redis的性能管理和雪崩
redis的性能管理
redis的数据是缓存在内存当中的
系统巡检:
硬件巡检、数据库、nginx、redis、docker、k8s
运维人员必须要关注的redis指标
在日常巡检中需要经常查看这些指标使用情况
info memory
#查看redis使用内存的指标
used_memory:11285512
#数据占用的内存(单位是字节)
used_memory_rss:24285184
#向操作系统申请的内存(单位是字节)
used_memory_peak:23952088
#redis使用内存的峰值(单位是字节)内存碎片率:used_mem0ry_rss/used_memory
#系统已经分配给了redis,但是未能够有效利用的内存如何查看内存碎片率?
内存碎片率:used_mem0ry_rss/used_memory
#系统已经分配给了redis,但是未能够有效利用的内存redis-cli info memory | grep ratio
#查看内存碎片率allocator_frag_ratio:1.03
#分配器碎片比例。由redis主进程调度时产生的内存,比例越小越好,值越高,内存浪费越多。
allocator_rss_ratio:1.80
#表示分配器占用物理内存的比例,主进程调度过程中占用了多少物理内存
rss_overhead_ratio:1.13
#RSS是向系统申请的内存空间,redis占用物理空间额外的开销比例。比例越低越好。redis实际占用的物理内存和向系统申请的内存越接近额外的开销就越低
mem_fragmentation_ratio:2.16
#内存碎片的比例。值越低越好。表示内存的使用率越高如何来进行清理碎片?
自动清理碎片
vim /etc/redis/6379.conf
最后一行插入
activedefrag yes
#自动清理碎片
/etc/init.d/redis_6379.conf restart
#重启redis服务手动清理碎片
redis-cli memory purge
#手动清理碎片设置redis的最大内存阈值
vim /etc/redis/6379.conf
567行
maxmemory 1gb
#一旦到达阈值会开始自动清理,开启key的回收机制key的回收机制是什么?
就是回收键值对
key回收的策略
vim /etc/redis/6379.conf598行
maxmemory-policy volatile-lru
#使用redis内置的LRU算法。把已经设置了过期时间的键值对淘汰出去。移除最近最少使用的键值对(只是针对已经设置了过期时间的键值对)maxmemory-policy volatile-ttl
#在已经设置了过期时间的键值对中,挑选一个即将过期的键值对(针对的是有设置生命周期的键值对)。maxmemory-policy volatile-random
#在已经设置了过期时间的键值对中,挑选数据然后随机淘汰一个键值对(对设置了过期时间的键值对进行随机移除)allkeys-lru
#根据redis内置的lru算法,对所有的键值对进行淘汰。移除最少使用的键值对。(针对所有的键值对)allkeys-random
#在所有键值对中,任意选择数据进行淘汰maxmemory-policy noeviction
#禁止对键值对回收(不删除任何键值对,知道redis把内存塞满,写不下,报错为止)工作用要么保证数据完整性使用maxmemory-policy noeviction 要么使用maxmemory-policy volatile-ttl挑选一个即将过期的键值对清除
在工作当中一定要给redis占用内存设置阈值否则会将整个系统内存占满为止
redis的雪崩
缓存雪崩:大量的应用请求无法在redis缓存当中处理,请求会全部发送到后台数据库。数据库并发能力并发能力本身就差,数据库会很快崩溃
什么情况可能会导致雪崩出现?
1、 redis集群大面积故障
2、 redis缓存中,大量数据同时过期,大量的请求无法得到处理
3、 redis实例宕机
防止雪崩出现的方法
事前:高可用架构,防止整个缓存故障。主从复制和哨兵模式、redis集群
事中:在国内用得较多的方式:HySTRIX有三种方式:熔断、降级、限流。可以使用这三个手段来降低雪崩发生之后的损失。确保数据库不死即可,慢可以,但是不能没有响应。
事后:redis数据备份的方式来恢复数据或使用快速缓存预热的方式
redis的缓存击穿
缓存击穿主要是热点数据缓存过期或者被删除,多个请求并发访问热点数据。请求也是转发到后台数据库了,导致数据库的性能快速下降。
经常被请求的缓存数据最好设置为永不过期
redis缓存穿透
缓存中没有数据,数据库中也没有对应数据,但是有用户一直发起这个没有的请求,而且请求的数据格式很大。
可能是黑客在利用漏洞攻击,压垮应用数据库。
redis的集群架构
高可用方案:
1、 持久化
2、 高可用:主从复制、哨兵模式、集群
主从复制
主从复制是redis实现高可用的基础,哨兵模式和集群都是在主从复制的基础上实现高可用。
主从复制实现数据的多机备份,以及读写分离(主服务器负责写,从服务器只能读)
缺陷:故障无法自动恢复,需要人工干预。无法实现写操作的负载均衡
主从复制的工作原理
1、 主节点(master)和从节点(slave)组成。数据的复制时单项的,只能从主节点到从节点。
主从复制节点最少要有三台
主从复制的数据流向和工作流程图:
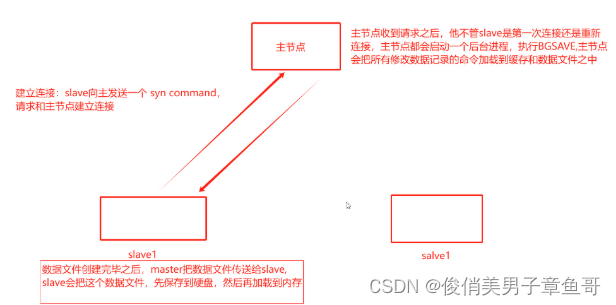
1、 从与主建立连接。从会发送一个syn command,请求和主建立连接
2、 主节点收到请求之后,不管slave是第一次连接还是重新连接。主节点都会启动一个后台进程。执行BGsave。
3、 主节点会把所有修改数据记录的命令也加载到缓存和数据文件之中。
4、 数据文件创建完毕之后,是由主系欸但把数据文件传送给从节点,从节点会把数据文件保存到硬盘当中后再加载到内存中去。
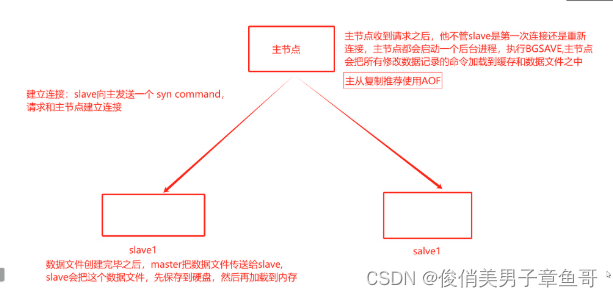
主从复制推荐使用AOF,通过AOF文件实现实时持久化,主从节点都开启AOF持久化服务。从节点同步的就是aof文件。
主从复制工作流程图:
主从复制实验
实验准备:
20.0.0.26 master
20.0.0.27 slave1
20.0.0.28 slave2
三台机器都需要安装redis服务做完后拍个快照systemctl stop firewalld
setenforce 0
#关闭三台机器的防火墙和安全机制主节点:
vim /etc/redis/6379.conf
修改网段 0.0.0.0
daemonize yes
700行
开启aof模式
/etc/init.d/redis_6379 restart从节点1:
vim /etc/redis/6379.conf
修改网段 0.0.0.0
288行
replicaof <masterip> <masterport>
replicaof 20.0.0.26 6379
#指向主的ip和端口
700行
开启aof模式
/etc/init.d/redis_6379 restart
开启了指向后从节点将变为只读模式从节点2:
vim /etc/redis/6379.conf
修改网段 0.0.0.0
288行
replicaof <masterip> <masterport>
replicaof 20.0.0.26 6379
#指向主的ip和端口
700行
开启aof模式
/etc/init.d/redis_6379 restart
开启了指向后从节点将变为只读模式主节点:
tail -f /var/log/redis_6379.log
#查看主节点日志,看是否指向成功验证效果:
主从都登录redis
主节点:
set test1 1
#创建一个键值对
主上创建成功后到两台从节点查看一下看是否可以查看到从节点:
set test2 2
#在从节点上测试是否为只读模式
报错,说明搭建成功从节点已经设置为只读模式了实验完成!redis-cli info replication
#查看主从配置信息停止一个从节点来测试。停机期间插入的数据,服务重启后依旧可以同步哨兵模式
哨兵模式依赖于主从模式,先有主从再有哨兵
哨兵模式是在主从复制的基础上实现主节点故障的自动切换
哨兵模式的工作原理
哨兵:是一个分布式系统。部署在每一个redis节点上用于在主从结构之间对每台redis的服务进行监控。
哨兵模式的投票机制
主节点出现故障时,从节点通过投票的方式选择一个新的master
哨兵模式也需要至少三个节点
哨兵模式的结构
哨兵节点和数据节点
哨兵节点:监控,不存储数据
数据节点:主节点和从节点,都是数据节点
哨兵模式的工作机制
哨兵模式的架构和工作机制图:
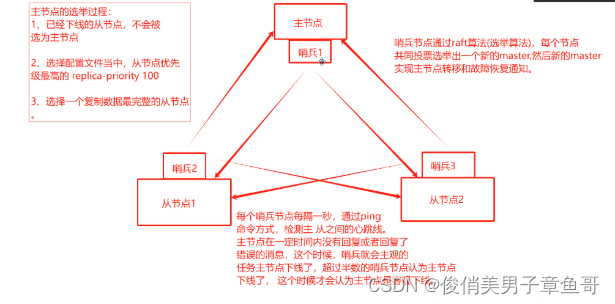
哨兵1节点会对应监控从节点1和从节点2
哨兵2节点会对应监控主节点和从节点2
哨兵3节点会监控主节点和从节点1
哨兵节点会互相监控架构内的其他节点主机
哨兵模式的投票机制:
1、 每个哨兵节点每隔1秒,通过ping命令的方式检测主从之间的心跳线。
2、 当主节点在一定时间内没有回复或者回复了错误的信息。哨兵会主观的认为主节点下线了。
3、 当有超过半数的哨兵节点认为主节点下线了,才会认为主节点是客观下线了
主节点选举过程:
哨兵节点会通过redis自带的raft算法(选举算法),每个节点共同投票,选举出一个新的master。
新的master来实现主节点的转移和故障恢复通知
1、 已经下线的从节点,不会被选择为主节点
2、 选择配置文件当中,从节点优先级最高的 replica-priority 100
3、 选择一个复制数据最完整的从节点
哨兵模式监控的是节点不是哨兵
故障恢复可能会优点延迟
最好是以复制数据最完整的从节点作为新的主节点
哨兵模式实验
主节点:
cd redis-5.0.7
vim sentinel.conf
#哨兵模式的配置文件17行
protected-mode no
#解除注释daemonize yes
#开启后台运行逃兵模式36行
logfile "/var/log/sentinel.log"
#指定日志文件的存放位置65行
dir"/var/lib/redis/6379"
#指定数据库存放的位置85行
sentinel monitor mymaster 20.0.0.26 6379 2
#声明主节点的IP和端口号.2代表至少要有2台服务认为主已经下线才会进行主从切换。一般配置为主从服务器的一半113行
sentinel down-after-milliseconds mymaster 30000
#服务器宕机的最小时间。单位是毫秒。30秒之内如果主节点但没有响应,主观认为主下线了。时间可以改可以自定义146行
sentinel failover-timeout mymaster 180000
#服务器宕机的最大时间,180秒之内如果主节点但没有响应,从节点开始投票,客观认为主下线了。时间可以改可以自定义两台从节点配置和主节点配置一致即可三台配置完成后需要先起主节点再起从节点三台主机在redis的源码包中启动哨兵模式
redis-sentinel sentinel.conf &
#启动哨兵模式。&表示后台运行主节点:
redis-cli -p 26379 info Sentinel
#查看整个集群的哨兵情况查看主从信息:
tail -f /var/log/redis_6379.log
#查看主节点日志,查看主从信息模拟故障切换:
可能会有延迟不是立刻切换
ps-elf | grep redis
#查看主节点
kill -9 redis的主进程或者/etc/init.d/redis_6379 stop停止redis都可以测试测试新主是否可以正常插入数据
测试两从是否可以数据同步
测试旧主机是否还有插入数据旧主失去写的功能,新主增加写的功能。从2的配置文件指向了新的主
而旧主的配置文件中指向自己的配置将会消失小模式用哨兵,大模式用集群
总结
运维人员日常巡检中关注的指标
#查看redis使用内存的指标
used_memory:11285512
#数据占用的内存(单位是字节)
used_memory_rss:24285184
#向操作系统申请的内存(单位是字节)
used_memory_peak:23952088
#redis使用内存的峰值(单位是字节)
内存碎片:
内存碎片率:used_mem0ry_rss/used_memory
#系统已经分配给了redis,但是未能够有效利用的内存redis-cli info memory | grep ratio
#查看内存碎片率allocator_frag_ratio:1.03
#分配器碎片比例。由redis主进程调度时产生的内存,比例越小越好,值越高,内存浪费越多。
allocator_rss_ratio:1.80
#表示分配器占用物理内存的比例,主进程调度过程中占用了多少物理内存
rss_overhead_ratio:1.13
#RSS是向系统申请的内存空间,redis占用物理空间额外的开销比例。比例越低越好。redis实际占用的物理内存和向系统申请的内存越接近额外的开销就越低
mem_fragmentation_ratio:2.16
#内存碎片的比例。值越低越好。表示内存的使用率越高如何清理碎片:
自动清理碎片
vim /etc/redis/6379.conf
最后一行插入
activedefrag yes
#自动清理碎片
/etc/init.d/redis_6379.conf restart
#重启redis服务手动清理碎片
redis-cli memory purge
#手动清理碎片如何设置阈值:
vim /etc/redis/6379.conf567行maxmemory 1gb
#一旦到达阈值会开始自动清理,开启key的回收机制工作用要么保证数据完整性使用maxmemory-policy noeviction 要么使用maxmemory-policy volatile-ttl挑选一个即将过期的键值对清除
在工作当中一定要给redis占用内存设置阈值否则会将整个系统内存占满为止
redis的缓存击穿:
缓存击穿主要是热点数据缓存过期或者被删除,多个请求并发访问热点数据。请求也是转发到后台数据库了,导致数据库的性能快速下降。
经常被请求的缓存数据最好设置为永不过期
主从复制:
主从复制是redis实现高可用的基础,哨兵模式和集群都是在主从复制的基础上实现高可用。
主从复制实现数据的多机备份,以及读写分离(主服务器负责写,从服务器只能读)
缺陷:故障无法自动恢复,需要人工干预。无法实现写操作的负载均衡
哨兵模式:
哨兵模式监控的是节点不是哨兵
故障恢复可能会优点延迟
最好是以复制数据最完整的从节点作为新的主节点
拓展
运维人员必须要关注的redis指标:
在日常巡检中需要经常查看这些指标使用情况
info memory
#查看redis使用内存的指标
used_memory:11285512
#数据占用的内存(单位是字节)
used_memory_rss:24285184
#向操作系统申请的内存(单位是字节)
used_memory_peak:23952088
#redis使用内存的峰值(单位是字节)如何查看内存碎片率?
内存碎片率:used_mem0ry_rss/used_memory
#系统已经分配给了redis,但是未能够有效利用的内存redis-cli info memory | grep ratio
#查看内存碎片率allocator_frag_ratio:1.03
#分配器碎片比例。由redis主进程调度时产生的内存,比例越小越好,值越高,内存浪费越多。
allocator_rss_ratio:1.80
#表示分配器占用物理内存的比例,主进程调度过程中占用了多少物理内存
rss_overhead_ratio:1.13
#RSS是向系统申请的内存空间,redis占用物理空间额外的开销比例。比例越低越好。redis实际占用的物理内存和向系统申请的内存越接近额外的开销就越低
mem_fragmentation_ratio:2.16
#内存碎片的比例。值越低越好。表示内存的使用率越高redis占用的内存效率问题如何解决?
1、 日常巡检中,针对redis的占用情况做监控
2、 给redis设置一个占用系统内存的阈值,避免占用系统的全部内容
3、 内存碎片清理,分为手动和自动两种模式
4、配置一个合适的key的回收机制。一般都是设置写满报错的方式(maxmemory-policy noeviction),通过运维人员手动维护。或者挑选一个即将过期的键值对清除(maxmemory-policy volatile-ttl)。
redis的缓存击穿
缓存击穿主要是热点数据缓存过期或者被删除,多个请求并发访问热点数据。请求也是转发到后台数据库了,导致数据库的性能快速下降。
经常被请求的缓存数据最好设置为永不过期
相关文章:
redis的性能管理和雪崩
redis的性能管理 redis的数据是缓存在内存当中的 系统巡检: 硬件巡检、数据库、nginx、redis、docker、k8s 运维人员必须要关注的redis指标 在日常巡检中需要经常查看这些指标使用情况 info memory #查看redis使用内存的指标 used_memory:11285512 #数据占用的…...

python:关于函数内 * 和 / 是什么意思?
总结:如果你希望调用者使用函数时一定不能使用关键字传参,要求它使用位置进行传参,那么就可以把这些参数放在 / 的前面即可;如果你希望调用者使用函数时一定要使用某些参数,且必须是关键字传参时,那么就可以…...

PPT密码解密,简单教程,保护幻灯片内容
在创建、编辑和共享幻灯片时,有时会解除密码来保护幻灯片的安全。如果因为忘记密码而无法编辑或打开幻灯片,下面是一种安全、简单、实惠的办法来解决这个问题。 具体步骤如下:第一步百度搜索【密码帝官网】,第二步点击“立即开始”…...
Apache Airflow (十一) :HiveOperator及调度HQL
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹…...

SpringBoot-Docker容器化部署发布
在生产环境都是怎么部署 Spring Boot? 打成 jar 直接一键运行打成 war 扔到 Tomcat 容器中运行容器化部署 一、准备Docker 在 CentOS7 上安装好 Docker 修改 Docker 配置,开启允许远程访问 Docker 的功能,开启方式很简单,修改 /usr/lib/s…...
重生奇迹mu格斗怎么加点
1.力量加点 力量是格斗家的主要属性之一,它可以增加你的攻击力和物理伤害。因此,对于格斗家来说,力量加点是非常重要的。建议在前期将大部分的加点放在力量上,这样可以让你更快地杀死怪物,提高升级速度。 2.敏捷加点…...

「浙江科聪新品发布」新品发布潜伏顶升式移动机器人专用控制器
聚焦专用车型 最小专用控制器 控制器只占整机5%,纵向出线方式,占比更小 更易插拔 整体解决方案 更具价格优势 提供整体解决方案,配套各类型产品设备及车体厂家 打造持久稳定使用 坚持工业级品质 采用车规级接口,不用其它类不可…...
-spark)
大数据学习(22)-spark
&&大数据学习&& 🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博主哦ᾑ…...

String类常用方法总结
目录 一.简单认识String 二.String对象的比较 1.equals 内部实现原理: 2.compareTo 3.compareToIgnoreCase 三.字符串查找 示例: 四.字符串与其他类型转化 1.数值和字符串相互转换 2.大小写相互转化 3.字符串转数组 4.格式化转化 五.字符串…...
-Keras实现BiLSTM微博情感分类和LDA主题挖掘分析)
TensorFlow实战教程(二十八)-Keras实现BiLSTM微博情感分类和LDA主题挖掘分析
从本专栏开始,作者正式研究Python深度学习、神经网络及人工智能相关知识。前一篇文章通过Keras深度学习构建CNN模型识别阿拉伯手写文字图像,一篇非常经典的图像分类文字。这篇文章将结合文本挖掘介绍微博情感分类知识,包括数据预处理、机器学习和深度学习的情感分类,后续结…...
个人博客添加访问人数以及访问时间-githubpage
layout: post # 使用的布局(不需要改) title: 个人博客添加访问人数以及访问时间 # 标题 subtitle: 个人博客优化 #副标题 date: 2023-11-18 # 时间 author: BY ThreeStones1029 # 作者 header-img: img/about_bg.jpg #这篇文章标题背景图片 catalog: tr…...

Django--重定向redirect
在 Django 中,redirect 是一个用于进行重定向的函数。它允许你将用户从一个 URL 重定向到另一个 URL,通常用于处理表单提交、用户登录、用户注册等操作后的页面跳转。redirect 函数属于 django.shortcuts 模块。 以下是 redirect 函数的基本用法和一些参…...
)
在html和css中的引用svg(一)
问题:如何让 DIV 中的svg垂直居中? HTML 代码: <div class"content"><svg ...> ... </svg></div> CSS代码: .content svg { vertical-align: middle;} 实用扩展:如何让 DIV 中…...

C/C++ 实现:自然排序:针对两个需要排序的字符串,不仅逐个比较每个字符的顺序,对于连在一起的数字字符会作为一个完整数字进行比较 某知名企业的笔试题
目录 题目描述: 分析: 代码实现: 完整代码: 运行结果: 题目描述: 下面是一个自然排序函数的声明,请实现该函数; 自然排序是指:针对两个需要排序的字符串,不仅逐个比较每个...

sse实时通信
使用原因:用户网络环境较差,之前使用ws总是出现断连重连,导致数据总是不能实时更新,所以更换为sse npm install event-source-polyfill createWebSocket:创建sse连接 getWebSocketMsg:接收sse消息 impo…...
Qt专栏3—Qt项目创建Hello World
setp1 打开软件 双击Qt Creator 11.0.3 (Community),打进入软件界面 step2 创建项目 点击创建项目 step3 选择模板 选着Application(Qt)->Qt Widgets Application setp4 设置项目 名称中填入项目号名,创建路径中填入项目保存位…...

linux输出的重定向无效问题和解决
我们在调试程序或者打印日志时经常会遇到重定向的问题,而有时候会遇到重定向无效的问题,下面给一个简单的例子,首先写一个简单的test.c #include <stdio.h>int main(){fprintf(stdout, "hello\n");fprintf(stderr, "world\n");return 0; }编译生…...
chromium114添加新的语言国际化支持
一、需求说明 需要chromium114支持新语言体系,例如藏语,蒙古语,苗语等 二、操作步骤 1. build/config/locales.gni修改 在all_chrome_locales变量中添加新的语种标识,如下图。 2. 添加编译文件,告诉浏览器在编译时需要加载和输出那些文件 尝试编译出现错误一提示。需要…...

赛氪荣幸受邀参与中国联合国采购促进会第五次会员代表大会
11 月21 日 (星期二) 下午14:00,在北京市朝阳区定福庄东街1号中国传媒大学,赛氪荣幸参与中国联合国采购促进会第五次会员代表大会。 2022年以来,联合国采购杯全国大学生英语大赛已经走上了国际舞台,共有来自…...

车载通信架构 —— 传统车内通信网络发展回顾
车载通信架构 —— 传统车内通信网络发展回顾 我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何…...

降论文AI率实用攻略:7个方法+专业工具高效过审
为什么你的论文总被判定为AIGC疑似? 近些年AI写作工具普及后,很多科研人都遇到了同一个棘手问题:论文AIGC疑似度过高。按照多数高校最新的管理要求,AIGC率超过30%就有可能被认定为AI代写,直接失去答辩资格。 不少同学…...

如何掌握KoboldAI本地部署:技术爱好者的AI写作助手终极指南
如何掌握KoboldAI本地部署:技术爱好者的AI写作助手终极指南 【免费下载链接】KoboldAI-Client For GGUF support, see KoboldCPP: https://github.com/LostRuins/koboldcpp 项目地址: https://gitcode.com/gh_mirrors/ko/KoboldAI-Client KoboldAI是一款开源…...

5个关键优化技巧:让你的Amlogic TV盒子OpenWrt性能飙升300% [特殊字符]
5个关键优化技巧:让你的Amlogic TV盒子OpenWrt性能飙升300% 🚀 【免费下载链接】amlogic-s9xxx-openwrt Supports running OpenWrt on Amlogic, Allwinner, and Rockchip devices. Support a311d, s922x, s905x3, s905x2, s912, s905d, s905x, s905w, s9…...

ARM处理器勘误文档解析与分类指南
1. ARM处理器勘误文档解析与分类指南在嵌入式系统开发领域,处理器勘误文档(Errata Notice)是硬件工程师和底层软件开发者的必备参考资料。这份2004年发布的ARM SY003文档虽然显示当前版本没有实际勘误项,但其结构体系为我们提供了…...

明日方舟MAA助手:解放双手的终极自动化游戏伴侣
明日方舟MAA助手:解放双手的终极自动化游戏伴侣 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://gitcode.c…...

Python 数据可视化实战:让数据说话
Python 数据可视化实战:让数据说话 数据可视化的重要性 数据可视化是数据科学中不可或缺的一部分,它通过图形化的方式展示数据,使得复杂的数据变得更加直观和易于理解。Python作为一种功能强大的编程语言,提供了丰富的数据可视化库…...

安全认证与访问控制
文章目录One Time Password一次性密码平台认证Basic Authentication 基本认证Digest Auth 摘要认证NTLM认证协议Kerberos 网络身份验证协议Token Authentication 令牌认证OAuth Authentication 第三方授权登录API Key AuthenticationSession-Cookie 会话认证ip白名单/白名单认证…...

抖音内容管理革命:如何用自动化工具将素材收集效率提升15倍
抖音内容管理革命:如何用自动化工具将素材收集效率提升15倍 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback …...

mysql5.7开启主从配置
一、 环境准备与前置检查 两台服务器(或虚拟机)均安装 MySQL 5.7,版本建议保持一致。 确保主从库之间 3306 端口互通(关闭防火墙或放行端口)。 如果是克隆的虚拟机,务必检查 /var/lib/mysql/auto.cnf中的 s…...

开源像素智能体监控平台:可视化调试AI决策,提升自动化任务效率
1. 项目概述:一个面向像素级智能体的开源监控平台最近在折腾一些AI智能体项目,特别是那些需要处理图像、进行像素级交互的自动化任务时,我遇到了一个很实际的问题:我怎么知道我的智能体“看”到了什么,又在“想”什么&…...