亚马逊云科技向量数据库助力生成式AI成功落地实践探秘(一)
随着大语言模型效果明显提升,其相关的应用不断涌现呈现出越来越火爆的趋势。其中一种比较被广泛关注的技术路线是大语言模型(LLM)+知识召回(Knowledge Retrieval)的方式,在私域知识问答方面可以很好的弥补通用大语言模型的一些短板,解决通用大语言模型在专业领域回答缺乏依据、存在幻觉等问题。其基本思路是把私域知识文档进行切片,然后向量化后续通过向量数据库检索进行召回,再作为上下文输入到大语言模型进行归纳总结。
在这个技术方向的具体实践中,知识库可以采取基于倒排和基于向量的向量数据库两种索引方式进行构建,它对于知识问答流程中的知识召回这步起关键作用,和普通的文档索引或日志索引不同,知识的向量化需要借助深度模型的语义化能力、存在文档切分、向量数据模型部署&推理等额外步骤。知识向量化建库即向量数据库过程中,不仅仅需要考虑原始的文档量级,还需要考虑切分粒度,向量维度等因素,最终被向量数据库索引的知识条数可能达到一个非常大的量级,可能由以下两方面的原因引起:
1.各个行业的既有文档量很高,如金融、医药、法律领域等,新增量也很大。
2.为了召回效果的追求,对文档的切分常常会采用按句或者按段进行多粒度的冗余存贮。
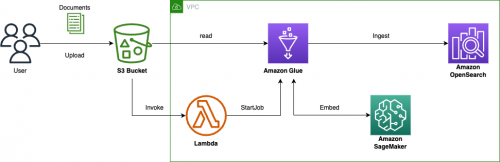
这些细节对知识向量数据库的写入和查询性能带来一定的挑战,为了优化向量化知识库的构建和管理,本文基于亚马逊云科技的服务,构建了如下图的知识库构建流程:
1.通过 S3 Bucket 的 Handler 实时触发 Amazon Lambda 启动对应知识文件入库的 Amazon Glue job;
2.Glue Job 中会进行文档解析和拆分,并调用 Amazon Sagemaker 的 Embedding 模型进行向量化;
3.通过 Bulk 方式注入到 Amazon OpenSearch 中去。

并对整个流程中涉及的多个方面,包括如何进行知识向量化、向量数据库调优总结了一些最佳实践和心得。
知识向量化(即向量数据库的原始步骤)的前置步骤是进行知识的拆分,语义完整性的保持是最重要的考量。分两个方面展开讨论。该如何选用以下两个关注点分别总结了一些经验:
a. 拆分片段的方法
关于这部分的工作,Langchain 作为一种流行的大语言模型集成框架,提供了非常多的 Document Loader 和 Text Spiltters,其中的一些实现具有借鉴意义,但也有不少实现效果是重复的。
目前使用较多的基础方式是采用 Langchain 中的 RecursiveCharacterTextSplitter,属于是 Langchain 的默认拆分器。它采用这个多级分隔字符列表 – [“\n\n”, “\n”, ” “, “”] 来进行拆分,默认先按照段落做拆分,如果拆分结果的 chunk_size 超出,再继续利用下一级分隔字符继续拆分,直到满足 chunk_size 的要求。
但这种做法相对来说还是比较粗糙,还是可能会造成一些关键内容会被拆开。对于一些其他的文档格式可以有一些更细致的做法。
FAQ 文件,必须按照一问一答粒度拆分,后续向量化的输入可以仅仅使用问题,也可以使用问题+答案(本系列 blog 的后续文章会进一步讨论)
Markdown 文件,”#”是用于标识标题的特殊字符,可以采用 MarkdownHeaderTextSplitter 作为分割器,它能更好的保证内容和标题对应的被提取出来。
PDF 文件,会包含更丰富的格式信息。Langchain 里面提供了非常多的 Loader,但 Langchain 中的 PDFMinerPDFasHTMLLoader 的切分效果上会更好,它把 PDF 转换成 HTML,通过 HTML 的 <div> 块进行切分,这种方式能保留每个块的字号信息,从而可以推导出每块内容的隶属关系,把一个段落的标题和上一级父标题关联上,使得信息更加完整。类似下面这种效果。
b. 模型对片段长度的支持
由于拆分的片段后续需要通过向量化模型进行推理,所以必须考虑向量化模型的 Max_seq_length 的限制,超出这个限制可能会导致出现截断,导致语义不完整。从支持的 Max_seq_length 来划分,目前主要有两类 Embedding 模型,如下表所示(这四个是有过实践经验的模型)。
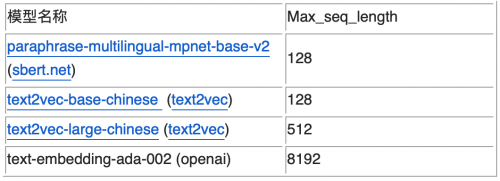
这里的 Max_seq_length 是指 Token 数,和字符数并不等价。依据之前的测试经验,前三个模型一个 token 约为 1.5 个汉字字符左右。而对于大语言模型,如 chatglm,一个 token 一般为 2 个字符左右。如果在切分时不方便计算 token 数,也可以简单按照这个比例来简单换算,保证不出现截断的情况。
前三个模型属于基于 Bert 的 Embedding 模型,OpenAI 的 text-embedding-ada-002 模型是基于 GPT3 的模型。前者适合句或者短段落的向量化,后者 OpenAI 的 SAAS 化接口,适合长文本的向量化,但不能私有化部署。
可以根据召回效果进行验证选择。从目前的实践经验上看 text-embedding-ada-002 对于中文的相似性打分排序性可以,但区分度不够(集中 0.7 左右),不太利于直接通过阈值判断是否有相似知识召回。
另外,对于长度限制的问题也有另外一种改善方法,可以对拆分的片段进行编号,相邻的片段编号也临近,当召回其中一个片段时,可以通过向量数据库的 range search 把附近的片段也召回回来,也能保证召回内容的语意完整性。
我们上面提到四个向量数据库模型只是提到了模型对于文本长度的支持差异,效果方面目前并没有非常权威的结论。可以通过 leaderboard 来了解各个模型的性能,榜上的大多数的模型的评测还是基于公开数据集的 benchmark,对于真实生产中的场景 benchmark 结论是否成立还需要 case by case 地来看。但原则上有以下几方面的经验可以分享:
经过垂直领域 Finetune 的模型比原始向量模型有明显优势;
目前的向量化模型分为两类,对称和非对称。未进行微调的情况下,对于 FAQ 建议走对称召回,也就是 Query 到 Question 的召回。对于文档片段知识,建议使用非对称召回模型,也就是 Query 到 Answer(文档片段)的召回;
没有效果上的明显的差异的情况下,尽量选择向量维度短的模型,高维向量(如 openai 的 text-embedding-ada-002)会给向量数据库造成检索性能和成本两方面的压力。
更多的内容会在本系列的召回优化部分进行深入讨论。
真实的业务场景中,文档的规模在百到百万这个数量级之间。按照冗余的多级召回方式,对应的知识条目最高可能达到亿的规模。由于整个离线计算的规模很大,所以必须并发进行,否则无法满足知识新增和向量检索效果迭代的要求。步骤上主要分为以下三个计算阶段。

文档切分并行
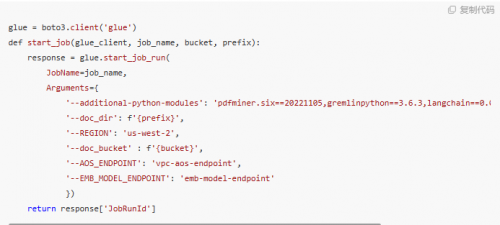
计算的并发粒度是文件级别的,处理的文件格式也是多样的,如 TXT 纯文本、Markdown、PDF 等,其对应的切分逻辑也有差异。而使用 Spark 这种大数据框架来并行处理过重,并不合适。使用多核实例进行多进程并发处理则过于原始,任务的观测追踪上不太方便。所以可以选用 Amazon Glue 的 Python shell 引擎进行处理。主要有如下好处:
1.方便的按照文件粒度进行并发,并发度简单可控。具有重试、超时等机制,方便任务的追踪和观察,日志直接对接到 Amazon CloudWatch;
2.方便的构建运行依赖包,通过参数–additional-python-modules 指定即可,同时 Glue Python 的运行环境中已经自带了 opensearch_py 等依赖。
可参考如下代码:
注意:Amazon Glue 每个账户默认的最大并发运行的 Job 数为 200 个,如果需要更大的并发数,需要申请提高对应的 Service Quota,可以通过后台或联系客户经理。
向量化推理并行
由于切分的段落和句子相对于文档数量也膨胀了很多倍,向量数据库模型的推理吞吐能力决定了整个流程的吞吐能力。这里采用 SageMaker Endpoint 来部署向量化模型,一般来说为了提供模型的吞吐能力,可以采用 GPU 实例推理,以及多节点 Endpoint/Endpoint 弹性伸缩能力,Server-Side/Client-Side Batch 推理能力这些都是一些有效措施。具体到离线向量知识库构建这个场景,可以采用如下几种策略:
GPU 实例部署
向量化模型 CPU 实例是可以推理的。但离线场景下,推理并发度高,GPU 相对于 CPU 可以达到 20 倍左右的吞吐量提升。所以离线场景可以采用 GPU 推理,在线场景 CPU 推理的策略。
多节点 Endpoint
对于临时的大并发向量生成,通过部署多节点 Endpoint 进行处理,处理完毕后可以关闭*(注意:离线生成的请求量是突然增加的,Auto Scaling 冷启动时间 5-6 分钟,会导致前期的请求出现错误)*
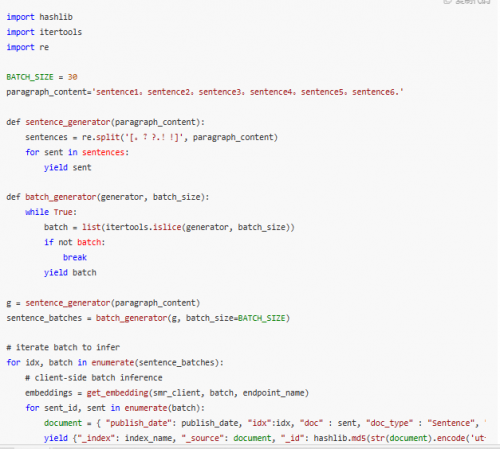
利用 Client-Side Batch 推理
离线推理时,Client-side batch 构造十分容易。无需开启 Server-side Batch 推理,一般来说 Sever-side batch 都会有个等待时间,如 50ms 或 100ms,对于推理延迟比较高的大语言模型比较有效,对于向量化推理则不太适用。可以参考如下代码:
OpenSearch 批量注入
Amazon OpenSearch 的写入操作,在实现上可以通过 bulk 批量进行,比单条写入有很大优势。参考如下代码:

相关文章:
亚马逊云科技向量数据库助力生成式AI成功落地实践探秘(一)
随着大语言模型效果明显提升,其相关的应用不断涌现呈现出越来越火爆的趋势。其中一种比较被广泛关注的技术路线是大语言模型(LLM)知识召回(Knowledge Retrieval)的方式,在私域知识问答方面可以很好的弥补通…...

C# MemoryCache的使用和封装
封装个缓存类,方便下次使用。 using Microsoft.Extensions.Caching.Memory; using System; using System.Collections.Generic;namespace Order.Core.API.Cache {public class GlobalCache C#有偿Q群:927860652{private static readonly MemoryCache …...
)
【nlp】4.2 nlp中标准数据集(GLUE数据集合中的dev.tsv 、test.tsv 、train.tsv)
nlp中标准数据集 1 GLUE数据集合介绍1.1 数据集合介绍1.2 数据集合路径2 GLUE子数据集的样式及其任务类型2.1 CoLA数据集文件样式2.2 SST-2数据集文件样式2.3 MRPC数据集文件样式2.4 STS-B数据集文件样式2.5 QQP数据集文件样式2.6 (MNLI/SNLI)数据集文件样式2.7 (QNLI/RTE/WNLI…...

Java LinkedList
LinkedList 一个双向链表。 本身是基于链表进行封装的列表, 所以具备了链表的特性: 变更简单, 容量是无限的, 不必像数组提前声明容量等。 同时 LinkedList 支持存储包括 null 在内的所有数据类型。 1 链表 了解 LinkedList 之前, 我们需要先了解一下双向链的特点 单链表, 双…...
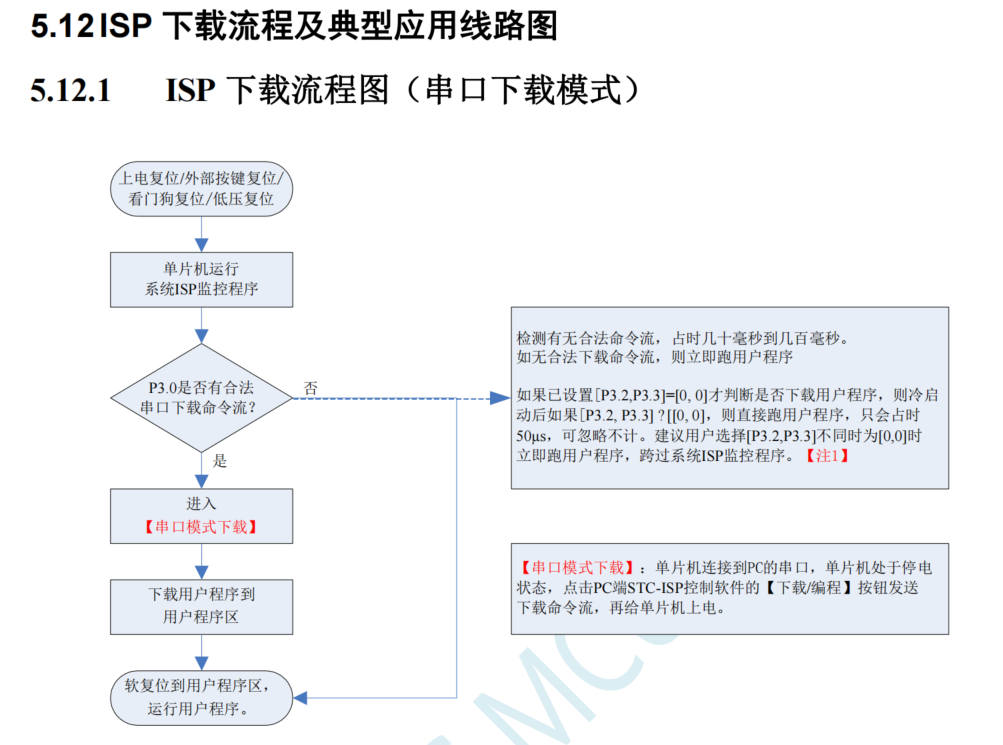
【单片机学习笔记】STC8H1K08参考手册学习笔记
STC8H1K08参考手册学习笔记 STC8H系列芯片STC8H1K08开发环境串口烧录 STC8H系列芯片 STC8H 系列单片机是不需要外部晶振和外部复位的单片机,是以超强抗干扰/超低价/高速/低功耗为目标的 8051 单片机,在相同的工作频率下,STC8H 系列单片机比传统的 8051约快12 倍速度…...

RevCol:可逆的柱状神经网络
文章目录 摘要1、简介2、方法2.1、Multi-LeVEl ReVERsible Unit2.2、可逆列架构2.2.1、MACRo设计2.2.2、MicRo 设计2.3、中间监督3、实验部分3.1、图像分类3.2、目标检测3.3、语义分割3.4、与SOTA基础模型的系统级比较3.5、更多分析实验3.5.1、可逆列架构的性能提升3.5.2、可逆…...

HCIA-RS基础-RIP路由协议
前言: RIP路由协议是一种常用的距离矢量路由协议,广泛应用于小规模网络中。本文将详细介绍RIP路由协议的两个版本:RIPv1和RIPv2,并介绍RIP的常用配置命令。通过学习本文,您将能够掌握RIP协议的基本原理、RIPv1和RIPv2的…...
虚拟化逻辑架构: LBR 网桥基础管理
目录 一、理论 1.Linux Bridge 二、实验 1.LBR 网桥管理 三、问题 1.Linux虚拟交换机如何增删 一、理论 1.Linux Bridge Linux Bridge(网桥)是用纯软件实现的虚拟交换机,有着和物理交换机相同的功能,例如二层交换&#…...

【Spring之AOP底层源码解析,持续更新中~~~】
文章目录 一、动态代理1.1、ProxyFactory1.2、Advice的分类1.3、Advisor的理解 二、创建代理对象的方式2.1、ProxyFactoryBean2.2、BeanNameAutoProxyCreator2.3、DefaultAdvisorAutoProxyCreator 三、Spring AOP的理解3.1、AOP中的概念3.2、Advice在Spring AOP中对应API3.3、T…...

C语言:有一篇文章,共三行文字,每行有80个字符。要求分别统计出单词个数、空格数。
分析: #include<stdio.h>:这是一个预处理指令,将stdio.h头文件包含到程序中,以便使用输入输出函数。 int main():这是程序的主函数,是程序执行的入口点。 char a[3][80];:定义了一个二维…...

【数据结构与算法篇】一文详解数据结构之二叉树
树的介绍及二叉树的C实现 树的概念相关术语树的表示 树的概念 树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一 个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树, 也就是说它是根朝上,而叶朝…...

Windows主机信息收集命令
一.常用信息搜集 whoami # 查看当前用户 net user # 查看所有用户 query user # 查看当前在线用户 ipconfig /all # 查看当前主机的主机名/IP/DNS等信息 route print # 查看路由表信息 netstat -ano # 查看端口开放情况 arp -a # 查看arp解析情况 tasklist /svc # 查看进…...

「go module」一文总结 go mod 入门使用
文章目录 什么是 Go Modules为什么要使用 Modules怎么使用前置条件项目初始化如何安装/管理依赖?依赖安装 go get版本选择方式 替换版本 replace间接依赖 && go mod tidy远程代理 总结 什么是 Go Modules Module 是 Go 的依赖管理工具。 核心概念 Module…...

48. 旋转图像 --力扣 --JAVA
题目 给定一个 n n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。 解题思路 顺时针旋转90度 上下翻转 对角线翻转;两次两层循环…...
——第17期)
Java中的jvm——面试题+答案(Java虚拟机更深层次的概念和原理,包括字节码、代理、内存管理、并发等)——第17期
什么是即时编译(JIT Compilation)? 答案: 即时编译是一种在运行时将字节码转换为本地机器代码的技术,以提高程序的执行速度。JVM中的JIT编译器负责执行这个过程。 什么是Java字节码?为什么Java使用字节码…...

docker打包前端镜像
文章目录 一、构建镜像二、查看本地镜像三、启动容器四、查看启动的容器五、保存镜像六、读取镜像七、创建镜像八、最后 docker官网 一、构建镜像 -t是给镜像命名,.(点)是基于当前目录的Dockerfile来构建镜像 docker build -t image_web .二、查看本地镜像 docke…...

深入理解数据结构:链表
文章目录 🌰导语🌰链表的定义及基本结构🌰单链表🥕单链表特点 🌰双向链表🥕双链表特点 🌰循环链表🥕循环链表特点 🌰链表的操作🍆链表的插入🫘链头…...
)
7:kotlin 数组 (Arrays)
数组是一种数据结构,它保存固定数量的相同类型或其子类型的值。kotlin中最常见的数组类型是对象类型数组,数组由array类表示。 什么时候使用 当你在kotlin中有特殊的底层需求需要满足时,可以使用数组。例如,如果你有超出常规应用…...

mysql 变量和配置详解
MySQL 中还有一些特殊的全局变量,如 log_bin、tmpdir、version、datadir,在 MySQL 服务实例运行期间它们的值不能动态修改,也就是不能使用 SET 命令进行重新设置,这种变量称为静态变量。数据库管理员可以使用前面提到的修改源代码…...

算法基础之合并集合
合并集合 核心思想:并查集: 1.将两个集合合并2.询问两个元素是否在一个集合当中 基本原理:每个集合用一棵树表示 树根的编号就是整个集合的编号 每个节点存储其父节点,p[x]表示x的父节点 #include<iostream>using namespace std;const int N100010;int p[N];…...

mysql数据库索引失效的常见原因_分析索引设计与使用误区
MySQL索引失效主因有三:WHERE中对字段用函数或表达式(如YEAR(create_time))、复合索引中范围查询后列无法命中、统计信息过期或数据倾斜致优化器误判;需改写为范围条件、定期ANALYZE TABLE并警惕隐式转换。WHERE 条件用了函数或表…...
:AI原生测试的7层抽象架构与4类不可逆迁移陷阱)
2026奇点大会闭门报告首发(仅限首批200名工程负责人):AI原生测试的7层抽象架构与4类不可逆迁移陷阱
第一章:2026奇点智能技术大会:AI原生测试自动化 2026奇点智能技术大会(https://ml-summit.org) 在2026奇点智能技术大会上,“AI原生测试自动化”不再是一个愿景,而是已落地的工程范式——它将大语言模型、多模态推理与测试生命周…...

告别失眠困扰,3步瑜伽入睡法让你享受优质深度睡眠
我们很多人都经历过躺在床上翻来覆去、大脑却异常清醒的夜晚?作为中国“瑜伽之母”,张蕙兰老师将瑜伽智慧与现代生活相结合,创立了一套独特的“瑜伽入睡法”。本文将带你深入了解如何通过古老的瑜伽智慧,无需药物,轻松…...

台达PLC伺服追剪程序及电子凸轮技术,含DVP15MC源代码与触摸屏程序一体化解决方案
台达PLC伺服追剪程序,电子凸轮,全部源代码,PLC程序和触摸屏程序,DVP15MC。最近在搞台达PLC的追剪项目,发现里面电子凸轮的设计挺有意思。直接上干货,咱们先看这个追剪系统的核心逻辑——电子凸轮的参数配置…...

如何处理phpMyAdmin提示配置文件读取失败_文件属组与读写权限调整
根本原因是PHP进程无法读取config.inc.php文件,主因是系统级权限问题:Web服务器用户(如www-data)无读取权限,或文件权限为666/660等不安全组合,或SELinux/AppArmor拦截,或符号链接目标权限错误。…...

AspNet MVC4 教学:AspNet MVC4 页面动态生成演示
HomeControllers.cs文件内容:using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.Web.Mvc;namespace MvcDynamicPage.Controllers {public class HomeController : Controller{//// GET: /Home/public ActionResult Index(){…...

FreakStudio锰
环境安装 pip install keystone-engine capstone unicorn 这3个工具用法极其简单,下面通过示例来演示其用法。 Keystone 示例 from keystone import * CODE b"INC ECX; ADD EDX, ECX" try:ks Ks(KS_ARCH_X86, KS_MODE_64)encoding, count ks.asm(CODE)…...

别再只会adb disable-verity了!深入拆解Android dm-verity如何守护你的system分区安全
深入拆解Android dm-verity:系统分区安全的最后防线 当你在调试Android系统时,是否遇到过这样的场景:修改了/system分区的某个关键文件,重启后却发现改动神奇地"消失"了?或者尝试刷入自定义ROM时,…...
移除shape中长度为1的冗余轴)

Altium Designer 21 保姆级教程:从PCB到Gerber文件,一次搞定所有制造输出设置
Altium Designer 21 全流程制造输出指南:从PCB设计到Gerber文件生成 在电子设计领域,将PCB设计转化为实际可生产的制造文件是一个关键但常被忽视的环节。许多新手工程师和学生往往在完成布局布线后,面对制造输出菜单中的各种选项感到无所适从…...