SQL Server 百万数据查询优化技巧三十则
点击上方蓝字关注我

互联网时代的进程越走越深,使用MySQL的人也越来越多,关于MySQL的数据库优化指南很多,而关于SQL SERVER的T-SQL优化指南看上去比较少,近期有学习SQLSERVER的同学问到SQL SERVER数据库有哪些优化建议?本文列举了部分常见的优化建议,具体内容如下:
1. 优化建议
索引优化:
eg:考虑一个订单表 Orders,其中有列 OrderDate 和 CustomerID。如果经常需要按订单日期范围和顾客ID进行查询,可以在这两列上建立复合索引,以提高查询性能。
NULL 值判断避免全表扫描:
eg:对于包含 status 列的用户表 Users,避免使用 SELECT * FROM Users WHERE status IS NULL,可以在设计表时设置 status 默认值,确保所有用户都有一个状态,然后使用 SELECT * FROM Users WHERE status = 0 进行查询。
!= 或 <> 操作符避免全表扫描:
eg:考虑一个产品表 Products,如果要查询所有不属于某个特定类别的产品,避免使用 SELECT * FROM Products WHERE CategoryID != 5,而是使用 SELECT * FROM Products WHERE CategoryID <> 5。
OR 连接条件避免全表扫描:
eg:对于一个学生成绩表 Grades,如果需要查询得分为 A 或 B 的记录,避免使用 SELECT * FROM Grades WHERE Grade = 'A' OR Grade = 'B',而是使用 SELECT * FROM Grades WHERE Grade = 'A' UNION ALL SELECT * FROM Grades WHERE Grade = 'B'。
IN 和 NOT IN 避免全表扫描:
eg:考虑一个员工表 Employees,如果需要查询属于某个特定部门的员工,避免使用 SELECT * FROM Employees WHERE DepartmentID IN (1, 2, 3),而是使用 SELECT * FROM Employees WHERE DepartmentID BETWEEN 1 AND 3。
LIKE 查询优化:
eg:在一个文章表 Articles 中,如果需要模糊查询标题包含关键词的文章,避免使用 SELECT * FROM Articles WHERE Title LIKE '%SQL%',可以考虑全文检索或者其他优化方式。
参数使用避免全表扫描:
eg:在一个订单表 Orders 中,如果需要根据输入的订单号查询订单信息,避免使用 SELECT * FROM Orders WHERE OrderID = @OrderID,可以使用强制索引的方式,如 SELECT * FROM Orders WITH(INDEX(OrderID_Index)) WHERE OrderID = @OrderID。
字段表达式操作避免全表扫描:
eg:在一个商品表 Products 中,如果需要查询价格除以2等于100的商品,避免使用 SELECT * FROM Products WHERE Price/2 = 100,可以改为 SELECT * FROM Products WHERE Price = 100*2。
字段函数操作避免全表扫描:
eg:在一个员工表 Employees 中,如果需要查询名字以"Smith"开头的员工,避免使用 SELECT * FROM Employees WHERE LEFT(LastName, 5) = 'Smith',可以改为 SELECT * FROM Employees WHERE LastName LIKE 'Smith%'。
不要在“=”左边进行函数、算术运算:
eg:在一个库存表 Inventory 中,避免使用 SELECT * FROM Inventory WHERE YEAR(StockDate) = 2023,而是使用 SELECT * FROM Inventory WHERE StockDate >= '2023-01-01' AND StockDate < '2024-01-01'。
索引字段顺序使用避免全表扫描:
eg:在一个订单表 Orders 中,如果有复合索引 (CustomerID, OrderDate),查询时应该先使用 CustomerID,如 SELECT * FROM Orders WHERE CustomerID = @CustomerID AND OrderDate BETWEEN @StartDate AND @EndDate。
避免写没有意义的查询:
eg:不建议使用 SELECT col1, col2 INTO #t FROM t WHERE 1 = 0,可以改为明确创建表结构并使用 CREATE TABLE #t (...)。
使用 EXISTS 代替 IN:
eg:在一个产品表 Products 中,避免使用 SELECT * FROM Products WHERE ProductID IN (SELECT ProductID FROM DiscontinuedProducts),可以改为 SELECT * FROM Products WHERE EXISTS (SELECT 1 FROM DiscontinuedProducts WHERE ProductID = Products.ProductID)。
索引不一定对所有查询有效:
eg:在一个性别字段 Gender 几乎均匀分布的表中,对 Gender 建立索引可能不会提高查询效率。
索引数量谨慎选择:
eg:在一个订单表 Orders 中,不宜过多地在每个列上建立索引,需要根据查询和更新的具体需求进行权衡。
更新 clustered 索引数据列谨慎操作:
eg:在一个用户表 Users 中,如果频繁更新用户姓名,考虑是否将姓名列设为非聚集索引,以避免整个表记录顺序调整。
使用数字型字段:
eg:在一个学生成绩表 Grades 中,如果考试成绩以整数形式表示,使用整数型字段而非字符型字段。
使用 VARCHAR/NVARCHAR:
eg:在一个文章表 Articles 中,如果存储文章内容,使用 VARCHAR(MAX) 而非 TEXT。
避免使用 SELECT *:
eg:在一个员工表 Employees 中,避免使用 SELECT * FROM Employees,而是明确指定需要的列,如 SELECT EmployeeID, FirstName, LastName FROM Employees。
使用表变量代替临时表:
eg:在一个小型数据集的情况下,可以使用表变量而不是创建临时表来存储中间结果。例如,使用表变量替代以下的临时表:
-- 不推荐
CREATE TABLE #TempResults (ID INT,Name VARCHAR(255),...-- 推荐
DECLARE @TempResults TABLE (ID INT,Name VARCHAR(255),...
);避免频繁创建和删除临时表:
eg:在一个存储过程中,如果需要多次使用相同的临时表,不要在每次使用时都创建和删除,而是在存储过程的开头创建一次,最后删除。
合理使用临时表:
eg:在一个复杂的查询中,如果需要多次引用中间结果,可以考虑使用临时表。但应注意不要滥用,确保临时表的使用是必要的。
选择合适的临时表创建方式:
eg:在需要一次性插入大量数据的情况下,可以使用 SELECT INTO 替代 CREATE TABLE 和 INSERT 的两步操作,以减少日志记录。
-- 不推荐
CREATE TABLE #TempTable (ID INT,Name VARCHAR(255),...
);INSERT INTO #TempTable
SELECT ID, Name, ...
FROM SomeTable;-- 推荐
SELECT ID, Name, ...
INTO #TempTable
FROM SomeTable;显式删除临时表:
eg:在存储过程或脚本的最后,确保显式删除所有创建的临时表,以释放系统表资源。
-- 不推荐
DROP TABLE #TempTable;-- 推荐
TRUNCATE TABLE #TempTable;
DROP TABLE #TempTable;避免使用游标:
eg:在一个订单表 Orders 中,避免使用游标来逐行处理数据,可以考虑使用集合操作或者其他优化方法。
基于集的方法替代游标或临时表:
eg:在需要对大量数据进行操作时,尽量寻找基于集的解决方案,以避免使用游标或临时表。例如,使用窗口函数或联接来处理数据。
存储过程中使用 SET NOCOUNT ON/OFF:
eg:在存储过程中使用 SET NOCOUNT ON 和 SET NOCOUNT OFF,以减少向客户端发送 DONE_IN_PROC 消息,提高性能。
-- 存储过程开头
SET NOCOUNT ON;-- 存储过程结尾
SET NOCOUNT OFF;避免大事务操作:
eg:在一个银行交易表 Transactions 中,避免在一个事务中处理过多的交易记录,以提高系统并发能力。
避免向客户端返回大数据量:
eg:在一个日志表 Logs 中,如果查询可能返回大量的日志记录,应该审查客户端是否真的需要这么多数据,考虑分页或其他方式减少返回的数据量。
SQL Server执行计划掌握:
使用EXPLAIN或Show Execution Plan分析查询执行计划,发现潜在问题。
2. 结语
熟悉其他数据库的同学应该也能对比出,很多数据库的优化经验是相通的,所以在学习其他数据库的时候可以借鉴已掌握的经验去对比学习,这样学习起来也会事半功倍。

往期精彩回顾
1. MySQL高可用之MHA集群部署
2. mysql8.0新增用户及加密规则修改的那些事
3. 比hive快10倍的大数据查询利器-- presto
4. 监控利器出鞘:Prometheus+Grafana监控MySQL、Redis数据库
5. PostgreSQL主从复制--物理复制
6. MySQL传统点位复制在线转为GTID模式复制
7. MySQL敏感数据加密及解密
8. MySQL数据备份及还原(一)
9. MySQL数据备份及还原(二)
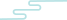
扫码关注



相关文章:
SQL Server 百万数据查询优化技巧三十则
点击上方蓝字关注我 互联网时代的进程越走越深,使用MySQL的人也越来越多,关于MySQL的数据库优化指南很多,而关于SQL SERVER的T-SQL优化指南看上去比较少,近期有学习SQLSERVER的同学问到SQL SERVER数据库有哪些优化建议?…...
)
list转map(根据某个或多个属性分组)
需要将对应的list换成本地list,和对象换成本地对象 1、List转Map<String,List> // 根据一个字段分组 Map<String, List<String>> map objectLists.stream().collect(Collectors.groupingBy(Object::getName,Collectors.mapping(Object::getId, …...

常见树种(贵州省):012茶、花椒、八角、肉桂、杜仲、厚朴、枸杞、忍冬
摘要:本专栏树种介绍图片来源于PPBC中国植物图像库(下附网址),本文整理仅做交流学习使用,同时便于查找,如有侵权请联系删除。 图片网址:PPBC中国植物图像库——最大的植物分类图片库 一、茶 灌…...
千云物流 - 使用k8s负载均衡openelb
openelb的介绍 具体根据官方文档进行安装官方文档,这里作为测试环境的安装使用. OpenELB 是一个开源的云原生负载均衡器实现,可以在基于裸金属服务器、边缘以及虚拟化的 Kubernetes 环境中使用 LoadBalancer 类型的 Service 对外暴露服务。OpenELB 项目最初由 KubeSphere 社区…...

C语言之字符串函数
C语言之字符串函数 文章目录 C语言之字符串函数1. strlen的使用和模拟实现1.1 strlen的使用1.2 strlen的模拟实现 2. strcpy的使用和模拟实现2.1 strcpy的使用2.2 strncpy的使用2.3 strcpy的模拟实现 3. strcat的使用和模拟实现3.1 strcat的使用3.2 strncat3.3 strcat的模拟实现…...
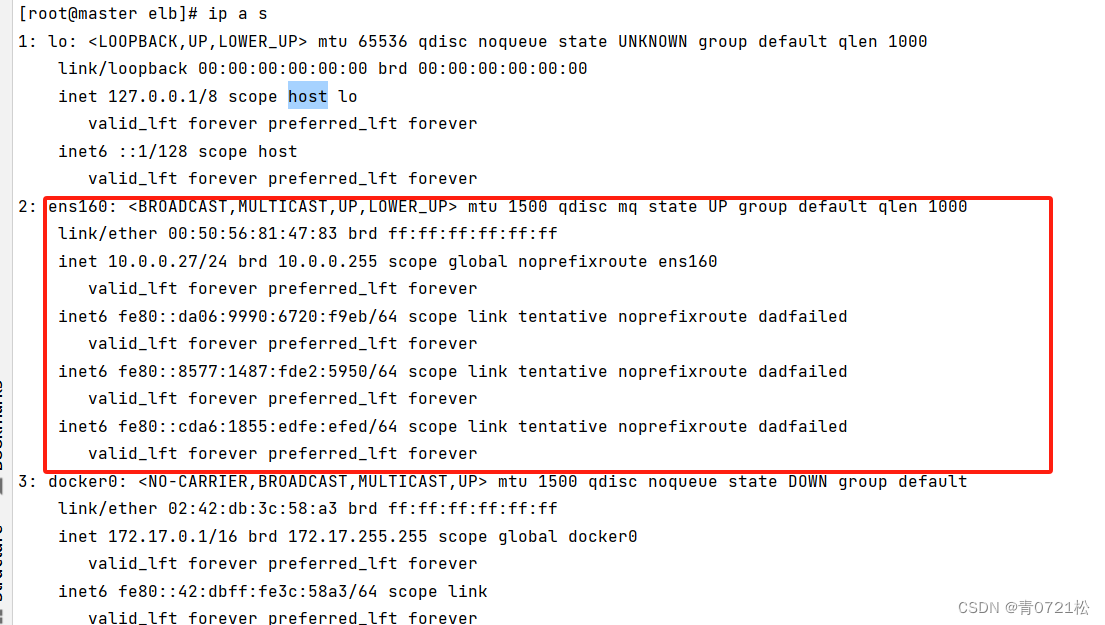
python中一个文件(A.py)怎么调用另一个文件(B.py)中定义的类AA详解和示例
本文主要讲解python文件中怎么调用另外一个py文件中定义的类,将通过代码和示例解读,帮助大家理解和使用。 目录 代码B.pyA.py 调用过程 代码 B.py 如在文件B.py,定义了类别Bottleneck,其包含卷积层、正则化和激活函数层,主要对…...

spark shuffle 剖析
ShuffleExchangeExec private lazy val writeMetrics SQLShuffleWriteMetricsReporter.createShuffleWriteMetrics(sparkContext)private[sql] lazy val readMetrics SQLShuffleReadMetricsReporter.createShuffleReadMetrics(sparkContext)用在了两个地方,承接的是…...
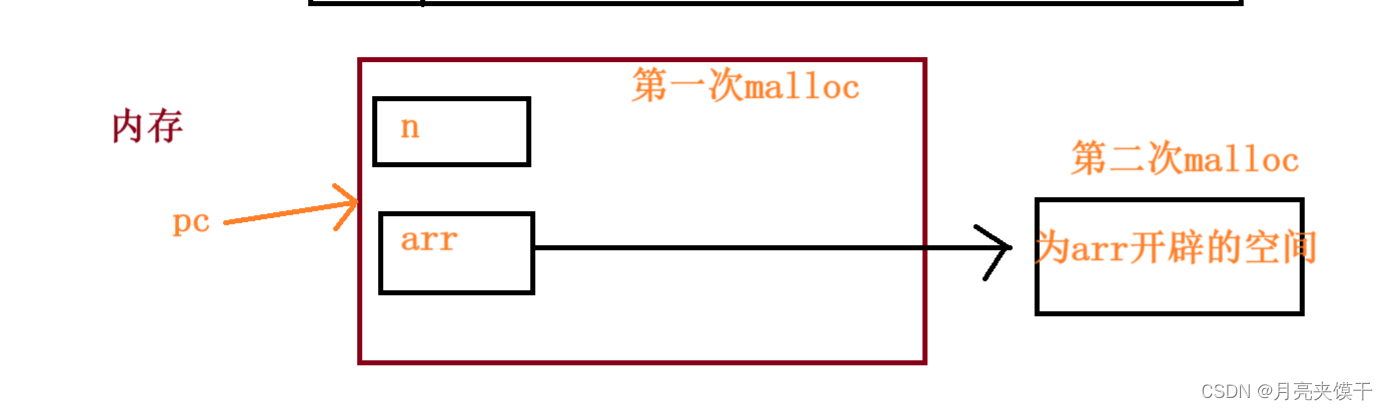
C语言之认识柔性数组(flexible array)
在学习之前,我们首先要了解柔性数组是放在结构体当中的,知道这一点,我们就开始今天的学习吧! 1.柔性数组的声明 在C99中,结构中的最后一个元素允许是未知大小的数组,这就叫做柔性数组成员 这里的结构是结构…...
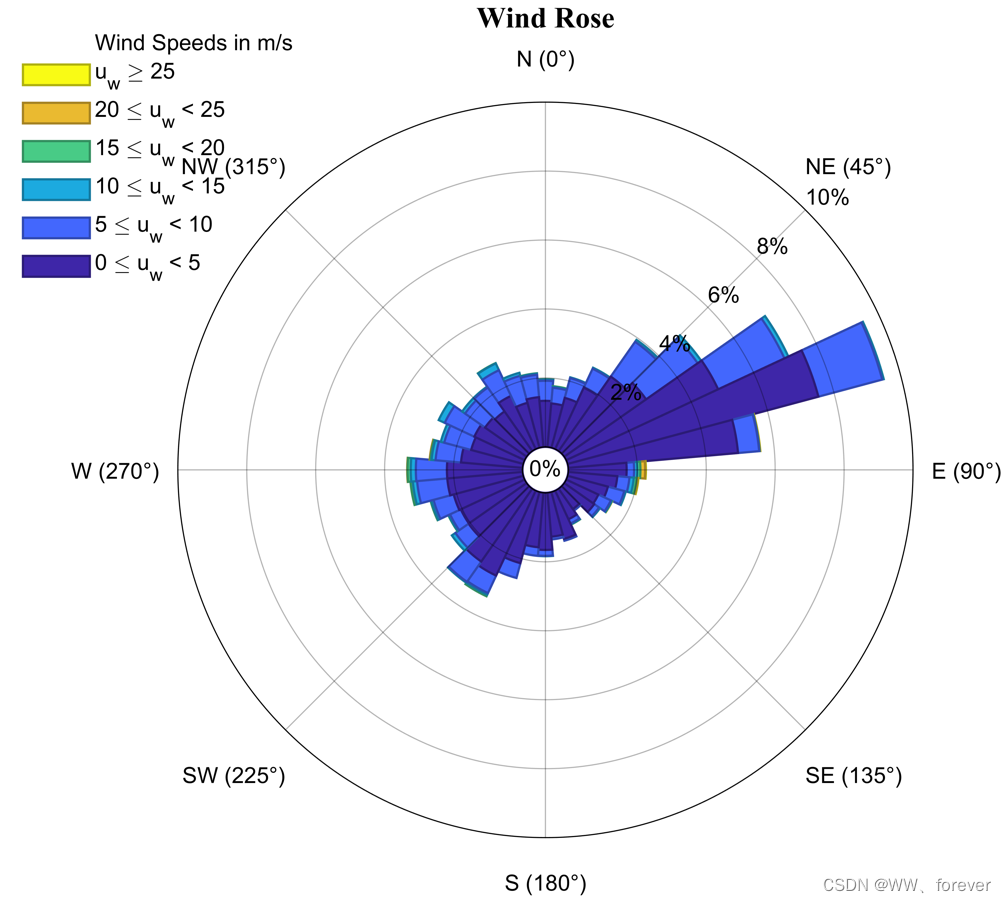
【MATLAB基础绘图第17棒】绘制玫瑰图
MATLAB绘制玫瑰图 玫瑰图(Nightingale Rose Chart)风玫瑰图(WindRose)准备工作:WindRose工具包下载案例案例1:基础绘图 参考 玫瑰图(Nightingale Rose Chart) 玫瑰图(Ni…...

Qt 基于海康相机的视频绘图
需求 在视频窗口上进行绘图,包括圆,矩形,扇形等 效果: 思路: 自己取图然后转成QImage ,再向QWidget 进行渲染,根据以往的经验,无法达到很高的帧率。因此决定使用相机SDK自带的渲染…...
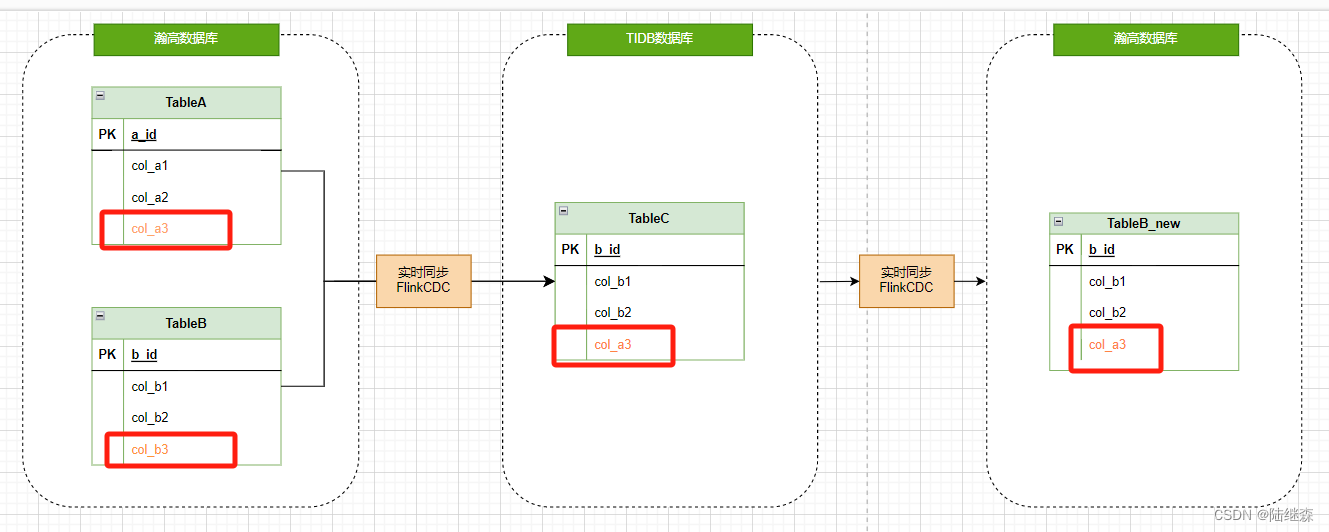
FlinkCDC实现主数据与各业务系统数据的一致性(瀚高、TIDB)
文章末尾附有flinkcdc对应瀚高数据库flink-cdc-connector代码下载地址 1、业务需求 目前项目有主数据系统和N个业务系统,为保障“一数一源”,各业务系统表涉及到主数据系统的字段都需用主数据系统表中的字段进行实时覆盖,这里以某个业务系统的一张表举例说明:业务系统表Ta…...
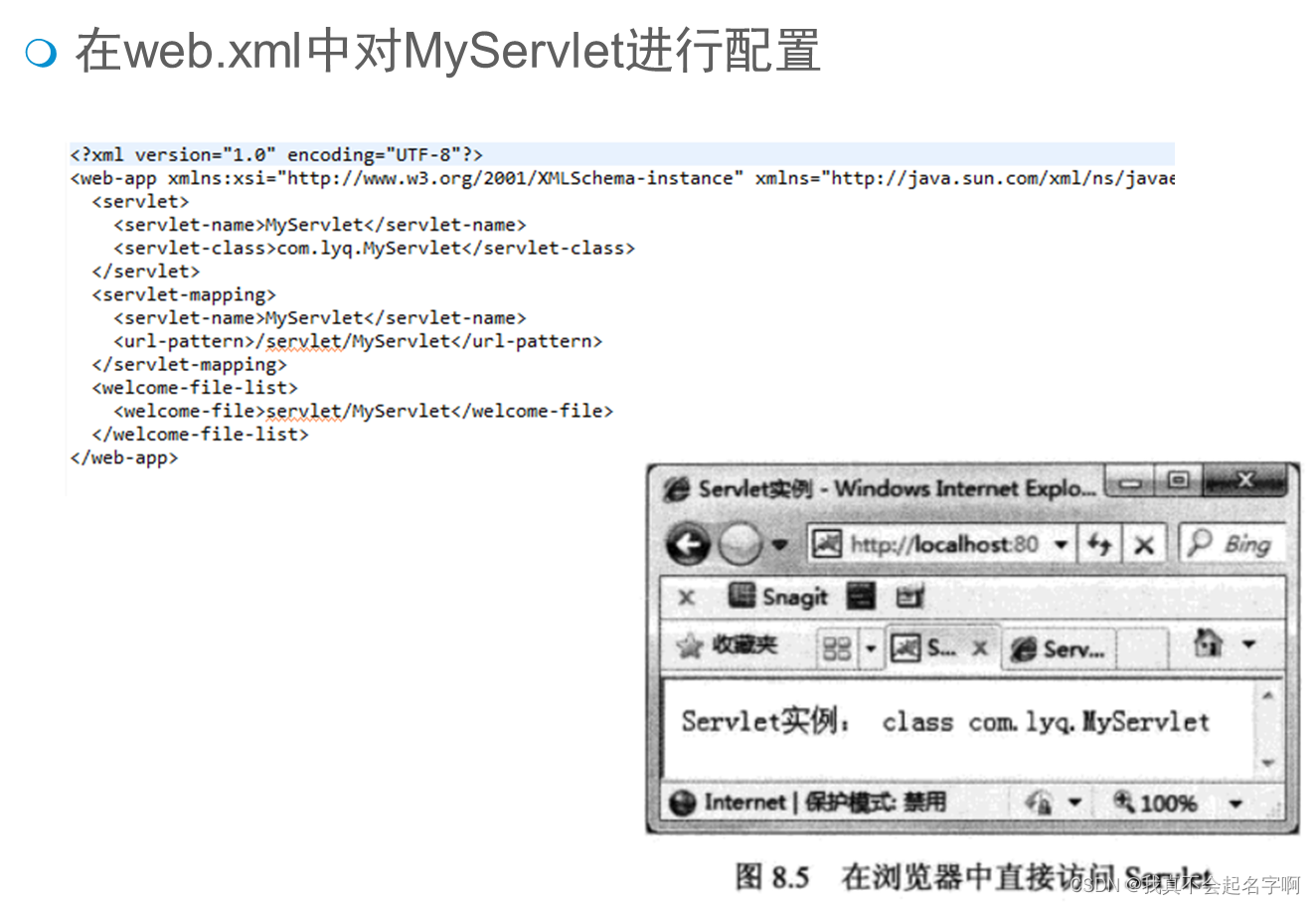
JSP:Servlet
Servlet处理请求过程 B/S请求响应模型 Servlet介绍 JSP是Servlet的一个成功应用,其子集。 JSP页面负责前台用户界面,JavaBean负责后台数据处理,一般的Web应用采用JSPJavaBean就可以设计得很好了。 JSPServletJavaBean是MVC Servlet的核心…...
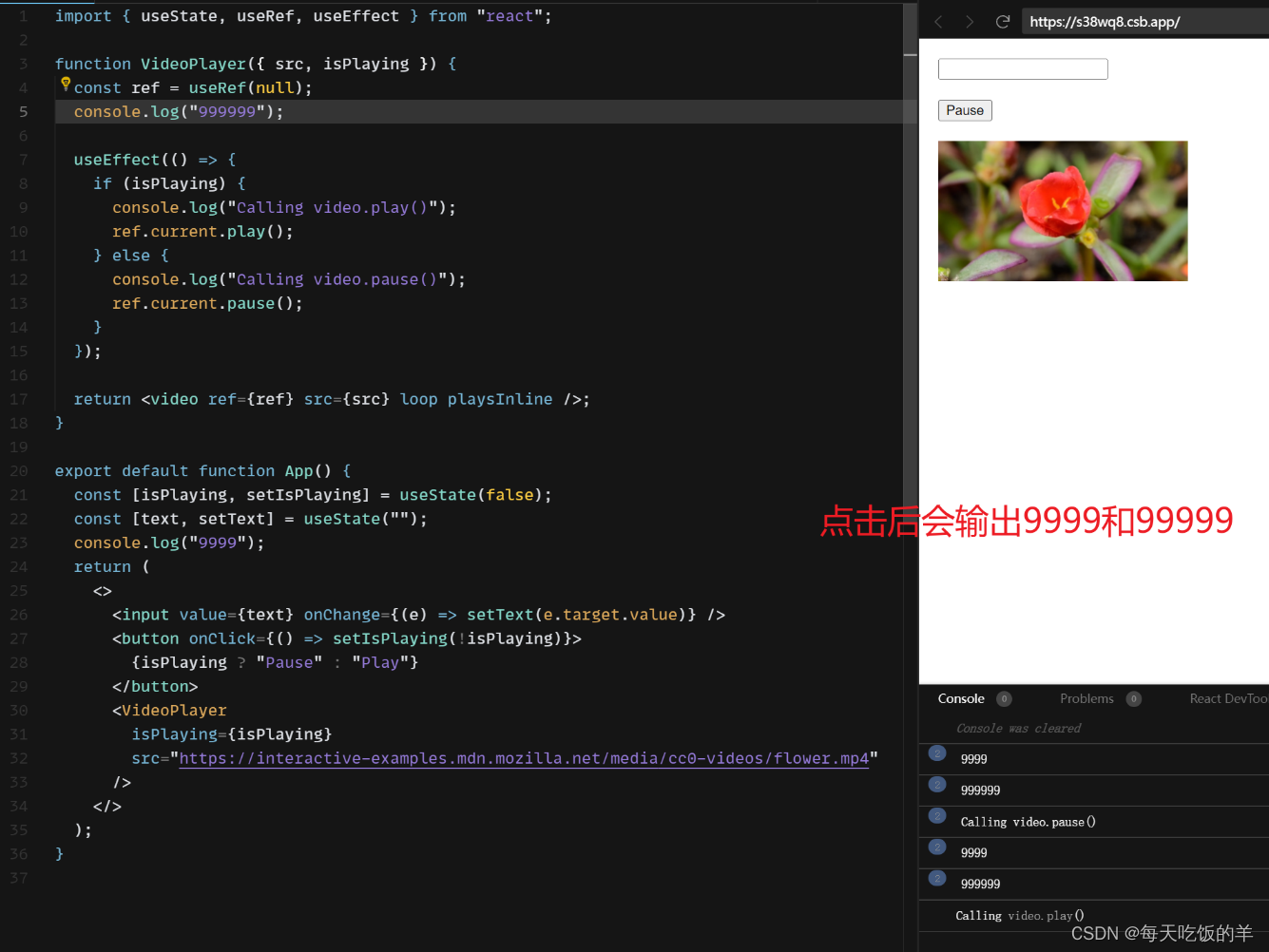
react中的state
没想到hooks中也有state这一说法 看下面的两个案例 1、无state变化不会执行父子函数 2、有state更改执行父子函数...

VR全景航拍要注意什么,航拍图片如何处理
引言: VR全景航拍技术是当前摄影和航拍领域的新潮流。它采用虚拟现实技术,通过360度全景镜头捕捉画面,可以为观众提供身临其境的视觉体验。在宣传展示中,利用VR全景航拍技术可以为品牌宣传带来更加生动、震撼的视觉效果。 一、航拍注意事项 …...
Spark---集群搭建
Standalone集群搭建与Spark on Yarn配置 1、Standalone Standalone集群是Spark自带的资源调度框架,支持分布式搭建,这里建议搭建Standalone节点数为3台,1台master节点,2台worker节点,这虚拟机中每台节点的内存至少给…...
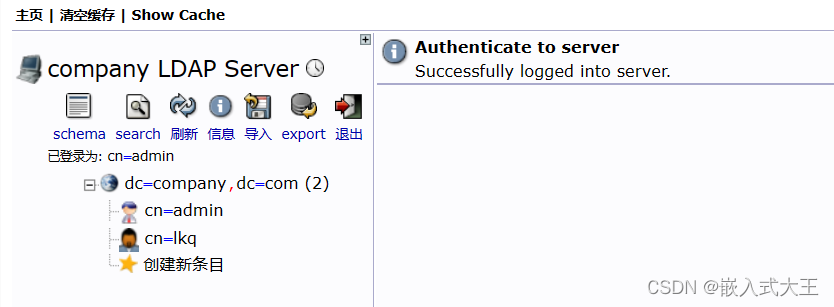
Linux上通过SSL/TLS和start tls连接到LDAP服务器
一,大致流程。 1.首先在Linux上搭建一个LDAP服务器 2.在LDAP服务器上安装CA证书,服务器证书,因为SSL/TLS,start tls都属于机密通信,需要客户端和服务器都存在一个相同的证书认证双方的身份。3.安装phpldapadmin工具&am…...

【华为OD题库-034】字符串化繁为简-java
题目 给定一个输入字符串,字符串只可能由英文字母(a ~ z、A ~ Z)和左右小括号()组成。当字符里存在小括号时,小括号是成对的,可以有一个或多个小括号对,小括号对不会嵌套,小括号对内可以包含1个或多个英文字母也可以不…...
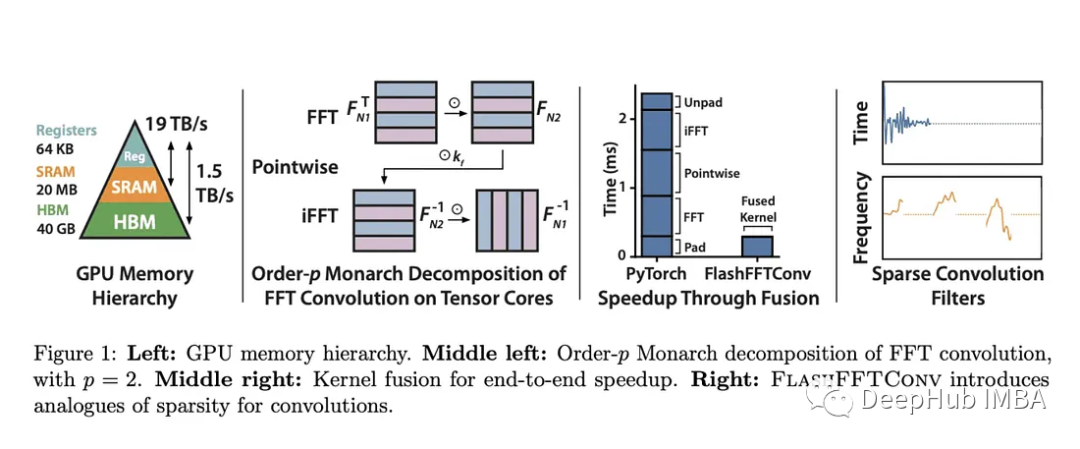
斯坦福大学引入FlashFFTConv来优化机器学习中长序列的FFT卷积
斯坦福大学的FlashFFTConv优化了扩展序列的快速傅里叶变换(FFT)卷积。该方法引入Monarch分解,在FLOP和I/O成本之间取得平衡,提高模型质量和效率。并且优于PyTorch和FlashAttention-v2。它可以处理更长的序列,并在人工智能应用程序中打开新的可…...

信息系统项目管理师-干系人管理论文提纲
快速导航 1.信息系统项目管理师-项目整合管理 2.信息系统项目管理师-项目范围管理 3.信息系统项目管理师-项目进度管理 4.信息系统项目管理师-项目成本管理 5.信息系统项目管理师-项目质量管理 6.信息系统项目管理师-项目资源管理 7.信息系统项目管理师-项目沟通管理 8.信息系…...

Windmill:最快的自托管开源工作流引擎
我们对 Windmill 进行了基准测试,认为它是 Airflow、Prefect 甚至 Temporal 中最快的自托管通用工作流引擎。对于 Airflow,有速度快了 10 倍! 工作流引擎编排工作人员的有向无环图 (DAG) 中定义的作业,同时尊重依赖性。 主要优点…...

Cyrus:自托管AI编码代理部署与实战,打造自动化开发流水线
1. 项目概述:一个能帮你写代码的“数字员工” 如果你和我一样,每天要在Linear、GitHub、Slack这些工具之间来回切换,处理数不清的工单、Issue和PR评论,那你肯定想过:要是能有个“数字员工”帮我处理这些重复性的编码任…...
)
避坑指南:树莓派摄像头+MJPG-Streamer配置中常见的5个错误及解决方法(从驱动到端口占用)
树莓派摄像头实战:MJPG-Streamer配置避坑手册 当你兴奋地拆开树莓派摄像头模块,准备搭建一个家庭监控系统时,可能没想到会在MJPG-Streamer配置过程中遇到这么多"坑"。从摄像头无法识别到端口冲突,从权限问题到依赖缺失&…...

下周一马斯克与奥特曼法庭重逢,8520亿美元OpenAI面临「违反慈善信托」诉讼
世纪诉讼即将开庭下周一,马斯克和奥特曼将在法庭重逢,估值8520亿美元的OpenAI要上被告席。加州奥克兰联邦法院已排好日程,4月27日进行陪审团遴选,4月28日开庭陈述,审期持续到5月中旬。半个硅谷的相关人士都要被传上证人…...

PyTorch自动微分引擎autograd原理与实战
1. PyTorch自动微分引擎autograd解析PyTorch的autograd系统是其作为深度学习框架的核心竞争力之一。与TensorFlow等框架不同,PyTorch采用动态计算图机制,使得自动微分过程更加直观灵活。让我们深入剖析autograd的工作原理。1.1 计算图构建机制当我们在Py…...

ChatGPT机器翻译优化指南:温度、提示词与避坑实践
1. 项目概述与核心价值最近在机器翻译(Machine Translation, MT)领域,一个绕不开的话题就是如何用好以ChatGPT为代表的大语言模型。我自己在尝试将GPT-3.5/4集成到翻译工作流中时,遇到了不少困惑:为什么有时候翻译质量…...

FPGA远程升级的“安全气囊”:手把手教你用ICAP原语实现Multiboot回滚机制
FPGA远程升级的“安全气囊”:手把手教你用ICAP原语实现Multiboot回滚机制 在工业自动化、医疗设备和通信基站等关键领域,FPGA设备的远程升级能力已成为刚需。想象一下,当数百公里外的风力发电机组FPGA需要修复逻辑漏洞时,工程师不…...

自然语言生成技术:从原理到实践
1. 自然语言生成技术解析:让机器像人类一样写作作为一名长期从事自然语言处理(NLP)领域的技术从业者,我见证了自然语言生成(NLG)技术从简单的规则匹配发展到如今能够创作出媲美人类水平的文本。这项技术正在…...

Phi-3.5-mini-instruct惊艳案例:从模糊需求描述生成可运行Python脚本
Phi-3.5-mini-instruct惊艳案例:从模糊需求描述生成可运行Python脚本 1. 引言 想象一下这样的场景:你脑海中有一个模糊的编程需求,但不确定具体该怎么实现。传统方式可能需要反复搜索、尝试各种代码片段,甚至需要请教同事。现在…...
)
UE5新手避坑指南:手把手教你从零集成Cesium for Unreal插件(含离线数据配置思路)
UE5实战:Cesium for Unreal插件深度集成与避坑手册 第一次打开UE5引擎时,那个闪烁着金属光泽的启动器界面总让人充满期待——直到你尝试集成Cesium for Unreal插件时遇到各种报错窗口。作为地理空间可视化领域的黄金标准,Cesium与虚幻引擎的结…...
)
Cloudflare HTML 解析器的十年演化史(二)
本文是 Cloudflare HTML 解析系列的第二篇。上篇讲了从 2010 年到 2016 年,Cloudflare 如何从一堆临时解析器走向 LazyHTML。这篇从 2017 年接着讲——当 Cloudflare Workers 上线之后,为什么 LazyHTML 不够用了,以及 LOL HTML 如何从架构层面…...