LLMLingua:集成LlamaIndex,对提示进行压缩,提供大语言模型的高效推理
大型语言模型(llm)的出现刺激了多个领域的创新。但是在思维链(CoT)提示和情境学习(ICL)等策略的驱动下,提示的复杂性不断增加,这给计算带来了挑战。这些冗长的提示需要大量的资源来进行推理,因此需要高效的解决方案,本文将介绍LLMLingua与专有的LlamaIndex的进行集成执行高效推理。

LLMLingua是微软的研究人员发布在EMNLP 2023的一篇论文,LongLLMLingua是一种通过快速压缩增强llm在长上下文场景中感知关键信息的能力的方法。
LLMLingua与llamindex的协同工作
LLMLingua作为解决LLM应用程序中冗长提示的开创性解决方案而出现。该方法侧重于压缩冗长提示,同时保证语义完整性和提高推理速度。它结合了各种压缩策略,提供了一种微妙的方法来平衡提示长度和计算效率。
以下是LLMLingua与LlamaIndex集成的优势:
LLMLingua与LlamaIndex的集成标志着llm在快速优化方面迈出了重要的一步。LlamaIndex是一个包含为各种LLM应用程序量身定制的预优化提示的专门的存储库,通过这种集成LLMLingua可以访问丰富的特定于领域的、经过微调的提示,从而增强其提示压缩能力。
LLMLingua的提示压缩技术和LlamaIndex的优化提示库之间的协同作用提高了LLM应用程序的效率。利用LLAMA的专门提示,LLMLingua可以微调其压缩策略,确保保留特定于领域的上下文,同时减少提示长度。这种协作极大地加快了推理速度,同时保留了关键领域的细微差别。
LLMLingua与LlamaIndex的集成扩展了其对大规模LLM应用程序的影响。通过利用LLAMA的专业提示,LLMLingua优化了其压缩技术,减轻了处理冗长提示的计算负担。这种集成不仅加速了推理,而且确保了关键领域特定信息的保留。
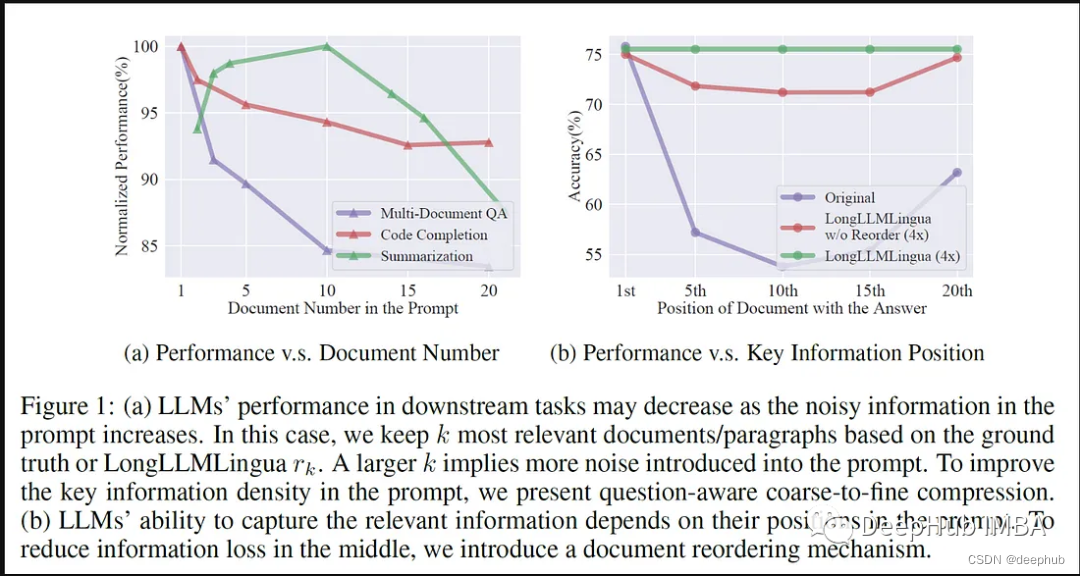
LLMLingua与LlamaIndex的工作流程
使用LlamaIndex实现LLMLingua涉及到一个结构化的过程,该过程利用专门的提示库来实现高效的提示压缩和增强的推理速度。
- 框架集成
首先需要在LLMLingua和LlamaIndex之间建立连接。这包括访问权限、API配置和建立连接,以便及时检索。
- 预先优化提示的检索
LlamaIndex充当专门的存储库,包含为各种LLM应用程序量身定制的预优化提示。LLMLingua访问这个存储库,检索特定于域的提示,并利用它们进行提示压缩。
- 提示压缩技术
LLMLingua使用它的提示压缩方法来简化检索到的提示。这些技术专注于压缩冗长的提示,同时确保语义一致性,从而在不影响上下文或相关性的情况下提高推理速度。
- 微调压缩策略
LLMLingua基于从LlamaIndex获得的专门提示来微调其压缩策略。这种细化过程确保保留特定于领域的细微差别,同时有效地减少提示长度。
- 执行与推理
一旦使用LLMLingua的定制策略与LlamaIndex的预优化提示进行压缩,压缩后的提示就可以用于LLM推理任务。此阶段涉及在LLM框架内执行压缩提示,以实现高效的上下文感知推理。
- 迭代改进和增强
代码实现不断地经历迭代的细化。这个过程包括改进压缩算法,优化从LlamaIndex中检索提示,微调集成,确保压缩后的提示和LLM推理的一致性和增强的性能。
- 测试和验证
如果需要还可以进行测试和验证,这样可以评估LLMLingua与LlamaIndex集成的效率和有效性。评估性能指标以确保压缩提示保持语义完整性并在不影响准确性的情况下提高推理速度。
代码实现
下面我们将开始深入研究LLMLingua与LlamaIndex的代码实现
安装程序包:
# Install dependency.!pip install llmlingua llama-index openai tiktoken -q # Using the OAIimport openaiopenai.api_key = "<insert_openai_key>"
获取数据:
!wget "https://www.dropbox.com/s/f6bmb19xdg0xedm/paul_graham_essay.txt?dl=1" -O paul_graham_essay.txt
加载模型:
from llama_index import (VectorStoreIndex,SimpleDirectoryReader,load_index_from_storage,StorageContext,)# load documentsdocuments = SimpleDirectoryReader(input_files=["paul_graham_essay.txt"]).load_data()
向量存储:
index = VectorStoreIndex.from_documents(documents)retriever = index.as_retriever(similarity_top_k=10)question = "Where did the author go for art school?"# Ground-truth Answeranswer = "RISD"contexts = retriever.retrieve(question)contexts = retriever.retrieve(question)context_list = [n.get_content() for n in contexts]len(context_list)#Output #10
原始提示和返回
# The response from original promptfrom llama_index.llms import OpenAIllm = OpenAI(model="gpt-3.5-turbo-16k")prompt = "\n\n".join(context_list + [question])response = llm.complete(prompt)print(str(response))#OutputThe author went to the Rhode Island School of Design (RISD) for art school.
设置 LLMLingua
from llama_index.query_engine import RetrieverQueryEnginefrom llama_index.response_synthesizers import CompactAndRefinefrom llama_index.indices.postprocessor import LongLLMLinguaPostprocessornode_postprocessor = LongLLMLinguaPostprocessor(instruction_str="Given the context, please answer the final question",target_token=300,rank_method="longllmlingua",additional_compress_kwargs={"condition_compare": True,"condition_in_question": "after","context_budget": "+100","reorder_context": "sort", # enable document reorder,"dynamic_context_compression_ratio": 0.3,},)
通过LLMLingua进行压缩
retrieved_nodes = retriever.retrieve(question)synthesizer = CompactAndRefine()from llama_index.indices.query.schema import QueryBundle# postprocess (compress), synthesizenew_retrieved_nodes = node_postprocessor.postprocess_nodes(retrieved_nodes, query_bundle=QueryBundle(query_str=question))original_contexts = "\n\n".join([n.get_content() for n in retrieved_nodes])compressed_contexts = "\n\n".join([n.get_content() for n in new_retrieved_nodes])original_tokens = node_postprocessor._llm_lingua.get_token_length(original_contexts)compressed_tokens = node_postprocessor._llm_lingua.get_token_length(compressed_contexts)打印2个结果对比:
print(compressed_contexts)print()print("Original Tokens:", original_tokens)print("Compressed Tokens:", compressed_tokens)print("Comressed Ratio:", f"{original_tokens/(compressed_tokens + 1e-5):.2f}x")
打印的结果如下:
next Rtm's advice hadn' included anything that. I wanted to do something completely different, so I decided I'd paint. I wanted to how good I could get if I focused on it. the day after stopped on YC, I painting. I was rusty and it took a while to get back into shape, but it was at least completely engaging.1]I wanted to back RISD, was now broke and RISD was very expensive so decided job for a year and return RISD the fall. I got one at Interleaf, which made software for creating documents. You like Microsoft Word? Exactly That was I low end software tends to high. Interleaf still had a few years to live yet. []the Accademia wasn't, and my money was running out, end year back to thelot the color class I tookD, but otherwise I was basically myself to do that for in993 I dropped I aroundidence bit then my friend Par did me a big A rent-partment building New York. Did I want it Itt more my place, and York be where the artists. wanted [For when you that ofs you big painting of this type hanging in the apartment of a hedge fund manager, you know he paid millions of dollars for it. That's not always why artists have a signature style, but it's usually why buyers pay a lot for such work. [6]Original Tokens: 10719Compressed Tokens: 308Comressed Ratio: 34.80x
验证输出:
response = synthesizer.synthesize(question, new_retrieved_nodes)print(str(response))#Output#The author went to RISD for art school.
总结
LLMLingua与LlamaIndex的集成证明了协作关系在优化大型语言模型(LLM)应用程序方面的变革潜力。这种协作彻底改变了即时压缩方法和推理效率,为上下文感知、简化的LLM应用程序铺平了道路。
这种集成不仅加快了推理速度,而且确保了在压缩提示中保持语义完整性。基于LlamaIndex特定领域提示的压缩策略微调在提示长度减少和基本上下文保留之间取得了平衡,从而提高了LLM推理的准确性。
从本质上讲,LLMLingua与LlamaIndex的集成超越了传统的提示压缩方法,为未来大型语言模型应用程序的优化、上下文准确和有效地针对不同领域进行定制奠定了基础。这种协作集成预示着大型语言模型应用程序领域中效率和精细化的新时代的到来。
如果你对LLMLingua感兴趣,在线的DMEO,还有论文,源代码等都在可以在这里找到:
https://avoid.overfit.cn/post/0fb3b50283c541d78e4d40c9083b88d9
相关文章:
LLMLingua:集成LlamaIndex,对提示进行压缩,提供大语言模型的高效推理
大型语言模型(llm)的出现刺激了多个领域的创新。但是在思维链(CoT)提示和情境学习(ICL)等策略的驱动下,提示的复杂性不断增加,这给计算带来了挑战。这些冗长的提示需要大量的资源来进行推理,因此需要高效的解决方案,本文将介绍LLM…...

数据资产确权的难点
数据是企业的重要资产之一,但是许多企业对于这项资产在管理上都面临着一些挑战,其中最关键就是数据确权的问题。接下来,将探讨数据资产确权的难点,并提出相应的解决方案,一起来看吧。 首先介绍一下数据资产入表的背景以…...

EMG肌肉电信号处理合集(二)
本文主要展示常见的肌电信号特征的提取说明。使用python 环境下的Pysiology计算库。 目录 1 肌电信号第一次burst的振幅, getAFP 函数 2 肌电信号波长的标准差计算,getDASDV函数 3 肌电信号功率谱频率比例,getFR函数 4 肌电信号直方图…...

2023亚马逊云科技re:Invent引领科技新潮流:云计算与生成式AI共塑未来
2023亚马逊云科技re:Invent引领科技新潮流:云计算与生成式AI共塑未来 历年来,亚马逊云科技re:Invent,不仅是全球云计算从业者的年度狂欢,更是全球云计算领域每年创新发布的关键节点。 2023年亚马逊云科技re:Invent大会在美国拉斯…...
案例018:基于微信小程序的实习记录系统
文末获取源码 开发语言:Java 框架:SSM JDK版本:JDK1.8 数据库:mysql 5.7 开发软件:eclipse/myeclipse/idea Maven包:Maven3.5.4 小程序框架:uniapp 小程序开发软件:HBuilder X 小程序…...

视频剪辑技巧:如何高效批量转码MP4视频为MOV格式
在视频剪辑的过程中,经常会遇到将MP4视频转码为MOV格式的情况。这不仅可以更好地编辑视频,还可以提升视频的播放质量和兼容性。对于大量视频文件的转码操作,如何高效地完成批量转码呢?现在一起来看看云炫AI智剪如何智能转码&#…...

node.js获取unsplash图片
1. 在Unsplash的开发者页面注册并创建一个应用程序,以便获取一个API访问密钥(即Access Key)。 2. 安装axios: npm install axios3. 使用获取到的API密钥进行请求。 示例代码如下: const axios require(axios);con…...

Git远程库操作(GitHub)
GitHub 网址:https://github.com/ 创建远程仓库 远程仓库操作 命令名称作用git remote -v查看当前所有远程地址别名git remote add 别名 远程地址起别名git push 别名 分支推送本地分支上的内容到远程仓库git clone 远程地址将远程仓库的内容克隆到本地git pull 别…...
java计算下一个整10分钟时间点
最近工作上遇到需要固定在整10分钟一个周期调度某个任务,所以需要这样一个功能,记录下 package org.example;import com.google.gson.Gson; import org.apache.commons.lang3.time.DateUtils;import java.io.InputStream; import java.util.Calendar; i…...
力扣刷题篇之排序算法
系列文章目录 前言 本系列是个人力扣刷题汇总,本文是排序算法。刷题顺序按照[力扣刷题攻略] Re:从零开始的力扣刷题生活 - 力扣(LeetCode) 这个之前写的左神的课程笔记里也有: 左程云算法与数据结构代码汇总之排序&am…...

一键填充字幕——Arctime pro
之前的博客中,我们聊到了PR这款专业的视频制作软件,但是pr有许多的功能需要搭配使用,相信不少小伙伴在剪辑视频时会发现一个致命的问题,就是字幕编写。伴随着人们对字幕需求的逐渐增加,这款软件便应运而生~ 相信应该有…...
)
间隔分区表(DM8:达梦数据库)
DM8:达梦数据库 - 间隔分区表 环境介绍1 按 年 - 间隔分区表2 按 月 - 间隔分区3 按 日 - 间隔分区4 按 数值 - 间隔分区表5 达梦数据库学习使用列表 环境介绍 间隔分区表使用说明: 仅支持一级范围分区创建间隔分区。 只能有一个分区列,且分区列类型为…...
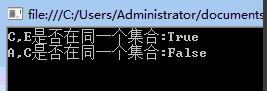
基于C#实现并查集
一、场景 有时候我们会遇到这样的场景,比如:M{1,4,6,8},N{2,4,5,7},我的需求就是判断{1,2}是否属于同一个集合,当然实现方法有很多,一般情况下,普通青年会做出 O(MN)的复杂度,那么有没有更轻量级的复杂度呢…...
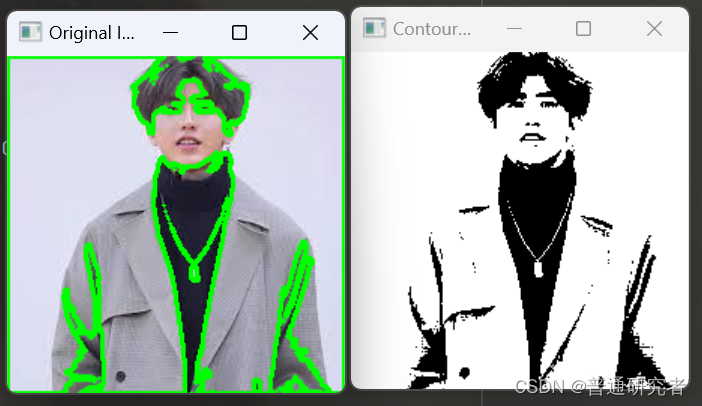
opencv-图像轮廓
轮廓可以简单认为成将连续的点(连着边界)连在一起的曲线,具有相同的颜色或者灰度。轮廓在形状分析和物体的检测和识别中很有用。 • 为了更加准确,要使用二值化图像。在寻找轮廓之前,要进行阈值化处理或者 Canny 边界检…...
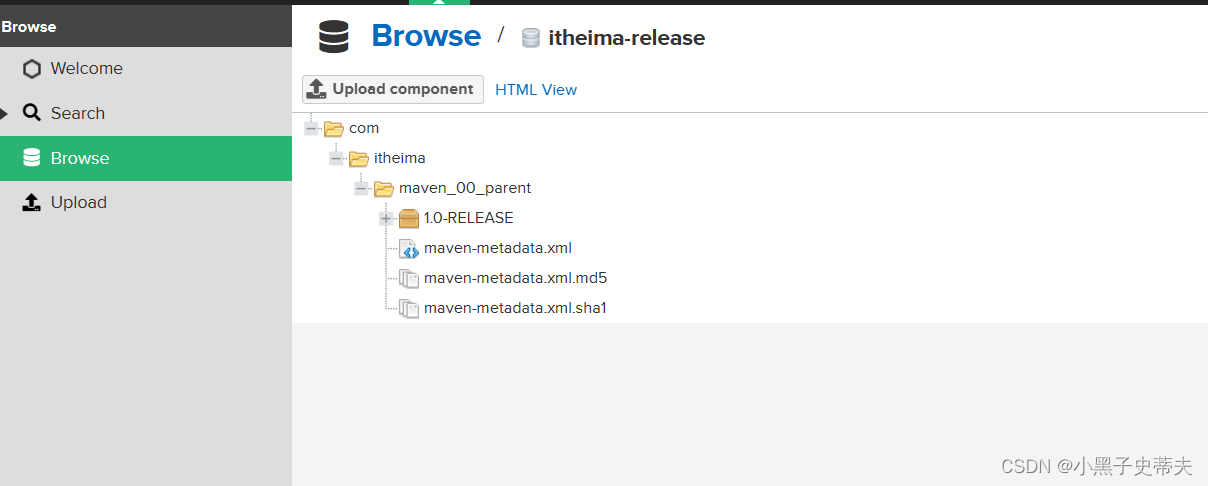
小黑子—Maven高级
Maven高级篇 二 小黑子的Maven高级篇学习1. 分模块开发1.1 分模块开发设计1.2 分模块开发实现1.2.1 抽取domain层1.2.2 抽取dao层 2. 依赖管理2.1 依赖传递2.2 可选依赖2.3 排除依赖 3. 继承与聚合3.1 聚合3.2 继承3.3 总结 4. 属性4.1 配置文件加载属性4.2 版本管理 5. 多环境…...
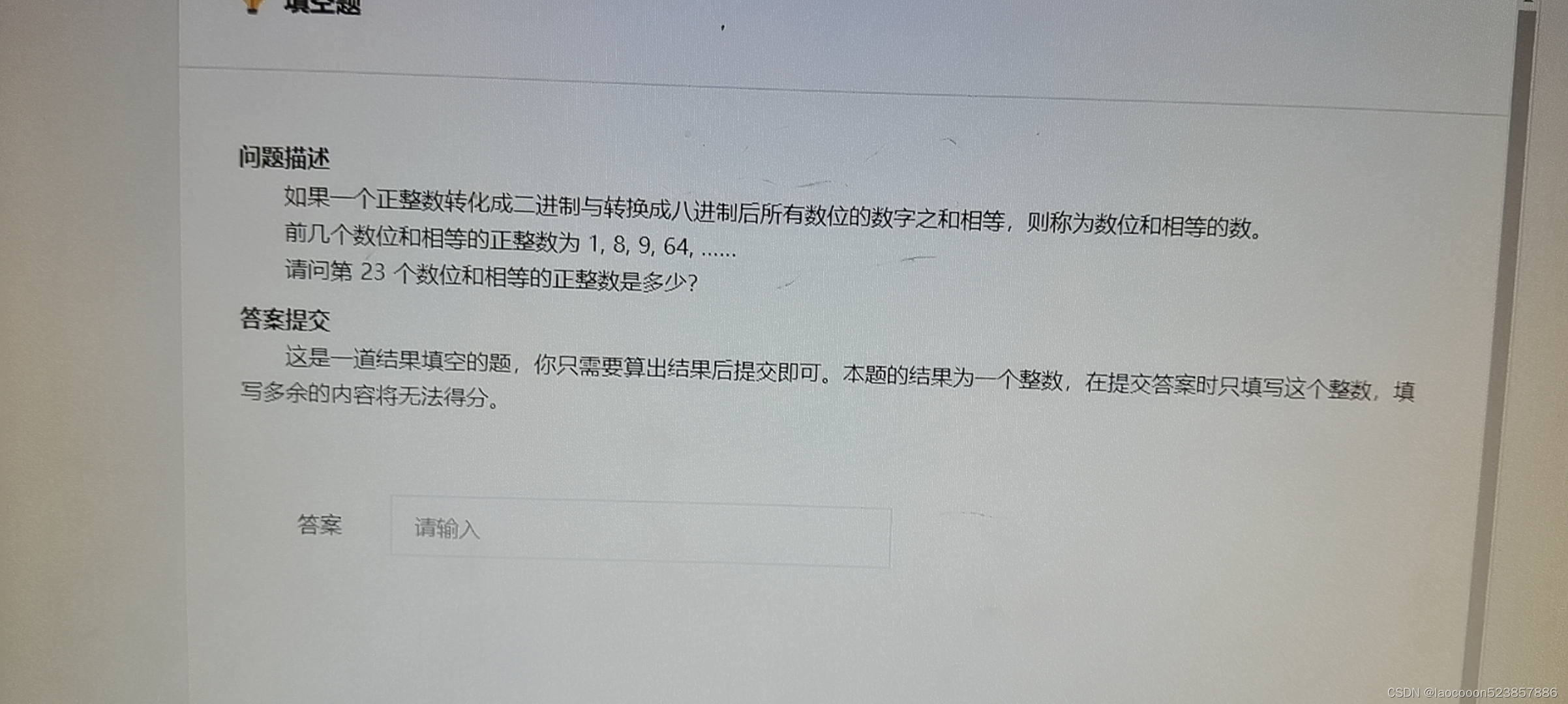
一个正整数转为2进制和8进制,1的个数相同的第23个数是什么?
package cn.com;import java.lang.*;//默认加载public class C2 {//10进制转8进制static int HtoO(int n){int cnt 0;while(n!0){cntn%8;n/8;}return cnt;}//10进制转2进制static int HtoB(int n){int cnt 0;while(n!0){cntn%2;n/2;}return cnt;}public static void main(Str…...
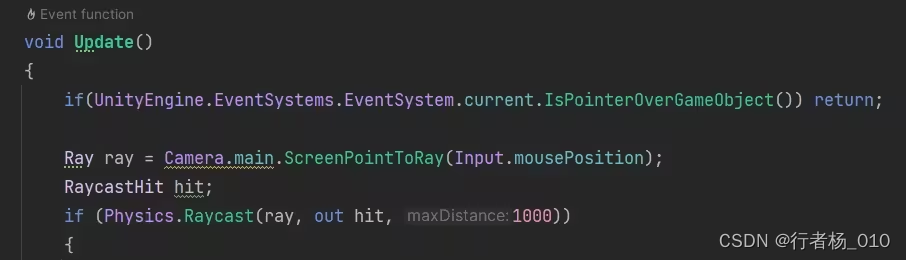
Unity阻止射线穿透UI的方法之一
if(UnityEngine.EventSystems.EventSystem.current.IsPointerOverGameObject()) return; 作者:StormerZ https://www.bilibili.com/read/cv27797873/ 出处:bilibili...

HarmonyOS开发:ArkTs常见数据类型
前言 无论是Android还是iOS开发,都提供了多种数据类型用于常见的业务开发,但在ArkTs中,数据类型就大有不同,比如int,float,double,long统一就是number类型,当然了也不存在char类型&…...

Unsupervised MVS论文笔记
Unsupervised MVS论文笔记 摘要1 引言2 相关工作3 实现方法3.1 网络架构3.2 通过光度一致性学习3.3 MVS的鲁棒光度一致性3.4 学习设置和实施的细节3.5.预测每幅图像的深度图 4 实验4.1 在DTU上的结果4.2 消融实验 Tejas Khot and Shubham Agrawal and Shubham Tulsiani and Chr…...
Matplotlib图形注释_Python数据分析与可视化
Matplotlib图形注释 添加注释文字、坐标变换 有的时候单单使用图形无法完整清晰的表达我们的信息,我们还需要进行文字进行注释,所以matplotlib提供了文字、箭头等注释可以突出图形中重点信息。 添加注释 为了使我们的可视化图形让人更加容易理解&#…...

能源转型与海上风电规模化驱动,高增前行:全球海上风电导管架2025年20.96亿,2032年锚定62.73亿,2026-2032年CAGR17.2%
QYResearch调研显示,2025年全球海上风电导管架市场规模大约为20.96亿美元,预计2032年将达到62.73亿美元,2026-2032期间年复合增长率(CAGR)为17.2%。一、技术迭代与市场驱动:导管架的产业价值重构海上风电导…...

GPT-SoVITS终极语音克隆指南:5分钟掌握零样本AI语音合成技术
GPT-SoVITS终极语音克隆指南:5分钟掌握零样本AI语音合成技术 【免费下载链接】GPT-SoVITS 1 min voice data can also be used to train a good TTS model! (few shot voice cloning) 项目地址: https://gitcode.com/GitHub_Trending/gp/GPT-SoVITS 你是否曾…...

如何用OBS高级计时器彻底解决直播时间管理难题:6种模式的完整指南
如何用OBS高级计时器彻底解决直播时间管理难题:6种模式的完整指南 【免费下载链接】obs-advanced-timer 项目地址: https://gitcode.com/gh_mirrors/ob/obs-advanced-timer 还在为直播时手忙脚乱看时间而烦恼吗?OBS Advanced Timer计时器插件是你…...

claude学习
后面会随着对claude的学习加深会逐渐更新的 文章目录后面会随着对claude的学习加深会逐渐更新的前言一、claude的三种模式二、阿里云千锤百炼前言 https://www.bilibili.com/video/BV1wuQEBDEN8/?spm_id_from333.337.search-card.all.click&vd_sourceeb433c8780bdd700f49…...

# Deno从零搭建高性能 Web 服务:权限控制与模块化设计实战在现代Node
Deno 从零搭建高性能 Web 服务:权限控制与模块化设计实战 在现代 Node.js 生态中,Deno 正以全新的姿态重新定义后端开发边界。它摒弃了 npm 和 package.json 的依赖管理方式,内置 TypeScript 支持,并通过严格的运行时权限模型提升…...

Python自动化控制Comsol多物理场仿真的完整指南:MPh库实战解析
Python自动化控制Comsol多物理场仿真的完整指南:MPh库实战解析 【免费下载链接】MPh Pythonic scripting interface for Comsol Multiphysics 项目地址: https://gitcode.com/gh_mirrors/mp/MPh 想要用Python代码自动化控制Comsol多物理场仿真吗?…...

魔兽争霸3现代兼容性终极解决方案:解锁高分辨率、高帧率与宽屏体验
魔兽争霸3现代兼容性终极解决方案:解锁高分辨率、高帧率与宽屏体验 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为魔兽争霸3…...

WarcraftHelper终极指南:5分钟让魔兽争霸3在现代电脑上重生
WarcraftHelper终极指南:5分钟让魔兽争霸3在现代电脑上重生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代电脑上无…...

实用三步轻松实现Mac微信防撤回:完整保护重要信息不消失
实用三步轻松实现Mac微信防撤回:完整保护重要信息不消失 【免费下载链接】WeChatIntercept 微信防撤回插件,一键安装,仅MAC可用,支持v3.7.0微信 项目地址: https://gitcode.com/gh_mirrors/we/WeChatIntercept 你是否经历过…...

从Betaflight到PX4:Kakute H7飞控固件刷写实战与避坑指南
1. 为什么需要从Betaflight迁移到PX4? 如果你正在使用Holybro Kakute H7飞控,可能已经习惯了Betaflight系统的简洁高效。但当你需要更复杂的自主飞行功能时,PX4生态系统的优势就显现出来了。Betaflight更适合竞速和花式飞行,而PX4…...