2023年亚太杯数学建模思路 - 案例:感知机原理剖析及实现
文章目录
- 1 感知机的直观理解
- 2 感知机的数学角度
- 3 代码实现
- 4 建模资料
# 0 赛题思路
(赛题出来以后第一时间在CSDN分享)
https://blog.csdn.net/dc_sinor?type=blog
1 感知机的直观理解
感知机应该属于机器学习算法中最简单的一种算法,其原理可以看下图:
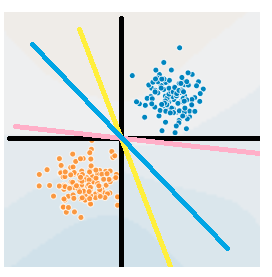
比如说我们有一个坐标轴(图中的黑色线),横的为x1轴,竖的x2轴。图中的每一个点都是由(x1,x2)决定的。如果我们将这张图应用在判断零件是否合格上,x1表示零件长度,x2表示零件质量,坐标轴表示零件的均值长度和均值重量,并且蓝色的为合格产品,黄色为劣质产品,需要剔除。那么很显然如果零件的长度和重量都大于均值,说明这个零件是合格的。也就是在第一象限的所有蓝色点。反之如果两项都小于均值,就是劣质的,比如在第三象限的黄色点。
在预测上很简单,拿到一个新的零件,我们测出它的长度x1,质量x2,如果两项都大于均值,说明零件合格。这就是我们人的人工智能。
那么程序怎么知道长度重量都大于均值的零件就是合格的呢?
或者说
它是怎么学会这个规则的呢?
程序拿到手的是当前图里所有点的信息以及标签,也就是说它知道所有样本x的坐标为(x1, x2),同时它属于蓝色或黄色。对于目前手里的这些点,要是能找到一条直线把它们分开就好了,这样我拿到一个新的零件,知道了它的质量和重量,我就可以判断它在线的哪一侧,就可以知道它可能属于好的或坏的零件了。例如图里的黄、蓝、粉三条线,都可以完美地把当前的两种情况划分开。甚至x1坐标轴或x2坐标轴都能成为一个划分直线(这两个直线均能把所有点正确地分开)。
读者也看到了,对于图中的两堆点,我们有无数条直线可以将其划分开,事实上我们不光要能划分当前的点,当新来的点进来是,也要能很好地将其划分,所以哪条线最好呢?
怎样一条直线属于最佳的划分直线?实际上感知机无法找到一条最佳的直线,它找到的可能是图中所有画出来的线,只要能把所有的点都分开就好了。
得出结论:
如果一条直线能够不分错一个点,那就是一条好的直线
进一步来说:
如果我们把所有分错的点和直线的距离求和,让这段求和的举例最小(最好是0,这样就表示没有分错的点了),这条直线就是我们要找的。
2 感知机的数学角度
首先我们确定一下终极目标:甭管找最佳划分直线啥中间乱七八糟的步骤,反正最后生成一个函数f(x),当我们把新的一个数据x扔进函数以后,它会预测告诉我这是蓝的还是黄的,多简单啊。所以我们不要去考虑中间过程,先把结果定了。
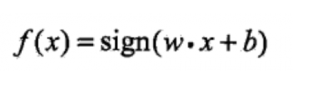
瞧,f(x)不是出来了嘛,sign是啥?wx+b是啥?别着急,我们再看一下sigin函数是什么。
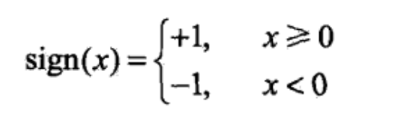
sign好像很简单,当x大于等于0,sign输出1,否则输出-1。那么往前递归一下,wx+b如果大于等于0,f(x)就等于1,反之f(x)等于-1。
那么wx+b是啥?
它就是那条最优的直线。我们把这个公式放在二维情况下看,二维中的直线是这样定义的:y=ax+b。在二维中,w就是a,b还是b。所以wx+b是一条直线(比如说本文最开始那张图中的蓝线)。如果新的点x在蓝线左侧,那么wx+b<0,再经过sign,最后f输出-1,如果在右侧,输出1。等等,好像有点说不通,把情况等价到二维平面中,y=ax+b,只要点在x轴上方,甭管点在线的左侧右侧,最后结果都是大于0啊,这个值得正负跟线有啥关系?emmm….其实wx+b和ax+b表现直线的形式一样,但是又稍有差别。我们把最前头的图逆时针旋转45度,蓝线是不是变成x轴了?哈哈这样是不是原先蓝线的右侧变成了x轴的上方了?其实感知机在计算wx+b这条线的时候,已经在暗地里进行了转换,使得用于划分的直线变成x轴,左右侧分别为x轴的上方和下方,也就成了正和负。
那么,为啥是wx+b,而不叫ax+b?
在本文中使用零件作为例子,上文使用了长度和重量(x1,x2)来表示一个零件的属性,所以一个二维平面就足够,那么如果零件的品质和色泽也有关系呢?那就得加一个x3表示色泽,样本的属性就变成了(x1,x2,x3),变成三维了。wx+b并不是只用于二维情况,在三维这种情况下,仍然可以使用这个公式。所以wx+b与ax+b只是在二维上近似一致,实际上是不同的东西。在三维中wx+b是啥?我们想象屋子里一个角落有蓝点,一个角落有黄点,还用一条直线的话,显然是不够的,需要一个平面!所以在三维中,wx+b是一个平面!至于为什么,后文会详细说明。四维呢?emmm…好像没法描述是个什么东西可以把四维空间分开,但是对于四维来说,应该会存在一个东西像一把刀一样把四维空间切成两半。能切成两半,应该是一个对于四维来说是个平面的东西,就像对于三维来说切割它的是一个二维的平面,二维来说是一个一维的平面。总之四维中wx+b可以表示为一个相对于四维来说是个平面的东西,然后把四维空间一切为二,我们给它取名叫超平面。由此引申,在高维空间中,wx+b是一个划分超平面,这也就是它正式的名字。
正式来说:
wx+b是一个n维空间中的超平面S,其中w是超平面的法向量,b是超平面的截距,这个超平面将特征空间划分成两部分,位于两部分的点分别被分为正负两类,所以,超平面S称为分离超平面。
细节:
w是超平面的法向量:对于一个平面来说w就是这么定义的,是数学知识,可以谷歌补习一下
b是超平面的截距:可以按照二维中的ax+b理解
特征空间:也就是整个n维空间,样本的每个属性都叫一个特征,特征空间的意思是在这个空间中可以找到样本所有的属性组合

我们从最初的要求有个f(x),引申到能只输出1和-1的sign(x),再到现在的wx+b,看起来越来越简单了,只要能找到最合适的wx+b,就能完成感知机的搭建了。前文说过,让误分类的点距离和最大化来找这个超平面,首先我们要放出单独计算一个点与超平面之间距离的公式,这样才能将所有的点的距离公式求出来对不?

先看wx+b,在二维空间中,我们可以认为它是一条直线,同时因为做过转换,整张图旋转后wx+b是x轴,那么所有点到x轴的距离其实就是wx+b的值对不?当然了,考虑到x轴下方的点,得加上绝对值->|wx+b|,求所有误分类点的距离和,也就是求|wx+b|的总和,让它最小化。很简单啊,把w和b等比例缩小就好啦,比如说w改为0.5w,b改为0.5b,线还是那条线,但是值缩小两倍啦!你还不满意?我可以接着缩!缩到0去!所以啊,我们要加点约束,让整个式子除以w的模长。啥意思?就是w不管怎么样,要除以它的单位长度。如果我w和b等比例缩小,那||w||也会等比例缩小,值一动不动,很稳。没有除以模长之前,|wx+b|叫函数间隔,除模长之后叫几何间隔,几何间隔可以认为是物理意义上的实际长度,管你怎么放大缩小,你物理距离就那样,不可能改个数就变。在机器学习中求距离时,通常是使用几何间隔的,否则无法求出解。

对于误分类的数据,例如实际应该属于蓝色的点(线的右侧,y>0),但实际上预测出来是在左侧(wx+b<0),那就是分错了,结果是负,这时候再加个符号,结果就是正了,再除以w的模长,就是单个误分类的点到超平面的举例。举例总和就是所有误分类的点相加。
上图最后说不考虑除以模长,就变成了函数间隔,为什么可以这么做呢?不考虑wb等比例缩小这件事了吗?上文说的是错的吗?
有一种解释是这样说的:感知机是误分类驱动的算法,它的终极目标是没有误分类的点,如果没有误分类的点,总和距离就变成了0,w和b值怎样都没用。所以几何间隔和函数间隔在感知机的应用上没有差别,为了计算简单,使用函数间隔。

以上是损失函数的正式定义,在求得划分超平面的终极目标就是让损失函数最小化,如果是0的话就相当完美了。

感知机使用梯度下降方法求得w和b的最优解,从而得到划分超平面wx+b,关于梯度下降及其中的步长受篇幅所限可以自行谷歌。
3 代码实现
#coding=utf-8
#Author:Dodo
#Date:2018-11-15
#Email:lvtengchao@pku.edu.cn
'''
数据集:Mnist
训练集数量:60000
测试集数量:10000
------------------------------
运行结果:
正确率:81.72%(二分类)
运行时长:78.6s
'''
import numpy as np
import time
def loadData(fileName):'''加载Mnist数据集:param fileName:要加载的数据集路径:return: list形式的数据集及标记'''print('start to read data')# 存放数据及标记的listdataArr = []; labelArr = []# 打开文件fr = open(fileName, 'r')# 将文件按行读取for line in fr.readlines():# 对每一行数据按切割福','进行切割,返回字段列表curLine = line.strip().split(',')# Mnsit有0-9是个标记,由于是二分类任务,所以将>=5的作为1,<5为-1if int(curLine[0]) >= 5:labelArr.append(1)else:labelArr.append(-1)#存放标记#[int(num) for num in curLine[1:]] -> 遍历每一行中除了以第一哥元素(标记)外将所有元素转换成int类型#[int(num)/255 for num in curLine[1:]] -> 将所有数据除255归一化(非必须步骤,可以不归一化)dataArr.append([int(num)/255 for num in curLine[1:]])#返回data和labelreturn dataArr, labelArr
def perceptron(dataArr, labelArr, iter=50):'''感知器训练过程:param dataArr:训练集的数据 (list):param labelArr: 训练集的标签(list):param iter: 迭代次数,默认50:return: 训练好的w和b'''print('start to trans')#将数据转换成矩阵形式(在机器学习中因为通常都是向量的运算,转换称矩阵形式方便运算)#转换后的数据中每一个样本的向量都是横向的dataMat = np.mat(dataArr)#将标签转换成矩阵,之后转置(.T为转置)。#转置是因为在运算中需要单独取label中的某一个元素,如果是1xN的矩阵的话,无法用label[i]的方式读取#对于只有1xN的label可以不转换成矩阵,直接label[i]即可,这里转换是为了格式上的统一labelMat = np.mat(labelArr).T#获取数据矩阵的大小,为m*nm, n = np.shape(dataMat)#创建初始权重w,初始值全为0。#np.shape(dataMat)的返回值为m,n -> np.shape(dataMat)[1])的值即为n,与#样本长度保持一致w = np.zeros((1, np.shape(dataMat)[1]))#初始化偏置b为0b = 0#初始化步长,也就是梯度下降过程中的n,控制梯度下降速率h = 0.0001#进行iter次迭代计算for k in range(iter):#对于每一个样本进行梯度下降#李航书中在2.3.1开头部分使用的梯度下降,是全部样本都算一遍以后,统一#进行一次梯度下降#在2.3.1的后半部分可以看到(例如公式2.6 2.7),求和符号没有了,此时用#的是随机梯度下降,即计算一个样本就针对该样本进行一次梯度下降。#两者的差异各有千秋,但较为常用的是随机梯度下降。for i in range(m):#获取当前样本的向量xi = dataMat[i]#获取当前样本所对应的标签yi = labelMat[i]#判断是否是误分类样本#误分类样本特诊为: -yi(w*xi+b)>=0,详细可参考书中2.2.2小节#在书的公式中写的是>0,实际上如果=0,说明改点在超平面上,也是不正确的if -1 * yi * (w * xi.T + b) >= 0:#对于误分类样本,进行梯度下降,更新w和bw = w + h * yi * xib = b + h * yi#打印训练进度print('Round %d:%d training' % (k, iter))#返回训练完的w、breturn w, b
def test(dataArr, labelArr, w, b):'''测试准确率:param dataArr:测试集:param labelArr: 测试集标签:param w: 训练获得的权重w:param b: 训练获得的偏置b:return: 正确率'''print('start to test')#将数据集转换为矩阵形式方便运算dataMat = np.mat(dataArr)#将label转换为矩阵并转置,详细信息参考上文perceptron中#对于这部分的解说labelMat = np.mat(labelArr).T#获取测试数据集矩阵的大小m, n = np.shape(dataMat)#错误样本数计数errorCnt = 0#遍历所有测试样本for i in range(m):#获得单个样本向量xi = dataMat[i]#获得该样本标记yi = labelMat[i]#获得运算结果result = -1 * yi * (w * xi.T + b)#如果-yi(w*xi+b)>=0,说明该样本被误分类,错误样本数加一if result >= 0: errorCnt += 1#正确率 = 1 - (样本分类错误数 / 样本总数)accruRate = 1 - (errorCnt / m)#返回正确率return accruRate
if __name__ == '__main__':#获取当前时间#在文末同样获取当前时间,两时间差即为程序运行时间start = time.time()#获取训练集及标签trainData, trainLabel = loadData('../Mnist/mnist_train.csv')#获取测试集及标签testData, testLabel = loadData('../Mnist/mnist_test.csv')#训练获得权重w, b = perceptron(trainData, trainLabel, iter = 30)#进行测试,获得正确率accruRate = test(testData, testLabel, w, b)#获取当前时间,作为结束时间end = time.time()#显示正确率print('accuracy rate is:', accruRate)#显示用时时长print('time span:', end - start)
4 建模资料
资料分享: 最强建模资料


相关文章:
2023年亚太杯数学建模思路 - 案例:感知机原理剖析及实现
文章目录 1 感知机的直观理解2 感知机的数学角度3 代码实现 4 建模资料 # 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 感知机的直观理解 感知机应该属于机器学习算法中最简单的一种算法,其…...

linux高级篇基础理论五(用户安全,口令设置,JR暴力破解用户密码,NMAP端口扫描)
♥️作者:小刘在C站 ♥️个人主页: 小刘主页 ♥️不能因为人生的道路坎坷,就使自己的身躯变得弯曲;不能因为生活的历程漫长,就使求索的 脚步迟缓。 ♥️学习两年总结出的运维经验,以及思科模拟器全套网络实验教程。专栏:云计算技…...

鸿蒙原生应用/元服务开发-AGC分发如何配置版本信息(上)
1.配置HarmonyOS应用的“发布国家或地区”。 2.设置是否为开放式测试版本。 注意:HarmonyOS应用开放式测试当前仅支持手机、平板、智能手表。如开发者想发布为开放式测试版本,选择“是”。正式发布的版本请选择“否”。 3.在“软件版本”下点击“软件包…...
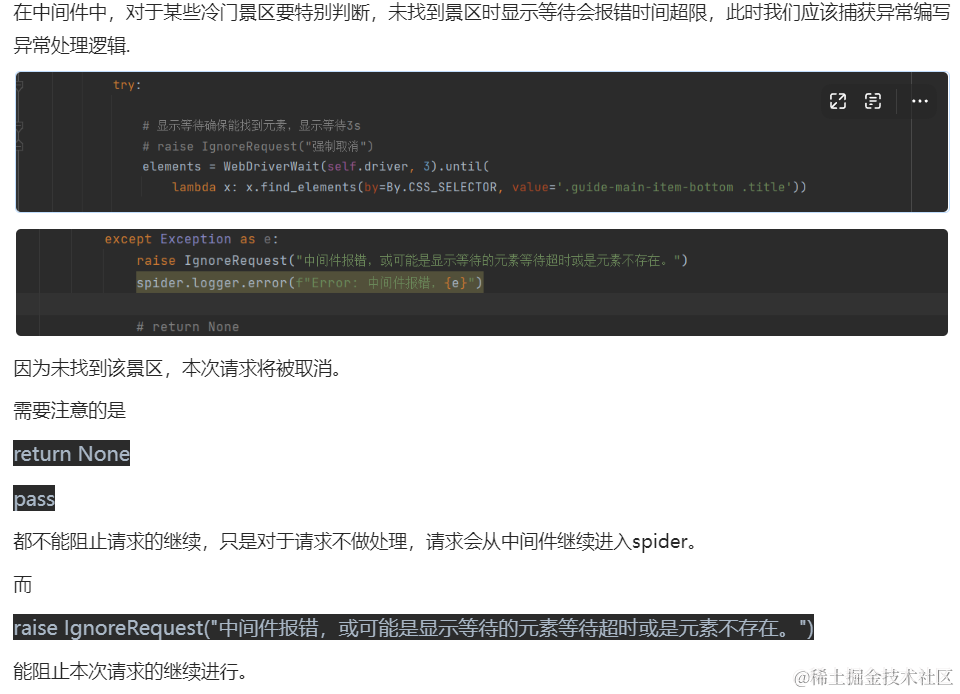
探索Scrapy中间件:自定义Selenium中间件实例解析
简介 Scrapy是一个强大的Python爬虫框架,可用于从网站上抓取数据。本教程将指导你创建自己的Scrapy爬虫。其中,中间件是其重要特性之一,允许开发者在爬取过程中拦截和处理请求与响应,实现个性化的爬虫行为。 本篇博客将深入探讨…...

渗透测试--3.中间人攻击
渗透测试--3.中间人攻击 一 .中间人攻击arp欺骗DNS欺骗无线局域网漏洞利用使用 Ettercap 执行欺骗攻击arp欺骗实例1、首先查看欺骗之前靶机ip以及默认网关,2、查看kali的IP地址(192.168.76.134),MAC:000c294079903、使用Ettercap,将A主机和B主机加入到target中4、点击右上…...

nginx/html关闭网页缓存方法
【问题】 通常代理服务器默认是有缓存的,即用户访问网址的时候默认获取到的是缓存,只有刷新之后才能得到服务器端的最新文件 【解决】 以nginx为例,找到配置文件nginx.conf,找到http {},在其花括号之内添加命令&…...
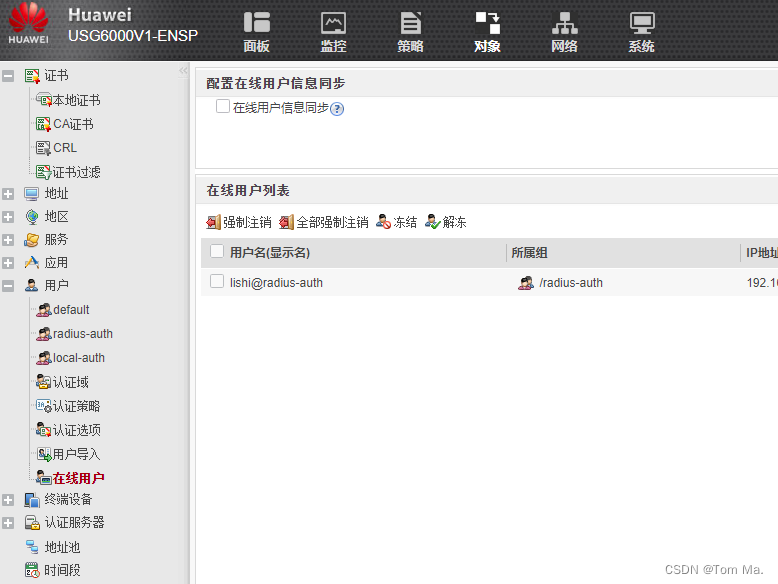
华为防火墙 Radius认证
实现的功能:本地内网用户上网时必须要进行Radius验证,通过后才能上网 前置工作请按这个配置:华为防火墙 DMZ 设置-CSDN博客 Windows 服务器安装 Radius 实现上网认证 拓扑图如下: 一、服务器配置 WinRadius 1、安装WinRadius …...
用spring发送http请求
在Spring中,你可以使用RestTemplate或WebClient来发送HTTP请求。下面分别给出使用这两个类的简单示例。 现在pom.xml中导入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artif…...

赴日开发工程师是做什么的?
日本的软件开发岗位对技术要求和沟通能力都有较高的要求,赴日开发工程师主要负责软件设计、开发和测试,包括编写代码、测试代码和修复漏洞等工作。开发人员必须对软件架构、设计模式和业务逻辑有深入的理解,并能做出合适的技术决策。 当然&a…...
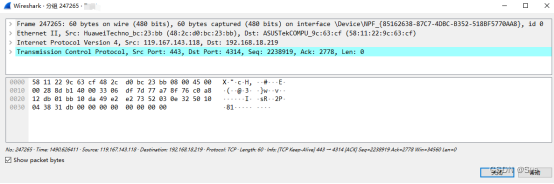
Wireshark的数据包它来啦!
通过Wireshark工具,可以轻松的看到网卡的数据信息。通过Wireshark显示的数据包内容信息,通常分七栏,介绍一下: 1No.: 数据包编号。 2.Time Time显示时间,以1号数据包发生开始计时。 3.Source Source显示内容…...

接口测试需要验证数据库么?
有的接口会返回很多数据,有的接口可能就返回一个状态码及success之类的消息,这些需要验证数据库么?现在在写一个测试框架,配置接口参数和预期返回值,生成xml文件管理用例,用一个比较方法对预期和返回作比较…...

配置 `PostgreSQL` 与 `Keepalived` 以实现高可用性
配置 PostgreSQL 与 Keepalived 以实现高可用性通常包括以下步骤: PostgreSQL 配置 安装 PostgreSQL:在两台服务器上安装相同版本的 PostgreSQL。 sudo yum install postgresql-server postgresql-contrib初始化数据库:在两台服务器上初始化…...

C++: int转换成LPCSTR
LPCSTR类型是指向字符常量的指针,因此需要将int类型转换为字符串类型,然后再将字符串类型转换为LPCSTR类型。 以下是一个示例代码: int num 123; char str[10]; sprintf(str, "%d", num); // 将int类型转换为字符串类型 LPCSTR …...

kettle官网和中文网地址
整理的kettle相关的网站地址: github 地址: https://github.com/pentaho/pentaho-kettle kettle下载目录: https://sourceforge/projects/pentaho/files/ kettle9.2下载地址: https://sourceforge/projects/pentaho/files/Penta…...
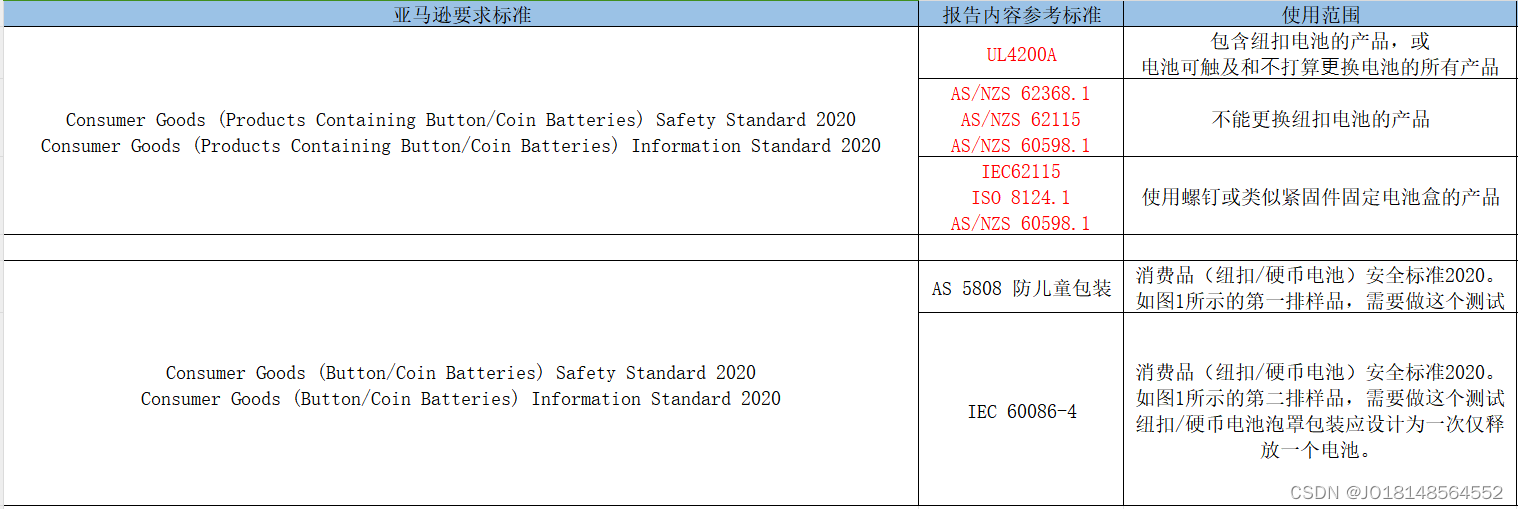
纽扣电池类产品上架亚马逊澳大利站认证标准要求AS/NZS 62368
纽扣电池一般来说常见的有充电的和不充电的两种, 充电的包括3.6V可充锂离子扣式电池(LIR系列),3V可充锂离子扣式电池(ML或VL系列);不充电的包括3V锂锰扣式电池(CR系列)及1.5V碱性锌锰扣式电池(LR及SR系列)。 澳大利亚*已经发布了经批准的《消…...

网站监控的重要性及实施策略
随着互联网的快速发展,网站已经成为企业和个人不可或缺的在线服务平台。然而,网站的安全性和稳定性一直是企业及个人非常关注的问题。一旦网站出现故障或者被攻击,将会给企业和个人带来严重的损失。因此,实施有效的网站监控策略对…...

亚马逊车灯外贸出口CE认证标准办理解析
车灯是车辆夜间行驶在道路照明的工具,也是发出各种车辆行驶信号的提示工具。车灯一般分为前照灯、尾灯、转向灯等。车灯出口欧盟需要办理CE认证。 CE认证是欧盟对进入欧洲市场的产品强制性的认证标志,是指符合欧盟安全、健康、环境保护等标准和要求的产…...
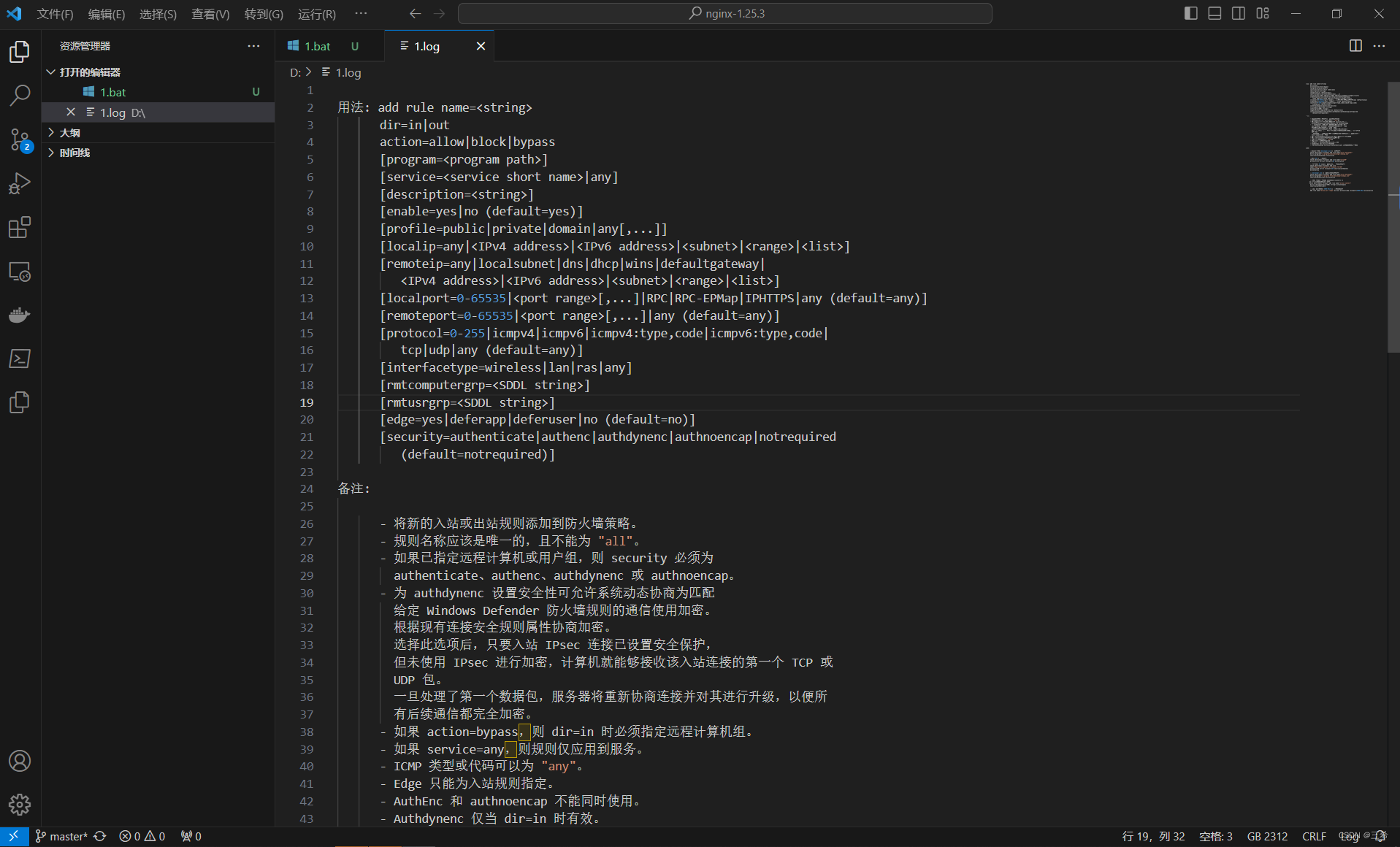
windows 查看防火墙设置命令使用方法
点击键盘上windows键,输入cmd,选择以管理员身份运行 输入下面命令查看使用说明 netsh advfirewall firewall add rule ? 发现显示不全,不方便看 可以输入下面命令,生成文件,方便查看 netsh advfirewall firewall ad…...
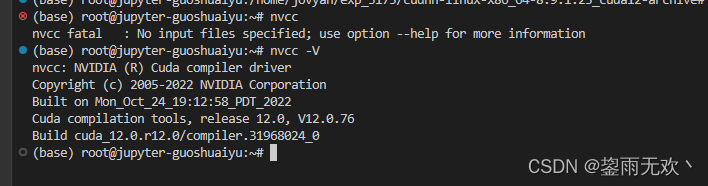
[Linux版本Debian系统]安装cuda 和对应的cudnn以cuda 12.0为例
写在前面 先检查自己有没有安装使用wget的命令,没有的话输入下面命令安装: apt-get install wget -y查看gcc的安装 sudo apt install gcc #安装gcc gcc --version #查看gcc是否安装成功 #若上述命令不成功使用下面的命令尝试之后再执行上面…...

NextJS开发:解决React Hook useEffect has a missing dependency
NextJS编译出现如下错误,原因是在使用useEffect时,当我们将函数的声明放在useEffect函数外面时 或者使用useState定义的历史变量,会报警告 Warning: React Hook useEffect has a missing dependency解决方法: 1、逐个添加注释忽略警告 useEffect(() &…...

【卷卷观察】菲尔兹奖得主亲测GPT-5.5 Pro:一小时产出博士级数学研究,我开始慌了
Tim Gowers,菲尔兹奖得主、剑桥数学教授,用了不到一小时让ChatGPT 5.5 Pro产出了一项博士级数学成果。全程没提供任何数学输入,纯旁观。他对这件事的结论是:培养数学博士的方式可能要变了。这话从一个菲尔兹奖得主嘴里说出来&…...

终极跨平台体验:如何在Windows上实现macOS三指拖动的高效解决方案?
终极跨平台体验:如何在Windows上实现macOS三指拖动的高效解决方案? 【免费下载链接】ThreeFingersDragOnWindows Enables macOS-style three-finger dragging functionality on Windows Precision touchpads. 项目地址: https://gitcode.com/gh_mirror…...

基于MCP协议与Google Docs API实现AI自动化文档编辑
1. 项目概述:当AI助手学会直接操作你的Google文档 如果你和我一样,日常工作中大量使用Google Docs来撰写技术文档、会议纪要或者项目计划,同时又频繁地与Claude、Cursor这类AI助手打交道,那你可能也遇到过这样的痛点:…...
)
别再让无人机‘炸机’了!手把手教你用BB响设置3.6V安全报警值(附常见误区)
无人机电池安全守护者:BB响3.6V报警值设置全攻略 户外飞行时最令人心惊的瞬间莫过于无人机突然断电坠落——这种被称为"炸机"的意外,往往源于对电池电压的误判。而一个售价不足20元的小工具BB响,却能成为你飞行安全的最后防线。本文…...

易语言多线程下如何安全调用大漠插件?免注册方案与资源管理避坑指南
易语言多线程环境下安全调用大漠插件的工程实践 在自动化工具开发领域,大漠插件因其强大的图像识别和模拟操作能力而广受欢迎。但当我们将这一利器应用于易语言多线程环境时,往往会遇到DLL加载冲突、对象生命周期管理混乱以及线程安全性等棘手问题。本文…...

BetterGI原神自动化助手完整指南:从零开始掌握智能游戏辅助
BetterGI原神自动化助手完整指南:从零开始掌握智能游戏辅助 【免费下载链接】better-genshin-impact 📦BetterGI 更好的原神 - 自动拾取 | 自动剧情 | 全自动钓鱼(AI) | 全自动七圣召唤 | 自动伐木 | 自动刷本 | 自动采集/挖矿/锄地 | 一条龙 | 全连音游…...

Blender 3MF插件完整指南:如何在Blender中直接处理3D打印文件
Blender 3MF插件完整指南:如何在Blender中直接处理3D打印文件 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 你是否厌倦了在Blender和3D打印软件之间来回切换…...

当‘感觉’驱动开发,安全与可控谁来兜底?—— Vibe Coding 时代的生存法则
当‘感觉’驱动开发,安全与可控谁来兜底?—— Vibe Coding 时代的生存法则 2025 年初,Andrej Karpathy 用一条推文引爆了开发者社区:“有一种全新的编程方式,我称之为‘vibe coding’。你完全顺应感觉,拥抱…...

如何删除三星手机和平板电脑上的应用程序
你有这样的经历吗?您可能一时兴起在 Samsung Galaxy 上安装了一些软件,但后来发现它没有用或不合适。或者,您最近安装的应用程序不断弹出广告、提醒或频繁刷新背景。不用担心。您可以卸载这些程序以保证您的手机安全。但你是否觉得将软件一一…...

大模型架构拆解:从零件到整体,带你秒懂重复的精密艺术
本文通过拆解大模型架构,阐述了其重复但精密的结构特点。核心内容分为输入层、核心层和输出层三部分,其中核心层由N个标准模块重复堆叠构成,每个模块包含自注意力模块和MLP前馈网络,负责理解语言关系和深化语义。文章强调理解整体…...