新王加冕,GPT-4V 屠榜视觉问答
当前,多模态大型模型(Multi-modal Large Language Model, MLLM)在视觉问答(VQA)领域展现了卓越的能力。然而,真正的挑战在于知识密集型 VQA 任务,这要求不仅要识别视觉元素,还需要结合知识库来深入理解视觉信息。
本文对 MLLM,尤其是近期提出的 GPT-4V,从理解、推理和解释等方面进行了综合评估。结果表明,当前开源 MLLM 的视觉理解能力在很大程度上落后于 GPT-4V,尤其是上下文学习能力需要进一步提升。并且,在广泛的常识类别中,GPT-4V 的问答水平也是明显领先的。

▲图1 知识密集型视觉问答(VQA)任务的评估框架
如图 1 所示,该框架从三个维度进行了深入评估:
-
常识知识:评估模型如何理解视觉线索并与常识知识联系;
-
精细化的世界知识:测试模型从图像中推理出特定专业领域知识的能力;
-
具有决策基础的全面知识:检查模型为其推理提供逻辑解释的能力,从可解释性的角度进行更深入分析。
有趣的是,作者发现:
-
在使用复合图像作为小样本时,GPT-4V 表现出增强的推理和解释能力;
-
在处理世界知识时,GPT-4V 产生严重幻觉,突显了该研究方向未来发展的需求。
论文题目:
A Comprehensive Evaluation of GPT-4V on Knowledge-Intensive Visual Question Answering
论文链接:
https://arxiv.org/abs/2311.07536
当人类与多模态人工智能系统交互时,通常期望获得他们不知道的有价值信息,并提出寻求知识的问题,这涉及到知识密集型挑战。这带来了一个重要的问题:基于 MLLM 的 VQA 系统在面对知识密集型寻求信息的问题时会如何表现?
因此,有必要明确 MLLM 在知识密集型 VQA 场景中的性能,因为这不仅将评估它们基于知识库的视觉推理能力,还将为增强它们在视觉问答方面的能力和提高可信度进行铺垫。
如图 2 所示,作者在这项研究里集中评估了先进的多模态大型模型,特别关注了 GPT-4V(ision) 在知识密集型 VQA 任务背景下的能力。

▲图2 GPT-4V 在三个维度上的性能
本文的研究结果总结如下:
-
MLLM 在知识领域的推理能力各异。分析突显了 MLLM 在涵盖常识和精细化世界知识的各种知识类别上的理解和推理能力的显著差异。
-
GPT-4V 在具有精细化世界知识的 VQA 方面具有挑战性。
-
GPT-4V 能够处理复合图像。将包含上下文引用以进行上下文学习的复合图像提供给 GPT-4V,使 GPT-4V 能够实现更高的答案准确性。尤其是在复合图像中引入上下文引用示例,提高了生成的基础质量,改善了 GPT-4V 的决策解释。
实验设置
数据集
作者选择了三个基于知识的 VQA 数据集:OK-VQA(常识知识),INFOSEEK(精细化世界知识)和 A-OKVQA(决策基础)。这些数据集涵盖了不同形式的知识,并相应地采用不同的评估维度。表 1 展示了这些数据集的统计信息,包括样本总数、类别分布等。
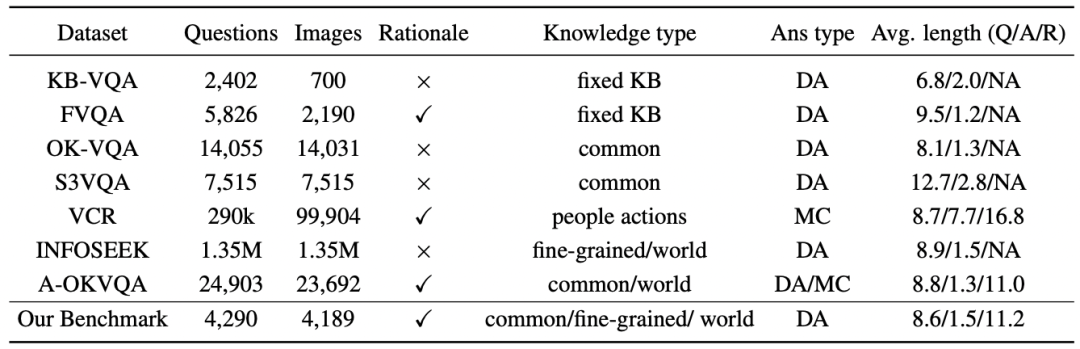
▲表1 基于知识的 VQA 数据集统计信息
图 3 有详细的知识范围统计数据,覆盖了植物、动物、食物、地点等十多个知识类别。
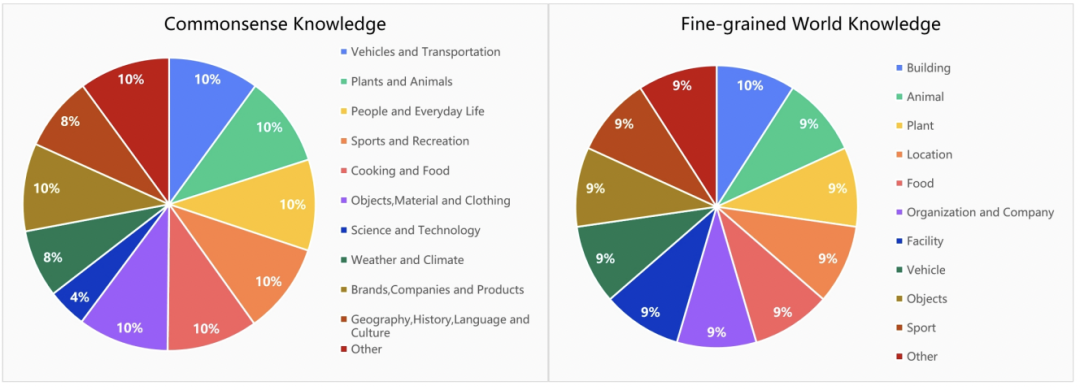
▲图3 根据常识和世界知识类型的知识类别问题的细分
评估方法
鉴于大多数答案是含有少量单词的短文本,而基础是句子级别的,采用以下评估方法:
-
精确匹配: 最直接的准确性评估方法,通过将生成的答案与一组预定义的正确答案进行比较,检查生成的答案是否与参考集中的任何答案完全匹配。
-
自动基础评估: 不仅考虑答案的正确性,还考虑模型回复解释答案背后的推理或逻辑的程度。使用生成性指标来评估语言质量和相关性。
-
人工评估: 人类判断在理解上下文、细微差别和自然语言微妙之处方面很重要。人类评估员将从一致性、充分性、事实正确性方面评估生成的基础句子。
常识知识问答评估
在处理需要常识推理的任务时,计算机通常缺乏人类的先天理解,例如理解在寒冷天气中穿外套的必要性。因此,AI 系统在这些任务上往往表现不佳。AI 研究的关键目标之一是设计方法,使计算机能够具备常识知识,以实现与人类的自然交互。
在常识知识问答任务中,回复通常是一个词或短语。为了激发模型的常识推理能力,作者采用了不同的提示策略,如图 4 所示。使用视觉输入方法,通过输入包含四个上下文参考示例的复合图像,提示模型利用其上下文学习能力生成回复。

▲图4 MLLM 的提示技术
表 2 展示了在具有常识知识 VQA 上的基准结果。其中,Llava-v1.5-13b 是最熟练的开源 MLLM,尤其在常识视觉问题回答方面表现卓越,但在许多领域仍远远低于 GPT-4V。
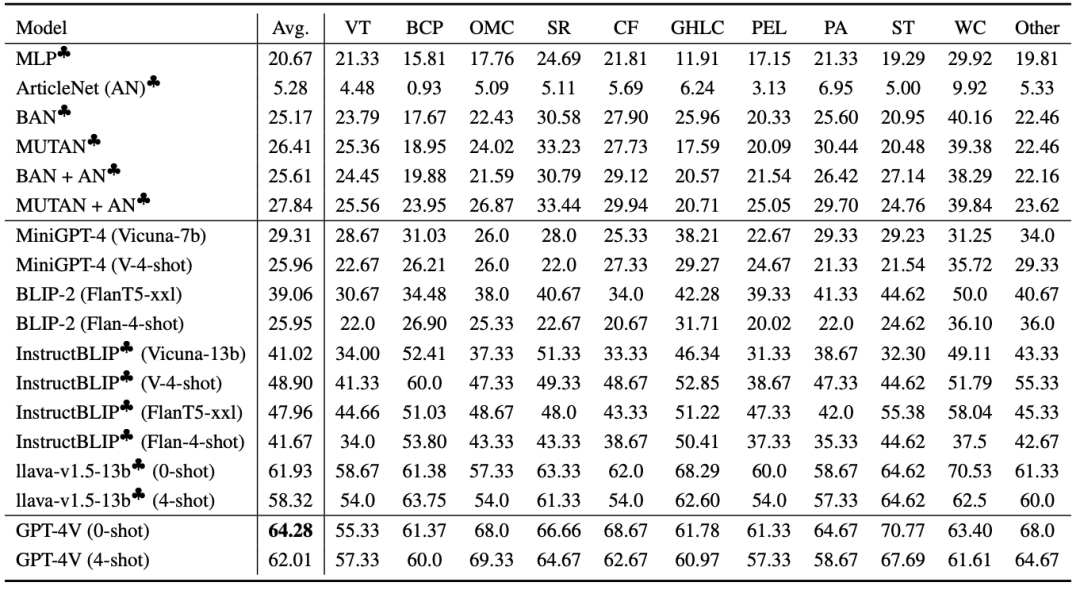
▲表2 通用知识 VQA 上的基准结果
此外,还有以下关键发现:
-
对 MLLM 进行常识 VQA 数据微调显著提高了性能。
-
使用 4-shot 上下文学习方法对一些 MLLM 的常识推理性能产生影响,尤其是对开源模型的影响较为敏感,而 GPT-4V 则相对不太敏感。
-
MLLM 在应用内部知识时存在长尾效应。
总体而言,尽管开源 MLLM 表现不错,但在广泛的常识类别中,GPT-4V 仍然明显领先。
如图 5 所示,GPT-4V 倾向于生成更详细和准确的答案,但存在一些视觉错觉问题,例如误识别图像中的关键元素和难以区分相似物种。此外,特别是在提供不确定性回复时,GPT-4V 有时能生成详细的推理过程。

▲图5 GPT-4V 和 Llava-v1.5-13b 在常识知识上生成的案例的对比
细粒度世界知识评估
相对于常识知识,世界知识更为具体和详细,使得 AI 能够回答关于事实和具体问题的提问,对于 MLLM 来说,处理信息检索问题至关重要。这种 VQA 需要 MLLM 识别视觉内容并将其与知识库联系起来,因此更关注 GPT-4V 在处理各种类别中的细粒度知识时的能力。
为了激发模型细粒度知识处理能力,作者采用了与图 4 中示例相同的提示方法,并选择了如图 6 所示的上下文参考示例。

▲图6 MLLM 在细粒度世界知识评估中的上下文参考示例
实验结果见表 3,GPT-4V 的平均准确率不到 30%。相比之下,开源 MLLM 的准确率更低。因此在处理细粒度世界知识方面,GPT-4V 明显优于开源 MLLM。所有评估的 MLLM,无论其复杂性如何,在准确回答需要详细世界知识的视觉问题方面效果都有欠缺。
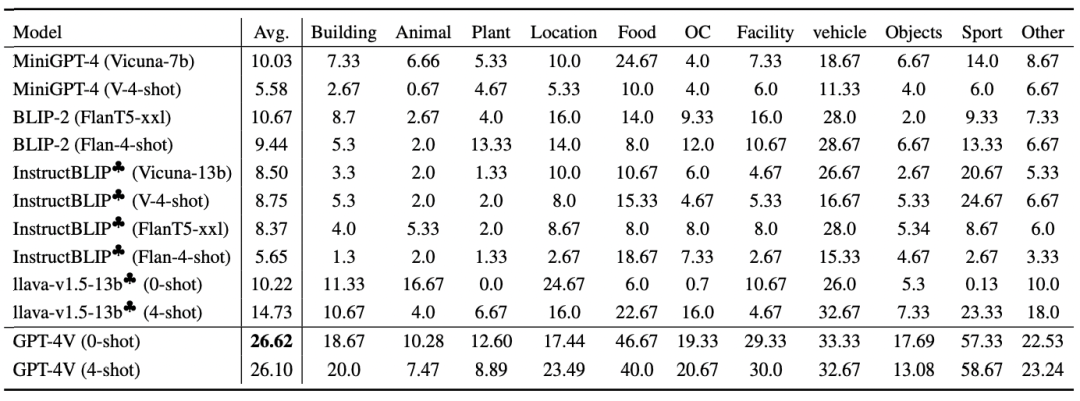
▲表3 在细粒度世界知识上的 VQA 基准结果
在不同知识类别之间存在显著的性能差距,导致了严重的长尾现象。目前的 MLLM(包括 GPT-4V 在内)回答复杂信息检索问题的能力需要进一步提高。
案例研究
图 7-11 展示了 GPT-4V 在 11 个细粒度世界知识问答中遇到的四个主要问题:
-
上下文不足而拒绝回答:由于上下文不足,GPT-4V 经常因为图像未提供与问题相关的足够信息而选择不回答寻求信息的问题(参见图 8-10)。GPT-4V 过于谨慎,通常在图像缺乏强烈相关视觉线索时选择保持沉默。
-
识别相似对象的挑战:GPT-4V 在具有广泛子类别范围的类别中难以区分相似物品,导致在这些领域内回答知识密集型问题的准确性明显降低。这一限制可能与视觉幻觉和LLM的幻觉有关。
-
视觉和知识维度整合不足:数据集主要专注于单跳视觉知识问题和答案,但观察到的事实不准确性表明视觉识别与相关知识的整合较弱。
-
过度依赖视觉线索,忽视文本提问:GPT-4V 有时在回答中过度依赖视觉元素,而忽视问题的文本内容。
图 7 的上半部分评估了建筑的建筑风格和目的,澄清了其实际的教区和举办的重要事件。下半部分评估了动物的栖息地、保护状况和入侵情况。

▲图7 GPT-4V 在识别相似对象方面存在困难(视觉幻觉)
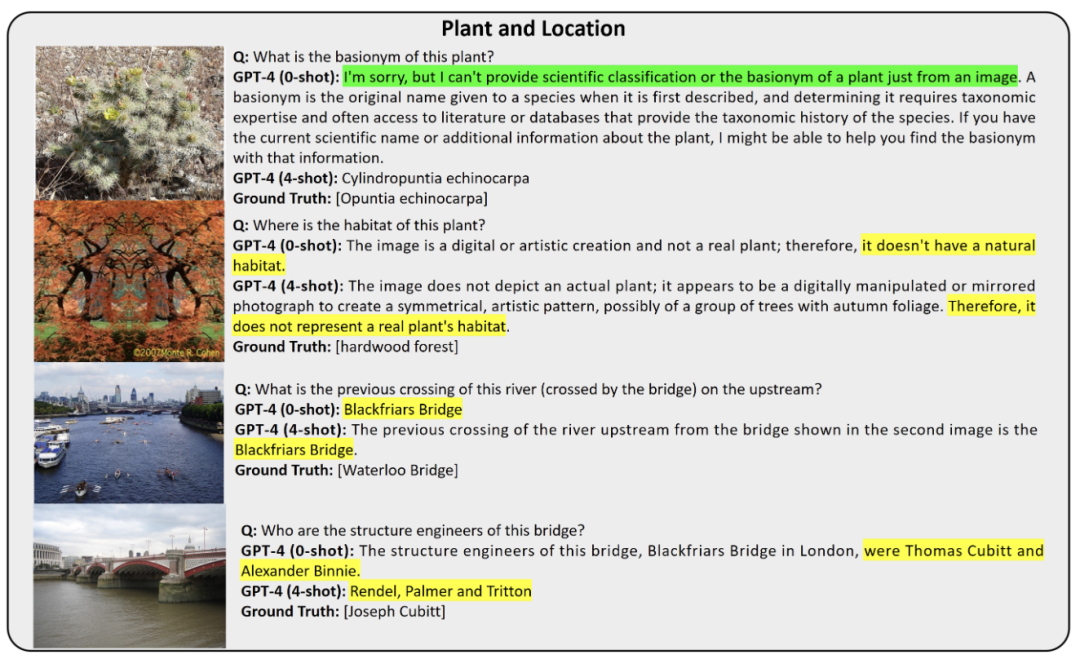
▲图8 过度依赖视觉线索来回答知识密集型的视觉问题
上图展示了一个被错误识别的植物物种及其不存在的栖息地,以及桥梁先前的渡河和其工程归属的历史细节。当图像无法提供足够信息时,GPT-4V 拒绝回答问题,过度依赖视觉线索来回答知识密集型的视觉问题。

▲图9 细粒度问题回答
图 10 呈现了当询问 GPT-4 识别并提供有关图像中各种对象和位置的详细信息时,对其回复进行比较分析。该图展示了模型在没有额外上下文的情况下,存在解释视觉信息的能力和局限性。

▲图10 在没有额外上下文的情况下解释视觉信息的能力和局限性
图 11 包括对几何结构、望远镜的发明者、飞机的环境影响以及古罗马市场的历史背景,以及传统划船比赛的起源进行评估。这些提问展示了模型试图从图像和相关问题中推断信息的尝试,展示了 GPT-4V 理解和历史归因的挑战和复杂性。

▲图11 GPT-4V 理解和历史归因的挑战和复杂性
尽管所有 MLLM 在需要实体特定知识的问题中都存在困难,但在这些场景中,GPT-4V 相对于开源 MLLM 展现了显著优势。然而,GPT-4V 往往过于谨慎,经常选择不回答与缺乏强相关视觉线索的图像提问,过度依赖视觉理解内容是它们此处表现不佳的关键限制。为了提高 MLLM 在精细化视觉对象知识任务中的能力,需要进一步研究提高详细视觉数据与上下文知识的整合和相关性。
全面知识与决策论据
通常,MLLM 充分利用广泛的知识库,将预训练的 LLM 与视觉编码器的能力相结合。在这里,作者提供了决策论据以评估 MLLM 在生成相关事实和支持推理的逻辑推理序列方面的熟练程度。
为了实现评估目标,问题的设计旨在引导模型进行概念上的深入思考,往往需要对呈现的图像之外的知识进行推断。
如图 12 所示,当前的多模态提示方法主要注重为决策过程生成论据,这标志着一个重要的变革。

▲图12 为 A-OKVQA 生成理由的提示方法
从表 4 可以看出,GPT-4V(4-shot)在性能方面优于其他模型。与 GPT-4V 不同,其他 MLLM 缺乏在上下文示例中生成论据的能力,除非它们提供了理由作为参考。
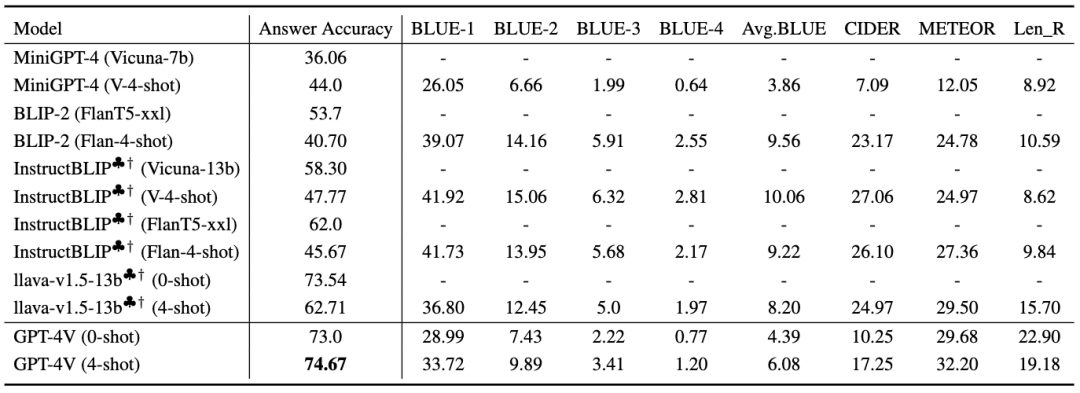
▲表4 在 A-OKVQA 上的多个知识类型和决策论据生成的基准结果
相比之下,GPT-4V 通常对人类的提问生成更详细的理由,这可能解释了它在这些指标上的不同表现。
此外,根据答案准确性、一致性、充分性和事实正确性这四个维度进行了人工评估,统计结果如表 5 所示。显然,GPT-4V 在答案准确性和决策论据质量方面表现出色,明显优于其他开源 MLLM。尽管在自动评估指标中论据评分略低,但从人工评估的角度来看,GPT-4V 生成的理由质量仍然是最好的。

▲表5 对生成答案和论据的子集进行人类评估
案例研究
在对这些样本提供的理由及准确性进行评估时,根据图 13,明显可以看出 GPT-4V 在性能上优于 Llava-v1.5。具体而言,GPT-4V 的输出不仅更为详细,而且提供了更加丰富的信息。相比之下,Llava-v1.5 生成的理由通常较为模糊,有时在解释视觉元素时可能产生幻觉。
对于不正确的回答进行进一步分析揭示了一个经常出现的问题:GPT-4V 和 Llava-v1.5 偶尔由于对图像中的视觉内容的误解而提供不准确的答案。这一趋势在 Llava-v1.5 的错误样本中尤为明显,表明其在处理视觉信息和理解指令方面有改进的空间。

▲图13 采用 4-shot 提示方法,由 GPT-4V 和 Llava-v1.5-13b 生成的样例
开源的 MLLM 在答案准确性方面表现得和 GPT-4V 相媲美,这归因于它们在多模态指令调优阶段利用了相关数据集。然而,这些模型在没有先前上下文引用情况下生成理由的能力较差,表明它们在理解各种指令的能力方面存在一定局限性。
此外,研究结果还揭示了当前开源 MLLM 的视觉理解能力在很大程度上落后于 GPT-4V,它们的上下文学习能力需要进一步提升。然而,GPT-4V 的 few-shot 设置方式提高了答案准确性和生成理由的质量。
总结
本研究主要关注对多模态大型模型性能的评估,作者着重探讨了 GPT-4V 在各种知识密集型 VQA 任务中的表现。通过对性能评估的详细分析,还揭示了 MLLM 面对的挑战和局限:
-
长尾知识推理是多模态大型模型的挑战。MLLM 在各种知识领域中的推理能力存在显著差异,尤其在涉及挑战性的人类实体知识的情境中。这一差异主要源于训练阶段的数据分布不平衡,因此解决这一问题对提高 MLLM 整体推理能力至关重要。
-
GPT-4V 和其他 MLLM 在细粒度世界知识问答中存在性能限制。解决这些限制对于提高 MLLM 在需要深入理解视觉和文本信息的复杂问答任务中的性能至关重要。
-
整合全面知识以提升视觉理解。MLLM 在处理需要理解图像中对象的背景知识的问题时经常表现不佳。扩展视觉语言训练,包括更广泛的有关视觉对象的知识,有助于提高 MLLM 对视觉内容的理解和准确回答复杂问题的能力。
-
GPT-4V 有效利用基于复合图像的上下文学习。这种技术提高了 GPT-4V 生成准确答案和推理的效率,尤其在处理包含丰富信息的复合图像时。然而,该方法对模型固有的图像理解能力产生影响,开源 MLLM 在这方面的表现相对较差。
本文强调了改善 MLLM 在处理不同领域和知识密集型任务中的能力的重要性。对长尾知识、视觉理解和语言推理的整合,以及对模型在特定场景下的优势和不足进行深入了解,这都是未来研究的关键方向。
在未来的工作中应当加强对 MLLM 的进一步改进,特别是在细粒度世界知识问答方面。通过整合更全面的知识、改善视觉理解和语言推理的整合,我们有望提高这些模型在处理复杂问题时的性能。期望未来在 MLLM 上有更多的研究和技术进展,这将为推动人工智能领域的发展提供新的机遇和创新基础。

相关文章:
新王加冕,GPT-4V 屠榜视觉问答
当前,多模态大型模型(Multi-modal Large Language Model, MLLM)在视觉问答(VQA)领域展现了卓越的能力。然而,真正的挑战在于知识密集型 VQA 任务,这要求不仅要识别视觉元素,还需要结…...
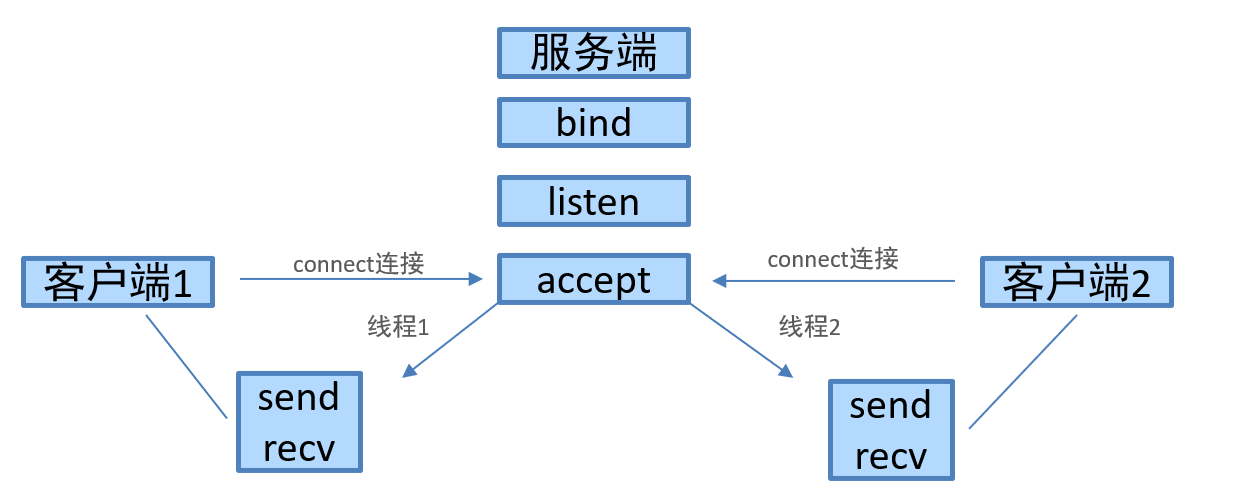
python之TCP的网络应用程序开发
文章目录 版权声明python3编码转换socket类的使用创建Socket对象Socket对象常用方法和参数使用示例服务器端代码客户端代码 TCP客户端程序开发流程TCP服务端程序开发流程TCP网络应用程序注意点socket之send和recv原理剖析send原理剖析recv原理剖析send和recv原理剖析图 多任务版…...
Axios 拦截器 请求拦截器 响应拦截器
请求拦截器 相当于一个关卡,如果满足条件就放行请求,不满足就拦截 响应拦截器 在处理结果之前,先对结果进行预处理,比如:对数据进行一下格式化的处理 全局请求拦截器 axios.interceptors.request.use(config > { /…...

Mysql Shell笔记
Mysql Shell部署 cd /usr/local/ tar -xvf /root/mysql-shell-8.0.35-linux-glibc2.17-x86-64bit.tar.gz chown -R mysql.mysql mysqlsh mysql-shell-8.0.35-linux-glibc2.17-x86-64bitmysqlsh登录退出 mysqlsh -uroot -S /data/3306/mysql.sock MySQL Shell 8.0.35 Copyrigh…...

Hive日志默认存储在什么位置?
在hive-log4j.properties配置文件中,有这么一段配置信息 hive.log.thresholdALL hive.root.loggerWARN,DRFA hive.log.dir${java.io.tmpdir}/${user.name} hive.log.filehive.log hive.log.dir就是日志存储在目录/tmp/${user.name}(当前用户名)/下 而hive.log就是h…...
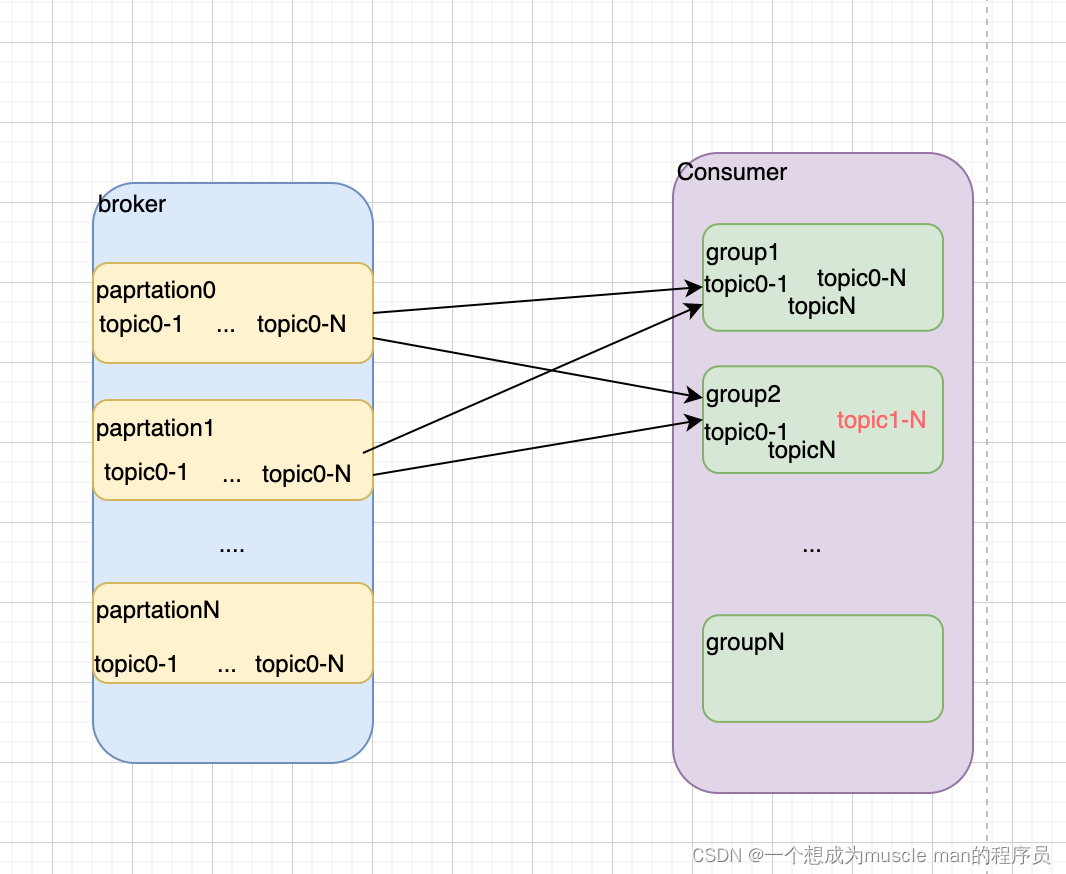
Kafka 常用功能总结(不断更新中....)
kafka 用途 业务中我们经常用来两个方面 1.发送消息 2.发送日志记录 kafka 结构组成 broker:可以理解成一个单独的服务器,所有的东西都归属到broker中 partation:为了增加并发度而做的拆分,相当于把broker拆分成不同的小块&…...
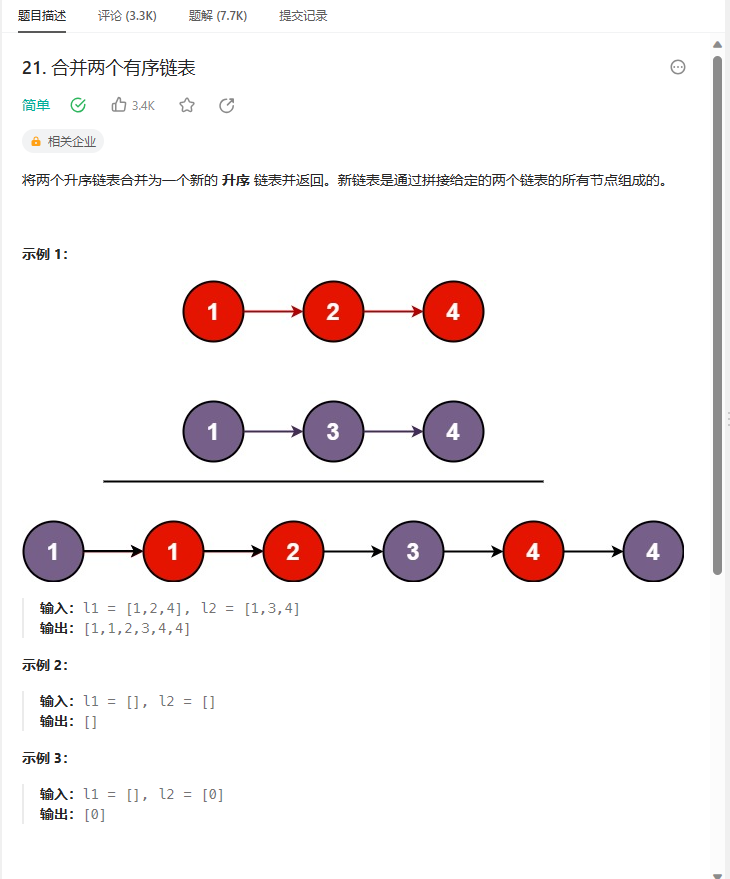
单链表相关面试题--5.合并有序链表
5.合并有序链表 21. 合并两个有序链表 - 力扣(LeetCode) /* 解题思路: 此题可以先创建一个空链表,然后依次从两个有序链表中选取最小的进行尾插操作进行合并。 */ typedef struct ListNode Node; struct ListNode* mergeTwoList…...

SV-7042VP sip广播4G无线网络号角
SV-7042VP sip广播4G无线网络号角 1. 采用防水一体化设计,整合了音频解码、数字功放及音柱 2. 提供配置软件,支持SIP标准协议,通过SIP服务器能够接入现有综合通信调度平台系统,接受sip通信调度平台。融合第三方sip协议及sip服务器…...

基于OpenCV+MediaPipe的手势识别
【精选】【优秀课设】基于OpenCVMediaPipe的手势识别(数字、石头剪刀布等手势识别)_石头剪刀布opencv识别代码_网易独家音乐人Mike Zhou的博客-CSDN博客 import cv2 import mediapipe as mp import mathdef vector_2d_angle(v1, v2):求解二维向量的角度v…...

YOLO目标检测——无人机航拍行人检测数据集下载分享【含对应voc、coc和yolo三种格式标签】
实际项目应用:智能交通管理、城市安防监控、公共安全救援等领域数据集说明:无人机航拍行人检测数据集,真实场景的高质量图片数据,数据场景丰富标签说明:使用lableimg标注软件标注,标注框质量高,…...

数据提取PDF SDK的对比推荐
PDF 已迅速成为跨各种平台共享和分发文档的首选格式,它作为一种数据来源,常见于公司的各种报告和报表中。为了能更好地分析、处理这些数据信息,我们需要检测和提取 PDF 中的数据,并将其转换为可用且有意义的格式。而数据提取的 PD…...
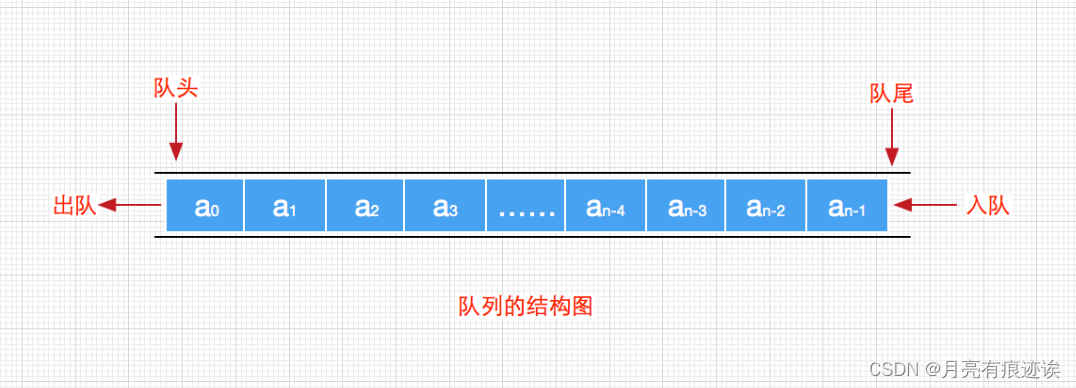
【数据结构(C语言)】浅谈栈和队列
目录 文章目录 前言 一、栈 1.1 栈的概念及结构 1.2 栈的实现 1.2.1. 支持动态增长的栈的结构 1.2.2 初始化栈 1.2.3 入栈 1.2.4 出栈 1.2.5 获取栈顶元素 1.2.6 获取栈中有效元素个数 1.2.7 检查栈是否为空 1.2.8 销毁栈 二、队列 2.1 队列的概念及结构 2.2 队…...

【NGINX--5】身份验证
1、HTTP 基本身份验证 需要通过 HTTP 基本身份验证保护应用或内容。 生成以下格式的文件,其中的密码使用某个受支持的格式进行了加密或哈希处理: # comment name1:password1 name2:password2:comment name3:password3第一个字段是用户名࿰…...

【网络奇缘】- 计算机网络|分层结构|ISO模型
🌈个人主页: Aileen_0v0🔥系列专栏: 一见倾心,再见倾城 --- 计算机网络~💫个人格言:"没有罗马,那就自己创造罗马~" 目录 计算机网络分层结构 OSI参考模型 OSI模型起源 失败原因: OSI模型组成 协议的作用 📝全文…...

使用whisper实现语音转文本
项目地址:GitHub - openai/whisper: Robust Speech Recognition via Large-Scale Weak Supervision 1、需要py3.8环境 conda activate p38 2、安装 pip install -U openai-whisper 3、下载项目 pip install githttps://github.com/openai/whisper.git 4、安装…...
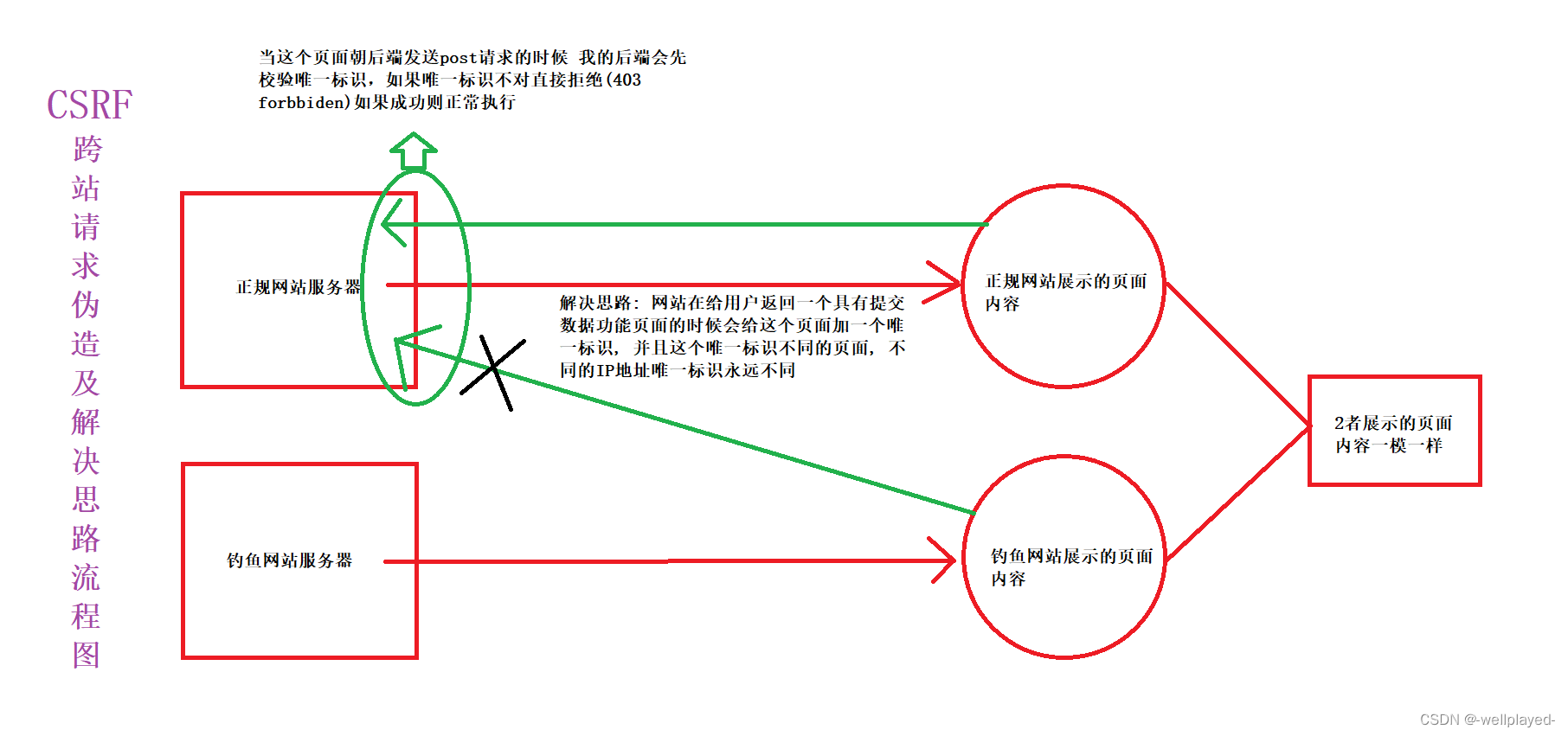
Django中间件与csrf
一. django中间件 1. 什么是django中间件 # django中间件是django的门户1. 请求来的时候需要先经过中间件才能到达真正的django后端2. 响应走的时候最后也需要经过中间件才能发送出去 2. django中间件的个数 django自带七个中间件, 分别是SecurityMiddleware, SessionMiddle…...
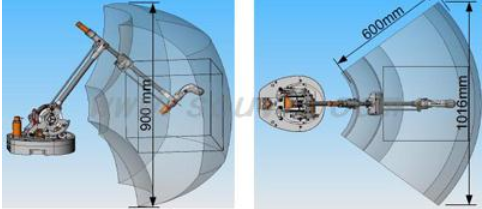
【搜维尔科技】产品推荐:Virtuose 6D RV,大型工作空间触觉设备
Virtuose 6D RV为一款具有大工作空间并在所有6自由度上提供力反馈的触觉设备,设计专用于虚拟现实环境,特别适合于大型虚拟物体的处理。 Virtuose 6D RV是当今市场上唯一将高工作效率与高工作量相结合在一起的产品。6D RV特别适合于缩放与操纵等应用&…...
<JavaEE> 什么是线程(Thread)?进程和线程有什么区别?
目录 一、线程(Thread)的概念 二、线程存在的意义 2.1 并发编程 2.2 比进程更“轻量” 三、使用线程时应该注意 四、进程和线程的区别 五、Java中的线程和操作系统中的线程是不同的概念 六、多线程编程 一、线程(Thread)的…...

【赠书第7期】从零基础到精通Flutter开发
文章目录 前言 1 安装Flutter和Dart 2 了解Flutter的基础概念 2.1 Widget 2.2 MaterialApp和Scaffold 2.3 Hot Reload 3 编写你的第一个Flutter应用 3.1 创建一个Flutter项目 3.2 修改默认页面 3.3 添加交互 4 深入学习Flutter高级特性 4.1 路由和导航 4.2 状态管…...
/发布者—订阅者模式)
《golang设计模式》第三部分·行为型模式-07-观察者模式(Observer)/发布者—订阅者模式
文章目录 1. 概念1.1 角色1.2 类图 2. 代码示例2.1 代码2.2 类图 1. 概念 观察者(Observer)指当目标对象状态发生变化后,对状态变化事件进行响应或处理的对象。 1.1 角色 Subject(抽象主题): 它可以有多…...

如何通过社区力量推动Preact技术公益发展:完整指南
如何通过社区力量推动Preact技术公益发展:完整指南 【免费下载链接】preact ⚛️ Fast 3kB React alternative with the same modern API. Components & Virtual DOM. 项目地址: https://gitcode.com/gh_mirrors/pr/preact Preact作为一款轻量级的React替…...
)
从Word模板到动态报表:手把手教你用poi-tl搞定Java后端Word导出(含多表格循环与合并)
从Word模板到动态报表:手把手教你用poi-tl搞定Java后端Word导出(含多表格循环与合并) 在企业管理系统中,自动生成标准化文档一直是开发中的痛点。想象一下人力资源部门每月需要手动处理上百份员工绩效报告,财务团队反…...

从崩溃到修复:深入解析egui在iOS平台的Color32颜色转换堆栈溢出问题
从崩溃到修复:深入解析egui在iOS平台的Color32颜色转换堆栈溢出问题 【免费下载链接】egui egui: an easy-to-use immediate mode GUI in Rust that runs on both web and native 项目地址: https://gitcode.com/GitHub_Trending/eg/egui egui是一款用Rust编…...

【AI】cursor使用小技巧
一、核心框架:6 段式 Prompt 结构 Cursor 的 Agent 对结构化指令的解析远优于段落式描述。官方推荐的 Prompt 遵循以下 6 段式模板 :模块作用示例写法Goal一句话定义产出,可衡量Goal: 为 /invoices API 添加分页,保留现有筛选和排…...

服务器还没挂你就知道?时间序列才是运维真正的“预知能力”
🔥 服务器还没挂你就知道?时间序列才是运维真正的“预知能力” 一、引子:你以为你在监控,其实你在“等死” 凌晨三点,告警响了。 CPU 100%、服务超时、用户投诉……一切来得猝不及防。 你打开监控面板,心里只有一句话: “怎么又是突然挂的?” 但真相是—— 它从来不…...

14万+下载量!为什么Tavily Search是OpenClaw必装的第一技能?
没有它,你的AI Agent就是"瞎子" 一、先问一个问题 你用过ChatGPT吗? 那你一定遇到过这种情况:问它"2026年最新AI趋势",它告诉你"我的知识截止到2024年4月"。 这就是大模型的先天缺陷——知识有截…...

仰望U8真牛,老戏骨都忍不住夸
2026北京车展看点还真不少!王志飞和宁理两位老师,特意来到仰望展台体验了仰望U8。两人亲自坐进车里,体验了车内空间和智能配置,整体体验下来评价都很不错。王志飞分享说,仰望U8车内静谧性很好,行驶起来特别…...

别再瞎猜了!我用JavaScript模拟了50万次购彩,算出了彩票站的“数据同步”成本
用JavaScript构建高并发数据分发系统的工程实践 想象一下,你需要在一小时内将更新的数据同步到全国30万个终端设备上——这不是科幻场景,而是许多大型系统架构师每天面临的真实挑战。从金融交易系统到物联网设备管理,数据分发的效率直接影响着…...

Allegro 16.6出Gerber避坑指南:从钻孔表到槽孔,新手必看的5个细节
Allegro 16.6出Gerber避坑指南:从钻孔表到槽孔,新手必看的5个细节 第一次使用Allegro 16.6输出Gerber文件时,那种既兴奋又忐忑的心情我至今记忆犹新。作为PCB设计流程中的关键环节,Gerber文件的质量直接决定了最终电路板的成败。本…...

3步掌握GEMMA:快速上手全基因组关联分析工具,轻松处理复杂遗传数据
3步掌握GEMMA:快速上手全基因组关联分析工具,轻松处理复杂遗传数据 【免费下载链接】GEMMA Genome-wide Efficient Mixed Model Association 项目地址: https://gitcode.com/gh_mirrors/gem/GEMMA 你是否曾被复杂的遗传数据分析困扰?面…...