文心一言 VS 讯飞星火 VS chatgpt (139)-- 算法导论11.4 3题
三、用go语言,考虑一个采用均匀散列的开放寻址散列表。当装载因子为 3/4 和 7/8 时,试分别给出一次不成功查找和一次成功查找的探查期望数上界。
文心一言:
在开放寻址法中,当散列表的装载因子超过其阈值时,会触发重新哈希。在均匀散列的情况下,我们可以使用二次探查来处理冲突。为了计算探查的期望次数上界,我们需要考虑在最坏的情况下需要多少次探查才能找到一个元素。
在此,我们假设哈希函数是均匀分布的,也就是说每个元素被散列到每个位置的概率是相等的。
首先,考虑装载因子为3/4的情况。在这种情况下,哈希表中的元素数量是散列表大小的3/4。假设散列表的大小为N,那么在理想情况下,哈希表中的元素数量为3/4 * N。
在不成功查找的情况下,我们需要遍历整个哈希表来寻找一个不存在的元素。因此,不成功查找的探查期望数上界为:
E[不成功查找] = N
在成功查找的情况下,我们需要找到一个存在的元素。在最坏的情况下,我们需要遍历整个哈希表来找到这个元素。因此,成功查找的探查期望数上界为:
E[成功查找] = N
然后,考虑装载因子为7/8的情况。在这种情况下,哈希表中的元素数量是散列表大小的7/8。假设散列表的大小为N,那么在理想情况下,哈希表中的元素数量为7/8 * N。
同样地,在不成功查找的情况下,我们需要遍历整个哈希表来寻找一个不存在的元素。因此,不成功查找的探查期望数上界仍然是:
E[不成功查找] = N
然而,在成功查找的情况下,由于装载因子更高,我们可能需要更多的探查次数才能找到一个存在的元素。在最坏的情况下,我们需要遍历整个哈希表并可能触发重新哈希才能找到这个元素。假设我们需要进行k次重新哈希才能找到元素,那么成功的探查期望数上界可以表示为:
E[成功查找] = N + k * (N + k)
其中k是一个大于0的整数,表示重新哈希的次数。这个公式表示我们在哈希表中查找一个元素所需的最小探查次数(即N),加上我们在重新哈希过程中所需的最小探查次数(即k * (N + k))。
需要注意的是,这些期望值是基于理论模型的,而在实际应用中可能会受到许多其他因素的影响,例如数据的分布、哈希函数的质量、重新哈希策略等。


讯飞星火,代码能运行,结果出错,不符合预期:
首先,我们需要了解均匀散列的开放寻址散列表的基本原理。当装载因子为 3/4 和 7/8 时,我们可以通过以下公式计算探查期望数上界:
- 当装载因子为 3/4 时,探查期望数上界 E = (1 - 1/(2^n)) * n
- 当装载因子为 7/8 时,探查期望数上界 E = (1 - 1/(2^n)) * n
接下来,我们将使用 Go 语言编写一个程序来计算这些值。
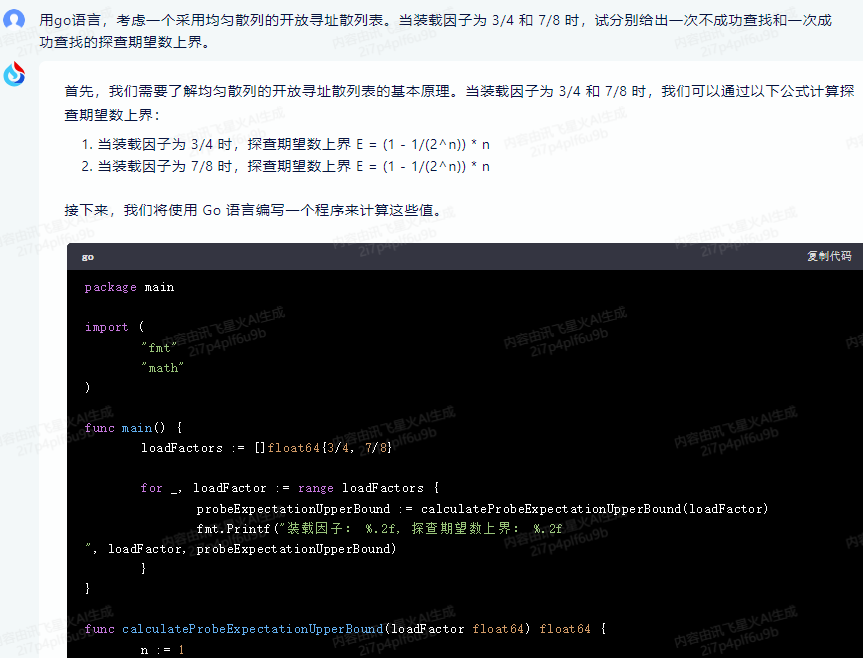
package mainimport ("fmt""math"
)func main() {loadFactors := []float64{3/4, 7/8}for _, loadFactor := range loadFactors {probeExpectationUpperBound := calculateProbeExpectationUpperBound(loadFactor)fmt.Printf("装载因子: %.2f, 探查期望数上界: %.2f
", loadFactor, probeExpectationUpperBound)}
}func calculateProbeExpectationUpperBound(loadFactor float64) float64 {n := 1while true {probeExpectation := (1 - 1/math.Pow(2, float64(n))) * float64(n)if probeExpectation >= loadFactor {return probeExpectation}n++}
}
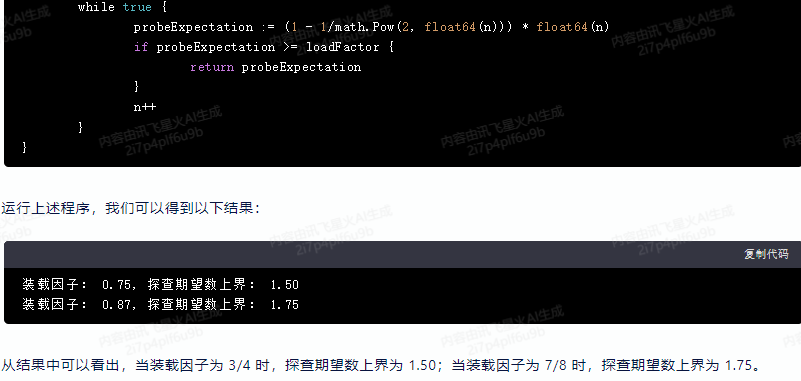
运行上述程序,我们可以得到以下结果:
装载因子: 0.75, 探查期望数上界: 1.50
装载因子: 0.87, 探查期望数上界: 1.75
从结果中可以看出,当装载因子为 3/4 时,探查期望数上界为 1.50;当装载因子为 7/8 时,探查期望数上界为 1.75。
360智脑:
在一个采用均匀散列的开放寻址散列表中,每次查找都需要进行平方探测。假设哈希表的大小为n,那么在一次不成功查找中,最多需要探测n个位置才能找到键值对;而在一次成功查找中,最多只需要探测log2(n)个位置。因此,一次不成功查找的探查期望数上界和一次成功查找的探查期望数上界分别为:
-
当装载因子为3/4时:
- 一次不成功查找的探查期望数上界:n
- 一次成功查找的探查期望数上界:log2(n)
-
当装载因子为7/8时:
- 一次不成功查找的探查期望数上界:n
- 一次成功查找的探查期望数上界:log2(n)

智谱清言,代码正常运行:
首先,我们需要了解均匀散列和开放寻址散列表的概念。
均匀散列是指将一组数据均匀地分布到散列表的各个位置,从而减少哈希冲突的概率。开放寻址散列表是一种在遇到哈希冲突时,将数据存储在下一个位置的散列表。
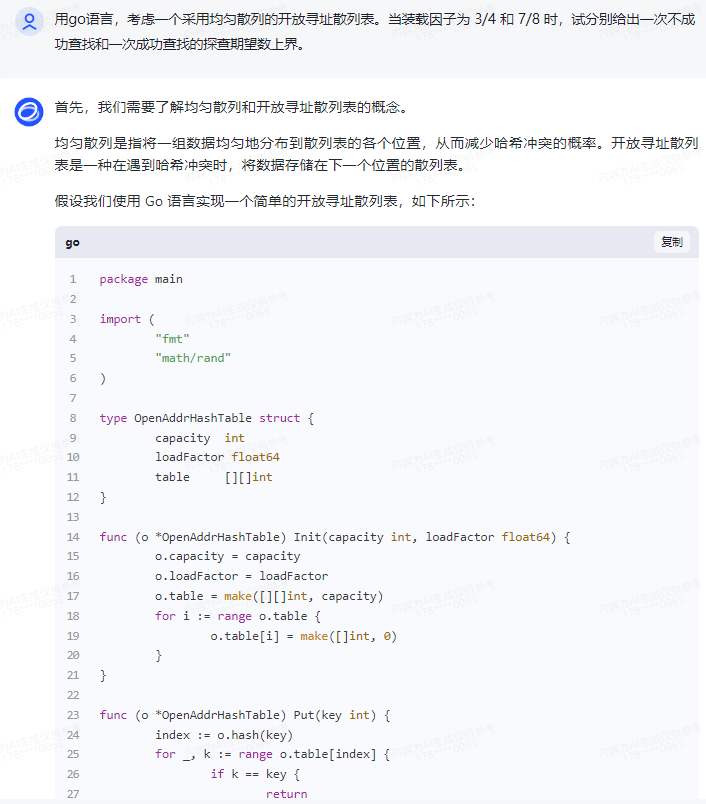
假设我们使用 Go 语言实现一个简单的开放寻址散列表,如下所示:
package main
import ( "fmt" "math/rand"
)
type OpenAddrHashTable struct { capacity int loadFactor float64 table [][]int
}
func (o *OpenAddrHashTable) Init(capacity int, loadFactor float64) { o.capacity = capacity o.loadFactor = loadFactor o.table = make([][]int, capacity) for i := range o.table { o.table[i] = make([]int, 0) }
}
func (o *OpenAddrHashTable) Put(key int) { index := o.hash(key) for _, k := range o.table[index] { if k == key { return } } o.table[index] = append(o.table[index], key)
}
func (o *OpenAddrHashTable) Get(key int) (int, bool) { index := o.hash(key) for _, k := range o.table[index] { if k == key { return k, true } } return 0, false
}
func (o *OpenAddrHashTable) hash(key int) int { return rand.Intn(o.capacity)
}
func main() { // 创建一个散列表 ht := &OpenAddrHashTable{ capacity: 16, loadFactor: 0.75, } ht.Init(16, 0.75)// 插入一些键值对 ht.Put(1) ht.Put(2) ht.Put(3) ht.Put(4)// 模拟不成功查找 notFoundKey := 5 for i := 0; i < 10; i++ { index, found := ht.Get(notFoundKey) if found { fmt.Printf("找到了键 %d,索引为 %d\n", notFoundKey, index) break } fmt.Printf("未找到键 %d,尝试次数:%d\n", notFoundKey, i) }// 模拟成功查找 successKey := 3 for i := 0; i < 10; i++ { index, found := ht.Get(successKey) if found { fmt.Printf("找到了键 %d,索引为 %d\n", successKey, index) break } fmt.Printf("未找到键 %d,尝试次数:%d\n", successKey, i) }
}
现在,我们需要计算在装载因子为 3/4 和 7/8 时,一次不成功查找和一次成功查找的探查期望数上界。
1.装载因子为3/4时,一次不成功查找的探查期望数上界:
假设散列表中有 n 个元素,那么平均来说,每个位置可能有 n/capacity 个元素。在一次不成功查找中,我们需要遍历的所有位置的总概率为 1 - (1 - 3/4)^n。
期望探查数上界为:1 / (1 - (1 - 3/4)^n)
1.装载因子为7/8时,一次成功查找的探查期望数上界:
当装载因子为7/8时,每个位置的平均概率为1 - (1 - 7/8)^n。
期望探查数上界为:1 / (1 - (1 - 7/8)^n)
注意:这里的计算假设了散列表是完全填充的,实际情况可能会因为


通义千问:
对于开放寻址散列表,通常使用线性探测方法,即从哈希函数计算出的位置开始,如果该位置已经有元素存在,则依次检查下一个位置,直到找到空位置为止。
装载因子是已存储的关键字数量与散列表的大小之比。
在最坏的情况下,所有关键字都映射到同一个槽中,因此每次插入都需要进行n次探查(其中n是散列表的大小)。但是,在实际情况下,这种情况非常罕见。如果我们假设散列函数将关键字均匀地分布在散列表中,那么我们可以估计平均探查次数。
1.当装载因子为3/4时,我们可以估算一次不成功的查找的探查期望数上界为:
探查期望数 = (1 - 装载因子) / 装载因子
所以,(1 - 3/4) / (3/4) = 1.
这意味着,当我们查找不存在的关键字时,预期需要探查整个散列表。
2.同样,当装载因子为7/8时,我们可以估算一次不成功的查找的探查期望数上界为:
探查期望数 = (1 - 装载因子) / 装载因子
所以,(1 - 7/8) / (7/8) = 15/7.
这意味着,当我们查找不存在的关键字时,预期需要探查整个散列表的15/7倍。
对于一次成功的查找,因为我们的目标元素一定存在于表中,所以其探查次数为1。

天工:
对于采用均匀散列的开放寻址散列表,探查期望数的计算公式如下:
E = 1 + (n-1) * (1-loadFactor)
其中,n 为散列表中元素的个数,loadFactor 为装载因子。
当装载因子为 3/4 时,一次不成功查找的探查期望数上界为:
E = 1 + (n-1) * (1-3/4) = 1 + (n-1) * 1/4
当装载因子为 7/8 时,一次不成功查找的探查期望数上界为:
E = 1 + (n-1) * (1-7/8) = 1 + (n-1) * 1/8
一次成功查找的探查期望数上界为 1,因为成功查找时不需要进行探查。
需要注意的是,以上计算公式只是探查期望数的上界,实际的探查期望数可能会比这个值小。此外,在实际应用中,还需要考虑其他因素,如散列函数的设计、冲突解决策略等。

灵小智:
对于具有均匀散列和开放寻址的散列表,在装载因子为 3/4 和 7/8 时,可以计算出一次不成功查找和一次成功查找的探查期望数上界。
装载因子(Load Factor)用来衡量散列表中已经被占用的位置比例。装载因子等于散列表中已存储元素数量与总槽数量之比。
探查期望数上界是指在散列表中进行查找时,平均需要尝试的次数的上限值。
1.装载因子为 3/4 时:
-
一次不成功查找的探查期望数上界:约为 1 / (1 - 3/4) = 4 次
-
一次成功查找的探查期望数上界:约为 -ln(1 - 3/4) ≈ 1.386 次
2.装载因子为 7/8 时:
-
一次不成功查找的探查期望数上界:约为 1 / (1 - 7/8) = 8 次
-
一次成功查找的探查期望数上界:约为 -ln(1 - 7/8) ≈ 2.772 次
这些数值仅作为近似值提供,实际情况可能会受到具体的散列函数和探查策略的影响而有所不同。

chatgpt:
对于采用均匀散列的开放寻址散列表,当装载因子为3/4时,不成功查找的探查期望数上界可以通过公式进行计算:
不成功查找的探查期望数上界 = 1 / (1 - 装载因子)
将装载因子替换为3/4,则有:
不成功查找的探查期望数上界 = 1 / (1 - 3/4) = 4
这意味着在平均情况下,进行一次不成功的查找最多需要进行4次探查。
同样地,当装载因子为7/8时,不成功查找的探查期望数上界为:
不成功查找的探查期望数上界 = 1 / (1 - 装载因子)
将装载因子替换为7/8,则有:
不成功查找的探查期望数上界 = 1 / (1 - 7/8) = 8
这意味着在平均情况下,进行一次不成功的查找最多需要进行8次探查。
至于一次成功查找的探查期望数上界,在采用均匀散列和开放寻址策略时是难以给出精确值的。这是由于具体元素位置和相邻元素被占用情况等因素的影响。但通常情况下,成功查找所需的探查次数会较不成功查找少得多。
相关文章:
文心一言 VS 讯飞星火 VS chatgpt (139)-- 算法导论11.4 3题
三、用go语言,考虑一个采用均匀散列的开放寻址散列表。当装载因子为 3/4 和 7/8 时,试分别给出一次不成功查找和一次成功查找的探查期望数上界。 文心一言: 在开放寻址法中,当散列表的装载因子超过其阈值时,会触发重…...
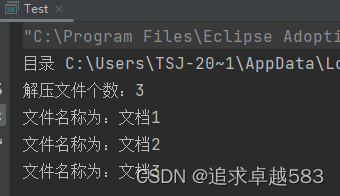
Java 解压文件
maven库: <!--FileUtil、ZipUtil 依赖--> <dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.3.1</version> </dependency><!--IOUtils 依赖--> <depen…...
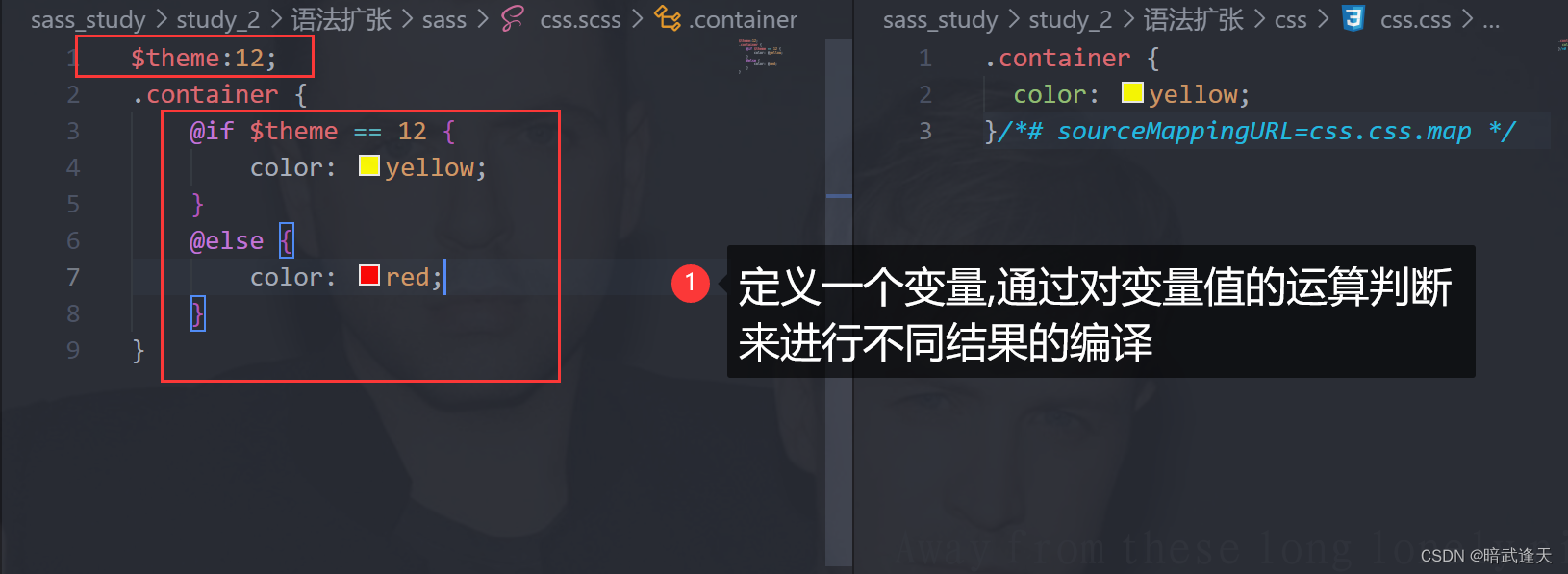
SASS/SCSS精华干货教程
目录 介绍 基本说明 特点 sass语法格式sass的语法格式一共有两种,一种是以".scss"作为拓展名,一种是以".sass"作为拓展名,这里我们只讲拓展名: 编译环境安装 Vscode安装编译插件 简单使用 sass语法扩张…...
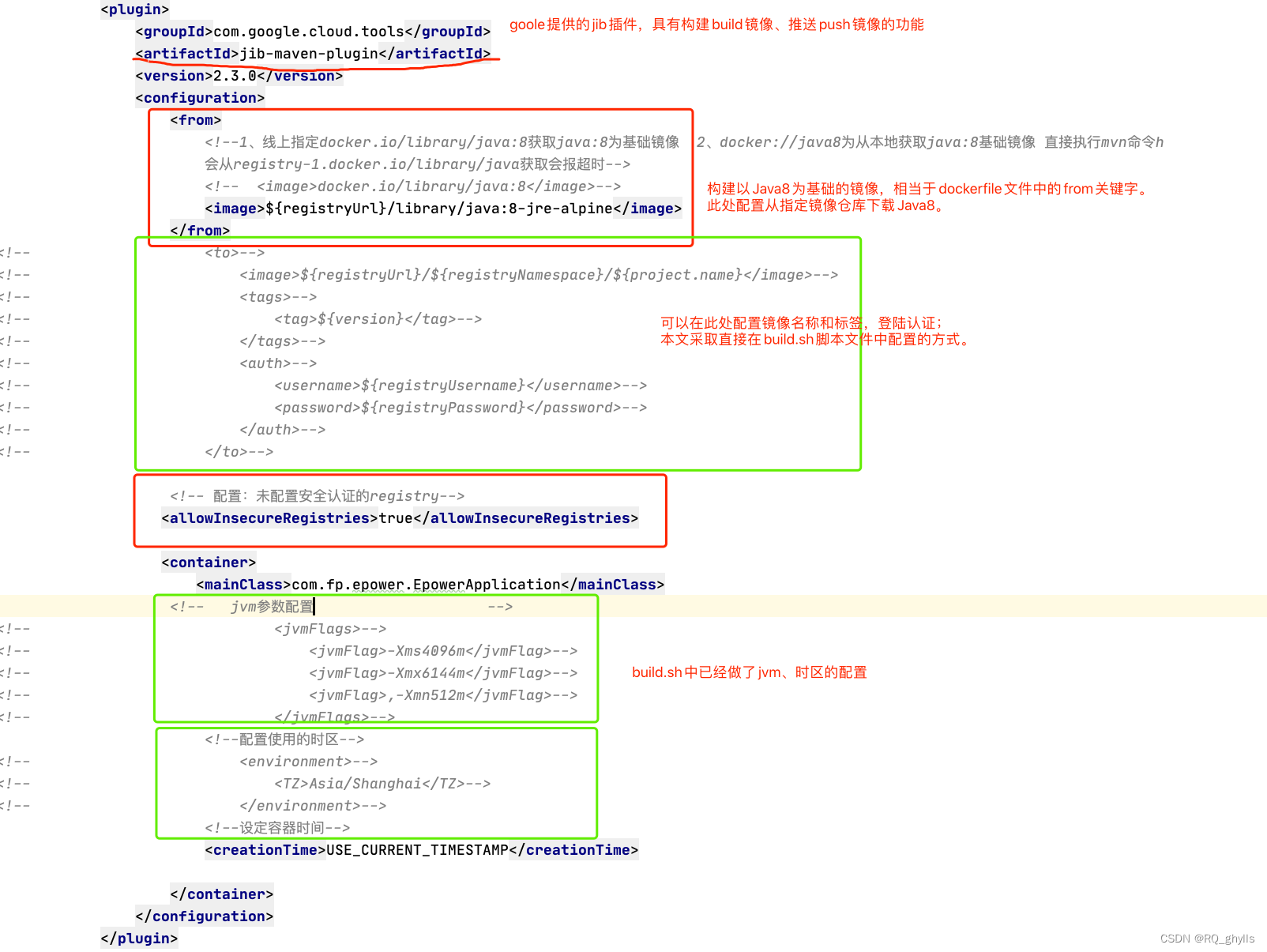
8.jib-maven-plugin构建springboot项目镜像,docker部署配置
目录 1.构建、推送镜像 1.1 执行脚本 2.2 pom.xml配置 2.部署镜像服务 2.1 执行脚本 2.2 compose文件 3.docker stack常用命令 介绍:使用goole jib插件构建镜像,docker stack启动部署服务; 通过执行两个脚本既可以实现构建镜像、部…...
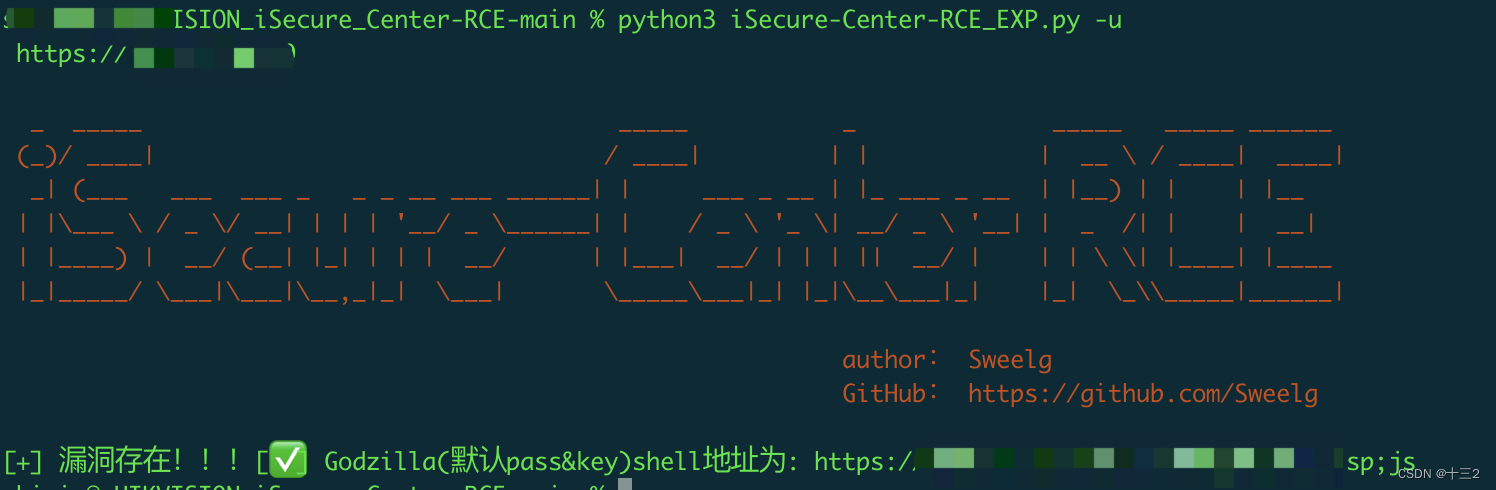
海康威视综合安防管理平台任意文件上传
系统介绍 HIKVISION iSecure Center综合安防管理平台是一套“集成化”、“智能化”的平台,通过接入视频监控、一卡通、停车场、报警检测等系统的设备,获取边缘节点数据,实现安防信息化集成与联动,公众号:web安全工具库…...
Linux环境下C++ 接入OpenSSL
接上一篇:Windows环境下C 安装OpenSSL库 源码编译及使用(VS2019)_vs2019安装openssl_肥宝Fable的博客-CSDN博客 解决完本地windows环境,想赶紧在外网环境看看是否也正常。毕竟现在只是HelloWorld级别的,等东西多了&am…...

美国网站服务器SSL证书介绍
美国网站服务器的SSL证书也是一种数字证书,由权威数字证书机构CA验证网站的身份后所颁发,可实现浏览器与网站主机之间的数据传输加密。美国网站服务器搭建的网站在安装SSL证书后会在浏览器显示安全锁标志,数据传输协议则从HTTP传统协议升级为…...
JSP命令标签 静态包含/动态包含
好 下面我们聊聊JSP中的指令标签 这边 我们来说两个 分别是 静态包含 和 动态包含 我们可以将重用性代码包含起来 更好的使用 比如 我们界面上中下 分别有三个导航栏 那么 如果你写三份 就会出现很多重复代码 而且 改起来 也很不方便 要一次改三份 口说无凭 我们来做一个小案…...
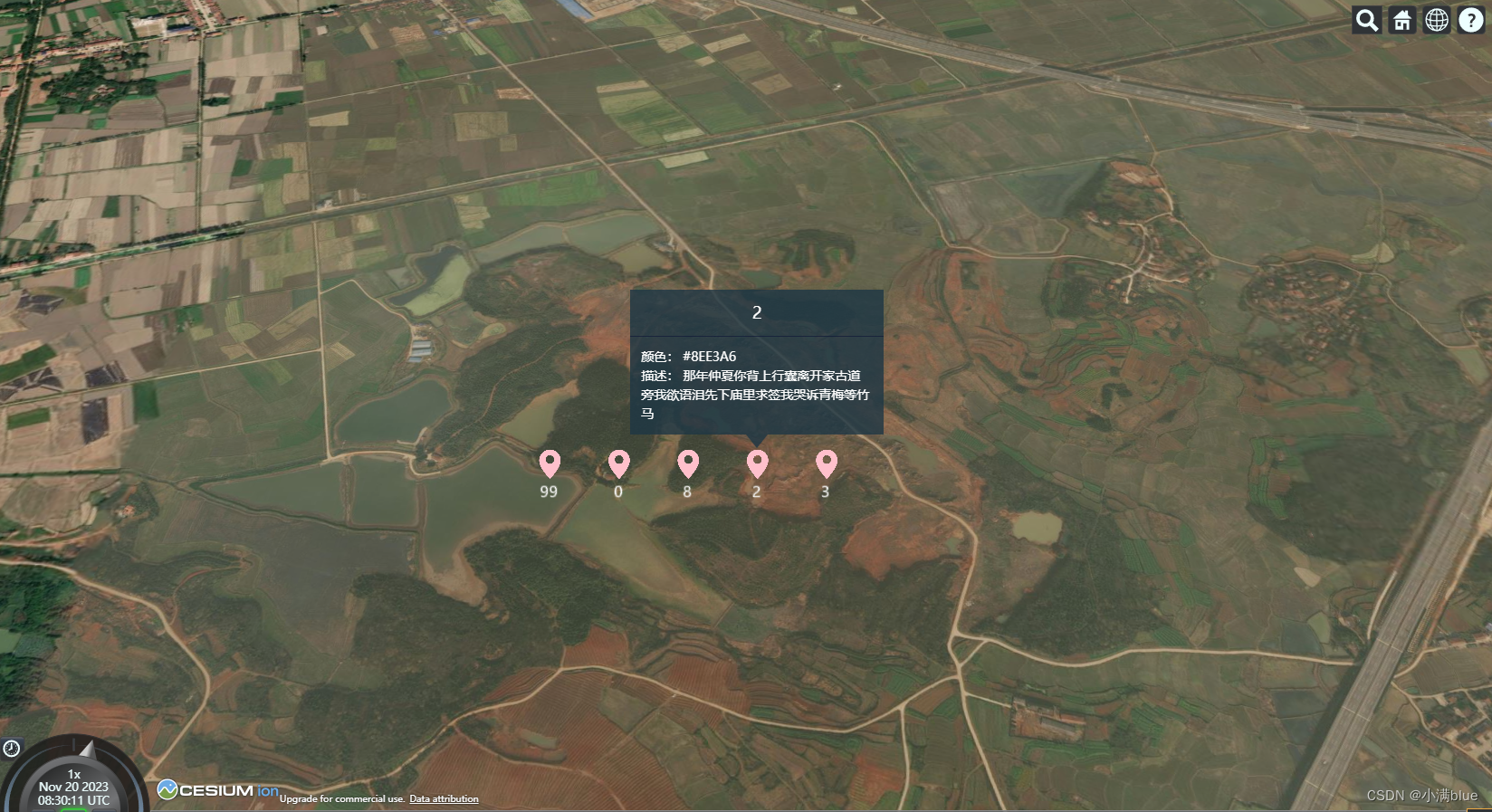
Cesium点位弹窗
1.弹窗没法向加入点位一样加入到地图内部,entity没法实现 2.使用绝对定位,将地图组件通过定位加入到地图上,注意弹窗层级一定在地图上 3.通过判断点击位置是否是点位来获取entity信息,将信息显示在弹窗 4.将点击处点位的经纬度转为…...

基于单片机16路抢答器仿真系统
**单片机设计介绍, 基于单片机16路抢答器仿真系统 文章目录 一 概要二、功能设计设计思路 三、 软件设计原理图 五、 程序六、 文章目录 一 概要 基于单片机的16路抢答器仿真系统是一种用于模拟和实现抢答竞赛的系统。该系统由硬件和软件两部分组成。 硬件方面&am…...

Linux常用命令亲测总结
在实际开发中,经常会进行下位机的搭建,在搭建过程中,对于常用的LInux命令进行总结,方便自己使用 1.rm -rf 删除对应文件(字节小的) 2、ln -s 文件关联(长的关联短的。三个则关联两次࿰…...
二百零六、Flume——Flume1.9.0单机版部署脚本(附截图)
一、目的 在实际项目部署时,要实现易部署易维护,需要把安装步骤变成安装脚本实现快速部署 二、部署脚本在Linux中文件位置 文件夹中只有脚本文件flume-install.sh和tar包apache-flume-1.9.0-bin.tar.gz 三、Flume安装脚本 #!/bin/bash #获取服务器名…...
不必购买Mac,这款国产设计工具能轻松替代Sketch!
介绍 即时设计是新一代可以直接在浏览器中使用的设计工具,具有Sketch和实时协作功能。与本地Sketch相比,增加了实时协作功能,即时设计可以看作是在线Sketch,两个工具可以简单粗暴地总结为一个公式: 即时设计Sketch云…...

通过多线程的方式每次发送10条MQ消息
背景:传入一个List<person>,不知道list中有多少条数据。 import org.apache.rocketmq.client.producer.DefaultMQProducer; import org.apache.rocketmq.client.producer.Message; import org.apache.rocketmq.client.producer.SendResult;import java.util.A…...
springboot上传文件后显示权限不足
前言: 最近一个老项目迁移,原本一直好好的,迁移后上传文件的功能使用不正常,显示文件没有可读取权限,这个项目并不是我们开发和配置的,由第三方开发的,我们只是接手一下。 前端通过api上传文件…...
spring-boot-maven-plugin插件 —— 打包时减小jar包的大小方法
Maven 在打包时会将所依赖的 jar 包全部打包进去,包含了所有的依赖和资源文件,就会导致打出来的包比较大。如果再上传服务器,那么耗时特别长。 由于依赖包变化小,占用空间大,而且大部分情况是添加一次后,就…...

java Bigdecimal
一、BigDecimal概述 BigDecimal是Java在java.math包中提供的线程安全的API类,用来对超过16位有效位的数进行精确的运算。双精度浮点型变量double可以处理16位有效数,但在实际应用中,可能需要对更大或者更小的数进行运算和处理。一般情况下&am…...

【C++11并发】thread 笔记
简介 进程和线程的区别 进程:一个在内存中运行的应用程序。每个进程都有自己独立的一块内存空间,一个进程可以有多个线程,比如在Windows系统中,一个运行的xx.exe就是一个进程。 线程:进程中的一个执行任务(…...

OBS Studio免费开源录屏工具
OBS是Open Broadcaster Software的缩写,是一款免费且开源的多平台录屏和直播软件。它可以用于录制屏幕、捕获游戏、创建教学视频、直播游戏等。OBS功能强大且灵活,提供了许多配置选项和自定义功能,使用户能够根据自己的需求进行设置和调整。它…...
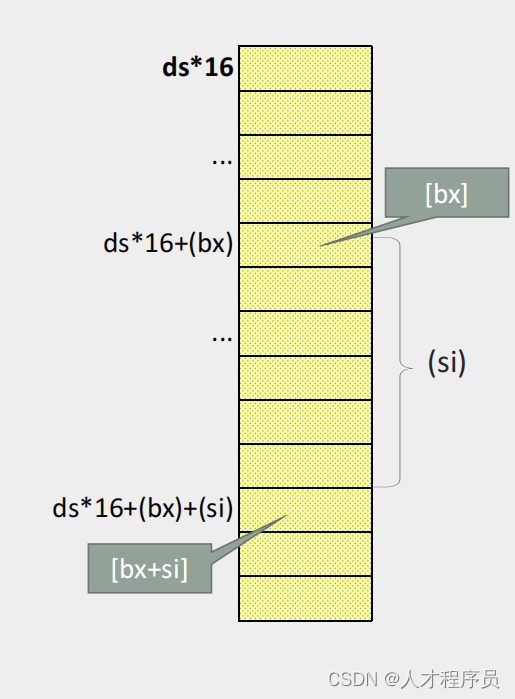
【汇编】[bx+idata]的寻址方式、SI和DI寄存器
文章目录 前言一、[bxidata]寻址方式1.1 [bxidata]的含义1.2 示例代码 二、SI和DI寄存器2.1 SI和DI寄存器是什么?2.2 [bxsi]和[bxdi]方式寻址2.3 [bxsiidata]和[bxdiidata] 总结 前言 在汇编语言中,寻址方式是指指令如何定位内存中的数据。BX寄存器与偏…...

AI Agent开发效率提升300%的7个核心框架选择逻辑:从LangChain到AutoGen,2024企业级选型权威对比
更多请点击: https://codechina.net 第一章:AI Agent开发效率提升300%的7个核心框架选择逻辑:从LangChain到AutoGen,2024企业级选型权威对比 企业在构建生产级AI Agent时,框架选型直接决定迭代速度、可观测性与多模态…...

实时任意风格迁移:AdaIN算法在PyTorch中的优雅实现
实时任意风格迁移:AdaIN算法在PyTorch中的优雅实现 【免费下载链接】pytorch-AdaIN Unofficial pytorch implementation of Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization [Huang, ICCV2017] 项目地址: https://gitcode.com/gh_mi…...

3分钟学会洛雪音乐音源配置:免费获取全网高品质音乐的终极指南
3分钟学会洛雪音乐音源配置:免费获取全网高品质音乐的终极指南 【免费下载链接】lxmusic- lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/gh_mirrors/lx/lxmusic- 还在为找不到高质量免费音乐资源而烦恼吗?lxmusic-项目为你提…...

如何利用Chanlun-Pro实现智能缠论量化交易:3步掌握市场结构识别
如何利用Chanlun-Pro实现智能缠论量化交易:3步掌握市场结构识别 【免费下载链接】chanlun-pro 基于缠中说禅所讲缠论理论,以便量化分析市场行情的工具 项目地址: https://gitcode.com/gh_mirrors/ch/chanlun-pro 在金融市场日益复杂的今天&#x…...

观察Taotoken在流量高峰时段的请求成功率和路由表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在流量高峰时段的请求成功率和路由表现 在构建依赖大模型能力的应用时,服务的稳定性是开发者关心的核心问…...

Illustrator智能填充脚本Fillinger:如何3步完成复杂图案设计
Illustrator智能填充脚本Fillinger:如何3步完成复杂图案设计 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 在Adobe Illustrator中,你是否曾为填充复杂形状…...
代码平台的方法)
在fnOS飞牛NAS上部署宝塔+NocoBase低(零)代码平台的方法
在fnOS飞牛NAS上部署宝塔NocoBase低(零)代码平台的方法 温馨提醒:本文全文免费,严禁盗用、二次收费行为! 更新日志: 2026/03/29 首次发布 2026/05/22 1、新增通过systemd托管进程,实现重启后自…...

Proteus 8.17安装超详细教程 保姆级教程【附安装包】
电子设计小伙伴们!今天我给大家带来一篇超详细的Proteus 8.17专业版安装教程 !这可是电子工程师和学生党的福音啊!作为PCB设计和单片机仿真的神器,Proteus绝对是你玩转电子设计必备的利器!不会安装?别担心&…...

欢迎新Buddy:DataBuddy
大数据人自己的原生Agent来了!腾讯云大数据智能体工作台DataBuddy正式发布。用户通过自然语言对话,即可完成数据接入、开发、治理、分析全链路任务,不用再在多个页面之间切换操作,一句话说清目标,Agent自己跑完全流程。…...

OpenClaw入门教程:从零部署到第一个智能体
OpenClaw OpenClaw(原 Moltbot)是一个开源的 AI 智能体(Agent)框架,旨在通过连接大语言模型(LLM)与外部工具(如浏览器、API、办公软件),实现自动化任务执行。…...