【分布式】小白看Ring算法 - 03
相关系列
【分布式】NCCL部署与测试 - 01
【分布式】入门级NCCL多机并行实践 - 02
【分布式】小白看Ring算法 - 03
【分布式】大模型分布式训练入门与实践 - 04
概述
NCCL(NVIDIA Collective Communications Library)是由NVIDIA开发的一种用于多GPU间通信的库。NCCL的RING算法是NCCL库中的一种通信算法,用于在多个GPU之间进行环形通信。
RING算法的基本思想是将多个GPU连接成一个环形结构,每个GPU与相邻的两个GPU进行通信。数据沿着环形结构传递,直到到达发送方的位置。这样的环形结构可以有效地利用GPU之间的带宽,提高通信的效率。
RING算法的步骤如下:
Scatter-Reduce
以Scatter-Reduce为例,假设有4张GPU,RANK_NUM=4。
则需要根据RANK_NUM把每张CPU划分为4个chunk。
为什么要这么划分?
在 NCCL 中,划分 chunk 的数量与 GPU 的数量相关联,这是因为 chunk 的目的是将大的消息划分为多个小的数据块,以便并行处理和降低通信的延迟。这种划分通常会基于 GPU 的数量,以确保每个 GPU 可以处理到一部分数据块,从而提高整体的通信效率。
- 并行性: 划分
chunk可以增加通信的并行性。每个 GPU 处理自己的数据块,不同的 GPU 可以并行地执行通信操作,从而提高整体的吞吐量。 - 减少延迟: 较小的数据块通常可以更快地传输,因此通过划分
chunk,可以减少每个通信操作的延迟。这对于一些对通信延迟敏感的应用程序是至关重要的。 - 资源分配: NCCL 可能会根据 GPU 的数量来分配适当的资源,例如内存等。通过划分
chunk,可以更好地管理这些资源。 - Load Balancing: 均衡负载是分布式系统中的一个关键问题。通过根据 GPU 的数量划分
chunk,可以更容易地实现负载均衡,确保每个 GPU 处理的工作量相对均匀。
划分了chunk以后,我们一次RING的通路将会走通4块GPU,每次只传输一块chunk的数据。这样需要走很多次通路才能把所有数据传输完。
假如 ringIx=0,第一次循环到第三次循环时:

我们将绿色视为这次循环需要传输的数据。
数据ABCD在不同的GPU中流通。
最终达到以下情况,scatter-reduce就完成了:

将图中蓝色部分输出,就完成了一次ring算法下的Scatter-Reduce。
当然,如果要做All-Reduce,此时不需要继续按照原来的规则计算类,理论上只需要再算一次All-Gather,就能把蓝色的块分发给其他几块卡。All-Reduce的相关讲解网络上很多。此处就不讲了。
NCCL代码流程
fillInfo:
这段代码在init.cc中
static ncclResult_t fillInfo(struct ncclComm* comm, struct ncclPeerInfo* info, uint64_t commHash) {info->rank = comm->rank;CUDACHECK(cudaGetDevice(&info->cudaDev));info->hostHash=getHostHash()+commHash;info->pidHash=getPidHash()+commHash;// Get the device MAJOR:MINOR of /dev/shm so we can use that// information to decide whether we can use SHM for inter-process// communication in a container environmentstruct stat statbuf;SYSCHECK(stat("/dev/shm", &statbuf), "stat");info->shmDev = statbuf.st_dev;info->busId = comm->busId;NCCLCHECK(ncclGpuGdrSupport(&info->gdrSupport));return ncclSuccess;
}
这段代码的目的是为了获取和存储与通信相关的信息,以便在NCCL通信中使用。其中包括设备标识、主机哈希、进程ID哈希、共享内存设备标识、总线ID以及对GDR的支持情况等。
在initTransportsRank中,搜索完信息并作第一次AllGather, 收集所有通信节点的信息。
然后再为通信组分配额外的内存,以存储每个通信节点的信息(包括一个额外的用于表示CollNet root的位置)。
遍历节点和复制信息时,需要检查是否存在相同主机哈希和总线ID的重复GPU。如果是,发出警告并返回ncclInvalidUsage错误。
后面的一系列过程就是计算路径,然后这里涉及一些搜索算法,通常会将BFS搜索到的路径都存在一个位置,选择更优的路径。
搜索时也会根据实际情况判断选择ring算法或者tree算法。
搜索内容可能是无穷的,因此NCCL设置了一个超时时间,超过该时间则终端搜索。
完成路径的计算后,再做一次AllGather。
来到scatter-reduce的实现部分:
size_t realChunkSize;if (Proto::Id == NCCL_PROTO_SIMPLE) {realChunkSize = min(chunkSize, divUp(size-gridOffset, nChannels));realChunkSize = roundUp(realChunkSize, (nthreads-WARP_SIZE)*sizeof(uint64_t)/sizeof(T));}else if (Proto::Id == NCCL_PROTO_LL)realChunkSize = size-gridOffset < loopSize ? args->coll.lastChunkSize : chunkSize;else if (Proto::Id == NCCL_PROTO_LL128)realChunkSize = min(divUp(size-gridOffset, nChannels*minChunkSizeLL128)*minChunkSizeLL128, chunkSize);realChunkSize = int(realChunkSize);ssize_t chunkOffset = gridOffset + bid*int(realChunkSize);
这里涉及了NCCL协议的通信模式:
一共有三种,分别是NCCL_PROTO_SIMPLE、NCCL_PROTO_LL和NCCL_PROTO_LL128。
NCCL_PROTO_SIMPLE:
描述: 使用简单的通信协议。
差异点: 计算realChunkSize时,采用了一些特殊的逻辑,其中min(chunkSize, divUp(size-gridOffset, nChannels))用于确定实际的块大小,并通过roundUp调整为合适的大小。这可能涉及到性能和资源的考虑,以及对通信模式的调整。
NCCL_PROTO_LL:
描述: 使用连续链表(Linked List,LL)的通信协议。
差异点: 在计算realChunkSize时,首先检查size-gridOffset < loopSize条件,如果为真,则使用args->coll.lastChunkSize,否则使用默认的chunkSize。这可能与LL协议的特性有关,具体考虑了循环的情况。
NCCL_PROTO_LL128:
描述: 使用连续链表的通信协议,每次传输128字节。
差异点: 计算realChunkSize时,采用了min(divUp(size-gridOffset, nChannels*minChunkSizeLL128)*minChunkSizeLL128, chunkSize)的逻辑。这考虑了128字节的限制,以及对通信块大小的一些限制。
总体来说,这三种协议模式的区别主要体现在计算realChunkSize的逻辑上,这可能受到性能、资源利用、通信模式等方面的不同考虑。具体选择哪种协议模式通常取决于系统的特性和应用场景的需求。
| Protocol Mode | Description | Calculation of realChunkSize |
|---|---|---|
NCCL_PROTO_SIMPLE | Uses a simple communication protocol. | realChunkSize = roundUp(min(chunkSize, divUp(size-gridOffset, nChannels)), (nthreads-WARP_SIZE)*sizeof(uint64_t)/sizeof(T)) |
NCCL_PROTO_LL | Uses a linked list (LL) communication protocol. | realChunkSize = size-gridOffset < loopSize ? args->coll.lastChunkSize : chunkSize |
NCCL_PROTO_LL128 | Uses a linked list (LL) communication protocol, with each transfer involving 128 bytes. | realChunkSize = min(divUp(size-gridOffset, nChannels*minChunkSizeLL128)*minChunkSizeLL128, chunkSize) |
最后是正式计算部分:
/////////////// begin ReduceScatter steps ///////////////ssize_t offset;int nelem = min(realChunkSize, size-chunkOffset);int rankDest;// step 0: push data to next GPUrankDest = ringRanks[nranks-1];offset = chunkOffset + rankDest * size;prims.send(offset, nelem);// k-2 steps: reduce and copy to next GPUfor (int j=2; j<nranks; ++j) {rankDest = ringRanks[nranks-j];offset = chunkOffset + rankDest * size;prims.recvReduceSend(offset, nelem);}// step k-1: reduce this buffer and data, which will produce the final resultrankDest = ringRanks[0];offset = chunkOffset + rankDest * size;prims.recvReduceCopy(offset, chunkOffset, nelem, /*postOp=*/true);
ssize_t offset; int nelem = min(realChunkSize, size-chunkOffset); int rankDest;:
offset 是一个偏移量变量,用于指定数据在通信缓冲区中的位置。
nelem 表示每次操作的元素个数,取 realChunkSize 和 size-chunkOffset 的较小值。
rankDest 是目标GPU的排名。
第一步:将数据推送到下一个GPU。
计算目标GPU的排名 rankDest 和在通信缓冲区中的偏移量 offset。
调用 prims.send 函数,将数据从当前GPU发送到目标GPU。
// k-2 steps: reduce and copy to next GPU:
第2到第k-1步:
将数据在环形路径上经过各个GPU节点,依次进行Reduce操作,并将结果复制到下一个GPU。
通过循环,依次计算目标GPU的排名 rankDest 和在通信缓冲区中的偏移量 offset。
调用 prims.recvReduceSend 函数,接收数据并执行Reduce操作,然后将结果发送到下一个GPU。
第k-1步:
将最后一个GPU的数据进行Reduce操作,得到最终的结果。
计算目标GPU的排名 rankDest 和在通信缓冲区中的偏移量 offset。
调用 prims.recvReduceCopy 函数,接收数据并执行Reduce操作,然后将结果复制到指定的位置,最终产生最终的ReduceScatter结果。
在实际运行中,我们在host端的代码只是规定计算流,当这些定义好的原子操作加入到stream中去以后,就由固定的流来分配实际运行的情况了。
加入Barria,在本地(intra-node)执行一个屏障操作,确保同一节点内的所有GPU都达到了同步点。
// Compute time models for algorithm and protocol combinationsNCCLCHECK(ncclTopoTuneModel(comm, minCompCap, maxCompCap, &treeGraph, &ringGraph, &collNetGraph));// Compute nChannels per peer for p2pNCCLCHECK(ncclTopoComputeP2pChannels(comm));if (ncclParamNvbPreconnect()) {// Connect p2p when using NVB pathint nvbNpeers;int* nvbPeers;NCCLCHECK(ncclTopoGetNvbGpus(comm->topo, comm->rank, &nvbNpeers, &nvbPeers));for (int r=0; r<nvbNpeers; r++) {int peer = nvbPeers[r];int delta = (comm->nRanks + (comm->rank-peer)) % comm->nRanks;for (int c=0; c<comm->p2pnChannelsPerPeer; c++) {int channelId = (delta+comm->p2pChannels[c]) % comm->p2pnChannels;if (comm->channels[channelId].peers[peer].recv[0].connected == 0) { // P2P uses only 1 connectorcomm->connectRecv[peer] |= (1<<channelId);}}delta = (comm->nRanks - (comm->rank-peer)) % comm->nRanks;for (int c=0; c<comm->p2pnChannelsPerPeer; c++) {int channelId = (delta+comm->p2pChannels[c]) % comm->p2pnChannels;if (comm->channels[channelId].peers[peer].send[0].connected == 0) { // P2P uses only 1 connectorcomm->connectSend[peer] |= (1<<channelId);}}}NCCLCHECK(ncclTransportP2pSetup(comm, NULL, 0));free(nvbPeers);}NCCLCHECK(ncclCommSetIntraProc(comm, intraProcRank, intraProcRanks, intraProcRank0Comm));/* Local intra-node barrier */NCCLCHECK(bootstrapBarrier(comm->bootstrap, comm->intraNodeGlobalRanks, intraNodeRank, intraNodeRanks, (int)intraNodeRank0pidHash));if (comm->nNodes) NCCLCHECK(ncclProxyCreate(comm));
以上就是整个scatter-reduce的流程。
相关系列
【分布式】NCCL部署与测试 - 01
【分布式】入门级NCCL多机并行实践 - 02
【分布式】小白看Ring算法 - 03
【分布式】大模型分布式训练入门与实践 - 04
相关文章:
【分布式】小白看Ring算法 - 03
相关系列 【分布式】NCCL部署与测试 - 01 【分布式】入门级NCCL多机并行实践 - 02 【分布式】小白看Ring算法 - 03 【分布式】大模型分布式训练入门与实践 - 04 概述 NCCL(NVIDIA Collective Communications Library)是由NVIDIA开发的一种用于多GPU间…...

使用Git bash切换Gitee、GitHub多个Git账号
Git是分布式代码管理工具,使用命令行的方式提交commit、revert回滚代码。这里介绍使用Git bash软件来切换Gitee、GitHub账号。 假设在gitee.com上的邮箱是alicefoxmail.com 、用户名为alice;在github上的邮箱是bobfoxmail.com、用户名为bob。 账号…...
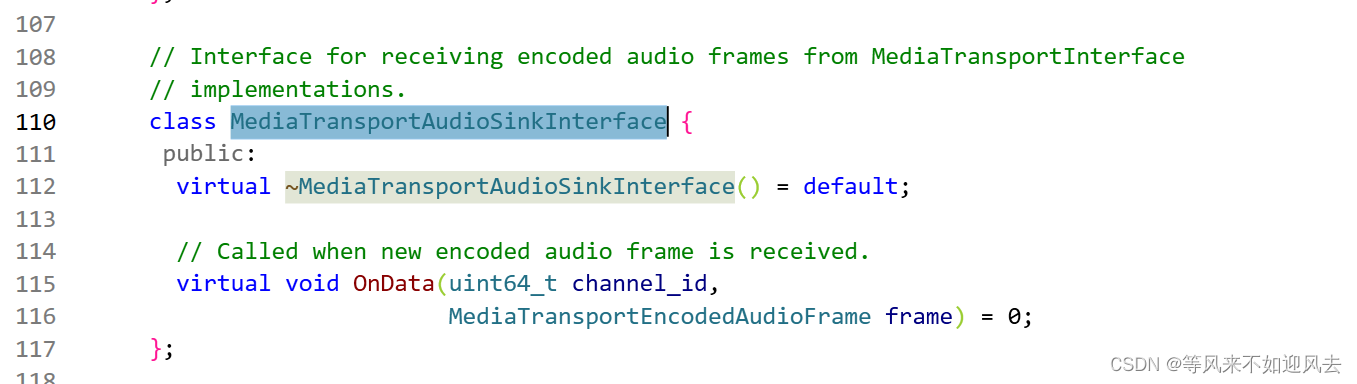
【RtpRtcp】1: webrtc m79:audio的ChannelReceive 创建并使用
m79中,RtpRtcp::Create 的调用很少 不知道谁负责创建ChannelReceiveclass ChannelReceive : public ChannelReceiveInterface,public MediaTransportAudioSinkInterface {接收编码后的音频帧:接收rtcp包:...

Ubuntu系统安装docker
1.检查是否安装老版本 检查卸载老版本docker ubuntu下自带了docker的库,不需要添加新的源。 但是ubuntu自带的docker版本太低,需要先卸载旧的再安装新的。 apt-get remove docker docker-engine docker.io containerd runc 如果不能正常卸载&#x…...
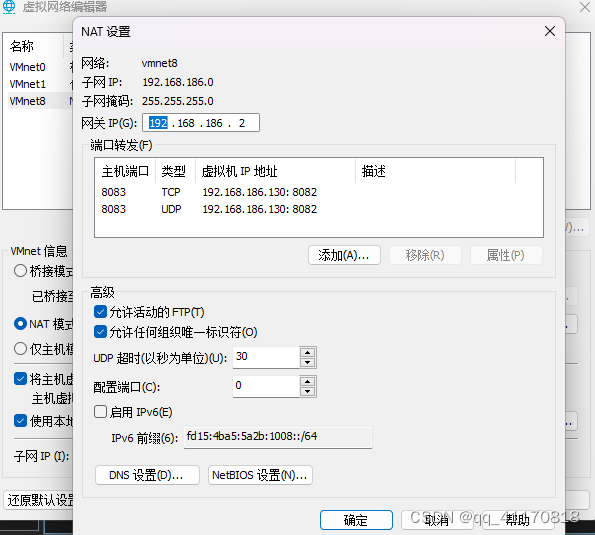
如何访问linux上的web服务
1.获取服务运行端口 例如8080 2.如果时vmware 需要先配置转发端口和主机ip 主机ip需要未使用的 例如: 3.查看虚拟机防火墙设置 centos8 为例 : firewall-cmd --zonepublic --list-ports 查看放通端口 如果没有放通 firewall-cmd --zonepublic --add-p…...

Vatee万腾的数字化掌舵:Vatee科技解决方案的全面引领
随着数字化时代的到来,Vatee万腾凭借其卓越的科技实力和全面的解决方案,成功地在数字化探索的航程中掌舵引领。 首先,Vatee万腾以其强大的数字化科技实力成为行业的引领者。vatee万腾不仅在人工智能、大数据分析、云计算等前沿领域取得了显著…...
YOLOv5 第Y6周 模型改进
🍨 本文为[🔗365天深度学习训练营学习记录博客 🍦 参考文章:365天深度学习训练营 🍖 原作者:[K同学啊] 🚀 文章来源:[K同学的学习圈子](https://www.yuque.com/mingtian-fkmxf/zxwb4…...

Unity Android FireBase bugly报错查询
报错如下图,注意,标红的三处 使用的il2cpp和架构是arm64-v8a 那我们就可以根据这些去找对应的符号表,在unity安装目录下 Unity2020.3.33f1\Editor\Data\PlaybackEngines\AndroidPlayer\Variations\il2cpp\Release\Symbols\arm64-v8a 找到l…...

React中如何解决点击<Tree>节点前面三角区域不触发onClick事件
React中如何解决点击节点前面三角区域不触发onClick事件,如何区别‘左边’和‘右边’区域点击逻辑呢?(Tree引用开源组件TDesign) 只需要在onClick里面加限制一下就行: <TreeexpandMutexactivabletransitiondata{t…...
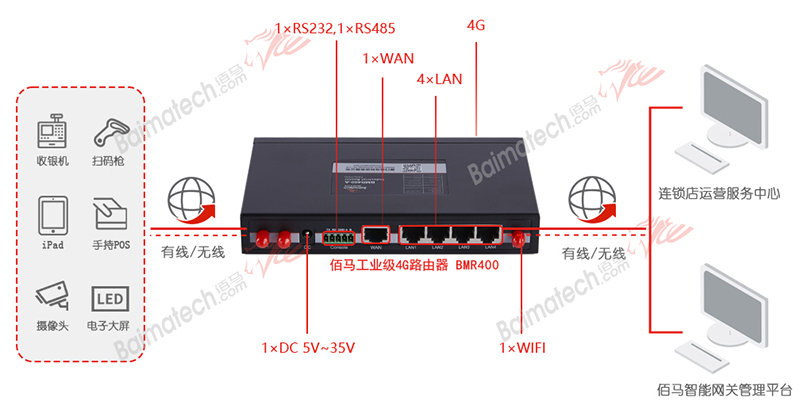
如何利用4G路由器构建茶饮连锁店物联网
随着年轻消费群体的增长,加上移动互联网营销的助推,各类新式奶茶消费风靡大街小巷,也促进了品牌奶茶连锁店的快速扩张。 在店铺快速扩张的局势下,品牌总部对于各间连锁店的零售统计、营销规划、物流调配、卫生监测、安全管理等事务…...

【2024系统架构设计】 系统架构设计师第二版-大数据架构理论设计与实践
目录 1 传统数据库的数据过载问题 2 大数据处理系统 3 Lambda架构 4 Kappa架构...

正整数分解
题目编号:Exp08-Basic01,GJBook3-12-05 题目名称:正整数分解 题目描述:正整数n,按第一项递减的顺序依次输出其和等于n的所有不增的正整数和式。 输入:一个正整数n(0<n≤15)。 …...
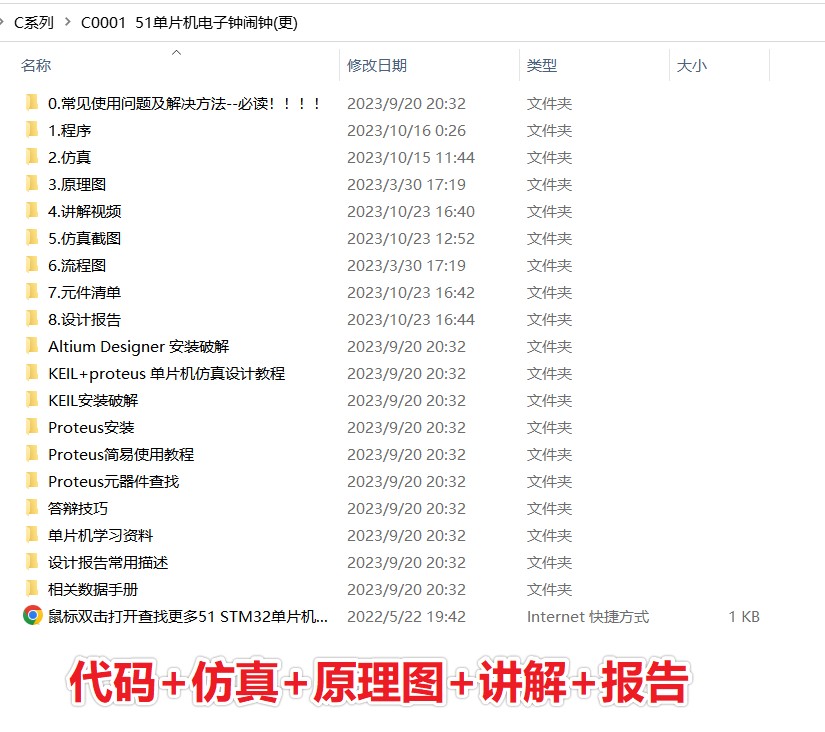
基于51单片机电子钟闹钟LCD1602显示proteus仿真设计
基于51单片机的LCD1602电子钟闹钟proteus仿真设计 基于51单片机的LCD1602电子钟闹钟proteus仿真设计功能介绍:仿真图:原理图:设计报告:程序:器件清单:资料清单&&下载链接: 基于51单片机…...

第三节-Android10.0 Binder通信原理(三)-ServiceManager篇
1、概述 在Android中,系统提供的服务被包装成一个个系统级service,这些service往往会在设备启动之时添加进Android系统,当某个应用想要调用系统某个服务的功能时,往往是向系统发出请求,调用该服务的外部接口。在上一节…...

使用XHProf查找PHP性能瓶颈
使用XHProf查找PHP性能瓶颈 XHProf是facebook 开发的一个测试php性能的扩展,本文记录了在PHP应用中使用XHProf对PHP进行性能优化,查找性能瓶颈的方法。 下载 网上很多是编译安装xhprof-0.9.4版本,应该是用php5,在php8.0下编译x…...
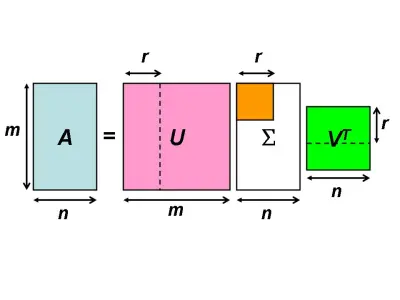
矩阵论(Matrix)
大纲 矩阵微积分:多元微积分的一种特殊表达,尤其是在矩阵空间上进行讨论的时候逆矩阵(inverse matrix)矩阵分解:特征分解(Eigendecomposition),又称谱分解(Spectral decomposition…...
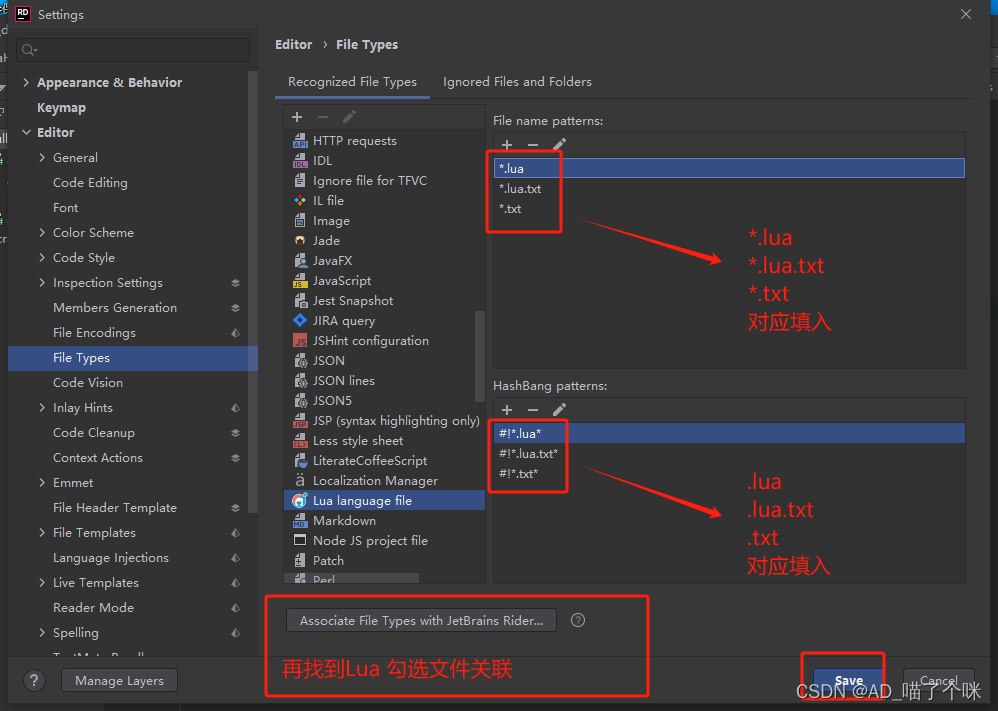
解决Emmy Lua插件在IDEA或 Reder 没有代码提示的问题(设置文件关联 增加对.lua.txt文件的支持)
目录 Reder版本2019.x Reder版本2021.1.5x Reder版本2019.x 解决Emmy Lua插件在IDEA或 Reder 没有代码提示的问题(设置文件关联 增加对.lua.txt文件的支持) Reder版本2021.1.5x 解决Emmy Lua插件在IDEA或 Reder 没有代码提示的问题(设置文件关联 增加对.lua.txt文件的支持)…...
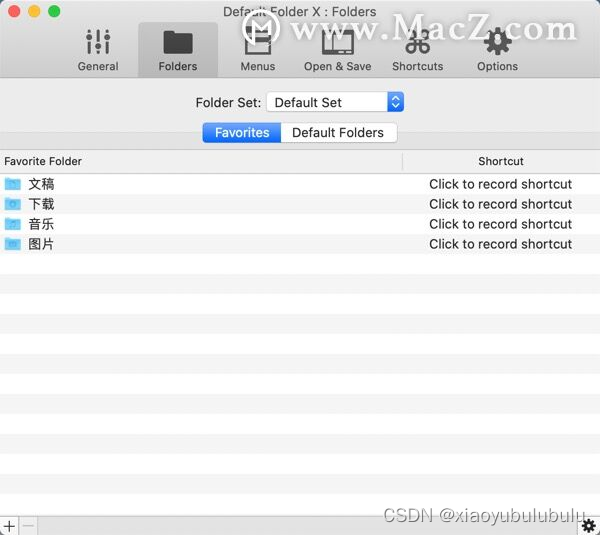
macos端文件夹快速访问工具 Default Folder X 最新for mac
Default Folder X 是一款实用的工具,提供了许多增强功能和快捷方式,使用户能够更高效地浏览和管理文件。它的快速导航、增强的文件对话框、自定义设置和快捷键等功能,可以大大提升用户的工作效率和文件管理体验。 快速导航和访问:…...
树形 DP:树的直径
leetCode 104.二叉树的最大深度104. 二叉树的最大深度 - 力扣(LeetCode) class Solution { public:int maxDepth(TreeNode* root) {if(root nullptr) return 0;int lDepth maxDepth(root->left);int rDepth maxDepth(root->right);return max(l…...

【Python百宝箱】第三维度的魔法:探索Python游戏世界
Python在游戏开发中的魔力 前言 游戏开发一直是计算机科学中最引人入胜和具有挑战性的领域之一。随着技术的不断进步,开发者们寻找着更快、更灵活的工具来实现他们的创意。在这个探索的过程中,Python以其简洁、易学和强大的特性成为了游戏开发的热门选…...

Jenkins远程部署Windows服务器,我踩过的那些坑:从SSH连接到计划任务
Jenkins远程部署Windows服务器避坑实战:SSH连接与计划任务深度解析 当Jenkins的自动化部署遇上Windows服务器,总会遇到一些让人抓狂的"坑"。作为一名经历过无数次深夜调试的DevOps工程师,我想分享那些让我掉进坑里又爬出来的实战经…...
)
磁芯选型不求人:用AP法快速估算EE、PQ、RM型磁芯尺寸(以TDK PC40为例)
磁芯选型实战指南:AP法在EE、PQ、RM型磁芯快速筛选中的应用 当你面对TDK、Magnetics等厂商琳琅满目的磁芯型号时,是否感到无从下手?EE、PQ、RM这些不同系列到底该如何选择?本文将带你用工程化的视角,通过AP法快速锁定最…...

ThinkPHP6 路由规则详解与实战:除了基础用法,这些高级匹配和分组技巧你用过吗?
ThinkPHP6 路由规则深度解析:从基础匹配到高阶实战技巧 在构建现代Web应用时,优雅的路由设计往往决定了API的可维护性和扩展性。ThinkPHP6作为PHP主流框架,其路由系统经过多次迭代已经发展出丰富的功能集,但大多数开发者仅停留在基…...

Qt表格里放下拉框,选setIndexWidget还是QItemDelegate?一个真实项目踩坑后的选择指南
Qt表格下拉框方案深度对比:从setIndexWidget到QItemDelegate的实战抉择 在开发一个需要动态生成带下拉框表格的报表工具时,我遇到了一个看似简单却暗藏玄机的技术选择——如何在QTableView中实现下拉框功能?经过反复试错和性能测试࿰…...
)
手把手教你用Vector工具链集成AUTOSAR RTM模块,实测CPU负载(含避坑点)
实战指南:Vector工具链集成AUTOSAR RTM模块与CPU负载监控全解析 在嵌入式软件开发领域,特别是汽车电子控制单元(ECU)开发中,实时监控系统资源使用情况是确保软件可靠性的关键环节。当项目周期紧张且资源有限时,如何快速实现CPU负载…...
)
Python Flask + Vue3 构建的电商系统(含完整文档与可运行源码)
温馨提示:文末有联系方式项目概览 这是一套功能完备、开箱即用的在线商城系统,采用主流前后端分离架构:后端基于Python Flask框架开发,数据库选用稳定成熟的MySQL 5.7,前端使用现代化响应式框架Vue3,服务环…...

Kali_Linux:从入门到精通,用VMware搭建你的专
Kali Linux:从入门到精通,用VMware搭建你的专属渗透测试实验室 资料在文章末尾 摘要: 本文带你全面了解Kali Linux这款专为网络安全专业人士设计的操作系统。从它的历史起源、核心作用,到在VMware虚拟机中的完整安装配置&#x…...

诊断测试效率翻倍:深度解析CDD文件在CANoe、Diva与VTsystem中的核心配置项
诊断测试效率翻倍:深度解析CDD文件在CANoe、Diva与VTsystem中的核心配置项 在汽车电子诊断测试领域,CDD文件的质量直接影响着自动化测试的效率和可靠性。对于使用Vector工具链(CANoe/Diva/VTsystem)的中高级工程师而言,…...

如何用Windows Cleaner解决C盘爆红:3步让你的Windows重获新生
如何用Windows Cleaner解决C盘爆红:3步让你的Windows重获新生 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是不是也经历过这样的场景:…...

WinSpy++深度解析:5个实战技巧助你高效调试Windows窗口界面
WinSpy深度解析:5个实战技巧助你高效调试Windows窗口界面 【免费下载链接】winspy WinSpy 项目地址: https://gitcode.com/gh_mirrors/wi/winspy WinSpy是一款专业的Windows窗口探查工具,专为开发者和技术爱好者设计,能够深入分析、调…...