开源vs闭源大模型如何塑造技术的未来?开源模型的优劣势未来发展方向
开源vs闭源大模型如何塑造技术的未来?开源模型的优劣势&未来发展方向
- 写在最前面
- 一、开源与闭源:定义与历史背景
- 开源和闭源的定义
- 开源大模型:社区驱动的创新
- 二、开源和闭源的优劣势比较
- 开源大模型(瓶颈)数据:ChatGPT的对话数据
- 代码大模型:开源生态会更好
- 开源优势:透明 用起来放心
- 开源的发展历程:模型越做越小,硬件越做越强大
- 开源大语言模型 服务部署层
- 三、开源社区在 AI开源创业 中扮演的角色
- 开源协作:透明 利于后期发展
- 资源对接:开发者找到更多的资源
- 催化剂:加速研发大模型
- 避免发生「局部最优化」:技术更多样
- 潜在(不愿付费)用户成为参与者
- 四、开源与闭源的商业模式比较
- 大模型现阶段商业化:为效果付费
- 盈利模式分析:开源大模型的商业化
- 市场竞争现状:开源大模型的生态
- 用户生态变化:从工程师到兴趣研究者
- 五、案例研究:成功与挑战
- Infra as Service的新型商业模式
- 开源生态:开发者工具的商业化
- 六、中国大模型的未来之路
- 中国大模型优势:用户量更多
- 开源社区的重要贡献者:国内热情高
- 开源无国界,但存在语言壁垒
- 结束语
写在最前面
创作活动:https://activity.csdn.net/creatActivity?id=10606
开源和闭源,两种截然不同的开发模式,对于大模型的发展有着重要影响。开源让技术共享,吸引了众多人才加入,推动了大模的创新。而闭源则保护了商业利益和技术优势,为大模型的商业应用提供了更好的保障。
那么,你认为大模型的未来会走向哪一边呢?请分享你的看法吧!
开源大模型与闭源大模型在人工智能领域内构成了两个相互竞争又共生的生态系统。开源模型,如Meta的Llama和斯坦福的Alpaca,展现了社区驱动的快速进步和创新。与此同时,闭源模型如OpenAI的GPT系列,保持着技术领先和商业应用的优势。
开源大模型正在成为推动AI领域进步的重要力量,而闭源模型则继续在商业化路径上稳步前进。这两种模式的并行发展,正在塑造人工智能的未来。

随着我们进入一个由大模型主导的新时代,开源与闭源将继续在技术的前沿领域内角逐,它们的未来走向和最终影响,仍是一个值得深入探讨的开放问题。在本文中,我们将探讨开源和闭源大模型的定义与历史背景,分析它们在技术革新中的角色。
首先介绍开源大模型的数据瓶颈、多模态大模型的发展,以及它们在AI领域如何推动创新,同时比较这两种模型的商业模式和市场现状。通过对成功案例的分析,我们将揭示这些模型背后的商业逻辑,以及它们如何影响未来的AI景观。本文最后,我们专注于中国在这场全球大模型竞争中的独特角色和潜力。中国的大模型,凭借其庞大的用户基础和对开源社区的贡献,在全球范围内占据了重要地位。
关键词:“人工智能”、“开源大模型”、“闭源技术”。
主要参考:7 月 23 日,在极客公园主办的 AGI Playground 大会上,来自 Hugging Face、RWKV、Stability AI 等几家知名开源大模型公司的从业者,分享了在这波 AI 浪潮中,开源模型的优势,以及未来的发展趋势
一、开源与闭源:定义与历史背景
开源和闭源的定义
开源软件指的是其源代码可以被公众自由使用、修改和共享的软件。这种模式鼓励开放合作和技术创新,其代表作如Linux操作系统和Apache Web服务器。
而闭源软件,则是指源代码不公开的软件,通常由个人、团队或企业独立开发和维护,如Microsoft Windows操作系统和Adobe Photoshop。
从历史上看,开源和闭源的较量源自计算机软件行业的发展。
开源大模型:社区驱动的创新
开源大模型如Llama和Alpaca,证明了开源社区在推动技术进步方面的巨大潜力。这些模型的快速迭代和改进,展现了一个由社区驱动的开放协作模式。
这种模式不仅加速了技术发展,而且通过透明性增加了模型的可信度。例如,Llama2的开放商业使用政策,体现了开源社区在推动大模型应用方面的积极作用。
从 2 月份 Meta 发布的 Llama,到 3 月份斯坦福大学微调 Llama 后发布的 Alpaca,再到 5 月份出现的 Falcon,世界各地的开源模型在「内卷」中快速进步。7 月 18 日,Llama2 的出现,更是直接让大模型的竞争格局变天了。开源模型作为大模型领域的「地板」,Llama2 开源且有条件地开放了商业使用后,很多「水平有限」的大模型还没商用,就已过时。
二、开源和闭源的优劣势比较
在质量方面,
- 开源软件由于其代码的公开性,通常更容易得到社区的测试和改进。
- 但闭源软件通常由专业团队进行系统的设计和测试,也能保证高质量的输出。
在安全性方面,
- 开源软件的透明性使其更容易被检查和修复漏洞,但也可能暴露给潜在的攻击者。
- 闭源软件则因其私有性,在安全漏洞被发现之前可能更加安全。
开源大模型(瓶颈)数据:ChatGPT的对话数据
在开源大模型的发展中,数据成为了一个关键因素。多数开源模型依赖于公共数据集,如ChatGPT的对话数据。
数据质量和多样性对于开源社区是很重要的。数据的开放和共享,将是推动开源大模型进步的关键。
见过「历史」的尹一峰(Hugging Face 工程师)认为,「模型每天都在变化,随时会被更新掉,但是建立很好的数据集,能让你接下来很长一段时间受用。」
然而,一个不常被讨论和关注的事实是:「
现在开源社区用的数据都是 ChatGPT 对话的数据」,RWKV罗璇说,「这是很大的问题,数据不会开源,而开源社区应该更关注数据的建立」。
代码大模型:开源生态会更好
数据的瓶颈一旦被破除,开源社区可以发挥极佳的组织优势,在大模型能力上接近甚至超过闭源大模型。
比如,在 AI 编程场景,开源遥遥领先。对于开源社区而言,没有明显的编程数据劣势,很多超越了闭源模型在 AI 编程场景的质量。
张萌说:除了常规的语言模型之外,coding 场景在社区层面发展得非常快,像 CodeGen2.5、WizardCoder、Phi-1 这样的模型都纷纷其实超越了这几个闭源模型在 coding 这个场景上的质量。
这是(我们公司)TabbyML 为什么在第一天就决定做开源很重要的原因,当这个生态相对多元,或者模型本身快速被变成标品。我们预期未来生态会比较多元,大家作为开发者工具部署的时候会有很多种选项。而且开发者场景里,开源本身就是在商业化获客角度非常理想的选项。在未来,尤其是 coding 这个场景,因为下游的用例太多种多样了,所以我们相信它会是一个开源模型主导,闭源模型很难追得上的状态。
开源优势:透明 用起来放心
另一方面,开源模型,企业客户用起来放心。相比闭源大模型的黑箱,「透明化的文章都出来了,代码也发出来了,用起来你放心,知道里面有什么」。像 Llama2 这样的开源模型,公布了训练数据、方法、标注等细节。
开源的发展历程:模型越做越小,硬件越做越强大
尹一峰:最近最火的项目就是 Llama2,但是在 Llama2 这方面能看到一个趋势,现在在 70B 左右的模型已经在很多方面能跟 175B 的 OpenAI 的闭源模型可以拼一拼,这应该是一个趋势。首先,OpenAI 的模型 2021 年就训练完了,有很多这两年出现的新技术、新架构他没有加进去。第二,像 Llama 这样的模型有这几年的技术经验积累,可以让一个小的模型做到之前大的模型才可以做到的事情。我觉得之后的趋势:可能强大到一定程度的模型,比如 100 分的模型,可能从 70B 降到 50B 也可以做到 100 分,最后可能 13B 也可以做到 100 分,最后模型越做越小,硬件越做越强大,很快就可以做到端了,等它到了端上之后 To C 的应用就可以做起来了。这也是我目前看到在商业化上面,在模型技术上面的趋势。
- 质量对比
- 安全性分析
- 产业化影响
- 技术适应性和可靠性
开源大语言模型 服务部署层
我们希望这些 serving layer 竞争的格局能够比较良性竞争,我们在应用层的角度就可以得到更好的开发者体验。
张萌:我们作为语言模型的应用层,特别关注的一点就是开源大语言模型的 serving layer(服务部署层)。我分享两个我们比较关注的项目:
一个是 Hugging Face 的 text generation inference,它现在是一个工程化非常好,支持、可观测性都做得非常完善的项目,我觉得已经接近于现在开源大语言模型 serving 的实施标准,它关注度也非常高。
另外有一个比较新一点的叫 vllm.ai,是伯克利的 Sky Computing Lab 在做的项目。让人惊讶的是他们应该也是打算在全方位竞争 serving layer,他们的特点是通过内存分页应用到 attention 的想法,去更容易的做 continuous patching,更容易去做吞吐量的提升。
三、开源社区在 AI开源创业 中扮演的角色
- 大模型技术概述
- 开源对技术发展的推动
- 闭源对技术保护的作用
- 数据共享和算法创新的影响
- 业务拓展的不同策略
开源协作:透明 利于后期发展
刘聪:开源是很重要的。现在不管是大模型,还是工具链都有很多新的项目出来。从我们创业公司的角度来说,我们没有足够的工程师能力覆盖到所有用例。举个例子,在我们社区里,对百川模型的支持就是社区开发者做的贡献。从开源大模型的角度来说,这个是非常重要的能力,需要比较透明的协作的方式做这个事情。从工具链的角度来说,在 Open MLL 上,是一个非常百花齐放的过程,很多人用不同的工具,做不同的功能。在开源协作的角度而言,会让这个生态变得发展更好,更 open,这样也会更易于后面的进展。
资源对接:开发者找到更多的资源
罗璇:RWKV 一直注重全球的开发者生态,一开始就是全球化的,born in Global。开发者为什么用 RWKV,为什么加入一个开源社区,初衷是非常简单的,觉得你这个项目有意思,有前景,值得投入。这是非常朴素的出发点。我们希望让 AI 更加平权,最近也在组织一些线上闭门会,包括 Hackthon 的项目,希望让更多的开发者找到更多的资源,我们给开发者提供一些资源对接。
催化剂:加速研发大模型
尹一峰:我觉得开源社区应该是催化剂的作用。
从 0 到 1 的工作,可能需要一帮特别聪明的大佬关起门来搞。
但是从 1 到 100 的工作,扔给开源社区就很快。
当时 Llama2 一出大家很惊艳,我们觉得这个模型肯定能在榜首上待几天。真的就只呆了几天就被超越了。从另一种角度来说,哪怕你在做闭源的工作,开源社区对你也有很大的帮助,因为开源算是闭源的地板。假如公司 A 做了一个闭源的模型,跑出来一看比这个 Llama2 低了 50 分,你直接去 Hugging face 下载 Llama2。无论是从创新上,对商业化公司的影响上,都起到了一个加速的作用。所以哪怕开源社区现在商业化上多多少少都会面临一些问题,但是这个事情真的是值得去做的。
避免发生「局部最优化」:技术更多样
郑屹州:开源社区有点像一团黏菌寻找食物。虽然黏菌是一个个体,但是我们可以把它比喻成群体。一开始方向是特别发散的,这个群体在四处探索不同的方向,逐渐扩散。这时候大家都没有明确的凝聚方向,但是只要有一个点接触到了食物,拿到了最终目标,很快其他路径会退化,会有一条非常粗的主干直接连向那个目标。
开源社区在这个地方扮演了探索的过程。黏菌即便抵达了一个食物,大量的主干形成以后,还会有非常多的枝干去探索其他的地方,去找到更多的食物。
开源社区可以避免发生「局部最优化」的状况。Transformer 是不是局部最优,我们现在还没有答案;RNN 是不是下一个答案我们也不知道。但是现在因为开源社区的存在,会有多个枝干在做不同的探索,有意义的枝干上面都会形成一股力量,在这个枝干上面更好做发展。
这是我看到开源社区在这个时代最大的意义,让技术多样,不至于陷入局部最优,最终卡死。
潜在(不愿付费)用户成为参与者
张萌:开源社区的存在,是开源项目从商业上的角度本质区别于其他所有商业模式的一个核心点。
开源社区使得潜在用户,即使是不愿意付费的用户,都有机会变成一个社区的 contributor(贡献者),产生价值。举一个例子,大家可能都做过国内互联网大厂的生意,国内互联网大厂基本是不太有付费意愿的客户群体,我们很难在他身上赚到钱。
但是客观行为上,国内互联网大厂有技术能力,也有技术意愿去使用先进的开源生产力工具。我们在策略上,从一开始就不指望从互联网大厂赚到钱,而是通过他们的使用,把他们 on board 进来,让他们作为社区的参与者,真正能够把 Tabby 这样产品在自己内部用起来,有机会成为这个社区的 contributor,然后从本质上就把这个商业模式的路拓宽了很多。
所以做开源商业化的时候,不得不去做的一个 engagement strategy 的判断就是,当一个客户显然不会付费的时候,我们的主要目标就是把它变成社区的 contributor。
四、开源与闭源的商业模式比较
开源和闭源大模型的并行发展,正在塑造人工智能的未来。社区驱动的创新、数据共享和技术透明度是推动开源模型前进的关键因素。
大模型现阶段商业化:为效果付费
现阶段大模型这个领域,大家还是为效果付费,语言模型是 ChatGPT,文生图就是 Midjourney 更多一些,现在买单的基本上都是个人或者企业,做效率提升。
未来还会有增量,增量的点在于会有新的计算平台、互联网出来。现阶段还是在效率提升上,会有更多的想象空间在。
罗璇:作为 RWKV,基底模型永远都会开源、免费可商用。我们也成立了商业公司,是整个开源生态的一部分,会去做垂类的一些优化。
盈利模式分析:开源大模型的商业化
开源大模型的商业化是一个复杂的挑战。
一方面,开源模型的免费和商业化版本之间需要平衡。
另一方面,商业化模式可能依赖于与云平台的结合,提供端到端的解决方案。
同时,开源社区的健康发展需要遵守相应的开源许可协议,以促进良性的商业生态。
刘聪:标志性事件比较重要的是,当 Falcon 最开始发布的时候要收你 10% 的 royalty(使用费)。他说他是一个开源模型,但收你10% 的 royalty。最后社区和公众对这个事情的反应很大,Falcon 最后又把这个东西去掉,完全改成 apache 兼容的license。但是最近 Llama2 发布之后,license里有一个商用条款,但是大家好像都没有再讨论这个事情,因为在他的条款里明确表示——如果你的月活超过 7 亿,你需要再找 Facebook 要grant(授权),而且他没有具体写出这个 grant 到底是什么,我觉得这是开源社区需要急需解决的,大模型的开源 license。
罗璇:关于 license 这个事情,因为我们一直都是 apache 2.0 开源可商用的,我认为 Llama还是给自己留了一些空间,Meta 毕竟是一家商业公司,我了解到他还是希望通过 Llama2能够拉近更多的开发资源、开发者生态做元宇宙那块的事情。
市场竞争现状:开源大模型的生态
在开源的生态,跟闭源的商业生态如果要做竞争,目标明确、路径明确以及执行力强,这是非常重要的事情。
罗璇:更关注在端侧,在终端上,比如手机、电脑、机器人、XR上面跑的大模型,像海外上有开发者做了Llama.CPP,也有人帮我们做RWKV.cpp,这个是跟开发者和更多的创业者更相关的事情。只要在终端上能够跑大模型,整个对算力的需求,包括对进入的门槛拉了很低,这是非常好的事情。另外一方面,我发现近期很多开源社区目标越来越明确,这是非常好的事情。
用户生态变化:从工程师到兴趣研究者
一个非常有意思的现象,从 Stable Diffusion 开始,开源社区的参与者的 profile(背景)发生了变化。
郑屹州:之前的开源社区参与者,特别是 ML(机器学习)相关的开源社区参与者,大多应该都是 ML Engineer 或者是工程师,非常非常技术导向的人。
但 SD(Stable Diffusion)可能是一个爆发点,开源社区的参与者里开始出现:大量以兴趣为驱动的人和很多草根研究者,有很多本身不是 ML(机器学习)领域但有一定研究能力的人进来。
这样丰富的社区就开始涌现,比如刚才提到端上的部署,Llama.cpp、ExLlama,这些全都是开源社区自己做出来的。
当社区开始变得更跨界,社区的范围变得更广,是现在 AGI 时代或者走向 AGI 的时代里面,看到的一个比较有趣的 pattern。
五、案例研究:成功与挑战
Infra as Service的新型商业模式
尹一峰:现在大模型越做越小,也越做越强,可能到最后每个人都会想拥有自己的大模型。但问题是,在端上不一定有自己的硬件去跑模型。有一个商业模式,就是我给你看一下我的模型有多么强大,你用我的这个模型,我帮你来 host,相当于 Infra as Service。
Hugging Face 也在做这个事情,我们会帮你 host model,训练完了之后就挂在那里。这样的话,我们有模型,有数据库,然后也有 Infra,就是一条龙服务,不需要去别的地方了。
如果把大模型类比为当年的互联网,下一波创业就类似于当年的互联网+,互联网加上外卖就有了美团,加上购物以及有了淘宝。因为互联网是一个具有颠覆性的技术,可以颠覆外卖,也可以颠覆购物。我觉得现在有一个很尖锐的问题,就是我们要找到大模型它到底可以颠覆啥?如果大模型可以颠覆某一个行业的话,这里是可以出巨头的。如果找不到这个可以颠覆的东西,找到可以增量的东西,至少能挣到钱。
开源生态:开发者工具的商业化
在开发者工具这个开源生态里,商业化是跑得比较通的一个模式。大家基本上根据席位、根据年付费,在海外是一个非常通顺的商业模式。对我们来说,比较核心的点在于怎么区分开源版和商业版功能的差别。TabbyML 本质上是给开发者提效的工具,那么我们在开源的这个 OpenCore 里,所有对开发者的提效包括补全、问答、一些简单的分析。这些功能都是被开源版本所覆盖,永久免费的一个能力。在面对企业做商业化,面向 CTO 或者 Engineering Manager 的时候,我们会提供的你团队使用 Tabby 产品之后整体提效的状况,你的整个 workflow,用 language model 做完分析之后,告诉你每个 issue 花了多少时间卡在哪里,这样一些偏生产力协作和 insight 层面的能力,我们会把它作为一个商业版能力,去对企业客户进行额外的收费。
六、中国大模型的未来之路
中国大模型优势:用户量更多
刘聪:非常同意开源就是一个无国界的事情。开源软件可能是要分两块,一块是基础设施相关的开源软件,一块是事务性的开源软件,这个 Panel 我们可能更多谈到基础设施的开源软件。
基础设施的开发软件,中国创业者或者开发者是有一定优势的。因为从互联网公司的角度,我们的用户量更多,并发和遇到困难的场景,比海外刚起步的开源项目更复杂。
我其实很建议国内的开发者,或者创业者,从一开始就去做全球的开发者社区,而不是专注中文开发者社区。其实海外的开发者也想要用我们中国的创业者、基础设施开发者创建的基础软件,但是因为语言原因而错过,我觉得是非常可惜的。
开源社区的重要贡献者:国内热情高
郑屹州:中国其实是开源社区特别重要的贡献者。举一个例子,Stable Diffusion 的 Dpmpp 采样算法是清华团队做的,这可以说是最重要的采样算法之一;而我们模型用的 Resnet 层来自微软亚研院的华人研究者。这些对于开源社区是非常核心的贡献。国内的开发者在做很多事情,因为语言的壁垒没有能够真的传到全球社区里面去;在语言模型上可能就更明显,因为模型底层的语言都不一样。如果我们抛开所有地域政治话题,就谈语言壁垒会存在多久,可能在近两三年内,这个问题会被各种各样的工具和现在的模型来解决。开源社区培养了一堆开源模型,可以帮助我们把巴别塔重建,让我们能够真正实现跨越语言壁垒去做合作,这是一个我特别兴奋的事情。未来半年或一年,可以看到更多的趋势,让跨语言的开发更多联合起来。
罗璇:Stable Diffusion 开源以后,国内开源热情就非常高了。我觉得国内对开源是非常有热情的,只是过去没有一个很好的闭环或者产品,或者是生态上的商业。
现在 RWKV 在国内开发者也很多,在国内 QQ 群开发者也超过一万人了。商业公司现在的开源是另外一条路,不会把最好的模型开源出来,或者有些商业公司发现自己的模型落后了,会把模型开源出来。
我觉得这是接下来会发生的事情。我们更多要跳出时间和空间的约束,想想未来三到五年,AI 会发生什么变化。
开源无国界,但存在语言壁垒
开源项目具有全球化的潜力,但语言壁垒仍然是一个挑战。语言模型在处理不同语言的数据时可能会出现分歧,这需要更多的跨语言合作和技术创新。中国在开源社区中发挥着重要作用,但语言和互联网环境的差异使得中文社区面临额外的挑战。
尹一峰:做开源模型的人能很容易把模型放上去,下模型的人把它下下来,这样很容易形成社区。但是社区又有一些障碍和分界线。Stable Diffusion 开源后,之所以全世界都在用,很大程度上是因为图谁都能看得懂。如果是语言模型可能会有语言障碍,英语(社区)会更多做英语模型,中文(社区)会更容易去做中文模型。Llama2 之所以这么火可能也是沾了英语的光,因为全世界都会说英语。我觉得这一方面也是会造成山头主义。如果要做国际化,我觉得最大问题是要打通语言壁垒。第一点,让别人学中文;第二点,自己的模型多放一点语言进去。
张萌:我们视角里面,中文社区和海外社区最大的问题还是因为互联网环境,导致不得不去做适配的一些事情,导致中文社区平白多了更多的障碍。海外的开源项目很多时候是不感兴趣解决中文社区特有的问题。这些问题只有靠中文开发者自己解决,也只有这样的问题解决了,国内才能够真正在工具链上跟海外保持持平,在解决语言问题后,我相信国内社区会更磅礴发展起来
结束语
我们探讨了开源与闭源大模型在AI领域的发展历程及其未来趋势。那么,您认为大模型的未来会走向哪一边呢?请分享您的看法!
相关文章:
开源vs闭源大模型如何塑造技术的未来?开源模型的优劣势未来发展方向
开源vs闭源大模型如何塑造技术的未来?开源模型的优劣势&未来发展方向 写在最前面一、开源与闭源:定义与历史背景开源和闭源的定义开源大模型:社区驱动的创新 二、开源和闭源的优劣势比较开源大模型(瓶颈)数据&…...
如何使用无代码系统搭建软件平台?有哪些开源无代码开发平台?
无代码是什么 无代码开发,也称为零代码(Zero Code)开发,是一种技术概念。无代码开发无需代码基础,适合业务人员、IT开发及其他各类人员使用。他们通过无代码开发平台快速构建应用,并适应各种需求变化&#…...
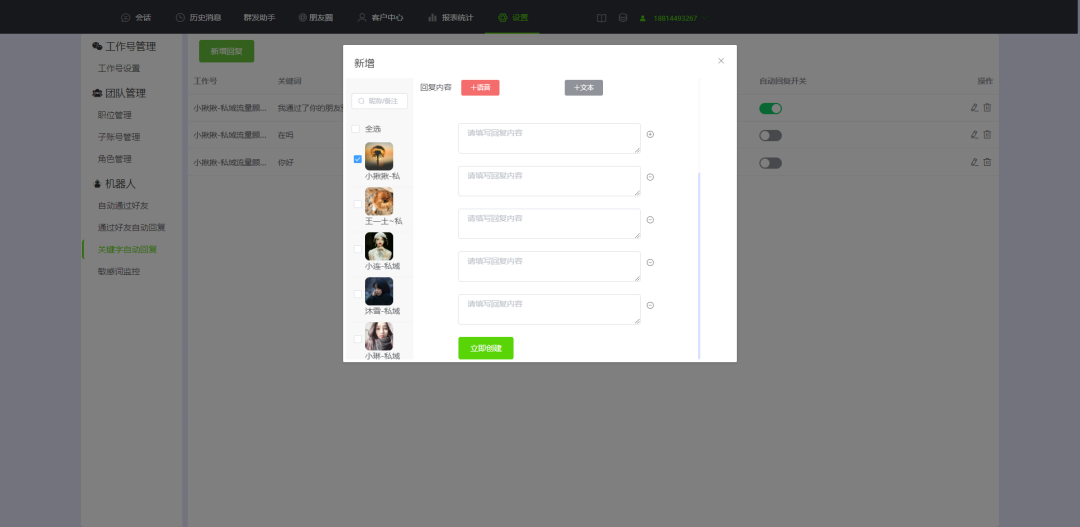
微信怎么设置自动回复?
自动回复的用处 微信自动回复可以提高沟通效率。当你无法立即回复消息时,设置自动回复可以让对方知道你的情况,并且不会因为长时间没有回复而产生误解或不满。 微信自动回复可以节省时间和精力。如果你经常收到类似的询问或回复,通过设置自动…...

基于Vue3的低代码开发平台——JNPF
目录 一、什么是Vue.js ? 二、Jnpf-Web-Vue3 的技术栈介绍 (1)Vue3.x (2)Vue-router4.x (3)Vite4.x (4)Ant-Design-Vue3.x (5)TypeScript &#x…...

Thinkphp6 模型 指定字段自增的方法
tp6要使用Db类必须使用门面方式(think\facade\Db)调用。 use think\facade\Db; 然后,用Db::raw就可以实现指定字段自增了。...

WhatsApp开发客户攻略来袭!还有你不知道的账号解封秘籍!
别人用 WhatsApp 都是订单多到爆单,自己用 WhatsApp 却是订单、客户寥寥无几甚至账号被封?想必外贸从业者在用 WhatsApp 开发客户的时候都有这样的烦恼,今天这篇文章就和大家聊一聊怎么用 WhatsApp 高效地开发客户。 WhatsApp 开发客户的优势…...

Linux C 基于tcp多线程在线聊天室
多线程在线聊天室 概述客户端服务端 概述 客户端实现了判单用户登录结果、防止单回车字符发送、保存和显示历史聊天记录(仅自己)、退出聊天室功能。 服务端实现了验证用户是否已经存在(支持最大64用户连接)支持广播用户进入退…...

代码随想录算法训练营第23期day60|84.柱状图中最大的矩形
一、84.柱状图中最大的矩形 力扣题目链接 42接雨水 是找每个柱子左右两边第一个大于该柱子高度的柱子,而本题是找每个柱子左右两边第一个小于该柱子的柱子。 本题是要找每个柱子左右两边第一个小于该柱子的柱子,所以从栈头(元素从栈头弹出…...

vue动态获取目录结构进行配置静态路由
文章目录 前言定义项目页面格式一、vite 配置动态路由新建 /router/utils.ts引入 /router/utils.ts 二、webpack 配置动态路由总结如有启发,可点赞收藏哟~ 前言 项目中动态配置路由可以减少路由配置时间,并可减少配置路由出现的一些奇奇怪怪的问题 路由…...

产品工程师工作的职责十篇(合集)
一、岗位职责的作用意义 1.可以最大限度地实现劳动用工的科学配置; 2.有效地防止因职务重叠而发生的工作扯皮现象; 3.提高内部竞争活力,更好地发现和使用人才; 4.组织考核的依据; 5.提高工作效率和工作质量; 6.规范操作行为; 7.减少违章行为和违章事故的发生…...
图片降噪软件 Topaz DeNoise AI mac中文版功能
Topaz DeNoise AI for Mac是一款专业的Mac图片降噪软件。如果你有噪点的相片,可以通过AI智能的方式来处理掉噪点,让照片的噪点降到最 低。有了Topaz DeNoise AI mac版处理图片更方便,更简单。 Topaz DeNoise AI mac软件功能 无任何预约即可在…...

【开源】基于Vue.js的车险自助理赔系统的设计和实现
项目编号: S 018 ,文末获取源码。 \color{red}{项目编号:S018,文末获取源码。} 项目编号:S018,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 数据中心模块2.2 角色管理模块2.3 车…...

2023年亚太杯数学建模思路 - 案例:粒子群算法
文章目录 1 什么是粒子群算法?2 举个例子3 还是一个例子算法流程算法实现建模资料 # 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 什么是粒子群算法? 粒子群算法(Pa…...
Android:Google三方库之Firebase集成详细步骤(一)
前提条件 安装最新版本的 Android Studio,或更新为最新版本。使用您的 Google 账号登录 Firebase请注意,依赖于 Google Play 服务的 Firebase SDK 要求设备或模拟器上必须安装 Google Play 服务 将Firebase添加到应用: 方式:使用…...
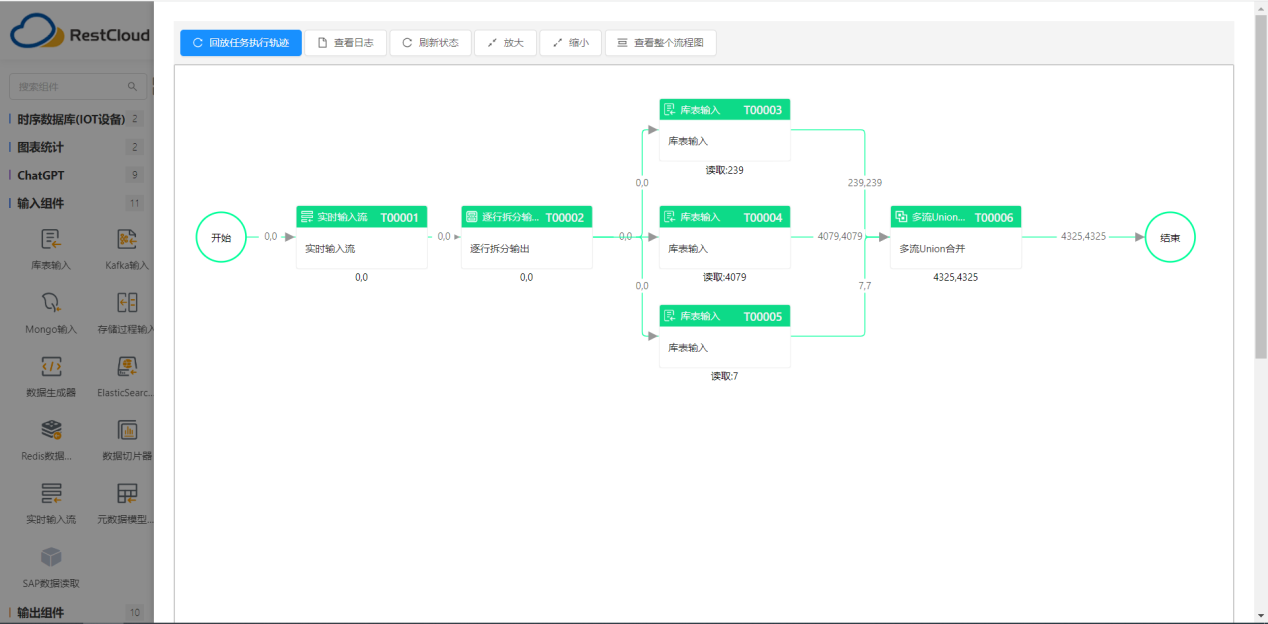
企业如何选择一款高效的ETL工具
企业如何选择一款高效的ETL工具? 在企业发展至一定规模后,构建数据仓库(Data Warehouse)和商业智能(BI)系统成为重要举措。在这个过程中,选择一款易于使用且功能强大的ETL平台至关重要,因为数…...
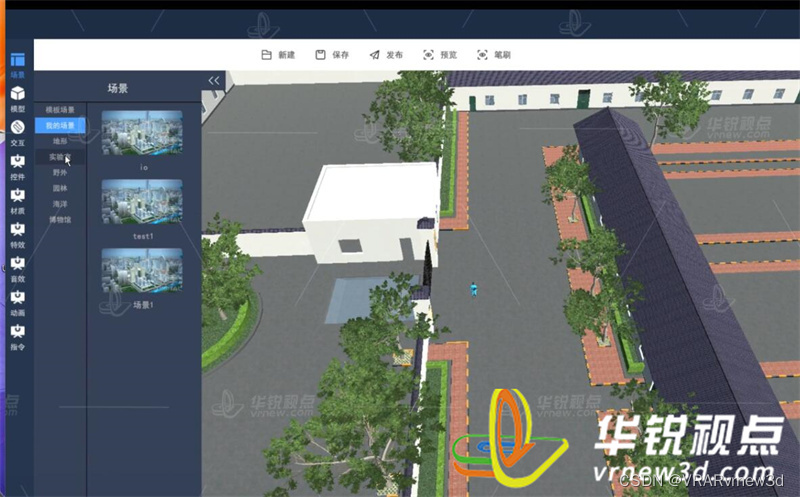
vr编辑器可以解决教育教学中的哪些问题
VR编辑器是一种基于虚拟现实技术的教育内容编辑器,可以帮助教师快速创建出高质量的虚拟现实教学内容。 比如在畜牧教学类,通过这个软件,教师可以将真实的动物场景、行为和特征模拟到虚拟现实环境中,让学生在沉浸式的体验中学习动物…...

国外聊天IM — Sendbird
接⼝⽂档: https://sendbird.com/docs 好久没写文章了 我在官网找到的pom, 下载不下来,git下载下来,打进项目里不能用,就只能用简单的http了 直接上代码,只是简单的调通代码,根据你自己业务改:…...

Django与Ajax
目录 一、什么是Ajax 二、Ajax引入 案例 小结 三、前后端数据传输的编码格式(contentType) 【1】form表单 【2】编码格式 【3】Ajax 【4】代码演示 四、Ajax发送JSON格式数据 【1】引入 【2】后端 【3】总结 五、Ajax提交文件数据 【发送文件数据的格式】 【结…...

linux日志不循环问题诊断
有一台Linux虚拟机的messages日志文件自2023年7月下旬开始没有按周为周期重新生成新的日志,一直累积在同一个messages文件中,如下所示: [root logrotate.d]# ls -l /var/log|grep me -rw-r--r-- 1 root root 107170 Nov 15 1…...
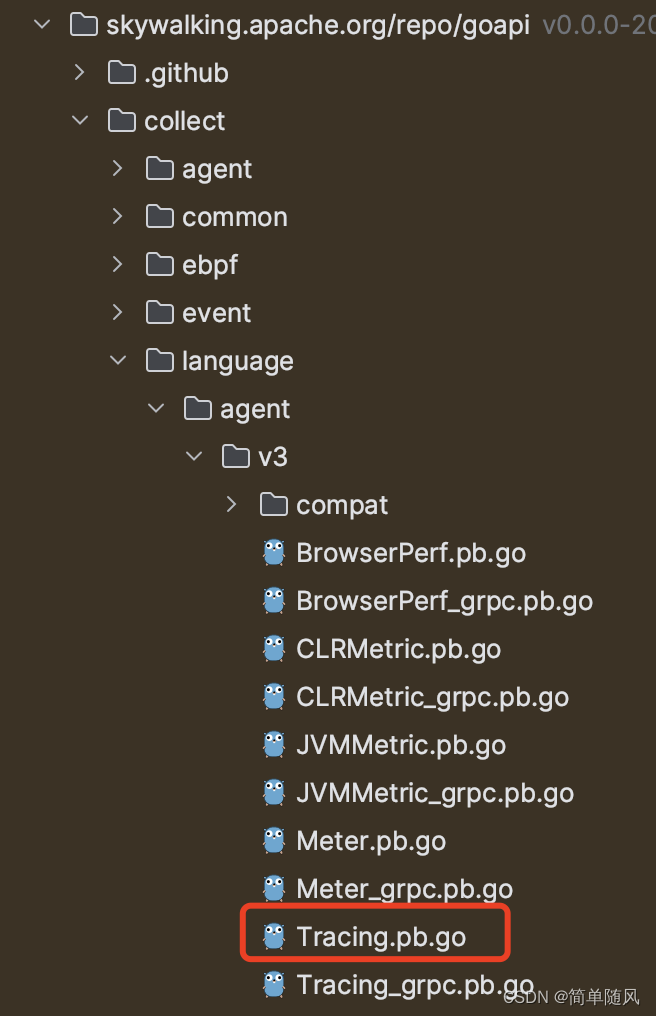
Golang版本处理Skywalking Trace上报数据
Tips: 中间记录了解决问题的过程,如不感兴趣可直接跳至结尾 首先去es里查询skywalking trace的元数据 可以拿到一串base64加密后的data_binary(直接解密不能用,会有乱码,可参考https://github.com/apache/skywalking/issues/7423) 对data_b…...

保姆级教程:用Python和CasADi从零实现一个简单的车辆MPC控制器
从零构建车辆MPC控制器的Python实战指南 引言 在自动驾驶和机器人控制领域,模型预测控制(MPC)已经成为实现精确轨迹跟踪的主流方法。与传统的PID控制相比,MPC能够显式处理多变量系统的约束条件,并通过滚动优化机制实现更好的控制性能。本文将…...

告别手动扫码:MHY_Scanner智能登录助手让游戏登录更高效
告别手动扫码:MHY_Scanner智能登录助手让游戏登录更高效 【免费下载链接】MHY_Scanner MHY扫码登录器,支持从直播流抢码。 项目地址: https://gitcode.com/gh_mirrors/mh/MHY_Scanner 还在为米哈游游戏登录时的手忙脚乱而烦恼吗?MHY_S…...

MPC-BE深度技术解析:现代Windows媒体播放器的架构设计与实现
MPC-BE深度技术解析:现代Windows媒体播放器的架构设计与实现 【免费下载链接】MPC-BE MPC-BE – универсальный проигрыватель аудио и видеофайлов для операционной системы Windows. 项目地…...

基于MCP协议构建AI驱动的Attio CRM自动化工作流实战
1. 项目概述:当Attio遇到MCP,自动化工作流的新篇章如果你和我一样,每天的工作都离不开各种SaaS工具,那你一定对“数据孤岛”和“重复劳动”这两个词深恶痛绝。Salesforce里更新了一个客户状态,Notion里的项目看板得手动…...

AI认知评估框架:从任务表现到认知能力的深度剖析
1. 项目概述与核心价值最近在GitHub上闲逛,又发现了一个挺有意思的仓库:kobie3717/ai-iq。光看这个名字,你可能会觉得这又是一个测AI智商的玩具项目,或者是一个简单的基准测试集。但当我真正点进去,花时间把它的代码、…...

【MIMO通信】神经网络MIMO无线通信全面性能分析【含Matlab源码 15415期】
💥💥💥💥💥💥💥💥💞💞💞💞💞💞💞💞💞Matlab武动乾坤博客之家💞…...

将格斗对战抽象为离散时间仿真:对象映射与循环结构
-----将格斗对战抽象为离散时间仿真:对象映射与循环结构(以 Street Fighter II 类系统为例)摘要 本文讨论如何把对战格斗抽象为可批量重演实验的仿真模型:给出概念映射、最小对战循环、指标体系与适用边界,便于在通用仿…...

炉石传说佣兵战记自动化脚本:5分钟轻松告别重复操作的终极指南
炉石传说佣兵战记自动化脚本:5分钟轻松告别重复操作的终极指南 【免费下载链接】lushi_script This script is to save your time from Mercenaries mode of Hearthstone 项目地址: https://gitcode.com/gh_mirrors/lu/lushi_script 还在为《炉石传说》佣兵战…...

深度学习模型压缩:从剪枝到知识蒸馏
深度学习模型压缩:从剪枝到知识蒸馏 1. 技术分析 1.1 模型压缩方法对比 方法压缩比精度损失计算开销适用场景剪枝2x-10x1-5%低所有模型量化2x-4x0.5-3%低推理优化知识蒸馏可变可忽略中分类/检测低秩分解2x-5x1-3%中CNN/全连接 1.2 压缩效果评估 指标定义测量方法压缩…...

保姆级教程:用阿里云源在CentOS 7上快速部署Zabbix 5.0代理服务器
保姆级教程:用阿里云源在CentOS 7上快速部署Zabbix 5.0代理服务器 最近在帮朋友搭建监控系统时,发现很多新手在部署Zabbix代理服务器时都会遇到各种问题——从依赖包安装失败到配置文件参数错误,再到数据库连接异常。作为一个踩过无数坑的老运…...