什么是机器学习
前言
机器学习(Machine Learning, ML)是一个总称,用于解决由各位程序员自己基于 if-else 等规则开发算法而导致成本过高的问题,想要通过帮助机器 「发现」 它们 「自己」 解决问题的算法来解决 ,而不需要程序员将所有规则都输入机器,明确告诉机器该怎么做。
机器学习概念
机器学习的核心是“使用算法解析数据,从中学习,然后对新数据做出决定或预测”。也就是说计算机利用以获取的数据得出某一模型,然后利用此模型进行预测的一种方法,这个过程跟人的学习过程有些类似,比如人获取一定的经验,可以对新问题进行预测。

可以看到,神经网络只是机器学习中的一部分,除了神经网络,机器学习还有着许多其他的算法。机器学习在多年的发展中逐步丰富,已经被人们开发出了许多中算法
- K 近邻(KNN)
- K 均值(K-Means)
- 支持向量机(SVM
- 随机森林(RandomForest)
- 逻辑回归(Logistic Regression)
- 神经网络(Neural Network)
- 其它
机器学习的分类
机器学习按照学习的方式可以分为
- 有监督学习通常指的是所有数据都含有特征 X 和标签 Y,有标准答案指导机器进行学习;
- 无监督学习指的是只有特征 X,没有特定的标签 Y,设计一定的规则让机器进行学习;
- 半监督学习指的是所有数据都有特征 X,但一部分数据含有标签 Y,一部分没有,需要通过联合没有标签和有标签的数据进行学习;
- 强化学习指的是可以通过外界或人为规定的奖励来指导机器进行下一步的行为。
无监督学习:例如聚类的算法,即把特征值相同的归为一类,或者降维
半监督学习: 一般通过聚类算法把无标签特征值和有标签特征值相同归为一类,并打上标签.然后使用有监督的学习方式学习
强化学习: 某种意义上也可以理解为一定的有监督,但其又不是完全将奖励值作为学习目标,并且一般是实时的,基于概率去抽样下一步行为的,所以又有着一定的区别。,例如阿尔法围棋和无人驾驶
按照工作的方式可以分为
-
批量学习(离线学习):Batch Learning,输入大量学习资料,机器学习算法学习训练出模型,将模型投入到生产中,模型不会发生变化;
- 优点:简单,只需要学习一次算法就可以,在生产过程中不需要修改模型;
- 缺点:无法随着环境变化而变化模型;
- 解决方案:定时重新批量学习,但是每次重新批量学习时,运算量巨大;在某些环境变化非常快的情况下,甚至是不可能的;
-
在线学习:Online Learning,机器学习算法的流程不变,只不过每次输入样例时,能够获取正确结果,并将此结果给到机器学习算法,改进模型,不断循环;

- 优点:及时反映新的环境变化;
- 缺点:新的数据带来不好的变化;新的数据不准确、质量不高,带来不好的变化,错误的结果;解决方案:需要加强对数据进行监控,及时对异常数据进行检测;
- 其他:也适用于数据量巨大,完全无法批量学习的环境。
对于算法模型本身分类
-
参数学习:对数据概率分布进行建模,有一种最为直接的方法就是先假设这个分布是服从某个特定分布的,比如高斯分布,泊松分布等等,当然这些分布中有些未知参数需要我们求得,而这些参数也正是决定了这个分布的形状的.求解通常根据现有的样本数据集进行,这个参数集 Θ \Theta Θ是一个有限的集合.
推出一个结论就是,在参数化模型的框架下,无论我接下来观察到多少数量的数据,哪怕是无限多个数据,我模型的参数量都只有固定数量多个,那便是 Θ \Theta Θ。也就是说,用有界的参数量(复杂度)对无界的(数据量)的数据分布进行了建模。
-
非参数学习:和参数化模型截然相反的是,对数据分布不进行任何的假设,只是依赖于观察数据,对其进行拟合。换句话说,其认为数据分布不能通过有限的参数集 Θ \Theta Θ进行描述,但是可以通过无限维度的参数 Θ \Theta Θ进行描述,无限维度也就意味着其本质就是一个函数 f ( . ) ∈ R ∞ f(.) \in \R^\infty f(.)∈R∞.
通常,实际中的模型是对这个无限维度参数集的近似,比如神经网络中的参数,虽然参数量通常很大,也有万有拟合理论保证其可以拟合函数,但是其只是对无限维度数据的近似而已。由于非参数化模型依赖于观察数据,因此参数集 Θ \Theta Θ能捕获到的信息量随着观察数据集的数量增加而增加,这个使得模型更加灵活。
机器学习的应用
机器学习的不同模型解决不同应用场景的问题

- 分类是我们知道有哪些组,然后对数据进行判断,判断这些数据到底是预先知道的那些组。举个很简单的例子,比如我们在军训排队时要求男生一组,女生一组,这就是一种分类,我们提前知道要分那些组,然后通过一种算法对输入的数据判定,来分类到已知的类别下,这个就是分类,所以分类属于监督学习方法
- 聚类是实现不知道这批数据有哪些类别或标签,然后通过算法的选择,分析数据参数的特征值,然后进行机器的数据划分,把相似的数据聚到一起,所以它是无监督学习;
- 回归在统计学角度,指的是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。回归分析按照涉及的变量的多少,分为一元回归和多元回归分析;按照因变量的多少,可分为简单回归分析和多重回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。它是对有监督的连续数据结果的预测,比如通过一个人过去年份工资收入相关的影响参数,建立回归模型,然后通过相关的参数的变更来预测他未来工资收入。
- 降维就是去除冗余的特征,降低特征参数的维度降低,用更加少的维度来表示特征
学习环境
- 语言:Python3
- 框架:scikit-learn,基于 SciPy 构建的机器学习 Python 模块
- IDE: jupyter Notebook 可以图形输出,文档编写
- 其它: matolotlib 画图工具,numpy科学计算的基础库
K近邻
我们通过“ K近邻”算法,来了解机器学习的流程.
学习算法原理
K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分类到这个类中。

如上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。
如果K=3,绿色圆点的最邻近的3个点是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
距离的度量
定义中所说的最邻近是如何度量呢?我们怎么知道谁跟测试点最邻近。这里就会引出我们几种度量俩个点之间距离的标准。

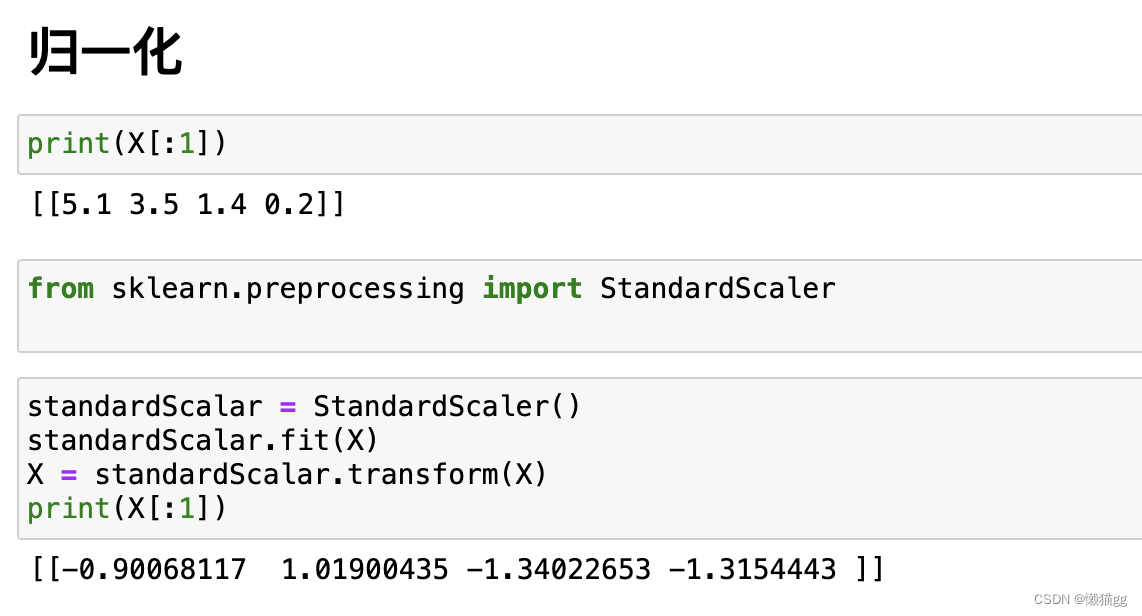
特征归一化
首先举例如下,我用一个人身高(cm)与脚码(尺码)大小来作为特征值,类别为男性或者女性。我们现在如果有5个训练样本,分布如下:
A [(179,42),男]
B [(178,43),男]
C [(165,36)女]
D [(177,42),男]
E [(160,35),女]
很容易看到第一维身高特征是第二维脚码特征的4倍左右,那么在进行距离度量的时候,我们就会偏向于第一维特征。这样造成俩个特征并不是等价重要的,最终可能会导致距离计算错误,从而导致预测错误。
所以我们应该让每个特征都是同等重要的,归一化公式如下:
- 方法一:最小-最大规范化(0-1归一化)

- 方法二:零-均值规范化(z-score标准化)

对一个数值特征来说,很大可能它是服从正态分布的。标准化将这个正态分布调整为均值为0,方差为1的标准正态分布而已.更好保持了样本间距.当样本中有异常点时,归一化有可能将正常的样本“挤”到一起去。
超参数K
k如何选值,如果我们选取较小的k值,那么就会意味着我们的整体模型会变得复杂,容易发生过拟合!

上图中有俩类,一个是黑色的圆点,一个是蓝色的长方形,现在我们的待分类点是红色的五边形。很容易我们能够看出来五边形离黑色的圆点最近,k又等于1,那太好了,我们最终判定待分类点是黑色的圆点。
相反,如果我们选取较大的k值(k=15), 同样待分类点也是黑色
k值既不能过大,也不能过小.通常采取交叉验证法来选取最优的k值.k也被称为超参数
同相的距离公式中的p,也是要通过实验来验证,也是超参数
相对的还有模型参数,即算法运算过程中学习的参数
流程实施
## 导入库
import numpy as np
# 加载莺尾花数据集
from sklearn import datasets
# 导入KNN分类器
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split## 数据导入
# 导入莺尾花数据集
iris = datasets.load_iris()X = iris.data
y = iris.target# 得到训练集合和验证集合, 8: 2
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)## 模型训练,参数的意思是使用欧式距离,k=5
clf = KNeighborsClassifier(n_neighbors=5, p=2, metric="minkowski")
## 使用训练集合,训练数据
clf.fit(X_train, y_train)## 模型预测,把测试集数据转入得到预测结果
X_pred = clf.predict(X_test)
## 预测结果传入得到准确率
acc = sum(X_pred == y_test) / X_pred.shape[0]
print("预测的准确率ACC: %.3f" % acc)
-
业务场景分析就是将我们的业务需求、使用场景转换成机器学习的需求语言,然后分析数据,选择算法的过程。这个是机器学习的准备阶段,主要包括以下3点:
-
业务抽象:莺尾花图区分
-
数据准备:提取莺尾花的特征

-
选择算法:使用KNN算法。
-
-
数据处理就是数据的选择和清洗的过程,数据准备好后,确定了算法,确定了需求,就需要对数据进行处理,数据处理的目的就是尽可能降低对算法的干扰。在数据处理中我们会经常用到
-
去噪 : 将数据分成训练和测试集, 然后通过调节超参数,选出准确率是高的

-
归一: 将数据统一标准化
-
-
特征工程就是对处理完成后的数据进行特征提取,转换成算法模型可以使用的数据。
主要参考
《如何入门机器学习?有哪些值得分享的学习心得?》
《Jupyter Notebook介绍、安装及使用教程》
《什么是机器学习》
《一文搞懂k近邻(k-NN)算法(一)》
《python/scikit-learn 机器学习实战 原理/代码:KNN (K近邻算法)》
相关文章:
什么是机器学习
前言 机器学习(Machine Learning, ML)是一个总称,用于解决由各位程序员自己基于 if-else 等规则开发算法而导致成本过高的问题,想要通过帮助机器 「发现」 它们 「自己」 解决问题的算法来解决 ,而不需要程序员将所有…...

电子桌牌如何赋能数字化会务?以深圳程序员节为例。
10月24日,由深圳市人民政府指导,深圳市工业和信息化局、龙华区人民政府、国家工业信息安全发展研究中心、中国软件行业协会联合主办的2023深圳中国1024程序员节开幕式暨主论坛活动在深圳龙华区启幕。以“领航鹏城发展,码动程序世界”为主题&a…...

打包和部署Java应用程序:Maven和Shell脚本的实用方法
在软件开发领域,高效打包和分发Java应用程序是至关重要的。本博客将探讨一种使用Maven插件和Shell脚本的简化方法,以创建一个分发包,其中包含了您项目的可执行JAR文件、配置文件和一个方便的启动脚本。 步骤1:Maven插件配置 旅程…...
Windows Python3安装salt模块失败处理
复现CVE-2020-11651时候运行CVE-2020-11651的poc时候需要salt模块 在下载时出现了错误 尝试在网上寻找解决方法: 1.更新 setuptools 和 wheel pip install --upgrade setuptools wheel 2. 安装Microsoft Visual C 14.0 因为salt模块包包使用了 C/C 扩展&#x…...

RabbitMQ 消息队列编程
安装与配置 安装 RabbitMQ 读者可以在 RabbitMQ 官方文档中找到完整的安装教程:Downloading and Installing RabbitMQ — RabbitMQ 本文使用 Docker 的方式部署。 RabbitMQ 社区镜像列表:https://hub.docker.com/_/rabbitmq 创建目录用于映射存储卷…...
基于安卓android微信小程序的个人管理小程序
运行环境 开发语言:Java 框架:ssm JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7(一定要5.7版本) 数据库工具:Navicat11 开发软件:eclipse/myeclipse/idea Maven包&a…...

免费图书教材配套资料:Spark大数据技术与应用(第2版)
《Spark大数据技术与应用(第2版)》课程内容全面介绍了Spark大数据技术的相关知识,内容包含包括Spark概述、Scala基础、Spark编程、Spark编程进阶、Spark SQL结构化数据文件处理、Spark Streaming实时计算框架、Spark GraphX图计算框架、Spark…...

SecureCRT9汉化版安装
CRT中文版安装说明 一、安装步骤1. 安装注意:2. 右键压缩包,解压到本地文件夹内3. 解压后进入目录,双击CRT_SFX_91_Run_Script激活脚本 3 如果运行结果是下图,就激活成功了:4. 双击桌面的CRT和FX图标5. 如果提示下图,,点击总是忽略即可6. 第一次安装CRT会出现下图,让你…...
【VSCode】VSCode 使用
目录 文章目录 目录插件配置设置代码不显示 git 提示 "xxx months ago | 1 author"设置打开项目不自动选择 CMakeLists 插件 以下插件为 C 开发偏好设置。 C/CCMakeCMake ToolsGitLensRemote DevelopmentRemote Explorer 配置 设置代码不显示 git 提示 “xxx mon…...

【ARM 嵌入式 编译系列 2.2 -- 如何在Makefile 中添加编译时间 | 编译作者| 编译 git id】
请阅读【ARM GCC 编译专栏导读】 上篇文章:【ARM 嵌入式 编译系列 2.1 – GCC 编译参数学习】 下篇文章:【ARM 嵌入式 编译系列 2.3 – GCC 中指定 ARMv8-M 的 Thumb 指令集参数详细介绍】 文章目录 编译参数介绍 编译参数介绍 通常我们在 OS 启动的时…...
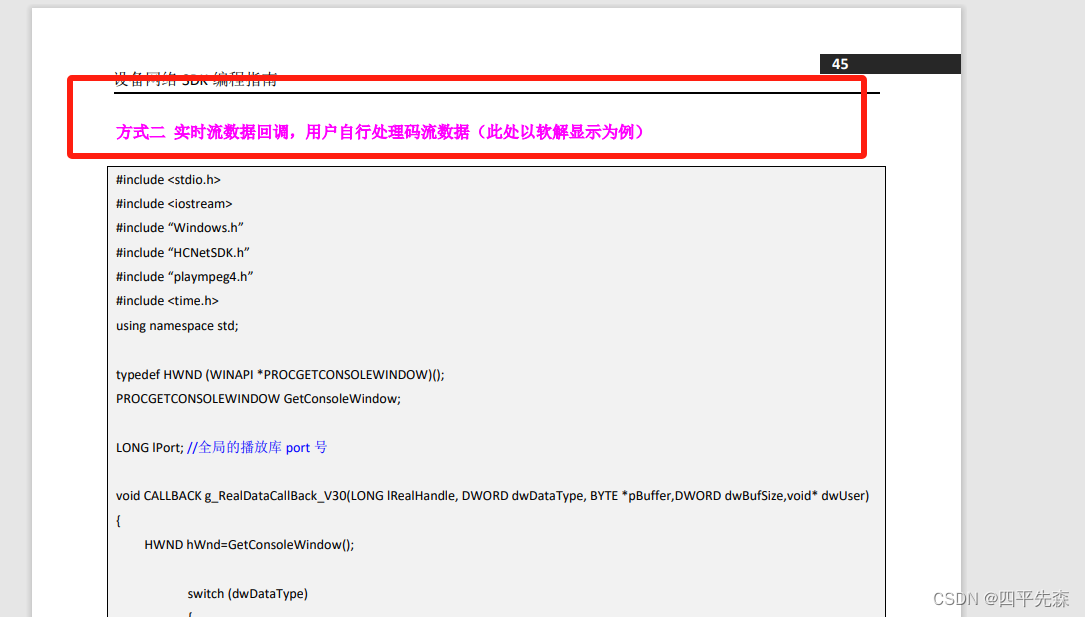
海康威视监控相机的SDK与opencv调用(非工业相机)
1.研究内容 本篇主要对海康威视的监控相机的SDK回调进行研究,并于opencv结合,保存图像,以供后续其他处理,开发语言为C 2.步骤及方法 2.1 海康SDK介绍 海康SDK下载地址 根据自身编译环境,下载对应的SDK,需要注意的是…...
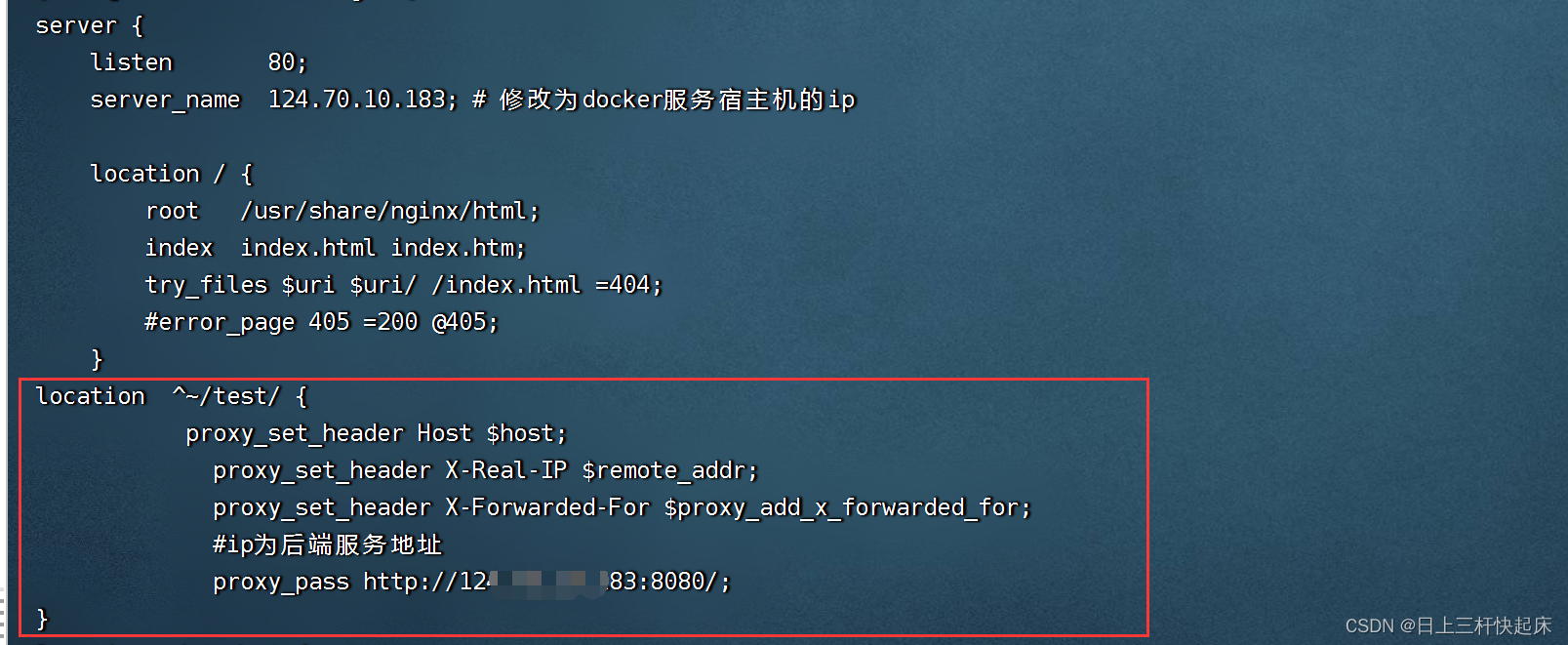
VUE项目部署过程中遇到的错误:POST http://124.60.11.183:9090/test/login 405 (Not Allowed)
我当初报了这个405错误,再网上查了半天,他们都说什么是nginx部署不支持post访问静态资源。 但后面我发现我是因为另一个原因才导致的无法访问。 我再vue中有使用devServer:{ proxy:{} }进行路由转发。 但是!! 在这个配置只…...

MongoDB——索引(单索引,复合索引,索引创建、使用)
MongoDB索引 官方文档 https://docs.mongodb.com/manual/indexes/#create-an-index 默认索引 _id index Mongodb 在 collection 创建时会默认建立一个基于_id 的唯一性索引作为 document 的 primarykey,这个 index 无法被删除 单个字段索引 单字段索引是 Mongo…...

ebpf实战(一)-------监控udp延迟
问题背景: 为了分析udp数据通信中端到端的延迟,我们需要对整个通信链路的每个阶段进行监控,找出延迟最长的阶段. udp接收端有2个主要路径 1.数据包到达本机后,由软中断处理程序将数据包接收并放入udp socket的接收缓冲区 数据接收流程 2. 应用程序调用recvmsg等a…...

中西部各省市翻译协会、公关协会会长金秋圆桌会议圆满结束
中西部翻译协会共同体、中西部公共关系协会共同体共同体创建8年来,已成功举办了八届翻译大赛。时值第九届中西部翻译大赛将拉开序幕,中西部翻译协会共同体、中西部公共关系协会共同体举办的2023年度中西部各省市翻译协会、公关协会会长金秋圆桌会议&…...

极盾故事|“五步”构建某三甲医院数据安全管理集成平台
极盾科技助力某三甲医院,构建统一的数据安全管理集成平台,最终实现: 1、数据安全管理的自动化,覆盖全院医教研管15个应用场景、14项管理活动、300+项数据,完成40+个重要信息系统的自动监控、风…...

【开题报告】基于uni-app的恋爱打卡app的设计与实现
1.选题背景 如今,随着移动互联网的普及和人们对生活品质的追求,恋爱已经成为了许多人关注的焦点。然而,在恋爱过程中,由于种种原因,往往会忽略掉一些重要的时刻和细节,导致感情降温甚至破裂。因此…...

Python 2.7 在 Debian 服务器上获取 URL 时的 SSL 验证失败问题与解决方案
在使用Python的requests库从Debian稳定服务器上获取简单URL时,遇到了SSL证书错误。 根据用户的问题描述,您遇到了SSL证书验证失败的问题。 要解决这个问题,您可以采取以下步骤: 1. 升级到Python 2.7的最新版本: 首…...

导出文件到指定路径??
需求:点击导出pdf按钮,弹出系统文件夹弹框,可以选择保存文件的位置。 经查询window.showSaveFilePicker可实现,但这个api处于实验阶段,且用下来确实和浏览器类型、浏览器版本、以及本身api就不稳定有关系。 代码见下…...
--如何使用spring cloud zuul实现线上流量复制)
腾讯微服务平台TSF学习笔记(二)--如何使用spring cloud zuul实现线上流量复制
需求提了n遍了,好好好,那这个需求就由我测试来做 1.在zuul端配置: ●假设provider-mirror是provider-demo的灰度应用 package com.tencent.tsf.msgw.zuul1.filter;import com.netflix.zuul.ZuulFilter; import com.netflix.zuul.context.Re…...

Refined Now Playing:网易云音乐美化插件终极指南
Refined Now Playing:网易云音乐美化插件终极指南 【免费下载链接】refined-now-playing-netease 🎵 网易云音乐沉浸式播放界面、歌词动画 - BetterNCM 插件 项目地址: https://gitcode.com/gh_mirrors/re/refined-now-playing-netease Refined N…...

如何高效使用F3D三维查看器:现代3D预览的完整指南
如何高效使用F3D三维查看器:现代3D预览的完整指南 【免费下载链接】f3d Fast and minimalist 3D viewer. 项目地址: https://gitcode.com/GitHub_Trending/f3/f3d F3D三维查看器是一款革命性的开源3D模型预览工具,以其极致的速度和简约的设计理念…...

告别网盘限速烦恼!这个免费神器让你下载速度飞起来
告别网盘限速烦恼!这个免费神器让你下载速度飞起来 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

复旦微FM33FR0xx低功耗设计:GPIO唤醒配置详解与实测功耗分析
复旦微FM33FR0xx低功耗设计:GPIO唤醒配置详解与实测功耗分析 在物联网终端设备和电池供电系统中,低功耗设计直接决定了产品的续航能力和市场竞争力。复旦微电子FM33FR0xx系列MCU凭借其出色的功耗控制特性,成为这类应用的热门选择。本文将深入…...

WindowResizer终极指南:免费工具强制调整任意窗口尺寸的完整教程
WindowResizer终极指南:免费工具强制调整任意窗口尺寸的完整教程 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为那些固执的应用程序窗口烦恼吗?有些…...

深入PX4源码:手把手解析姿态控制PID参数如何从QGC地面站映射到飞控代码
深入PX4源码:从QGC参数到飞控代码的PID控制全链路解析 在无人机飞控开发领域,理解参数如何从配置界面传递到实际控制算法是进阶开发的必经之路。本文将以PX4中姿态控制的PID参数为例,完整追踪一个典型参数(如MC_ROLLRATE_P&#x…...

Tailwind CSS 指令与函数
Tailwind CSS 指令与函数学习笔记 一、总览 Tailwind CSS 的指令与函数分为两大类:类别作用域用途指令(Directives)CSS 文件中控制 Tailwind 的编译行为函数(Functions)CSS 文件 / 配置文件中动态引用主题值 二、指令&…...

M2FP人体解析零基础教程:5分钟搭建WebUI服务,一键识别身体部位
M2FP人体解析零基础教程:5分钟搭建WebUI服务,一键识别身体部位 1. 什么是M2FP人体解析? M2FP(Mask2Former-Parsing)是一种先进的计算机视觉模型,专门用于识别图片中人物的各个身体部位。想象一下…...

贝叶斯最优分类器:原理、实现与应用指南
1. 贝叶斯最优分类器入门指南在机器学习领域,分类问题是我们每天都要面对的基础挑战。当我在金融风控系统第一次接触贝叶斯最优分类器时,这个理论上完美的分类器立刻吸引了我——它就像分类问题中的"理想终点",为我们提供了评估其他…...

ControlNet与Stable Diffusion整合:AI图像生成精准控制指南
1. ControlNet与Stable Diffusion深度整合指南作为一名长期从事AI图像生成的技术实践者,我见证了Stable Diffusion从基础文本生成到精细化控制的发展历程。ControlNet的出现彻底改变了我们与扩散模型的交互方式,它就像给画家提供了一套精准的素描工具&am…...