模型优化【2】-剪枝[局部剪枝]
模型剪枝是一种常见的模型压缩技术,它可以通过去除模型中不必要的参数和结构来减小模型的大小和计算量,从而提高模型的效率和速度。在 PyTorch 中,我们可以使用一些库和工具来实现模型剪枝。
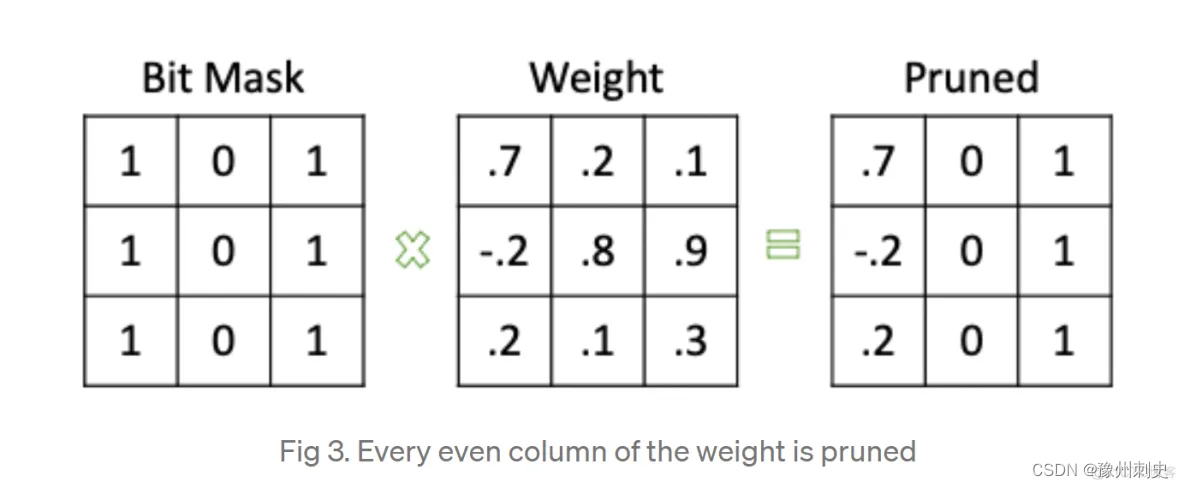
pytorch实现剪枝的思路是生成一个掩码,然后同时保存原参数、mask、新参数,如下图:
Pytorch实现模型剪枝的基本步骤
-
加载模型:我们首先需要加载一个已经训练好的模型,可以使用 PyTorch 提供的模型库或者自己训练的模型。
-
定义剪枝方法:我们需要定义一种剪枝方法,来决定哪些参数和结构需要被剪枝。
-
执行剪枝操作:我们需要执行剪枝操作,将不必要的参数和结构从模型中去除。
-
保存剪枝后的模型:我们需要将剪枝后的模型保存下来,以便后续使用。
pytorch 剪枝分为 局部剪枝、全局剪枝、自定义剪枝;
局部剪枝
局部剪枝是指在什么网络的单个层或局部范围内进行剪枝。
Pytorch中与剪枝有关的接口封装在torch.nn.utils.prune中。下面开始演示三种剪枝在LeNet网络中的应用效果,首先给出LeNet网络结构。
加载模型
import torch
from torch import nnclass LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()# 1: 图像的输入通道(1是黑白图像), 6: 输出通道, 3x3: 卷积核的尺寸self.conv1 = nn.Conv2d(1, 6, 3)self.conv2 = nn.Conv2d(6, 16, 3)self.fc1 = nn.Linear(16 * 5 * 5, 120) # 5x5 是经历卷积操作后的图片尺寸self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))x = F.max_pool2d(F.relu(self.conv2(x)), 2)x = x.view(-1, int(x.nelement() / x.shape[0]))x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x
model = LeNet().to(device=device)
局部剪枝实验,假定对模型的第一个卷积层中的权重进行剪枝
# 打印输出剪枝前的参数
module = model.conv1
print(list(module.named_parameters()))
print(list(module.buffers()))
print(module.weight)
运行结果
[('weight', Parameter containing:
tensor([[[[ 0.1158, -0.0091, -0.2742],[-0.1132, 0.1059, -0.0381],[ 0.0430, -0.1634, -0.1345]]],...[[[-0.0226, 0.2091, -0.1479],[ 0.2302, -0.0988, 0.2117],[-0.2000, -0.2531, 0.2770]]]], device='cuda:0', requires_grad=True)), ('bias', Parameter containing:
tensor([ 0.2658, 0.2096, -0.2639, -0.3063, -0.1453, 0.1201], device='cuda:0',requires_grad=True))]
[]
Parameter containing:
tensor([[[[ 0.1158, -0.0091, -0.2742],[-0.1132, 0.1059, -0.0381],[ 0.0430, -0.1634, -0.1345]]],...[[[-0.0226, 0.2091, -0.1479],[ 0.2302, -0.0988, 0.2117],[-0.2000, -0.2531, 0.2770]]]], device='cuda:0', requires_grad=True)
定义剪枝+执行剪枝
# 修剪是从 模块 中 删除 参数(如 weight),并用 weight_orig 保存该参数
# random_unstructured 是一种裁剪技术,随机非结构化裁剪
# 第一个参数:modeul,代表要进行剪枝的特定模型,之前我们已经制定了module=module.conv1,说明这里要对第一个卷积层执行剪枝
# 第二个参数:name,指定要对选中模块中的那些参数执行剪枝,这里设定为name='weight',意味着对连接网络的weight剪枝,而不死bias剪枝
# 第三个参数:amount,指定要对模型中的多大比例的参数执行剪枝,amount是一个介于0.0~1.0的float数值,或者一个正整数指定裁剪多少条连接边。
prune.random_unstructured(module, name="weight", amount=0.3) # weight bias
print(list(module.named_parameters()))
# 通过修剪技术会创建一个mask命名为 weight_mask 的模块缓冲区
print(list(module.named_buffers()))# 经过裁剪操作后的模型,原始的参数存放在了weight-orig中,
# 对应的剪枝矩阵存放在weight-mask中,而将weight-mask视作掩码张量
# 再和weight-orig相乘的结果就存放在了weight中
print(module.weight)
print(module.bias)
运行结果
[('bias', Parameter containing:
tensor([ 0.1303, 0.1208, -0.0989, -0.0611, -0.1103, -0.2433], device='cuda:0',requires_grad=True)), ('weight_orig', Parameter containing:
tensor([[[[-1.1443e-01, 3.2276e-01, -2.4664e-02],[ 4.6659e-02, 1.8311e-01, 6.6681e-02],[-2.5493e-01, -1.1471e-01, 2.8336e-01]]],...[[[ 1.4041e-01, 2.0963e-02, 2.2884e-01],[ 3.5870e-02, 7.5861e-02, 8.4728e-02],[ 4.1965e-02, -1.2838e-01, 8.8462e-02]]]], device='cuda:0',requires_grad=True))]
[('weight_mask', tensor([[[[1., 0., 0.],[1., 0., 0.],[0., 0., 0.]]],...[[[1., 0., 0.],[1., 0., 1.],[0., 1., 0.]]]], device='cuda:0'))]
tensor([[[[-1.1443e-01, 0.0000e+00, -0.0000e+00],[ 4.6659e-02, 0.0000e+00, 0.0000e+00],[-0.0000e+00, -0.0000e+00, 0.0000e+00]]],...[[[ 1.4041e-01, 0.0000e+00, 0.0000e+00],[ 3.5870e-02, 0.0000e+00, 8.4728e-02],[ 0.0000e+00, -1.2838e-01, 0.0000e+00]]]], device='cuda:0',grad_fn=<MulBackward0>)
Parameter containing:
tensor([ 0.1303, 0.1208, -0.0989, -0.0611, -0.1103, -0.2433], device='cuda:0',requires_grad=True)
保存剪枝后的模型
# 保存剪枝后的模型
torch.save(model.state_dict(), 'pruned_model.pth')
模型经历剪枝以后,原始的权重矩阵weight参数不见了,变成了weight_orig。并且剪枝前打印为空的列表module.name_buffers(),此时拥有了一个weight_mask参数。经过剪枝操作后的模型,原始的参数存放在了weight_orig中,对应的剪枝矩阵存在weight_mask中,而将weight_mask视作掩码张量,再和weight_orig相乘的结果就存在了weight中。
Q1:打印经过剪枝处理的 weight 参数。这个 weight 实际上是原始的 weight_orig 和 weight_mask 的元素乘积,其中被剪枝的权重会被设置为0。这个weight不是剪枝了嘛?为什么还能打印出来?
答:在Pytorch的剪枝过程中,当我们说剪枝一个权重的参数时,并不是真的从网络中移除这些参数,而是通过一个掩码来“禁用”它们。这是通过将某些权重的值设为0来实现的,从而在网络的前向传播中这些权重不会有任何作用,这种方法允许我们在保留原始权重信息的同时,实现剪枝的效果。
在 PyTorch 的剪枝过程中,当我们说“剪枝”一个权重参数时,并不是真的从网络中移除这些权重,而是通过应用一个掩码来“禁用”它们,为什么禁用就可以达到模型压缩的目的?为什么剪枝完,执行print(list(module.named_parameters())),没有显示weight属性,但是执行print(module.weight)时,weight依然存在?
- 为什么“禁用”权重可以达到模型压缩的目的?
虽然剪枝后的权重仍然占据内存空间,但在实际计算中,值为0的权重不会对前向传播产生任何影响。这意味着在计算层面可以忽略这些权重,从而减少计算量。 - 为什么 print(list(module.named_parameters())) 没有显示 weight 属性,但执行 print(module.weight) 时 weight 依然存在?
-
修改参数列表:当执行剪枝操作时,PyTorch 会修改模块的参数列表。原始的 weight 参数被重命名为 weight_orig,并且创建了一个新的名为 weight_mask 的缓冲区。原始的 weight 参数(现在是 weight_orig)和 weight_mask 通过一个钩子(hook)相结合,生成了新的 weight 属性。
-
动态权重生成:在调用 module.weight 时,由于剪枝过程中添加的前向钩子,weight 参数是动态生成的,它是 weight_orig 和 weight_mask 的元素乘积。因此,尽管 weight 在 named_parameters 列表中看起来已经不存在,但它实际上是在运行时动态生成的。
-
参数与属性的区别:在 PyTorch 中,模块的参数(可通过 named_parameters 访问)和模块的属性(如直接通过 module.weight 访问)是不同的。module.weight 被视为一个可访问的属性,但由于剪枝过程的内部处理,它可能不再直接列在模块的参数列表中。
-
既然原始的 weight 参数被重命名为 weight_orig,那参数是不是并没有发生变化,又怎么能达到剪枝的效果呢?
原始的 weight 参数在剪枝过程中被重命名为 weight_orig,并且保持不变。剪枝的效果是通过以下几个关键步骤实现的:
- 掩码(Mask)创建:
- 在剪枝过程中,PyTorch 创建了一个掩码(weight_mask),它是一个与 weight 形状相同的二进制张量(由0和1组成)。
- 在这个掩码中,1表示相应的权重保持不变,而0表示相应的权重被“剪枝”(实际上是被禁用)。
- 动态权重更新:
- 尽管 weight_orig 保持不变,但是模块的 weight 属性被动态更新为 weight_orig 和 weight_mask 的元素乘积。
- 这意味着,在模型的前向传播过程中,实际使用的 weight 是被掩码修改过的。在这个新的 weight 中,被剪枝的权重(在 weight_mask 中对应0的位置)的值为0,而其他位置的权重保持原始值。
- 前向传播的影响:
- 当模型进行前向传播时,使用的是被掩码修改过的 weight。因此,尽管原始的 weight 参数(现在是 weight_orig)没有变化,模型实际上使用的权重已经被剪枝修改了。
- 剪枝过程实际上通过使某些权重值为0,从而在模型的计算过程中禁用了这些权重。
- 模型复杂度的降低:
- 通过这种方式,模型的复杂度在实际运行时降低了,因为一部分权重不再对输出产生影响。
- 这可以提高计算效率,并且在某些情况下,可以通过专门的硬件和软件优化来利用权重的这种稀疏性。
综上所述,虽然原始的 weight 参数作为 weight_orig 保留下来,但是实际上模型使用的是被掩码修改过的权重,这就是剪枝效果的实现方式。这种方法的一个优势是可以在不永久性地移除权重的情况下,测试和评估剪枝的影响,甚至可以在必要时撤销剪枝操作。
相关文章:
模型优化【2】-剪枝[局部剪枝]
模型剪枝是一种常见的模型压缩技术,它可以通过去除模型中不必要的参数和结构来减小模型的大小和计算量,从而提高模型的效率和速度。在 PyTorch 中,我们可以使用一些库和工具来实现模型剪枝。 pytorch实现剪枝的思路是生成一个掩码࿰…...

VMware 系列:ESXI6.7升级7.0
ESXI6.7升级7.0 一、下载补丁二、上传文件三 启用Shell四、登录Shell后台五、删除不兼容驱动六、正常升级最近,将一台使用ESXI6.7的虚拟机升级到了7.0版本,下面记录一下自己的升级过程。 升级条件 首先确保硬件是否能升级到7.0版本,物理网卡驱动为e1000e不能升级,如果是ig…...
4-20mA高精度采集方案
下载链接!https://mp.weixin.qq.com/s?__bizMzU2OTc4ODA4OA&mid2247557466&idx1&snb5a323285c2629a41d2a896764db27eb&chksmfcfaf28dcb8d7b9bb6211030d9bda53db63ab51f765b4165d9fa630e54301f0406efdabff0fb&token976581939&langzh_CN#rd …...
案例022:基于微信小程序的行政复议在线预约系统
文末获取源码 开发语言:Java 框架:SSM JDK版本:JDK1.8 数据库:mysql 5.7 开发软件:eclipse/myeclipse/idea Maven包:Maven3.5.4 小程序框架:uniapp 小程序开发软件:HBuilder X 小程序…...
:模块缓存清理工具)
Go 工具链详解(七):模块缓存清理工具
go mod 缓存 在 Golang 中,模块是对一组版本化的包的集合的描述。Go 1.11 版本引入了模块支持,通过 go mod 命令提供了对模块的管理。Go 模块的一个重要特性是依赖管理,可以清晰地定义项目所依赖的模块及对应的版本,并确保代码使…...

1.7 C语言之函数概述
1.7 C语言之函数概述 一、概述二、练习 一、概述 函数就是把一组计算操作封装起来,供程序员调用,我们只需知道其提供了什么功能,而无需关注具体实现细节(前提是其久经考验,设计没有问题,后续我们自己写的函数大概率还…...
CTA-GAN:基于生成对抗性网络的主动脉和颈动脉非集中CT血管造影 CT到增强CT的合成技术
Generative Adversarial Network–based Noncontrast CT Angiography for Aorta and Carotid Arteries 基于生成对抗性网络的主动脉和颈动脉非集中CT血管造影背景贡献实验方法损失函数Thinking 基于生成对抗性网络的主动脉和颈动脉非集中CT血管造影 https://github.com/ying-f…...
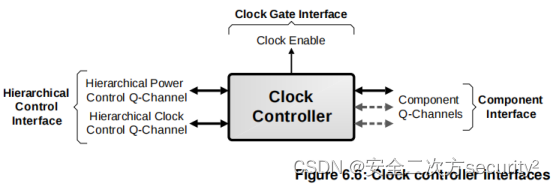
电源控制系统架构(PCSA)之电源管理基础设施组件
目录 6.5 电源管理基础设施组件 6.5.1 电源策略单元 6.5.2 时钟控制器 6.5.3 低功耗Distributor 6.5.4 低功耗Combiner 6.5.5 P-Channel到Q-Channel转换器 6.5 电源管理基础设施组件 6.5.1 电源策略单元 本节介绍电源策略单元(Power Policy Unit, PPU)。PPU的完整细节见…...

影刀RPA_boss直聘翻页(避坑)
boss直聘翻页这里有个坑 问题: 无限循环中,点击下一页按钮,直到不可点击为止。 发现,在点到第5页的时候,再次点击下一页,直接就点击了页码10,导致流程直接就结束了。 在第5页进行校验࿰…...

第十四章 控制值的转换 - 在DISPLAYLIST中投影值
文章目录 第十四章 控制值的转换 - 在DISPLAYLIST中投影值在DISPLAYLIST中投影值 第十四章 控制值的转换 - 在DISPLAYLIST中投影值 在DISPLAYLIST中投影值 对于 %String 类型(或任何子类)的属性,XML 投影可以使用 DISPLAYLIST 参数。 简单…...

C++类与对象(5)—流运算符重载、const、取地址
目录 一、流输出 1、实现单个输出 2、实现连续输出 二、流输入 总结: 三、const修饰 四、取地址 .取地址及const取地址操作符重载 五、[ ]运算符重载 一、流输出 1、实现单个输出 创建一个日期类。 class Date { public:Date(int year 1, int month 1,…...

Vue框架学习笔记——事件修饰符
文章目录 前文提要事件修饰符prevent(常用)stop(不常用)事件冒泡stop使用方法三层嵌套下的stop三层嵌套看出的stop: once(常用)capture(不常用)self(不常用&a…...

嵌入式虚拟机原理
欢迎关注博主 Mindtechnist 或加入【智能科技社区】一起学习和分享Linux、C、C、Python、Matlab,机器人运动控制、多机器人协作,智能优化算法,滤波估计、多传感器信息融合,机器学习,人工智能等相关领域的知识和技术。关…...

AMESim|Make failed:Unable to create an excutable for the system
最近在AMESIM与MATLAB进行联合仿真的时候遇到如下问题: Make failed:Unable to create an excutable for the system. 看了网上的解决办法如下 配置环境变量重装AMESIM,有顺序要求,首先是VS,然后是AMESIM与MATLAB。在AMESIM安装…...

OpenHarmony之NAPI框架介绍
张志成 诚迈科技高级技术专家 NAPI是什么 NAPI的概念源自Nodejs,为了实现javascript脚本与C库之间的相互调用,Nodejs对V8引擎的api做了一层封装,称为NAPI。可以在Nodejs官网(https://nodejs.org/dist/latest-v20.x/docs/api/n-api…...
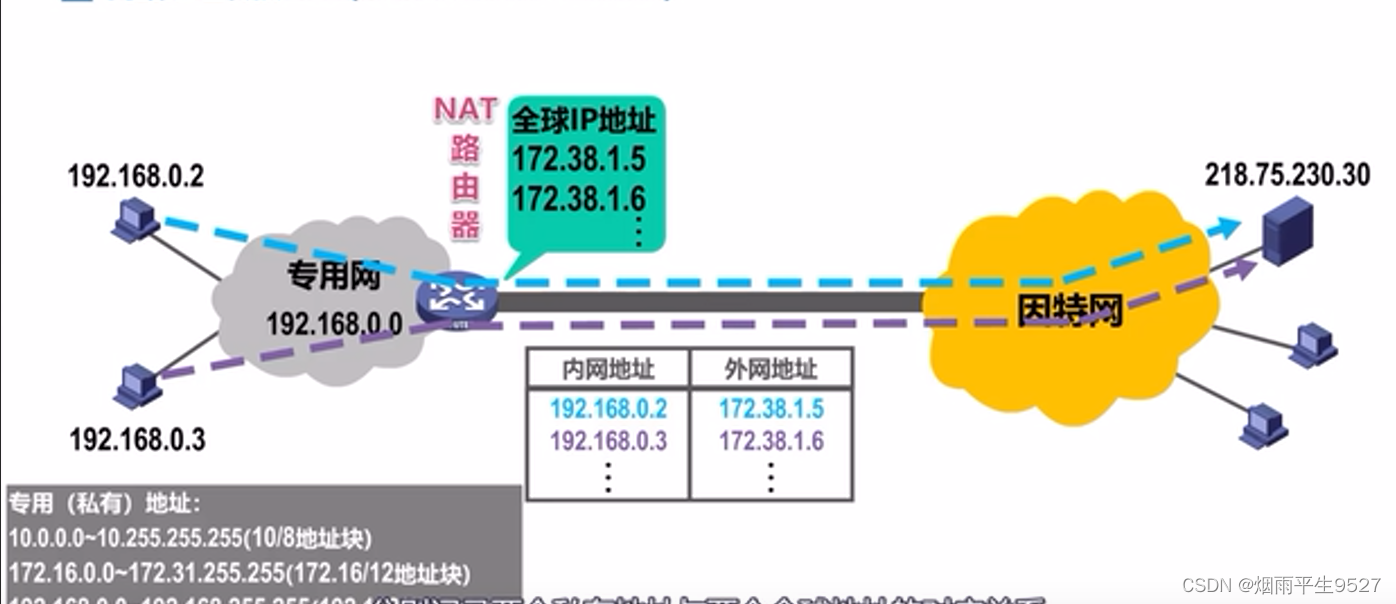
计算机网络之网络层
一、概述 主要任务是实现网络互连,进而实现数据包在各网络之间的传输 1.1网络引入的目的 从7层结构上看,网络层下是数据链路层 从4层结构上看,网络层下面是网络接口层 至少我们看到的网络层下面是以太网 以太网解决了什么问题? 答…...

【C指针(五)】6种转移表实现整合longjmp()/setjmp()函数和qsort函数详解分析模拟实现
🌈write in front :🔍个人主页 : 啊森要自信的主页 ✏️真正相信奇迹的家伙,本身和奇迹一样了不起啊! 欢迎大家关注🔍点赞👍收藏⭐️留言📝>希望看完我的文章对你有小小的帮助&am…...

浅谈电力设备智能无线温度检测系统
安科瑞 华楠 摘要:在长期工作中,由于设备基础变化、温湿度变化、严重超负荷运行、触点氧化等原因造成的电力设备压接不紧,触头接触部分发生改变。终导致接触电阻增大,造成巨大的风险隐患。本系统将通过无线测温的方式,…...
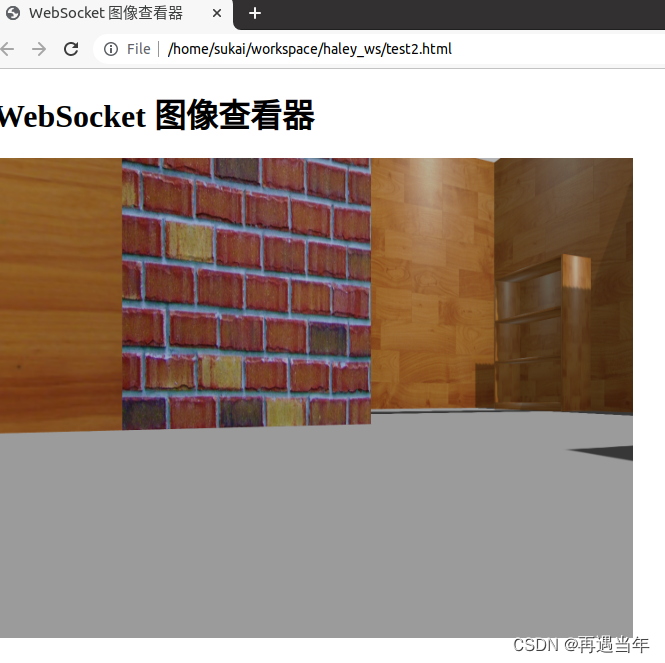
通过ros系统中websocket中发送sensor_msgs::Image数据给web端显示(二)
通过ros系统中websocket中发送sensor_msgs::Image数据给web端显示(二) mp4媒体流数据 #include <ros/ros.h> #include <signal.h> #include <sensor_msgs/Image.h> #include <message_filters/subscriber.h> #include <message_filters/synchroniz…...

LeetCode [简单] 283. 移动零
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请注意 ,必须在不复制数组的情况下原地对数组进行操作。 283. 移动零 - 力扣(LeetCode) 思路: 快慢指针&…...

AGI自主学习不是“试错”,而是“推演”——基于17万小时仿真数据的认知跃迁模型
第一章:AGI自主学习不是“试错”,而是“推演”——基于17万小时仿真数据的认知跃迁模型 2026奇点智能技术大会(https://ml-summit.org) 传统强化学习依赖海量环境交互与稀疏奖励信号,本质上是统计意义上的试错收敛;而新一代AGI认…...

PostgreSQL MVCC 深度解析
PostgreSQL MVCC 深度解析 摘要: 本文通过每条元组头部的 t_xmin 和 t_xmax 字段,解释 PostgreSQL 的多版本并发控制(Multi-Version Concurrency Control)在存储层的工作原理。展示了快照如何在并发会话之间确定可见性࿰…...

25+平台直播录制实战:Fideo跨平台架构解析与性能优化指南
25平台直播录制实战:Fideo跨平台架构解析与性能优化指南 【免费下载链接】fideo-live-record A convenient live broadcast recording software! Supports Tiktok, Youtube, Twitch, Bilibili, Bigo!(一款方便的直播录制软件! 支持tiktok, youtube, twitch, 抖音&am…...

OmenSuperHub终极指南:解锁惠普OMEN游戏本全部性能的完整教程
OmenSuperHub终极指南:解锁惠普OMEN游戏本全部性能的完整教程 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub OmenSuperHub是一款专为惠普OMEN…...

抖音批量下载工具终极指南:3分钟快速上手,轻松获取无水印内容
抖音批量下载工具终极指南:3分钟快速上手,轻松获取无水印内容 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and brow…...

如何用5个步骤实现网站完整离线备份方案
如何用5个步骤实现网站完整离线备份方案 【免费下载链接】WebSite-Downloader 项目地址: https://gitcode.com/gh_mirrors/web/WebSite-Downloader 你是否曾遇到过这种情况:收藏的重要网页突然无法访问,精心整理的教程网站突然改版,或…...

eqMac:macOS系统级音频均衡器与音量混合器的终极解决方案
eqMac:macOS系统级音频均衡器与音量混合器的终极解决方案 【免费下载链接】eqMac macOS System-wide Audio Equalizer & Volume Mixer 🎧 项目地址: https://gitcode.com/gh_mirrors/eq/eqMac 你是否曾为MacBook平淡的音质感到困扰࿱…...

告别复杂环境!用C# Winform + OpenCVSharp4 5分钟搞定一个桌面人脸识别小工具
5分钟极速开发:用C# Winform OpenCVSharp4打造桌面人脸识别工具 想象一下这样的场景:周一晨会上,产品经理突然提出需要一个能在Windows电脑上运行的人脸识别演示工具,要求周三前完成原型演示。作为C#开发者的你,如何在…...

从房价预测到用户分群:CART回归树与分类树在真实业务场景下的应用避坑指南
从房价预测到用户分群:CART回归树与分类树实战避坑指南 在金融风控和电商推荐系统中,我们经常需要预测用户的贷款违约概率或对客户进行价值分层。去年为某银行优化信用卡审批系统时,我曾用CART分类树将用户逾期率预测准确率提升了23%…...

新概念英语第二册09_A cold welcome
Lesson 9: A cold welcomeKey words and expressions Town Hall 市政厅crowd 人群gather 聚集strike 敲,打the minute hand 分针refusewelcomelaugh Questions on the text Where did people gather on the last evening of the year? The people gath…...