linux 内存回收mglru算法代码注释2
mglru与原lru算法的兼容
旧的lru算法有active与inactive两代lru,可参考linux 内存回收代码注释(未实现多代lru版本)-CSDN博客
新的算法在引入4代lru的同时,还引入了tier的概念。
新旧算法的切换的实现在lru_gen_change_state,当开启mglru时,调用fill_evictable,将active list 与 inactive list 的folio迁移到 mglru上(mglru的组织方式是:lruvec[gen][type][zone]),如果是关闭mglru,则调用drain_evictable,将mglru的folio迁移回active/inactive list两代的情况。
当开启mglru时,原有shrink_node与shrink_lruvec的路径会短路,主要体现在两个地方,对于全局的回收直接调用lru_gen_shrink_node,对于某个memory group 的回收会间接调用lru_gen_shrink_lruvec:
shrink_nodeif (lru_gen_enabled() && root_reclaim(sc)) {lru_gen_shrink_node(pgdat, sc);return;}shrink_lruvecif (lru_gen_enabled() && !root_reclaim(sc)) {lru_gen_shrink_lruvec(lruvec, sc);return;}真正做页的回收的逻辑还是在shrink_folio_list。
mglru与原lru算法的差别
与旧的lru算法区别,主要有三个方面:1、修改了一次扫描要扫的数量计算逻辑。2、修改了代与代之间转换的逻辑。3、添加了refault页的延迟回收机制
mglru的组织
每个numa node 有一个 pgdat 结构,上面绑定了为每个memory group准备了两代bin list,分别为young bin list和old bin list,第个bin list 上有8个bin,新加入的memory group会随机找一个 bin list 加入(lru_gen_online_memcg)。回收总是在old代上做,找一个bin list,从头扫描到尾。memory group 会随着它分配的内存大小和是否做了回收,在old与young的bin list 头尾上游走。(lru_gen_rotate_memcg),具体而言:
1、memory group 的内存超过 soft limit 时,将它移至同代的开头,下次可能回收它(lru_gen_soft_reclaim,MEMCG_LRU_HEAD)
2、新加入的memory group会放在新代的结尾处,第一次扫描发现页数少于2^priority或是第一次扫描发现页数在low水位线以下时,会放在新代的结尾处(MEMCG_LRU_TAIL)
3、当第一次扫描发现内存在min水位以下,或第二次扫描发现上次扫描是小于2^priority的,或是每次扫描完足够页数时会把最后一个扫描的memory group 移至新代(MEMCG_LRU_YOUNG)。
4、在移除一个memory group时,需要回收全部内存,会把它放在old代(lru_gen_offline_memcg,MEMCG_LRU_OLD)
bin list 中每一项是memory group的lruvec指针。
lruvec内部分成了4代,每代有两个type:文件or匿名,每个type又维护了每个zone上的页框,如下:
// 找一个 group 对应在某个 node 上的lru
lruvec = &memcg->nodeinfo[pgdat->node_id]->lruvec.lrugen;
// 遍历一个 node 上某个 binlist 的 lru
lrugen = pgdat->memcg_lru.fifo[gen][bin];
// lru 内的页框
lrugen->folios[gen][type][zone]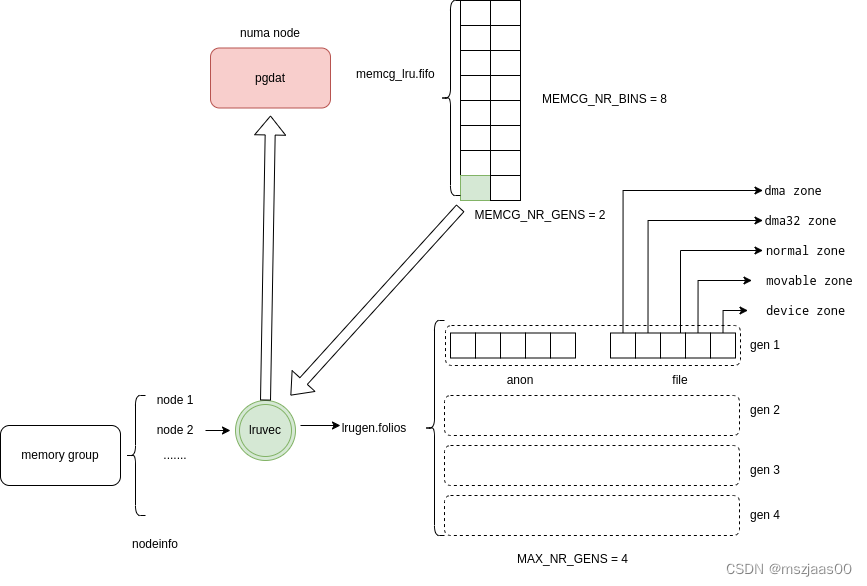
扫描数量
原有的swappiness表示回收匿名页与文件页的加权,取值1~200,值越小越支持从匿名页回收。新算法计算扫描数量的方法变了,只根据swappiness有无赋值来决定要不要计算扫描匿名页的数量,文件页一定会扫描回收。计算的方式也比较粗暴:total >> sc->priority;具体计算逻辑在get_nr_to_scan->should_run_aging。
代际转换
如果在should_run_aging计算时发现最新一代的页框数已经是总页框数的一半,或第三代的页框数小于总页框数的四分之一,就触发一次代际迭换,尝试发现young 页,把它们提升至最新代。代际迭换的代码在try_to_inc_max_seq。
try_to_inc_max_seq():// 硬件不支持自动标记access flagif (!should_walk_mmu()) {iterate_mm_list_nowalk(lruvec, max_seq);return;}// 尝试扫描 hot pmd 中的 young 页。 do {is_last = iterate_mm_list(lruvec, walk, &mm);if (mm)walk_mm(lruvec, mm, walk);} while (mm);// 这一代扫描结束,更新代际if (is_last)inc_max_seq(lruvec, can_swap, force_scan);如果硬件支持自动在页表记录访问标记,则扫描一遍(扫描的实现在try_to_inc_max_seq->walk_mm->walk_pgd_range->walk_pud_range->walk_pmd_range->walk_pte_range),通过检查bloom filter,找到标记为hot的pmd,访问pmd中全部pte,将标记脏的pte对应页框标记为脏,并更新至最新代。这里说的bloom filter标记了平均每个cacheline中young页数大于1的pmd,只需要对这些pmd的全部pte中young 页的扫描,并标记脏和更新代数,因为这个pmd范围的young页多,是个热点区,意味着后面可能还会产生hot页。如果硬件不支持自动设置访问标记,就不能在这个地方扫了,而要等到建立rmap时,folio_referenced_one->lru_gen_look_around
bloom filter的设置有两个途径,一个是在上面说的扫描全部pte之后,计算young页数/total页数大于cacheline中能装下的pte数(或者说是不是平均每个cacheline都有一个pte项对应了young页,实现在suitable_to_scan);另一个是在shrink_folio_list时,会找一个页框映射的次数(folio_referenced),会调一次lru_gen_look_around,尝试看下这个pte对应的pmd中全部pte,同样是在标记完脏页、统计完young页数时,计算young页数/total页数大于cacheline中能装下的pte数,并把young 标记清掉。
这个过程大概代码如下:
walk_pmd_range():
{
restart:for pmd_i in start_addr.. end_addr:// 检查是不是hot pmdif (!test_bloom_filter(max_seq, pmd_i))continue;// 检查hot pmd的所有pte中的脏页,并统计young的页数和清空young标记(young 指最近有访问),计算它还是不是hot pmdis_still_hot = walk_pte_range(addr, pmd_end_addr);// 如果是hot的pmd,则在bloom filter 标记一下,下一轮(代)扫描时再检查一次这个pmdif (is_still_hot)update_bloom_filter(max_seq + 1, pmd + i);}if (i < PTRS_PER_PMD && get_next_vma(PUD_MASK, PMD_SIZE, args, &start, &end))goto restart;
}walk_pte_range():new_gen = lru_gen_from_seq(walk->max_seq);
restart:for pte_i in start_addr.. end_addr: {// 硬件标记pte脏的,但页框没有标记脏,且这是文件页或未换出的匿名页,则在页框上标记下脏if (pte_dirty(ptent) && !folio_test_dirty(folio) &&!(folio_test_anon(folio) && folio_test_swapbacked(folio) &&!folio_test_swapcache(folio)))folio_mark_dirty(folio);// 将这一页框更新到最新代old_gen = folio_update_gen(folio, new_gen);// 更新统计walk->nr_pages[old_gen][type][zone] 和 walk->nr_pages[new_gen][type][zone]if (old_gen >= 0 && old_gen != new_gen)update_batch_size(walk, folio, old_gen, new_gen);}if (i < PTRS_PER_PTE && get_next_vma(PMD_MASK, PAGE_SIZE, args, &start, &end))goto restart;// 计算young页数/total页数大于cacheline中能装下的pte数(或者说是不是平均每个cacheline都有一个pte项对应了young页)return suitable_to_scan(total, young);
}Refault页的延迟回收
refault指缺页读入后又换出又读入。mglru引入tier概念,组织形式为lrugen->refaulted[hist][type][tier]。为file 和anon类型的页,维护了4代统计直方图(hist),每个直方图中有4个范围(tier),分别统计了本轮回收中访问了1次,2次,4次,8次的页数。
当触发refault时,会统计累加本轮回收中,已经refault这么多次的页数。(lru_gen_refault)
lru_gen_refault():// recent 指refault与上次回收在同一代内recent = lru_gen_test_recent(shadow, type, &lruvec, &token, &workingset);// 总共有4代histogram,根据当前代数算出它在那个histogram中hist = lru_hist_from_seq(READ_ONCE(lrugen->min_seq[type]));// 每代有4个tier,tier的index = log2(本轮扫描中这页的 access 数),即分别为访问1次,2次,4次,8次的tier。tier = lru_tier_from_refs(refs);// 统计累加本轮扫描过程中发生 2^tier 次 refault 的页数。atomic_long_add(delta, &lrugen->refaulted[hist][type][tier]);在决定是否回收页时,evict_folios->isolate_folios,会平衡本轮发生refault 的页数与回收+延时回收页数的比值,计算一个控制值(refaulted/(evicted+protected)),可以理解为发生refault的频繁程度。如果发生n次refault的频繁程度达到了发生1次refault频繁程度的2倍,则发生n次以上refault的页都不再回收。
isolate_folios():// 计算refault次数超过多少后不再释放tier_idx = get_tier_idx(lruvec, type);isolate_folios->scan_folios->sort_folio():// 本轮扫描中 refault 次数超过2^tier_idx 次的页不再释放,而是推到下一代if (tier > tier_idx) {// 将页放在下一次lru尾(回收是从本代的头开始的)gen = folio_inc_gen(lruvec, folio, false);list_move_tail(&folio->lru, &lrugen->folios[gen][type][zone]);// 累加本代中不释放页的页数int hist = lru_hist_from_seq(lrugen->min_seq[type]);WRITE_ONCE(lrugen->protected[hist][type][tier - 1],lrugen->protected[hist][type][tier - 1] + delta);return true;}在回收过程中,每完成一次分离出回收页的计算后(isolate_folios),会将这一代的统计值更新为新值与历史值的滑动平均值。
在一轮回收结束时,会调inc_max_seq将下一轮回收的代统计值清空,为最新代的统计留出位置。
相关文章:
linux 内存回收mglru算法代码注释2
mglru与原lru算法的兼容 旧的lru算法有active与inactive两代lru,可参考linux 内存回收代码注释(未实现多代lru版本)-CSDN博客 新的算法在引入4代lru的同时,还引入了tier的概念。 新旧算法的切换的实现在lru_gen_change_state&a…...
Exchange意外登录日志
最近在审计Exchange邮件系统的时候,发现大量用户半夜登录的日志。而且都是成功的,几乎没有失败的情况。其中Logon Type 8表示用户从网络登录。 Logon type 8: NetworkCleartext. A user logged on to this computer from the network. The user’s pas…...

NX二次开发UF_CURVE_ask_curve_turn_angle 函数介绍
文章作者:里海 来源网站:https://blog.csdn.net/WangPaiFeiXingYuan UF_CURVE_ask_curve_turn_angle Defined in: uf_curve.h int UF_CURVE_ask_curve_turn_angle(tag_t curve, double orientation [ 3 ] , double * angle ) overview 概述 Returns …...

UE 进阶篇一:动画系统
导语: 下面的动画部分功能比较全,可以参考这种实现方式,根据自己项目的颗粒度选择部分功能参考,我们商业项目动画部分也是这么实现的。 最后实现的效果如下: 最终效果 目录: ------------------------------------------- 文末有视频教程/工程地址链接 -------------…...

超文本传输协议
超文本传输协议(HypertextTransfer Protocol,HTTP)是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。请求和响应消息的头以ASCII形式给出;而消息内容…...

『heqingchun-Ubuntu系统+x86架构+编译安装ffmpeg+带有nvidia硬件加速』
Ubuntu系统x86架构编译安装ffmpeg带有nvidia硬件加速 一、准备文件 注:可直接下载我上传的CSDN资源,然后直接跳到"一"中的第"3"项"将文件按以下顺序存放"。 ffmpeg源码:音视频开发ffmpeg编译所需资源文件 其…...

UE5 UI教程学习笔记
参考资料:https://item.taobao.com/item.htm?spma21n57.1.0.0.2b4f523cAV5i43&id716635137219&ns1&abbucket15#detail 基础工程:https://download.csdn.net/download/qq_17523181/88559312 1. 介绍 工程素材 2. 创建Widget UE5 UI系统的…...
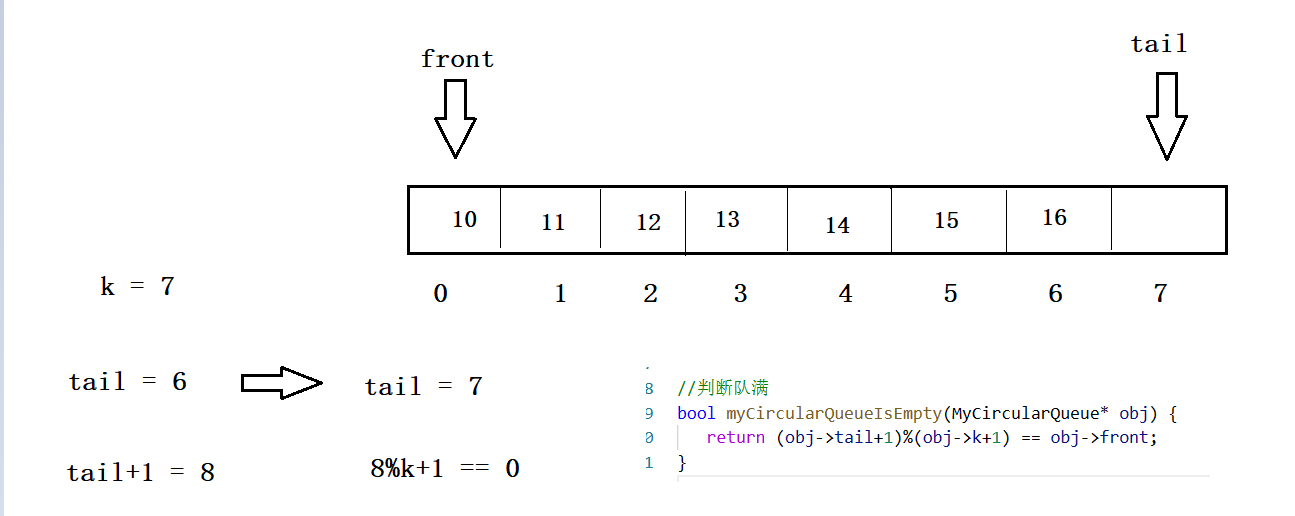
Leetcode:622. 设计循环队列 题解【具详细】
目录 一、题目: 二、思路详解: 1.循环队列的存储定义 2.循环队列的创建 3.循环队列的判空与判断情况 (1) 循环队列的判空: (2) 循环队列的判满 4.循环队列元素的插入 5.循环队列元素的删除 6.获取队头元素 7.获取队尾元素 8.循环队列释放 三…...

ArkTS基础知识 【习题】
判断题 1.循环渲染ForEach可以从数据源中迭代获取数据,并为每个数组项创建相应的组件。 正确(True) 2. Link变量不能在组件内部进行初始化。 正确(True) 单选题 1.用哪一种装饰器修饰的struct表示该结构体具有组件化能力?(A) A. Component B. Entry C…...

是否有无限提取的代理IP?作为技术你需要知道这些
最近有互联网行业的技术小伙伴问到,有没有可以无限提取的代理IP?就是比如我一秒钟提取几万、几十万次,或者很多台机器同时调用API提取链接,这样可以吗?看到这个问题,不禁沉思起来,其实理论上是存…...

【算法萌新闯力扣】:卡牌分组
力扣热题:卡牌分组 一、开篇 今天是备战蓝桥杯的第22天。这道题触及到我好几个知识盲区,以前欠下的债这道题一并补齐,哈希表的遍历、最大公约数与最小公倍数,如果你还没掌握,这道题练起来! 二、题目链接:…...

深入解析:如何开发抖音票务小程序
当下,开发抖音票务小程序成为了吸引年轻用户群体的一种创新方式。本文将深入解析如何开发抖音票务小程序,探讨关键步骤和技术要点。 1.确定需求和功能 考虑到抖音的用户特点,可以加入与短视频相关的票务功能,如在线购票、观影记录…...

vue中 mixin用法
在Vue.js中,mixin是一种可以在多个组件之间共享Vue组件选项的灵活方式。mixin对象可以包含任何组件选项。当组件使用mixin时,所有mixin对象的选项将被“混合”到该组件的选项中。 使用mixin的一个主要优点是可以在多个组件之间重用和共享代码。这可以帮…...

Java入门基础:浅显易懂 while
文章目录 前言一、布尔表达式二、while三、语法四、示例 前言 在开发过程中不管是 while 语句还是其他语句都会经常用到布尔表达式,所以在学习 while 之前需要先明白什么是布尔表达式? 一、布尔表达式 布尔表达式只有2种结果:true / false 看…...
DNS/ICMP协议、NAT技术
目录 DNS协议DNS背景域名简介 ICMP协议ICMP功能ping命令traceroute命令 NAT技术NAT技术背景NAT IP转换过程NAPTNAT技术的缺陷NAT和代理服务器 网络协议总结应用层传输层网络层数据链路层 DNS协议 DNS(Domain Name System,域名系统)协议&…...
)
React整理总结(七、Hooks)
1.Class组件的优缺点 优点 class组件可以定义自己的state,用来保存组件自己内部的状态;函数式组件不可以,因为函数每次调用都会产生新的临时变量;class组件有自己的生命周期,我们可以在对应的生命周期中完成自己的逻…...

软件测试之银行测试详解
一、金融类软件测试 举个栗子,银行里的软件测试工程师。横向跟互联网公司里的测试来说,薪资相对稳定,加班的话想对来说没那么多(有些银行加班也挺严重的),但业务稳定。实在是测试类岗位中的香饽饽…...

C#中的警告CS0120、CS0176、CS0183、CS0618、CS8600、CS8602、CS8604、CS8625及处理
目录 一、CS0120 二、CS0176 1.解决前 2.解决后 3.解决办法 三、CS0183 四、CS0618 五、CS8600 六、CS8602 七、CS8622 1. 解决前: 2. 解决后: 3.解决方法: 八、CS8604和CS8625 一、CS0120 严重性 代码 说明 项目 文件 行…...
CSS:浏览器设置placeholder样式 / 微信小程序设置placeholder样式
一、web 设置placeholder 设置浏览器的placeholder样式 ::-webkit-input-placeholder { /* WebKit browsers */color: #999; } :-moz-placeholder { /* Mozilla Firefox 4 to 18 */color: #999; } ::-moz-placeholder { /* Mozilla Firefox 19 */color: #999; } :-ms-input-p…...
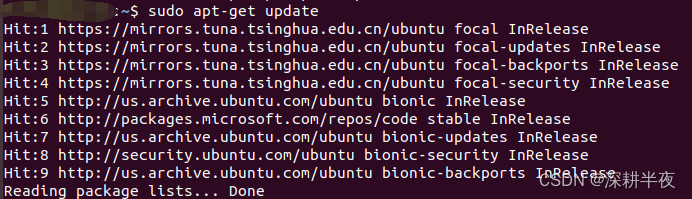
升级python后sudo apt-get update报错
sudo apt-get update 报错: sh: /usr/lib/cnf-update-db: /usr/bin/python3.7.5: bad interpreter: No such file or directory Reading package lists... Done E: Problem executing scripts APT::Update::Post-Invoke-Success if /usr/bin/test -w /var/lib/c…...

Obsidian Weread插件:一键同步微信读书笔记到知识库的高效解决方案
Obsidian Weread插件:一键同步微信读书笔记到知识库的高效解决方案 【免费下载链接】obsidian-weread-plugin Obsidian Weread Plugin is a plugin to sync Weread(微信读书) hightlights and annotations into your Obsidian Vault. 项目地址: https://gitcode.c…...

Degrees of Lewdity汉化版终极配置指南:从零开始的中文游戏体验
Degrees of Lewdity汉化版终极配置指南:从零开始的中文游戏体验 【免费下载链接】Degrees-of-Lewdity-Chinese-Localization Degrees of Lewdity 游戏的授权中文社区本地化版本 项目地址: https://gitcode.com/gh_mirrors/de/Degrees-of-Lewdity-Chinese-Localiza…...

SQL左连接查询结果为NULL怎么办_使用ISNULL函数替换空值技巧
LEFT JOIN 后字段为 NULL 是因右表无匹配行或连接条件不满足;ISNULL 为 SQL Server 特有、仅两参数且类型继承易截断,COALESCE 为标准函数、多参数且类型推导严谨;WHERE 中误写右表条件会使 LEFT JOIN 退化为 INNER JOIN;NULL 参与…...

XueQiuSuperSpider实战:游资追踪与龙虎榜数据分析完整方案
XueQiuSuperSpider实战:游资追踪与龙虎榜数据分析完整方案 【免费下载链接】XueQiuSuperSpider 雪球股票信息超级爬虫 项目地址: https://gitcode.com/gh_mirrors/xu/XueQiuSuperSpider XueQiuSuperSpider是一款功能强大的雪球股票信息超级爬虫,专…...

终极指南:如何用ViGEmBus虚拟手柄驱动彻底解决Windows游戏兼容性问题
终极指南:如何用ViGEmBus虚拟手柄驱动彻底解决Windows游戏兼容性问题 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否曾经遇到过这样的尴尬…...

从CRNN到BERT:图解BiLSTM如何成为NLP经典模块的‘骨架’
从CRNN到BERT:BiLSTM如何塑造NLP的十年技术演进 在自然语言处理领域,某些技术模块如同生物进化中的关键器官,它们跨越不同模型架构,成为解决特定问题的通用方案。BiLSTM(双向长短期记忆网络)正是这样一个&q…...
)
Windows 10 下 Node.js 16.15.1 保姆级安装与环境变量配置(含 npm 报错解决)
Windows 10 下 Node.js 16.15.1 完整安装与深度配置指南 对于刚接触 Node.js 开发的 Windows 用户来说,从零开始搭建开发环境往往会遇到各种"坑"。本文将带你一步步完成 Node.js 16.15.1 LTS 版本的安装、环境变量配置以及常见问题的解决方案,…...
)
别再写嵌套if了!用Java 8的Comparator.thenComparing优雅搞定多级排序(附实战代码)
告别嵌套if:用Java 8链式比较器重构电商多维度排序 每次看到同事在商品管理模块写下三层嵌套的if-else排序逻辑时,我都能从他颤抖的鼠标光标感受到那份绝望。上周五深夜,当我第N次调试一个漏判了null值的比较器时,终于决定彻底革新…...

OmenSuperHub:3步彻底解决惠普OMEN游戏本性能与散热难题
OmenSuperHub:3步彻底解决惠普OMEN游戏本性能与散热难题 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 对于众多惠普OMEN游戏本用户而言&…...

终极指南:3步免费解锁Cursor Pro完整功能,告别试用限制
终极指南:3步免费解锁Cursor Pro完整功能,告别试用限制 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reac…...