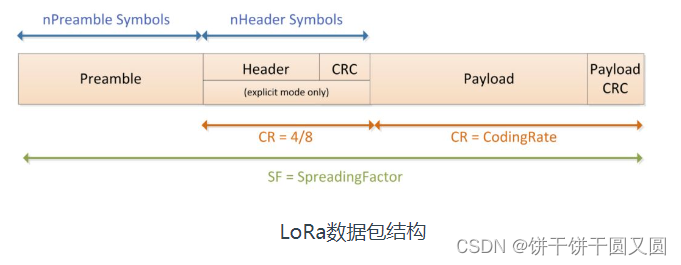
LoRa模块空中唤醒功能原理和物联网应用
LoRa模块是一种广泛应用于物联网领域的无线通信模块,支持低功耗、远距离和低成本的无线通信。 其空中唤醒功能是一项重要的应用,可以实现设备的自动唤醒,从而在没有人工干预的情况下实现设备的远程监控和控制。 LoRa模块空中唤醒功能的原理…...
spring中的DI
【知识要点】 控制反转(IOC)将对象的创建权限交给第三方模块完成,第三方模块需要将创建好的对象,以某种合适的方式交给引用对象去使用,这个过程称为依赖注入(DI)。如:A对象如果需要…...
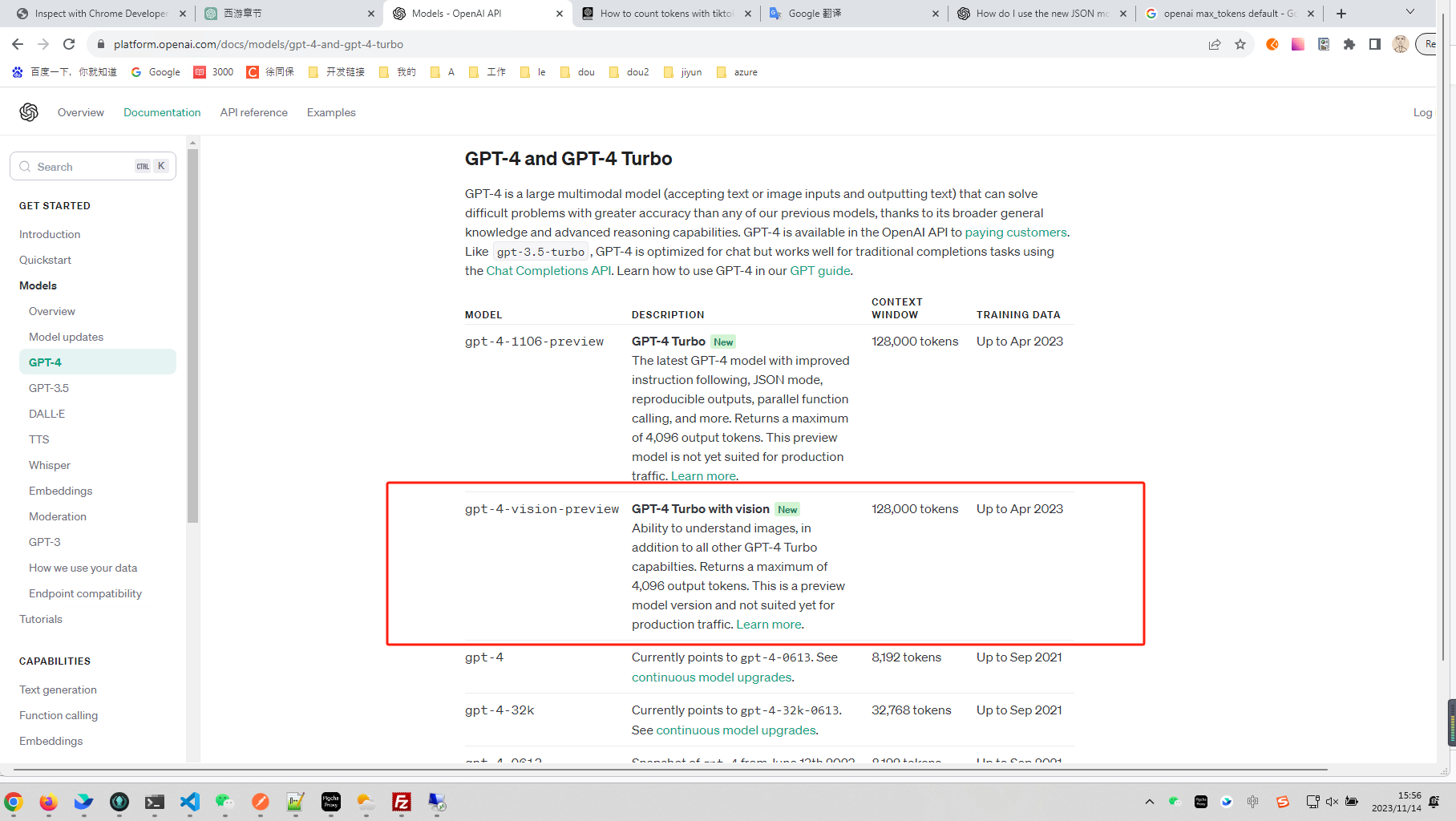
gpt-4-vision-preview 识图
这些图片都是流行动画角色的插图。 第一张图片中的角色是一块穿着棕色方形裤子、红领带和白色衬衫的海绵,它站立着并露出开心的笑容。该角色在一个蓝色的背景前,显得非常兴奋和活泼。 第二张图片展示的是一只灰色的小老鼠,表情开心…...

Spring Framework 6.1 正式发布
Spring Framework 6.1.0 现已从 Maven Central 正式发布!6.1 一代有几个关键主题: 拥抱 JDK 21 LTS虚拟线程(Project Loom)JVM 检查点恢复(项目 CRaC)重新审视资源生命周期管理重新审视数据绑定和验证新的…...
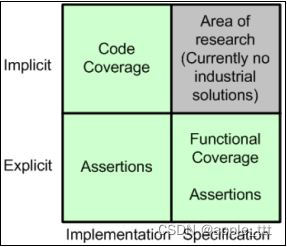
SystemVerilog学习 (11)——覆盖率
目录 一、概述 二、覆盖率的种类 1、概述 2、分类 三、代码覆盖率 四、功能覆盖率 五、从功能描述到覆盖率 一、概述 “验证如果没有量化,那么就意味着没有尽头。” 伴随着复杂SoC系统的验证难度系数成倍增加,无论是定向测试还是随机测试ÿ…...

jQuery,解决命名冲突的问题
使用noConflict(true),把$和jQuery名字都给别人 <body><script>var $ zanvar jQuery lan</script><script src"./jquery.js"></script><script>console.log(jQuery, 11111); // 打印jquery函数console.log($, 222…...
为什么C++标准库中atomic shared_ptr不是lockfree实现?
为什么C标准库中atomic shared_ptr不是lockfree实现? 把 shared_ptr 做成 lock_free,应该是没有技术上的可行性。shared_ptr 比一个指针要大不少:最近很多小伙伴找我,说想要一些C的资料,然后我根据自己从业十年经验&am…...
)
Python基础入门例程58-NP58 找到HR(循环语句)
最近的博文: Python基础入门例程57-NP57 格式化清单(循环语句)-CSDN博客 Python基础入门例程56-NP56 列表解析(循环语句)-CSDN博客 Python基础入门例程55-NP55 2的次方数(循环语句)-CSDN博客 目录 最近的博文: 描述...
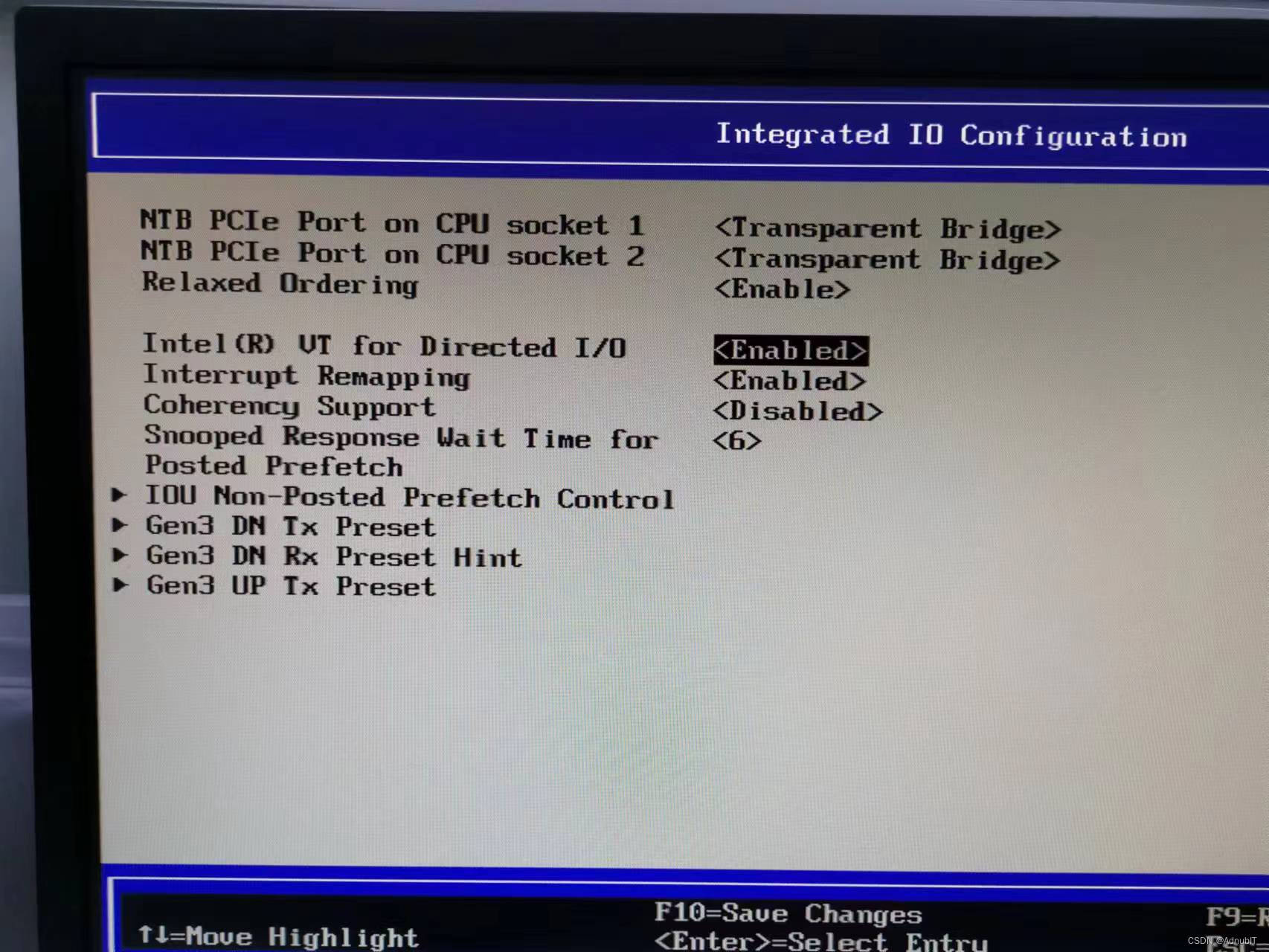
航天联志Aisino-AISINO26081R服务器通过调BIOS用U盘重新做系统(windows系统通用)
产品名称:航天联志Aisino系列服务器 产品型号:AISINO26081R CPU架构:Intel 的CPU,所以支持Windows Server all 和Linux系统(重装完系统可以用某60驱动管家更新所有硬件驱动) 操作系统:本次我安装的服务器系统为Serv…...
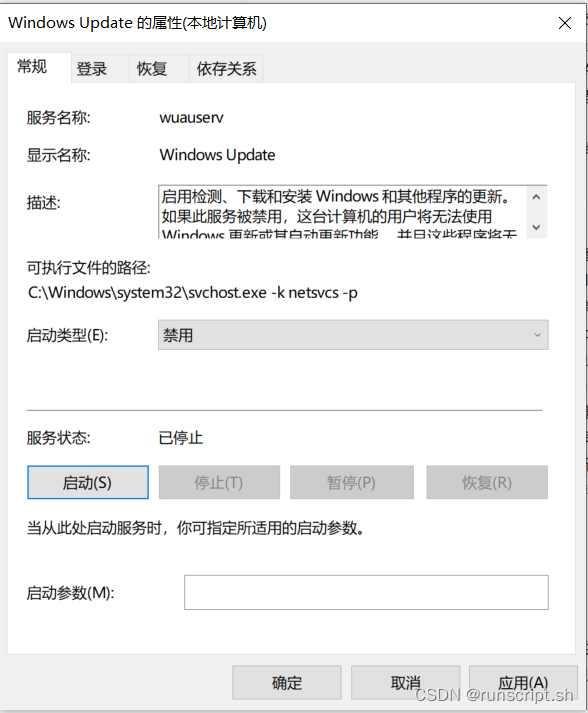
windows 10 更新永久关闭
1 winR 输入:services.msc 编辑: 关闭:...

轻量化目标检测实战:基于Pytorch的Mobilenet-YOLOv4融合架构设计与性能调优
1. 为什么需要轻量化目标检测模型 在移动端和嵌入式设备上运行目标检测模型时,我们常常面临两个关键挑战:计算资源有限和功耗约束。传统的YOLOv4虽然检测精度高,但其基于CSPDarknet53的主干网络参数量大、计算复杂度高,难以在资源…...

朋升爱生活
我爱生活。...

Armbian重置前的数据保卫战——备份与迁移的5层防护策略
备份就像买保险——平时觉得麻烦,出事时觉得买少了。 引言:那个让我彻夜未眠的晚上 凌晨三点,我的香橙派突然失联了。 SSH连不上,ping不通,插显示器一看——文件系统只读,内核panic。前一天刚折腾完Docker网络配置,手贱改了个内核参数,重启后直接翻车。 那一刻,我脑…...

如何用一句话让小爱音箱播放你的私人音乐库?Docker部署XiaoMusic完全指南
如何用一句话让小爱音箱播放你的私人音乐库?Docker部署XiaoMusic完全指南 【免费下载链接】xiaomusic 使用小爱音箱播放音乐,音乐使用 yt-dlp 下载。 项目地址: https://gitcode.com/GitHub_Trending/xia/xiaomusic 你是否曾经想过,只…...

DLSS Swapper完全指南:3步轻松优化游戏性能的终极方案
DLSS Swapper完全指南:3步轻松优化游戏性能的终极方案 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款专为游戏玩家设计的智能工具,能够自动管理、下载和替换游戏中的DLSS、F…...

3步轻松解锁QQ音乐加密文件:macOS用户必备的解码工具
3步轻松解锁QQ音乐加密文件:macOS用户必备的解码工具 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转…...

C++/Qt项目内存问题排查:除了Valgrind,这些工具和技巧你也该知道
C/Qt项目内存问题排查:除了Valgrind,这些工具和技巧你也该知道 在开发中等复杂度的Qt桌面或嵌入式应用时,内存问题往往是最难缠的"隐形杀手"。我曾参与过一个医疗影像处理系统的开发,项目后期突然出现随机崩溃ÿ…...

终端工作空间新选择:从 tmux 到 Zellij 的迁移与实战
1. 为什么需要从 tmux 迁移到 Zellij 作为一个用了五年 tmux 的老用户,我最初对 Zellij 这个"新玩具"是持怀疑态度的。直到有一次在远程服务器上调试时,tmux 的窗格突然卡死,所有工作进度瞬间归零,我才开始认真寻找替代…...

React Styleguidist权限控制终极指南:如何实现私有组件文档访问限制
React Styleguidist权限控制终极指南:如何实现私有组件文档访问限制 【免费下载链接】react-styleguidist Isolated React component development environment with a living style guide 项目地址: https://gitcode.com/gh_mirrors/re/react-styleguidist R…...

Marathon已过时?迁移到Swift Package Manager的完整步骤
Marathon已过时?迁移到Swift Package Manager的完整步骤 【免费下载链接】Marathon [DEPRECATED] Marathon makes it easy to write, run and manage your Swift scripts 🏃 项目地址: https://gitcode.com/gh_mirrors/mar/Marathon Marathon作为…...