Linux进程间通信之匿名管道
文章目录
- 为什么要有进程间通信
- pipe函数
- 共享管道原理
- 管道特点
- 管道的四种情况
- 管道的应用场景(进程池)
- ProcessPool.cc
- Task.hpp
为什么要有进程间通信
数据传输:一个进程需要将它的数据发送给另一个进程
资源共享:多个进程之间共享同样的资源。
通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
pipe函数
通过pipe函数实现两个进程间的通信
pipe()函数作用:生成两个文件描述符,分别为读端和写端
参数:
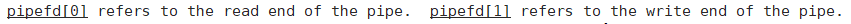
输出型参数pipefd[2],返回值pipefd[0]为读端,pipefd[1]为写端
返回值:
成功返回0,失败返回-1,并且设置错误码error
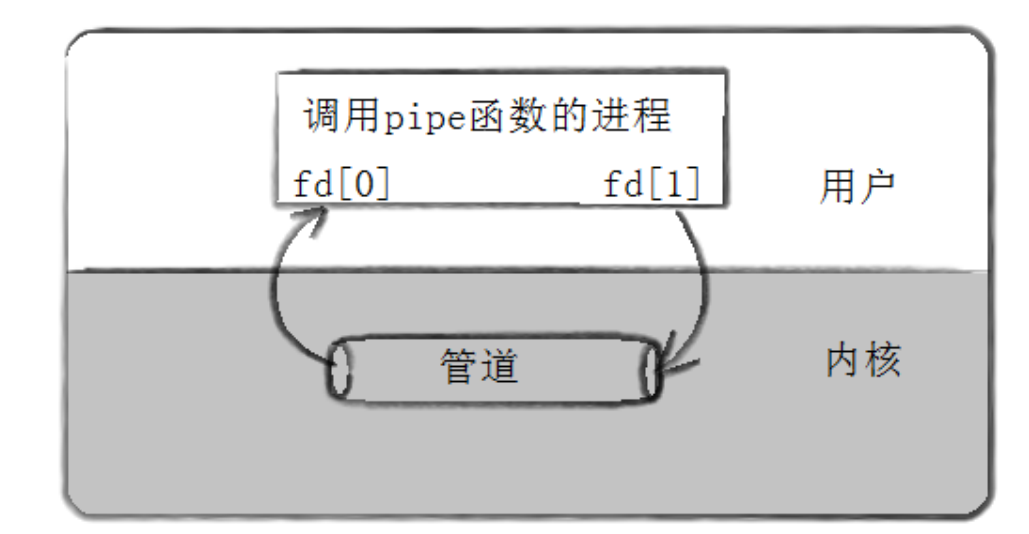
共享管道原理
通过fork函数实现父子之间的管道共享,同一进程fork出的多个进程之间都可以进行管道共享,因此只要是亲戚就可以。
管道共享更确切的说应该是缓冲区共享,我们先来理解一下fork函数,一个进程fork出了子进程,两个进程之间的代码是共享的,数据是独有的,当其中一个进程的数据发生改变时,就会发生写时拷贝。那么文件缓冲区呢?
父子之间的文件缓冲区也是共享的,因此父子之间就是借助这一点进行通信的。
我们以3号文件描述符为读端,4号文件描述符为写端为例,父进程向3号文件描述符写,子进程将数据写入到4号文件描述符。而4号文件描述符读到的就是父进程向3号文件描述符写的数据,这是怎么实现的呢?
1.父子进程是同步的
2.父子之间缓冲区是共享的。
因此当父亲向缓冲区写的时候,子进程就直接从缓冲区内读
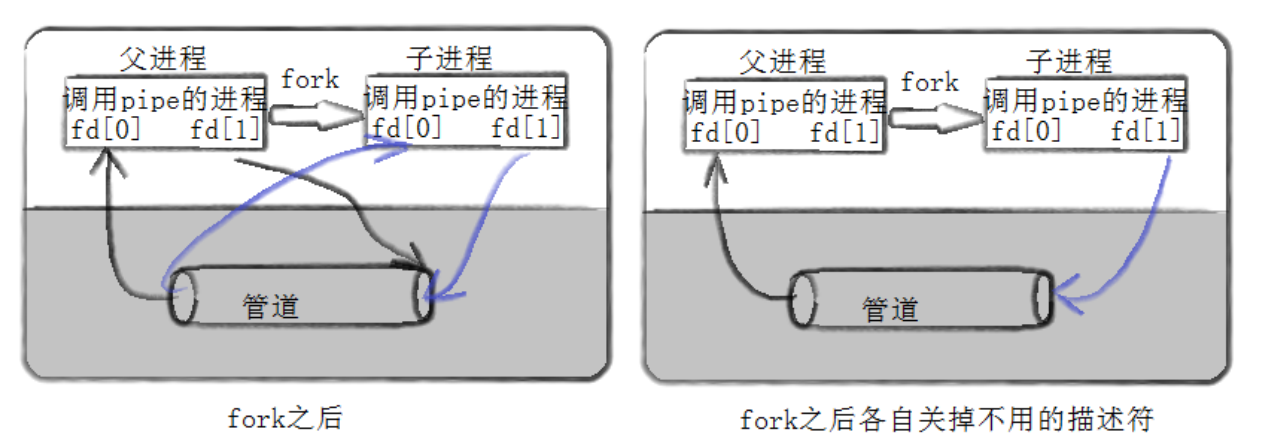
你可能会有疑问,操作系统为什么要搞出管道,要是上面那样的话,和父进程直接向一个文件写,子进程从这个文件里读有什么区别?
管道通信是加载在内存上的,管道本身是一块缓冲区,这种方式更快,因为对于文件而言,它是在磁盘上加载的,如果单纯的对一个文件进行读写操作,肯定是要慢一些的
为什么说这种管道通信只能应用于亲戚之间呢?
因为只有亲戚之间,也就是同一个进程fork出的进程之间才会进行缓冲区共享
#include <iostream>
#include <unistd.h>
#include <error.h>
#include <stdio.h>
#include <cstring>
#include <sys/wait.h>#define N 2
#define NUM 1024using namespace std;void Writer(int wfd)
{string s = "i am a child abcdefg";char buf[NUM];buf[0] = 0;snprintf(buf, sizeof(buf), "%s", s.c_str());//把s.c_str()以字符串形式写入到buf里write(wfd, buf, sizeof(buf));//write(wfd, buf, sizeof(s.c_str()));// cout << "sizeof(s.c_str()):" << sizeof(s.c_str()) << endl;//s.c_str()返回值为char类型的指针// cout << "strlen(buf):" << strlen(buf) << endl;// cout << "strlen(s.c_str()):" << strlen(s.c_str()) << endl;
}void Reader(int rfd)
{char buf[NUM];ssize_t n = read(rfd, buf, sizeof(buf));//sizeof != strlenbuf[n] = 0;//0 == '\0' cout << buf << endl;//cout << n << endl;//printf("%s\n", buf);
}int main()
{int pipefd[N] = {0};//pipefd[2]int n = pipe(pipefd);//给pipe()函数传递一个数组,返回的数组下标0位置是读的文件描述符,下标1位置为写的文件描述符//cout << pipefd[0] << " " << pipefd[1] << endl;pid_t id = fork();if(id < 0){perror("fork error");return 1;}if(id == 0)//child --- 我们让子进程写,父进程读{close(pipefd[0]);//关闭子进程的读文件描述符Writer(pipefd[1]);close(pipefd[1]);//可关可不关,因为进程结束,它会自动关闭exit(0);}if(id > 0)//father----我么让父进程读,子进程写{close(pipefd[1]);//关闭父进程的写文件描述符Reader(pipefd[0]); }pid_t rid = waitpid(id, nullptr, 0);//return id -------- ridclose(pipefd[0]);//可关可不关,因为进程结束,它会自动关闭return 0;
}
管道特点
1.只能用于具有共同祖先的进程(具有亲缘关系的进程)之间进行通信;通常,一个管道由一个进程创建,然后该进程调用fork,此后父、子进程之间就可应用该管道。
2.管道提供流式服务
3.一般而言,进程退出,管道释放,所以管道的生命周期随进程
4.一般而言,内核会对管道操作进行同步与互斥管道是半双工的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道
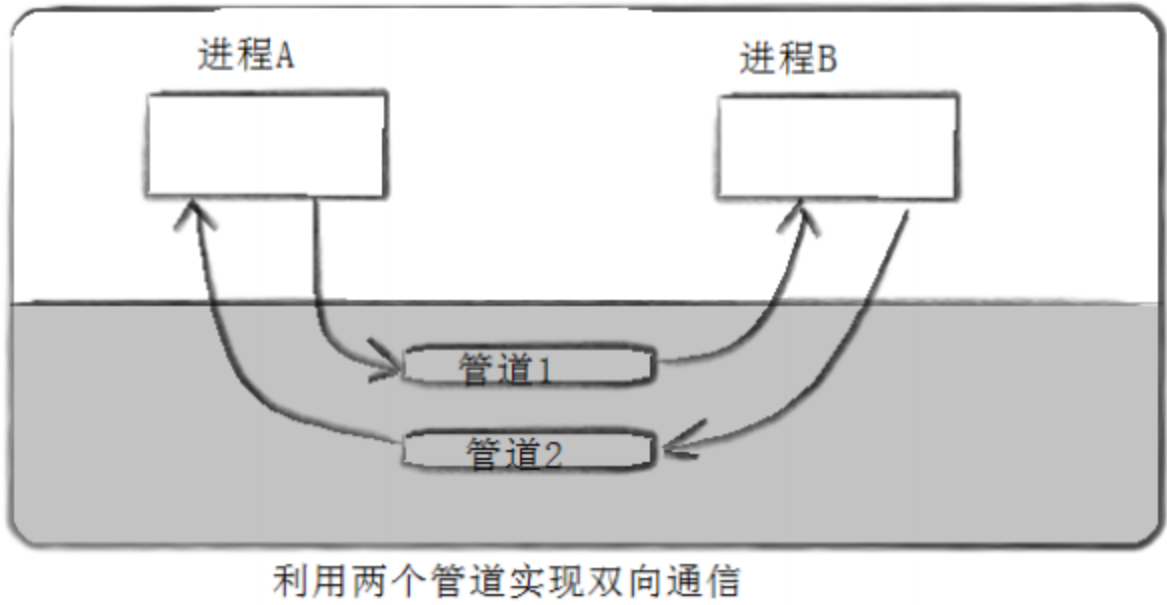
管道的四种情况
1.读写端正常,管道如果为空,读端就要阻塞
2.读写端正常,管道如果被写满,写端就要阻塞
3.读端正常读,写端关闭,读端就会读到0,表明读到了文件pipe的结尾,不会被阻塞
4.写端正常写,读端关闭了。操作系统就要杀掉正在写入的进程。如何杀掉?通过信号杀掉,因为操作系统是不会做这种抵消,浪费等类似的工作,如果做了就是操作系统的bug
管道的应用场景(进程池)
我们知道当一个进程要执行一个事情时,一般它会创建一个子进程,并把这件事交给该进程让它去完成,现在我们有若干个任务要去让这个进程去完成,因此该进程就要去创建多个子进程,让他们分别去完成这些事,但是像这种每一次都要创建子进程的过程是很浪费时间的,操作系统是不会允许这种影响效率的事情发生的,那么我们要怎么提高效率呢?
进程池,就是让为该进程提前创建好若干个子进程,当有多个任务来的时候,就让这个父进程给子进程去派发不同的任务。我们以父进程为老板,子进程为打工人的场景来模拟,具体实现如下:
ProcessPool.cc
#include <unistd.h>
#include <string>
#include <iostream>
#include <vector>
#include <sys/wait.h>
#include <ctime>
#include "Task.hpp"using namespace std;#define processnum 10
#define N 2
#define NUM 1024
vector<task_t> tasks;//声明Task.hpp中的变量//先描述
class channel//管道
{
public:channel(int cmdfd, pid_t slaverid, const string& processname):_cmdfd(cmdfd),_slaverid(slaverid),_processname(processname){}public:int _cmdfd;//发送任务的文件描述符pid_t _slaverid;//该子进程的pidstring _processname;//子进程的名字
};void slaver()
{// char buf[NUM];// read(0, buf, sizeof(buf));int cmdnum = 0;//几号任务read(0, &cmdnum, sizeof(int));//cout << "读到了:" << cmdnum << endl;if(cmdnum > 0 && cmdnum <= tasks.size()){//cout << "cmdnum:" << cmdnum << endl;tasks[cmdnum - 1]();//为什么要加括号?//cout << "读到了:" << cmdnum << endl;}}void Menu()
{cout << "*******************************" << endl;cout << "********1.开机 2.打怪兽******" << endl;cout << "********3.回血 4.关机********" << endl;cout << "*******************************" << endl;cout << "请输入要执行的任务" << endl;
}void InitChannels(vector<channel>* channels)
{for(int i = 0; i < processnum; i++){int pipefd[N] = {0};pipe(pipefd);//cout << "pipefd[0]:" << pipefd[0] << " " << "pipefd[1]:" << pipefd[1] << endl;pid_t pid = fork();if(pid == 0){close(pipefd[1]);dup2(pipefd[0], 0);slaver();//slaver(pipefd[0]);//close(pipefd[0]);//子进程读的文件描述符可以不用关exit(0);}//fatherclose(pipefd[0]);//write(pipefd[1], "abcd", sizeof("abcd"));//Writer();string name = "process:" + to_string(i);channels->push_back(channel(pipefd[1], getpid(), name));//close(pipefd[1]);//waitpid(getpid(), nullptr, 0);}
}void Print(vector<channel> channels)
{int i = 0;for(auto& e : channels){cout << e._cmdfd << " " << e._processname << " " << e._slaverid << endl;//cout << "xxxxxxxxxxxxxxxxxxx" << i << "xxxxxxxxxxxxxxxxxxxxx" << endl;i++;}
}void ctrlSlaver(vector<channel> channels)
{while(1){//1.选择任务Menu();int select = 0; cin >> select;//2.选择进程srand(time(nullptr));int processpos = rand() % channels.size();//进程vector中对应的下标位置//3.发送任务write(channels[processpos]._cmdfd, &select, sizeof(int));//cout << channels[processpos]._cmdfd << endl;sleep(1);}
}void QuitProcess(const std::vector<channel> &channels)
{for(const auto &c : channels) close(c._cmdfd);// sleep(5);for(const auto &c : channels) waitpid(c._slaverid, nullptr, 0);// sleep(5);
}int main()
{LoadTask(&tasks);vector<channel> channels;//1.初始化channelsInitChannels(&channels);//Print(channels);//2.控制子进程ctrlSlaver(channels);QuitProcess(channels);return 0;
}
Task.hpp
#pragma once#include <iostream>
#include <vector>using namespace std;typedef void (*task_t)();//task_t先和*结合,所以task_t是一个指向参数为空,返回值为void的函数指针void task1()
{cout << "开机" << endl;
}void task2()
{cout << "打怪兽" << endl;
}void task3()
{cout << "回血" << endl;
}void task4()
{cout << "关机" << endl;
}void LoadTask(vector<task_t> *tasks)
{tasks->push_back(task1);tasks->push_back(task2);tasks->push_back(task3);tasks->push_back(task4);
}
相关文章:
Linux进程间通信之匿名管道
文章目录 为什么要有进程间通信pipe函数共享管道原理管道特点管道的四种情况 管道的应用场景(进程池)ProcessPool.ccTask.hpp 为什么要有进程间通信 数据传输:一个进程需要将它的数据发送给另一个进程 资源共享:多个进程之间共享…...

【PTA题目】6-19 使用函数输出指定范围内的Fibonacci数 分数 20
6-19 使用函数输出指定范围内的Fibonacci数 分数 20 全屏浏览题目 切换布局 作者 C课程组 单位 浙江大学 本题要求实现一个计算Fibonacci数的简单函数,并利用其实现另一个函数,输出两正整数m和n(0<m≤n≤10000)之间的所有F…...

运行ps显示msvcp140.dll丢失怎么恢复?msvcp140.dll快速解决的4个不同方法
msvcp140.dll无法继续执行代码的主要原因有以下几点 系统缺失:msvcp140.dll是Visual Studio 2015编译的程序默认的库文件,如果系统中没有这个库文件,那么在运行相关程序时就会出现找不到msvcp140.dll的错误提示。 文件损坏:如果…...

Java多线程(3)
Java多线程(3) 深入剖析Java线程的生命周期,探秘JVM的线程状态! 线程的生命周期 Java 线程的生命周期主要包括五个阶段:新建、就绪、运行、阻塞和销毁。 **新建(New):**线程对象通过 new 关键字创建&…...

Java线程周期
Java线程的生命周期包含以下状态: 新建(New):当一个线程被创建但还没有被启动时,它的状态是新建。就绪(Runnable):当线程已经被启动并且没有任何阻止它立即运行的条件时,…...
map与set的封装
目录 红黑树的结点 与 红黑树的迭代器 红黑树的实现: 迭代器: 编辑 红黑树的查找: 红黑树的插入: 编辑 检查红色结点:编辑红黑树的左旋 编辑红黑树的右旋 编辑红黑树的双旋 Map的封装 编辑set的…...
mac无法向移动硬盘拷贝文件怎么解决?不能读取移动硬盘文件怎么解决
有时候我们在使用mac的时候,会遇到一些问题,比如无法向移动硬盘拷贝文件或者不能读取移动硬盘文件。这些问题会给我们的工作和生活带来不便,所以我们需要找到原因和解决办法。本文将为你介绍mac无法向移动硬盘拷贝文件怎么回事,以…...

基于Netty实现的简单聊天服务组件
目录 基于Netty实现的简单聊天服务组件效果展示技术选型:功能分析聊天服务基础设施配置(基于Netty)定义组件基础的配置(ChatProperties)定义聊天服务类(ChatServer)定义聊天服务配置初始化类&am…...

视频封面:从视频中提取封面,轻松制作吸引人的视频
在当今的数字时代,视频已成为人们获取信息、娱乐和交流的重要方式。一个吸引人的视频封面往往能抓住眼球,提高点击率和观看率。今天将介绍如何从视频中提取封面,轻松制作吸引人的视频封面。 一、准备素材选择合适的视频片段 首先࿰…...
CICD 持续集成与持续交付——gitlab
部署 虚拟机最小需求:4G内存 4核cpu 下载:https://mirrors.tuna.tsinghua.edu.cn/gitlab-ce/yum/el7/ 安装依赖性 [rootcicd1 ~]# yum install -y curl policycoreutils-python openssh-server perl[rootcicd1 ~]# yum install -y gitlab-ce-15.9.3-ce.0…...

Linux - 驱动开发 - RNG框架
说明 公司SOC上有一个新思的真随机数(TRNG)模块,Linux平台上需要提供接口给外部使用。早期方式是提供一个独立的TRNG驱动,实现比较简单的,但是使用方式不open,为了加入Linux生态环境,对接linux…...
qsort使用举例和qsort函数的模拟实现
qsort使用举例 qsort是C语言中的一个标准库函数,用于对数组或者其他数据结构中的元素进行排序。它的原型如下: void qsort(void *base, size_t nmemb, size_t size, int (*compar)(const void *, const void *)); 我们可以去官网搜来看一看:…...

AttributeError: module ‘gradio‘ has no attribute ‘ClearButton‘解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...
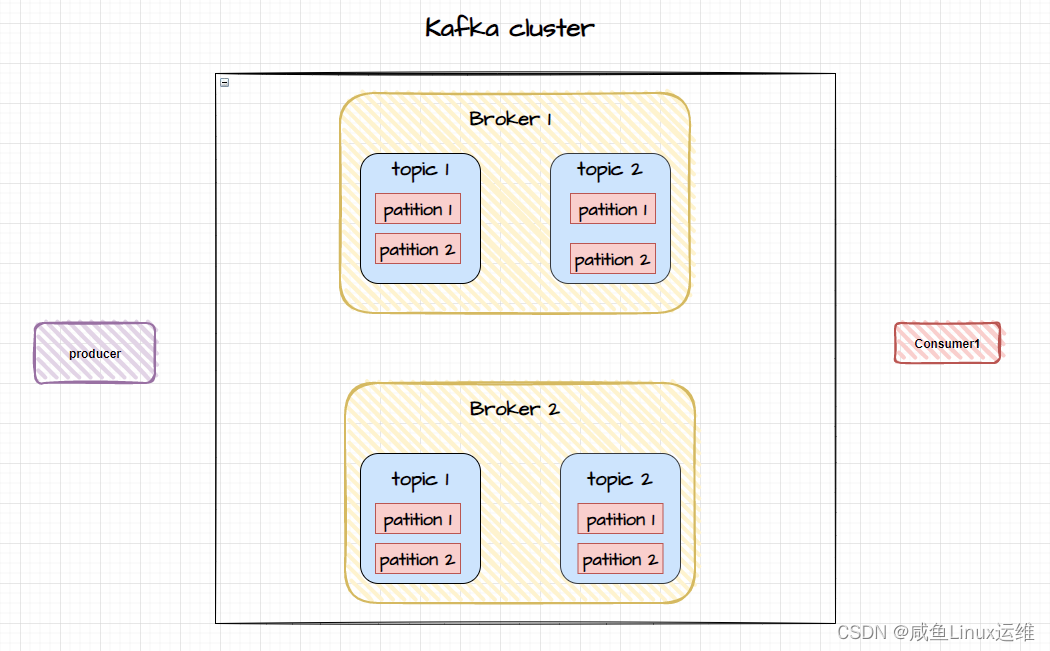
Kafka 集群如何实现数据同步?
哈喽大家好,我是咸鱼 最近这段时间比较忙,将近一周没更新文章,再不更新我那为数不多的粉丝量就要库库往下掉了 T﹏T 刚好最近在学 Kafka,于是决定写篇跟 Kafka 相关的文章(文中有不对的地方欢迎大家指出)…...
一本了解生成式人工智能
上周,发了一篇关于大语言模型图数据库技术相结合的文章,引起了很多朋友的兴趣。当然了,这项技术本身就让俺们很兴奋,比如我就是从事图研发的,当然会非常关注它在图领域的应用与相互促就啦。 纵观人类文明历史ÿ…...
)
git 相关指令总结(持续更新中......)
文章目录 一、git clone 相关指令1.1 clone 指定分支的代码 一、git clone 相关指令 1.1 clone 指定分支的代码 git clone -b 分支名 仓库地址...
windows 安装 Oracle Database 19c
目录 什么是 Oracle 数据库 下载 Oracle 数据库 解压文件 运行安装程序 测试连接 什么是 Oracle 数据库 Oracle数据库是由美国Oracle Corporation(甲骨文公司)开发和提供的一种关系型数据库管理系统,它是一种强大的关系型数据库管理系统…...

【数据结构】图的存储结构(邻接矩阵)
一.邻接矩阵 1.图的特点 任何两个顶点之间都可能存在边,无法通过存储位置表示这种任意的逻辑关系。 图无法采用顺序存储结构。 2.如何存储图? 将顶点与边分开存储。 3.邻接矩阵(数组表示法) 基本思想: 用一个一维数…...

kubernetes--Pod控制器详解
目录 一、Pod控制器及其功用: 二、pod控制器的多种类型: 1、ReplicaSet: 1.1 ReplicaSet主要三个组件组成: 2、Deployment: 3、DaemonSet: 4、StatefulSet: 5、Job: 6、Cronjob: …...
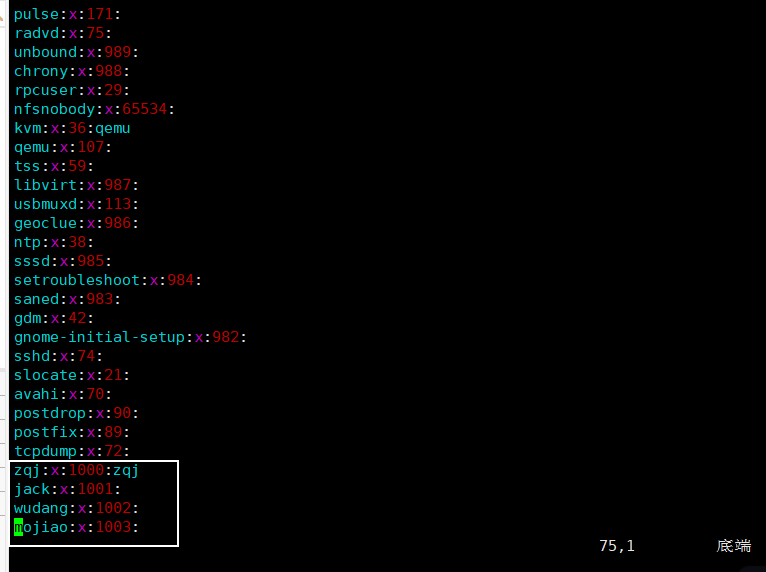
九、Linux用户管理
1.基本介绍 Linux系统是一个多用户多任务的操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,让后以这个账号的身份进入系统 2.添加用户 基本语法 useradd 用户名 应用案例 案例1:添加一个用户 m…...

从API调用成功率看Taotoken服务的稳定性与容灾表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从API调用成功率看Taotoken服务的稳定性与容灾表现 在将大模型能力集成到自动化流程或日常开发工具链时,服务的稳定性和…...

终极虚拟显示器解决方案:ParsecVDisplay完整使用指南
终极虚拟显示器解决方案:ParsecVDisplay完整使用指南 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd ParsecVDisplay是一个基于Parsec虚拟显示驱动(VDD)的独立应用程序…...

ComfyUI-WD14-Tagger:AI智能图像标签提取的终极完整指南
ComfyUI-WD14-Tagger:AI智能图像标签提取的终极完整指南 【免费下载链接】ComfyUI-WD14-Tagger A ComfyUI extension allowing for the interrogation of booru tags from images. 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-WD14-Tagger 在AI图像…...

第5章 薪资重构——AI时代的程序员价值重估
第5章 薪资重构——AI时代的程序员价值重估 核心问题:AI时代,程序员的薪资会发生怎样的变化?哪些人在涨薪?哪些人在降薪? 5.1 问题定义:薪资分化的真相是什么? 5.1.1 一个令人震惊的数据 2026年第一季度,一个对比让整个技术圈哗然: 同一家公司内部: - 一个AI方向…...
)
Lovable后端集成方案深度拆解(含Spring Boot 3.2+GraalVM+OpenTelemetry完整Demo)
更多请点击: https://kaifayun.com 第一章:Lovable后端集成方案全景概览 Lovable 是一个面向现代 Web 应用的轻量级后端协作框架,其核心设计理念是“可组合、可观测、可演进”。它不绑定特定语言或运行时,而是通过标准化协议与契…...

[特殊字符] 高效统计排序数组中目标元素的出现次数
给定一个已排序的数组和一个目标值,如何快速统计该目标值在数组中出现的次数?这是面试中非常经典的一道题,今天就来聊聊两种解法:线性搜索和二分搜索。 问题描述 假设有一个已排序的数组 arr[] 和一个整数 target,需…...

BurpSuite+SqlMap深度集成:构建高可信SQL注入检测流水线
1. 这不是“点几下就出结果”的玩具,而是你真正能放进渗透流程里的SQL注入检测流水线很多人第一次看到“BurpSuiteSqlMap插件5分钟搞定SQL注入检测”这个标题,第一反应是:又一个标题党?点开全是截图堆砌、参数照抄、报错就卡住的半…...

OpenTK 3.3.3实现3D旋转立方体:C# OpenGL入门实战
1. 为什么一个旋转立方体是3D图形编程真正的“Hello World” 很多人第一次接触OpenGL或现代图形API时,总想直接上手做粒子系统、PBR渲染或者实时阴影——结果卡在顶点缓冲对象(VBO)绑定失败、着色器编译报错、甚至窗口根本没显示出来。我带过…...

Balena Etcher:跨平台系统镜像安全写入的技术实现
Balena Etcher:跨平台系统镜像安全写入的技术实现 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher 当你需要在不同操作系统之间部署系统镜像时&#x…...

KMS智能激活工具:如何一键永久激活Windows和Office的完整指南
KMS智能激活工具:如何一键永久激活Windows和Office的完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows和Office激活问题而烦恼吗?每次系统重装后都要…...