【ChatGLM3-6B】Docker下部署及微调
【ChatGLM2-6B】小白入门及Docker下部署
- 注意:Docker基于镜像中网盘上上传的有已经做好的镜像,想要便捷使用的可以直接从Docker基于镜像安装看
- Docker从0安装
- 前提
- 下载
- 启动
- 访问
- Docker基于镜像安装
- 容器打包操作(生成镜像时使用的命令)
- 安装时命令
- 微调
- 前提
- 微调和验证文件准备
- 微调和验证文件格式转换
- 修改微调脚本
- 执行微调
- 微调完成
- 结果推理验证
- 报错解决
- 出现了$‘\r’: command not found错误
- 加载微调模型
- API接口调用
注意:Docker基于镜像中网盘上上传的有已经做好的镜像,想要便捷使用的可以直接从Docker基于镜像安装看
Docker从0安装
前提
- 安装好了docker
- 安装好了NVIDIA
- 显卡16G
下载
-
新建一个文件夹,用来存放下载下来的ChatGLM3代码和模型
-
右键,打开一个git窗口,拉取模型(会很慢,耐心等待)
- 地址: https://modelscope.cn/models/ZhipuAI/chatglm3-6b/summary
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
-
右键,打开一个git窗口,拉取源代码
- 地址:https://github.com/THUDM/ChatGLM3
git clone https://github.com/THUDM/ChatGLM3或
git clone https://ghproxy.com/https://github.com/THUDM/ChatGLM3
- 注意:将下载好的模型(chatglm3-6b-models)和代码放到一个目录里面,并上传到服务器上
启动
docker run -itd --name chatglm3 -v `pwd`/ChatGLM3:/data \
--gpus=all -e NVIDIA_DRIVER_CAPABILITIES=compute,utility -e NVIDIA_VISIBLE_DEVICES=all \
-p 8501:8501 pytorch/pytorch:2.0.1-cuda11.7-cudnn8-devel
# 进入启动好的容器
docker exec -it chatglm3 bash# 设置pip3下载路径为国内镜像
cd /data
pip3 config set global.index-url https://mirrors.aliyun.com/pypi/simple
pip3 config set install.trusted-host mirrors.aliyun.com# 安装基础依赖
pip3 install -r requirements.txt
修改模型路径
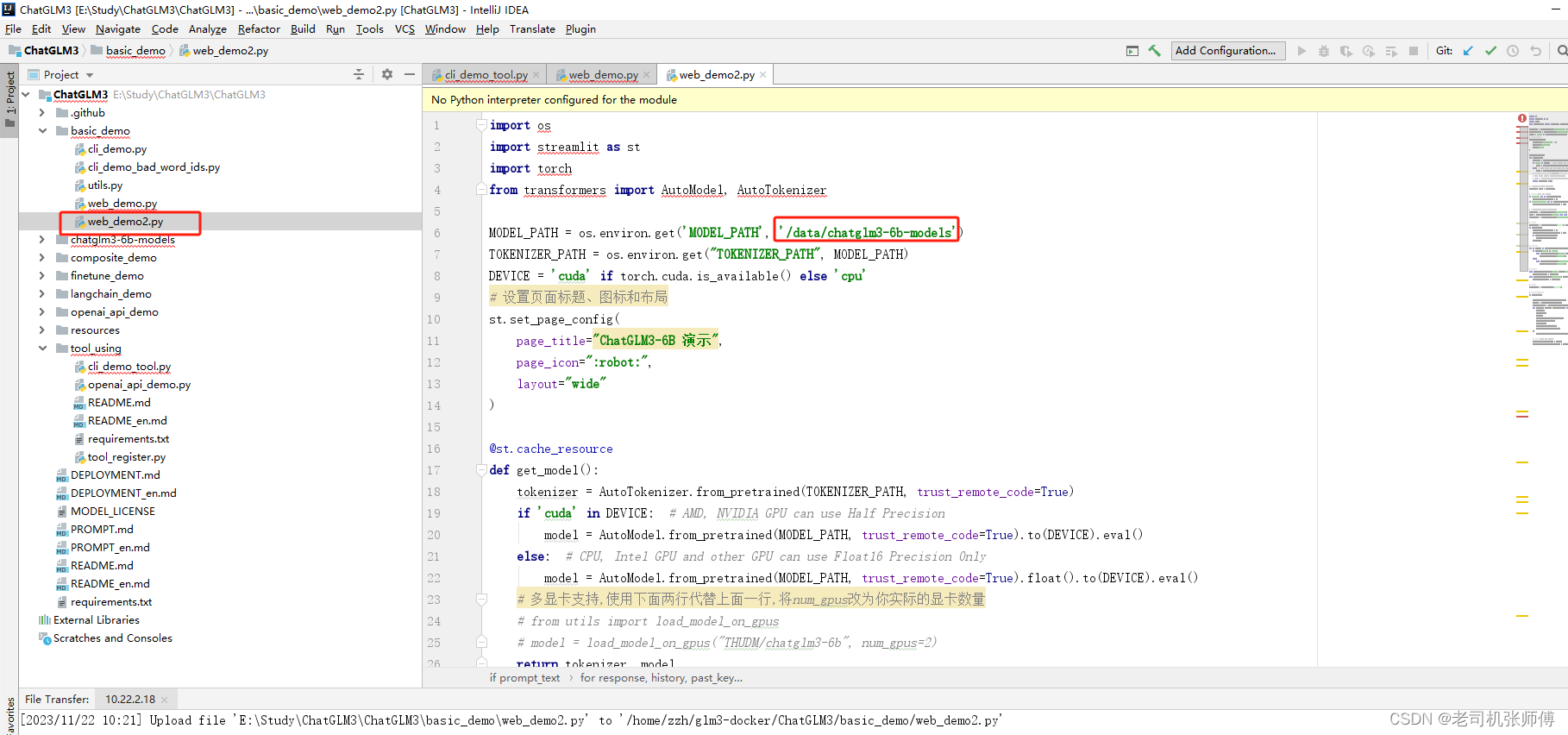
启动
streamlit run basic_demo/web_demo2.py
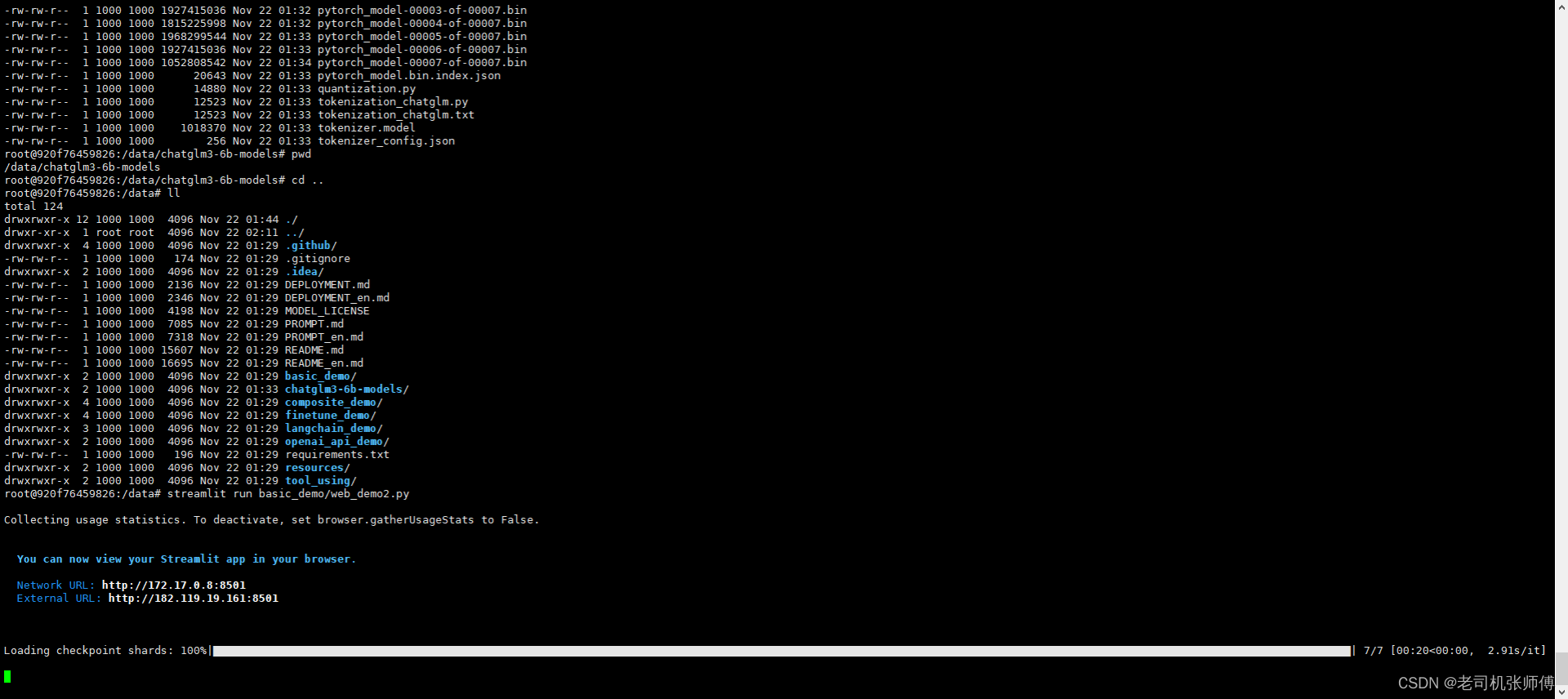
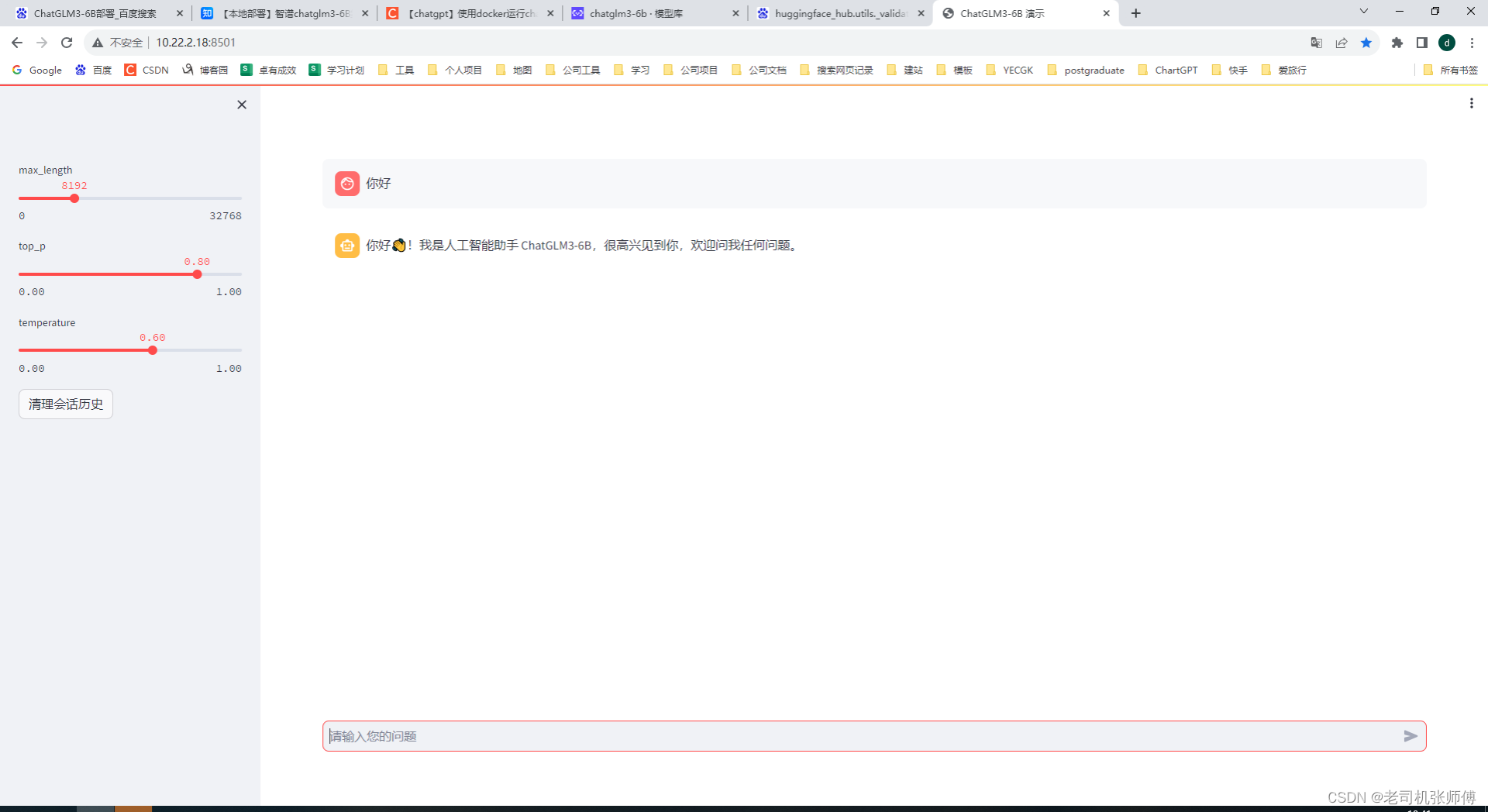
访问
http://10.22.2.18:8501/
Docker基于镜像安装
容器打包操作(生成镜像时使用的命令)
-
将安装好、启动好的容器打包成镜像
docker commit -m='glm3 commit' -a='zhangzh' chatglm3 chatglm3-6b:1.1 -
将镜像,打成可以传到其他地方的tar包
docker save -o chatglm3-6b.tar chatglm3-6b:1.1
安装时命令
-
网盘地址
这里因为网盘上传文件有大小限制,所以使用了分卷压缩的方式进行了上传,全部下载下来就可以。
链接:https://pan.baidu.com/s/1wY3QqaWrMyBR39d2ZhN_Kg?pwd=9zdd 提取码:9zdd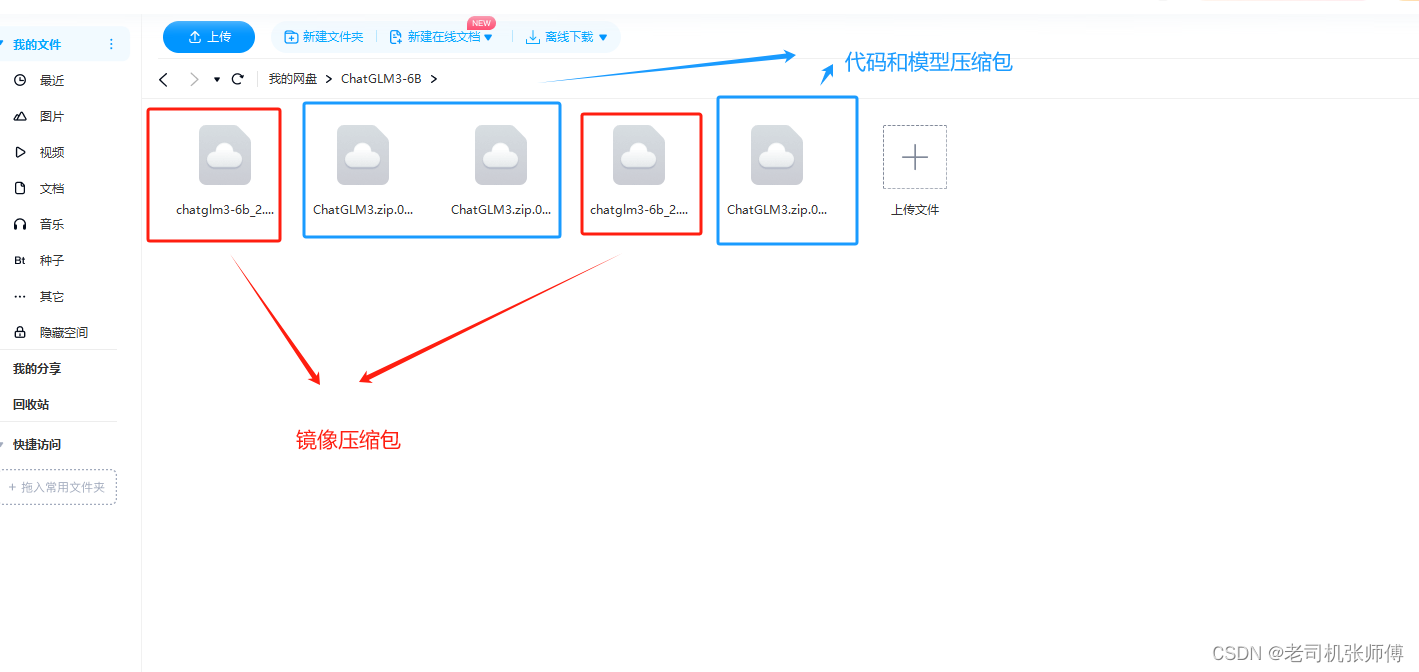
-
将下载好的镜像文件和代码模型文件上传到服务器上,并进行解压,然后在该目录进行操作。
-
在其他的docker服务器加载镜像
docker load -i chatglm3-6b.tar -
启动
docker run -itd --name chatglm3 -v `pwd`/ChatGLM3:/data \ --gpus=all -e NVIDIA_DRIVER_CAPABILITIES=compute,utility -e NVIDIA_VISIBLE_DEVICES=all \ -p 8501:8501 -p 8000:8000 chatglm3-6b:1.1 -
进入容器
docker exec -it chatglm3 bash -
启动
cd /data streamlit run basic_demo/web_demo2.py -
访问:http://10.22.2.18:8501/
微调
微调操作直接在docker内进行
docker exec -it chatglm3 bash
前提
运行示例需要 python>=3.9,除基础的 torch 依赖外,示例代码运行还需要依赖
pip install transformers==4.30.2 accelerate sentencepiece astunparse deepspeed
微调和验证文件准备
微调参数文件为.json文件,先将你的微调数据和验证数据处理成如下格式:
{"content": "类型#裤*版型#宽松*风格#性感*图案#线条*裤型#阔腿裤", "summary": "宽松的阔腿裤这两年真的吸粉不少,明星时尚达人的心头爱。毕竟好穿时尚,谁都能穿出腿长2米的效果宽松的裤腿,当然是遮肉小能手啊。上身随性自然不拘束,面料亲肤舒适贴身体验感棒棒哒。系带部分增加设计看点,还让单品的设计感更强。腿部线条若隐若现的,性感撩人。颜色敲温柔的,与裤子本身所呈现的风格有点反差萌。"}
{"content": "类型#裙*风格#简约*图案#条纹*图案#线条*图案#撞色*裙型#鱼尾裙*裙袖长#无袖", "summary": "圆形领口修饰脖颈线条,适合各种脸型,耐看有气质。无袖设计,尤显清凉,简约横条纹装饰,使得整身人鱼造型更为生动立体。加之撞色的鱼尾下摆,深邃富有诗意。收腰包臀,修饰女性身体曲线,结合别出心裁的鱼尾裙摆设计,勾勒出自然流畅的身体轮廓,展现了婀娜多姿的迷人姿态。"}
{"content": "类型#上衣*版型#宽松*颜色#粉红色*图案#字母*图案#文字*图案#线条*衣样式#卫衣*衣款式#不规则", "summary": "宽松的卫衣版型包裹着整个身材,宽大的衣身与身材形成鲜明的对比描绘出纤瘦的身形。下摆与袖口的不规则剪裁设计,彰显出时尚前卫的形态。被剪裁过的样式呈现出布条状自然地垂坠下来,别具有一番设计感。线条分明的字母样式有着花式的外观,棱角分明加上具有少女元气的枣红色十分有年轻活力感。粉红色的衣身把肌肤衬托得很白嫩又健康。"}
{"content": "类型#裙*版型#宽松*材质#雪纺*风格#清新*裙型#a字*裙长#连衣裙", "summary": "踩着轻盈的步伐享受在午后的和煦风中,让放松与惬意感为你免去一身的压力与束缚,仿佛要将灵魂也寄托在随风摇曳的雪纺连衣裙上,吐露出<UNK>微妙而又浪漫的清新之意。宽松的a字版型除了能够带来足够的空间,也能以上窄下宽的方式强化立体层次,携带出自然优雅的曼妙体验。"}
其中content是向模型输入的内容,summary为模型应该输出的内容。
其中微调数据是通过本批数据对模型进行调试(文件是train.json),验证数据是通过这些数据验证调试的结果(文件是dev.json)。
微调和验证文件格式转换
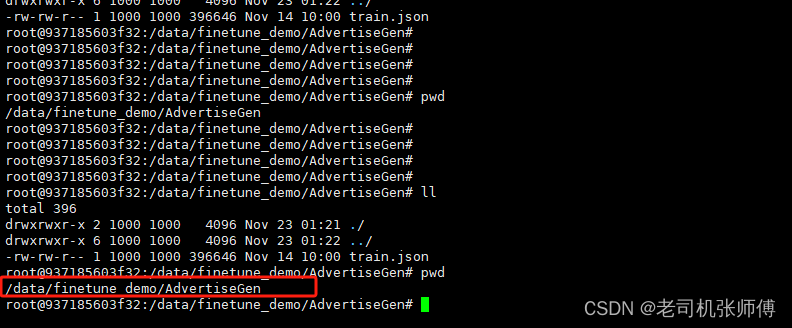
1、在项目代码的finetune_demo目录下新建一个AdvertiseGen目录,并将你的文件上传上去。
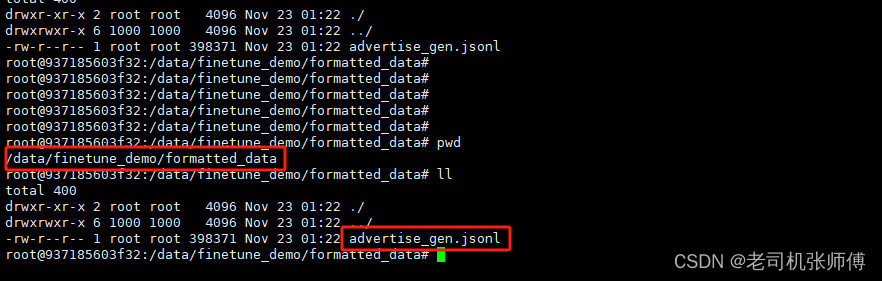
2、然后回到finetune_demo目录,执行以下脚本进行转换,转换后的文件放在formatted_data目录下。
python ./scripts/format_advertise_gen.py --path "AdvertiseGen/train.json"
修改微调脚本
本方法使用的微调脚本是finetune_demo/scripts/finetune_pt.sh,修改各个参数为自己的环境,其中:
PRE_SEQ_LEN: 模型长度,后续使用微调结果加载时要保持一直
MAX_SOURCE_LEN:模型输入文本的长度,超过该长度会截取,会影响占用GPU,我这里GPU为16G基本吃满
MAX_TARGET_LEN:模型输出文本的最大长度,会影响占用GPU,我这里GPU为16G基本吃满
BASE_MODEL_PATH:原模型的地址
DATASET_PATH:模型微调参数文件的地址
OUTPUT_DIR:模型微调结果存放的地址
MAX_STEP:调试的步数,主要跟微调需要的时间有关,越小则时间越短,但微调的准确度(影响度)越小
SAVE_INTERVAL:多少步保存一个微调结果
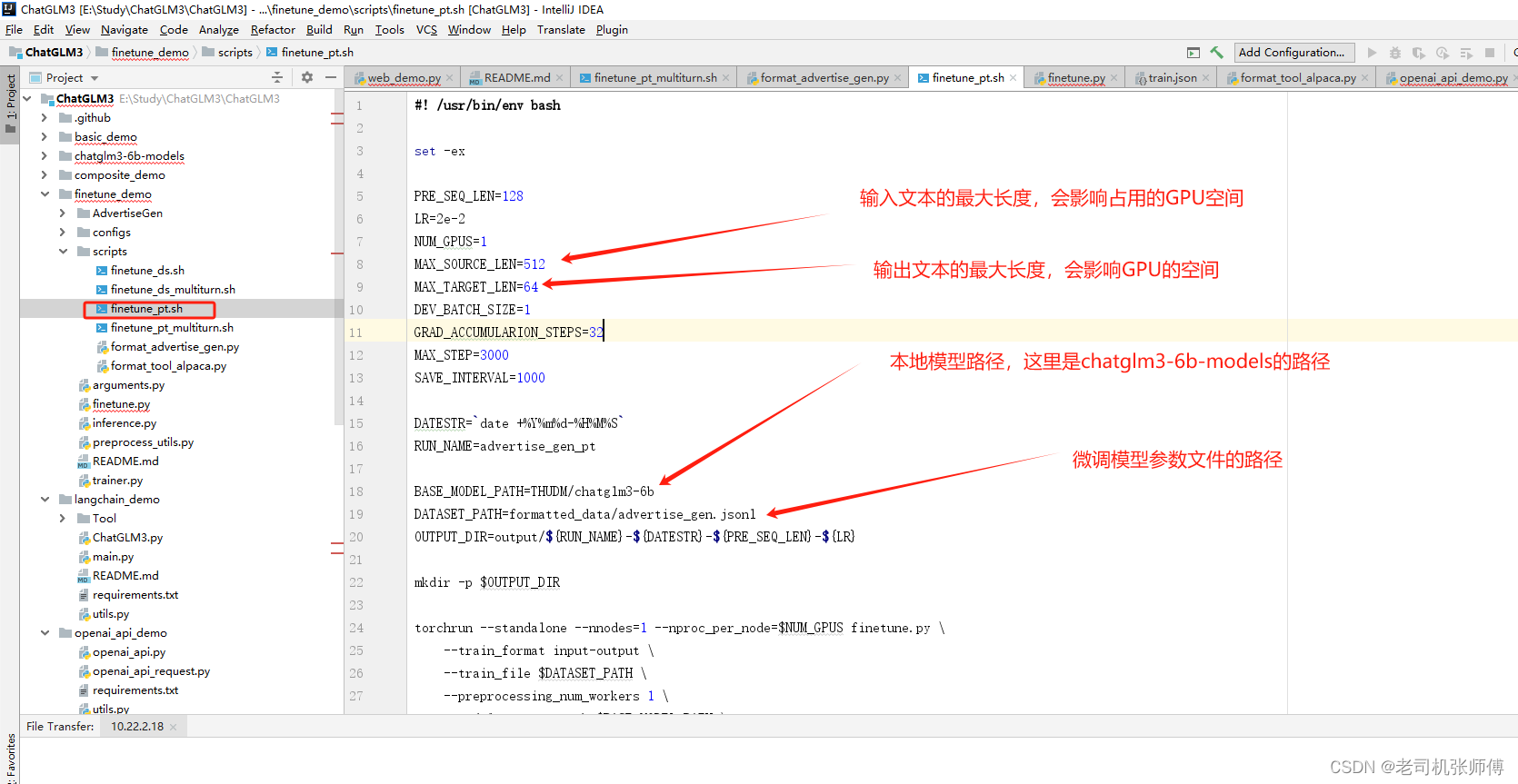
脚本如下:
#! /usr/bin/env bashset -exPRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1
MAX_SOURCE_LEN=512
MAX_TARGET_LEN=64
DEV_BATCH_SIZE=1
GRAD_ACCUMULARION_STEPS=32
MAX_STEP=1500
SAVE_INTERVAL=500DATESTR=`date +%Y%m%d-%H%M%S`
RUN_NAME=advertise_gen_ptBASE_MODEL_PATH=/data/chatglm3-6b-models
DATASET_PATH=formatted_data/advertise_gen.jsonl
OUTPUT_DIR=output/${RUN_NAME}-${DATESTR}-${PRE_SEQ_LEN}-${LR}mkdir -p $OUTPUT_DIRtorchrun --standalone --nnodes=1 --nproc_per_node=$NUM_GPUS finetune.py \--train_format input-output \--train_file $DATASET_PATH \--preprocessing_num_workers 1 \--model_name_or_path $BASE_MODEL_PATH \--output_dir $OUTPUT_DIR \--max_source_length $MAX_SOURCE_LEN \--max_target_length $MAX_TARGET_LEN \--per_device_train_batch_size $DEV_BATCH_SIZE \--gradient_accumulation_steps $GRAD_ACCUMULARION_STEPS \--max_steps $MAX_STEP \--logging_steps 1 \--save_steps $SAVE_INTERVAL \--learning_rate $LR \--pre_seq_len $PRE_SEQ_LEN 2>&1 | tee ${OUTPUT_DIR}/train.log
执行微调
先给脚本执行权限
chmod -R 777 ./scripts/finetune_pt.sh
执行脚本
./scripts/finetune_ds.sh # 全量微调
./scripts/finetune_pt.sh # P-Tuning v2 微调
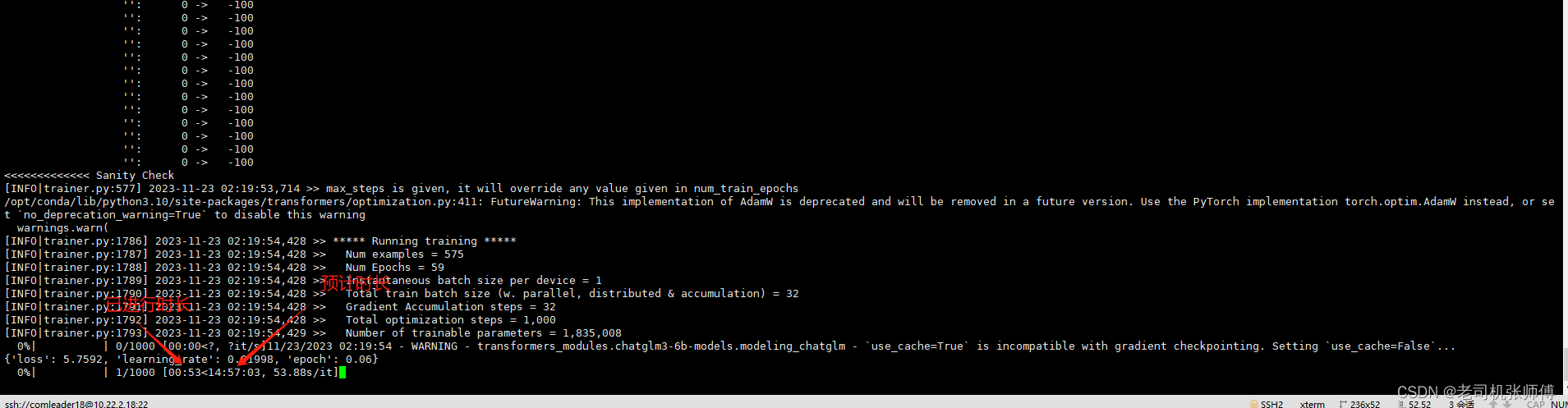
微调完成
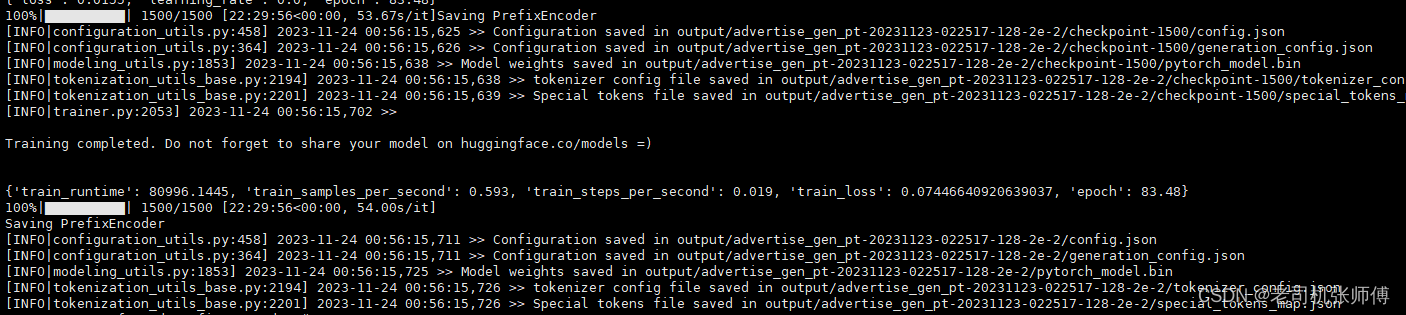
结果推理验证
python inference.py \--pt-checkpoint "/data/finetune_demo/output/advertise_gen_pt-20231123-022517-128-2e-2/checkpoint-1500" \--model /data/chatglm3-6b-models
报错解决
出现了$‘\r’: command not found错误
可能因为该Shell脚本是在Windows系统编写时,每行结尾是\r\n
而在Linux系统中行每行结尾是\n
在Linux系统中运行脚本时,会认为\r是一个字符,导致运行错误
使用dos2unix 转换一下就可以了
dos2unix <文件名># dos2unix: converting file one-more.sh to Unix format ...-bash: dos2unix: command not found
就是还没安装,安装一下就可以了
apt install dos2unix
加载微调模型
cd ../composite_demo
MODEL_PATH="/data/chatglm3-6b-models" PT_PATH="/data/finetune_demo/output/advertise_gen_pt-20231123-022517-128-2e-2/checkpoint-1500" streamlit run main.py
重新访问页面,即可啦~
API接口调用
-
下载依赖
pip install openai==1.3.0 pip install pydantic==2.5.1 -
进入openai_api_demo目录
-
修改脚本
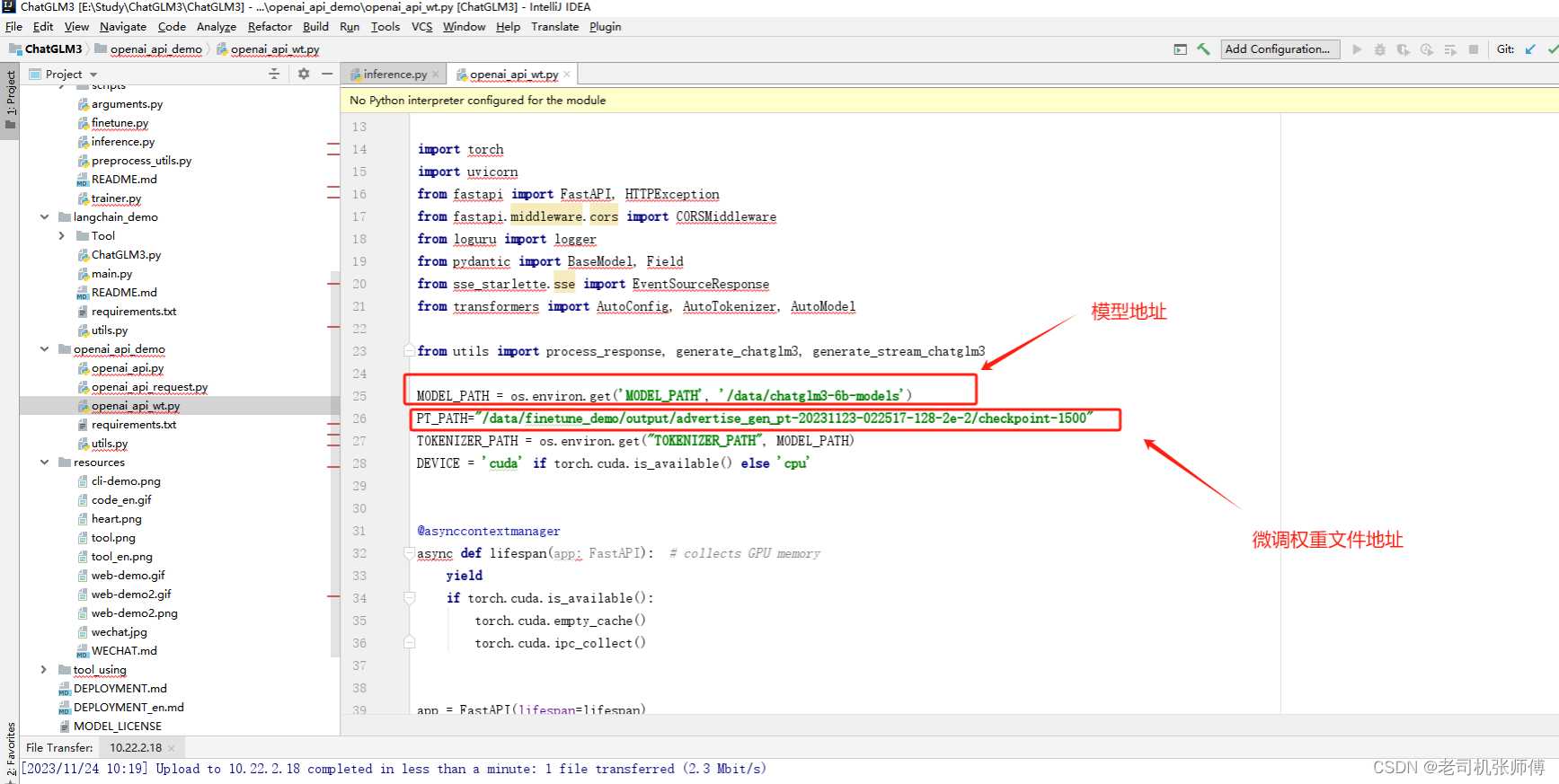
-
启动脚本
python openai_api_wt.py -
访问SwaggerUI地址
http://10.22.2.18:8000/docs#/default/list_models_v1_models_get
接口:http://10.22.2.18:8000/v1/chat/completions
参数:
{"model": "chatglm3-6b","messages": [{"role": "user","content": "你好,给我讲一个故事,大概100字" # 这里是请求的参数}],"stream": false,"max_tokens": 100,"temperature": 0.8,"top_p": 0.8 }
相关文章:
【ChatGLM3-6B】Docker下部署及微调
【ChatGLM2-6B】小白入门及Docker下部署 注意:Docker基于镜像中网盘上上传的有已经做好的镜像,想要便捷使用的可以直接从Docker基于镜像安装看Docker从0安装前提下载启动访问 Docker基于镜像安装容器打包操作(生成镜像时使用的命令࿰…...

编程常见报错信息及解决方案汇总
编程常见报错信息及解决方案汇总 1.Java语言编程 1.1 jdk相关 Java API java8帮助文档 Java最新JDK和API下载(持续同步更新于官网) jdk1.8.0_212 全平台下载 官网下载JDK1.7的方法和步骤 力扣 (LeetCode) PTA题库 1.2 编程工具Eclipse Eclips…...

从Redis反序列化UserDetails对象异常后发现FastJson序列化的一些问题
最近在使用SpringSecurityJWT实现认证授权的时候,出现Redis在反序列化userDetails的异常。通过实践发现,使用不同的序列化方法和不同的fastJson版本,异常信息各不相同。所以特地记录了下来。 一、项目代码 先来看看我项目中redis相关配置信息…...
0001Java程序设计-springboot基于微信小程序批发零售业商品管理系统
文章目录 **摘 要****目录**系统实现开发环境 编程技术交流、源码分享、模板分享、网课分享 企鹅🐧裙:776871563 摘 要 本毕业设计的内容是设计并且实现一个基于微信小程序批发零售业商品管理系统。它是在Windows下,以MYSQL为数据库开发平台…...
)
中国防锈油市场深度调研与投资战略报告(2023版)
内容简介: 防锈油是在石油类基本组分中加入油溶性缓蚀剂及清净分散剂、抗氧抗腐剂、极压抗磨剂等辅助添加剂,多用于金属制品工序间、运输和贮存时的暂时防锈,是一种较理想、有效的防护方法,具有效果好、使用方便、成本低廉、易施…...

Linux C 基于tcp和epoll在线聊天室
基于tcp和epoll在线聊天室 说明服务端代码 说明 服务端:实现了验证用户是否已经存在(支持最大64用户连接)支持广播用户进入退出聊天室以及用户聊天内容。 这里只提供里服务端代码,如果想要看客户端代码点击这里。 服务端代码…...

为什么要隐藏id地址?使用IP代理技术可以实现吗?
随着网络技术的不断发展,越来越多的人开始意识到保护个人隐私的重要性。其中,隐藏自己的IP地址已经成为了一种常见的保护措施。那么,为什么要隐藏IP地址?使用IP代理技术可以实现吗?下面就一起来探讨这些问题。 首先&am…...

前端(HTML + CSS + JS)
文章目录 一、HTML1. 概念(1)HTML 文件基本结构(2)HTML代码框架 2. 、HTML常见标签 二、CSS1. CSS基本语法规范2. 用法(1) 引用方式(2)选择器(3)常用元素属性…...

12 要素 12 Factor
I. 基准代码 一份基准代码,多份部署 一个应用,一个基准代码git仓库,多个环境版本部署(prod,staging,develop) II. 依赖 显式声明依赖关系 docker的dockerfile,php的composer.jso…...

十大排序之冒泡排序与快速排序(详解)
文章目录 🐒个人主页🏅算法思维框架📖前言: 🎀冒泡排序 时间复杂度O(n^2)🎇1. 算法步骤思想🎇2.动画实现🎇 3.代码实现🎇4.代码优化(添加标志量) …...

【SpringBoot篇】阿里云OSS—存储文件的利器
文章目录 🌹什么是阿里云OSS⭐阿里云OSS的优点 🏳️🌈为什么要使用云服务OSS🎄使用步骤⭐OSS开通⭐参考官方SDK 🍔编写代码⭐上传文件 🌹综合案例 🌹什么是阿里云OSS 阿里云对象存储…...
Leetcode—58.最后一个单词的长度【简单】
2023每日刷题(四十) Leetcode—58.最后一个单词的长度 实现代码 int lengthOfLastWord(char* s) {int len strlen(s);int left 0, right 0;if(len 1) {return 1;}while(right < len) {if(right 1 < len) {if(s[right] && s[righ…...

Apach Ozone部署
前言 最近由于工作需要,要部署一套ozone。我自己对hadoop这套体系不是很熟悉,所以过程磕磕碰碰,好不容易勉强搭起来,所以记录一下部署方式 准备 三台主机,主机均已安装jdk、hdfs,相关的安装配置就不另外写…...

【nlp】3.2 Transformer论文复现:1. 输入部分(文本嵌入层和位置编码器)
Transformer论文复现:输入部分(文本嵌入层和位置编码器) 1 输入复现1.1 文本嵌入层1.1.1 文本嵌入层的作用1.1.2 文本嵌入层的代码实现1.1.3 文本嵌入层中的注意事项1.2 位置编码器1.2.1 位置编码器的作用1.2.2 位置编码器的代码实现1.2.3 位置编码器中的注意事项1 输入复现…...
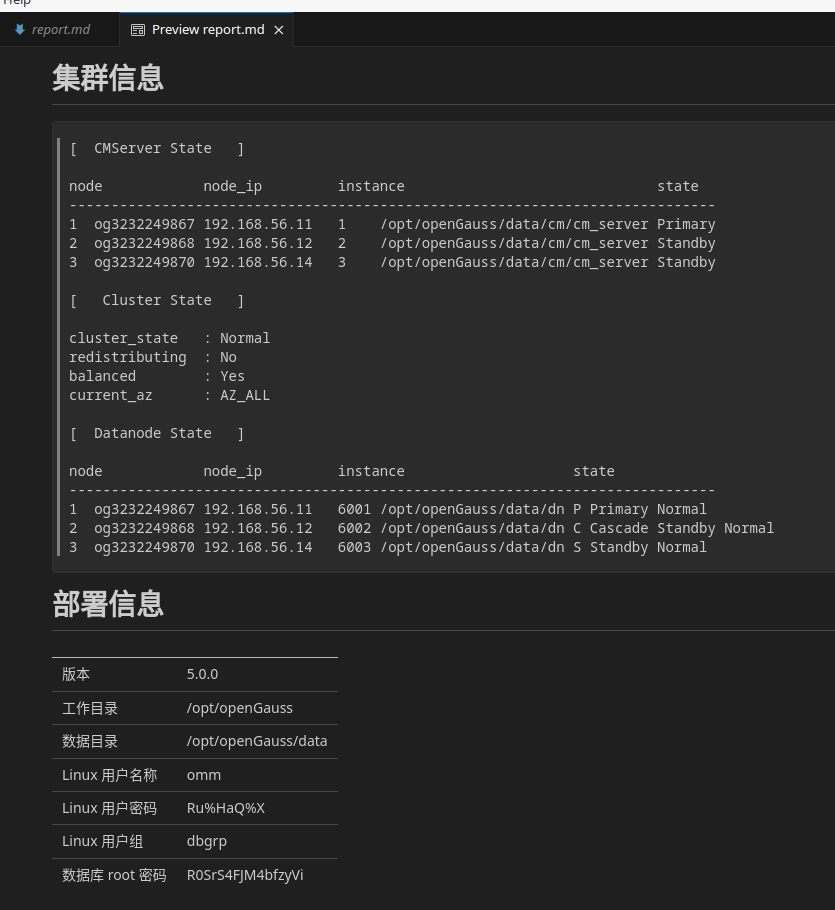
自动化部署 / 扩容openGauss —— Ansible for openGauss
前言 大家好,今天我们为大家推荐一套基于 Ansible 开发的,自动化部署及扩容 openGauss 的脚本工具:Ansible for openGauss(以下简称 AFO)。 通过AFO,我们只需简单修改一些配置文件,即可快速部署…...

Go 实现网络代理
使用 Go 语言开发网络代理服务可以通过以下步骤完成。这里,我们将使用 golang.org/x/net/proxy 包来创建一个简单的 SOCKS5 代理服务作为示例。 步骤 1. 安装 golang.org/x/net/proxy 包 使用以下命令安装 golang.org/x/net 包,该包包含 proxy 子包&am…...
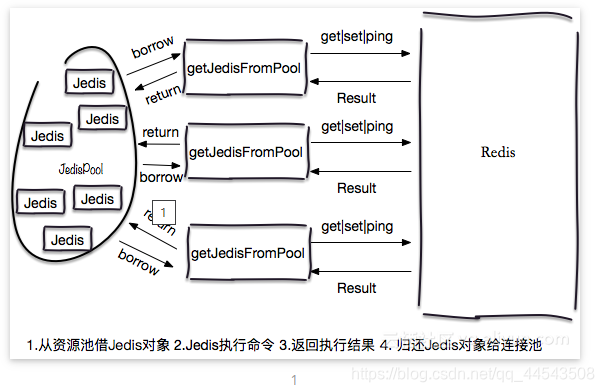
Redis报错:JedisConnectionException: Could not get a resource from the pool
1、问题描述: redis.clients.jedis.exceptions.JedisConnectionException: Could not get a resource from the pool 2、简要分析: redis.clients.util.Pool.getResource会从JedisPool实例池中返回一个可用的redis连接。分析源码可知JedisPool 继承了 r…...
【广州华锐互动】Web3D云展编辑器能为展览行业带来哪些便利?
在数字时代中,传统的展览方式正在被全新的技术和工具所颠覆。其中,最具有革新意义的就是Web3D云展编辑器。这种编辑器以其强大的功能和灵活的应用,正在为展览设计带来革命性的变化。 广州华锐互动开发的Web3D云展编辑器是一种专门用于创建、编…...
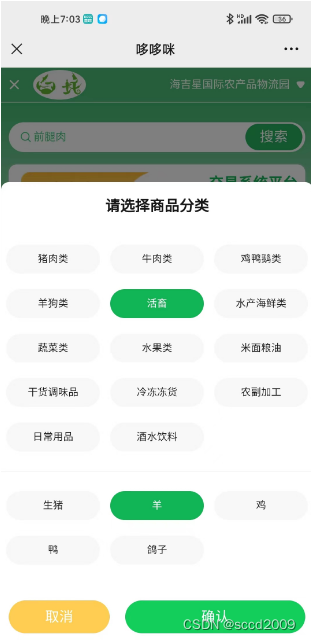
Vue项目实战之一----实现分类弹框效果
效果图 实现 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title><script src"js/vue.js"></script><!-- 引入样式 --><link rel"stylesheet&qu…...
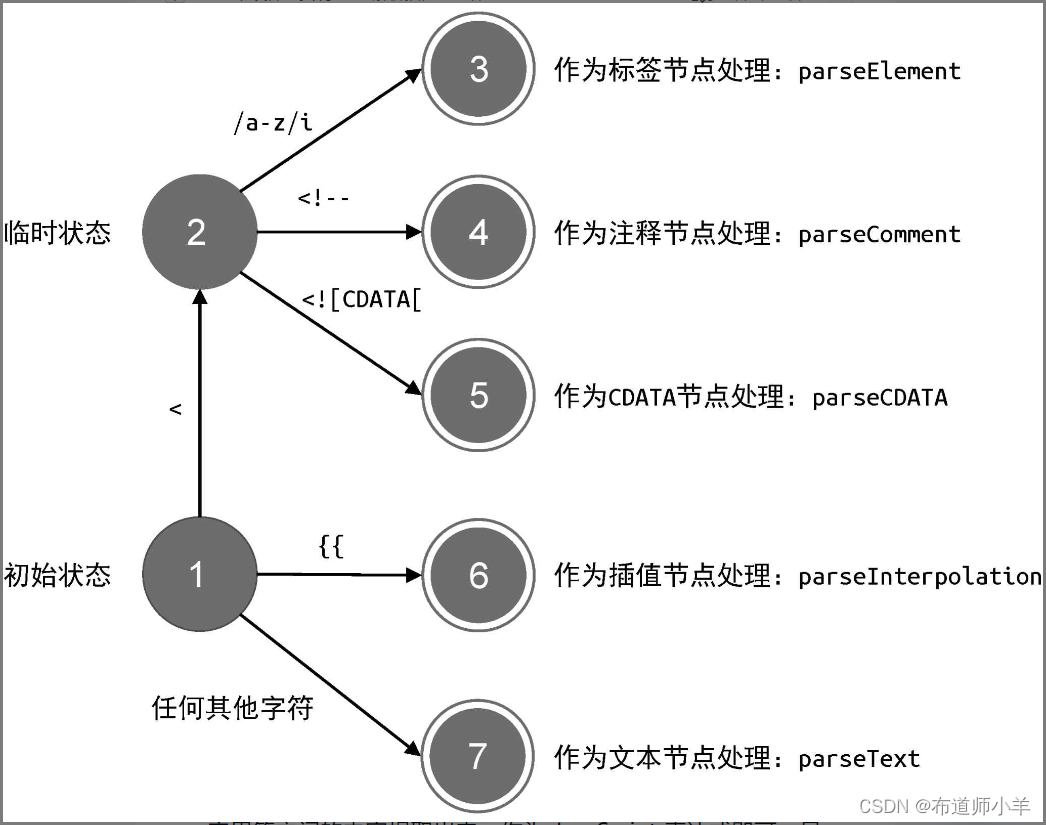
Vue解析器
解析器本质上是一个状态机。但我们也曾提到,正则表达式其实也是一个状态机。因此在编写 parser 的时候,利用正则表达式能够让我们少写不少代码。本章我们将更多地利用正则表达式来实现 HTML 解析器。另外,一个完善的 HTML 解析器远比想象的要…...

【电池-超级电容器混合存储系统】单机光伏电池-超级电容混合储能系统的能量管理系统附Simulink仿真
✅作者简介:热爱科研的Matlab仿真开发者,擅长数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室🍊个人信条:格物致知,完整Matlab代码及仿真咨询…...

#VCS# 编译选项+vcs+initreg+random实战解析:从后仿困境到高效验证
1. 理解vcsinitregrandom的核心价值 在后仿真验证过程中,最让人头疼的问题之一就是网表中存在大量未初始化的寄存器。这些寄存器在仿真开始时处于不确定状态(X态),会导致仿真结果不可预测。我曾经在一个PCIe项目中,因为…...
在实战中的选择与调参)
从MobileNet到U-Net:聊聊那些‘非标准’卷积(空洞、深度可分离)在实战中的选择与调参
从MobileNet到U-Net:非标准卷积的工程实践指南 在计算机视觉领域,卷积神经网络(CNN)早已成为基础架构。但当我们从理论研究转向实际部署时,标准卷积操作往往难以满足多样化的工程需求——移动端需要极致的计算效率,医学图像分割要…...

5分钟快速上手:BetterJoy让Switch手柄在PC上完美工作的终极指南
5分钟快速上手:BetterJoy让Switch手柄在PC上完美工作的终极指南 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://git…...

别再傻傻分不清了!华为交换机上三种ARP代理的实战配置与场景选择指南
华为交换机三种ARP代理的深度解析与实战指南 在复杂的网络环境中,ARP代理技术常常成为网络工程师的"隐形助手"。它像一位熟练的翻译官,在不同网络边界间架起沟通的桥梁。今天,我们就来揭开华为交换机上三种ARP代理技术的神秘面纱&…...

深入ego_planner状态机:从FSM回调函数看无人机如何应对突发障碍与目标点变化
深入解析ego_planner状态机:无人机动态避障与轨迹重规划的核心逻辑 当无人机在复杂环境中执行任务时,如何实时应对突发障碍和目标点变化是运动规划算法的核心挑战。ego_planner通过精心设计的状态机机制,实现了从初始规划到动态调整的全流程自…...

3步玩转AI视频神器:让短视频创作效率提升10倍
3步玩转AI视频神器:让短视频创作效率提升10倍 【免费下载链接】MoneyPrinterPlus AI一键批量生成各类短视频,自动批量混剪短视频,自动把视频发布到抖音,快手,小红书,视频号上,赚钱从来没有这么容易过! 支持本地语音模型chatTTS,fasterwhisper,GPTSoVITS,支持云语音&…...

数学建模小白必看:从组队到拿奖,避开这5个坑你也能成大神
数学建模竞赛避坑指南:从组队到获奖的实战策略 第一次参加数学建模竞赛时,我和两位室友组队,信心满满地选了最短的题目——结果三天后交了一篇连格式都没调好的论文。那次惨痛经历让我明白,数学建模远不止解题那么简单。本文将分…...

番茄小说下载器:构建个人离线数字图书馆的终极指南
番茄小说下载器:构建个人离线数字图书馆的终极指南 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 在数字阅读时代,你是否曾因网络中断而无法继续阅读心爱的小说&am…...

通义实验室推出 Fun-ASR1.5:方言工业级可用,多语言识别能力大幅提升!
通义实验室正式推出 Fun-ASR1.5 语音识别大模型,实现「方言工业级可用」,单模型覆盖 30 种语言及多种方言,典型方言场景字错误率大幅下降。多语言与方言覆盖Fun-ASR1.5 基于统一大模型架构,能无缝覆盖 30 种语言、汉语七大方言体系…...