Flink(七)【输出算子(Sink)】
前言
今天是我写博客的第 200 篇,恍惚间两年过去了,现在已经是大三的学长了。仍然记得两年前第一次写博客的时候,当时学的应该是 Java 语言,菜的一批,写了就删,怕被人看到丢脸。当时就想着自己一年之后,两年之后能学到什么水平,什么是 JDBC、什么是 MVC、SSM,在当时都是特别好奇的东西,不过都在后来的学习中慢慢接触到,并且好多已经烂熟于心了。
那,今天我在畅想一下,一年后的今天,我又学到了什么水平?能否达到三花聚顶、草木山石皆可为码的超凡入圣的境界?拿没拿到心仪的 offer?和那个心动过的女孩相处怎么样了?哈哈哈哈哈
输出算子(Sink)
学完了 Flink 在不同执行环境(本地测试环境和集群环境)下的多种读取(多种数据源)和转换操作(多种转换算子),最后就是输出操作了。

1、连接到外部系统
Flink 1.12 之前,Sink 算子是通过调用 DataStream 的 addSink 方法来实现的:
stream.addSink(new SinkFunction(...));从 Flink 1.12 开始,Flink 重构了 Sink 架构:
stream.sinkTo(...)查看 Flink 支持的连接器
需要我们自己导入依赖,比如上面的 Kfaka 和 DataGen 我们之前使用的时候都导入过相关依赖,需要知道,有的是只支持source,有的只支持sink,有的全都支持。
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-datagen</artifactId><version>${flink.version}</version></dependency>2、输出到文件
Flink 专门提供了一个流式文件系统的连接器:FileSink,为批处理和流处理提供了一个统一的 Sink,它可以将分区文件写入 Flink支持的文件系统。
它的主要操作是将数据写入桶(buckets),每个桶中的数据都可以分割成一个个大小有限的分区文件,这样一来就实现真正意义上的分布式文件存储。我们可以通过各种配置来控制“分桶”的操作;默认的分桶方式是基于时间的,我们每小时写入一个新的桶。换句话说,每个桶内保存的文件,记录的都是 1 小时的输出数据。
FileSink 支持行编码(Row-encoded)和批量编码(Bulk-encoded,比如 Parquet)格式。这两种不同的方式都有各自的构建器(builder),调用方法也非常简单,可以直接调用 FileSink 的静态方法:
- 行编码:FileSink.forRowFormat(basePath,rowEncoder)。
- 批量编码:FileSink.forBulkFormat(basePath,bulkWriterFactory)。
在创建行或批量编码 Sink 时,我们需要传入两个参数,用来指定存储桶的基本路径(basePath)和数据的编码逻辑(rowEncoder 或 bulkWriterFactory)。
package com.lyh.sink;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.connector.source.util.ratelimit.RateLimiterStrategy;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.datagen.source.DataGeneratorSource;
import org.apache.flink.connector.datagen.source.GeneratorFunction;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.OutputFileConfig;
import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;import java.time.Duration;
import java.time.ZoneId;/*** @author 刘xx* @version 1.0* @date 2023-11-18 9:51*/
public class SinkFile {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);// 必须开启 检查点 不然一直都是 .inprogressenv.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);DataGeneratorSource<String> dataGeneratorSource = new DataGeneratorSource<String>(new GeneratorFunction<Long, String>() {@Overridepublic String map(Long value) throws Exception {return "Number:"+value;}},Long.MAX_VALUE,RateLimiterStrategy.perSecond(10), // 每s 10条Types.STRING);DataStreamSource<String> dataGen = env.fromSource(dataGeneratorSource, WatermarkStrategy.noWatermarks(), "data-generate");// todo 输出到文件系统FileSink<String> fileSink = FileSink.// 泛型方法 需要和输出结果的泛型保持一致<String>forRowFormat(new Path("D:/Desktop"), // 指定输出路径 可以是 hdfs:// 路径new SimpleStringEncoder<>("UTF-8")) // 指定编码.withOutputFileConfig(OutputFileConfig.builder().withPartPrefix("lyh").withPartSuffix(".log").build())// 按照目录分桶 一个小时一个目录(这里的时间格式别改为分钟 会报错: flink Relative path in absolute URI:).withBucketAssigner(new DateTimeBucketAssigner<>("yyyy-MM-dd HH", ZoneId.systemDefault()))// 设置文件滚动策略-时间或者大小 10s 或 1KB 或 5min内没有新数据写入 滚动一次// 滚动的时候 文件就会更名为我们设定的格式(前缀)不再写入.withRollingPolicy(DefaultRollingPolicy.builder().withRolloverInterval(Duration.ofSeconds(10L)) // 10s.withMaxPartSize(new MemorySize(1024)) // 1KB.withInactivityInterval(Duration.ofMinutes(5)) // 5min.build()).build();dataGen.sinkTo(fileSink);env.execute();}
}
这里我们创建了一个简单的文件 Sink,通过.withRollingPolicy()方法指定了一个“滚动策略”。“滚动”的概念在日志文件的写入中经常遇到:因为文件会有内容持续不断地写入,所以我们应该给一个标准,到什么时候就开启新的文件,将之前的内容归档保存。也就是说,上面的代码设置了在以下 3 种情况下,我们就会滚动分区文件:
⚫ 至少包含 10 秒的数据
⚫ 最近 5 分钟没有收到新的数据
⚫ 文件大小已达到 1 KB
通过 withOutputFileConfig()方法指定了输出的文件名前缀和后缀。
需要特别注意的就是一定要开启检查点,否则我们的数据一直都是正在写入的状态(具体原因后面学习到检查点的时候会详细说)。
运行结果:

3、输出到 Kafka
- 需要添加 Kafka 依赖(之前导入过了)
- 启动 Kafka
- 编写示例代码
package com.lyh.sink;import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.kafka.clients.producer.ProducerConfig;/*** @author 刘xx* @version 1.0* @date 2023-11-18 11:20*/
public class SinkKafka {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 如果是 精准一次 必须开启 checkpointenv.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);SingleOutputStreamOperator<String> sensorDS = env.socketTextStream("localhost", 9999);KafkaSink<String> kafkaSink = KafkaSink.<String>builder()// 指定 kafka 的地址和端口.setBootstrapServers("hadoop102:9092,hadoop103:9092,hadoop104:9092")// 指定序列化器 我们是发送方 所以我们是生产者.setRecordSerializer(KafkaRecordSerializationSchema.<String>builder().setTopic("like").setValueSerializationSchema(new SimpleStringSchema()).build())// 写到 kafka 的一致性级别: 精准一次 / 至少一次// 如果是精准一次// 1.必须开启检查点 env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE)// 2.必须设置事务的前缀// 3.必须设置事务的超时时间: 大于 checkpoint间隔 小于 max 15分钟.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE).setTransactionalIdPrefix("lyh-").setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG,10*60*1000+"").build();sensorDS.sinkTo(kafkaSink);env.execute();}
}
启动 kafka 并开启一个消费者:
kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic like
运行结果: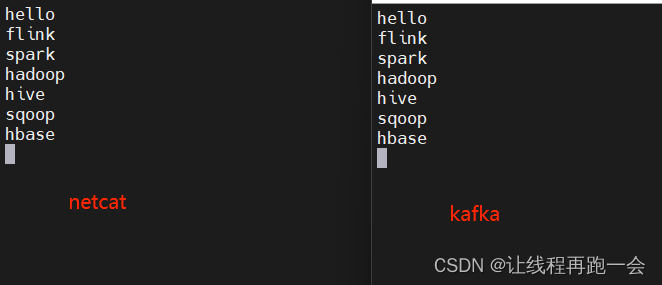
需要特别注意的三点:
如果是精准一次1.必须开启检查点 env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE)2.必须设置事务的前缀3.必须设置事务的超时时间: 大于 checkpoint间隔 小于 max 15分钟
自定义序列化器
我们上面用的自带的序列化器,但是如果我们有 key 的话,就需要自定义序列化器了,替换上面的代码:
.setRecordSerializer(/*** 如果要指定写入 kafka 的key 就需要自定义序列化器* 实现一个接口 重写序列化方法* 指定key 转为 bytes[]* 指定value 转为 bytes[]* 返回一个 ProducerRecord(topic名,key,value)对象*/new KafkaRecordSerializationSchema<String>() {@Nullable@Override// ProducerRecord<byte[], byte[]> 返回一个生产者消息,key,value 分别对应两个字节数组public ProducerRecord<byte[], byte[]> serialize(String element, KafkaSinkContext context, Long timestamp) {String[] datas = element.split(",");byte[] key = datas[0].getBytes(StandardCharsets.UTF_8);byte[] value = element.getBytes(StandardCharsets.UTF_8);return new ProducerRecord<>("like",key,value);}}
)运行结果:
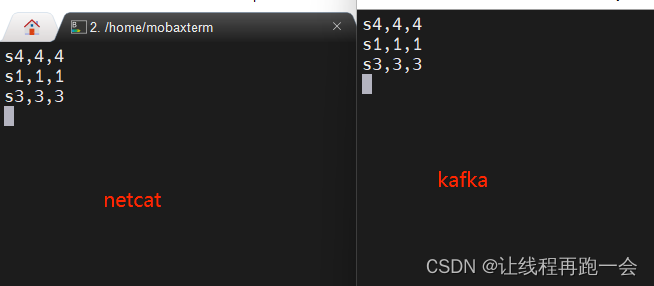
4、输出到 MySQL
添加依赖(1.17版本的依赖需要指定仓库才能找到,因为阿里云和默认的maven仓库是没有的):
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId><version>1.17-SNAPSHOT</version></dependency>
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.31</version></dependency>....<repositories><repository><id>apache-snapshots</id><name>apache snapshots</name><url>https://repository.apache.org/content/repositories/snapshots/</url></repository></repositories>创建表格

编写代码,将输入的数据行分隔为对象参数,每行数据生成一个对象进行处理。
package com.lyh.sink;import com.lyh.bean.WaterSensor;
import function.WaterSensorFunction;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;import java.sql.PreparedStatement;
import java.sql.SQLException;/*** @author 刘xx* @version 1.0* @date 2023-11-18 12:32*/
public class SinkMySQL {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<WaterSensor> sensorDS = env.socketTextStream("localhost", 9999).map(new WaterSensorFunction()); //输入进来的数据自动转为 WaterSensor类型/*** todo 写入 mysql* 1.这里需要用旧的sink写法:addSink* 2.JDBC的4个参数* (1) 执行的sql语句* (2) 对占位符进行填充* (3) 执行选项 -> 攒批,重试* (4) 连接选项 -> driver,username,password,url*/SinkFunction<WaterSensor> jdbcSink = JdbcSink.sink("insert into flink.ws values(?,?,?)",// 指定 sql 中占位符的值new JdbcStatementBuilder<WaterSensor>() {@Overridepublic void accept(PreparedStatement stmt, WaterSensor sensor) throws SQLException {// 占位符从 1 开始stmt.setString(1, sensor.getId());stmt.setLong(2, sensor.getTs());stmt.setInt(3, sensor.getVc());}}, JdbcExecutionOptions.builder().withMaxRetries(3) //最多重试3次(不包括第一次,共4次).withBatchSize(100) //每收集100条记录进行一次写入.withBatchIntervalMs(3000) // 批次3s(即使没有达到100条记录,只要过了3s JDBCSink也会进行记录的写入),这有助于确保数据及时写入,而不是无限期地等待批处理大小达到。.build(), new JdbcConnectionOptions.JdbcConnectionOptionsBuilder().withUrl("jdbc:mysql://localhost:3306/flink?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8").withDriverName("com.mysql.cj.jdbc.Driver").withUsername("root").withPassword("Yan1029.")// mysql 默认8小时不使用连接就主动断开连接.withConnectionCheckTimeoutSeconds(60) // 重试连接直接的间隔,上面我们设置最多重试3次,每次间隔60s.build());sensorDS.addSink(jdbcSink);env.execute();}
}
查询结果: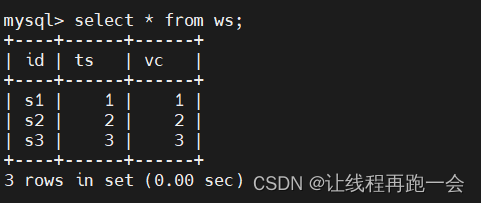
5、自定义 Sink 输出
与 Source 类似,Flink 为我们提供了通用的 SinkFunction 接口和对应的 RichSinkDunction抽象类,只要实现它,通过简单地调用 DataStream 的.addSink()方法就可以自定义写入任何外部存储。
这里我们自定义实现一个向 HBase 中插入数据的 Sink。
注意:这里只是做一个简单的 Demo,下面的代码不难发现,我们只是对 nosq:student 表下的 info:name 进行了两次的覆盖。如果要实现复杂的处理功能,需要对数据类型进行定义,因为 HBase 的数据是按列存储的,所以对于复杂的 Hbase 表,我们难以通过 Java bean 来插入数据。而且,一般经常用的连接器,Flink 大部分已经提供了,开发中我们一般也很少自定义 Sink 输出。
package com.lyh.sink;import com.lyh.utils.HBaseConnection;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;import java.nio.charset.StandardCharsets;/*** @author 刘xx* @version 1.0* @date 2023-11-18 15:59*/
public class SinkCustomHBase {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.fromElements("tom","bob").addSink(new RichSinkFunction<String>() {public Connection con;@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);con = HBaseConnection.getConnection("hadoop102:2181");}@Overridepublic void invoke(String value, Context context) throws Exception {super.invoke(value, context);Table table = con.getTable(TableName.valueOf("nosql","student"));Put put = new Put("1001".getBytes(StandardCharsets.UTF_8));put.addColumn("info".getBytes(StandardCharsets.UTF_8),"name".getBytes(StandardCharsets.UTF_8),value.getBytes(StandardCharsets.UTF_8));table.put(put);table.close();}@Overridepublic void close() throws Exception {super.close();HBaseConnection.close();}});env.execute();}
}
这里用到一个简单的连接 HBase 的工具类:
package com.lyh.utils;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;import java.io.IOException;/*** @author 刘xx* @version 1.0* @date 2023-11-18 16:04*/
public class HBaseConnection {private static Connection connection;public static Connection getConnection(String hosts) throws IOException {Configuration conf = new Configuration();conf.set("hbase.zookeeper.quorum", hosts);conf.setInt("hbase.rpc.timeout", 10000); // 设置最大超时 10 sconnection = ConnectionFactory.createConnection(conf);return connection;}public static void close() throws IOException {if (connection!=null)connection.close();}
}
相关文章:
Flink(七)【输出算子(Sink)】
前言 今天是我写博客的第 200 篇,恍惚间两年过去了,现在已经是大三的学长了。仍然记得两年前第一次写博客的时候,当时学的应该是 Java 语言,菜的一批,写了就删,怕被人看到丢脸。当时就想着自己一年之后&…...

【自我管理】To-do list已过时?学写Done List培养事业成功感
自我管理:已完成清单(doneList)培养事业成功感 待办事项清单常常让人感到压力山大,让人不想面对工作。但是,你知道吗?除了待办清单之外,还有一个叫做「已完成清单」的东西,它可能更符…...

优思学院|什么是精益生产管理?从一个生活上的故事出发来说明。
你关掉电脑,离开办公室。 一个小时后,你进入家门和孩子们在一起。 你和家人一起吃晚饭。 你的老板打电话来查看你的项目进展。 你哄孩子入睡并给他们读个故事。 作为一个负责任的父母,你想要与孩子们的互动时间增加并提高生活的质量&…...

Swagger-----knife4j框架
简介 使得前后端分离开发更加方便,有利于团队协作 接口的文档在线自动生成,降低后端开发人员编写接口文档的负担 功能测试 Spring已经将Swagger纳入自身的标准,建立了Spring-swagger项目,现在叫Springfox。通过在项目中引入Spri…...

企业数字化过程中数据仓库与商业智能的目标
当前环境下,各领域企业通过数字化相关的一切技术,以数据为基础、以用户为核心,创建一种新的,或对现有商业模式进行重塑就是数字化转型。这种数字化转型给企业带来的效果就像是一次重构,会对企业的业务流程、思维文化、…...
协议)
从零开始写一个APM监控程序(一)协议
APM(Application Performance Monitoring)是一种用于监控和管理应用程序性能的解决方案。它通过收集、分析和报告应用程序的性能数据,帮助开发人员和系统管理员更好地了解应用程序的运行状况,识别潜在的性能问题,并进行…...
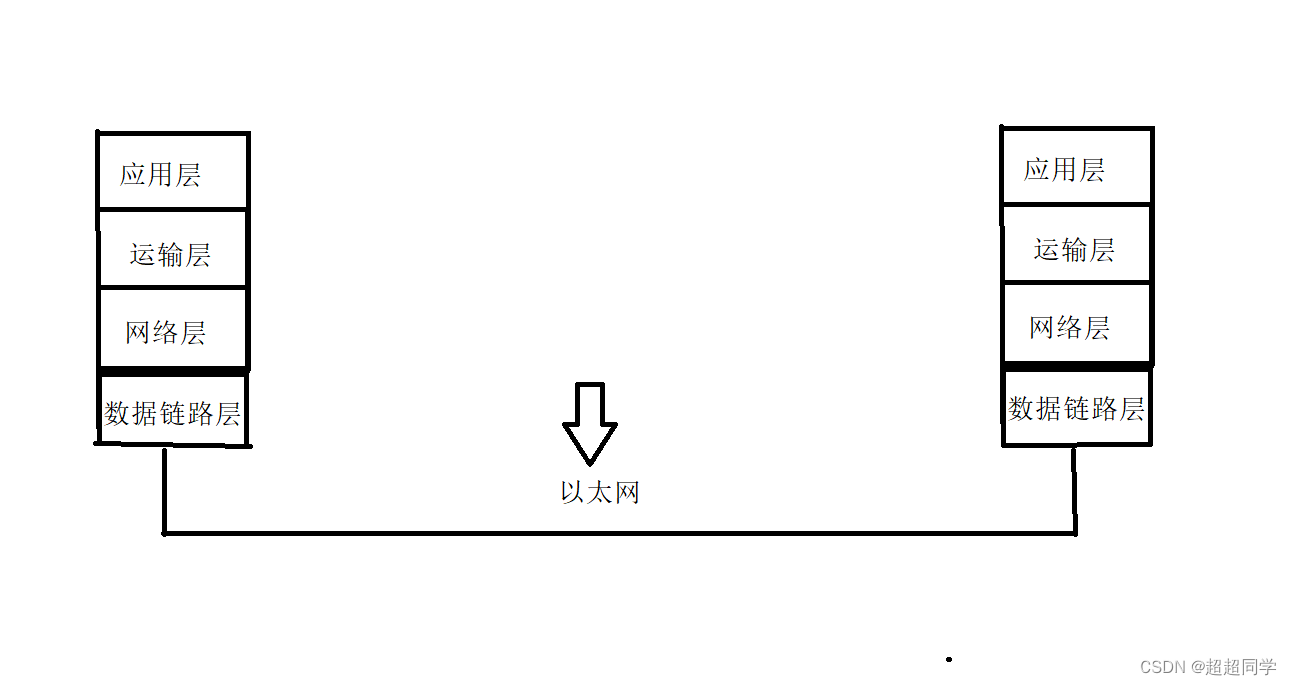
UDP网络套接字编程
先来说说数据在网络上的传输过程吧,我们知道系统其实终究是根据冯诺依曼来构成的,而网络数据是怎么发的呢? 其实很简单,网络有五层。如下: 如上图,我们知道的是,每层对应的操作系统中的那些地方…...
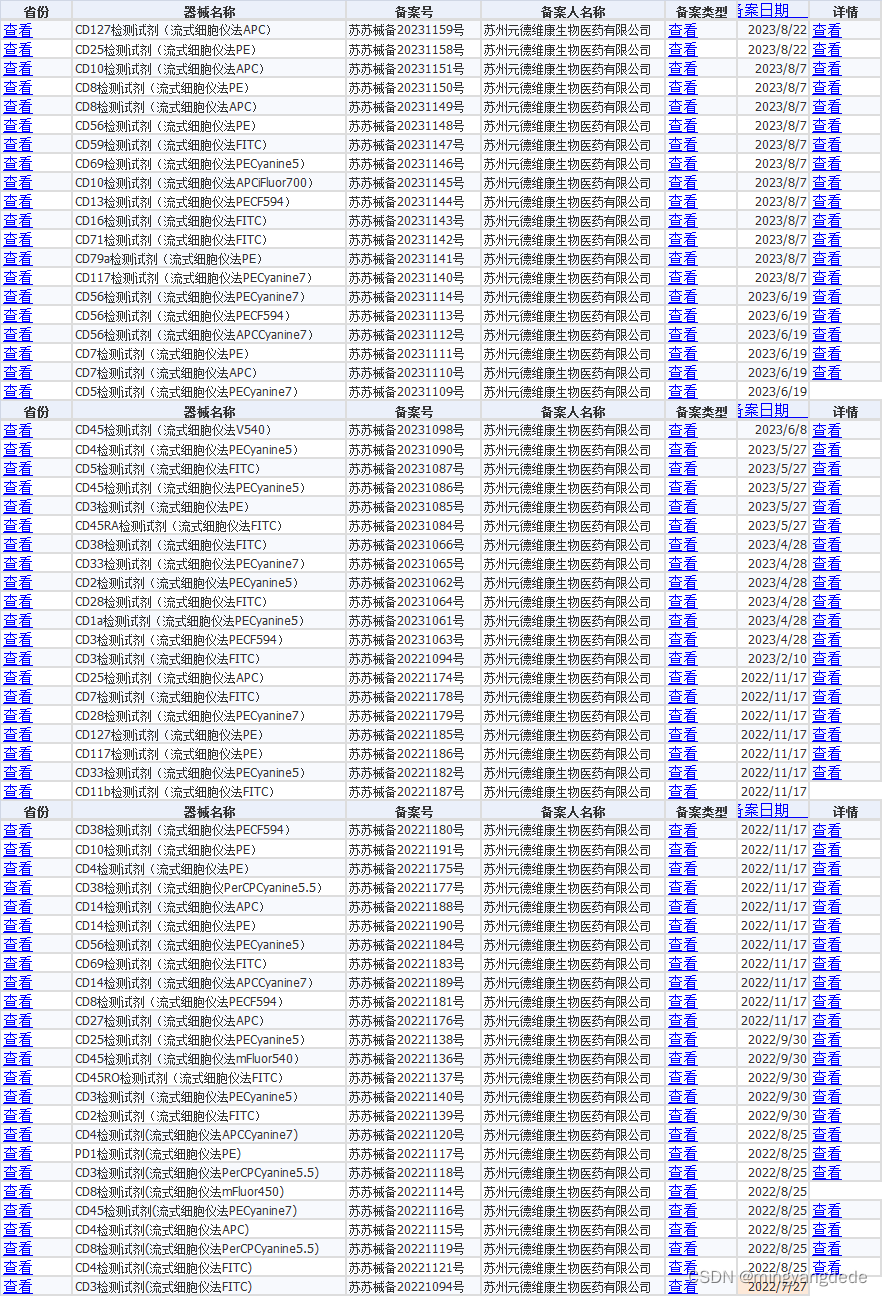
【苏州元德维康生物医药-注册】
...
)
从零带你底层实现unordered_map (1)
💯 博客内容:从零带你实现unordered_map 😀 作 者:陈大大陈 🚀 个人简介:一个正在努力学技术的准C后端工程师,专注基础和实战分享 ,欢迎私信! 💖 欢迎大家…...
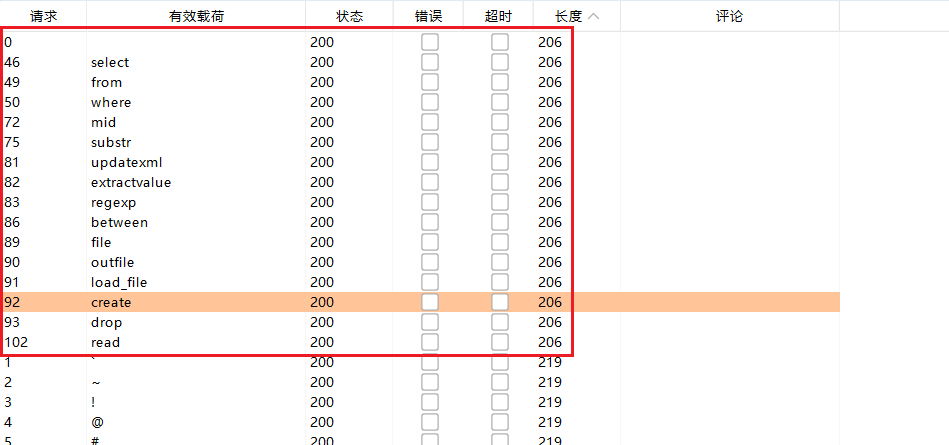
第六届浙江省大学生网络与信息安全竞赛 2023年 初赛/决赛 WEB方向 Writeup
-------------------【初赛】------------------- easy php 简单反序列化 __debuginfo()魔术方法打印所需调试信息,反序列化时候执行! 链子如下: BBB::__debuginfo()->CCC::__toString()->AAA::__call()EXP: <?php…...

设计模式篇---装饰模式
文章目录 概念结构实例总结 概念 装饰模式:动态的给一个对象增加一些额外的职责。就扩展功能而言,装饰模式提供了 一种比使用子类更加灵活的替代方案。 装饰模式是一种对象结构型模式,它以对客户透明的方式动态地给一个对象附加上更多的责任…...

JAXB:根据Java文件生成XML schema文件
说明 JAXB有个schemagen脚本,可以根据Java文件生成XML schema。这个工具在JAXB独立发布包中有,可以从官网下载JAXB的独立发布包: https://eclipse-ee4j.github.io/jaxb-ri/ 示例 使用schemagen -d <path> <java files>格式 …...

opencv(5): 滤波器
滤波的作用:一幅图像通过滤波器得到另一幅图像;其中滤波器又称为卷积核,滤波的过程称为卷积。 锐化:边缘变清晰 低通滤波(Low-pass Filtering): 目标:去除图像中的高频成分&#…...
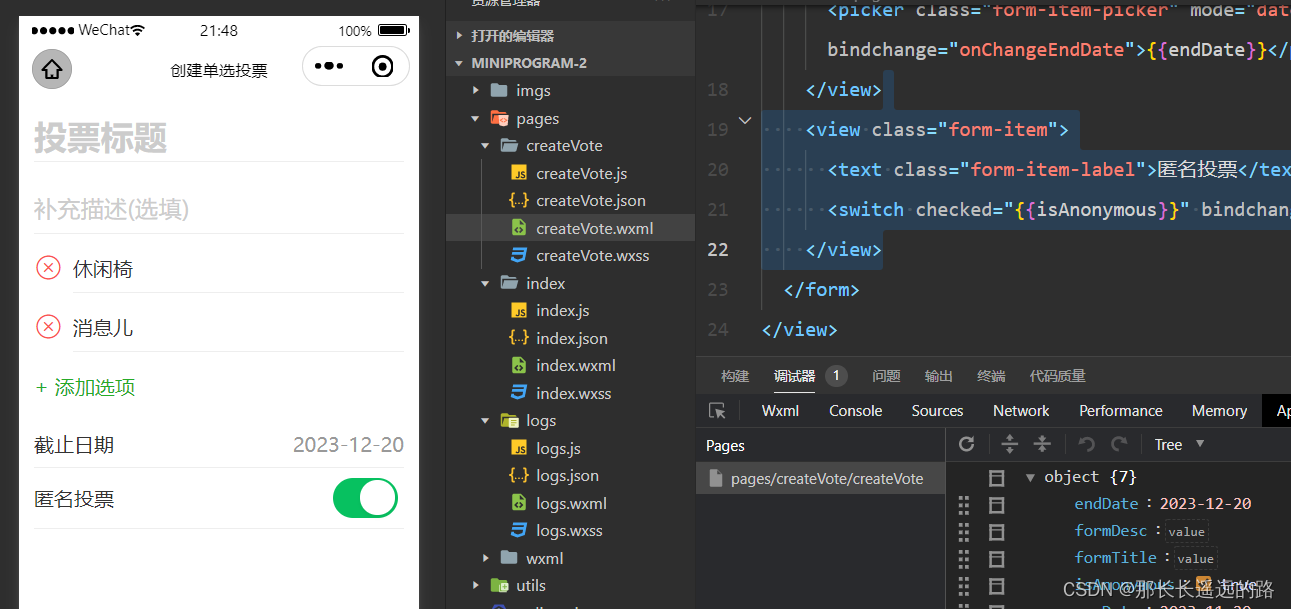
《微信小程序开发从入门到实战》学习二十二
3.3 开发创建投票页面 3.3.10 使用switch开关组件 用switch开关组件增加一个设置是否匿名投票的功能。 switch常用属性如下: checked 开还是关,默认false关 disabled 是否禁用,默认false不禁用࿰…...

LLM模型-讯飞星火与百度文心api调用
spark-wenxin 1-讯飞星火1_1-SparkApi.py1_2- Chat_spark.py1_3-调用api 2-百度文心2_1.code 3-两者之间比较与openai 1-讯飞星火 进入讯飞官网进行创建应用,获取相关密钥APPID,APISecret,APIKey,选择最新版本 首次调用讯飞官方a…...
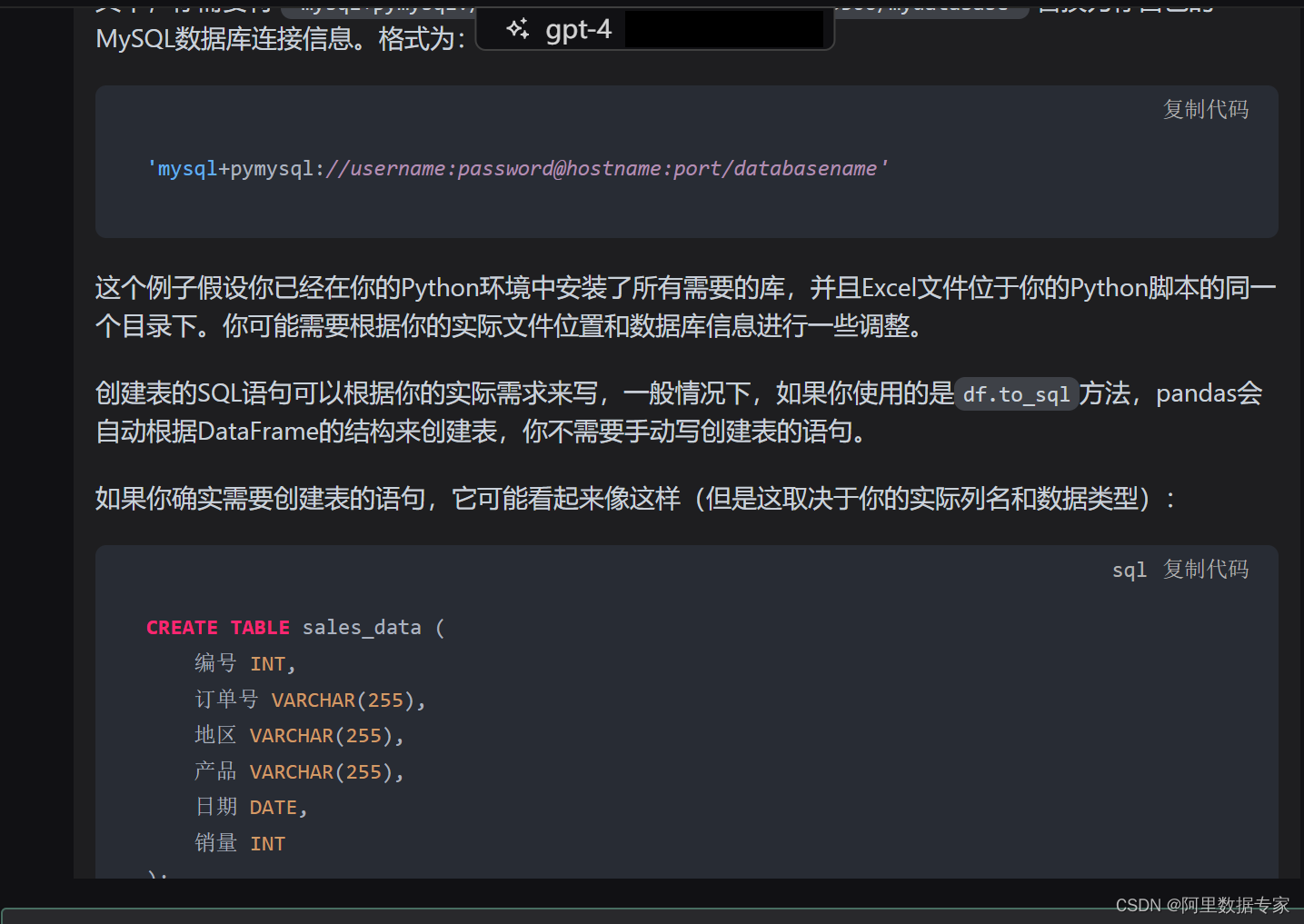
AIGC ChatGPT 4 将数据接口文件使用Python进行入库Mysql
数据分析,数据处理的过程,往往将采集到的数据,或者从生产库过来的接口文件,我们都需要进行入库操作。 如下图数据: 将这样的数据接口文件,进行入库,插入到Mysql数据库中。 用Python代码来完成。 ChatGPT4来完成代码输入。 ChatGPT4完整内容如下: 这个任务可以使用`…...
Loguru:一个超酷的Python库
在项目中,了解代码运行情况至关重要,特别是遇到Bug需要排除问题的时候,而这正是日志记录发挥作用的地方。对于Python开发者来说,Loguru是一个简单但功能强大的日志记录库,它使得跟踪代码的行为变得轻松而高效。 什么是…...

cloud的概念
"Cloud"(云)通常指的是云计算(cloud computing)领域。云计算是一种通过网络(通常是互联网)提供计算资源和服务的模型。这些计算资源包括计算能力、存储空间、数据库、网络、分析能力等。云计算模…...
物联网赋能:WIFI HaLow在无线连接中的优势
在探讨无线网络连接时,我们不难发现,WIFI已经成为我们日常生活中不可或缺的一部分,承载了半数以上的互联网流量,并在家庭、学校、娱乐场所等各种场合广泛应用。然而,尽管WIFI4、WIFI5和WIFI6等协议无处不在,…...
淘宝商品详情数据接口(Taobao.item_get)
淘宝商品详情接口是一种程序化的接口,允许开发者根据商品ID或商品链接,获取淘宝平台上的商品详细信息。通过这个接口,开发者可以方便地获取商品的标题、价格、销量、描述等数据,进而提供给用户进行展示和购买。 使用淘宝商品详情…...

Python爬虫中如何正确配置住宅IP代理?新手避坑指南
很多人买完住宅IP,配置半天还是报错、被封。本文手把手教你用Python正确接入住宅代理,附代码和常见问题解决。一、为什么你的代理配置总失败?常见的几种错误:协议用错:服务商给的SOCKS5,你却按HTTP方式配认…...

Cardboard XR Plugin实战指南:轻量级Android VR落地方案
1. 这不是“加个插件就能跑”的VR接入——为什么Cardboard XR Plugin在2024年仍值得认真对待 很多人看到“Unity Cardboard Android VR”第一反应是:这不早淘汰了吗?毕竟Google早在2019年就停止了Cardboard官方支持,2021年彻底下架了Cardbo…...

终极指南:如何通过开源固件将泉盛UV-K5/K6对讲机性能提升300%
终极指南:如何通过开源固件将泉盛UV-K5/K6对讲机性能提升300% 【免费下载链接】uv-k5-firmware-custom 全功能泉盛UV-K5/K6固件 Quansheng UV-K5/K6 Firmware 项目地址: https://gitcode.com/gh_mirrors/uvk5f/uv-k5-firmware-custom 泉盛UV-K5/K6对讲机开源…...

毕业答辩 PPT 救星!okbiye AI PPT 如何让学术演示稿制作效率提升 10 倍?
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPTAI PPT制作 - Okbiye智能写作https://www.okbiye.com/ppt 毕业季的深夜,多少人对着空白 PPT 文档陷入崩溃:找模板、排大纲、调格式,光是基础框架就要耗上两三天&…...

百考通:AI一键生成期刊论文写作,全流程智能化支撑,让学术创作更高效
在学术研究领域,期刊论文的撰写是成果输出的关键环节,却也让众多科研工作者与学生倍感压力:选题迷茫、逻辑梳理困难、格式规范复杂、内容提炼耗时,严重拖慢了学术成果的发表节奏。百考通(https://www.baikaotongai.com…...

轻松实现颜色与数字的映射:Python 数据处理实战
在数据分析与日常数据处理中,我们经常需要将文本信息转换为数值型数据,尤其在颜色编码、分类标签等场景中尤为常见。 今天,我将分享一个简单实用的 Python 示例,演示如何利用 pandas 库将颜色名称映射为对应的数字,并将…...

终极热键冲突解决方案:Hotkey Detective专业指南
终极热键冲突解决方案:Hotkey Detective专业指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾经在W…...

拆解正点原子STM32F103综合例程:如何用一块MCU实现MP3播放器、NES游戏机和简易手机?
STM32F103多功能系统设计:从MP3播放器到NES游戏机的工程实践 在嵌入式系统开发领域,如何利用有限资源实现复杂功能一直是工程师面临的挑战。正点原子STM32F103战舰开发板的综合例程展示了这款经典MCU的强大潜力——通过精心设计的软件架构,将…...

GRETNA脑网络分析工具包:MATLAB中的图论网络分析终极指南
GRETNA脑网络分析工具包:MATLAB中的图论网络分析终极指南 【免费下载链接】GRETNA A Graph-theoretical Network Analysis Toolkit in MATLAB 项目地址: https://gitcode.com/gh_mirrors/gr/GRETNA GRETNA(Graph-theoretical Network Analysis To…...

肺部X光AI诊断系统:五分类模型实战与临床可解释性
1. 项目概述:当X光片遇上深度学习——一个肺部疾病AI诊断系统的实操手记 我做医疗影像AI项目快七年了,从最早在医院信息科帮放射科老师写脚本批量重命名DICOM文件,到后来带着学生团队在基层医院部署轻量级肺炎筛查工具,踩过的坑比…...