Django批量插入数据及分页器
文章目录
- 一、批量插入数据
- 二、分页
- 1.分页器的思路
- 2.用一个案例试试
- 3.自定义分页器
一、批量插入数据
当我们需要大批量创建数据的时候,如果一条一条的去创建或许需要猴年马月 我们可以先试一试for循环试试
我们首先建立一个模型类来创建一个表
models.py;建议连接到MySQL数据库下进行实验
class Book(models.Model):name = models.CharField(max_length=32)'记得创建好模型类后,执行数据库迁移命令:makemigrations、migrate'
配置路由文件urls.py
from django.conf.urls import urlfrom django.contrib import adminfrom app import viewsurlpatterns = [url(r'^admin/', admin.site.urls),url(r'^data/', views.data),]
'html代码'<div class="col-md-8 col-md-offset-2">{% for book_obj in book_query %}<p class="text-center" style="font-size:20px;">{{ book_obj.name }}</p>{% endfor %}</div>'views.py'from app import modelsdef data(request):for i in range(10000):models.Book.objects.create(name=f"第{i}本书")book_query = models.Book.objects.all()return render(request,'data.html',locals())'''浏览器访问一个django路由,立刻创建1万条数据并展示到前端页面涉及到大批量数据的创建,直接使用create可能会造成数据库崩溃所以django就有一个专门来创建的参数就是 dulk_create还有dulk_update 效率极高'''
从最后批量插入数据的结果来看,效率太慢了。
原因就是每一次插入一条数据时,都需要和数据库做链接,因此创建效率就特别慢。
所以我们就用到了django专门用来批量创建数据的参数dulk_create
from app import modelsdef data(request):book_list = []for i in range(10000):book_obj = models.Book(name=f"第{i}本书")book_list.append(book_obj)'''上述代码可以简化为一行'''[models.Book(name=f"第{i}本书") for i in range(10000)]models.Book.objects.bulk_create(book_list) # 批量创建# models.Book.objects.bulk_update(book_list) # 批量更新book_query = models.Book.objects.all()return render(request,'data.html',locals())
最终结果:
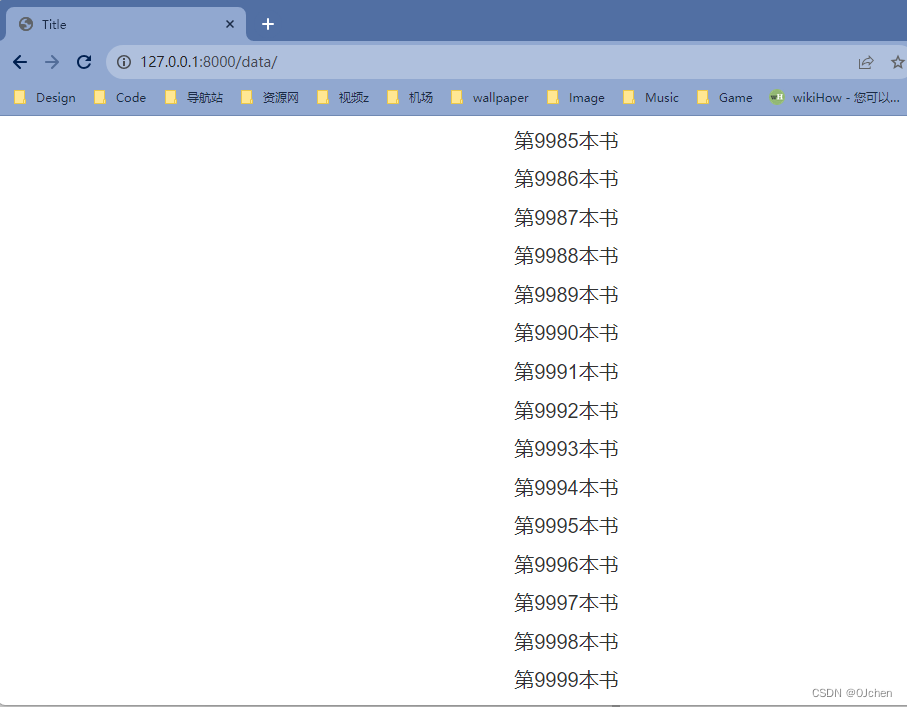
从浏览器展示中可以看到,使用了
bulk_create批量创建插入数据时,极快的创建完成后并在同一个页面展示出来了。但是这样展示出来的效果不够美观,所以我们需要把展示的数据进行分页展示
二、分页
这里我们将利用Django提供给我们的一个分页模块来帮助我们的页面达到一个分页的效果
1.分页器的思路
1.get请求也是可以携带参数的,所以我们在朝后端发送查看数据的同时可以携带一个参数告诉后端我们想看第几页的数据
current_page = request.GET.get('page',1) # 获取用户想访问的页码,如果没有,默认展示第一页try: # 由于后端接收到的前端数据是字符串类型所以我们这里做类型转换处理加异常捕捉current_page = int(current_page)except Exception as f:current_page = 1# 还需要定义页面到底展示几条数据per_page_num = 10 # 一页展示10条数据# 需要对总数据进行切片操作,需要确定切片起始位置和终止位置start_page = (current_page-1)*per_page_numend_page = current_page*per_page_num'''下面需要研究current_page、per_page_num、start_page、end_page四个参数之间的数据关系per_page_num = 10current_page start_page end_page1 0 102 10 203 20 30 4 30 40per_page_num = 5current_page start_page end_page1 0 52 5 103 10 15 4 15 20可以很明显的看出规律start_page = (current_page-1)*per_page_numend_page = current_page*per_page_num'''
2.数据总页面获取
内置方法之divmoddivmod(100,10)#(10,0) 10页divmod(101,10)#(10,1) 11页divmod(99,10)#(9,9) 10页'''余数只要不是0就需要在第一个数字上加一'''总共需要多少页数info_queryset = models.UserInfo.objects.all()all_count = info_queryset.count() # 数据总条数all_pager,more = divmod(all_count,per_page_num)if more: # 有余数则总页数加一all_pager += 1
3.利用start_page和end_page对总数据进行切片取值再传入前端页面就能够实现分页展示
后端info_list = models.UesrInfo.objects.all()[start_page:end_page]return render(request,'info.html',locals())前端{% for info in info_list %}<p>{{ info.name }}</p>{% endfor %}
4.由于模版语法没有range功能,但是我们需要循环产生很多分页标签,所以考虑后端生成传递给前端页面
后端
html_srt = ''xxx = current_pageif xxx<6:xxx = 6for i in range(xxx - 5,xxx+6)if current_page == i:html_str += '<li class="active"> <a href="?page=%s">%s</a></li>' %(i,i)else:html_str += '<li>href="?page=%s">%s</a></li>' % (i,i)
前端
{{ html_str }}
分页器主要是处理逻辑,代码最后很简单推导流程:1.queryset支持切片操作(正数)2.分页样式添加3.页码展示如果根据总数据和每页展示的数据得出总页码divmod()4.如何渲染出所有的页码标签前端模版语法不支持range 但是后端支持,我们可以在后端创建好html标签然后传递给html页面使用5.如何限制住展示的页面标签个数页码推荐使用奇数位(对称美),利用当前页前后固定位置来限制6.首尾页码展示范围问题上述是分页器组件的推导流程,我们无需真正编写django自带一个分页器组件,但是不是很好用,所以我们也可以自己自定义一个分页器
2.用一个案例试试
实验环境搭建
我们首先建立一个模型类来存储数据,因为要实现分页需要一定的数据量。
models.py;建议连接到MySQL数据库下进行实验
class UserInfo(models.Model):name = models.CharField(max_length=32)age = models.CharField(max_length=32)address = models.CharField(max_length=32)'记得创建好模型类后,执行数据库迁移命令:makemigrations、migrate'
配置路由文件urls.py
from django.conf.urls import urlfrom django.contrib import adminfrom app import viewsurlpatterns = [url(r'^admin/', admin.site.urls),url(r'^info/', views.info),]
tests.py 制作我们待会进行分页的数据,并将其写入数据库内
import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "nine.settings")import djangodjango.setup()from app import modelsfrom faker import Faker # 生成加的数据import random # 用来创建随机年龄obj_list = []for i in range(300): # 制作300条虚拟数据fake = Faker(locale='zh-CN') # 选择地区name = fake.name() # 生成随机名称age = random.randint(18,55) # 生成随机年龄address = fake.address() # 生成随机地址info_obj = models.UserInfo(name=name,age=age,address=address) # 生成一个个用户对象obj_list.append(info_obj)models.UserInfo.objects.bulk_create(obj_list) # 将一个个对象写入数据库内保存,一个对象对应一条记录
这里用到了一个Python第三方模块
faker,主要是生成各种各样的伪数据。具体使用自行搜索引擎查找。
views.py:先简单的搭建出模型,在web能看到数据效果
def info(request):info_list = models.UserInfo.objects.all() # 获取所有的数据all_count = info_list.count() # 通过计数获取有多少条数据per_page_num = 10 # 自定义每一页展示的数据条数,这个时候就可以动态计算了all_page_num,more = divmod(all_count,per_page_num) # divmod计算需要多少页来展示if more:all_page_num += 1 # 这样就获取到了所有的页码的数量current_page = request.GET.get('page',1) #获取用户指定的page,如果没有则默认展示第一页try:current_page = int(current_page) # 因为返回给前端的是字符串要转换成整型except ValueError: # 抛出异常类型错误current_page = 1html_str = ''xxx = current_pageif current_page < 6: # 一用户访问的页码小于6就等于6xxx = 6for i in range(xxx-5,xxx+6):if current_page == i:html_str += '<li class="active"><a href="?page=%s">%s</a></li>' % (i,i)else:html_str += '<li><a href="?page=%s">%s</a></li>' % (i,i)start_page = (current_page-1)*per_page_num # 定义出切片的起始位置end_page = current_page*per_page_num # 定义出切片的终止位置info_query = models.UserInfo.objects.all()[start_page:end_page]'''all返回的是QuerySet,可以看成列表套对象,也就是说支持索引取值现在的问题总可能让客户用源码修改页数吧?'''return render(request, 'info.html', locals())
info.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title><script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.7.1/jquery.min.js"></script><link href="https://cdn.bootcdn.net/ajax/libs/twitter-bootstrap/3.4.1/css/bootstrap.min.css" rel="stylesheet"><script src="https://cdn.bootcdn.net/ajax/libs/twitter-bootstrap/3.4.1/js/bootstrap.min.js"></script>
</head>
<body>
<div class="container"><div class="row"><div class="col-md-8 col-md-offset-2"><table class="table table-striped"><thead><tr><th class="text-center">ID</th><th class="text-center">姓名</th><th class="text-center">年龄</th><th class="text-center">住址</th></tr></thead><tbody>{% for info in info_query %}<tr class="text-center"><td>{{ info.id }}</td><td>{{ info.name }}</td><td>{{ info.age }}</td><td>{{ info.address }}</td></tr>{% endfor %}</tbody></table></div><nav aria-label="Page navigation" class="text-center"><ul class="pagination"><li><a href="#" aria-label="Previous"><span aria-hidden="true">«</span></a></li>{{ html_str | safe }}<li><a href="#" aria-label="Next"><span aria-hidden="true">»</span></a></li></ul></nav></div>
</div>
</body>
</html>
最终效果:
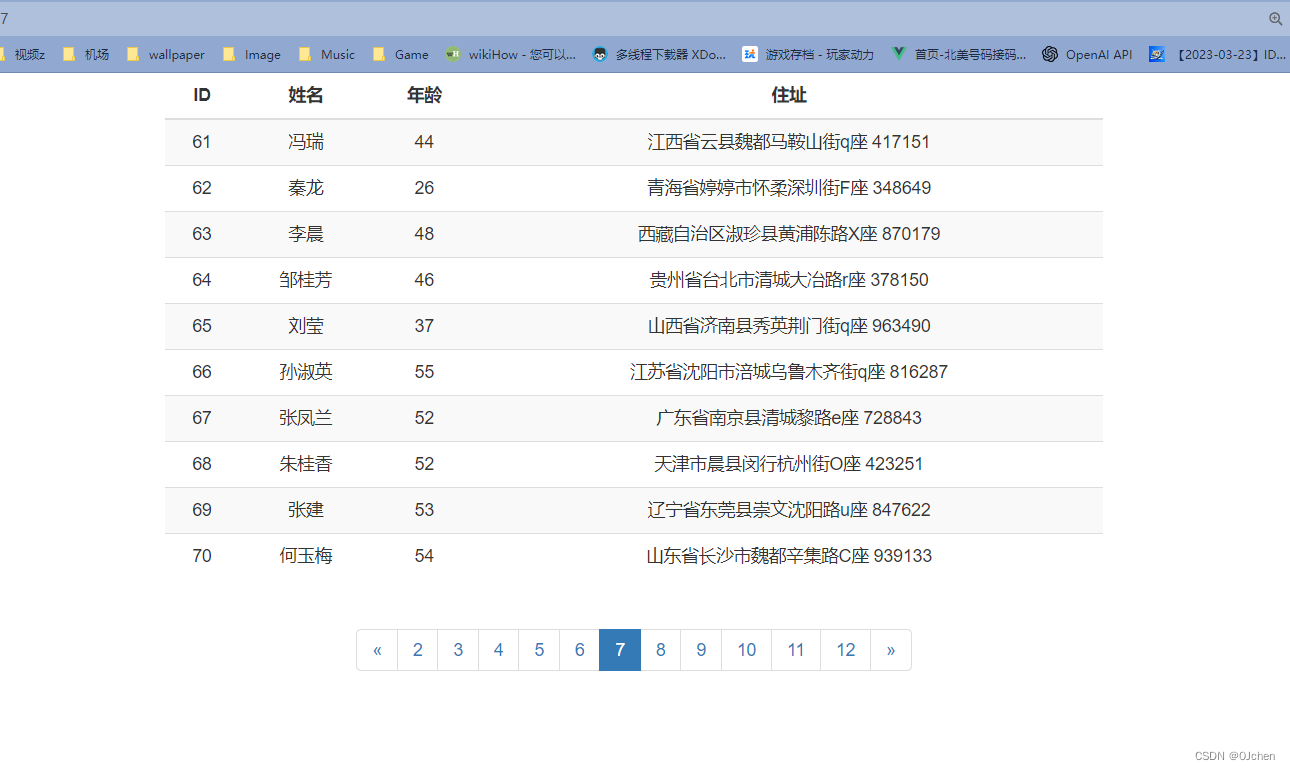
3.自定义分页器
是我们自己写好的分页器代码
一般是存在应用层.utils.mypage文件下的,我们需要的时候导入就行
class Pagination(object):def __init__(self, current_page, all_count, per_page_num=2, pager_count=11):"""封装分页相关数据:param current_page: 当前页:param all_count: 数据库中的数据总条数:param per_page_num: 每页显示的数据条数:param pager_count: 最多显示的页码个数"""try:current_page = int(current_page)except Exception as e:current_page = 1if current_page < 1:current_page = 1self.current_page = current_pageself.all_count = all_countself.per_page_num = per_page_num# 总页码all_pager, tmp = divmod(all_count, per_page_num)if tmp:all_pager += 1self.all_pager = all_pagerself.pager_count = pager_countself.pager_count_half = int((pager_count - 1) / 2)@propertydef start(self):return (self.current_page - 1) * self.per_page_num@propertydef end(self):return self.current_page * self.per_page_numdef page_html(self):# 如果总页码 < 11个:if self.all_pager <= self.pager_count:pager_start = 1pager_end = self.all_pager + 1# 总页码 > 11else:# 当前页如果<=页面上最多显示11/2个页码if self.current_page <= self.pager_count_half:pager_start = 1pager_end = self.pager_count + 1# 当前页大于5else:# 页码翻到最后if (self.current_page + self.pager_count_half) > self.all_pager:pager_end = self.all_pager + 1pager_start = self.all_pager - self.pager_count + 1else:pager_start = self.current_page - self.pager_count_halfpager_end = self.current_page + self.pager_count_half + 1page_html_list = []# 添加前面的nav和ul标签page_html_list.append('''<nav aria-label='Page navigation>'<ul class='pagination'>''')first_page = '<li><a href="?page=%s">首页</a></li>' % (1)page_html_list.append(first_page)if self.current_page <= 1:prev_page = '<li class="disabled"><a href="#">上一页</a></li>'else:prev_page = '<li><a href="?page=%s">上一页</a></li>' % (self.current_page - 1,)page_html_list.append(prev_page)for i in range(pager_start, pager_end):if i == self.current_page:temp = '<li class="active"><a href="?page=%s">%s</a></li>' % (i, i,)else:temp = '<li><a href="?page=%s">%s</a></li>' % (i, i,)page_html_list.append(temp)if self.current_page >= self.all_pager:next_page = '<li class="disabled"><a href="#">下一页</a></li>'else:next_page = '<li><a href="?page=%s">下一页</a></li>' % (self.current_page + 1,)page_html_list.append(next_page)last_page = '<li><a href="?page=%s">尾页</a></li>' % (self.all_pager,)page_html_list.append(last_page)# 尾部添加标签page_html_list.append('''</nav></ul>''')return ''.join(page_html_list)
自定义分页器的使用
django自带分页器模块但是使用起来很麻烦 所以我们自己封装了一个只需要掌握使用方式即可后端def info(request):info_list = models.UserInfo.objects.all()from app.utils.my_page import Pagination # 导入current_page = request.GET.get('page') # 获取当前页page_obj = Pagination(current_page=current_page,all_count=info_list.count(),per_page_num=10) # 生成对象info_query = info_list[page_obj.start:page_obj.end] # 切片html = page_obj.page_htmlreturn render(request,'info.html',locals())
前端
<div class="container"><div class="row"><div class="col-md-8 col-md-offset-2"><table class="table table-striped"><thead><tr><th class="text-center">ID</th><th class="text-center">姓名</th><th class="text-center">年龄</th><th class="text-center">住址</th></tr></thead><tbody>{% for info in info_query %}<tr class="text-center"><td>{{ info.id }}</td><td>{{ info.name }}</td><td>{{ info.age }}</td><td>{{ info.address }}</td></tr>{% endfor %}</tbody></table>{{ html | safe }}</div></div></div>
最终结果:
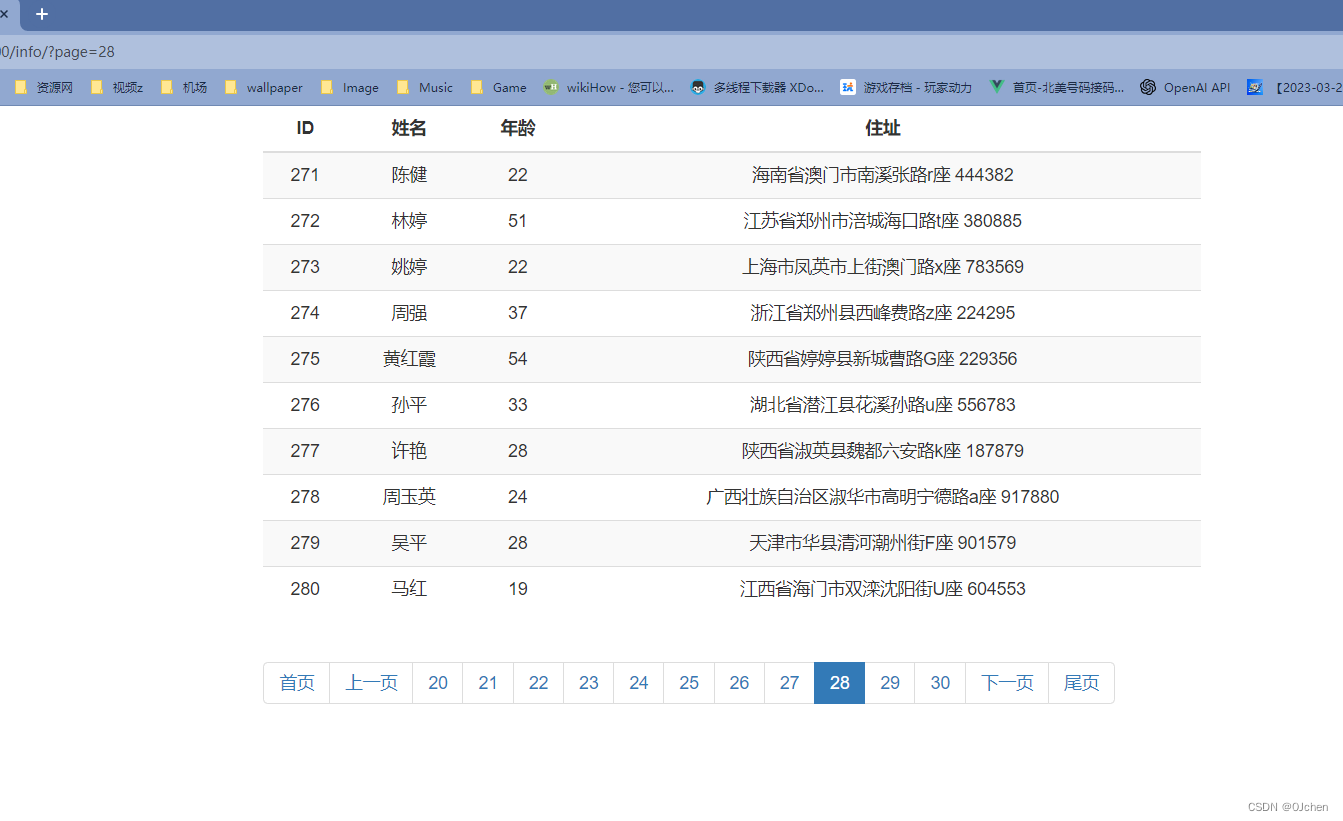
相关文章:
Django批量插入数据及分页器
文章目录 一、批量插入数据二、分页1.分页器的思路2.用一个案例试试3.自定义分页器 一、批量插入数据 当我们需要大批量创建数据的时候,如果一条一条的去创建或许需要猴年马月 我们可以先试一试for循环试试 我们首先建立一个模型类来创建一个表 models.pyÿ…...

PHP 语法||PHP 变量
PHP 脚本在服务器上执行,然后将纯 HTML 结果发送回浏览器。 基本的 PHP 语法 PHP 脚本可以放在文档中的任何位置。 PHP 脚本以 <?php 开始,以 ?> 结束: <?php // PHP 代码 ?> 值得一提的是,通过设定php.ini的相…...
】if语句详解)
【python基础(四)】if语句详解
文章目录 一. 一个简单示例二. 条件测试1. 检查多个条件1.1. 使用and关联多个条件1.2. 使用or检查多个条件1.3. in的判断 2. 布尔表达式 三. if语句1. 简单的if语句2. if-else语句3. if-elif-else结构4. 使用多个elif代码块5. 省略else代码块 四. 使用if语句处理列表1. 检查特殊…...

Spring Boot中常用的参数传递注解
RequestParam:用于将请求参数绑定到控制器处理方法的参数上,适用于GET请求。PathVariable:用于获取请求URL中的动态参数,适用于RESTful风格的URL。RequestBody:用于将请求体中的JSON字符串绑定到控制器处理方法的参数上…...

Quartz .Net 的简单使用
参考了:c# .net framework 4.5.2 , Quartz.NET 3.0.7 - runliuv - 博客园 (cnblogs.com) https://www.cnblogs.com/personblog/p/11277527.html, Quartz.NET 作业调度(一):Test - 简书 自己要轮询的任务:…...

面试Java笔试题精选解答
文章目录 热身级别数组中重复的数字思路:使用map或HashSet来遍历一遍就可以找出重复的字符样例解答 用两个栈实现队列思路:Stack1正向进入,队头在栈底,用于进队列操作;Stack2是Stack1倒栈形成,队头在栈顶&a…...

使用Python画一棵树
🎊专栏【不单调的代码】 🍔喜欢的诗句:更喜岷山千里雪 三军过后尽开颜。 🎆音乐分享【如愿】 🥰欢迎并且感谢大家指出我的问题 文章目录 🌹Turtle模块🎄效果🌺代码🛸代码…...
Nginx 负载均衡)
nginx学习(4)Nginx 负载均衡
负载均衡:是将负载分摊到不同的服务单元,既保证服务的可用性,又保证响应 足够快,给用户很好的体验。 在 linux 下有 Nginx、LVS、Haproxy 等等服务可以提供负载均衡服 务, 而且 Nginx 提供了几种分配方式(策略)&#…...

WSL登录时提示nsenter: cannot open /proc/320/ns/time: No such file or directory的解决办法
在登录 WSL 的 Ubuntu 时,不仅要求 root 权限,还登录失败,提示“nsenter: cannot open /proc/320/ns/time: No such file or directory”。 解决办法是在 powershell 中执行 “wsl – sudo vi /etc/profile”命令,删除文件内容&a…...

git修改远程分支名称
先拉取old_branch最新代码到本地 git checkout old_branchgit pull origin old_branch本地修改后并推送 git branch -m old_branch new_branch # 修改分支名称git push --delete origin old_branch # 删除在远程的老分支推送新分支 git push origin new_branch本地分支与远…...
Django 入门学习总结7-静态文件管理
Django Web框架有关门的静态文件管理机制。 首先,在polls文件夹中创建static文件,Django 将会自动地在这里查询静态文件。 Django 框架在配置 STATICFILES_FINDERS中,指出了一系列静态文件所在位置。 依据配置 INSTALLED_APPS 的名称来查询…...
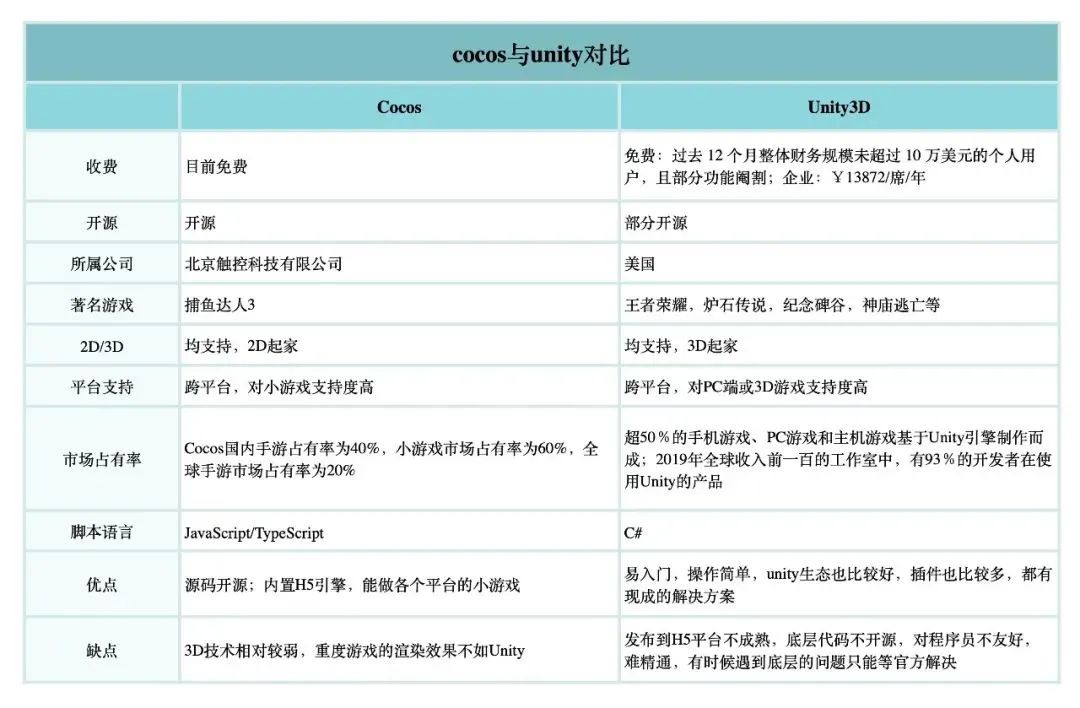
游戏开发引擎Cocos Creator和Unity如何对接广告-AdSet聚合广告平台
在游戏开发方面,游戏引擎的选择对开发过程和最终的产品质量有着重大的影响,Unity和Cocos是目前全球两大商用、通用交互内容开发工具,这两款引擎受到广泛关注,本文将从多个维度对两者进行比较,为开发者提供正确的选择建…...

振南技术干货集:制冷设备大型IoT监测项目研发纪实(4)
注解目录 1.制冷设备的监测迫在眉睫 1.1 冷食的利润贡献 1.2 冷设监测系统的困难 (制冷设备对于便利店为何如何重要?了解一下你所不知道的便利店和新零售行业。关于电力线载波通信的论战。) 2、电路设计 2.1 防护电路 2.1.1 强电防护 …...
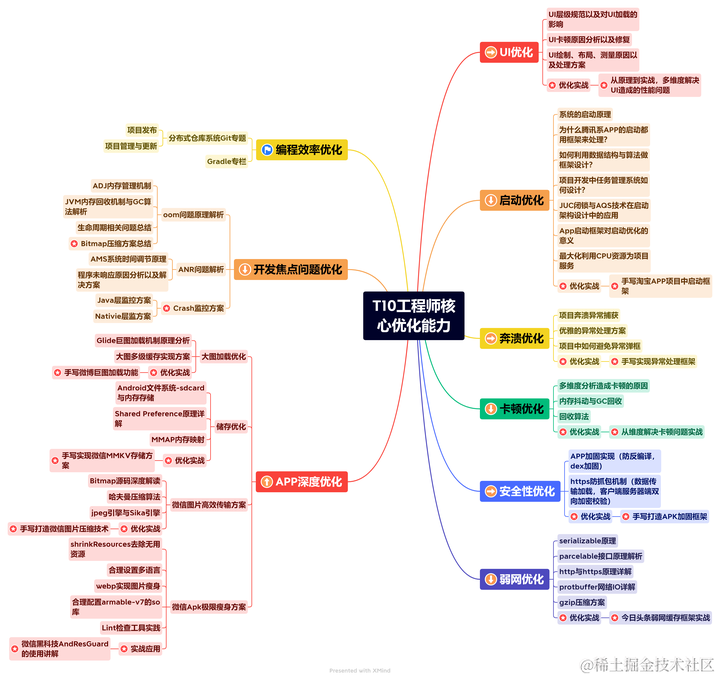
Android线程优化——整体思路与方法
**在日常开发APP的过程中,难免需要使用第二方库和第三方库来帮助开发者快速实现一些功能,提高开发效率。但是,这些库也可能会给线程带来一定的压力,主要表现在以下几个方面: 线程数量增多:一些库可能会在后…...

论防火墙的体系结构
防火墙的体系结构 防火墙的体系结构 双重宿主主机体系结构。屏蔽主机体系结构。屏蔽子网体系结构。 双重宿主主机体系结构 双重宿主主机体系结构是指以一台具有双重宿主的主机计算机作为防火墙系统的主体,执行分离外部网络与内部网络的任务。该计算机至少有两个…...

BeansTalkd 做消息队列服务
无意间看到这个仓库讲php关于 BeanStalkd 的扩展,然后就去了解了一下beanstalkd,用它可以用来做队列服务。 话不多说,安装一下试试。 首先 sudo apt search beanstalk 搜索一下发现 Sorting... Done Full Text Search... Done awscli/focal…...
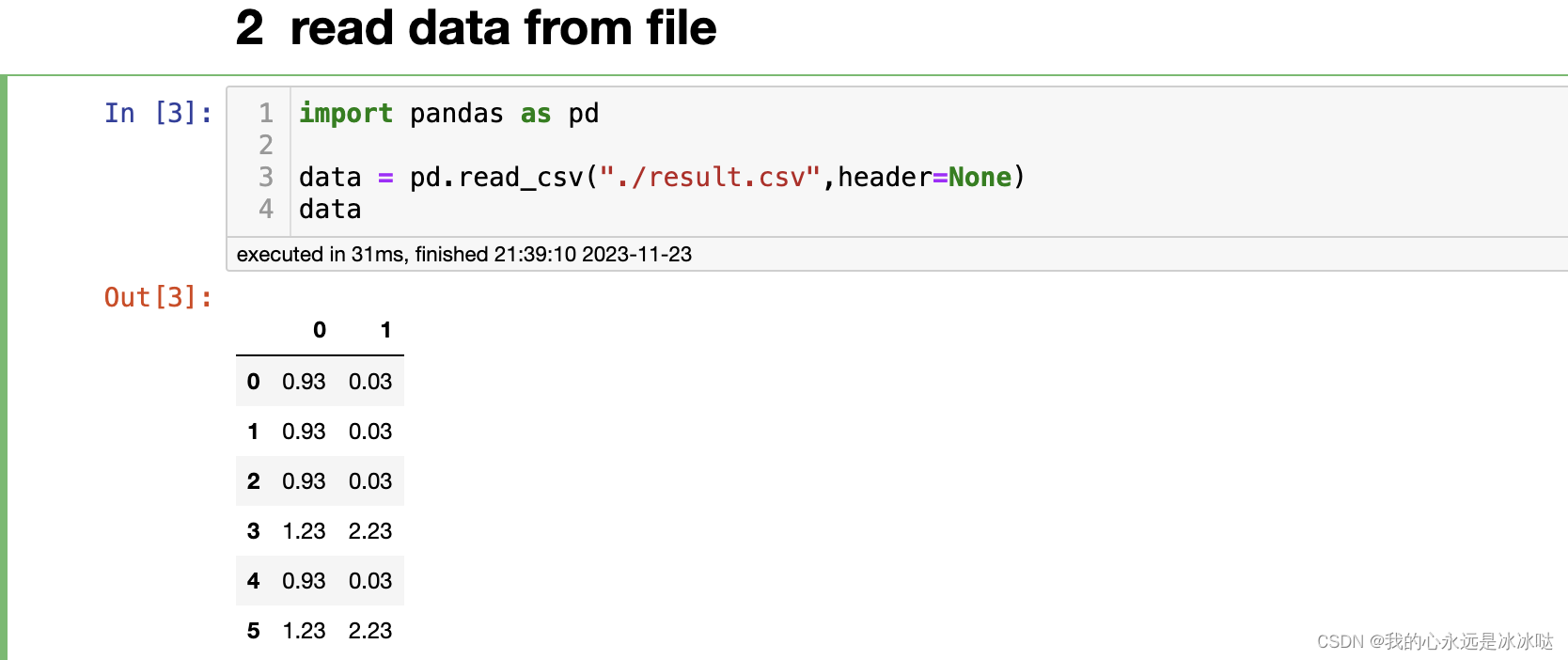
csv文件添加文件内容和读取
append content to file import numpy as np acc_listnp.array([0.97,0.92,0.93,0.89]) # 注意这个地方添加文件不需要特别声明是什么文件 file open("result.csv", "a") print("{:.2f}, {:.2f}".format(acc_list.mean(), acc_list.std()), f…...

关于禅道的安装配置以及项目管理、团队协同工作
目录 一、禅道是什么? 二、特点和功能 三、安装禅道 3.1 下载官网 3.2 版本考虑 3.3 禅道使用手册参考 3.4 Windows端安装禅道 四、启动禅道 4.1 访问禅道 四、禅道部分功能的使用 4.1 添加项目集 4.2 启动/关闭项目 4.3 项目计划仪表盘/阶段目标/研发…...
使用Wireshark提取流量中图片方法
0.前言 记得一次CTF当中有一题是给了一个pcapng格式的流量包,flag好像在某个响应中的图片里。比较简单,后来也遇到过类似的情况,所以总结和记录一下使用Wireshark提取图片的方法。 提取的前提是HTTP协议,至于HTTPS的协议需要导入服…...

C#,简单修改Visual Studio 2022设置以支持C#最新版本的编译器,尊享编程之趣
1 PLS README & CHAPTER 5 用一个超简单的例子说明各版本 C# 的差异。 使用新版本(比如C#.11),当然有一定的好处。我们在写程序的时候一般这样: Visual Studio 2022 默认只能这样写: string imageFile Path.C…...

python开发|yaml用法知识介绍
随着互联网技术的快速发展,服务器编程变得越来越重要。Python作为一种强大的编程语言,越来越受到开发者的青睐。而PyYAML则是Python中最常用的YAML格式解析器之一,本文将系统介绍yaml知识 01yaml介绍 YAML(YAML Aint Markup Language)是一种直观的数据序列化格式,它旨在以…...

全网最全网安合规资源站汇总,从入门到挖洞收藏这篇就够
我们学习网络安全,很多学习路线都有提到多逛论坛,阅读他人的技术分析帖,学习其挖洞思路和技巧。但是往往对于初学者来说,不知道去哪里寻找技术分析帖,也不知道网络安全有哪些相关论坛或网站,所以在这里给大…...

爬虫效率翻倍!指纹浏览器一键检测代理IP太实用
做高并发数据采集久了就会发现,很多效率问题其实不在代码,而是在环境层,尤其是代理IP和指纹浏览器这块。如果这两部分不稳定,再好的采集逻辑也跑不稳,要么频繁失败,要么中途被限制。我之前处理代理问题的方…...

终极指南:超级个体时代,如何用Agent实现百倍效率
终极指南:超级个体时代,如何用Agent实现百倍效率1. 引入与连接:从「短剧单月流水破百万的1人团队」说起 1.1 开场故事:那个“10天攒10部短剧,单月变现97万”的博主 你最近在抖音、快手或者YouTube Shorts上刷到过这类“…...

OMR转换时间时区后返回
class ConvertTZ(Func):function CONVERT_TZoutput_field models.DateTimeField()# 支持多种调用方式def __init__(self, expression, from_tz, to_tz):super(ConvertTZ, self).__init__(expression,Value(from_tz),Value(to_tz))使用 F() 表达式或字段名进行时区转换 在 Dj…...

百度Agent岗一面:你知道哪些更复杂的 RAG 范式?
👔面试官:你了解哪些更复杂的 RAG 范式?除了最基本的检索加生成,还有什么更高级的玩法? 🙋♂️我:呃,我觉得 Advanced RAG 就是最复杂的了吧,加个 Rerank 和 Query 改…...

CodeClash:动态评估语言模型编码能力的竞技平台
1. CodeClash:目标导向软件工程的竞技场在AI辅助编程和自动化软件工程快速发展的今天,如何准确评估语言模型(LM)的编码能力成为一个关键问题。传统评估方法如静态代码补全或单文件生成测试存在明显局限——它们无法反映真实开发中…...

国产时频仪器突围进阶:掌控时间精度,赋能产业自主升级
社会进步的提速与科技自主可控浪潮下,精密时频测量赛道迎来格局重塑。过去,高端时频检测仪器长期被海外巨头垄断,核心技术、行业话语权牢牢受制于人。如今,国内科创企业持续深耕自研、突破技术壁垒,国产时频设备加速突…...

【FME应用3】FME在土地延包数据生产中的5大实战应用
FME在土地延包数据生产中的5大实战应用(干货落地) 摘要:农村土地承包到期延包工作核心难点在于存量确权数据杂乱、拓扑错误多、图属不一致、批量更新繁琐、成果标准化难。传统人工处理方式效率低、错漏多、标准不统一。本文结合一线土地延包数…...

如何应对“不懂技术的领导”?向上管理实战手册
当专业壁垒遇上管理权威在软件研发体系中,测试岗位因其独特的技术深度与质量视野,常常成为技术与业务、管理与执行的关键交汇点。许多测试工程师都曾面临一个经典困境:如何与一位对自动化框架、性能瓶颈、安全漏洞或敏捷测试策略缺乏深度理解…...