GZ033 大数据应用开发赛题第08套
2023年全国职业院校技能大赛
赛题第08套
赛项名称: 大数据应用开发
英文名称: Big Data Application Development
赛项组别: 高等职业教育组
赛项编号: GZ033
背景描述
工业互联网是工业全要素、全产业链、全价值链的全面连接,是人、机、物、工厂互联互通的新型工业生产制造服务体系,是互联网从消费领域向生产领域、从虚拟经济向实体经济拓展的核心载体,是建设现代化经济体系、实现高质量发展和塑造全球产业竞争力的关键支撑,工业大数据则是工业互联网实现工业要素互联之后的核心价值创造者。随着大数据行业的发展,工业数据收集呈现时间维度不断延长、数据范围不断扩大、数据粒度不断细化的趋势。以上三个维度的变化使得企业所积累的数据量以加速度的方式在增加,最终构成了工业大数据的集合。
为完成工业大数据分析工作,你所在的小组将应用大数据技术,以Scala作为整个项目的基础开发语言,基于大数据平台综合利用
Hive、Spark、Flink、Vue.js等技术,对数据进行处理、分析及可视化呈现,你们作为该小组的技术人员,请按照下面任务完成本次工作。
任务A:大数据平台搭建(容器环境)(15分)
环境说明:
| 服务端登录地址详见各任务服务端说明。 补充说明:宿主机及各容器节点可通过Asbru工具或SSH客户端进行SSH访问。 MySQL已在容器的Master中安装完毕,用户名/密码为root/123456 |
子任务一:Hadoop 完全分布式安装配置
本任务需要使用root用户完成相关配置,安装Hadoop需要配置前置环境。命令中要求使用绝对路径,具体要求如下:
- 从宿主机/opt目录下将文件hadoop-2.7.7.tar.gz、jdk-8u212-linux-x64.tar.gz复制到容器master中的/opt/software路径中(若路径不存在,则需新建),将master节点JDK安装包解压到/opt/module路径中(若路径不存在,则需新建),将JDK解压命令复制并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
- 修改容器中/etc/profile文件,设置JDK环境变量并使其生效,配置完毕后在master节点分别执行“java -version”和“javac”命令,将命令行执行结果分别截图并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
- 请完成host相关配置,将三个节点分别命名为master、slave1、slave2,并做免密登录,用scp命令并使用绝对路径从master复制JDK解压后的安装文件到slave1、slave2节点(若路径不存在,则需新建),并配置slave1、slave2相关环境变量,将全部scp复制JDK的命令复制并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
- 在master将Hadoop解压到/opt/module(若路径不存在,则需新建)目录下,并将解压包分发至slave1、slave2中,其中master、slave1、slave2节点均作为datanode,配置好相关环境,初始化Hadoop环境namenode,将初始化命令及初始化结果截图(截取初始化结果日志最后20行即可)粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
- 启动Hadoop集群(包括hdfs和yarn),使用jps命令查看master节点与slave1节点的Java进程,将jps命令与结果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下。
子任务二:Kafka安装配置
本任务需要使用root用户完成相关配置,已安装Hadoop及需要配置前置环境,具体要求如下:
- 从宿主机/opt目录下将文件zookeeper-3.4.6.tar.gz、kafka_2.12-2.0.0.tgz复制到容器master中的/opt/software路径中(若路径不存在,则需新建),将Master节点Zookeeper,Kafka安装包解压到/opt/module目录下,将Kafka解压命令复制并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
- 配置好zookeeper,其中zookeeper使用集群模式,分别将master、slave1、slave2作为其节点(若zookpeer已安装配置好,则无需再次配置),配置好Kafka的环境变量,使用kafka-server-start.sh --version查看Kafka的版本内容,并将命令和结果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
- 完善其他配置并分发Kafka文件到slave1、slave2中,并在每个节点启动Kafka,创建Topic,其中Topic名称为installtopic,分区数为2,副本数为2,将创建命令和创建成果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下。
子任务三:Hive安装配置
本任务需要使用root用户完成相关配置,已安装Hadoop及需要配置前置环境,具体要求如下:
- 从宿主机/opt目录下将文件apache-hive-2.3.4-bin.tar.gz、mysql-connector-java-5.1.47.jar复制到容器master中的/opt/software路径中(若路径不存在,则需新建),将容器master节点Hive安装包解压到/opt/module目录下,将命令复制并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
- 设置Hive环境变量,并使环境变量生效,执行命令hive --version并将命令与结果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
- 完成相关配置并添加所依赖包,将MySQL数据库作为Hive元数据库。初始化Hive元数据,并通过schematool相关命令执行初始化,将初始化结果截图(范围为命令执行结束的最后10行)粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下。
任务B:离线数据处理(25分)
环境说明:
| 服务端登录地址详见各任务服务端说明。 补充说明:各节点可通过Asbru工具或SSH客户端进行SSH访问; 主节点MySQL数据库用户名/密码:root/123456(已配置远程连接); Hive的配置文件位于/opt/apache-hive-2.3.4-bin/conf/ Spark任务在Yarn上用Client运行,方便观察日志。 |
子任务一:数据抽取
编写Scala代码,使用Spark将MySQL库中表EnvironmentData,ChangeRecord,BaseMachine,MachineData,ProduceRecord全量抽取到Hive的ods库中对应表environmentdata,changerecord,basemachine, machinedata, producerecord中。
- 抽取MySQL的shtd_industry库中EnvironmentData表的全量数据进入Hive的ods库中表environmentdata,字段排序、类型不变,同时添加静态分区,分区字段为etldate,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。使用hive cli执行show partitions ods.environmentdata命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取MySQL的shtd_industry库中ChangeRecord表的全量数据进入Hive的ods库中表changerecord,字段排序、类型不变,同时添加静态分区,分区字段为etldate,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。使用hive cli执行show partitions ods.changerecord命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取MySQL的shtd_industry库中BaseMachine表的全量数据进入Hive的ods库中表basemachine,字段排序、类型不变,同时添加静态分区,分区字段为etldate,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。使用hive cli执行show partitions ods.basemachine命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取MySQL的shtd_industry库中ProduceRecord表的全量数据进入Hive的ods库中表producerecord,剔除ProducePrgCode字段,其余字段排序、类型不变,同时添加静态分区,分区字段为etldate,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。使用hive cli执行show partitions ods.producerecord命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取MySQL的shtd_industry库中MachineData表的全量数据进入Hive的ods库中表machinedata,字段排序、类型不变,同时添加静态分区,分区字段为etldate,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。使用hive cli执行show partitions ods.machinedata命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下。
子任务二:数据清洗
编写Hive SQL代码,将ods库中相应表数据全量抽取到Hive的dwd库中对应表中。表中有涉及到timestamp类型的,均要求按照yyyy-MM-dd HH:mm:ss,不记录毫秒数,若原数据中只有年月日,则在时分秒的位置添加00:00:00,添加之后使其符合yyyy-MM-dd HH:mm:ss。
- 抽取ods库中environmentdata的全量数据进入Hive的dwd库中表fact_environment_data,分区字段为etldate且值与ods库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。使用hive cli按照envoid降序排序,查询前5条数据,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取ods库中changerecord的全量数据进入Hive的dwd库中表fact_change_record,抽取数据之前需要对数据根据changeid和changemachineid进行联合去重处理,分区字段为etldate且值与ods库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。使用hive cli按照change_machine_id、change_id降序排序,查询前1条数据,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取ods库中basemachine的全量数据进入Hive的dwd库中表dim_machine,抽取数据之前需要对数据根据basemachineid进行去重处理。分区字段为etldate且值与ods库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。使用hive cli按照base_machine_id升序排序,查询dim_machine前2条数据,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取ods库中producerecord的全量数据进入Hive的dwd库中表fact_produce_record,分区字段为etldate且值与ods库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。使用hive cli按照produce_machine_id、produce_record_id升序排序,查询fact_produce_record前2条数据,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取ods库中machinedata的全量数据进入Hive的dwd库中表fact_machine_data。分区字段为etldate且值与ods库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。使用hive cli按照machine_id、machine_record_id降序排序,查询前1条数据,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下。
子任务三:指标计算
- 本任务基于以下2、3、4小题完成,使用DolphinScheduler完成第2、3、4题任务代码的调度。工作流要求,使用shell输出“开始”作为工作流的第一个job(job1),2、3、4题任务为并行任务且它们依赖job1的完成(命名为job2、job3、job4),job2、job3、job4完成之后使用shell输出“结束”作为工作流的最后一个job(endjob),endjob依赖job2、job3、job4,并将最终任务调度完成后的工作流截图,将截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 编写Scala代码,使用Spark根据dwd层的fact_environment_data表,统计检测设备(baseid)每月的PM10的检测平均浓度,然后将每个设备的每月平均浓度与厂内所有检测设备每月检测结果的平均浓度做比较(结果值为:高/低/相同),计算结果存入MySQL数据库shtd_industry的machine_runningAVG_compare表中(表结构如下),然后在Linux的MySQL命令行中根据检测设备ID降序排序,查询出前5条,将SQL语句复制粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下,将执行结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
| 字段 | 类型 | 中文含义 | 备注 |
| base_id | int | 检测设备ID | |
| machine_avg | varchar | 单设备检测平均值 | |
| factory_avg | varchar | 厂内所有设备平均值 | |
| comparison | varchar | 比较结果 | 高/低/相同 |
| env_date_year | varchar | 检测年份 | 如:2021 |
| env_date_month | varchar | 检测月份 | 如:12 |
- 编写Scala代码,使用Spark根据dwd层的fact_change_record表统计每个月(change_start_time的月份)、每个设备、每种状态的时长,若某状态当前未结束(即change_end_time值为空)则该状态不参与计算,计算结果存入MySQL数据库shtd_industry的machine_state_time表中(表结构如下),然后在Linux的MySQL命令行中根据设备id、状态持续时长均为降序排序,查询出前10条,将SQL语句复制粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下,将执行结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
| 字段 | 类型 | 中文含义 | 备注 |
| machine_id | int | 设备id | |
| change_record_state | varchar | 状态 | |
| duration_time | varchar | 持续时长(秒) | 当月该状态的时长和 |
| year | int | 年 | 状态产生的年 |
| month | int | 月 | 状态产生的月 |
- 编写Scala代码,使用Spark根据dwd层的fact_change_record表关联dim_machine表统计每个车间中所有设备运行时长(即设备状态为“运行”)的中位数在哪个设备(为偶数时,两条数据原样保留输出),若某个设备运行状态当前未结束(即change_end_time值为空)则该状态不参与计算,计算结果存入MySQL数据库shtd_industry的machine_running_median表中(表结构如下),然后在Linux的MySQL命令行中根据所属车间、设备id均为降序排序,查询出前5条数据,将SQL语句复制粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下,将执行结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
| 字段 | 类型 | 中文含义 | 备注 |
| machine_id | int | 设备id | |
| machine_factory | int | 所属车间 | |
| total_running_time | int | 运行总时长 | 结果以秒为单位 |
任务C:数据挖掘(10分)
环境说明:
| 服务端登录地址详见各任务服务端说明。 补充说明:各节点可通过Asbru工具或SSH客户端进行SSH访问; 主节点MySQL数据库用户名/密码:root/123456(已配置远程连接); Hive的配置文件位于/opt/apache-hive-2.3.4-bin/conf/ Spark任务在Yarn上用Client运行,方便观察日志。 该任务均使用Scala编写,利用Spark相关库完成。 |
子任务一:特征工程
- 根据dwd库中fact_machine_data表(或MySQL的shtd_industry库中MachineData表),根据以下要求转换:获取最大分区(MySQL不用考虑)的数据后,首先解析列machine_record_data(MySQL中为MachineRecordData)的数据(数据格式为xml,采用dom4j解析,解析demo在客户端/home/ubuntu/Documents目录下),并获取每条数据的主轴转速,主轴倍率,主轴负载,进给倍率,进给速度,PMC程序号,循环时间,运行时间,有效轴数,总加工个数,已使用内存,未使用内存,可用程序量,注册程序量等相关的值(若该条数据没有相关值,则按下表设置默认值),同时转换machine_record_state字段的值,若值为报警,则填写1,否则填写0,以下为表结构,将数据保存在dwd.fact_machine_learning_data,使用hive cli按照machine_record_id升序排序,查询dwd.fact_machine_learning_data前1条数据,将结果截图粘贴至客户端桌面【Release\任务C提交结果.docx】中对应的任务序号下。
dwd.fact_machine_learning_data表结构:
| 字段 | 类型 | 中文含义 | 备注 |
| machine_record_id | int | 主键 | |
| machine_id | double | 设备id | |
| machine_record_state | double | 设备状态 | 默认0.0 |
| machine_record_mainshaft_speed | double | 主轴转速 | 默认0.0 |
| machine_record_mainshaft_multiplerate | double | 主轴倍率 | 默认0.0 |
| machine_record_mainshaft_load | double | 主轴负载 | 默认0.0 |
| machine_record_feed_speed | double | 进给倍率 | 默认0.0 |
| machine_record_feed_multiplerate | double | 进给速度 | 默认0.0 |
| machine_record_pmc_code | double | PMC程序号 | 默认0.0 |
| machine_record_circle_time | double | 循环时间 | 默认0.0 |
| machine_record_run_time | double | 运行时间 | 默认0.0 |
| machine_record_effective_shaft | double | 有效轴数 | 默认0.0 |
| machine_record_amount_process | double | 总加工个数 | 默认0.0 |
| machine_record_use_memory | double | 已使用内存 | 默认0.0 |
| machine_record_free_memory | double | 未使用内存 | 默认0.0 |
| machine_record_amount_use_code | double | 可用程序量 | 默认0.0 |
| machine_record_amount_free_code | double | 注册程序量 | 默认0.0 |
| machine_record_date | timestamp | 记录日期 | |
| dwd_insert_user | string | ||
| dwd_insert_time | timestamp | ||
| dwd_modify_user | string | ||
| dwd_modify_time | timestamp |
子任务二:报警预测
- 根据子任务一的结果,建立随机森林(随机森林相关参数可自定义,不做限制),使用子任务一的结果训练随机森林模型,然后再将hive中dwd.fact_machine_learning_data_test(该表字段含义与dwd.fact_machine_learning_data表相同,machine_record_state列值为空,表结构自行查看)转成向量,预测其是否报警将结果输出到MySQL数据库shtd_industry的ml_result表中(表结构如下)。在Linux的MySQL命令行中查询出machine_record_id为1、8、20、28和36的5条数据,将SQL语句复制并粘贴至客户端桌面【Release\任务C提交结果.docx】中对应的任务序号下,将执行结果截图粘贴至客户端桌面【Release\任务C提交结果.docx】中对应的任务序号下。
ml_result表结构:
| 字段 | 类型 | 中文含义 | 备注 |
| machine_record_id | int | 主键 | |
| machine_record_state | double | 设备状态 | 报警为1,其他状态则为0 |
任务D:数据采集与实时计算(20分)
环境说明:
| 服务端登录地址详见各任务服务端说明。 补充说明:各节点可通过Asbru工具或SSH客户端进行SSH访问; Flink任务在Yarn上用per job模式(即Job分离模式,不采用Session模式),方便Yarn回收资源。 |
子任务一:实时数据采集
- 在主节点使用Flume采集/data_log目录下实时日志文件中的数据,将数据存入到Kafka的Topic中(Topic名称分别为ChangeRecord、ProduceRecord和EnvironmentData,分区数为4),将Flume采集ChangeRecord主题的配置截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下;
- 编写新的Flume配置文件,将数据备份到HDFS目录/user/test/flumebackup下,要求所有主题的数据使用同一个Flume配置文件完成,将Flume的配置截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下。
子任务二:使用Flink处理Kafka中的数据
编写Scala代码,使用Flink消费Kafka中的数据并进行相应的数据统计计算。
- 使用Flink消费Kafka中EnvironmentData主题的数据,监控各环境检测设备数据,当温度(Temperature字段)持续3分钟高于38度时记录为预警数据。将结果存入Redis中,key值为“env_temperature_monitor”,value值为“设备id-预警信息生成时间,预警信息”(预警信息生成时间格式:yyyy-MM-dd HH:mm:ss)。使用redis cli以HGETALL key方式获取env_temperature_monitor值,将结果截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下,需要Flink启动运行6分钟以后再截图;
注:时间语义使用Processing Time。
value示例:114-2022-01-01 14:12:19,设备114连续三分钟温度高于38度请及时处理!
中文内容及格式必须为示例所示内容。
同一设备3分钟只预警一次。
- 使用Flink消费Kafka中ChangeRecord主题的数据,每隔1分钟输出最近3分钟的预警次数最多的设备。将结果存入Redis中,key值为“warning_last3min_everymin_out”,value值为“窗口结束时间,设备id”(窗口结束时间格式:yyyy-MM-dd HH:mm:ss)。使用redis cli以HGETALL key方式获取warning_last3min_everymin_out值,将结果截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下,需两次截图,第一次截图和第二次截图间隔1分钟以上,第一次截图放前面,第二次截图放后面;
注:时间语义使用Processing Time。
- 使用Flink消费Kafka中ChangeRecord主题的数据,实时统计每个设备从其他状态转变为“运行”状态的总次数。将结果存入MySQL数据库shtd_industry的change_state_other_to_run_agg表中(表结构如下)。请将任务启动命令复制粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下,启动1分钟后根据change_machine_id降序查询change_state_other_to_run_agg表并截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下,启动2分钟后根据change_machine_id降序查询change_state_other_to_run_agg表并再次截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下。
注:时间语义使用Processing Time。
change_state_other_to_run_agg表:
| 字段 | 类型 | 中文含义 |
| change_machine_id | int | 设备id |
| last_machine_state | varchar | 上一状态。即触发本次统计的最近一次非运行状态 |
| total_change_torun | int | 从其他状态转为运行的总次数 |
| in_time | varchar | flink计算完成时间(yyyy-MM-dd HH:mm:ss) |
任务E:数据可视化(15分)
环境说明:
| 数据接口地址及接口描述详见各任务服务端说明。 注:所有数据排序按照接口返回数据顺序处理即可,不用特意排序。 |
子任务一:用饼状图展示每日各状态总时长
编写Vue工程代码,根据接口,用饼状图展示每日各状态总时长(秒),同时将用于图表展示的数据结构在浏览器的console中进行打印输出,将图表可视化结果和浏览器console打印结果分别截图并粘贴至客户端桌面【Release\任务E提交结果.docx】中对应的任务序号下。
子任务二:用柱状图展示设备历史各个状态持续时长
编写Vue工程代码,根据接口,用柱状图展示接口所有数据中各设备各个状态持续时长(秒),同时将用于图表展示的数据结构在浏览器的console中进行打印输出,将图表可视化结果和浏览器console打印结果分别截图并粘贴至客户端桌面【Release\任务E提交结果.docx】中对应的任务序号下。
子任务三:用单轴散点图展示各设备加工每件产品所需时长
编写Vue工程代码,根据接口,用单轴散点图展示各设备加工每件产品所需时长(秒),同时将用于图表展示的数据结构在浏览器的console中进行打印输出,将图表可视化结果和浏览器console打印结果分别截图并粘贴至客户端桌面【Release\任务E提交结果.docx】中对应的任务序号下。
子任务四:用散点图展示环境湿度变化
编写Vue工程代码,根据接口,用基础散点图展示设备所处环境的湿度(Humidity)的变化,同时将用于图表展示的数据结构在浏览器的console中进行打印输出,将图表可视化结果和浏览器console打印结果分别截图并粘贴至客户端桌面【Release\任务E提交结果.docx】中对应的任务序号下。
子任务五:用折柱混合图展示设备日均产量和所在车间日均产量
编写Vue工程代码,根据接口,用折柱混合图展示设备日均产量(四舍五入保留两位小数)和所在车间日均产量(四舍五入保留两位小数),其中柱状图展示各设备的日均产量,折线图展示该设备所在车间的日均产量,同时将用于图表展示的数据结构在浏览器的console中进行打印输出,将图表可视化结果和浏览器console打印结果分别截图并粘贴至客户端桌面【Release\任务E提交结果.docx】中对应的任务序号下。
任务F:综合分析(10分)
子任务一:Hadoop有哪些类型的调度器?简要说明其工作方法。
简要描述Hadoop有哪些类型的调度器并简要说明其工作方法,将内容编写至客户端桌面【Release\任务F提交结果.docx】中对应的任务序号下。
子任务二:请简述Spark中共享变量的基本原理和用途。
请简述Spark中共享变量的基本原理和用途,将内容编写至客户端桌面【Release\任务F提交结果.docx】中对应的任务序号下。
子任务三:请根据可视化部分设备各状态时长等信息进行以下分析。
根据设备各状态运行时长等信息,分析哪些设备使用率高,将内容编写至客户端桌面【Release\任务F提交结果.docx】中对应的任务序号下。
相关文章:

GZ033 大数据应用开发赛题第08套
2023年全国职业院校技能大赛 赛题第08套 赛项名称: 大数据应用开发 英文名称: Big Data Application Development 赛项组别: 高等职业教育组 赛项编号: GZ033 …...

【SpringMvc】SpringMvc +MyBatis整理
🎄欢迎来到边境矢梦的csdn博文🎄 🎄本文主要梳理 Java 框架 中 SpringMVC的知识点和值得注意的地方 🎄 🌈我是边境矢梦,一个正在为秋招和算法竞赛做准备的学生🌈 🎆喜欢的朋友可以关…...
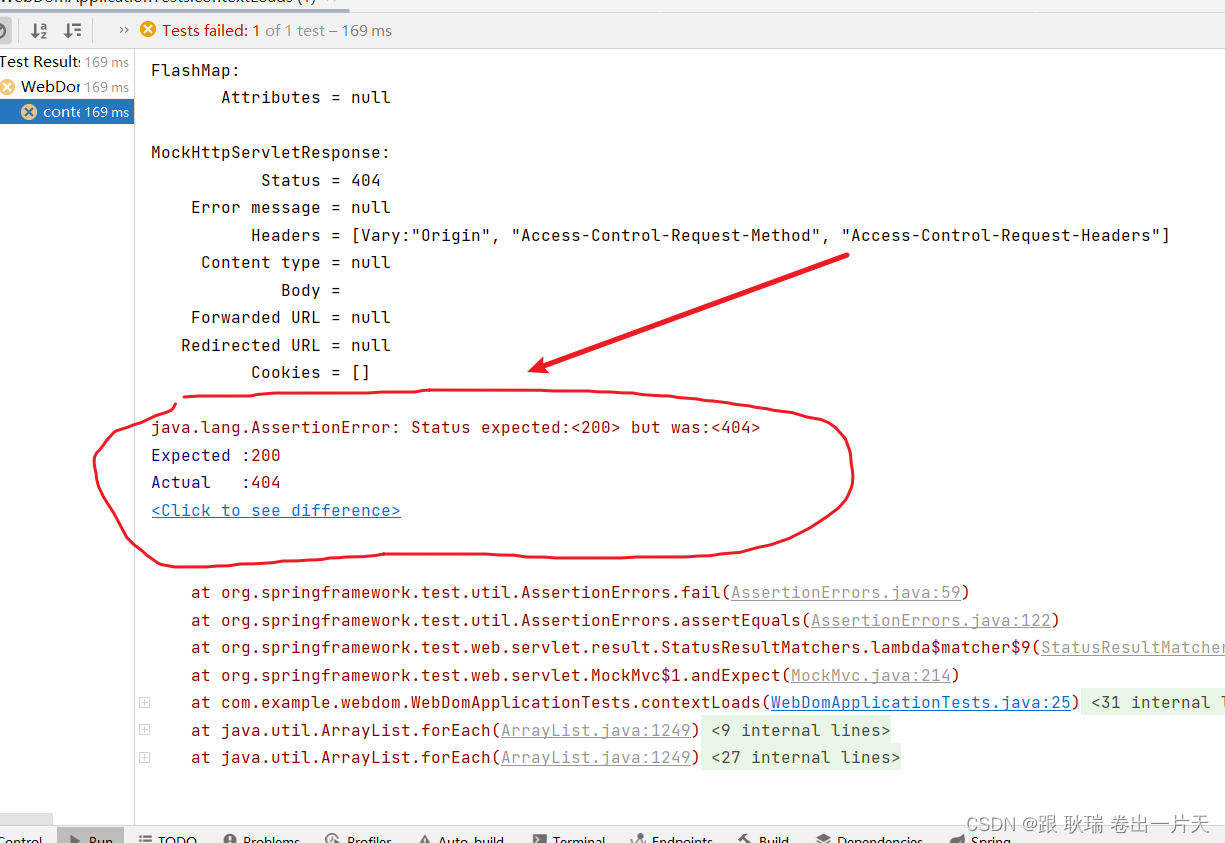
java springboot测试类鉴定虚拟MVC运行值与预期值是否相同
好 上文java springboot在测试类中构建虚拟MVC环境并发送请求中 我们模拟的MVC环境 发送了一个请求 我们这次需要 对比 预期值和运行值是否一直 这里 我们要用一个 MockMvcResultMatchers 他提供了非常多的校验类型 例如 请求有没有成功 有没有包含请求头信息 等等 这里 我们做…...
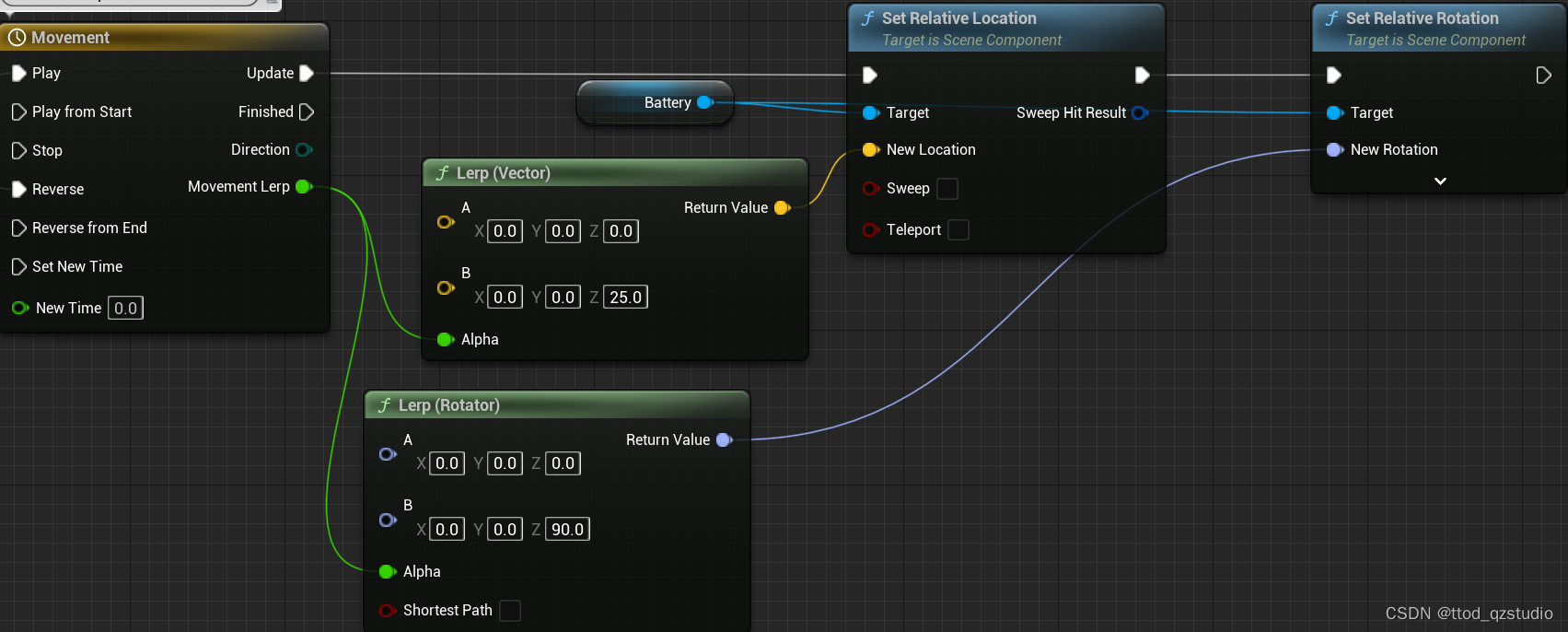
UE5的TimeLine的理解
一直以来,我对动画的理解一直是这样的: 所谓动画,就是可导致可视化内容变化的参数和时间的对应关系。 我不能说这个观点现在过时了,只能说自己狭隘了。因为UE的TimeLine的设计理念真让人竖大拇指。 当我第一次看到TimeLine节点的…...

react原理及合成事件原理
文章目录 react的理解react创建组件的三种写法react的工作原理初始化的渲染流程。页面更新的流程。diffing 算法计算更新视图diff策略 react合成事件原理一、React合成事件的概念二、React合成事件的原理三、React合成事件的优势四、React合成事件的使用方法五、总结 react的理…...
独立版求职招聘平台小程序开发
小程序招聘系统开发 我们开发了一款高效、便捷的互联网招聘平台。在这里,可以轻松实现企业入驻、职位发布、在线求职、精准匹配职位和人才,以及参与招聘会等功能。目标是为求职者和企业搭建一个连接彼此的桥梁,帮助您更快地找到满意的工作&…...
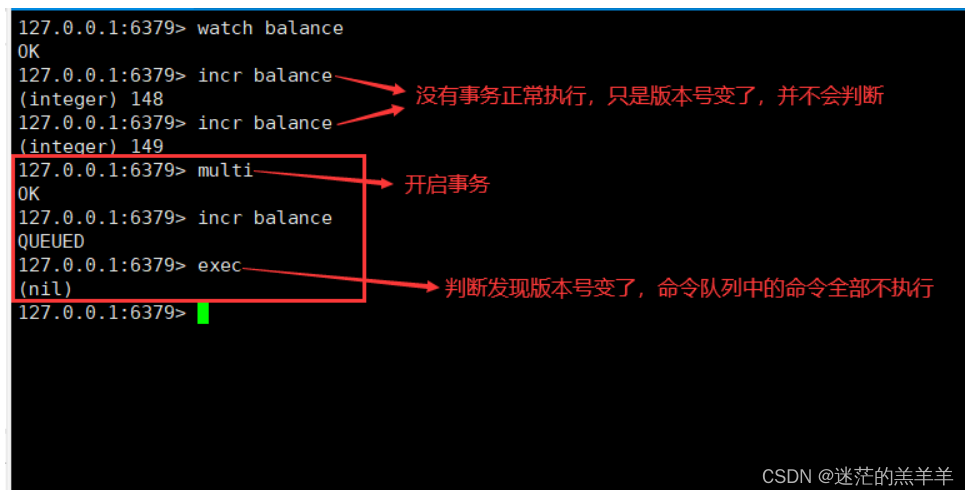
Redis事务+秒杀案例
Redis事务是一个单独的隔离操作,是指将多条命令放在一个命令队列当中,按顺序执行,保证多个命令在同一个事务中执行而不受其他客户端的影响。 通俗来说就是:串联多个命令防止别的命令插队。 1.Multi、Exec、discard 在输入Multi命…...
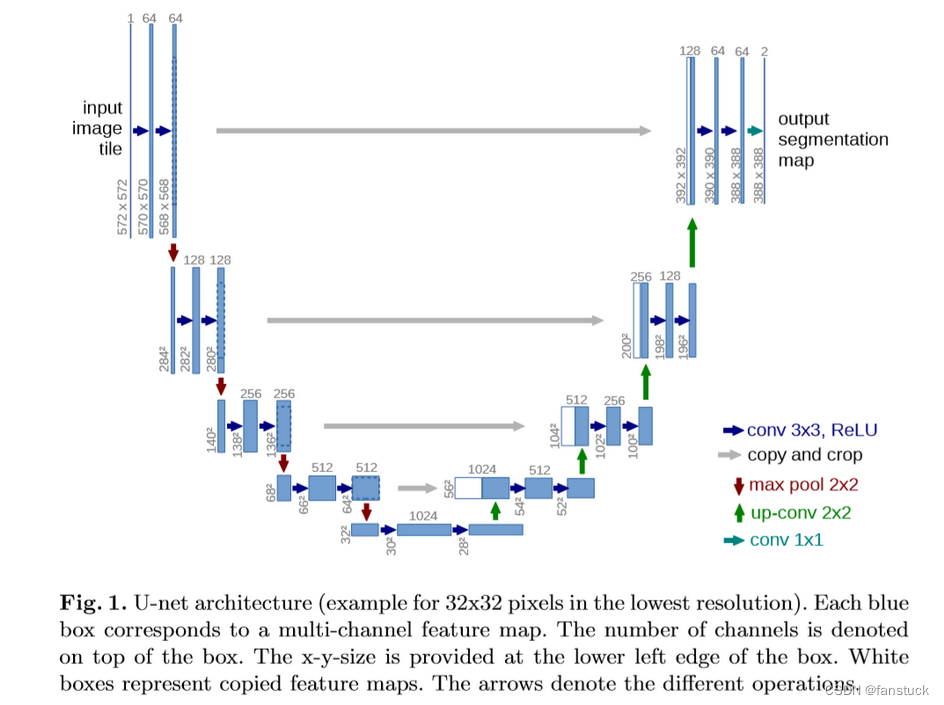
目标分割技术-语义分割总览
前言 博主现任高级人工智能工程师,曾发表多篇SCI且获得过多次国际竞赛奖项,理解各类模型原理以及每种模型的建模流程和各类题目分析方法。目的就是为了让零基础快速使用各类代码模型,每一篇文章都包含实战项目以及可运行代码。欢迎大家订阅一…...

基于C#实现最长公共子序列
一、作用 最长公共子序列的问题常用于解决字符串的相似度,是一个非常实用的算法,作为码农,此算法是我们的必备基本功。 二、概念 举个例子,cnblogs 这个字符串中子序列有多少个呢?很显然有 27 个,比如其…...

物联网AI MicroPython学习之语法 SPI串行外设通信
学物联网,来万物简单IoT物联网!! SPI 介绍 模块功能: SPI串行外设驱动 接口说明 SPI - 构建SPI对象 函数原型:SPI(id, baudrate,polarity, phase,sck, mosi, miso)参数说明: 参数类型必选参…...
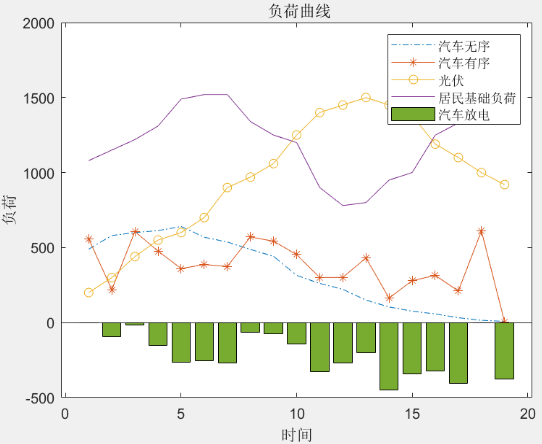
电动汽车充放电V2G模型MATLAB代码
微❤关注“电气仔推送”获得资料(专享优惠) 主要内容: 本程序主要建立电动汽车充放电V2G模型,采用粒子群算法,在保证电动汽车用户出行需求的前提下,为了使工作区域电动汽车尽可能多的消纳供给商场基础负荷…...
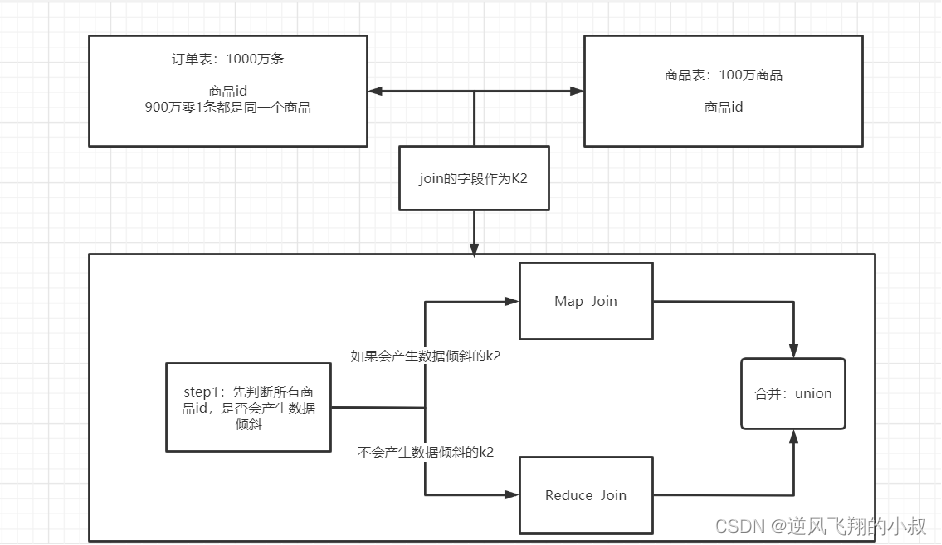
【大数据Hive】hive 优化策略之job任务优化
目录 一、前言 二、hive执行计划 2.1 hive explain简介 2.1.1 语法格式 2.1.2 查询计划阶段说明 2.2 操作演示 2.2.1 不加条件的查询计划分析 2.2.2 带条件的查询计划分析 三、MapReduce属性优化 3.1 本地模式 3.1.1 本地模式参数设置 3.1.2 本地模式操作演示 3.2 …...
OpenAI再次与Altman谈判;ChatGPT Voice正式上线
11月22日,金融时报消息,OpenAI迫于超过700名员工联名信的压力,再次启动了与Sam Altman的谈判,希望他回归董事会。 在Sam确定加入微软后,OpenAI超700名员工签署了一封联名信,要求Sam和Greg Brockman&#x…...

【JS】Chapter15-高阶技巧
站在巨人的肩膀上 黑马程序员前端JavaScript入门到精通全套视频教程,javascript核心进阶ES6语法、API、js高级等基础知识和实战教程 (十五)高阶技巧 1. 深浅拷贝 开发中我们经常需要复制一个对象。如果直接用赋值会有下面问题:/…...
Google Chrome 任意文件读取 (CVE-2023-4357)漏洞
漏洞描述 该漏洞的存在是由于 Google Chrome 中用户提供的 XML 输入验证不足。远程攻击者可以创建特制网页,诱骗受害者访问该网页并获取用户系统上的敏感信息。远程攻击者可利用该漏洞通过构建的 HTML 页面绕过文件访问限制,导致chrome任意文件读取。Li…...
)
psql 模式(SCHEMA)
模式是数据库领域的一个基本概念,有些数据库把模式和用户合二为一了,而postgresql则是有清晰的模式定义。 模式是数据库中的一个概念,可以理解为一个命名空间或目录,不同模式下可以有相同名称的表、函数等对象而不会产生冲突。提出…...

网络吞吐量 公网带宽有关吗?
环境: 华为交换机 深信服防火墙 问题描述: 网络吞吐量 公网带宽有关吗? 解决方案: 网络吞吐量网络吞吐量是指在特定时间内通过网络传输的数据量。它衡量了网络设备(如防火墙、交换机、路由器)或网络连…...
Linux设置静态IP
Linux设置静态IP 使用ip addr查看ip,如下所示就是动态IP 1、什么是静态IP? 静态ip就是固定的ip,需要手动设置。静态IP地址(又称固定IP地址)是长期分配给一台计算机或网络设备使用的 IP 地址。一般来说,一…...
六、Big Data Tools安装
1、安装 在Jetbrains的任意一款产品中,均可安装Big Data Tools这个插件。 2、示例 下面以DadaGrip为例: (1)打开插件中心 (2)搜索Big Data Tools,下载 3、链接hdfs (1࿰…...
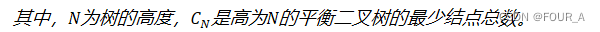
数据结构【DS】特殊二叉树
完全二叉树 叶子结点只能出现在最下层和次下层, 最下层的叶子结点集中在树的左部完全二叉树中, 度为1的节点数 0个或者1个【计算时可以用这个快速计算, 配合𝑛0𝑛21】若n为奇数,则分支节点每个都有左右孩子;若n为偶数࿰…...

AListFlutter常见问题解决方案:从安装到运行的全方位排错
AListFlutter常见问题解决方案:从安装到运行的全方位排错 【免费下载链接】AListFlutter AList 安卓版本,APK安装即用,无需Root或Termux。 项目地址: https://gitcode.com/gh_mirrors/al/AListFlutter AListFlutter是一款无需Root或Te…...

AI自动化内容发布:基于MCP协议构建Substack智能助手
1. 项目概述:一个让AI帮你写Substack的“智能副驾”最近在折腾AI工作流的朋友,可能都听说过MCP(Model Context Protocol)这个概念。简单来说,它就像给AI大模型(比如Claude、GPT)装上了一套标准化…...

Bibliometrix ::biblioshiny全界面介绍
引言 相信但凡接触过 R 语言文献计量分析的朋友,都听过Bibliometrix的大名,而它自带的biblioshiny交互式界面,简直是我们不想写代码、又想快速出分析结果的人的福音!但不知道有没有人和我当初一样,刚打开这个界面的时…...
)
Python 数据分析基础入门:《Excel Python:飞速搞定数据分析与处理》学习笔记系列(附录 A Conda 环境)
Excel Python:飞速搞定数据分析与处理 附录 A Conda 环境 A.1 创建新的Conda环境 在 Anaconda Prompt 中执行下列命令以创建一个名为 xl38 的新环境,该环境使用了 Python 3.8: (base)> conda create --name xl38 python3.8安装完成之后…...

ARM调试状态原理与寄存器访问机制详解
1. ARM调试状态基础解析调试状态(Debug State)是ARM处理器为开发者提供的一种特殊运行模式,它允许处理器暂停正常指令流执行,转而进入调试环境。这种机制在嵌入式系统开发、芯片验证和故障排查中扮演着关键角色。当处理器进入调试…...

深度解析强化学习第九周:掌握TRPO和PPO高级策略优化技术的终极指南
深度解析强化学习第九周:掌握TRPO和PPO高级策略优化技术的终极指南 【免费下载链接】Practical_RL A course in reinforcement learning in the wild 项目地址: https://gitcode.com/gh_mirrors/pr/Practical_RL GitHub 加速计划 / pr / Practical_RL项目提供…...

fnlp性能优化指南:模型压缩与并行计算提升处理速度300%
fnlp性能优化指南:模型压缩与并行计算提升处理速度300% 【免费下载链接】fnlp 中文自然语言处理工具包 Toolkit for Chinese natural language processing 项目地址: https://gitcode.com/gh_mirrors/fn/fnlp fnlp是一款功能强大的中文自然语言处理工具包&am…...

FluxCD v2实战:基于Kustomize与Helm的GitOps自动化部署指南
1. 项目概述:一个声明式GitOps的实战演练场如果你正在寻找一个能帮你快速上手FluxCD v2,并理清它如何与Kustomize和Helm协同工作的“一站式”示例项目,那么fluxcd/flux2-kustomize-helm-example这个官方仓库就是你梦寐以求的宝藏。它不是一个…...

SkyBridge:构建AI模型统一接入层,实现多模型智能路由与生产级运维
1. 项目概述:当AI模型需要“搭桥”时,我们做了什么最近在折腾大模型应用落地的朋友,估计都绕不开一个核心痛点:模型能力很强,但怎么把它稳定、高效、低成本地集成到自己的业务流里,是个大问题。尤其是在面对…...

文件大小和token 的 256k 是一回事吗?NO
文件大小和token 的 256k 是一回事吗 目录 文件大小和token 的 256k 是一回事吗核心结论先给清楚一、核心计算:1MB Excel到底对应多少Token?二、不同模型的可行性判断1. 常规主流模型(90%用户的日常使用场景):完全不可…...