milvus数据库的数据管理-插入数据
一、插入数据
1.准备数据
数据必须与数据库中定义的字段元数据一致,与集合的模式匹配
import random
data = [[i for i in range(2000)],[str(i) for i in range(2000)],[i for i in range(10000, 12000)],[[random.random() for _ in range(2)] for _ in range(2000)],# use `default_value` for a field 使用空值占位一个字段[], # orNone,# or just omit the field 直接省略一个字段
]
# 对于动态模式,可以灵活地增加字段和值
data.append([str("dy"*i) for i in range(2000)])2.插入数据
连接现有的集合,可通过指定partition_name来选择将数据插入指定分区。
from pymilvus import Collection
collection = Collection("book") # Get an existing collection.
mr = collection.insert(data)
Parameter Description
data Data to insert into Milvus.
partition_name (optional) Name of the partition to insert data into.
3.flush调用
当数据被插入到Milvus中时,会被插入到段中。段必须达到一定大小才能被密封和索引。
未密封的段将被暴力搜索。为了避免这种情况,最好调用flush()。flush调用将密封任何剩余段并将它们发送到索引。
二、从文本批量插入实体
1.准备数据文件
①基于行的json文件
文件名自定义,但是根键必须是raw。实体以字典组织,key是字段名,value是字段值
提示:
不要添加不存在于目标集合中的字段,也不要漏掉目标集合模式定义的任何字段。
在每个字段中使用正确类型的值。例如,在整数字段中使用整数,在浮点字段中使用浮点数,在varchar字段中使用字符串,在向量字段中使用浮点数组。
不要在JSON文件中包含自动生成的主键。
对于二进制向量,请使用uint8数组。每个uint8值表示8个维度,值必须介于0和255之间。例如,[1, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 1, 1, 1]是一个16维的二进制向量,应该在JSON文件中写成[128, 7]。
{"rows":[{"book_id": 101, "word_count": 13, "book_intro": [1.1, 1.2]},{"book_id": 102, "word_count": 25, "book_intro": [2.1, 2.2]},{"book_id": 103, "word_count": 7, "book_intro": [3.1, 3.2]},{"book_id": 104, "word_count": 12, "book_intro": [4.1, 4.2]},{"book_id": 105, "word_count": 34, "book_intro": [5.1, 5.2]}]
}{"rows":[{"book_id": 101, "word_count": 13, "book_intro": [1.1, 1.2], "book_props": {"year": 2015, "price": 23.43}},{"book_id": 102, "word_count": 25, "book_intro": [2.1, 2.2], "book_props": {"year": 2018, "price": 15.05}},{"book_id": 103, "word_count": 7, "book_intro": [3.1, 3.2], "book_props": {"year": 2020, "price": 36.68}},{"book_id": 104, "word_count": 12, "book_intro": [4.1, 4.2] , "book_props": {"year": 2019, "price": 20.14}},{"book_id": 105, "word_count": 34, "book_intro": [5.1, 5.2] , "book_props": {"year": 2021, "price": 9.36}}]
}②基于列的numpy文件
可以使用NumPy数组将数据集的每个列组织到单独的文件中。在这种情况下,使用每个列的字段名称来命名NumPy文件。
使用每个列的字段名称来命名NumPy文件。不要添加命名为目标集合中不存在的字段的文件。每个字段应该有一个NumPy文件。
创建NumPy数组时使用正确的值类型。
import numpy
numpy.save('book_id.npy', numpy.array([101, 102, 103, 104, 105]))
numpy.save('word_count.npy', numpy.array([13, 25, 7, 12, 34]))
arr = numpy.array([[1.1, 1.2],[2.1, 2.2],[3.1, 3.2],[4.1, 4.2],[5.1, 5.2]])
numpy.save('book_intro.npy', arr)2.插入实体
①上传数据文件
可以使用MinIO或本地硬盘进行存储。
要使用MinIO进行存储,请将数据文件上传到milvus.yml配置文件中定义的存储桶中minio.bucketName;
对于本地存储,请将数据文件复制到本地磁盘的目录中。
②插入实体
对于json文件,传入单个文件的列表,如:
from pymilvus import utility
task_id = utility.do_bulk_insert(collection_name="book",partition_name="2022",files=["test.json"]
)对于numpy文件,传入多元素列表:
from pymilvus import utility
task_id = utility.do_bulk_insert(collection_name="book",partition_name="2022",files=["book_id.npy", "word_count.npy", "book_intro.npy", "book_props.npy"]
)每次批量插入API调用都会立即返回。返回值是在后台运行的数据导入任务的ID。
设置文件路径时,请注意
如果您将数据文件上传到MinIO实例,则有效的文件路径应相对于在**“milvus.yml"中定义的根桶,例如"data/book_id.npy”。
如果您将数据文件上传到本地硬盘,则有效的文件路径应为绝对路径,例如"/tmp/data/book_id.npy"**。
如果您有很多文件需要处理,请考虑创建多个数据导入任务并让它们并行运行。
三、检查任务状态
批量插入API是异步的,您可能需要检查数据导入任务是否已完成。
使用get_bulk_insert_state()
1.检查单个任务:
task = utility.get_bulk_insert_state(task_id=task_id)
print("Task state:", task.state_name)
print("Imported files:", task.files)
print("Collection name:", task.collection_name)
print("Partition name:", task.partition_name)
print("Start time:", task.create_time_str)
print("Imported row count:", task.row_count)
print("Entities ID array generated by this task:", task.ids)if task.state == BulkInsertState.ImportFailed:print("Failed reason:", task.failed_reason)2.检查所有任务
使用list-bulk-insert-tasks()
tasks = utility.list_bulk_insert_tasks(collection_name="book", limit=10)
for task in tasks:print(task)四、检查数据可搜索性
1.检查索引构建进度
PyMilvus提供了一种实用方法,等待索引构建过程完成。
utility.wait_for_index_building_complete(collection_name)2.将新段加载到查询节点
collection.load(_refresh = True)默认情况下,_refresh参数为false。在首次加载集合时不要将其设置为true。
相关文章:

milvus数据库的数据管理-插入数据
一、插入数据 1.准备数据 数据必须与数据库中定义的字段元数据一致,与集合的模式匹配 import random data [[i for i in range(2000)],[str(i) for i in range(2000)],[i for i in range(10000, 12000)],[[random.random() for _ in range(2)] for _ in range(2…...
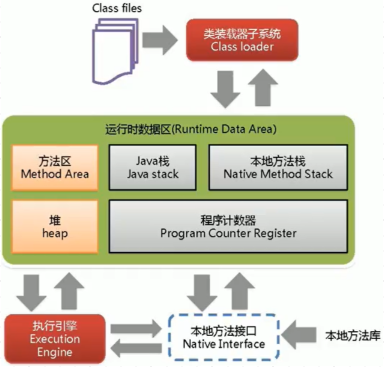
系列一、请谈谈你对JVM的理解?Java8的虚拟机有什么更新?
一、请谈谈你对JVM的理解?Java8的虚拟机有什么更新? JVM是Java虚拟机的意思。它是建立在操作系统之上的,由类加载器子系统、本地方法栈、Java栈、程序计数器、方法区、堆、本地方法库、本地方法接口、执行引擎组成。 (1࿰…...

恕我直言,大模型对齐可能无法解决安全问题,我们都被表象误导了
是否听说过“伪对齐”这一概念? 在大型语言模型(LLM)的评估中,研究者发现了一个引人注目的现象:当面对多项选择题和开放式问题时,模型的表现存在显著差异。这一差异根源在于模型对复杂概念的理解不够全面&…...

Apache Airflow (九) :Airflow Operators及案例之BashOperator及调度Shell命令及脚本
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹…...
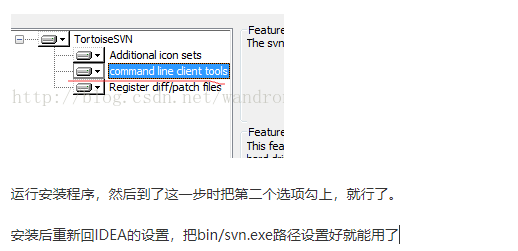
IJ中配置TortoiseSVN插件:
文章目录 一、报错情况:二、配置TortoiseSVN插件: 一、报错情况: 由于公司电脑加密,TortoiseSVN菜单没有提交和更新按钮,所以需要使用IJ的SVN进行代码相关操作 二、配置TortoiseSVN插件: 需要设置一个svn.…...

个人实现在线支付,一种另类的在线支付解决方案
Hi, I’m Shendi 个人实现在线支付,一种另类的在线支付解决方案 个人实现在线支付的方式 对于在线支付,最多的是接入微信与支付宝。但都需要营业执照,不适用于个人。 当然,可以去办理一个个体工商户,但对我这种小额收…...

浅谈智能安全配电装置应用在银行配电系统中
【摘要】银行是国家重点安全保护部分,关系到社会资金的稳定,也是消防重点单位。消防安全是银行工作的重要组成部分。在银行配电系统中应用智能安全配电装置,可以提高银行的智能控制水平,有效预防电气火灾。 【关键词】银行&#…...
macOS下如何使用Flask进行开发
👨🏻💻 热爱摄影的程序员 👨🏻🎨 喜欢编码的设计师 🧕🏻 擅长设计的剪辑师 🧑🏻🏫 一位高冷无情的编码爱好者 大家好,我是全栈工…...
记一次服务器配置文件获取OSS
一、漏洞原因 由于网站登录口未做双因子校验,导致可以通过暴力破解获取管理员账号,成功进入系统;未对上传的格式和内容进行校验,可以任意文件上传获取服务器权限;由于服务器上配置信息,可以进一步获取数据库权限和OSS管理权限。二、漏洞成果 弱口令获取网站的管理员权限通…...

合众汽车选用风河Wind River Linux系统
导读合众新能源汽车股份有限公司近日选择了Wind River Linux 用于开发合众智能安全汽车平台。 合众智能安全汽车平台(Hozon Automo-tive Intelligent Security Vehicle Plat-form)是一个面向高性能服务网关及车辆控制调度的硬件与软件框架,将于2024年中开始投入量产…...
)
PTA平台-2023年软件设计综合实践_5(指针及引用)
第一题 6-1 调和平均 - C/C 指针及引用 函数hmean()用于计算整数x和y的调和平均数,结果应保存在指针r所指向的浮点数对象中。当xy等于0时,函数返回0表示无法计算,否则返回1。数学上,两个数x和y的调和平均数 z 2xy/(xy) 。 直接…...

智慧卫生间
智慧卫生间 获取ApiKey/SecretKey获取Access_token获取卫生间实时数据返回说明 获取ApiKey/SecretKey ApiKey/SecretKey采用 线下获取的方式,手动分配。 获取Access_token 向授权服务地址http://xxxxxx:12345/token(示意)发送post请求,并在data中带上…...
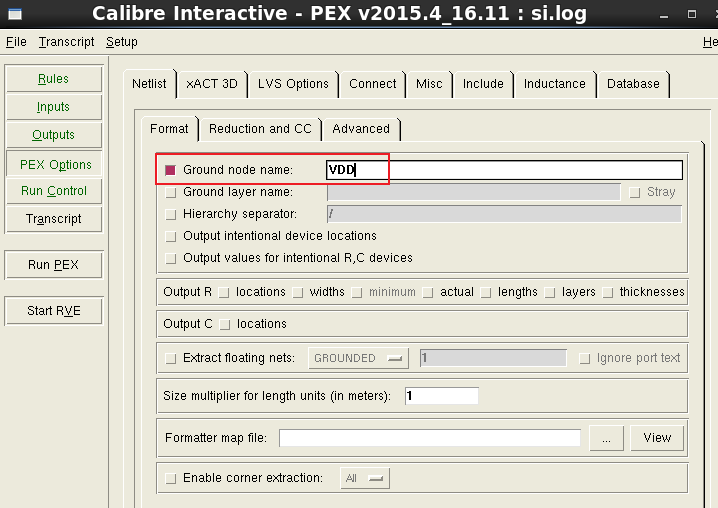
Cadence virtuoso drc lvs pex 无法输入
问题描述:在PEX中的PEX options中 Ground node name 无法输入内容。 在save runset的时候也出现无法输入名称的情况 解决办法: copy一个.bashrc文件到自己的工作目录下 打开.bashrc文件 在.bashrc中加一行代码:unset XMODIFIERS 在终端sour…...
, 分析调用链, 编写POC)
反序列化漏洞(2), 分析调用链, 编写POC
反序列化漏洞(2), 反序列化调用链分析 一, 编写php漏洞脚本 http://192.168.112.200/security/unserial/ustest.php <?php class Tiger{public $string;protected $var;public function __toString(){return $this->string;}public function boss($value){eval($valu…...

Pytorch reshape用法
这里-1是指未设定行数,程序自动计算,所以这里-1表示任一正整数 example reshape(-1, 1) 表示(任意行,1列),4行4列变为16行1列reshape(1, -1) 表示(1行,任意列)…...

Latex 辅助写作工具
语法修改 https://app.grammarly.com/润色 文心一言、ChatGPTlatex 编辑公式 https://www.latexlive.comlatex 编辑表格 https://www.tablesgenerator.comlatex 图片转公式 https://www.tablesgenerator.com...

frp新版本frp_0.52.3设置
服务端 frps.toml cp /root/frp/frpc /usr/bin #bindPort 7000 bindPort 7000# 如果指定了“oidc”,将使用 OIDC 设置颁发 OIDC(开放 ID 连接)令牌。默认情况下,此值为“令牌”。auth.method “token” auth.method "…...

100G.的DDoS高防够用吗?
很多人以为100G的DDoS防御已经足够了,但殊不知DDoS攻击大小也是需要分行业类型的,比如游戏、金融、影视、电商甚至ZF或者行业龙头等等行业类型,都是大型DDoS攻击的重灾区,别说100G防御,就算300G防御服务器也不一定够用…...

【django+vue】项目搭建、解决跨域访问
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~ 【djangovue】项目搭建、解决跨域访问 djangovue介绍vue环境准备vue框架搭建1.创建vue项目2.配置vue项目3.进入项目目录4.运行项目5.项目文件讲解6.vue的扩展库或者插件 django环境准备django框架搭建1.使用conda…...
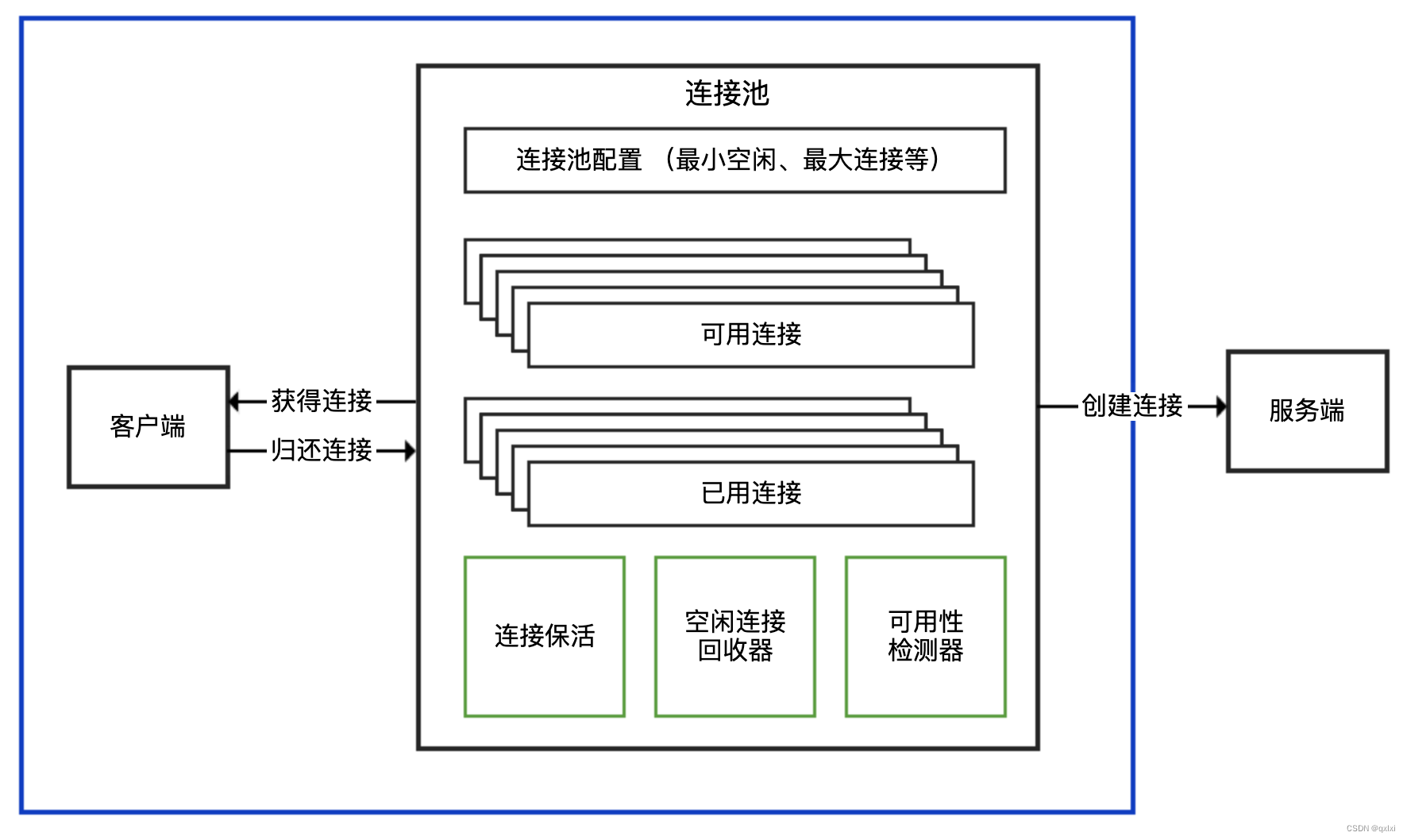
【数据库】数据库连接池导致系统吞吐量上不去-复盘
在实际的开发中,我们会使用数据库连接池,但是如果不能很好的理解其中的含义,那么就可以出现生产事故。 HikariPool-1 - Connection is not available, request timed out after 30001ms.当系统的调用量上去,就出现大量这样的连接…...

Stitches API完全指南:从基础配置到自定义扩展
Stitches API完全指南:从基础配置到自定义扩展 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一款强大的HTML5 Sprite Sheet Generator,它提供了直观的API接口&…...

诚信标签工厂端解决方案 适配俄标 CRPT 体系一体化技术方案
俄罗斯诚实标签依托 CRPT 体系执行强制管控,各类出口货品必须完成 Data Matrix 编码采集、格式转换、多层包装数据绑定,数据合规后方可通关流通。美妆食品、日化建材、玩具五金等品类包装形态差异较大,人工采集方式普遍存在识别精度不足、批量…...

串口通信粘包问题:成因深度解析与项目实战解决方案
在嵌入式开发、工业工控、上位机下位机交互项目中,串口(RS232/RS485)是最基础、最常用的通信方式。绝大多数开发者都遇到过这样的问题:串口接收的数据偶尔错乱、解析报错、数据拼接异常,单次接收的数据时而半包、时而多…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...

Windows文件夹共享
目标:同一局域网实现在一台计算机上共享文件夹,在另一台电脑访问一、电脑A 1.点击要共享的文件夹 -> 属性 -> 共享2.添加Everyone用户组3.控制面板中网络共享关闭密码保存,在访问时不用输入账号密码。二、电脑B 1.在文件资源管理器路径…...

2026论文顶级降AI率工具大曝光:一键把AIGC率降至安全线!
步入2026年,学术圈的规则已经彻底变了味。过去那种只盯着查重率的“降重焦虑”早就被更可怕的“降AI焦虑”取代了。AI检测算法越来越聪明,高校审核标准也越来越严苛,光是把重复率压下去已经完全不够用了。现在摆在学生和科研人员面前的难题是…...

告别手动复制!用这个自定义编辑器脚本一键备份/克隆Unity Terrain Data
告别手动复制!用这个自定义编辑器脚本一键备份/克隆Unity Terrain Data在Unity关卡设计和技术美术的工作流中,地形数据的灵活复用往往意味着反复的手动操作——导出高度图、备份材质参数、复制植被分布,每个环节都可能成为效率瓶颈。想象这样…...

告别KITTI!用TartanAir数据集在Unreal Engine+AirSim里复现那些让VSLAM算法“翻车”的雨天和黑夜
超越KITTI:用TartanAir数据集在虚拟极端环境中锤炼VSLAM算法当视觉SLAM算法在KITTI数据集上取得95%的准确率时,开发者们常常会松一口气——直到这些算法被部署到真实世界的雨夜街道上。突然之间,那些在阳光明媚的德国道路上表现优异的特征点检…...
)
【C++】零基础入门 · 第 4 节:循环结构(while、for、do-while)
上一节我们学习了条件判断,这一节来学习循环结构。循环让程序能够重复执行某段代码,直到满足特定条件为止。C 提供了三种循环语句:while、for 和 do-while。 1. while 循环:先判断后执行 while 循环在每次执行前先检查条件&#x…...

基于A2A协议将智能体注册到Nacos3.x
1.配置和简介Nacos3.x比Nacos2.x多了可以注册智能体的功能。配置密钥,32位即可启动分为集群模式和单机模式,单机模式下,默认存储在derby下。2.智能体注册中心:AgentScope也是自带注册中心的,叫AgentScopeA2aServer。现…...